基于用戶部分特征的協(xié)同過濾算法①
2017-10-13 14:47:02李永超
計算機系統(tǒng)應(yīng)用 2017年3期
關(guān)鍵詞:用戶
李永超, 羅 軍
?
基于用戶部分特征的協(xié)同過濾算法①
李永超, 羅 軍
(國防科技大學(xué)計算機學(xué)院, 長沙 410073)
協(xié)同過濾算法作為推薦系統(tǒng)中應(yīng)用最廣泛的算法之一, 在大數(shù)據(jù)環(huán)境下面臨嚴(yán)重的數(shù)據(jù)稀疏問題, 使得近鄰選擇的效果不佳, 直接影響了算法的推薦性能. 為了解決這一問題, 本文提出了一種基于用戶部分特征的協(xié)同過濾算法(UPCF), 該算法首先基于評分偏差和項目流行度進行矩陣缺失值填充, 隨后利用初始聚類中心優(yōu)化的K-means算法對該填充矩陣進行項目聚類, 并利用用戶在項目分類下的局部特征進行近鄰集合構(gòu)建, 最終采用基于用戶的協(xié)同過濾算法獲得推薦. 我們采用流行的MAE指標(biāo)對算法在MovieLens數(shù)據(jù)集上進行評測. 實驗表明, 與目前流行的協(xié)同過濾算法相比, 提出的UPCF算法在沒有增加算法復(fù)雜性的前提下, 性能有近10%的提升.
項目流行度; 最近鄰選擇; 項目聚類; 協(xié)同過濾算法
1 引言
隨著互聯(lián)網(wǎng)的興起, 互聯(lián)網(wǎng)上的信息呈指數(shù)化增長, 人類進入了信息爆炸的大數(shù)據(jù)時代. 如何從浩瀚的數(shù)據(jù)信息中獲取自己感興趣的信息, 已成為人類面臨的巨大難題. 于是無需用戶提供明確需求, 僅通過用戶歷史行為主動幫助用戶快速有效篩選信息的推薦系統(tǒng)應(yīng)運而生[1]. 我們在互聯(lián)網(wǎng)網(wǎng)站中看到的“猜你喜歡”, “大家都在看”, “看過的也看”, “你可能會感興趣”等都是推薦技術(shù)的實際應(yīng)用. 據(jù)報道, 早在2002 年, 在線購物企業(yè)Amazon 總銷售額的20%便源自它的推薦系統(tǒng). 推薦技術(shù)在新聞領(lǐng)域更是產(chǎn)生了“今日頭條”這樣的不生產(chǎn)內(nèi)容, 僅依靠推薦引擎便擁有3.5 億注冊用戶, 3500 萬活躍用戶的新興科技媒體.
協(xié)同過濾作為推薦系統(tǒng)的主流技術(shù)之一, 主要包括基于用戶的協(xié)同過濾推薦、基于項目的協(xié)同過濾推薦和基于矩陣分解的協(xié)同過濾推薦[2]. 而其中基于用戶的協(xié)同過濾算法是目前在實際應(yīng)用中最為成功的算法. 該算法首先通過用戶間的共同評分項計算用戶間的相似度, 然后根據(jù)用戶間的相似度選擇目標(biāo)用戶的近鄰集合, 最后根據(jù)用戶近鄰集合對目標(biāo)用戶進行推薦. 最近鄰選擇作為該算法中最關(guān)鍵的步驟, 直接決定了推薦的質(zhì)量. 然而在實際應(yīng)用中由于數(shù)據(jù)集中項目的維度巨大, 大多數(shù)用戶只會對極少數(shù)的項目進行評價, 從而導(dǎo)致用戶評分?jǐn)?shù)據(jù)的極端稀疏,不同用戶間的共同評分項極少,用戶間相似性計算的可靠性和準(zhǔn)確性難以得到保證, 推薦算法的效果大打折扣.
