基于特征點群相似度計算模型的圖像表示方法
2017-10-10 01:04:43何敬劉仁義張豐杜震洪陳永佩
浙江大學學報(理學版) 2017年5期
何敬, 劉仁義, 張豐, 杜震洪*, 陳永佩
(1.浙江大學 浙江省資源與環境信息系統重點實驗室, 浙江 杭州 310028;2.浙江大學 地理信息科學研究所, 浙江 杭州 310027)
基于特征點群相似度計算模型的圖像表示方法
何敬1,2, 劉仁義1,2, 張豐1,2, 杜震洪1,2*, 陳永佩1,2
(1.浙江大學 浙江省資源與環境信息系統重點實驗室, 浙江 杭州 310028;2.浙江大學 地理信息科學研究所, 浙江 杭州 310027)
針對空間金字塔匹配模型缺乏對圖像中視覺物體旋轉、平移和縮放的考慮問題,提出了一種基于特征點群相似度計算模型的圖像表示方法.基于詞匯樹模型的粗匹配結果,通過特征點群拓撲、方向、距離等計算其相似度,并以此作為評價指標對匹配結果進行過濾;根據由特征點群計算所得的標準差橢圓的圓心、旋轉角度對金字塔匹配的圖像劃分子區域并進行調整,從而得到圖像抗旋轉、平移和縮放的表示.分別在自建校園建筑物數據集和自建物體圖像數據集上對方法進行了驗證和比較,結果表明,該方法提高了分類識別的準確率和檢索的查全率,特別是對于包含明顯旋轉、平移和縮放變化的圖像數據效果更好.
特征點群相似度;Voronoi圖;標準差橢圓;FREAK特征描述;空間金字塔匹配
近年來,圖像中空間位置信息的研究成了圖像識別領域的研究熱點,且隨著各個學科的發展融合,GIS(geographic information system)中的空間關系理論已成為研究圖像檢索中特征點之間關系的一個重要方向.
基于地理位置服務的增強現實(augmented reality,AR)技術是目前智慧校園建設中重要的技術手段.隨著數字圖像的大量增加,傳統的基于內容的圖像搜索方法很難滿足目前的檢索需求.NISTER等[1]提出的基于詞匯樹的詞袋模型表示算法是目前圖像檢索領域的主流算法.LAZEBNIK等[2]提出的空間金字塔匹配SPM(spatial pyramid matching)采用多尺度分塊,分別統計并比較每一個子塊的特征,考慮了視覺詞袋模型忽視的視覺單詞在圖像上的空間分布信息.SPM能有效提升圖像的識別精度,得到了普遍認可和廣泛應用.
然而,SPM方法是對圖像整體進行劃分,限制了視覺目標在圖像上的位置,具體表現為對發生了旋轉、平移和縮放的圖像的表示所包含的信息不精確,導致匹配精確度下降.本文研究的圖像數據集為校園建筑物數據,這些建筑物圖片具有一定的規格,同時主體明顯,背景一般較為干凈.數據集中的圖像在采集的過程中,由于設備、人員的不同,常常會出現圖片旋轉的狀況,導致視覺目標發生較為嚴重的旋轉變化,同時也伴有一定的尺度和平移變化.
結合本文的數據特點,同時考慮到移動端設備對于特征提取的效率,本文在SPM方法的基礎上進行了改進,提出了一種基于特征點群相似度計算模型的圖像表示方法.該方法采取FREAK二進制描述符進行圖像特征的提取,并構建詞匯樹模型.通過詞匯樹模型的粗匹配,篩選出距離目標圖像較近的訓練圖像.在此基礎上,對粗篩選結果進行特征點群相似度計算,過濾特征點群相似度較差的訓練圖像.然后,借助由特征點群計算得到的標準差橢圓的圓心、旋轉角度來調整SPM對圖像子區域的劃分,提高SPM在處理發生旋轉、平移和尺度變化的圖像時的精確度.
