高維數(shù)據(jù)集中局部離散文本數(shù)據(jù)挖掘方法研究
2017-10-12 09:18:15農(nóng)曉鋒
現(xiàn)代電子技術(shù) 2017年19期
關(guān)鍵詞:數(shù)據(jù)挖掘
農(nóng)曉鋒

摘 要: 提出利用基于多目標優(yōu)化軟子空間聚類理論的關(guān)聯(lián)規(guī)則數(shù)據(jù)挖掘方法對高維數(shù)據(jù)集中局部離散文本數(shù)據(jù)實現(xiàn)數(shù)據(jù)特征有效挖掘。首先,利用多目標優(yōu)化軟子空間聚類思想結(jié)合非支配排序遺傳理論優(yōu)化加權(quán)類內(nèi)緊致及加權(quán)類間分離函數(shù),獲取優(yōu)化后的目標函數(shù)及非占優(yōu)Pareto最優(yōu)解集,運用加權(quán)子空間劃分方法對最優(yōu)解集完成特征聚類;其次,基于關(guān)聯(lián)規(guī)則思想運用一種特征提取和關(guān)聯(lián)文本的識別方法,對聚類后的文本特征進行文本間及文本內(nèi)部的特征識別和分類,即實現(xiàn)了文本信息數(shù)據(jù)的有效挖掘。實驗證明,利用多目標優(yōu)化軟子空間聚類數(shù)據(jù)挖掘方法可以有效實現(xiàn)高維集中局部離散文本數(shù)據(jù)的挖掘。
關(guān)鍵詞: 高維數(shù)據(jù); 數(shù)據(jù)特征聚類; 數(shù)據(jù)挖掘; 關(guān)聯(lián)規(guī)則
中圖分類號: TN911.1?34; TP391 文獻標識碼: A 文章編號: 1004?373X(2017)19?0138?04
Research on local discrete text data mining method in high?dimensional dataset
NONG Xiaofeng
(Modern Educational and Technological Center, Guilin Tourism University, Guilin 541006, China)
Abstract: An association rules data mining method based on the theory of multi?objective optimization soft subspace clustering is proposed to mine the data feature of local discrete text data in high?dimensional dataset effectively. The thought of multi?objective optimization soft subspace clustering is combined with the theory of non?dominated sorting genetic optimization to optimize the weighted intra?class compactness and weighted inter?class separation function, and obtain the optimized objective function and non?dominated Pareto optimal solution set. The weighting subspace classification method is used to cluster the features of the optimal solution set. A recognition method for feature extraction and text association based on the thought of association rules is used to recognize and classify the features among texts and within texts for the clustered text features, which can realize the effective mining of the text information data. The experimental results show that the data mining method of multi?objective optimization soft subspace clustering can realize the local discrete text data mining in high?dimensional dataset effectively.