為了解決稀疏性問題, 多種措施相繼被提出. Ungar LH等[3]首次提出基于用戶聚類的協(xié)同過濾算法(UBCF), 通過用戶聚類來降低最近鄰搜索的數(shù)據(jù)規(guī)模, 增加最近鄰可靠性. 黃裕洋等[4]根據(jù)評分?jǐn)?shù)據(jù)的稀疏性情況, 提出了一種動態(tài)計算相似性的方法(HCFR). Xavier Amatriain[5]等提出在提前構(gòu)建的專家集合中尋找用戶近鄰集合, 以確保用戶的近鄰對待預(yù)測項目有過評分記錄. 黃創(chuàng)光等[6]提出了一種不確定近鄰的協(xié)同過濾推薦算法(UNCF). 該算法通過不確定近鄰因子及調(diào)和參數(shù)去計算基于用戶和產(chǎn)品的預(yù)測評分并產(chǎn)生推薦. Koren Y[7]通過將矩陣分解和最近鄰算法相結(jié)合, 大大提高了算法的推薦性能.
以上方法雖然從一定程度上減弱了數(shù)據(jù)稀疏對近鄰選擇帶來的影響, 提高了協(xié)同過濾的推薦質(zhì)量和效率, 但在最近鄰計算的過程中, 對用戶的相似性計算仍基于全局相似性, 沒有充分考慮用戶在不同項目類別下的興趣差異. 正如世上沒有完全相同的兩片樹葉一樣, 在各個方面興趣都相似的用戶也難以尋找. 大多用戶可能只在某個領(lǐng)域內(nèi)興趣相仿, 在其他領(lǐng)域內(nèi)可能興趣完全相悖. 因此本文提出了一種基于用戶部分特征的協(xié)同過濾算法UPCF, 該算法首先對填充矩陣進行項目聚類, 然后僅根據(jù)用戶在該項目分類下的所有評價進行相似度矩陣構(gòu)建, 降低數(shù)據(jù)維度的同時提升了最近鄰計算的可靠性, 最后根據(jù)相似性矩陣進行近鄰集合構(gòu)建, 從而最終得到推薦結(jié)果.
2 問題定義及基本方法
基于用戶的協(xié)同過濾算法基于以下假設(shè): 如果用戶之間對一些項目的評分比較相似, 則他們對其它項目的評分也將會比較相似. 協(xié)同過濾推薦系統(tǒng)首先搜索目標(biāo)用戶的若干近鄰, 然后根據(jù)最近鄰對項目的評分去預(yù)測目標(biāo)用戶對項目的評分, 從而產(chǎn)生推薦列表. 作為算法的輸入, 數(shù)據(jù)源=(,,), 其中={u,u,···,u}是基本用戶的集合,;{i,i,···,i}是項目集合,.階矩陣是用戶對各項目的評分矩陣, 其中的元素r表示中第個用戶對中第個項目的評分. 基于用戶的協(xié)同過濾算法主要包括以下三個步驟.
2.1 評分矩陣預(yù)處理
由于在實際應(yīng)用中, 項目集的維數(shù)很大, 用戶只能對極少數(shù)項目進行評價, 因此評分矩陣十分稀疏, 這對后面的相似性計算提出了很大的挑戰(zhàn). 合理的矩陣缺失值預(yù)測填充可以從一定程度上緩解稀疏性問題.
目前常用的缺失值預(yù)測方法包括評分中值、眾數(shù)、用戶評分均值、項目評分均值、采用奇異值分解填補近鄰評分缺失值[7]以及基于近似項目預(yù)測評分值[8]等.
2.2 用戶近鄰集合構(gòu)建
接下來, 我們在預(yù)處理過的用戶評分矩陣上采用相似度計算方法, 計算用戶之間的相似度, 形成用戶的相似度矩陣. 協(xié)同過濾算法研究中最常用的相似度計算方法是相關(guān)相似度、余弦相似度和修正的余弦相似度, 它們的計算公式分別如下:
相關(guān)相似度:
余弦相似度:
修正的余弦相似度:
各公式中表示用戶、.r表示用戶對項目的評分,表示用戶的平均評分,I、I表示用戶已經(jīng)評價過的項目集合,I表示用戶和用戶的共同評分項目集合.
相似矩陣構(gòu)建結(jié)束后, 便可根據(jù)用戶指定的最近鄰篩選規(guī)則構(gòu)建近鄰集合, 常用的篩選規(guī)則包括指定近鄰數(shù)量和設(shè)置相似度閾值.
