基于雙閾值AdaBoost算法的4-CBA含量軟測量建模
2017-10-13 15:28:33劉瑞蘭劉樹云戎舟江兵龐宗強
化工學報 2017年5期
劉瑞蘭,劉樹云,戎舟,江兵,龐宗強
?
基于雙閾值AdaBoost算法的4-CBA含量軟測量建模
劉瑞蘭,劉樹云,戎舟,江兵,龐宗強
(南京郵電大學自動化學院,江蘇南京 210003)
針對PX氧化過程中4-CBA含量無法在線測量的問題,提出了一種基于雙閾值更新樣本權重的AdaBoost算法,該算法以BP神經網絡作為弱學習器,采用輪盤賭方法根據樣本權重在訓練樣本集中選擇部分樣本訓練弱學習器,采用上一輪弱學習器的訓練相對誤差絕對值來更新所有訓練樣本的權重,在此基礎上,用雙閾值對樣本誤差范圍進行劃分,然后用不同的權重因子與原來的樣本權值相乘實現樣本權值的二次更新。該過程降低了含有大誤差的樣本的權值,增加了較大誤差的樣本的權值,從而減小了在下一輪訓練過程中選到異常樣本的概率。分別采用5種不同的方法并用實測的工業數據建立了4-CBA含量軟測量模型,仿真結果表明用提出的改進AdaBoost算法建立的4-CBA含量軟測量模型,其預測誤差小于其他方法建立的模型誤差。
AdaBoost算法;軟測量;雙閾值;異常樣本;4-CBA含量;輪盤賭方法
引 言
精對苯二甲酸(purified terephthalic acid,PTA)是制造聚酯纖維和化工生產中重要的有機原料。對羧基苯甲醛(4-carboxy-benzaldchydc,4-CBA)是PTA生產過程中對二甲苯(paraxylene,PX)氧化反應的副產物,為保證產品純度一般工業要求其含量為2.0~3.5 g·kg-1[1]。但PTA生產過程中涉及多元熱力學平衡,工藝流程復雜,按照常規方法難以精確測量并控制4-CBA含量。而4-CBA含量是反應過程中主要產品質量的重要指標,當4-CBA含量不在要求范圍時會嚴重影響產品的質量,本文將采用軟測量技術來解決4-CBA含量不能在線測量的問題。
軟測量技術的核心是建立軟測量模型。目前,有關4-CBA含量的軟測量建模方法主要分為機理建模方法[2-5]和基于數據驅動的建模方法[6-13]。文獻[2]提出了一個基于實驗小試結果的PX氧化反應機理模型,并對反應溫度、催化劑濃度、停留時間、反應器尾氧濃度對反應物濃度的影響進行了研究。文獻[3]在文獻[2]的基礎上,對模型中的某些參數設置裝置因數,并提出了改進的LM (Levenberg-Marquardt)阻尼非線性最小二乘算法和工廠實測數據來辨識裝置因數。由于非線性最小二乘法對初始值比較敏感,文獻[4]提出了用支持向量機提取特征樣本、采用粒子群算法辨識裝置因數的4-CBA含量機理軟測量模型,避免了傳統方法對初始點和樣本的依賴。文獻[5]采用簡化的機理模型,根據4-CBA含量和氧化反應器進料流量與第一結晶器空氣流量的非線性函數關系,結合優生優選進化算法對模型的參數進行估計。文獻[6]采用3層BP人工神經網絡并結合LM學習規則建立了4-CBA含量的軟測量模型;文獻[7]利用貝葉斯方法,結合多項式線性基函數,建立了4-CBA含量的軟測量模型;文獻[8-9]提出用模糊神經網絡方法建立了4-CBA含量的軟測量模型;文獻[10]和[11]都采用最小二乘支持向量機方法建立4-CBA含量的軟測量模型,并分別用參數的自動調整方式和稀疏化的方式提高模型的泛化性能;文獻[12]和[13]分別采用模糊支持向量機和偏最小二乘結合前向神經網絡方法建立4-CBA含量的軟測量模型。由于機理模型本身包含了過程本質的信息,因此模型的泛化性能較好。但是對于復雜的過程,機理模型建立比較困難。基于數據驅動的方法建立軟測量模型則需要大量高質量的訓練樣本和合適的算法,基于經驗風險最小化的BP神經網絡方法和模糊神經網絡方法可能會出現過擬合現象。
