基于稀疏表示的醫學圖像融合*
2017-11-01 07:19:13邱紅梅李華鋒余正濤
傳感器與微系統 2017年10期
邱紅梅, 李華鋒, 余正濤
(昆明理工大學 信息工程與自動化學院,云南 昆明 650500)
基于稀疏表示的醫學圖像融合*
邱紅梅, 李華鋒, 余正濤
(昆明理工大學信息工程與自動化學院,云南昆明650500)
針對傳統基于K階奇異值分解 (KSVD)的字典學習算法時間復雜度高,學習字典對源圖像的表達能力不理想,應用于醫學圖像融合效果差的問題,提出了一種新的字典學習方法:在字典學習之前對醫學圖像的特征信息進行篩選,選取能量和細節信息豐富的圖像塊作為訓練集學習字典;根據學習得到的字典建立源圖像的稀疏表示模型,運用正交匹配追蹤算法(OMP)求解每個圖像塊的稀疏系數,采用“絕對值最大”策略構造融合圖像的稀疏表示系數,最終得到融合圖像。實驗結果表明:針對不同的醫學圖像,提出的方法有效。
稀疏表示; 字典學習; 醫學圖像融合; 正交匹配追蹤
0 引 言
圖像融合技術已經廣泛地應用到各個領域[1~4]。其中,稀疏表示因能更為稀疏地表示圖像的奇異信息,而得到眾多關注[5~7]。在基于稀疏表示(sparse representation,SR)的圖像融合中,字典的選擇是影響融合性能的關鍵因素之一。在醫學圖像融合方面,提出了很多有效的字典學習方法。Liu Y等人[8]提出了一種基于自適應稀疏表示的多源圖像融合算法,并成功應用于醫學圖像融合中,根據訓練集圖像塊的梯度方向直方圖的主方向對其進行分類,再對每一類圖像塊分別訓練字典。在融合過程中,根據源圖像塊梯度方向直方圖主方向自適應地選擇所在類的字典。Zhu Z Q等人[9]提出了一種基于采樣和聚類的醫學圖像融合算法,通過對圖像塊采樣獲得信息豐富的塊,并對其聚類,最后,利用K階奇異值分解(Korder singular value decomposition,KSVD)算法得到每一類的子字典。這些方法雖然能得到較好的融合效果,但在字典學習過程中仍面臨著學習速度慢的缺陷,而字典表達能力也有很大的提升空間。
針對以上缺陷,本文結合人眼視覺系統對圖像質量的感知特性,提出了一種新的字典學習方法,并利用學習的字典對醫學圖像進行融合。
1 SR理論
SR理論的主要思想是目標信號能夠由少量信號的線性組合來表示[10]。假設目標信號y∈Rm,則信號向量可以被分解成k個m維向量di∈Rm的線性組合k>m如下