Keywords: high?dimensional data; data feature clustering; data mining; association rule
0 引 言
文獻[1]指出,在人工智能和數(shù)據(jù)庫領(lǐng)域中,目前各種數(shù)據(jù)挖掘方法也獲得了不同程度的關(guān)注。20世紀末開始,人們對各種不同的數(shù)據(jù)挖掘方法進行深入研究。數(shù)據(jù)挖掘作為一種決策支持手段,幫助各個領(lǐng)域的專家和開發(fā)人員分析各種類型的數(shù)據(jù)[2?3],然后從中挖掘出潛在的模式并做出正確決策判斷。文獻[4]中提到數(shù)據(jù)挖掘通常會利用人工智能、機器學習、模式識別、統(tǒng)計學、可視化等技術(shù)來實現(xiàn)該過程。
當前數(shù)據(jù)挖掘研究領(lǐng)域發(fā)展迅速,其面臨的問題與挑戰(zhàn)也越來越多。第一,越來越大的數(shù)據(jù)規(guī)模,也稱之為大規(guī)模數(shù)據(jù)問題;第二,不斷增加的數(shù)據(jù)特征維數(shù)引起的問題也稱為維數(shù)災(zāi)難問題;第三,有生物學、腦科學、證券金融等學科的知識背景[5?6]。文獻[7]中提出基于上述問題面臨的挑戰(zhàn),部分學者提出針對大規(guī)模數(shù)據(jù)的流數(shù)據(jù)分析方法、針對高維數(shù)據(jù)的特征加權(quán)和特征選擇方法。目前數(shù)據(jù)挖掘領(lǐng)域的研究重點包括很多學科的交叉領(lǐng)域。
由于數(shù)據(jù)挖掘方法被越來越廣泛的應(yīng)用,本文提出對高維數(shù)據(jù)集中局部離散文本數(shù)據(jù)進行有效數(shù)據(jù)挖掘。首先,運用多目標優(yōu)化軟子空間聚類思想獲得優(yōu)化后的目標函數(shù)和非占優(yōu)Pareto最優(yōu)解集,最優(yōu)解集的獲取即實現(xiàn)了數(shù)據(jù)特征聚類;其次,以關(guān)聯(lián)規(guī)則思想為基礎(chǔ),通過一種特征提取和關(guān)聯(lián)文本的識別方法實現(xiàn)對聚類后的文本特征進行文本之間及文本內(nèi)部的特征識別和分類,最終達到有效挖掘文本信息數(shù)據(jù)的目的[8?9]。
1 高維數(shù)據(jù)集中局部離散文本數(shù)據(jù)挖掘研究
1.1 基于多目標優(yōu)化軟子空間的數(shù)據(jù)特征聚類
多目標優(yōu)化屬于最合理的通用優(yōu)化方法,在特定條件的約束下,能夠優(yōu)化兩個以上的多個目標函數(shù),該過程可描述如下:
多目標優(yōu)化:最小化[M]個目標函數(shù)[fx=][f1x,f2x,…,fMx],找出全部可行域[X]范圍內(nèi)的[D]維決策目標向量[x?=x?1,x?2,…,x?D],通過目標函數(shù)變換決策目標向量,則:
[x?=argminx∈Xfx=argminx∈Xf1x,f2x,…,fMx] (1)
式中:[i]表示目標函數(shù)數(shù)量;[fi?]表示目標函數(shù);[x?]代表決策目標向量;[x]表示解向量。
針對多目標優(yōu)化的可行解問題,其含有的解是多個或者無限多,組成Pareto集合。因為Pareto集合借助目標函數(shù)存在相互占優(yōu)的關(guān)系,所以也稱之為非占優(yōu)解集,可將其描述如下。