2.3 物品推薦
利用上一步計算得到的近鄰集合, 找到這個集合中的用戶喜歡且目標(biāo)用戶沒有聽說過的物品推薦給用戶. 具體而言, 我們利用公式(4)計算用戶對指定項目的預(yù)測評分.
其中N為用戶的最近鄰集合, sim()為用戶、的相似度, 其余符號與前面定義一致. 最終便得到了用戶關(guān)于項目i的預(yù)測評分.
3 基于用戶部分特征的協(xié)同過濾算法(UPCF)
傳統(tǒng)的基于用戶的協(xié)同過濾算法在計算最近鄰的過程中使用了用戶的所有評分記錄, 考察了用戶的全局相似性. 然而在全部項目集上興趣都相似的用戶并不常見, 大多用戶可能只在某一主題下興趣相似, 而在其余項目分類中喜好完全不同. 因此傳統(tǒng)的近鄰集合構(gòu)建往往選擇了全局相對相似而舍棄了在某些領(lǐng)域內(nèi)興趣高度契合的用戶. 為了解決這個問題, 本文提出了一種基于用戶部分特征的協(xié)同過濾算法, 使得在最近鄰選擇時所需的相似度僅根據(jù)用戶在該項目所在類內(nèi)的評價信息計算獲得. 算法詳細流程如下所示.
3.1 未評分項目預(yù)測填充
為了緩解在項目聚類時矩陣的稀疏問題, 我們首先對評分矩陣進行缺失值預(yù)測填充. 考慮到熱門項目對用戶特征貢獻度不大, 以及相對冷門項目而言, 用戶接觸到熱門項目的概率大得多, 而如果用戶未對熱門項目進行反饋評價, 很可能是因為用戶對該項目并不感興趣. 而在推薦系統(tǒng)中, 項目流行度是衡量項目熱門程度的主要指標(biāo), 它是指項目被用戶反饋的總次數(shù), 被反饋的次數(shù)越多代表項目流行度越高. 因此為了能夠從一定程度上合理懲罰未評分熱門項目, 我們引入了項目流行度權(quán)重系數(shù),在此次試驗中, 我們采用以下公式計算項目流行度, 其中()表示項目已被評分的總次數(shù).
項目被評分總次數(shù)()越大則對應(yīng)權(quán)重越小, 預(yù)測評分則會相應(yīng)降低.最終我們采用如下方法進行缺失值預(yù)測填充.
3.2 項目聚類
缺失數(shù)據(jù)處理過后, 我們便可對項目進行聚類, 本次我們采用聚類算法中最經(jīng)典的K-means算法進行項目聚類. 而傳統(tǒng)的K-means算法對初始聚類中心非常敏感, 聚類結(jié)果隨不同的初始輸入而有較大波動. 為消除這種敏感性, 本文采用袁方等提出的優(yōu)化初始聚類中心的改進K-means算法[9]進行聚類計算. 與傳統(tǒng)聚類算法不同的是, 該算法在選取初始聚類中心時計算每個數(shù)據(jù)對象所在區(qū)域的密度, 選擇相互距離最遠的個處于高密度區(qū)域的點作為初始聚類中心. 實驗表明改進后的K-means算法能產(chǎn)生質(zhì)量較高的聚類結(jié)果, 并且消除了對初始輸入的敏感性.

過程1. 基于項目的kmeans聚類 輸入: 聚類數(shù)目k, 最大迭代次數(shù)iter_num和用戶評分?jǐn)?shù)據(jù)填充矩陣R輸出: k個聚類 1) 計算以項目集I中每個項目ij為中心, 包含常數(shù)Minpts個數(shù)據(jù)對象的半徑, 記為ij的密度參數(shù). 越大, 說明數(shù)據(jù)對象所處區(qū)域的數(shù)據(jù)密度越低. 反之則說明數(shù)據(jù)對象所處區(qū)域的數(shù)據(jù)密度越高. 選取滿足的點ij為高密度區(qū)域D. 取D中處于最高密度區(qū)域的點作為第1個聚類中心rl; 取D中距離rl最遠的點作第2個聚類中心r2; 計算D中各數(shù)據(jù)對象ij到rl, r2的距離d(ij, r1), d(ij, r2), r3為滿足max(min(d(ij, r1), d(ij, r2)),j=1,2···n的數(shù)據(jù)對象ij; rm為滿足max(min(d(ij, r1), d(ij, r2)...d(ij, rm-1)),j=1,2···n的數(shù)據(jù)對象ij,ij∈D. 依此得到k個初始聚類中心. 記為集合centerold={r1, ···, rk}; 2) k個聚類簇cluster1, ···clusterk均初始化為空, 記為集合Cluster=(cluster1, ···clusterk)3) REPEATFOR each item i in I:FOR each center rjin centerold : 計算項目i和聚類中心rj的相似性; sim(i,rm)=max(sim(i,r1),sim(i,r2),···,sim(i,rk))EndforFor each clusterm in Cluster: 計算clusterm的均值, 生成新的聚類中心cnewm. Centernew={cnew1,cnew2,···, cnewk}EndforUTILCenterold=(c1, ···ck)和Centernew=(c1, ···ck)相同或達到最大迭代次數(shù)iter_num.4) 返回Cluster.