(1)
式中 列向量di為原子,所有原子構成的矩陣D=[d1,d2,…,dk]稱為字典或庫。由于k?m,因此,字典D是過完備的。求解在過完備字典D下的稀疏表示系數α是一個稀疏編碼問題,在實際情況中,該稀疏編碼問題可如下表示
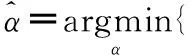
(2)
上述問題一般可用貪婪算法和全局優化算法來求解。在基于稀疏表示的圖像融合算法中,常用的稀疏優化方法包括匹配追蹤算法(matching pursuit,MP)和正交匹配追蹤算法(orthogonal matching pursuit,OMP)。
2 提出的融合方法
2.1 字典構建
為提升字典的表達能力,本文針對醫學圖像融合問題[11],提出了利用源圖像中反映亮度的能量信息和反映邊緣細節變化的空間頻率信息來構建超完備字典,字典學習的流程如圖1所示。
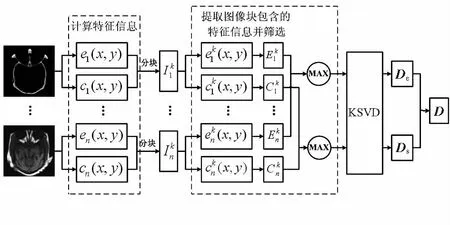
圖1 字典學習流程
考慮到圖像的鄰域內像素具有較強的相關性,采用像素的鄰域能量信息來度量該像素點的亮度。具體地,像素點(x,y)的鄰域能量特征計算式如下
(3)
式中I(x+p,y+q)為源圖像I在(x+p,y+q)處的像素值;P×Q為預設的鄰域窗口大小;(x+p,y+q)為以(x,y)為中心的鄰域窗口內任一像素點。
采用像素的空間頻率信息反映圖像邊緣細節信息的變化,其定義如式(4)所示
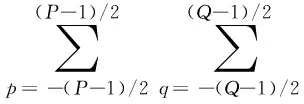
(4)
對每個待融合的源圖像分割成相互重疊的圖像塊,分割結果如下
(5)
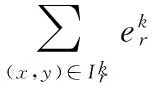
(6)
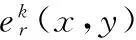
(7)
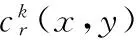
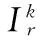
(8)
式中Xe為篩選的能量信息最豐富的圖像塊組成的訓練集。ik定義如下
(9)
利用KSVD算法對訓練集Xe進行學習得到能量字典

(10)
同理,選取包含邊緣細節信息最豐富的圖像塊構造細節信息字典
(11)
式中Xs為篩選的邊緣細節信息最豐富的圖像塊組成的訓練集;為了不讓Xs與Xe重疊,jk定義為
(12)