Pareto解集:最小化[M]個目標函數(shù)[fx=][f1x,f2x,…,fMx,]解向量[x]是全部可行域[X]范圍內(nèi)多目標優(yōu)化問題的可行解,Pareto解集必須滿足最優(yōu)準則,同時在全部可行域[X]范圍內(nèi),比[x]更加占優(yōu)的解向量[x]是不存在的,則:
[?i∈1,2,…,M, fix=fix] (2)
式中[fix]表示占優(yōu)解向量目標函數(shù)。目標優(yōu)化問題的可行解通過Pareto最優(yōu)準則來獲取,稱為Pareto解集。
如果所有數(shù)據(jù)簇的特征加權(quán)系數(shù)都是[D]維特征向量,用[wi=wi1,wi2,…,wiD1≤i≤C]表示,[C×D]表示含有[C]個數(shù)據(jù)簇的染色體長度。其中,[w1]表示初始數(shù)據(jù)簇的特征因子,由前[D]個基因團來表示,[w2]也就是第二個數(shù)據(jù)簇的特征因子,以此類推。
定義目標函數(shù)以及劃分數(shù)據(jù)樣本,聚類評價準則選用模糊軟子空間聚類目標函數(shù)[JFWSC]來優(yōu)化目標函數(shù),則[JFWSC]可描述為:
[JFWSC=i=1Cj=1Numijk=1Dwτikxjk-vik2] (3)
式中:[N]表示數(shù)據(jù)樣本的個數(shù);[j]表示常數(shù);模糊聚類指數(shù)為[m]的隸屬度用[umij]表示;模糊加權(quán)指數(shù)為[τ]的加權(quán)系數(shù)用[wτik]表示;維數(shù)為[k]的第[j]個可行解用[xjk]表示;[vik]表示聚類中心。獲取各個數(shù)據(jù)簇加權(quán)系數(shù)[W]及聚類中心[V=vi,1≤i≤C],樣本到各個聚類中心的模糊隸屬度[uij]可描述為:
[uij=dij-1m-1i=1Ddij-1m-1, i=1,2,…,C; j=1,2,…,N] (4)
式中[dij]表示樣本到聚類中心的距離。可描述聚類中心為:
[vik=j=1Numijxjkj=1Numij] (5)
選擇聚類評價準則的合理性決定了最終聚類結(jié)果的產(chǎn)生,多目標優(yōu)化問題的適應(yīng)度函數(shù)可選擇FWSC目標函數(shù)[JFWSC]。然后構(gòu)建聚類數(shù)據(jù)集的樣本和聚類中心二部圖,數(shù)據(jù)聚類劃分可通過圖劃分方法推導(dǎo)得出。
構(gòu)建二部圖[G=V,E],以二部圖[G]為基礎(chǔ),通過譜聚類取得相應(yīng)聚類中心以及樣本點劃分的結(jié)果,由[VCi]表示每個聚類中心的劃分結(jié)果,相應(yīng)的特征加權(quán)向量[wi]通過計算得出,同時輸出[N]個數(shù)據(jù)樣本的聚類劃分。
1.2 關(guān)聯(lián)規(guī)則理論下文本數(shù)據(jù)挖掘
對不同詞語數(shù)據(jù)實現(xiàn)不同加權(quán)就是文本特征提取方法,在數(shù)據(jù)樣本中詞語的重要性由此表示。加權(quán)實現(xiàn)方法中選用布爾加權(quán)方式,如果一個文本數(shù)據(jù)出現(xiàn)在數(shù)據(jù)樣本中,則加權(quán)為1,反之為0,加權(quán)參數(shù)可描述為:
[wij=1,fij≥10,fij<1] (6)
式中:[wij]表示文本加權(quán)結(jié)果;[fij]表示文本數(shù)據(jù)在數(shù)據(jù)樣本中出現(xiàn)的頻率。
權(quán)重可以表示文本數(shù)據(jù)出現(xiàn)的概率,同時可以反映出文本數(shù)據(jù)的重要性,是一種基于信息理論的權(quán)重計算方法,以熵權(quán)重為基礎(chǔ)的文本挖掘方法,則:
[wij=logfij+1.0*1+log1Nk=1Nfiknilogfikni ] (7)
式中:[ni]表示研究特征次數(shù);[fik]表示目標函數(shù)在數(shù)據(jù)樣本中出現(xiàn)的頻率。
通過數(shù)字化的歸一化方法進行處理實現(xiàn)文本數(shù)據(jù)挖掘識別過程能夠有效地分類度量數(shù)據(jù)樣本中的關(guān)鍵數(shù)據(jù),文本個數(shù)與最大相關(guān)系數(shù)互相關(guān)聯(lián),則可作如下描述:
[maxLac=log2k] (8)
式中:[Lac]表示相關(guān)系數(shù);[maxLac]表示各個特征類信息熵的最大值;[k]為常數(shù)。
變化加權(quán)時采用固定系數(shù)coff1和coffconst對IDF1和IDFconst值進行適度調(diào)整,可以達到較好的分類效果。
關(guān)聯(lián)挖掘?qū)儆谝环N數(shù)據(jù)處理的挖掘方法,基于數(shù)據(jù)關(guān)聯(lián)度挖掘文本特征。文本挖掘首先要將文本挖掘區(qū)域劃定,參數(shù)[xi,yi]表示各文本在區(qū)域[Z]中的坐標,也就是文本坐標。假設(shè)將該區(qū)域視為圖像區(qū)域,設(shè)定像素點為[p,q,]若存在待識別的數(shù)據(jù)為[K(r),]運用關(guān)聯(lián)規(guī)則挖掘該數(shù)據(jù)的概率為:
[Q(Z)=KZpqp×q] (9)
式中:[Q(Z)]表示在文本[Z]區(qū)域內(nèi)數(shù)據(jù)信息的挖掘概率;[KZpq]表示區(qū)域中的某文本數(shù)據(jù)樣本點。
利用關(guān)聯(lián)度挖掘方法對高維數(shù)據(jù)集中局部文本數(shù)據(jù)進行數(shù)據(jù)樣本的特征提取,并利用關(guān)聯(lián)規(guī)則求解出數(shù)據(jù)被挖掘的概率,通過以上步驟可以較好地實現(xiàn)高維數(shù)據(jù)內(nèi)部特征的描述,完成數(shù)據(jù)挖掘過程。
2 仿真實驗與結(jié)果分析
數(shù)據(jù)規(guī)模的不斷增大使數(shù)據(jù)挖掘成為核心的研究課題,本文以高維數(shù)據(jù)集中局部離散文本數(shù)據(jù)為研究對象,運用基于多目標軟子空間聚類理論的關(guān)聯(lián)規(guī)則法對其進行數(shù)據(jù)挖掘。通過以下實驗驗證本文方法的可行性,具體如下。
實驗1:在對數(shù)據(jù)特征實現(xiàn)挖掘前,先對數(shù)據(jù)進行特征聚類處理,實驗設(shè)定高維文本數(shù)據(jù)共8組,每組為400個樣本,要求聚類為5個數(shù)據(jù)簇,每個簇為80個高維文本數(shù)據(jù)。采用本文多目標軟子空間聚類方法及數(shù)據(jù)流軟子空間聚類方法對實驗給出的400個文本數(shù)據(jù)進行聚類處理,獲取經(jīng)過聚類處理后的數(shù)據(jù)簇結(jié)果及每個簇含有的文本數(shù)據(jù)個數(shù),將結(jié)果與設(shè)定結(jié)果進行比較。具體數(shù)據(jù)結(jié)果如表1,表2所示。
根據(jù)實驗條件設(shè)定每組為400個數(shù)據(jù)樣本,經(jīng)過聚類處理后,400個文本數(shù)據(jù)聚類為5個數(shù)據(jù)簇,且每個數(shù)據(jù)簇內(nèi)包含80個數(shù)據(jù)樣本。對照實驗事先設(shè)定的條件,表1為利用數(shù)據(jù)流軟子空間聚類法獲取的聚類結(jié)果,觀察聚類后形成數(shù)據(jù)簇的結(jié)果能夠看出,利用該方法獲取的數(shù)據(jù)簇個數(shù)與實驗預(yù)先設(shè)定結(jié)果不相符,表明利用數(shù)據(jù)流軟子空間聚類法對文本數(shù)據(jù)并未準確實現(xiàn)聚類處理;表2為多目標軟子空間聚類方法獲取的聚類結(jié)果,從表2能夠觀察出利用該方法經(jīng)過聚類處理后形成的數(shù)據(jù)簇個數(shù)及每組數(shù)據(jù)簇包含的文本數(shù)據(jù)個數(shù)與實驗事先設(shè)定的限制條件吻合,依據(jù)結(jié)果顯示,利用本文多目標軟子空間聚類方法能夠?qū)Ω呔S文本數(shù)據(jù)進行有效聚類處理。
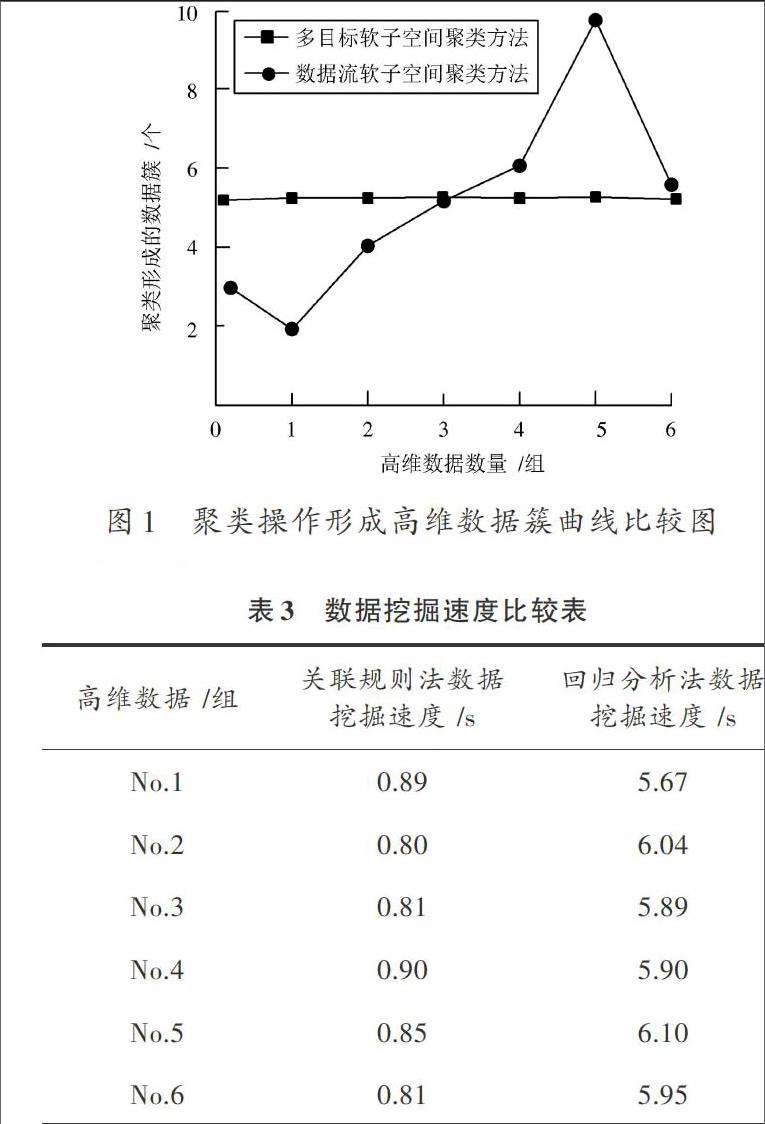
利用數(shù)據(jù)流軟子空間聚類法及本文多目標軟子空間聚類方法對文本數(shù)據(jù)進行聚類處理后形成曲線,并比較兩條曲線的差異,具體如圖1所示。
