視覺與激光點云融合的深度圖像獲取方法
2017-11-01 15:20:17王東敏彭永勝李永樂
軍事交通學院學報 2017年10期
王東敏,彭永勝,李永樂
(1.陸軍軍事交通學院 研究生管理大隊,天津 300161; 2.陸軍軍事交通學院 軍用車輛系,天津 300161)
● 基礎科學與技術BasicScience&Technology
視覺與激光點云融合的深度圖像獲取方法
王東敏1,彭永勝2,李永樂2
(1.陸軍軍事交通學院 研究生管理大隊,天津 300161; 2.陸軍軍事交通學院 軍用車輛系,天津 300161)
針對無人車駕駛車輛使用相機進行環境感知時容易受到光照、陰影等影響,導致難以獲得有效的障礙物種類及位置信息等問題,使用64線激光雷達獲取前方6~60 m,左、右9 m范圍內的點云數據,使用k-d樹的方法將映射到圖像的三維激光點云進行排列并插值,對激光雷達數據與圖像信息進行融合。為解決映射后圖像深度信息稀疏的問題,采用二維圖像的紋理信息豐富雷達點云的方法對稀疏的深度圖像進行擬合插值,得到分辨率為1 624×350的小粒度深度圖像,為無人車行駛提供準確的環境場景信息。
無人車;視覺;激光點云;深度圖像
深度圖像利用場景中物體的深度信息來反映場景中物體之間的相互關系。一般的二維彩色圖像,容易受光照、環境陰影等影響,缺失原本的辨識特征,導致按顏色、紋理等特征進行分割難以得到令人滿意的結果。深度圖像不但能夠反映出場景中物體的外部紋理信息,還能夠反映出場景中各點相對于無人車相機的距離,有效區別遮擋物體,更方便地表現出場景中物體表面的三維信息。通過深度圖像可直接求解出物體的三維幾何特征,方便無人車在感知過程中對場景中的物體進行識別與定位[1]。
通常無人車系統通過對獲取的彩色圖像進行處理獲得場景的深度圖像。