1 相關研究
1.1 FREAK特征描述符
移動終端設備在配置和性能上與普通計算機仍存在一定的差距,傳統的SIFT等算法存在計算量大、占用內存多、匹配時間長等問題.因此,近年來,出現了一些實效性更強、更適合在移動端計算的特征點提取和描述方法.CALONDER等[3]提出的BRIEF算法, RUBLEE等[4]提出的ORB算法, ALAHI等[5]提出的FREAK算法等,都采用了二進制描述符,降低了描述符的維度,依靠計算特征描述符之間的漢明距離,使得運算速度和內存占用得到了優化.文獻[6]證明了FREAK算法在處理諸多變化時其性能強于ORB算法和BRIEF算法,特別在處理光照變化時其穩定性最好.
FREAK是一種二值描述符,其核心思想就是采用仿視網膜結構的采樣模板對特征點進行描述符構造[5].與人眼的視網膜神經節細胞相似,FREAK特征描述符采樣點結構由許多大小不同并有重疊的圓構成.圓代表感受野,重疊的結構可以獲取更多的信息;對應的圓心代表采樣點,采樣點均勻分布在以特征點為中心的同心圓上.同時,FREAK采樣結構根據距離特征點的距離決定采樣密集度,離中心特征點越近,采樣點越密集.通過采樣點之間像素值的兩兩比較級聯成的FREAK描述子是二進制比特串,假設F為某個特征點的FREAK描述符,則
(1)
其中,Pa是第a對采樣點,N表示描述符的維數,且T(Pa)滿足:
(2)
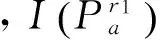
本文選取較高維的二進制特征描述符——FREAK特征在客戶端對圖像進行處理,同時在服務器端采取同樣的特征進行層級式聚類,以漢明空間概率中心向量作為聚類中心,進行詞匯樹的構建.
1.2 基于詞匯樹的金字塔匹配方法
詞袋模型源于自然語言處理和信息檢索,與文本相似,圖像可以被視為一些與位置無關的局部特征的集合.基于樹形結構的詞袋模型通過樹形結構的層次索引方式,解決了非層次化檢索量化過程太慢的問題,大大提高了檢索的效率[1].
詞匯樹采用TF-TDF模型量化訓練圖像各特征在詞匯樹中的分布情況,本文詞匯樹各節點權值計算采用文獻[7]的計算方法.
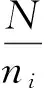
(3)
其中,mi,j為視覺單詞Fi在圖像Pj中出現的次數,N為訓練圖像的總數,ni為包含視覺單詞Fi的訓練圖像數目.
依據生成的詞匯樹,可將圖像特征表示轉化為視覺單詞表示.具體過程為:對于圖像中提取的某特征點,計算其與視覺詞典中各個視覺單詞間的距離,找到距離最近的視覺單詞代替此底層特征.對圖像所有提取的特征點重復上述步驟,并通過統計圖像中每個視覺單詞出現的頻次得到該圖像的視覺詞匯直方圖.通過TF-TDF模型量化,圖片可由向量[w1,j,w2,j,w3,j,w4,j…,wM-1,j,wM,j]表示.
視覺詞袋模型忽略了圖像視覺單詞之間的空間分布信息.SPM采用多尺度的分塊方法,即將特征空間劃分為不同尺度0,1,…,L,在尺度l下特征空間的每一維劃出2l個細分區域.在每個尺度下計算每個細分子區域內的直方圖,每層金字塔的提取方式和分塊直方圖類似,當L=0時,即為詞袋模型的情景.SPM將圖像劃分為金字塔各個水平上需逐漸精細的網格序列,然后分別計算各個子區域的詞典直方圖向量,將不同層次、不同區域的直方圖向量組合起來,以此作為圖像的表示.這樣雖然考慮了特征點的空間信息,但是SPM限制了目標在圖像中出現的方位,當圖像目標出現旋轉、平移和縮放變化時,匹配精確度就會受到比較大的影響.
