基于卷積神經網絡的面罩語音識別*
2017-11-01 07:19:14杜桂明王光艷
傳感器與微系統 2017年10期
關鍵詞:信號
王 霞, 杜桂明, 王光艷, 張 艷
(1.河北工業大學 電子信息工程學院,天津 300401; 2.天津商業大學 信息工程學院,天津 300134)
基于卷積神經網絡的面罩語音識別*
王 霞1, 杜桂明1, 王光艷2, 張 艷1
(1.河北工業大學電子信息工程學院,天津300401;2.天津商業大學信息工程學院,天津300134)
針對帶噪面罩語音識別率低的問題,結合語音增強算法,對面罩語音進行噪聲抑制處理,提高信噪比,在語音增強中提出了一種改進的維納濾波法,通過譜熵法檢測有話幀和無話幀來更新噪聲功率譜,同時引入參數 控制增益函數;提取面罩語音信號的Mel頻率倒譜系數(MFCC)作為特征參數;通過卷積神經網絡(CNN)進行訓練和識別,并在每個池化層后經局部響應歸一化(LRN)進行優化。實驗結果表明:該識別系統能夠在很大程度上提高帶噪面罩語音的識別率。
面罩語音識別; 卷積神經網絡; 語音增強; 維納濾波法
0 引 言
面罩語音識別有助于潛水人員的交流[1],近些年,深度神經網絡(deep neural network,DNN)在語音識別上顯示出了獨特的優勢。2012年,Ossama Abdel-Hamid等人通過研究發現,卷積神經網絡(convolutional neural network,CNN)相對于神經網絡(NN)和通過限制玻爾茲曼機(restricted Boltzmann machine,RBM)初始化權重的NN識別率較高[2]。2013年,Tara N Sainath等人通過比較CNN與DNN和高斯混合模型(Gaussian mixture model,GMM)的語音識別性能,得出了CNN在語音識別上有更好的性能[3]。2014年,Ossama Abdel-Hamid等人又對CNN進行了深入研究,得出了CNN相對于DNN性能有很大的提高[4]。