應用于軟測量建模的訓練樣本都來自工廠的實測過程數據和分析數據,樣本不可避免會存在誤差,有些甚至含有粗大誤差,含有粗大誤差的樣本會嚴重影響模型準確度。針對這一問題,本文提出了雙閾值AdaBoost(adaptive Boosting)算法,該算法以一個隱含層、隱含層節點數為2的簡單的BP神經網絡作為弱學習器,采用輪盤賭方法根據樣本權重在總的訓練樣本集中選擇部分樣本訓練弱學習器,并用弱學習器的相對訓練誤差的絕對值來更新每個訓練樣本的權重。在此基礎上,縮小含有粗大誤差的訓練樣本權重,放大一些具有較大隨機誤差的訓練樣本權重,這樣可以防止在第2輪以后的弱學習器學習中每次都選中具有粗大誤差的訓練樣本。最后將本文提出的方法建立了PX 氧化過程中4-CBA含量的軟測量模型,比較了不同方法建立的軟測量模型的訓練精度和預測精度。
1 BPNN-AdaBoost 回歸算法簡介
AdaBoost.R算法是由Freund等[14]提出的應用到回歸問題中的方法,Drucker[15]在AdaBoost.R的基礎上提出了改進的AdaBoost.R2算法驗證了回歸問題的適用性。2004年,Solomatine等[16]在AdaBoost.R算法的基礎上通過設置閾值提出了AdaBoost.RT算法用于回歸預測。Baumann等[17]通過設定閾值限定分類器來排除誤差較大的分類器,在訓練時間上作了改進,提出SEAdaBoost算法;袁雙等[18]結合PCA降維方法來提高AdaBoost算法的訓練速度;查翔等[19]提出了一種以均方根相對誤差為衡量標準的自適應調整閾值的方法,提高了預測精度題;Zhang等[20]以每個弱學習器的統計誤差來自動調節閾值,提高了算法的精度和速度;胡國勝[21]將加權的支持向量機作為弱學習器應用于電力負荷預測,提高了預測精度;劉慶華等[22]在高速公路交通事件檢測時選用遺傳算法優化BP神經網絡弱學習器,降低了誤報率。
AdaBoost算法原理是將多個弱學習器多次訓練并組合成強學習器。強學習器預測精度高于單一弱學習器[23]。BPNN-AdaBoost算法是將BP神經網絡作為弱學習器,反復訓練得到一組弱學習器,最后將這組弱學習器組合得到強學習器,其訓練步驟如下[24-25]。
(1)確定輸入輸出樣本,初始化BP神經網絡參數,并設置迭代次數。給定一組訓練樣本(,),其中∈R,∈,為輸入,為輸出。
(2)樣本預處理。將輸入輸出數據歸一化。
(3)初始化訓練樣本的權重。給每個訓練樣本設置初始權重1=1,并給每個訓練樣本指定一個初始概率
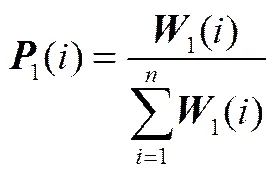
其中,為訓練樣本個數。
(4)訓練弱學習器。將單一BP神經網絡作為弱學習器進行訓練,計算弱學習器的相對誤差絕對值
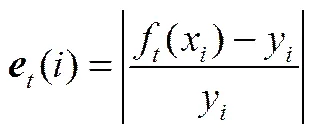
其中,f(x)為第個弱學習器在訓練輸入x時的估計值,y為訓練樣本的實際值。
(5)計算第個弱學習器的訓練平均損失函數值
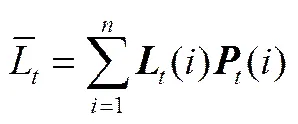
其中
(4)
(6)計算弱學習器權重系數,依據弱學習器平均損失函數計算弱學習器權值,計算公式為
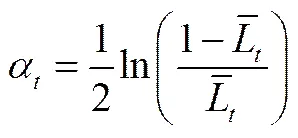
從式(2)、式(3)和式(5)可以看出,所有樣本的相對誤差絕對值越小,弱學習器平均損失函數也越小,弱學習器權值越大。
(7)更新樣本權重和概率。
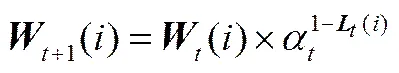
(7)
(8)判斷循環次數是否達到次,若達到則結束循環向下執行,否則返回步驟(4)。