在GIS中,空間關系具有尺度、認知、層次、拓撲等特征.本文針對空間金字塔模型的缺陷,提出了基于特征點群相似度計算模型的圖像表示方法.該方法通過計算特征點群之間的空間拓撲相似度、距離相似度和方向相似度對圖像進行篩選,并圍繞由特征點群計算得到的標準差橢圓的中心以及旋轉角度來調整SPM對圖像子區域的劃分,以進一步增強圖像分類檢索的準確性.
2 基于特征點群相似度計算模型的圖像表示方法
2.1 基于FREAK特征的層級式聚類
FREAK是二進制描述符,二進制向量漢明空間一般采用漢明距離衡量二進制特征差異.在對二進制向量進行聚類的過程中,需要將這些二進制向量分成K份,每一份用一個均值向量表示,也就是所謂的聚類中心.
文獻[8]證明了漢明空間存在密集邊緣特性,同時由于漢明距離中心不具有明顯的區分性,二進制向量聚類也無法求出理想的聚類中心.為了有效克服這些問題,本文采取512維的FREAK特征,避免了邊緣密集特征,用概率中心與詞匯樹節點替代原始二進制中心向量[9]進行關聯,能有效量化特征分布情況.
2.2 特征點群相似度計算模型
當通過詞匯樹進行粗篩選后,得到與待匹配圖像距離較為接近的一些訓練圖像.由于詞袋模型對特征點空間信息的描述有缺失,此時,可能會在結果集中遇到僅僅與直方圖統計結果近似,但實際卻不是同一目標的結果.
由此,需要分析特征點的空間位置分布,進一步提高對圖像描述的準確性.點群目標是空間分布分析的重要研究對象,點群目標的拓撲關系、距離關系、方向關系、分布范圍和分布密度等是對空間點群相似度整體度量的重要參考.特征點群的分布具有一定的規律性,同一個目標物體所在的圖片提取的點群分布其點群之間的拓撲關系、方向關系和距離關系具有相似性.在圖像規格相差不大,同一目標物體發生旋轉、平移、縮放變化的情況下,提取的特征點群的拓撲、方向和距離表示如圖1所示.

圖1 特征點群相似度示意圖Fig.1 Similarity of keypoints
圖1中彩色塊代表的是特征點周圍的Voronoi鄰居,可以作為特征點群的拓撲鄰居來衡量點群的拓撲關系.根據特征點群計算得到的標準差橢圓,其大小和方向反映了特征點群的分布形狀和分布方向等信息,即可以代表圖像中目標主體的大小位置和朝向,并且平移和旋轉不變形.
因此,本文就從拓撲、方向、距離三方面對特征點群相似度進行度量.通過對特征點群相似度的計算,從粗篩選結果中過濾掉特征點群相似度較差的訓練圖像.同時,根據特征點群計算得到的標準差橢圓,通過其圓心所在位置以及旋轉角度,進一步改進SPM多尺度下細分區域的劃分,得到抗旋轉、平移和縮放的圖像表示.處理過程如圖2所示.
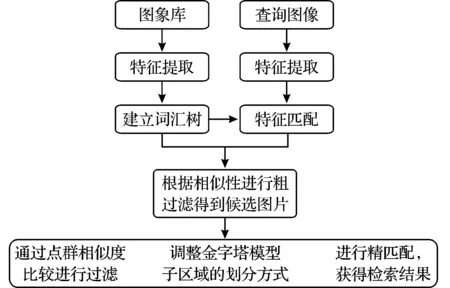
圖2 系統流程示意圖Fig.2 System flow
2.2.1 特征點群拓撲相似度
對于特征點群之間的拓撲關系判定,本文采用的是Voronoi鄰居作為點群拓撲信息的描述參數.不同于地理空間中拓撲關系的判定,柵格圖像中距離的界定無統一標準,而采用Voronoi鄰居作為點群拓撲信息的描述,其鄰居個數不需要人為固定,也不需要考慮特征點之間距離的絕對關系,同時對于尺度和密度變化具有一定適應性[10].