2015年Takuya Yoshioka等人提出了CNN-DNN-HMM的模型來進行語音識別[5];張晴晴通過比較CNN的尺寸來分析CNN在語音識別方面的性能[6]。2016年,Qian Yanmin等人研究改變卷積層的數量、大小和池化層的尺寸等實現了錯詞率的下降,通過搭建與長短記憶—循環神經網絡(LSTM-RNN)相結合的模型,錯詞率也有所下降[7]。
實際中,淺海水聲通信通常會有海洋噪聲的干擾,導致語音識別的識別率嚴重下降,影響人機交互的正常進行。
本文設計了面罩語音識別系統,提出了一種改進的維納濾波算法對帶有海洋噪聲面罩語音增強,然后通過優化的CNN來進行面罩語音識別,與級聯譜減法和維納濾波法相比,該識別系統具有較好的識別效果。
1 CNN算法原理
CNN由輸入層、輸出層和中間的隱含層組成,中間的隱含層由多對卷積層、池化層交替組成。屬于多階段全局可訓練的神經網絡模型,主要有三個特征:局部接收域、全局共享和子采樣[8,9]。這些特征可以保證在輸入目標平移、縮放和扭曲一定程度上的不變性,結構如圖1所示。
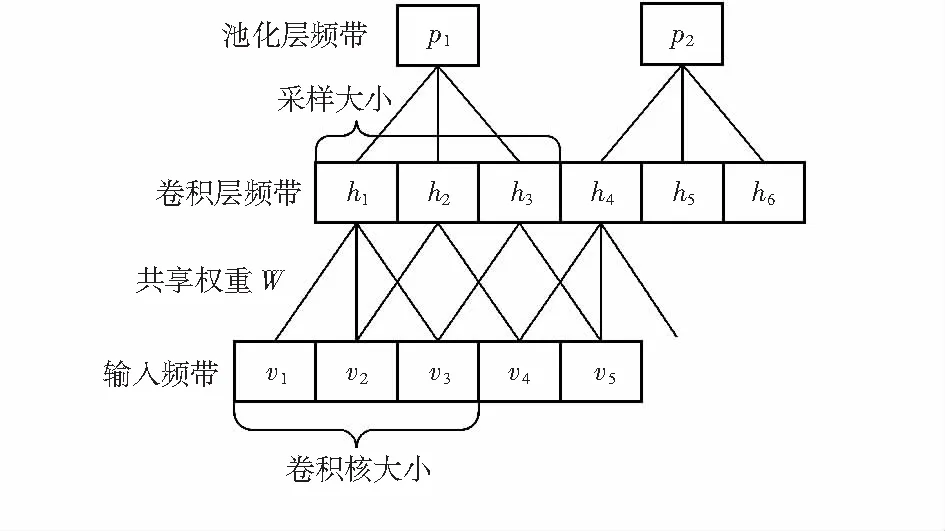
圖1 CNN的結構
假設語音信號作為輸入層且有B個頻帶,則有v=[v1v2…vb…vB],vb為頻帶b對應的特征矢量。卷積層的激活值被分為K個頻帶,每個頻帶包含J個濾波器激活值。假設每個頻帶定義為hk=[hk,1hk,2…hk,J],卷積層的激活值可以通過前一層的值與卷積核進行卷積運算得到
(1)
式中θ(x)為非線性激活函數,本文采用Relu函數;s為輸入層濾波器的大小;wb,j為對應的權重矢量。
假設池化層被劃分為M個頻帶,每個頻帶接收r個卷積層激活值,通常有最大值采樣和均值采樣,本文采用最大池化,對n個頻帶取最大值,則m個頻帶的激活值,定義為pm=[pm,1pm,1…pm,J]T計算過程如下
pm,j=max(hm×n+k,j)
(2)