(9)合成強學習器,訓練結束后得到一組弱學習器,將其組合成強學習器,組合算式為
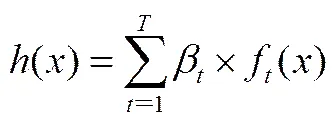
其中
2 雙閾值BPNN_AdaBoost算法
2.1 弱學習器訓練樣本的選擇
本文提出了如下的方法選擇BP神經網絡弱學習器的訓練樣本,當=1時,用全部訓練樣本集中的樣本訓練弱學習器。當>1時,依據每個樣本的概率()采用輪盤賭的方法對樣本進行重采樣。輪盤賭方法是由Holland[26]提出用于遺傳算法中按概率選擇個體的隨機方法,該方法類似于賭博游戲中的賭輪盤,群體中的每個個體的適應度按比例轉化為選中概率,根據該概率將輪盤分成與個體數目相同的扇區,扇區的大小與概率呈正比。旋轉這個輪盤,直到輪盤停止時,看指針停止在哪一塊上,就選中與它對應的那個個體,個體概率越大,被選中的機會越大。這種方法的好處是在迭代過程中訓練樣本不一樣。但是隨著迭代的進行,誤差絕對值大的樣本對應的()也越大,被抽取作為下一輪訓練樣本的概率越大,最后每次都有可能選中這些誤差大的樣本,導致所有的弱學習器近似相同。
2.2 雙閾值更新樣本權重
本文對式(6)更新樣本權重公式進行了如下改進
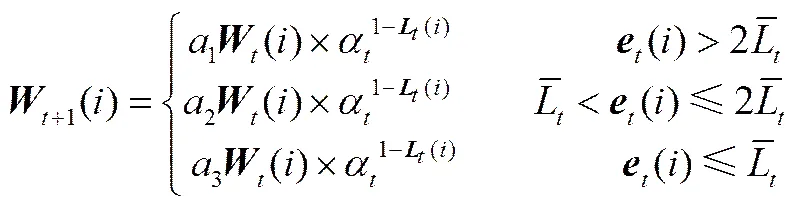
其中1,2,3分別為不同的權重調整因子,為更新樣本的權重,1、2取值在1附近,且2>3=1>1。當訓練樣本的誤差()大于2倍相對誤差絕對值均值時,這部分樣本可以看成是具有粗大誤差的樣本,通過乘一個小于1的調整因子,縮小樣本權重,減小該樣本在下一輪訓練弱學習器時被選中的概率。當訓練樣本的誤差()位于1倍和2倍相對誤差絕對值均值之間時,這部分樣本可以看成是具有較大隨機誤差的樣本,通過乘一個大于1的調整因子,放大樣本的權重,提高該樣本在下一輪訓練弱學習器時被選中的概率。值得指出的是,式(9)改變了樣本的權重,從而改變了式(7)的概率+1(),但是這種改變有的增加,有的減小,在迭代過程中對平均損失函數值有一定的影響,最終會導致弱學習器的權重不會出現較大的分散度。
3 仿真實例
為了驗證提出的雙閾值BPNN_AdaBoost算法的有效性,選用通用函數=sin(p)/(p)+作為例子,其中訓練輸入樣本∈[-4,4],為[-0.03,0.03]均勻分布的噪聲。訓練樣本中有5個點加了粗大誤差,如圖1所示。分別采用本文提出的方法和經典的BPNN_AdaBoost算法進行了仿真實驗,其中弱學習器個數為5,弱學習器的隱含層節點數為10,隱含層數為1。
圖1顯示了兩種方法得到的模型的擬合值和預測值與對應的實際值和真實值之間的比較曲線。圖2顯示了模型輸出值與真實值之間的相對誤差比較。從圖中可以看出,雙閾值方法得到的模型更能逼近函數的真實值。
4 應用實例
4.1 PX氧化過程簡介
PX氧化過程[27-29]是在反應溫度為190℃左右,壓力為1.258 MPa,在醋酸鈷、醋酸錳等催化劑和溴化物促進劑作用下以醋酸為溶劑,用空氣中的氧氣將PX氧化為TA (terephthalic acid,對苯二甲酸),并將TA溶于水后經過逐級降溫,再固液分離干燥后得到PTA (purified terephthalic acid,精對苯二甲酸)的過程。PX氧化反應過程中會出現3種中間產物:對甲基苯甲醛(-tolualdehyde, TALD)、對甲基苯甲酸(-toluic acid, PT)和4-CBA。而4-CBA是氧化反應的主要副產物,是衡量產品的重要指標。
4-CBA含量無法用常規的傳感器在線測量,而是通過實驗室分析化驗出來,化驗時間比較長;同時由于化驗成本較高,其采樣間隔較長,比如某工廠對4-CBA含量的采樣周期為8 h,每天固定在0點,8點和16點采樣,因此一天最多只有3個滯后數小時的4-CBA含量的分析值。