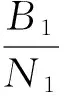
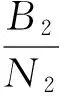
點群P1和點群P2的拓撲相似度判定采用文獻[11]的計算公式:
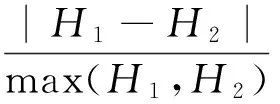
(3)
2.2.2 特征點群方向相似度
GIS中對于空間點群模式一般會從點的疏密、方位、數量、大小等多角度進行考察.標準差橢圓就是同時對點的方位和分布進行分析的一種經典算法.它可以從二維的角度對特征點的分布方向的偏離大小以及分布形狀等空間信息進行描述[12].
圖像特征點群的方向會隨著圖像的旋轉發生一定的變化,因此在計算2幅圖像特征點群方向相似度時,不能直接用計算得到的標準差橢圓的方向進行度量.本文綜合考慮特征點群方向以及特征點群的特征主方向,用計算得到的2個方向之間的夾角進行方向相似度度量.
2.2.2.1 FREAK特征點主方向
在采樣點對中選取45個長的、對稱的采樣點對來提取特征點的方向,因而提高了FREAK算法的速度,內存占用也可大大降低.本文采用文獻[5]的公式計算FREAK特征方向.
(4)

FREAK特征點主方向代表了該特征點主要的梯度變化方向.本文對圖像中所有獲取的特征點進行特征方向計算,得到梯度方向后,使用直方圖進行統計.直方圖的橫軸是梯度方向的角度,為0°~360°,每36°一個柱共10個柱;縱軸為梯度方向統計數量,直方圖的峰值就是該幅圖像特征點群的主方向.
2.2.2.2 標準差橢圓
標準差橢圓的生成算法包含了3個重要因素:圓心、旋轉角度和XY軸的長度[11].計算步驟如下:
(i) 由橢圓圓心直接計算算術平均:
(5)
其中,xi和yi是每個要素在圖像上的位置信息.
(ii) 確定橢圓的方向,即計算旋轉角度.
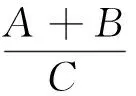
(6)
(iii) 確定XY軸的長度,即沿長軸方向的標準差δx和短軸方向的標準差δy:
(7)
得到特征點群分布方向以及特征點群梯度方向統計值的主方向后,定義特征點群方向相似度:
SIM_dire=|cos((θ1-?1)-(θ2-?2))|,
(8)
其中,θ,?分別表示圖像的特征點群分布方向和特征點群梯度主方向.
2.2.3 特征點群距離相似度
特征點群距離相似度用于描述點群的集中程度,用標準差橢圓長、短軸距離之比來度量.本文采用文獻[12]的計算公式:
(9)
其中,a1、b1和a2、b2分別為2個點群標準差橢圓的長、短軸.
2.3 特征點群相似度計算
主要以特征點群之間的拓撲相似度、方向相似度以及距離相似度進行度量.充分考慮了由圖像尺度變化、旋轉變化等因素造成的影響.在無顯著側重的條件下,取幾何平均進行空間相似度計算:
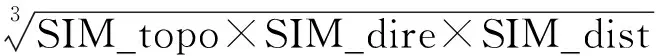
(10)
用特征點群相似度計算的結果,進一步篩選通過詞匯樹進行的粗匹配結果,從而可以排除與目標物體不一樣的圖像,同時,通過計算得到的標準差橢圓的圓心、旋轉角度,為金字塔匹配更好地劃分子區域提供依據.
2.4 改進的空間金字塔匹配
通過特征點群相似度計算得到標準差橢圓的圓心和旋轉角度,由此可以得到目標物體在圖像中的位置和朝向.本文以橢圓圓心為劃分中心,通過旋轉角度對坐標軸進行旋轉,以調整金字塔匹配圖像子區域的劃分.通過改善金字塔匹配方法,得到抗旋轉、平移和縮放的圖像表達,并用于進一步的匹配工作.改進劃分示意圖如圖3所示.

圖3 金字塔匹配調整示意圖Fig.3 The adjustment of SPM
3 實驗及分析
為了驗證算法的正確性,在自建的建筑物圖像數據集上進行了相關的實驗.
