基于互信息特征選擇和LSSVM的網絡入侵檢測系統
2017-11-29 13:31:34莊夏
中國測試 2017年11期
莊 夏
(中國民航飛行學院科研處,四川 廣漢 618307)
基于互信息特征選擇和LSSVM的網絡入侵檢測系統
莊 夏
(中國民航飛行學院科研處,四川 廣漢 618307)
為提高網絡入侵檢測系統(IDS)的性能,提出一種基于互信息特征選擇和LSSVM的入侵檢測方案(BMIFSLSSVM)。將采集到的網絡連接數據進行規范化處理,并提出一種權衡考慮特征相關性和冗余性的新型互信息特征選擇(BMIFS)方法,以此從網絡連接數據中選擇出有效特征集。根據提取的訓練樣本特征集,利用最小二乘支持向量機(LSSVM)構建分類器和簡化粒子群優化(SPSO)算法來優化LSSVM的核函數寬度系數和正則化參數,最后利用訓練好的分類器進行入侵檢測。仿真結果表明:提出的BMIFS能夠選擇出最優特征集,使BMIFS-LSSVM提高入侵檢測準確率且降低誤報率。
網絡入侵檢測;互信息特征選擇;最小二乘支持向量機;簡化粒子群優化
0 引 言
隨著網絡技術的發展,計算機網絡面臨的安全問題越來越嚴重。但由于網絡安全漏洞的不斷增加,當前計算機網絡具備的防火墻、統一威脅管理系統等安全應用已不能實現高安全性[1]。為此,需要一種高效的網絡入侵檢測系統(intrusion detection system,IDS)[2]。近些年,學者提出了多種IDS,主要可分為3類:基于數據統計的IDS,基于數據挖掘的IDS和基于機器學習的IDS。其中,機器學習方法是基于對數據的智能學習來構建分類器,其檢測性能較好[3],如神經網絡算法、支持向量機(support vector machine,SVM)等。
最小二乘 SVM(least square SVM,LSSVM)[4]比SVM具有更快的運算速度,在入侵檢測領域中廣泛應用。然而,其性能依賴于兩個參數因子。為了獲得最優參數組合,學者提出了多種智能算法與LSSVM相結合的 IDS,如遺傳算法(GA)[5]、粒子群算法(PSO)[6]、杜鵑鳥搜索(MCS)[7]等。 這些算法的結合一定程度上提高了LSSVM的性能,但由于這些智能優化算法的計算復雜度較高,使整個系統的運行時間較長,不太適合應用在實時網絡入侵檢測中。
另外,網絡連接數據具有大量的特征,冗余特征不僅增加了分類器的計算時間,而且還會降低檢測準確率。為此,在輸入到分類器進行檢測之前,需要對其進行特征降維。目前,特征選擇方法主要有歐式距離法、余弦相似度法、互信息法等[8]。其中,互信息(mutual information,MI)是衡量兩個隨機變量相關性的一種有效方法。