4.2 軟測量模型輸入變量的選擇
影響4-CBA含量的因素較多,綜合文獻[4,11,30]選擇氧化反應器物料進料流量、氧化反應器催化劑濃度、氧化反應器溶劑、氧化反應器液位、氧化反應器溫度、氧化反應器尾氧含量、第一結晶器溫度、第一結晶器尾氧含量、第三冷凝器排出水量、第四冷凝器排出水量、反應生成的二氧化碳含量和反應生成的一氧化碳含量共12個過程變量作為軟測量模型的輸入變量。
4.3 工業數據仿真結果
本文采用的數據來源于某化工廠,共收集了196組樣本,樣本按時間順序排列,取前面120組樣本作為訓練總樣本,后面76組樣本作為驗證樣本。
采用BP神經網絡作為雙閾值AdaBoost算法的弱學習器,所有神經網絡弱學習器只有一個隱含層,輸入層節點個數為12,為了減少弱學習器的規模,選擇隱含層節點個數為2,弱學習器的個數為5。弱學習器的初始值均隨機賦值,采用輪盤賭方法根據樣本權重在訓練樣本集中選擇80%以上的樣本訓練弱學習器。1和2根據經驗分別選為0.78和1.1。
本文采用相對誤差絕對值的平均值作為模型的性能指標,具體計算公式為
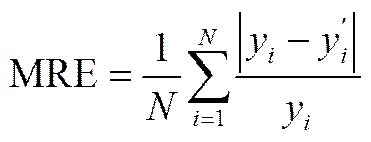
式中,y為實際值,y′為估計值,是樣本個數。
為了驗證本文提出的雙閾值BPNN_AdaBoost算法的性能,分別比較了雙閾值非輪盤賭BPNN_AdaBoost算法模型、非雙閾值輪盤賭BPNN_AdaBoost算法模型、非雙閾值非輪盤賭的BPNN_AdaBoost算法模型和單一的BP神經網絡模型的性能,其中非輪盤賭表示所有訓練樣本都參與弱學習器的學習。單一BP神經網絡模型結構為輸入層節點數12,隱含層節點數10。
在弱學習器的學習過程中,第3、第6、第103和第105號訓練樣本的相對誤差絕對值均大于2倍的平均相對誤差。在沒有使用雙閾值改變樣本權重的BPNN_AdaBoost算法中,每次都被選中,而在雙閾值改變樣本權重的BPNN_AdaBoost算法中,只有1次被選中。
表1給出了不同方法的相對誤差絕對值的平均值,從表中可以看出,本文提出的雙閾值結合輪盤賭選擇訓練樣本的BPNN_AdaBoost算法建立的軟測量模型的預測誤差(PE)最小,訓練誤差(TE)最大,但是兩者數值較接近。這是因為雙閾值法減小了粗大樣本的權重,在使用輪盤賭重采樣時,這部分樣本被選中的概率變小,在5個弱學習器中,只有2個弱學習器使用了含有粗大誤差的樣本,由于含有粗差的樣本只用于少量的弱學習器的學習,使得最終模型的預測誤差較小,沒有出現過擬合現象。從表1中還可以看出,輪盤賭方式選擇訓練樣本時訓練誤差都比較大,這是因為采用輪盤賭的方式選擇訓練樣本時,實際上是在給定的120組訓練樣本中依據每個樣本的權值選擇80%的樣本作為每輪弱學習器的訓練樣本,沒有選中的樣本不參與弱學習器的訓練,也就是說采用輪盤賭的方法實質上是將總的訓練樣本分成了訓練樣本子集和測試樣本子集,因此總的訓練誤差包含訓練樣本子集的擬合誤差和測試樣本子集的測試誤差,導致總的訓練誤差比較大。
從表1可以看出采用輪盤賭的方式訓練的軟測量模型預測誤差相比而言較小。雖然從模型規模上看,本文由5個BP弱學習器組成的BPNN_AdaBoost強學習器軟測量模型(每個弱學習器結構為12-2-1)和一個12-10-1的單一BP神經網絡軟測量模型一樣,但是本文提出的方法建立的軟測量模型的預測效果是最好的。

表1 不同方法建立的4-CBA軟測量模型結果比較
BPNN_AdaBoost也可以看成是一種串行訓練BP神經網絡的方法,在網絡規模相同的情況下,串行方法訓練時間長,但是模型的預測效果與單一的BP神經網絡相比要好得多。圖3分別顯示了本文提出的雙閾值方法建立的4-CBA含量軟測量模型和單一BP神經網絡軟測量模型的擬合值、預測值和對應的真實值的比較曲線。