實驗中,以浙江大學紫金港校區建筑物數據集中的數據為例,包括20類建筑物圖片,每一類10張共200張.首先,對圖像集中的20類建筑物圖像進行了特征點群相似度計算,初步得到屬于同一類建筑物圖像之間特征點群相似度平均約為0.74,最小值為0.6.同時,對不同類別的建筑物圖像進行了抽樣計算,得到其特征點群相似度平均值約為0.4.為了獲得更好的查全率,以相似度0.6為特征點群相似度計算的臨界值,作為不同目標圖片的篩選標準,用于進一步過濾粗匹配的訓練圖像.
對移動端實時采集的圖像進行分類檢索,通過對分類檢索的準確率以及查全率進行統計和比較,以驗證本實驗方法的抗旋轉、抗平移和抗縮放性能.用移動端攝像頭分別對其中6類建筑捕獲10幅圖像,計算每一幅圖像檢索分類的準確率和查全率,再取平均值作為實驗的結果.

圖4 4類建筑物圖像Fig.4 The four class of building images
實驗部分數據展示如圖4所示,從上至下分別為紫金港行政樓、安中大樓、蒙明偉樓和月牙樓. 準確率以最終的分類結果為準;查全率為排名前10的候選圖像正確匹配數與所有訓練的圖像數之比.
分別采用基于SPM的圖像表示方法和本實驗方法對移動端采集的圖像進行分類檢索,運行結果如表1~2所示.
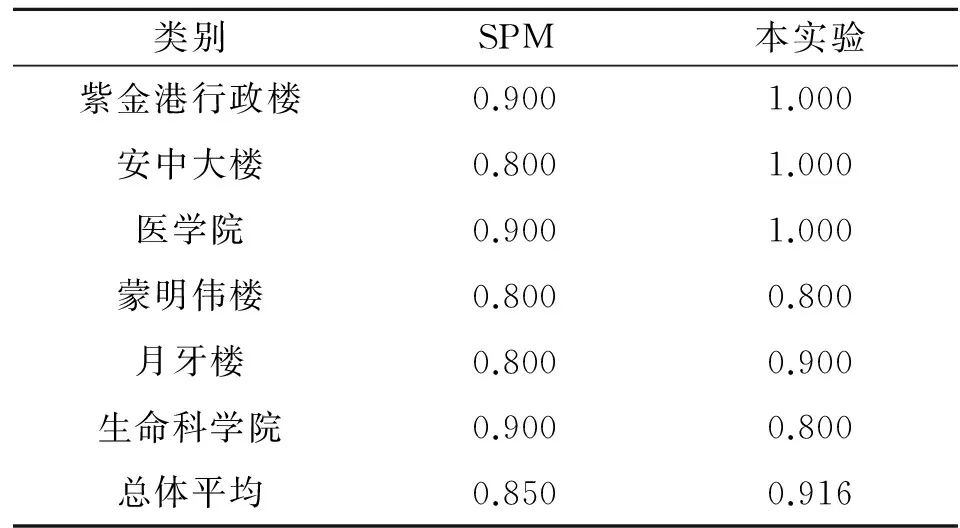
表1 建筑物數據集2種方法的分類準確率
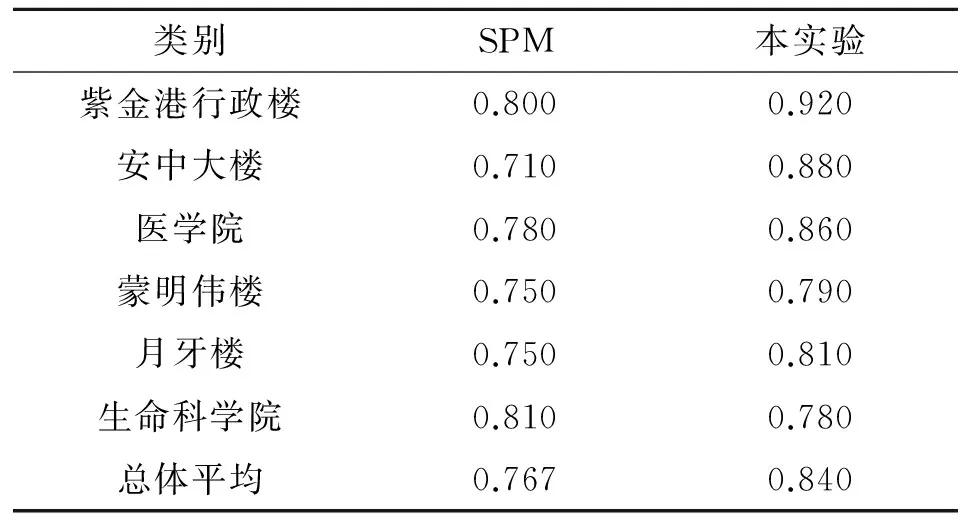
表2 建筑物數據集2種方法的查全率