3.3 推薦生成
為了保證預(yù)測的精確性, 避免提前引入誤差, 我們在評分預(yù)測階段采用原始用戶評價矩陣而非填充矩陣. 并使用公式(1)計算待推薦用戶在待推薦項目所在類內(nèi)與其余用戶的相似度, 構(gòu)建用戶相似性矩陣. 查找與用戶相似度最大的個最近鄰. 使用公式(4)計算用戶預(yù)測評分, 得到最終評分預(yù)測值, 算法過程如下.

過程2. 評分預(yù)測 輸入: 原始用戶評價矩陣R, 最近鄰個數(shù)n, 待預(yù)測評分用戶u, 項目i, 項目i所在聚類簇clusterj=[il,ij,···,ip]. 輸出: 評分預(yù)測值 1) simDict={}2) For user v in U: IF v!=u: simDict[v]=sim(u,v) Endif Endfor3) Nu=sort(simDict)[:n]4)
其中, 此處,的特征向量為=(,,···,),= (,, ··· ,). sim(,)我們采用公式(1)所提供的相關(guān)相似性計算. 算法的復(fù)雜度為. 至此, 我們便可獲得指定用戶對指定項目的評分預(yù)測值, 為隨后的推薦提供支持.
4 實驗結(jié)果及分析
本次實驗的硬件平臺是配置Intel pentium E58003.2 GHz CPU, 4G RAM, 操作系統(tǒng)為ubuntu 14.04的個人計算機, 所有程序均由python實現(xiàn).
4.1 數(shù)據(jù)集
本文采用的實驗數(shù)據(jù)集是目前衡量推薦算法質(zhì)量常用的著名電影評分?jǐn)?shù)據(jù)集MovieLens中的100k數(shù)據(jù)集(http://grouplens.org/datasets/movielens), 該數(shù)據(jù)集由美國明尼蘇達大學(xué)GroupLens研究小組創(chuàng)建并維護. 該實驗數(shù)據(jù)集共包含930個用戶對1682部電影的100000條評價信息, 其中每個用戶至少對20部電影進行了評分, 每個電影也都收到了用戶評論. 該數(shù)據(jù)集的稀疏性為1-100000/(943*1682) = 0.937. 數(shù)據(jù)集中用戶評分范圍是1-5, 數(shù)值越大代表用戶對該電影的興趣越大. 本次實驗按照80%和20%的比例隨機的將數(shù)據(jù)集劃分成為訓(xùn)練集和測試集, 隨后進行5-折交叉實驗, 取五次試驗的平均值作為最終結(jié)果.
4.2 評價標(biāo)準(zhǔn)
平均絕對誤差MAE(mean absolute error)是目前學(xué)術(shù)研究中應(yīng)用廣泛的推薦系統(tǒng)推薦質(zhì)量評價標(biāo)準(zhǔn). 其主要通過公式(7)計算測試集中用戶實際評分和推薦算法根據(jù)訓(xùn)練集的訓(xùn)練預(yù)測值的差的絕對值均值, 平均絕對誤差MAE越小, 推薦算法的質(zhì)量越高. 其中表示測試集的數(shù)據(jù)個數(shù),p為預(yù)測評分值,r為測試集中的實際評分值.