式中k從1到r,r為采樣的大小。輸入層到卷積層中間有多個卷積核,可以在卷積層得到相同數量的特征圖,采樣層是對卷積層的采樣,因此,特征圖的大小會改變而數量不會改變,交替進行,再加一個全連接層,最后由分類器輸出結果。輸出的結果與對應的標簽比較,通過反向傳播算法,調整權值,使之最佳,最終得到性能最好的神經網絡。
2 基于CNN的面罩語音識別
2.1 算法整體流程
整體算法流程如圖2所示。
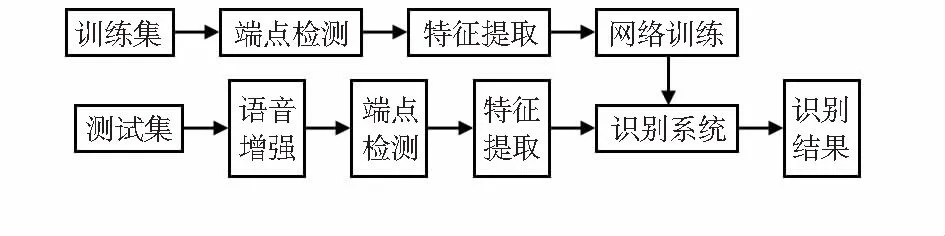
圖2 整體算法流程
算法分為2個階段:訓練階段和識別階段。前者利用未帶噪聲的面罩語音來訓練CNN;后者對帶噪的面罩語音進行識別。首先對測試集的面罩語音進行增強處理,抑制海洋噪聲,然后分別對訓練集和測試集進行端點檢測,本文采用雙門限法,對檢測到的有話段提取Mel頻率倒譜系數(Mel frequency cepstrum coefficient,MFCC)作為訓練網絡和測試網絡的輸入。
2.2 面罩語音增強
2.2.1譜減法
譜減法[10]的基本原理如圖3所示。先對語音信號進行快速傅里葉變換(fast Fourier transform,FFT),將語音信號轉換到頻域,計算語音信號的功率譜并根據語音信號前導無音段估計噪聲的平均功率譜,那么用語音信號的功率譜減去噪聲的功率譜,得到干凈語音信號的功率譜,最后根據保留的相角,用快速傅里葉逆變換(inverse FFT,IFFT)合成時域的語音信號,即增強后的語音信號。
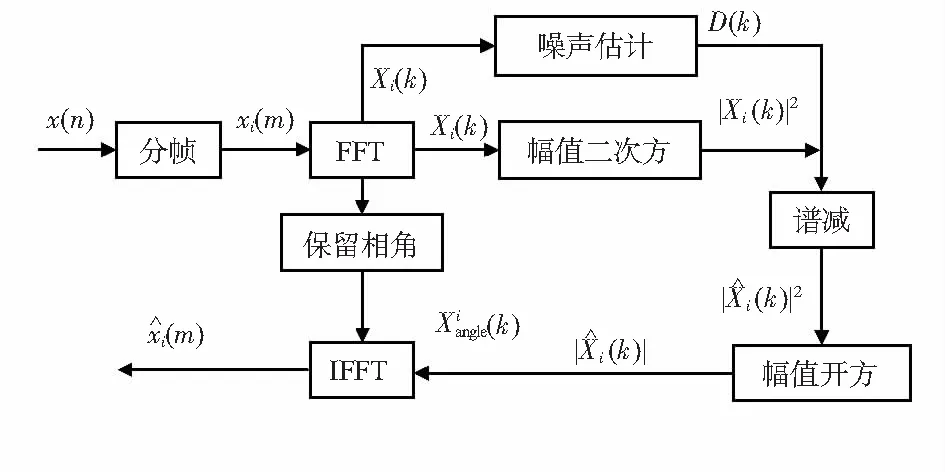
圖3 譜減算法基本原理
2.2.2維納濾波算法
假設語音信號為
y(n)=s(n)+d(n)
(3)
式中s(n)為語音信號;d(n)為噪聲信號;經FFT后,語音信號由時域變換到頻域,因此有
Yi(k)=Si(k)+Di(k)
(4)
維納濾波法[11]濾波器的增益函數為
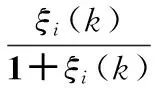
(5)
式中ξi(k)為先驗信噪比。則增強后的語音為
(6)
2.2.3譜熵法