從表1和2中可以看出,總體上本實驗的圖像表示方法的識別準確率要高于基于SPM的圖像表示方法.在平均查全率上,本實驗的圖像表示方法能更準確地找到對應的相似圖像.尤其是校園建筑物數據集中某類別的圖像出現旋轉、平移和縮放變化時,如對于安中大樓、行政樓等建筑圖像,本實驗方法的識別準確率、查全率要高于基于SPM的圖像表示方法.同時,實驗中也發現,生命科學學院樓的準確率和查全率是下降的.通過對實驗數據的分析可知,生命科學學院建筑在圖像中主體不明顯,特征點群相似度計算結果誤差大,尤其是對于標準差橢圓的計算,最后導致了圖像檢索結果的偏差.
為了驗證本文方法在處理圖像旋轉、平移和縮放上的優勢,有針對性地建立了一些背景干凈,具有明顯旋轉、平移和縮放變化的物品圖像數據集20類,每類6幅共120幅圖像,部分數據如圖5所示,分別為鑰匙、墨水盒、眼鏡、鼠標等日常用品.實驗選取其中4類物體,分別采用基于SPM的圖像表示方法和本實驗方法對圖像進行分類檢索.
通過移動端在上述4類物體中每類采集10幅圖像,計算每一幅圖像檢索分類的準確率和查全率,再取平均值作為實驗的結果,并進行分析.

圖5 自建數據集中4類圖像Fig.5 The four class of self-built image sets
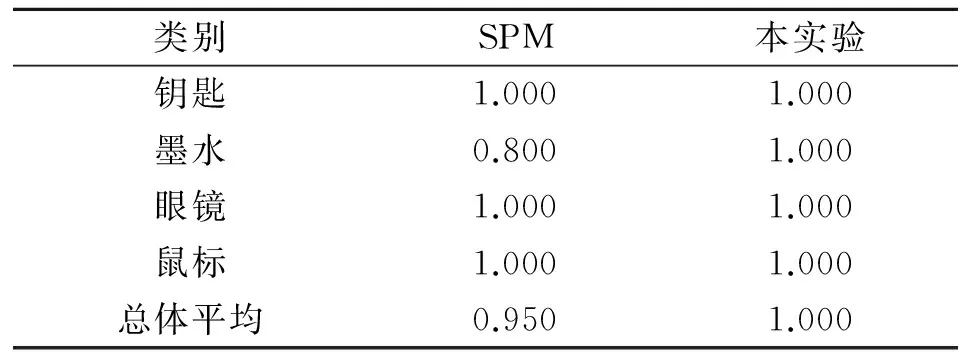
類別SPM本實驗鑰匙1.0001.000墨水0.8001.000眼鏡1.0001.000鼠標1.0001.000總體平均0.9501.000
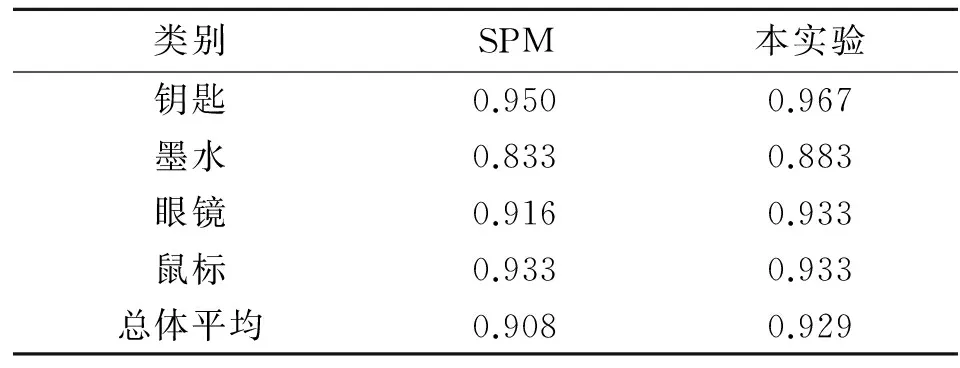
表4 自建數據集2種方法查全率
由實驗結果可知,無論是檢索準確率還是查全率,本實驗的結果基本都要優于SPM,尤其當墨水和眼鏡出現比較明顯的旋轉、平移和縮放變化時.而對于無明顯縮放和平移的類別,準確率和查全率基本一致.表明基于本實驗的圖像表示方法具有良好的抗旋轉、平移和縮放特征.