利用KSVD算法對訓練集Xs進行學習得到邊緣細節信息字典
(13)
由此,綜合能量信息和邊緣細節信息的字典如式(14)
D=[De,Ds]
(14)
本文訓練得到的字典如圖2(c)所示。對比圖2(a)傳統KSVD算法學習的字典和圖2(b)文獻[12]提出的聯合聚類算法學習的字典,本文方法得到的字典包含了更加豐富的特征信息,原子對比度也更高,具有更強的表達能力。

圖2 不同方法構建的字典視覺效果
2.2 融合算法
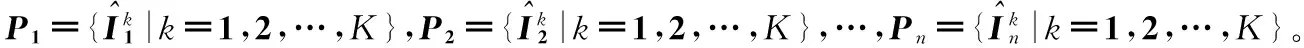
(15)
最后利用字典和融合圖像的稀疏表示系數,根據式(16)對融合圖像塊向量進行重構,得到第k塊融合圖像的列向量
(16)
通過式(17)對所有的融合圖像塊進行重構,然后將重構圖像塊矩陣化得到最終的融合圖像
(17)

圖3 本文提出算法的融合流程
在訓練子塊數量和時間消耗上,圖4(a)、圖(b)源圖像為例,傳統的KSVD字典學習方法(子塊不經過篩選)需訓練31250個子塊,字典訓練耗時713s,而本文提出的字典學習方法(子塊經過篩選)只需訓練21050個子塊,字典訓練耗時679s,從中也可以看出,本文提出的字典學習方法在訓練量和訓練時間上均有所改進。
3 實驗分析
為客觀地評價方法的融合性能,采用互信息[13](mutual information,MI)、邊緣信息度量算子[14](edge information preservation values,QAB/F) 和視覺信息保真度[15](visual information fidelity ,VIF)3個客觀評價指標對不同算法下的融合結果進行度量,數值越大說明融合效果越好。
文采用了離散小波變換(discrete wavelet transform,DWT)、非下采樣輪廓波變換 (nonsubsampled contourlet transform,NSCT)、 非下采樣輪廓波變換和SK相結合的方法[16](nonsubsampled contourlet transform-sparse representation,NSCT-SR)、聯合塊聚類[12](joint patch clustering based dictionary,JCPD)、自適應SR[8](adaptive sparse representation,ASR)等5個不同融合算法與本文算法進行對比。實驗中,本文方法的圖像塊大小為8×8,求鄰域能量和清晰度信息所用的鄰域窗口大小為P×Q=5×5,重疊像素為6,稀疏表示的重構誤差為0.1。