根據其獲取深度圖像原理的不同,通常采用如下幾種方法[2]:利用圖像的投影原理,得到場景的幾何模型,根據幾何模型及特征點,獲取特定相機參數下深度圖像的三維重建視覺方法[3-5];利用平行設置的兩臺保持相同配置的相機,同時對同一場景進行記錄,通過建立兩幅圖像點與點之間的對應關系,計算出兩圖像像素點的視差,恢復出圖像的三維信息的雙目視覺方法[6-7];利用獨立于相機之外的深度傳感器,通過激光雷達深度成像及結構光測距等方法,來獲取獨立于圖像之外的場景深度信息,通過融合相同時刻采集的彩色圖像及深度信息,來構建場景深度圖像的三維重構方法[8-11]。
然而,利用彩色圖像獲取深度圖像的三維重建視覺方法及雙目視覺方法,單純依靠攝像機獲取的圖像色彩及紋理信息,難以擺脫由于光照、環境陰影對圖像處理的干擾問題,造成生成深度數據的誤差[12]。使用三維重構方法,如Kinect相機獲取的場景深度信息難以獲得較遠距離的可靠數據,無法滿足無人車獲取較遠距離深度信息的場景感知要求。因此,針對無人車的感知需求,使用64線激光雷達及彩色相機采集場景數據,融合后生成小粒度深度圖像,提升獲取深度圖像的范圍,降低光照對深度場景感知的影響。由于64線激光雷達獲取的點云數據在圖像平面內是稀疏的,因此,利用彩色圖像的顏色紋理信息對激光雷達點進行擬合插值,生成小粒度的深度圖像,可使深度圖像獲取到場景中的紋理信息。
1 基于二維圖像與激光點云融合的深度圖像獲取方法
本文結合無人車平臺傳感器特點,提出采用相機采集場景的顏色數據,使用64線激光雷達獲取獨立的場景深度數據,用顏色數據對場景深度數據進行插值,形成小粒度深度圖像的方法[13-14],為無人車提供包含深度信息的高解析度場景圖像,提高無人車環境感知和理解的準確性。
使用圖像及雷達點云來獲得高分辨率的深度圖像,分為4個部分進行(如圖1所示):①使用已經進行64線激光雷達與相機聯合標定的無人車,獲取同一時刻的圖像與64線三維激光點云數據。②使用標定好的64線激光雷達三維坐標與相機平面二維坐標的轉化矩陣M,將激光點云投影到圖像相應的獨立于圖像的顏色通道之外的深度通道。③將投影到相機數據點上已知深度的雷達數據構建k-d樹。④使用圖像的顏色信息,對稀疏的64線激光雷達信息進行插值重構,獲得小粒度的深度圖像。
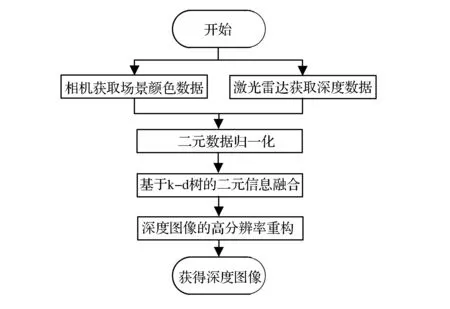