學者提出了多種基于MI的特征選擇算法,如傳統的互信息特征選擇(mutual information feature selection,MIFS)、MIFS-U 算法等[9]。然而,這些算法都涉及到一個用來表征輸入特征之間冗余度的參數β,而選擇合適的β目前還較為困難。基于上述分析,本文提出一種新型MIFS和參數優化LSSVM的網絡入侵檢測系統,表示為BMIFS-LSSVM(SPSO)。其主要創新點在于:
1)基于MI提出了一種新的均衡型MIFS(BMIFS)。在傳統MIFS計算候選特征之間相關性中融入了特征與類之間的相關性,以此來表征在已選特征集中,特征fi對于特征fs的相對最小冗余。同時也不需要確定參數β的值,從而提高了特征選擇的能力。
2)利用LSSVM來構建分類器,利用一種新型的簡化粒子群優化 (simplified particle swarm optimization,SPSO)算法來優化LSSVM參數,在提高分類器性能的同時,避免過大的計算復雜度,提升訓練過程的時間效率。
1 系統框架
入侵檢測系統框架如圖1所示,主要由4個部分組成:1)數據收集和預處理,即收集網絡數據包,并將收集的數據進行規范化處理;2)特征選擇,即通過提出的BMIFS從數據特征集中選擇出具有代表性的特征;3)訓練分類器,即根據所選擇的特征集來訓練LSSVM分類器;4)入侵檢測,即利用訓練好的分類器來檢測測試數據。
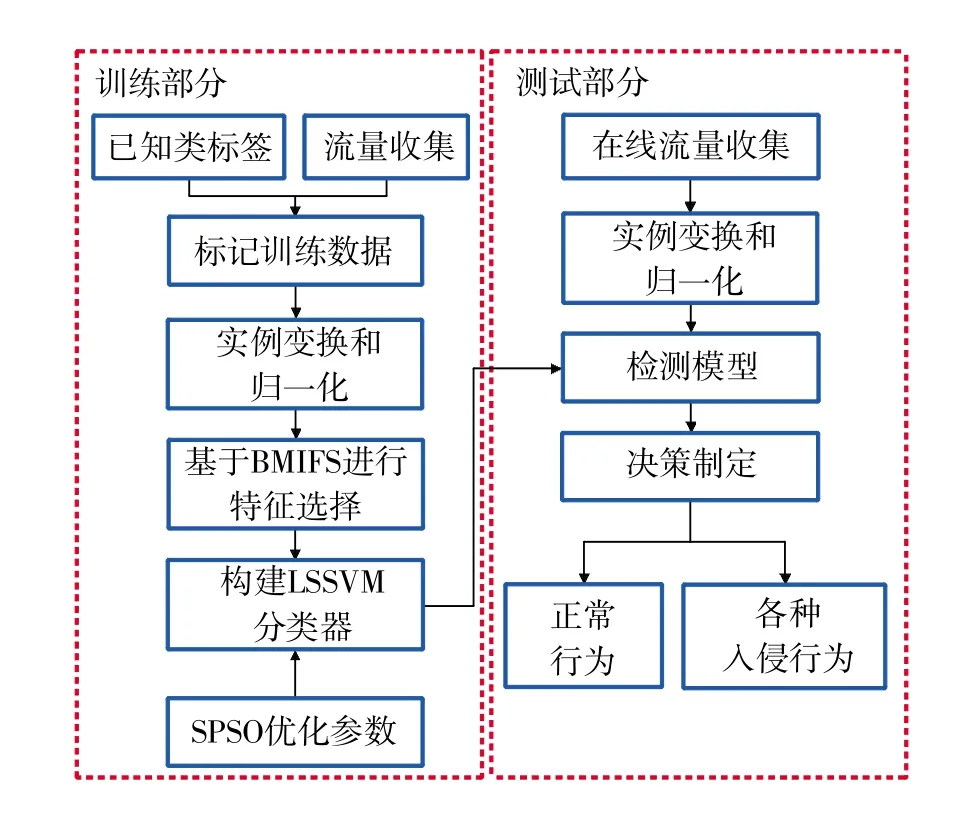
圖1 提出的BMIFS-LSSVM(SPSO)入侵檢測系統框圖
2 數據收集和預處理
數據收集是入侵檢測的第一個關鍵步驟。數據源的類型和收集數據的位置是IDS有效性的兩個決定性因素。為了為目標主機或網絡提供最佳保護,本研究提出了一種基于網絡的IDS,在距離保護目標最近的路由器上運行并監視入站的網絡流量。在訓練階段,根據傳輸/互聯網層協議來分類所收集的數據樣本,并將其標記為各類攻擊。
本研究根據標準數據集KDD Cup 99中的數據格式,對收集的網絡數據進行規范化預處理。首先,執行數據轉換,即用特定的數值表示數據的一些屬性特征,例如協議類型(TCP、UDP、ICMP),服務類型(HTTP、FTP、Telnet等)和 TCP 狀態(SF、REJ)等。 然后,執行數據歸一化。即將每個屬性值歸一化到[0-1]范圍內。
在訓練階段還需要將每條數據標記為正常或特定的攻擊類型,本研究采用了4種常見類型,即探測攻擊(Probe)、拒絕服務攻擊(DoS)、遠程登陸攻擊(R2L)和提權攻擊(U2R)。
3 基于BMIFS的特征選擇