5 結 論
本文以小規模BP神經網絡為弱學習器,采用雙閾值BPNN_AdaBoost算法,通過增加調整因子的方式二次更新訓練樣本的權值,使得模型訓練不再僅專注誤差大的樣本。采用輪盤賭方法在訓練樣本集中選擇部分樣本訓練弱學習器,增加了弱學習器的多樣性。最后用本文提出的方法建立了4-CBA含量的軟測量模型,用工業數據仿真結果表明,用本文提出的方法與單一的BP神經網絡模型相比,在不增加模型規模的情況下,預測效果提高了幾乎一個百分點。
References
[1] 冒永生, 楊開香, 王麗軍. PTA裝置氧化過程實時優化與先進控制[J]. 化工自動化及儀表, 2012, 39(9): 1128-1132. MAO Y S, YANG K X, WANG L J. Real-time optimization and advanced control for pta oxidation process[J]. Control & Instruments in Chemical Industry, 2012, 39(9): 1128-1132.
[2] 王麗軍. PX氧化動力學研究及氧化反應器模擬[D]. 杭州: 浙江大學, 2001. WANG L J. Studies on the kinetics of-xylene oxidation oxidation and the reactor simulation[D]. Hangzhou: Zhejiang University, 2001.
[3] 牟盛靜. 石化工業過程建模與優化若干問題研究[D]. 杭州: 浙江大學, 2004. MOU S J. The studies of process modeling and optimization in petrochemical industry[D]Hangzhou: Zhejiang University, 2004.
[4] 劉瑞蘭, 牟盛靜, 蘇宏業, 等. 基于支持向量機和粒子群算法的軟測量建模[J]. 控制理論與應用, 2006, 23(6): 895-900. LIU R L, MOU S J, SU H Y,Modeling soft sensor based on support vector machine and particle swarm optimization algorithms[J]. Control Theory and Applications, 2006, 23(6): 895-900
[5] 顏學峰, 余娟, 錢鋒. 基于自適應偏最小二乘回歸的初頂石腦油干點軟測量[J]. 化工學報, 2005, 56(8): 1151-1156. YANG X F, YU J, QIAN F. An evolution algorithm with select-best and prepotency operator and parameter estimation of 4-CBA model[J]. Journal of Chemical Industry and Engineering(China), 2005, 56(8): 1151-1156.
[6] 胡永有, 古勇, 蘇宏業, 等. 基于BPANN的4-CBA軟測量模型研究[J]. 儀器儀表學報, 2003, 24(3): 226-230. HU Y Y, GU Y, SU H Y,The research of 4-CBA soft- sensor model based on BPANN[J]. Chinese Journal of Scientific Instruments, 2003, 24(3): 226-230.