假設語音信號為s(n),加窗分幀后得到第i幀語音信號為Si(m),經過FFT后,第k條線譜線頻率分量fs的能量譜為Yi(k),則每個頻率分量的歸一化概率密度為
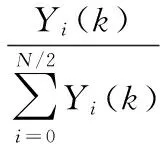
(7)
式中N為FFT的長度,則每個語音幀的短時譜熵
(8)
根據最大離散定理可知,等概率分布時熵達到最大值,對于噪聲來說,歸一化譜概率密度分布比較均勻,譜熵[12]值相對于語音比較大,因此,可以利用這個特性進行端點檢測,進而判斷有話幀和無話幀。
2.2.4改進的維納濾波算法
通過譜熵法檢測無話幀,更新噪聲的功率譜,引入參數 來控制增益函數,減少語音信號的失真。
1)根據無話段估計噪聲的平均功率譜作為初始值,NIS為前導無話段幀數
(9)
2)通過譜熵法端點檢測判斷有話幀和無話幀,對于無話幀,更新噪聲功率譜;對于有話幀,先計算其后驗信噪比
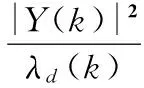
(10)
3)根據后驗信噪比計算其先驗信噪比
(11)
式中α為平滑參數。
4)求增益函數Gi(k)。為減少語音失真,引入增益函數控制參數β,此時的增益函數為
(12)
隨著β的增大,在減少噪聲的同時,也會引入語音的失真,通過多次實驗優化參數β,本實驗β取值2/3。
2.3 特征參數提取
特征參數采用語音信號的美爾頻率倒譜系數,基于人耳的聽覺特性,將語音信號的頻譜轉換到感知域中,能更好模擬人的聽覺機理。本文取美爾頻率倒譜系數和一階對數能量譜及其一階差分系數和二階差分系數,即每幀語音信號的維數為39維。
2.4 改進的CNN
本文的CNN結構為:不包括輸入層在內,采用了6層的CNN,前4層為卷積層和池化層交替進行,卷積核的大小為5×5,池化的大小為2×2,特征圖的個數分別為10和20個,在每個池化層后增加了局部響應歸一化(local response normalization,LRN)處理優化神經網絡,接著是全連接層和輸出層,輸出層采用Softmax分類器。其中LRN模仿生物神經系統的“側抑制”機制,對局部神經元的活動創建競爭環境,使得其中較大的值變得更大,并抑制其他值較小的神經元,增強整個神經網絡的泛化能力。CNN的訓練過程如下:
1)神經網絡的前向傳播,并計算出傳播過程中L2,L3,…,Lnt各層節點的激活。
2)對于最后一層輸出層,計算輸出值和樣本的殘差
δ(nt)=-(y-a(nt))·f′(z(nt))
(13)
3)對于中間的隱含層,計算各個節點的殘差
δ(l)=-((wl)Tδ(l+1))·f′(zl)
(14)
4)計算最終需要的偏倒數
(15)
(16)
5)使用梯度下降法,對網絡的參數w和b進行調整
(17)
(18)
使用梯度下降法調節神經網絡結構參數的目的為使代價函數獲得最小值,能得到性能最佳的神經網絡結構代價函數的定義為
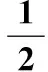
(19)
全體代價函數的定義為
(20)
3 實驗結果與分析
3.1 仿真平臺搭建
實驗仿真的平臺為谷歌的TensorFlow深度學習框架,實驗面罩語音采用10個同學(4個男生,6個女生)錄制的20個孤立詞,共1400個面罩語音作為實驗的語音,其中,1000個作為訓練集,剩下的400個作為測試集。面罩語音為單聲道、采樣頻率為16000Hz,編碼數16bit,幀長為25ms,幀移為10ms,提取語音信號的Mel頻率倒譜系數作為特征參數。
3.2 仿真結果與分析
3.2.1面罩語音增強結果與分析
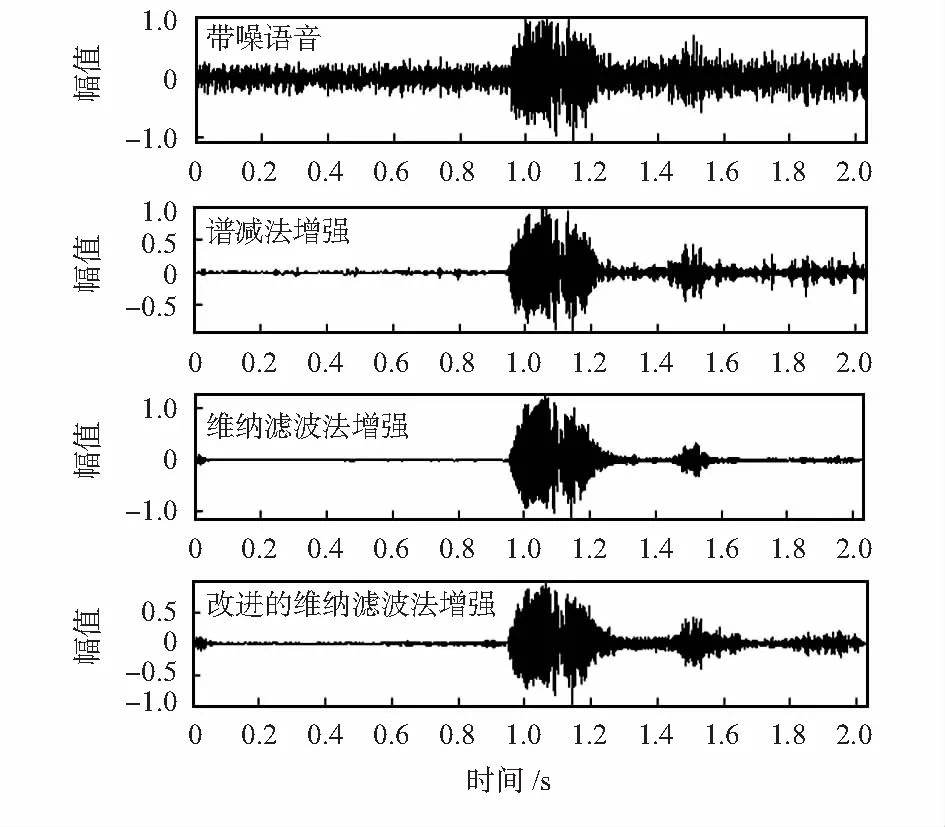
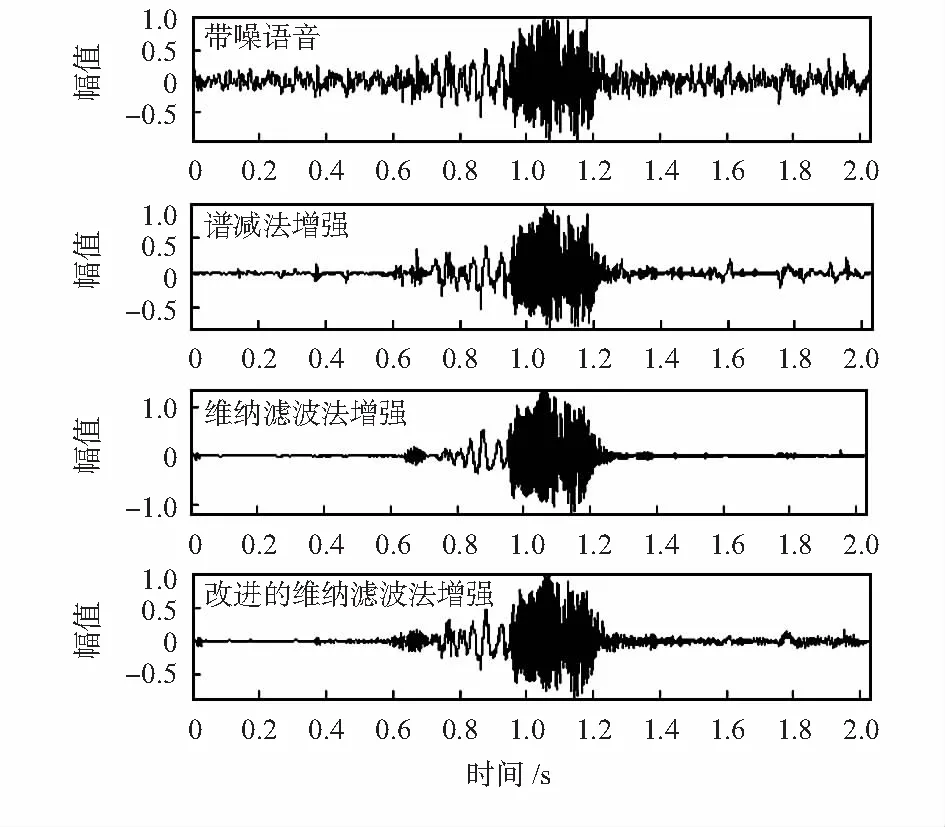
先對面罩語音進行增強處理,分別用譜減法和維納濾波法對添加不同信噪比(-5,0,5,10dB)海浪和海水噪聲的面罩語音增強。圖4給出了原始語音信號的時域波形,圖5給出了海浪和海水噪聲干擾下,譜減法、維納濾波法和本文方法時域波形,信噪比為0dB。
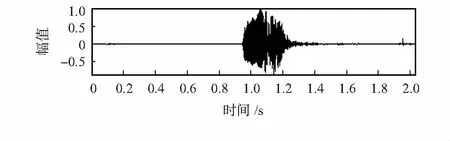