4.3 實驗結(jié)果分析
我們首先研究聚類個數(shù)對本文算法性能的影響. 實驗結(jié)果如圖1所示, 其中橫坐標(biāo)表示聚類個數(shù), 縱坐標(biāo)表示MAE值, 最近鄰個數(shù)統(tǒng)一取=30.
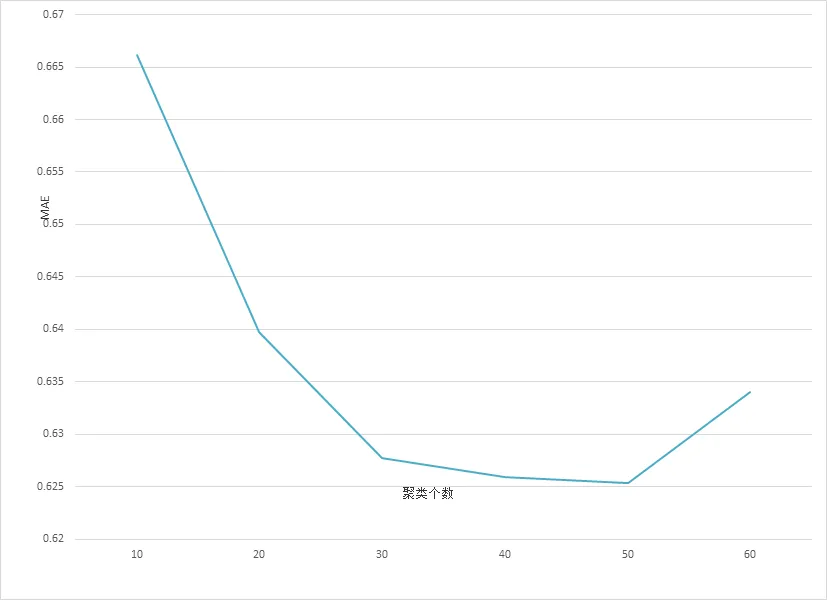
圖1 聚類個數(shù)對MAE值的影響
通過圖1我們可以清晰看到剛開始, 隨著聚類族數(shù)的增多, 算法性能不斷提升, 當(dāng)項目聚類個數(shù)為50時, 算法取得了最好的性能, 此后聚類族數(shù)的增多反而引起算法性能的下降. 接下來, 我們通過將本文所提出算法UPCF與傳統(tǒng)的基于用戶聚類的協(xié)同過濾算法(UBCF)[3]、綜合用戶和項目因素的協(xié)同過濾推薦算法(HCFR)[4]、基與不確定近鄰的協(xié)同過濾算法(UNCF)[6]的平均絕對誤差MAE進行對比觀測試驗性能. 為了縮短算法的運行時間, 聚類個數(shù)均設(shè)置為20.

圖2 算法性能比較
由圖2可以看出, 本文算法與其他算法在MAE值上有了10%左右的提高, 特別是當(dāng)近鄰個數(shù)比較少的時候, 本文算法體現(xiàn)了非常好的推薦效果, 性能優(yōu)勢明顯更好, 這充分說明本文提出算法最近鄰選擇的高效合理性. 我們也可以觀察到, 當(dāng)最近鄰個數(shù)達到一定數(shù)量后, 所有算法的MAE性能趨于平穩(wěn), 這也反映出當(dāng)近鄰相似度不斷減小時, 該近鄰對算法的性能提升沒有顯著的影響.
此外, 本文算法在提高推薦質(zhì)量的同時并沒有帶來算法復(fù)雜性的提升. 數(shù)據(jù)的預(yù)填充和項目聚類均可提前離線完成, 僅需根據(jù)需求隔一段時間更新. 而評分預(yù)測由于不再依賴用戶全局特征, 單個評分預(yù)測的復(fù)雜性由變?yōu)? 其中表示用戶總個數(shù),表示項目總個數(shù),表示項目聚類個數(shù). 用戶還可根據(jù)實際需求, 并行的在各個項目類內(nèi)進行用戶評分預(yù)測.