圖1 基于二維圖像與激光點云融合的深度圖像獲取流程
2 二元數據歸一化
在無人車系統中, 64線激光雷達和相機的相對位置與姿態固定不變, 64線激光雷達與相機所獲取數據,在兩個傳感器都覆蓋的采集范圍內,存在著一一對應關系[15]。根據激光雷達與相機的工作原理和成像模型,64線激光雷達數據點云坐標與圖像像素坐標之間存在如下關系:
(1)
式中:fx與fy為圖像坐標系中一個像素點所代表實際x、y方向上的距離;(u,v)為圖像坐標系坐標;s為圖像的深度距離與實際距離的比例因子;(u0,v0)為相機光軸與成像平面的交點坐標;R為3×3的正交旋轉矩陣;t為相機與64線激光雷達的外部平移向量;(Xw,Yw,Zw)為三維激光雷達數據點云坐標。
通過相機與64線激光雷達的內部參數與外部參數,可求得64線激光雷達點到圖像平面的轉化矩陣M:
(2)
式(1)可以簡化為
(3)
3 基于k-d樹的二元信息融合
經過歸一化處理,圖像上任意點的位置,通過二維坐標(u,v)進行定位,將圖像擴展為4個像素通道R、G、B、D,分別對應彩色圖像R、G、B顏色通道,以及深度通道。通過使用標定好的64線激光雷達三維坐標點與圖像二維坐標點的轉化矩陣M,將64線獲得的激光雷達坐標點轉化到圖像平面,將激光雷達點的深度值添加到相應位置的深度通道,作為深度圖像生成的原始數據。
使用k-d樹對映射后的深度值點進行排列,便于對像素點進行處理,使得圖像中的各像素點都能夠查找到距離最近的雷達數據映射點。如圖2所示,k-d樹在構建的過程中,按照二叉樹的方式對圖像平面中獲得深度值的二維坐標點進行排列,分別計算x、y兩個維度上的坐標方差,按照維度方差較大的中位坐標點進行垂直劃分,將圖像平面的坐標點劃分為左、右兩個點集,按各個數據點遞歸進行左右子集空間劃分,同時記錄著每次劃分的節點,及各節點的父代節點,從而生成方便查找的k-d樹,直至生成包含空間中所需記錄的每一個像素點的k-d樹。將構建的k-d樹中沒有子節點的節點作為“葉子節點”進行記錄。將每一個節點進行保存,從而完成構建k-d樹。