實驗的兩組CT/MRI醫學圖像及不同方法產生的融合結果分別如圖4和圖5所示。從中可以看出,DWT得到的融合圖像對比度較低,容易出現偽影現象;NSCT在很大程度上克服了DWT的不足,但融合規則過于簡單,導致融合圖像的對比度不高,視覺效果較差。JCPD和ASR得到的融合圖像對比度雖有所提升,但細節信息不夠清晰,仍不利于人眼的觀察和醫療診斷。相比之下,NSCT-SR方法和本文算法在對比度上均取得了很好的效果。但從融合結果的局部放大區域可以看出,源圖像中的部分有用信息沒有被NSCT-SR方法保留到融合結果中,而本文方法卻能有效避免這一缺陷。此外,表1給出了2組CT/MRI圖像在不同算法下的融合圖像的客觀評價數據,從中可以看出,本文算法在3個客觀評價指標上均高于其他方法,客觀上也證明了本文算法優于其他方法。
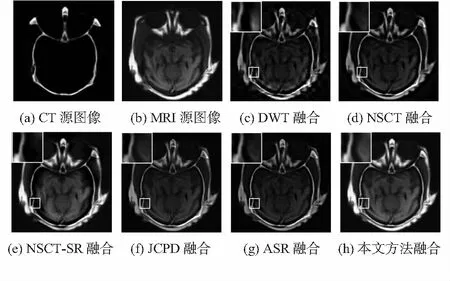
圖4 不同方法獲得融合結果比較
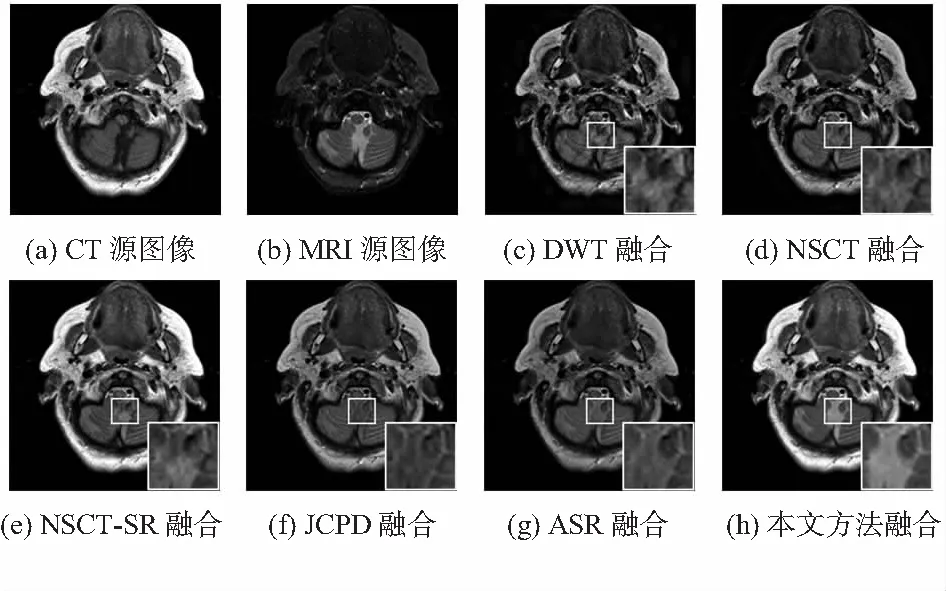
圖5 不同方法獲得融合結果比較
為進一步證明本文方法對其他類型的圖像同樣有效,圖6給出了PET/MRI醫學圖像在不同算法下的融合結果,客觀評價數據如表1中的圖6列所示。也可以看出,本文算法具有一定的適用性。
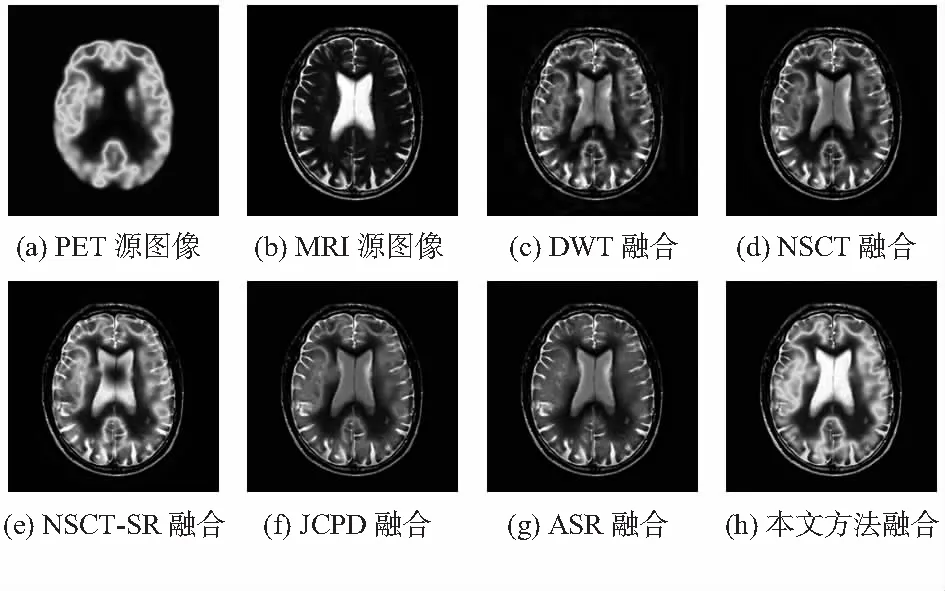
圖6 PET/MRI在不同方法下的融合結果比較
4 結束語
針對醫學圖像融合,提出了一種新的超完備字典構建方法,并利用該字典對醫學圖像進行了融合實驗。結果表明:本文方法訓練得到的字典能有效提升字典的表達能力,同時,克服了傳統字典學習算法中圖像塊數量較多,字典學習效率較低的缺陷。在融合圖像的視覺效果和客觀評價指標上,本文算法均優于其他傳統圖像融合算法以及最新的基于SR的融合方法。在今后的研究中,重點將進一步優化字典學習方法,增強字典的適應性。
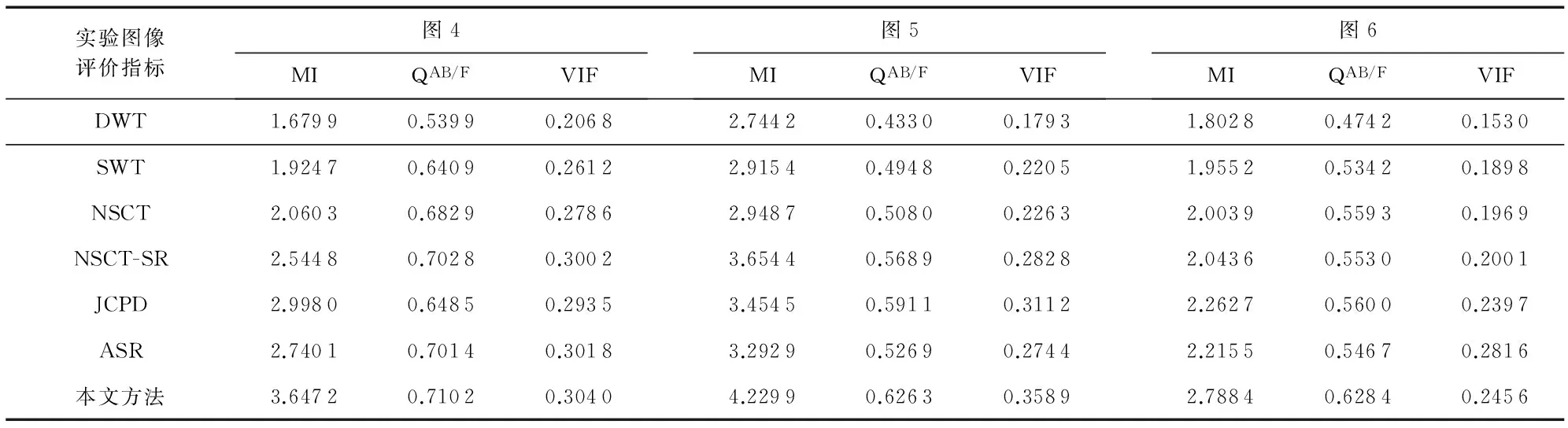
表1 不同方法在融合3組醫學圖像時的客觀評價結果比較
[1] 林玉池,周 欣,宋 樂,等.基于 NSCT 變換的紅外與可見光圖像融合技術研究[J].傳感器與微系統,2008,27(12):45-47.
