海量數據干擾下冗余數據高性能消除方法*
2017-11-14 08:20:27新鄉學院計算機與信息工程學院河南新鄉453003吉林省質監檢測基地吉林省纖維檢驗處長春3003
沈陽工業大學學報 2017年6期
茹 蓓, 李 虹(. 新鄉學院 計算機與信息工程學院, 河南 新鄉 453003; . 吉林省質監檢測基地 吉林省纖維檢驗處, 長春 3003)
控制工程
海量數據干擾下冗余數據高性能消除方法*
茹 蓓1, 李 虹2
(1. 新鄉學院 計算機與信息工程學院, 河南 新鄉 453003; 2. 吉林省質監檢測基地 吉林省纖維檢驗處, 長春 130103)
針對海量數據處理過程中大量相似特征會給數據分類造成冗余干擾,在分類中心確定時出現多次校驗、重復等弊端,提出一種海量數據干擾下冗余數據高性能消除方法.采用主動采樣方法提取海量數據干擾下冗余數據特征,并對其進行分類.引入均值漂移傳遞函數對冗余數據進行分類處理,獲取冗余數據活躍程度,實現冗余數據的高性能消除.結果表明,相比傳統的消除方法,高效消除方法性能良好,所需時間短,具有一定的優越性.
海量數據; 干擾; 冗余數據; 高性能; 消除方法; 改進; 均值; 傳遞函數
隨著計算機技術與信息處理技術的快速發展,許多領域的信息被儲存在計算機系統中,形成海量數據,使得其存儲和管理成為相當棘手的問題[1-2].雖然如今存儲設備容量越來越大,但也無法滿足處理數據量的增長需要[3-4],形成了大量的冗余數據.而對冗余數據進行高效消除、減輕數據存儲負擔、提高數據存儲效率成為了近年來信息處理技術的研究熱點,受到廣大學者的廣泛關注,也出現了很多有效方法[5-7].
文獻[8]提出局部均值分解的消除方法,采用數值模擬把線性、多項式及指數趨勢項融入至要消除的數據中進行消除,該方法可對冗余數據進行消除,但消除過程需要一定約束條件;文獻[9]提出規則分段技術法,把多個冗余數據進行消除,但該方法只能應用到小聚類環境中;文獻[10]提出一種基于均值分解的消除方法,在CPU里設定一個特別的任務切換專用數據鏈路,實現在CPU硬件資源限制狀態時進行數據存儲,引入Hyper-Scheduling法對冗余數據進行消除,但是該方法誤差較大.
針對上述問題的產生,本文提出一種新的海量數據干擾下冗余數據高性能消除方法,采用主動采樣方法提取數據特征,并引入均值漂移傳遞函數對冗余數據進行分類,相比傳統的消除方法具有一定的優越性.
1 海量數據干擾下冗余數據分類
由于海量數據的相似特征容易造成循環分類、多次處理等問題,因此,需要專門針對相似性干擾提取冗余數據特征,并根據特征對冗余數據進行分類,加快消除速率.
1.1 冗余數據特征獲取
海量數據在特征相似的環境下,會形成冗余干擾,在進行冗余數據分類之前,采用主動采樣方法提取海量數據冗余數據特征.
假設最初訓練數據集的全部樣本數是N,大類樣本數為Nmax,小類樣本數為Nmin,則當大類樣本數大于小類樣本數據,即Nmax>Nmin,對小類中每個樣本的分類密度ρl定義為
ρl=Ml/K(l=1,2,…,Nmin)
(1)
式中:K為空間中基于歐式距離的最近鄰數目;Ml為K個最近鄰數目中屬于大類的樣本數.很明顯,ρl∈[0,1],其密度分布表達式為
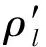
(2)
假設對p個樣本的第j個輸出值和目標值分別是ypj(τ)和dpj,則特征提取約束條件為
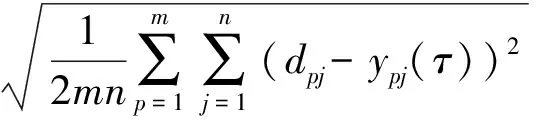
(3)
式中:τ為迭代數目;n為輸出數據量;m為最后訓練數據集的數量.分類迭代次數表達式為
w(τ+1)=w(τ)+ηΔw(τ)+α(w(τ)-
w(τ-1))
(4)
式中:η為迭代速率;α為動量因子.此時提取過程收縮量為
(5)
式中:φpj(τ)為輸入量總和;o(τ)為冗余數據輸出量.在此基礎上,提取海量數據干擾下冗余數據特征.