5 總結(jié)
針對傳統(tǒng)協(xié)同過濾算法中最近鄰計算時所面臨的稀疏性和準(zhǔn)確性挑戰(zhàn), 本文提出了一種基于用戶部分特征的協(xié)同過濾算法. 該算法采用基于評分偏差與項目流行度的思想進行缺失值填充, 并在最近鄰構(gòu)建時僅考慮用戶在該項目分類下的特征, 動態(tài)的根據(jù)待預(yù)測項目篩選用戶最近鄰, 從而提高了推薦的質(zhì)量. 此外, 由于僅需考慮用戶類內(nèi)特征, 該算法實現(xiàn)了一定程度的降維, 降低了算法的復(fù)雜性. 并可根據(jù)需要, 分布并發(fā)的計算各個類內(nèi)用戶的預(yù)測評分值, 一定程度上提高了算法的實時性.
但算法中項目分類以及用戶最近鄰選擇時特征選擇的準(zhǔn)確性仍需要進一步研究改良, 所使用的聚類算法K-means的聚類效果仍不是十分理想. 此外, 在此次研究前期對推薦算法的了解中, 我們發(fā)現(xiàn)目前針對各種推薦算法模型的融合以及算法并行化的研究也成為業(yè)界的新熱點. 而能夠更好地反應(yīng)用戶興趣的用戶社交關(guān)系的引入[10,11]大大提高了協(xié)同過濾算法的近鄰可靠性和準(zhǔn)確性, 為算法的改良提供了新的方向. 如何將用戶社交關(guān)系引入本文提出的算法, 進一步改善本文算法的性能, 將是下一階段研究的重點.
1 Park DH, Kim HK, Choi IY, Kim JK. A literature review and classification of recommender systems research. Expert Systems with Applications, 2012, 39(11): 10059–10072.
2 Bobadilla J, Ortega F, Hernando A, Gutiérrez A. Recommender system survey. Knowledge-Based Systems. 2013, 46: 109–132.
3 Ungar LH, Foster DP. Clustering methods for collaborative filtering. AAAI Workshop on Recommendation Systems, 1998, 1: 114–129.
4黃裕洋,金遠平.一種綜合用戶和項目因素的協(xié)同過濾推薦算法.東南大學(xué)學(xué)報(自然科學(xué)版),2010,40(5):917–921.
5 Amatriain X, Lathia N, Pujol JM, Kwak H, Oliver N. The wisdom of the few: A collaborative filtering approach based on expert opinions from the web. Proc. of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM. 2009. 532–539.
6 黃創(chuàng)光,印鑒,汪靜,劉玉葆,王甲海.不確定近鄰的協(xié)同過濾推薦算法.計算機學(xué)報,2010,33(8):1369–1377.
7 Koren Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. Proc. of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2008. 426–434.
8 鄧愛林,朱揚勇,施伯樂.基于項目評分預(yù)測的協(xié)同過濾推薦算法.軟件學(xué)報,2003,14(9):1621–1628.
9袁方,周志勇,宋鑫.初始聚類中心優(yōu)化的K-means算法.計算機工程,2007,33(3):65–66.
10 Daly EM, Geyer W. Effective event discovery: Using cation and social information for scoping event recommendations. Proc. of the 5th ACM Conference on Recommender Systems. ACM. 2011. 277–280.
11 Guy I. Social recommender systems. Recommender Systems Handbook. Springer US, 2015: 511–543.
Collaborative Filtering Algorithm Based on User Partial Feature
LI Yong-Chao, LUO Jun
(Department of Computer Science, National University of Defense Technology, Changsha 410073, China)
As one of the most widely used algorithms in recommender system, the traditional collaborative filtering algorithm faces serious data sparseness problem in the big data trend, which leads to the ineffective in nearest neighbor selection, and restricts the performance of the algorithm. To address this problem, this paper proposes a collaborative filtering algorithm based on user partial feature(UPCF). In our method, it first rates the missing values based on rating bias and item popularity; and then clusters the items in the filled matrix with a K-means clustering algorithm of meliorated initial center. At last, it uses the user-based collaborative filtering algorithm with the user feature in item class to get the recommendations. The MAE measures on the MovieLens dataset shows that compared with the current popular algorithms, the performance of our UPCF algorithm improves about 10% without any increase of algorithm complexity.
item popularity; nearest neighbor selection; item clustering; collaborative filtering algorithm
2016-07-01;
2016-08-31
[10.15888/j.cnki.csa.005704]
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業(yè)黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛(wèi)星與網(wǎng)絡(luò)(2016年12期)2016-02-05 09:23:23
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