[2] 朱 煉,孫 楓,夏芳莉,等.圖像融合研究綜述[J].傳感器與微系統,2014,33(2):14-18.
[3] 何國棟,石建平,馮友宏,等.一種新的紅外與可見光圖像融合算法[J].傳感器與微系統,2014,33(4):139-141.
[4] 張明源,王宏力,陳國棟.基于小波分析的多源圖像融合去云技術研究[J].傳感器與微系統,2007,26(11):19-21.
[5] Yin H T.Sparse representation with learned multiscale dictionary for image fusion[J].Neurocomputing,2015,148(19):600-610.
[6] Liu Y,Liu S P,Wang Z F.A general framework for image fusion based on multi-scale transform and sparse representation[J].Information Fusion,2015,24:147-164.
[7] Li S T,Yin H T,Fang L Y.Group-sparse representation with dictionary learning for medical image denoising and fusion[J].IEEE Transactions on Biomedical Engineering,2012,59(12):3450-3459.
[8] Liu Y,Wang Z F.Simultaneous image fusion and denoising with adaptive sparse representation[J].IET Image Processing,2015,9(5):347-357.
[9] Zhu Z Q,Chai Y,Yin H P.A novel dictionary learning approach for multi-modality medical image fusion[J].Neurocomputing,2016,214:471-482.
[10] 張賢達.矩陣分析與應用[M].2版.北京:清華大學出版社,2013:78-82.
[11] Elan M,Yavnef I.A plurality of sparse representations is better than the sparsest one alone[J].IEEE Transactions Information Theory,2009,55(10):4701-4714.
[12] Kim M,Han D K,KO H,et al.Joint patch clustering-based dictionary learning for multimodal image fusion[J].Information Fusion,2016,27:198-214.
[13] Qu G H,Zhang D L,Yan P F.Information measure for performance of image fusion[J].Electronics Letters,2002,38 (7):313-315.
[14] Xydeas C S,Petrovic V.Objective image fusion performance measure[J].Electronics Letters,2000,36(4):308-309.
[15] Sheikh H R,Bovik A C.Image information and visual quality[J].IEEE Transactions on Image Processing,2006,15 (2):430-444.
[16] Liu Y,Liu S P,Wang Z F.A general framework for image fusion based on multi-scale transform and sparse representation[J].Information Fusion,2015,24:147-164.
Medicalimagefusionbasedonsparserepresentation*
QIU Hong-mei, LI Hua-feng, YU Zheng-tao
(FacultyofInformationEngineeringandAutomation,KunmingUniversityofScienceandTechnology,Kunming650500,China)
In the traditional K order singular value decomposition (KSVD)-based methods,the dictionary learning process is time-consuming and the learned dictionary can’t represent the source images well.Therefore,a novel dictionary learning method is proposed for the medical images fusion problem.In which,these image blocks with rich energy feature and detail information are firstly filtrated to form the training set and the dictionary is learned from the training set.Next,the sparse model is constructed according to the learned dictionary and the sparse coefficients are solved by the orthogonal matching pursuit(OMP) algorithm.Finally,the ‘max absolute’ rule is employed to obtain the fused coefficient and the final fused image is obtained. The experiment has verified that the proposed method is effective for different medical images.
sparse representation(SR); dictionary learning; medical image fusion; orthogonal matching pursuit (OMP)
10.13873/J.1000—9787(2017)10—0057—04
2016—09—12
國家自然科學基金資助項目(61302041,61562053,61363043);云南省科技廳應用基礎研究計劃基金資助項目(2013FD011)
TP 391
A
1000—9787(2017)10—0057—04
邱紅梅(1990-),女,碩士研究生,CCF會員,主要研究方向為圖像處理。李華鋒(1983-),男,通訊作者,博士,副教授,主要從事計算機視覺、模式識別、數字圖像處理研究工作,E—mail: 1175266310@qq.com。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