[7] 陳渭泉, 劉瑞蘭, 牟盛靜, 等. 基于貝葉斯方法的4-CBA含量的軟測量研究[J]. 化工自動化及儀表, 2003, 30(5): 49-51. CHEN W Q, LIU R L, MOU S J,The research on soft sensor of the concentration of 4-CBA based on Bayesian approach[J]. Control & Instruments in Chemical Industry, 2003, 30(5): 49-51.
[8] LIU R L, SU H Y, MOU S J,. Fuzzy neural network model of 4-CBA concentration for industrial PTA oxidation process[J]. Chinese Journal of Chemical Engineering, 2004, 12(2): 234-239.
[9] DU W L, QIAN F, LIU M D,. 4-CBA soft sensor based on fuzzy CMAC neural networks[J]. Chinese Journal of Chemical Engineering, 2005, 13(3): 437-440.
[10] 鄭小霞, 錢鋒. 基于證據框架的最小二乘支持向量機在精對苯二甲酸生產中的應用[J]. 化工學報, 2006, 57(7): 1612-1616. ZENG X X, QIAN F. Application of least squares support vector machine within evidence framework in PTA process[J]. Journal of Chemical Industry and Engineering(China), 2006, 57(7): 1612- 1616.
[11] 劉瑞蘭, 徐艷, 戎舟. 基于稀疏最小二乘支持向量機的軟測量建模[J]. 化工學報, 2015, 66(4): 1402-1407. LIU R L, XU Y, RONG Z. Modeling soft sensor based on sparse least square support vector machine[J]. CIESC Journal, 2015, 66(4): 1402-1407.
[12] ZANG Y, SU H Y, LIU R L. Fuzzy support vector regression model of 4-CBA concentration for industrial PTA oxidation process[J]. Chinese Journal of Chemical Engineering, 2005, 13(5): 642-648.
[13] 顏學峰. 基于MLFN-PLSR的PX氧化反應組合建模方法[J]. 化工學報, 2007, 58(1): 149-154. YAN X F. Delvelop-xylene oxidation reaction model based on MLFN_PLSR[J]. Journal of Chemical Industry and Engineering(China), 2007, 58(1): 149-154 .
[14] FREUND Y, SCHAPIRE R E. A decision-theoretic generation of online learning and an application to Boosting[J]. Journal of Computer and System Science, 1997, 55(1): 119-139.
[15] DRUCKER H. Improving regressor using Boosting techniques[C]//Proc. of the 13th Annual Conf. on Computational Learning Theory. San Francisco, 1997: 208-219.
[16] SOLOMATINE D P, SHRESTHA D L. AdaBoost.RT: a boosting algorithm for regression problem[C]//Proc. of the Int. Joint Conf. on Networks. Budapes, 2004: 1163-1168.
[17] BAUMANN F, ERNST K, EHLERS A,. Symmetry enhanced AdaBoost[C]//International Conference on Advances in Visual Computing. Springer-Verlag,2010: 286-295.
[18] 袁雙, 呂賜興. 基于PCA改進的快速AdaBoost算法研究[J]. 科學技術與工程, 2015, 15(29): 62-67. YUAN S, Lü C X. Fast AdaBoost algorithm based on improved PCA[J]. Science Technology and Engineerring, 2015, 15 (29): 62-67.
[19] 查翔, 倪世宏, 張鵬. 關于AdaBoost.RT集成算法時間序列預測研究[J]. 計算機仿真, 2015, 32(9): 391-395. ZHA X, NI S H, ZHANG P. AdaBoost.RT intergrating prediction of time series based on adaptive and dynamic threshold[J]. Computer Simulation, 2015, 32(9): 391-395.
[20] ZHANG P B, YANG Z X. A novel AdaBoost framework with robust threshold and structural optimization[J]. IEEE Trans Cybem., 2016, (99): 1-13.
[21] 胡國勝. 基于加權支持向量機與AdaBoost集成的預測模型研究[J]. 計算機應用與軟件, 2012, 29(12): 280-281. HU G S. Study on forecasting model based on WSVR and AdaBoost[J]. Computer Applications and Software, 2012, 29(12): 280-281.
[22] 劉慶華, 丁文濤, 涂娟娟, 等. 優化BP_AdaBoost算法及其交通事件檢測[J]. 同濟大學學報(自然科學版), 2015, 43(12): 1829-1833. LIU Q H, DING W T, TU J J,Improved BP_AdaBoost algorithm and its application in traffic incident detection[J]. Journal of Tongji University(Natural Science), 2015, 43(12): 1829-1833.