4 結 語
針對目前將空間位置信息引入圖像表示的SPM方法沒有考慮圖像中視覺物體的旋轉、平移和縮放變化,本文提出了基于特征點群相似度計算模型的圖像表示方法,利用特征點群相似度的計算,在詞匯樹粗匹配的基礎上,進一步篩選特征點群分布相似度較高的圖像,同時,利用計算得到的標準差橢圓的圓心、旋轉角度調整空間金字塔匹配方法對子區域的劃分,得到了圖像抗旋轉、平移和縮放變化的表示.實驗結果表明,相較基于SPM的圖像表示方法本文方法的分類檢索準確率和查全率更高;對于視覺物體具有明顯旋轉、平移和縮放變化的圖像,本文方法優勢更加顯著.
但是,實驗也發現,當采集圖像中的建筑物主體發生較為嚴重的形變,或者只有建筑物主體一部分時,特征點群相似度的計算會受到影響,尤其是對于標準差橢圓的計算,會導致結果產生誤差.如對于浙江大學生命科學學院建筑的識別,會因特征點群相似度的計算對結果產生誤判.如何提高此類數據的查詢準確率是本方法亟待解決的問題.
[1]NISTERD,STEWENIUSH.Scalablerecognitionwithavocabularytree[C]//IEEEComputerSocietyConferenceonComputerVisionandPatternRecognition. Washington: IEEE Computer Society,2006,2(10):2161-2168.
[2] LAZEBNIK S,SCHMID C,PONCE J.Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories[C]//IEEEComputerSocietyConferenceonComputerVision&PatternRecognition.Washington: IEEE Computer Society,2006:2169-2178.
[3] CALONDER M,LEPETIT V,OZUYSAL M,et al.BRIEF: Computing a local binary descriptor very fast[J].IEEETransactionsonPatternAnalysis&MachineIntelligence,2011,34(7):1281-1298.
[4] RUBLEE E,RABAUD V,KONOLIGE K,et al.ORB: An efficient alternative to SIFT or SURF[C]//IEEEInternationalConferenceonComputerVision. Washington: IEEE,2012:2564-2571.
[5] ALAHI A,ORTIZ R,VANDERGHEYNST P.FREAK: Fast retina keypoint[C]//IEEEConferenceonComputerVisionandPatternRecognition, Washington: IEEE,2012:510-517.
[6] 索春寶,楊東清,劉云鵬,等.多種角度比較SIFT、SURF、BRISK、ORB、FREAK算法[J].北京測繪,2014(4):23-26. SUO C B, YANG D Q, LIU Y P. Comparing SIFT, SURF, BRISK, ORB and FREAK in some different perspectives [J].BeijingSurveyingandMapping,2014(4):23-26.
[7] 陳赟,沈一帆.基于詞匯樹的圖片搜索[J].計算機工程,2010,36(6):189-191. CHEN Y,SHEN Y F. Image search based on vocabulary tree[J].ComputerEngineering,2010,36(6):189-191.