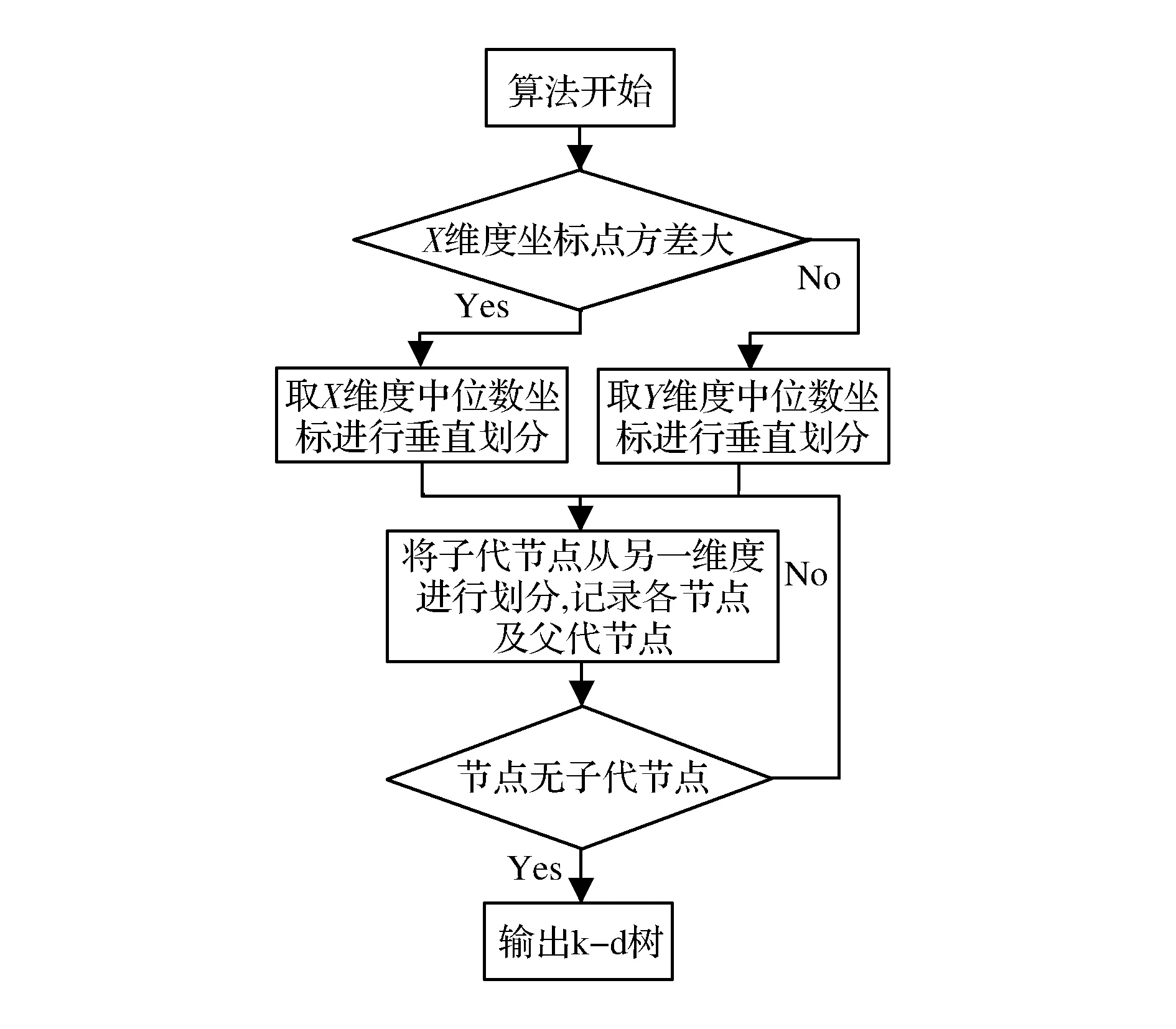
圖2 算法流程
4 深度圖像的高分辨率重構
通過構建好的k-d樹,查找到距離所需要計算的像素點最近的k-d樹節點(如圖3所示),再依據無人車場景中相似外表的區域具有相近的深度值的假設,通過R、G、B三通道的顏色信息相關性得到的權值,對沒有雷達數據的像素點進行插值,生成高分辨率的深度圖像。
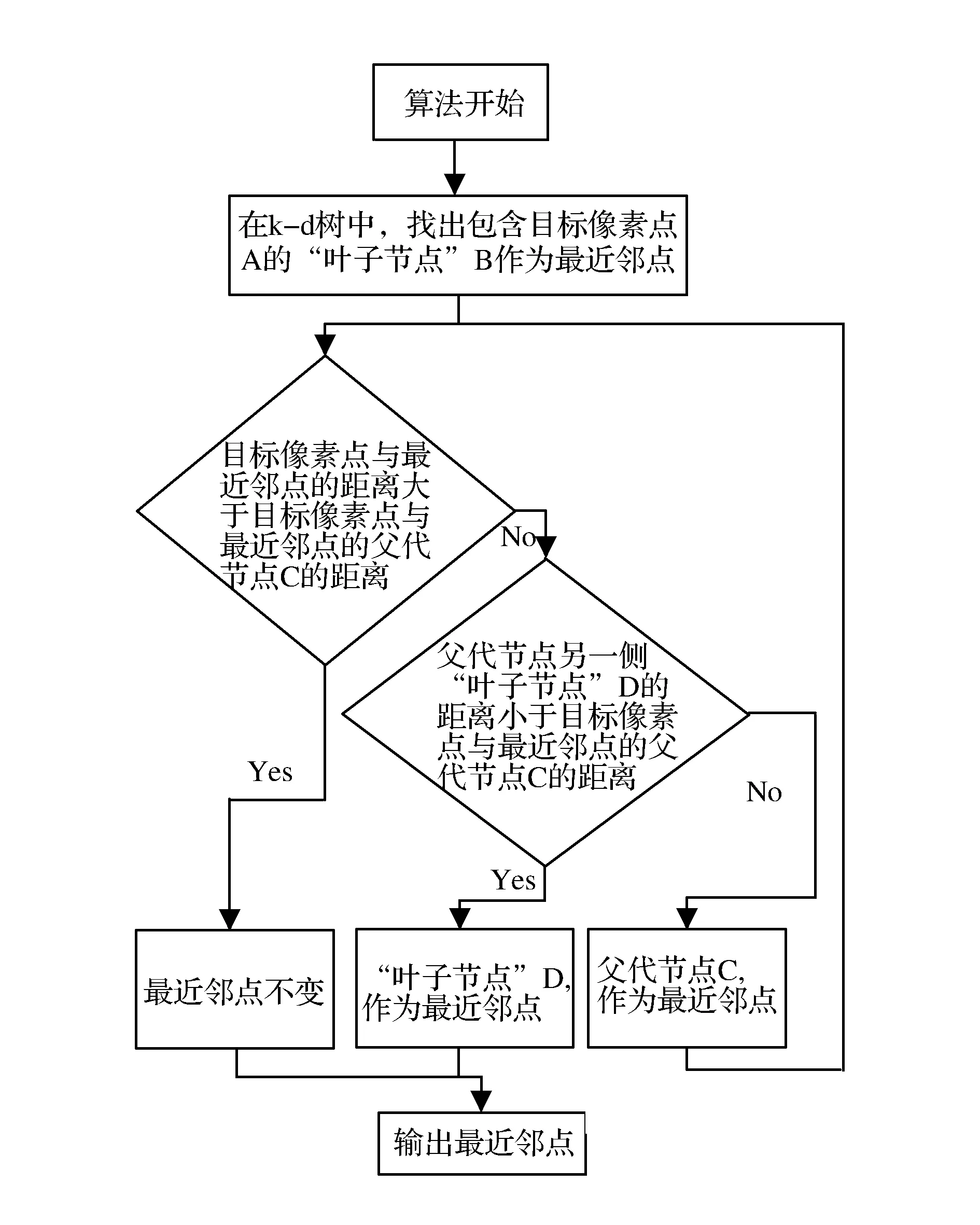
圖3 算法流程
在對圖像的深度信息進行插值的過程中,其使用的加權平均方式為
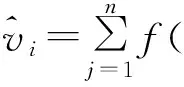
(4)
在求取深度信息的過程中,vj為鄰近像素點所代表的該點的深度值,p為基于相機顏色的描述符,函數f為
f(x)=e-|x|2/2σ2
(5)
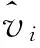
通過對圖像像素點進行插值重構后,生成高分辨率的深度圖像,如圖4所示。16 309個激光點云投影在圖像平面內,通過對圖像第4個深度通道的數據進行重構,圖像中564 589個像素點,得到其深度值,在寬1 624p、高350p的平面內覆蓋了99%以上,從而獲得相應高分辨率的深度圖像。
如圖4—6所示,圖像中的顏色隨著無人車場景深度的變化而變化。深度圖像的下半部分,距離無人車較近,生成深度圖像顏色較深。圖像6(c)下方已知深度的像素點多,因此能夠獲得較為準確的圖像深度信息,如圖像中的黑色區域。由圖像的下方向上,隨著無人車場景距離的增加,使得深度圖像深度值隨之增加,從而使得圖像的顏色也隨之變淺。而在中間部分,雷達已知的深度值的像素點較為密集,且雷達坐標系與相機坐標系標定良好,能夠獲得準確的圖像深度信息值,如圖6(c)中的灰色區域。在距離圖像較遠的場景中,激光點云稀疏,獲取的獨立于彩色圖像之外的圖像深度信息值較少,圖像遠距離的像素分辨率低,因此難以獲得遠距離的場景的準確深度信息,如圖6(c)的白色區域。如圖5(c)圖像中上部的黑色區域,超出了采集的雷達數據范圍,而無法產生深度信息,造成生成深度圖像數據缺失。