假設有一個標準的樣本數據集Nh,激勵函數為g(x),采集的樣本數為Ns,樣本為(xq,tq),其中xq=[xq1,xq2,…,xqn]T∈Rn且tq=[tq1,tq2,…,tqm]T∈Rm,則建立的冗余數據提取模型為
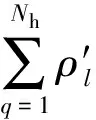
(6)
式中,bq為冗余數據偏置.
1.2 冗余數據特征分類
在獲取冗余數據特征的基礎上,采用線性頻譜分析法,對海量數據干擾下的冗余數據特征進行分類,為改進冗余數據消除方法提供基礎依據.
在海量數據干擾下,冗余數據特征通常在時間及空間上的標點為離散狀態,所以冗余數據分類過程及有關理論也應建立在離散狀態下.當在采集面z=z0處時,其分類分量表示為
S+(zm)=W+(zm,z0)S+(z0)
(7)
式中:W+(zm,z0)為從z0到zm的分類算子;S+(z0)為分類集合.在進行冗余數據分類時,往往只需要去除M階多次分類,故提取的前M項分類結果表示為
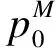
p(z0)S+(z0)
(8)
式中:p(z0)為記錄的原始數據;t(z0)為數據特征.
假設初始樣本冗余數據采樣頻率為f0,計算確定冗余數據提取結果為
(9)
采用線性頻譜分析法得到冗余數據的適應值函數,對海量數據干擾下的冗余數據進行分類,則其冗余數據的分類約束函數為
F=XmaxA+(1-Xmax)B
(10)
式中:A為分類準確率;B為消減百分比.對異常數據的類內離散度集合進行加權處理,得到分類結果為
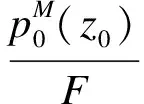
COVmin)]
(11)
式中,COVmax、COVmin分別為樣本的最大協方差和最小協方差.
2 海量數據干擾下冗余數據消除
在對冗余數據進行分類的基礎上,假設LU為U時刻采集分類后的冗余數據,LV為V時刻采集分類后的冗余數據,則其冗余數據采集速度可表示為
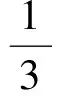
Smin(LU,LV))
(12)
式中,Smax,Savg,Smin分別為最大速度、平均速度、最小速度差異程度的絕對值.此時LU與LV間的位置距離獲取表達式為
D=V(LU,LV)dist(LU,LV)
(13)
式中,dist()為冗余數據間的歐氏距離.
為了進一步對冗余過程進行改進,引入相似度概念,根據冗余數據的突出特征獲取整體相似度.對于任意第i個冗余數據,其整體相似度可表示為
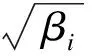
(14)
式中:Ci為相關度系數;βi為冗余數據的突出特征.
對于單個冗余數據來說,它包括γi個冗余數據特征.冗余數據整體相似度可表示成突出特征βi的結構相似度.對整體相似度進行加權處理,則其加權平均數表達式為
(15)
式中:si為i個冗余數據的加權平均數;I為冗余數據集上的特征數量.顯然整體速度大,冗余數據特征越明顯,進行消除越徹底;反之,冗余數據特征越不顯著,消除效果越差.為了能在冗余數據特征不顯著的情況下,也能對冗余數據進行消除,引入了均值漂移傳遞函數對冗余數據進行處理,提高了方法的消除性能.
假設數據集O中存在Hi個冗余數據,則均值漂移傳遞函數可表示為
(16)

(17)
式中:tmin為冗余數據最短活躍時間;tmax為冗余數據最長活躍時間;t為總活躍時間.由此可知,Y越大,說明冗余數據越活躍,消除效果越好;反之,Y越小,說明冗余數據不活躍,消除效果越差.
3 實驗結果分析
為了驗證本文所設計的冗余數據消除方法的性能,進行了實驗對比分析.實驗電腦的硬件設置為:16 Gbit內存,Xeon E5606處理器,主頻2.13 GHz、14 Tbit RAID6磁盤陣列(16個1 Tbit磁盤,其中2個是校驗盤)以及120 Gbit的閃存(SVP200S37A120G),配置的操作系統為Ubuntn12.04,測試數據集為GCC、SciLab、Linux,數據集的數據特征設置如表1所示.
測試數據集合將3種數據集結合在一起,由于3種數據集合中存在大量的相似數據,這種數據的相似性會形成實驗環境中的冗余干擾,符合干擾環境條件.
3.1 準確率實驗分析
為了驗證本文方法的有效性,在數據量一定的情況下,采用文獻[8]局部均值分解的消除方法、文獻[9]規則分段技術法與改進方法進行消除準確率方面的對比.在固定數據量情況下,采用不同方法進行冗余數據消除試驗,實驗準確率用消除數據量與原始數據量的比值表示,取10次結果平均值進行統計.實驗在GCC數據集中進行,其三維數據冗余環境模擬如圖1所示(x、y、z軸表示數據空間的存儲位置).