觀察圖1能夠看出,運用本文多目標軟子空間聚類方法對400個文本數(shù)據(jù)進行聚類處理后,獲取的數(shù)據(jù)簇為5個,而運用數(shù)據(jù)流軟子空間聚類法進行聚類處理后,形成的數(shù)據(jù)簇結(jié)果與實驗預(yù)先設(shè)定結(jié)果不吻合,比較兩種聚類方法,本文方法更為有效。
實驗2:為測試文中關(guān)聯(lián)規(guī)則方法的有效性能,實驗給出900個高維數(shù)據(jù),將其分為6組。通過運用本文方法及回歸分析法對高維數(shù)據(jù)進行數(shù)據(jù)挖掘,比較兩種方法數(shù)據(jù)挖掘的速度,具體數(shù)據(jù)如表3所示。
3 結(jié) 論
數(shù)據(jù)挖掘是對數(shù)據(jù)進行特征有效分類及挖掘其內(nèi)部關(guān)聯(lián)性的一種方法,在眾多科學領(lǐng)域中得到了廣泛應(yīng)用。因此,本文以高維數(shù)據(jù)集中局部離散文本數(shù)據(jù)為研究對象,提出基于多目標軟子空間聚類理論的關(guān)聯(lián)規(guī)則法對數(shù)據(jù)實現(xiàn)挖掘。首先,將多目標軟子空間聚類理論與非支配排序遺傳思想結(jié)合,獲取Pareto最優(yōu)解集,對數(shù)據(jù)實現(xiàn)聚類處理;其次,運用關(guān)聯(lián)規(guī)則數(shù)據(jù)挖掘法在數(shù)據(jù)特征聚類結(jié)果的基礎(chǔ)上,采用本文特征提取法對文本數(shù)據(jù)進行特征分類與識別,最終實現(xiàn)高維數(shù)據(jù)集中局部離散文本數(shù)據(jù)的挖掘過程。
參考文獻
[1] 張銀柯,張驥,趙達.基于CNKI數(shù)據(jù)庫的文獻探索我國人工智能的研究狀況[J].內(nèi)江科技,2016,37(1):79?80.
[2] 王元卓,賈巖濤,劉大偉,等.基于開放網(wǎng)絡(luò)知識的信息檢索與數(shù)據(jù)挖掘[J].計算機研究與發(fā)展,2015,52(2):456?474.
[3] 王樂,王芳.數(shù)據(jù)庫異常數(shù)據(jù)的檢測仿真研究[J].計算機仿真,2016,33(1):430?433.
[4] 米允龍,米春橋,劉文奇.海量數(shù)據(jù)挖掘過程相關(guān)技術(shù)研究進展[J].計算機科學與探索,2015,9(6):641?659.
[5] 耿娟,焦紅兵.統(tǒng)計學專業(yè)數(shù)據(jù)挖掘課程教學探索[J].產(chǎn)業(yè)與科技論壇,2016,15(3):202?203.
[6] 何光凝.數(shù)據(jù)挖掘在計算機網(wǎng)絡(luò)安全領(lǐng)域的應(yīng)用研究[J].技術(shù)與市場,2016,23(8):13.
[7] 許麗娟.基于自適應(yīng)波束形成的高維數(shù)據(jù)挖掘算法[J].電聲技術(shù),2016,40(3):65?68.
[8] 邱云飛,狄龍娟.基于簇間距離自適應(yīng)的軟子空間聚類算法[J].計算機工程與應(yīng)用,2016,52(21):88?93.
[9] 張春生.大數(shù)據(jù)環(huán)境下相容數(shù)據(jù)集的關(guān)聯(lián)規(guī)則數(shù)據(jù)挖掘[J].微電子學與計算機,2016,33(8):34?39.
[10] 董本清,彭健鈞.復(fù)雜網(wǎng)絡(luò)數(shù)據(jù)流中的異常數(shù)據(jù)挖掘算法仿真[J].計算機仿真,2016,33(1):434?437.
[11] 郭崇,王征,紀建偉,等.電力用戶數(shù)據(jù)中用電特征數(shù)據(jù)挖掘模型仿真[J].計算機仿真,2016,33(5):447?450.
猜你喜歡
艦船科學技術(shù)(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設(shè)計工程(2014年18期)2014-02-27 12:00:13
電子設(shè)計工程(2014年18期)2014-02-27 12:00:12