而對于深度連續的地面,本文方法能夠避免樹木的陰影造成的不良影響,如圖6(c)。雖然地面上存在著復雜的陰影,但是在深度圖像中,地面上的深度值是連續的,沒有受到陰影的影響而產生圖像不連續的變化。通過產生深度圖像,降低了場景中光照、陰影對無人車感知周圍場景的影響。

圖4 無人車場景圖像Ⅰ

圖5 無人車場景圖像Ⅱ

圖6 無人車場景圖像Ⅲ
5 結 語
本文通過將二維彩色圖像與激光點云進行融合,以及加權平均的方法,產生高分辨率的深度圖像。首先將無人駕駛實驗平臺安裝的64線激光雷達與彩色相機進行聯合標定,采集單幀的二維彩色圖片及前方6~60 m,左、右9 m的范圍內單圈的激光雷達點云數據,再通過對深度圖像的高分辨率重構,為無人車環境感知提供可靠的深度圖像。使用本方法,獲取深度值的圖像面積占整個圖像平面的99%以上,本方法通過獲取獨立于二維彩色圖像信息之外的場景深度信息,獲取高分辨率的場景深度圖像對周圍場景進行感知,降低無人車由于使用相機進行環境感知時光照及陰影造成的影響,方便無人車在感知過程中對場景中的物體進行識別與定位。但是依然存在深度信息會隨物體距離的增加而使得誤差增長的不足, 在接下來的工作需在現有工作的基礎上,調整攝像機焦距,增強雷達獲取的三維激光雷達深度信息映射到圖像平面在遠距離的準確性,從而處理得到更大范圍的深度圖像。
[1] THOMAS D, SUGIMOTO A.A flexible scene representation for 3D reconstruction using an RGB-D camera[C].Sydney:IEEE International Conference on Computer Vision,2013: 2800-2807.
[2] 李可宏,姜靈敏,龔永義.2維至3維圖像/視頻轉換的深度圖提取方法綜述[J].中國圖象圖形學報,2014,19(10):1393-1406.