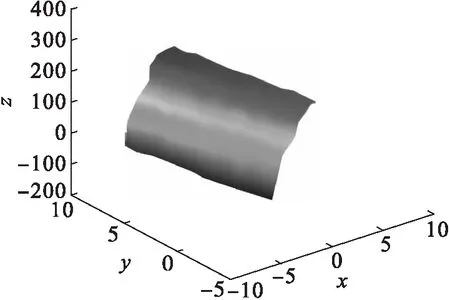
圖1 GCC冗余環境模擬Fig.1 GCC redundant environment simulation
在圖1冗余環境中進行不同方法的準確率對比研究,統計結果如圖2所示.
由圖2可知,在GCC數據集中,采用局部均值分解法其準確率可達到49.3%;采用規則分段技術法時,其消除準確率約為68.1%,兩種算法隨著數據量的增加,均出現準確率下降的趨勢,不適合大量數據應用;采用改進方法時,其消除準確率約為79.7%,其整體要比局部均值分解法、規則分段技術法的準確率提高了約30.4%、11.6%,具有一定的優越性.在冗余干擾的環境下,本文方法可以運用有限次數的分類使得冗余數據被迅速排除在聚類中心之外;而其他方法都需要進行多次的對比和聚類中心校驗操作,大幅度降低了聚類的效率,使得干擾數據無法被有效排除.
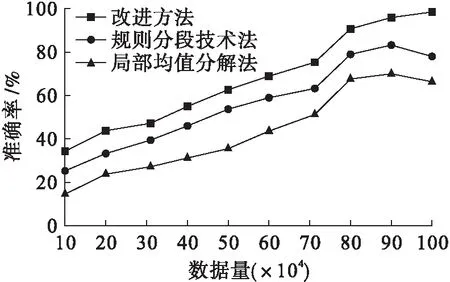
圖2 GCC數據集冗余數據消除準確率對比Fig.2 Comparison in elimination accuracyof redundant data in GCC dataset
3.2 效率對比分析
采用文獻[8]局部均值分解的消除方法、文獻[9]規則分段技術法與改進方法進行消除效率方面的對比,實驗在SciLab和Linux數據集中進行,其三維數據冗余環境模擬如圖3所示.

圖3 SciLab和Linux冗余環境模擬Fig.3 SciLab and Linux redundantenvironment simulation
在圖3冗余環境中進行不同方法效率方面的對比研究,統計結果如圖4所示.
由圖4可以看出,在數據量一定的情況下,采用局部均值分解法時,其消除平均時間約為7.23 s;采用規則分段技術法時,其消除所需時間約為5.53 s,且隨著數據量的增加,消除時間存在多處波動,穩定性較差;采用改進消除方法時,其消除所需時間約為3.42 s,相比傳統的方法,本文方法耗時降低明顯,具有一定的優勢.耗時是最能反映算法優劣性的參考數據,在數據流增加的環境下,冗余干擾強度勢必成倍增加,本算法雖然在后期冗余去除過程中耗時略有增加,但是優化效果明顯.
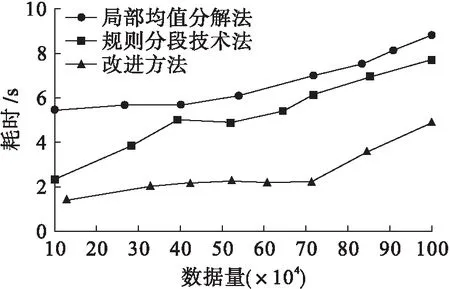
圖4 不同算法下消除所需時間對比Fig.4 Comparison in elimination timewith different algorithms
4 結 論
針對傳統冗余數據消除方法一直存在消除時間長、性能差的問題,本文提出一種冗余數據高性能消除方法.采用主動采樣方法提取海量數據干擾下冗余數據特征,通過線性頻譜分析法對海量數據干擾下的冗余數據進行分類,并以此為基礎計算出冗余數據的相似度,引入均值漂移傳遞函數對冗余數據進行處理,獲取冗余數據活躍程度,實現海量數據干擾下冗余數據的高性能消除.仿真實驗結果表明,相比傳統的消除方法,改進方法的準確率及效率均有所提高,具有一定的優越性.
[1] 宛婉,周國祥.Hadoop平臺的海量數據并行隨機抽樣 [J].計算機工程與應用,2014,50(20):115-118.
(WAN Wan,ZHOU Guo-xiang.Massive data parallel random sampling based on Hadoop [J].Computer Engineering and Applications,2014,50(20):115-118.)
[2] 李志虹.基于遺傳迭代優化的云計算下海量數據分類查詢 [J].科技通報,2015,31(6):34-36.