圖4 原始語音
(a) 海浪
(b) 海水圖5 海浪和海水噪聲環境下增強后波形
從圖5中可以看出,譜減法在增強過程中,會產生明顯的音樂噪聲,維納濾波法在對海浪噪聲干擾下的面罩語音增強過程中會產生輕微的失真,改進的維納濾波法相對于譜減法音樂噪聲減小,相對于維納濾波法失真減小。
3.2.2面罩語音識別結果與分析
實驗分別用傳統和增加了LRN處理的CNN對未加噪聲的面罩進行訓練和識別。針對本實驗錄制的面罩語音,2種算法均能夠實現較高的識別率,未加LRN處理的識別率為98%,加LRN處理后的識別率為98.50%,結果表明優化的可行,且相對于不加LRN處理的識別率有所提高。
測試本文設計的識別系統,其中SS代表譜減法,WF代表維納濾波法,IWF代表改進的維納濾波法,CNN代表已經優化的CNN。表1和表2分別給出了本文算法對于添加不同信噪比海浪噪聲和海水噪聲面罩語音的識別率。
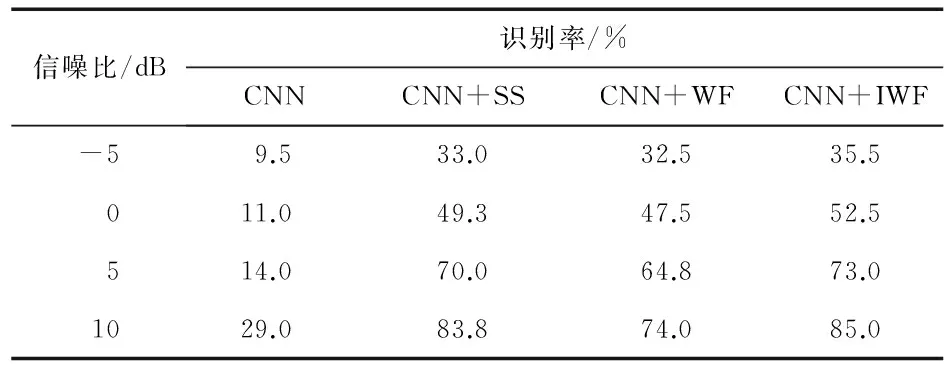
表1 添加海浪噪聲4種方法的識別率
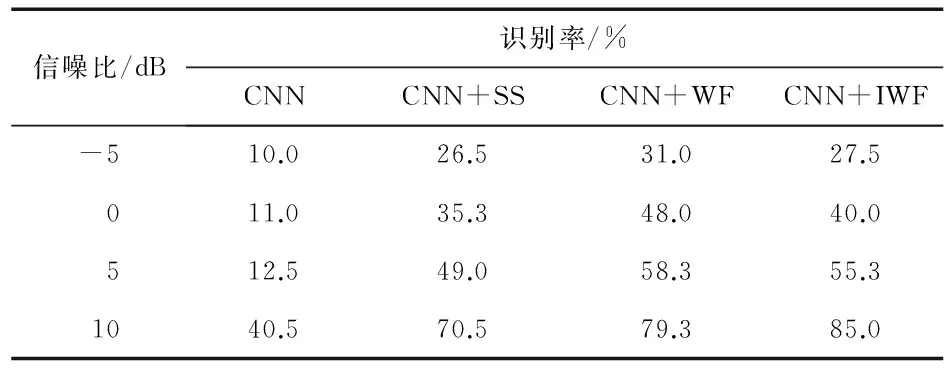
表2 添加海水噪聲4種方法的識別率
由數據可以看出,只用CNN識別在低信噪比的情況下識別率非常低,隨著信噪比的提高識別率會有所提高。即在海洋背景噪聲大的情況下,面罩語音識別的性能很差。本文系統能夠顯著提高面罩語音的識別率。
4 結束語
本文提出了一種結合語音增強算法與優化的卷積神經網絡的面罩語音識別方法,通過在池化層后做局部響應歸一化處理,提高了卷積神經網絡的泛化能力,實驗結果表明,該系統能夠在很大程度上提高帶有不同信噪比海洋噪聲的面罩語音識別率,本文提出的語音增強算法與CNN相結合的方法對帶噪面罩語音的識別效果更好。在低信噪比下,面罩語音識別率雖然有較大提高,但總體識別率仍然有待提高。
[1] 楊士莪.研究海洋 開發海洋——海洋環境及海洋資源調查、監測技術概述[J].艦船科學技術,2008,30(5):17-19.