[3] 劉三毛,朱文球,孫文靜,等.基于RGB-D單目視覺的室內場景三維重建[J].微型機與應用,2017(1):44-47.
[4] LEE K R,NGUYEN T.Realistic surface geometry reconstruction using a hand-held RGB-D camera[J].Machine Vision &Applications,2016,27( 3) : 377-385.
[5] KERL C, STURM J, CREMERS D.Dense visual SLAM for RGB-D cameras[C].Chiago:IEEE /RSJ International Conference on Intelligent Robots and Systems,2013:2100-2106.
[6] 李海軍,王洪豐,沙煥濱.平行雙目視覺系統的三維重建研究[J].自動化技術與應用,2007,26(6):56-58.
[7] 朱波,蔣剛毅,張云,等.面向虛擬視點圖像繪制的深度圖編碼算法[J].光電子·激光,2010(5):718-724.
[8] 張勤,賈慶軒.基于激光與單目視覺的室內場景三維重建[J].系統仿真學報,2014(2):357-362.
[9] 鄒廣群,張維忠,卞思琳.上采樣深度圖像與RGB圖像的融合[J].青島大學學報(自然科學版),2016(1):71-74.
[10] 楊宇翔,曾毓,何志偉,等.基于自適應權值濾波的深度圖像超分辨率重建[J].中國圖象圖形學報,2014,19(8):1210-1218.
[11] 彭誠,孫新柱.一種改進的深度圖像修復算法研究[J].重慶工商大學學報(自然科學版),2016(1):65-69.
[12] 劉嬌麗,李素梅,李永達,等. 基于TOF與立體匹配相融合的高分辨率深度獲取[J].信息技術,2016(12):190-193.
[13] 江文婷,龔小謹,劉濟林. 顏色指導的深度圖像升采樣算法的對比性研究[J].杭州電子科技大學學報,2014(1):21-24.
[14] KOPF J,COHEN MF,LISCHINSKI D,etal.Joint Bilateral Upsampling[J].Acm Trans Graph,2007,26(3):96.
[15] 邱茂林,馬頌德,李毅.計算機視覺中攝像機定標綜述[J].自動化學報,2000, 26(1):43-55.
(編輯:史海英)
AcquisitionMethodforVisionandLaser-pointCloudIntegratedRangeImage
WANG Dongmin1, PENG Yongsheng2, LI Yongle2
(1.Postgraduate Training Brigade, Army Military Transportation University, Tianjin 300161, China; 2.Military Vehicle Department, Army Military Transportation University, Tianjin 300161, China)
Since the unmanned vehicle is easily influenced by illumination and shadow while perceiving environment with camera, and it is difficult to acquire effective obstacles variety and location, the paper firstly acquires point cloud data in the range of 6~30 m ahead and 9 m at left and right with HDL-64E. Then, it arranges and interpolates three-dimensional laser-point cloud which maps to image with k-d tree, and integrates LIDAR data with image information. Finally, in order to solve the sparse depth information of the image after mapping, it obtains the range image of 1 624×350 by making fitting and interpolation on the sparse range image with the method of enriching radar point cloud by the texture information of two-dimensional image, which can provide accurate information of environment scenario for unmanned vehicle.
unmanned vehicle; vision; laser point cloud; range image
10.16807/j.cnki.12-1372/e.2017.10.019
TP391
A
1674-2192(2017)10- 0080- 05
2017-05-03;
2017-08-21.
國家重大研發計劃“智能電動汽車路徑規劃及自主決策方法”(2016YFB0100903);國家自然科學基金重大項目“自主駕駛車輛關鍵技術與集成驗證平臺”(91220301).
王東敏(1992—),男,碩士研究生;彭永勝(1972—),男,博士,教授,碩士研究生導師.
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中華手工(2017年2期)2017-06-06 23:00:31
新聞傳播(2015年10期)2015-07-18 11:05:40
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