(LI Zhi-hong.Classification query of huge amounts of data in cloud computing environment based on genetic optimization [J].Bulletin of Science and Technology,2015,31(6):34-36.)
[3] 錢勤,張瑊,張坤,等.用于入侵檢測及取證的冗余數據刪減技術研究 [J].計算機科學,2014,41(增刊2):252-258.
(QIAN Qin,ZHANG Jian,ZHANG Kun,et al.Technical study of reducing redundant data for intrusion detection and intrusion forensics [J].Computer Science,2014,41(Sup2):252-258.)
[4] 王永利,王川,蔣效會,等.基于時空布隆過濾器的RFID冗余數據清洗算法 [J].南京理工大學學報,2015,39(3):253-259.
(WANG Yong-li,WANG Chuan,JIANG Xiao-hui,et al.RFID duplicate removing algorithm based on temporal-spatial Bloom filter [J].Journal of Nanjing University of Science and Technology,2015,39(3):253-259.)
[5] 孟慶娟,曹青媚,馬占飛.海量冗余數據干擾下的網絡數據捕獲和分析系統研究 [J].現代電子技術,2016,39(16):27-30.
(MENG Qing-juan,CAO Qing-mei,MA Zhan-fei.Research on network data capture system and analysis system under interference of massive redundant data [J].Modern Electronics Technique,2016,39(16):27-30.)
[6] 王樂,王芳.網絡數據庫中冗余環境下的高效數據定位仿真 [J].計算機仿真,2016,33(4):364-367.
(WANG Le,WANG Fang.Simulation of efficient data localization in network database under redundant environment [J].Computer Simulation,2016,33(4):364-367.)
[7] 聶軍.基于 K-L 特征壓縮的云計算冗余數據降維算法 [J].微電子學與計算機,2016(2):125-129.
(NIE Jun.A data reduction algorithm based on K-L feature compression for cloud computing [J].Microelectronics & Computer,2016(2):125-129.)
[8] 韓曉慧,杜松懷,蘇娟,等.基于局部均值分解的觸電故障信號瞬時參數提取 [J].農業工程學報,2015,31(17):221-227.
(HAN Xiao-hui,DU Song-huai,SU Juan.Extraction of biological electric shock signal instantaneous amplitude and frequency based on local mean decomposition [J].Transactions of the Chinese Society of Agricultural Engineering,2015,31(17):221-227.)
[9] 刁愛軍.基于壓縮特征編碼的混合云冗余數據刪除算法 [J].科技通報,2015,31(8):42-44.
(DIAO Ai-jun.Hybrid cloud redundant data delete algorithm based on feature code compression [J].Bulletin of Science and Technology,2015,31(8):42-44.)
[10]趙志科,張曉光,王新.基于局部均值分解的機械振動信號趨勢項消除方法 [J].鄭州大學學報(工學版),2014,35(5):100-104.
(ZHAO Zhi-ke,ZHANG Xiao-guang,WANG Xin.Trend elimination method of mechanical vibration signal based on local mean decomposition [J].Journal of Zhengzhou University(Engineering Science),2014,35(5):100-104.)
Highperformanceeliminationmethodforredundantdataundermassivedatainterference
RU Bei1, LI Hong2
(1. School of Computer and Information Engineering, Xinxiang University, Xinxiang 453003, China; 2. Office of Fiber Inspection of Jilin Province, Quality Supervision and Inspection Base of Jilin Province, Changchun 130103, China)
Aiming at the problem that in the data treatment process of massive data, a lot of similar characteristics can bring the redundant interference to the data classification, and cause such drawbacks as multiple check and repetition during the determination with the classification center, a high performance elimination method for redundant data under the massive data interference was proposed. With the active sampling method, the redundancy data feature under the massive data interference was extracted and classified. In addition, the mean shift transfer function was introduced to perform the classification of redundant data, obtain the redundant data activity and realize the high performance elimination of redundancy data. The results show that compared with the traditional method, the high performance elimination method has good properties, short processed time and certain superiority.
massive data; interference; redundant data; high performance; elimination method; improvement; mean value; transfer function
2016-11-21.
河南省科技廳科技攻關資助項目(172102210445); 河南省科技廳軟科學研究資助項目(152400410345); 河南省教育廳資助項目(15A520093).
茹 蓓(1977-),女,河南新鄉人,副教授,碩士,主要從事軟件開發、信息安全等方面的研究.
* 本文已于2017-10-25 21∶13在中國知網優先數字出版. 網絡出版地址: http:∥www.cnki.net/kcms/detail/21.1189.T.20171025.2113.068.html
10.7688/j.issn.1000-1646.2017.06.16
TP 311
A
1000-1646(2017)06-0686-05
(責任編輯:景 勇 英文審校:尹淑英)
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