[2] Abdel-Hamid O,Mohamed A R,Jiang H,et al.Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition[C]∥IEEE International Conference on Acoustics,Speech and Signal Processing,IEEE,2012:4277-4280.
[3] Sainath T N,Mohamed A R,Kingsbury B,et al.Deep convolutio-nal neural networks for LVCSR[C]∥IEEE International Confe-rence on Acoustics,Speech and Signal Processing,IEEE,2013:8614-8618.
[4] Abdel-Hamid O,Mohamed A R,Jiang H,et al.Convolutional neural networks for speech recognition[J].IEEE/ACM Transactions on Audio Speech & Language Processing,2014,22(10):1533-1545.
[5] Yoshioka T,Karita S,Nakatani T.Far-field speech recognition using CNN-DNN-HMM with convolution in time[C]∥IEEE International Conference on Acoustics,Speech and Signal Processing,IEEE,2015:4360-4364.
[6] 張晴晴,劉 勇,潘接林,等.基于卷積神經網絡的連續語音識別[J].工程科學學報,2015,37(9):1212-1217.
[7] Qian Y,Woodland P C.Very deep convolutional neural networks for robust speech recognition[C]∥IEEE Global Conference on Signal and Information Processing,IEEE,2016:481-488.
[8] Huang J T,Li J,Gong Y.An analysis of convolutional neural networks for speech recognition[C]∥IEEE International Conference on Acoustics,Speech and Signal Processing,IEEE,2015:4989-4993.
[9] 張 軍,張 婷,楊正瓴,等.深度卷積神經網絡的汽車車型識別方法[J].傳感器與微系統,2016,35(11):19-22.
[10] 宋知用.Matlab在語音信號分析與合成中的應用[M].北京:北京航空航天大學出版社,2013.
[11] Cheng C.Research on speech enhancement based on Wiener filtering[J].Applied Mechanics & Materials,2014,513-517:3130-3133.
[12] 杜志然,周 萍,景新幸,等.基于譜熵的耳語音增強研究[J].傳感器與微系統,2012,31(6):69-72.
Maskspeechrecognitionbasedonconvolutionalneuralnetwork*
WANG Xia1, DU Gui-ming1, WANG Guang-yan2, ZHANG Yan1
(1.SchoolofElectronicandInformationEngineering,HebeiUniversityofTechnology,Tianjin300401,China;2.SchoolofInformationEngineering,TianjinUniversityofCommerce,Tianjin300134,China)
Aiming at problem of low mask speech recognition rate of noise mask speech,mask speech recognition method based on improved convolutional neural network(CNN) is proposed.Combine speech enhancement algorithm to suppress noise of mask speech and increase signal-to-noise ratio(SNR).An improved Wiener filtering algorithm is proposed for speech enhancement.Using spectral entropy algorithm to detect the frame which has speech to update noise power spectrum.At the same time,introducing parameterβto control gain function.Extract Mel frequency cepstrum coefficient(MFCC) as characteristic parameters.Use CNN for training and recognization.The CNN includes two convolution layers,two pooling layers,one fully connected layer and a softmax classifier.And add local response normalization(LRN) after every pooling layer to optimize CNN.The experimental results show that the recognition system can greatly improve the recognition rate of noisy mask speech.
mask speech recognition; convolutional neural network(CNN); speech enhancement; Wiener filtering algorithm
2017—08—30
天津市自然科學基金重點資助項目(14JCZDJC32600)
10.13873/J.1000—9787(2017)10—0031—04
TN 912
A
1000—9787(2017)10—0031—04
王 霞(1970-),女,博士,教授,碩士生導師,研究領域為計算機視覺、語音信號處理,E—mail:wangx@hebut.edu.cn。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