[8] TRZCINSKI T,LEPETIT V,FUA P.Thick boundaries in binary space and their influence on nearest-neighbor search[J].PatternRecognitionLetters,2011,33(16):2173-2180.
[9] 張運超,陳靖,王涌天,等.基于移動增強現實的智慧城市導覽[J].計算機研究與發展,2014,51(2):302-310. ZHANG Y C,CHEN J,WANG Y T,et al.Smart city guide using mobile augmented reality[J].JournalofComputerResearchandDevelopment,2014,51(2):302-310.
[10] 劉濤.空間群(組)目標相似關系及計算模型研究[D].武漢:武漢大學,2011. LIU T.SimilarityofSpatialGroupObjects[D].Wuhan: Wuhan University,2011.
[11] 劉濤,杜清運,閆浩文.空間點群目標相似度計算[J].武漢大學學報:信息科學版,2011,36(10): 1149-1153. LIU T,DU Q Y,YAN H W.Spatial similarity assessment of point clusters[J].GeomaticsandInformationScienceofWuhanUniversity,2011,36(10): 1149-1153.
[12] 石丹丹.基于特征點空間關系的圖像檢索技術研究[D].南昌:南昌航空大學,2013. SHI D D.ImageRetrievalTechnologyResearchbasedontheSpatialRelationsofFeaturePoints[D].Nanchang :Nanchang Hangkong University,2013.
[13] 朱道廣,郭志剛,趙永威,等.基于空間上下文加權詞匯樹的圖像檢索方法[J].模式識別與人工智能,2013,26(11):1050-1056. ZHU D G,GUO Z G,ZHAO Y W.Image retrieval with spatial context weighting based vocabulary tree[J].PatternRecognitionandArtificialIntelligence,2013,26(11):1050-1056.
HE Jing1,2, LIU Renyi1,2, ZHANG Feng1,2, DU Zhenhong1,2, CHEN Yongpei1,2
(1.Zhejiang Provincial Key Lab of GIS,Zhejiang University,Hangzhou 310028,China;2.Department of Geographic Information Science,Zhejiang University,Hangzhou 310027,China)
To overcome the shortcoming of the Spatial Pyramid Matching (SPM) approach, which lacks invariance to translation, scale and rotation of visual objects in images, this paper proposes an image representation method based on the similarity of feature points. Firstly, it filters the rough matching result of bag-of-words by some properties including the topological similarity, the directional similarity and the distance similarity. Then, it adjusts the division of the image sub-regions according to the standard deviation ellipse center and the rotation angle of the feature points. Finally, the representation of anti-rotation, anti-translation and anti-scaling of image can be obtained. Experiments have been conducted by applying the proposed method to the campus building dataset and the object image dataset. It indicates that our method significantly improves the classification accuracy and recall ratio, especially for the dataset containing images with obvious rotation, translation and scaling transforms.
similarity of feature points; Voronoi diagram; standard deviational ellipse; FREAK feature description; spatial pyramid matching

10.3785/j.issn.1008-9497.2017.05.016
P 208
:A
:1008-9497(2017)05-599-07
2016-12-12.
測繪地理信息公益性行業科研專項(201512024);國家自然科學基金資助項目(41671391,41471313);國家科技基礎性工作專項(2012FY112300).
何敬(1991-),ORCID:http://orcid.org/0000-0003-4164-442X,男,碩士研究生,主要從事移動GIS基礎研究.
*通信作者,ORCID:http://orcid.org/0000-0001-9449-0415,E-mail:duzhenhong@zju.edu.cn.
Animagerepresentationmethodbasedonthesimilarityoffeaturepoints.Journal of Zhejiang University (Science Edition),2017,44(5):599-605
猜你喜歡
計算機應用(2022年2期)2022-03-01 12:33:42
計算機應用(2021年4期)2021-04-20 14:06:36
計算機應用(2021年1期)2021-01-21 03:22:38
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
小天使·一年級語數英綜合(2015年2期)2015-01-14 06:35:05