[23] HU W M, HU W, MAYBNK S. AdaBoost-based algorithm for network intrusion detection[J]. Systems, Man, and Cybernetics, Part B: Cybernetics, IEEE Transactions on, 2008, 238(2): 577-583.
[24] SHRESTHA D L, SOLOMATINE D P. Experiments with AdaBoost. RT, an improved boosting scheme for regression[J]. Neural Computation, 2006, 18(7): 1678-1710.
[25] DEVON K B, SVEN F C. A comparison of AdaBoost algorithms for time series forecast combination[J]. International Journal of Forecasting, 2016, 32(4): 1103-1119.
[26] HOLLAND J H. Adaptation in Natural and Aritificial Systems[M]. Ann. Arbor: University of Michigan Press, 1992: 126-137.
[27] 李希, 謝剛, 華衛琦. PTA技術國產化的主要化學工程問題及其研究思路[J]. 聚酯工業, 2001, 14(1): 1-7. LI X, XIE G, HUA W Q. Key problems and research program for PTA process domestic development[J]. Polyester Industry, 2001, 14(1): 1-7.
[28] 尹云華, 向陽, 刁磊, 等. PTA生產工藝及技術的研究進展[J]. 化工工業與工程技術, 2011, 32(5): 33-39. YIN Y H, XIANG Y, DIAO L,Research progress of PTA production technology[J]. Journal of Chemical Industry &Engineering, 2011, 32(5): 33-39.
[29] 黃浩. 中國PTA行業的發展和現狀[J]. 聚酯工業, 2016, 29(1): 1-2. HUANG H. Development and current situation of PTA industry in China[J]. Polyester Industry, 2016, 29(1): 1-2.
[30] 劉瑞蘭, 戎舟. 工業PX氧化過程4-CBA含量的軟測量[J]. 信息與控制, 2014, 43(3): 339-343. LIU R L, RONG Z. A soft sensor for 4-CBA soncentration in industrial PX oxidation processes[J]. Information and Control, 2014, 43(3): 339-343.
Modeling soft sensor of 4-CBA concentration by AdaBoost algorithm with dual threshold technique
LIU Ruilan, LIU Shuyun, RONG Zhou,JIANG Bing,PANG Zongqiang
(College ofAutomation, Nanjing University of Post & Telecomomunication, Nanjing 210003, Jiangsu, China)
A modified AdaBoost algorithm with updating sample weight by dual threshold technique was proposed to model a soft sensor for estimating 4-CBA concentration, which could not be measured on-line in PX oxidation process. In this method, weak learners of BP neural networks were trained by part of samples selected by their weights and roulette wheel mechanism. The absolute values of last round training relative errors in weak learners were adopted to update weights of all training samples. Then, a second round updating on sample weights were completed by the product of original sample value and its weighting factor, which was defined by ratio of error range over dual thresholds. In the second updating process, weights were decreased for samples with gross errors but were increased for those with medium error. Consequently, probability of selecting outliers was reduced in following iteration of the training process. Five different methods were applied to model soft sensor of 4-CBA concentration with industrial data. Simulation results showed that the modified AdaBoost algorithm can improve soft sensor performance of 4-CBA concentration with predicting error less than that of other models.
AdaBoost algorithm; soft sensor; dual threshold technique; outliers; 4-CBA concentration; roulette wheel mechanism
10.11949/j.issn.0438-1157.20161609
TP 274
A
0438—1157(2017)05—2009—07
劉瑞蘭(1972—),女,博士,副教授。
國家自然科學基金項目(61203213)。
2016-11-14收到初稿,2017-02-08收到修改稿。
2016-11-14.
LIU Ruilan, liurl@njupt.edu.cn
supported by the National Natural Science Foundation of China (61203213).
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:02
中學生數理化·八年級物理人教版(2019年3期)2019-04-25 06:20:54
中學生數理化·八年級物理人教版(2018年3期)2018-05-31 08:52:45
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
少兒科學周刊·兒童版(2016年1期)2016-03-14 03:52:21
Coco薇(2015年1期)2015-08-13 02:47:34