如果將網絡流量記錄之間的相關性視為線性關聯的,則可以使用線性相關系數來度量兩個隨機變量之間的相關性。然而,在實際網絡通信中,變量之間的相關性也可以是非線性的。因此,本文提出一種新的基于MI的特征選擇度量BMIFS,用來分析線性和非線性變量之間關系,從而選擇出最佳特征集。
3.1 互信息
互信息(MI)是兩個隨機變量關系的對稱度量,輸出為一個非負值,其中零表示兩個變量是統計獨立的[9]。
給定 2 個聯系隨機變量U={u1,u2,…,ud}和V={ν1,ν2,…,νd},其中d為樣本總數,U和V之間的 MI定義為
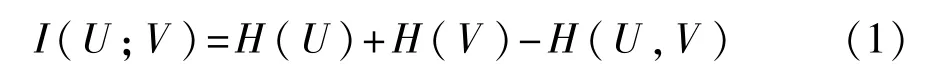
其中,H(U)和H(V)為U和V的信息熵,信息熵為變量不確定性的度量,其表達式分別為
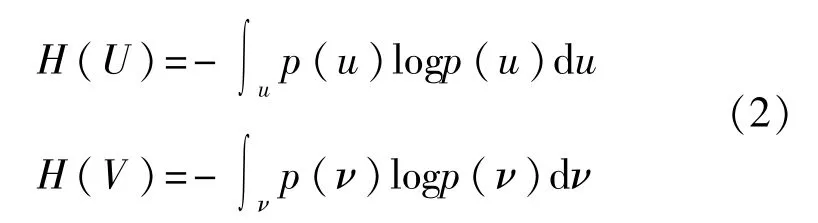
U和V之間的聯合熵定義為
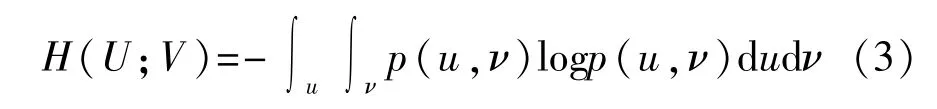
那么,U和V之間的MI可表示為
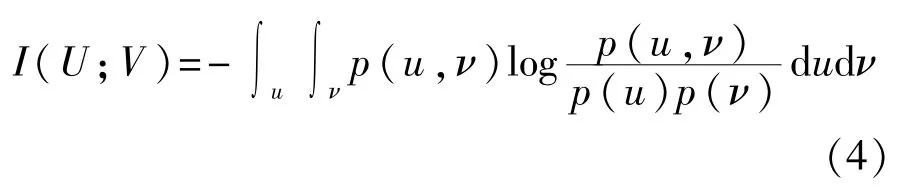
對于離散化的U和V,則MI可表示為
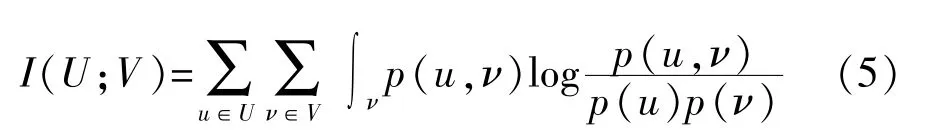
在特征選擇中,如果特征包含關于類的重要信息,則該特征與該類相關,否則不相關或多余。由于MI可以量化兩個隨機變量共享的信息量,因此可用作評估特征和類標簽之間相關性,預測能力更高的特征f具有更大的互信息I(C;f)。
3.2 互信息特征選擇(MIFS)
在互信息特征選擇(MIFS)[10]中,通過計算I(C;fi,S)來選擇特征。I(C;fi,S)表示在所選擇的特征集S中,增加特征fi后形成的新特征集與類別C之間的互信息,反應了特征fi對分類的貢獻程度。I(C;fi,S)的計算思想是計算特征fi與類別C之間的互信息I(C;fi),然后計算特征fi與先前所選特征fs之間的互信息I(fi;fs)之和,并將其乘以一個比例系數β對I(C;fi)進行校正。 表達式如下:
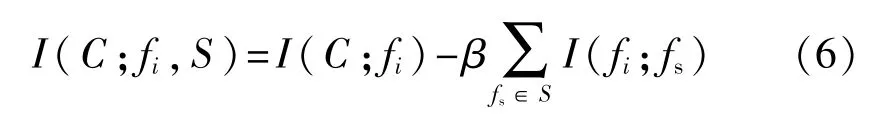
β值為進行特征選擇時考慮輸入特征之間冗余度的權重,其決定選擇特征時,兩個方面(即特征與類之間的MI和特征與特征之間的MI)的重要性比重。
3.3 BMIFS算法
在傳統MIFS基礎上,學者提出的改進型MIFS算法大多是對式(6)中I(C;fi,S)中第 2 項進行改進。然而,這些方法存在一些限制。 例如,I(C;fi,S)等式右邊的第1項是計算候選特征與類別之間的互信息,表示相關性;第2項則是求和候選特征與已選特征之間的互信息,表示冗余性。這兩個部分通過一個參數β來進行權衡。如果β太小,則算法偏重候選特征與類之間的MI,根據單個候選特征和類之間的MI依次選擇特征。如果選擇的β太大,則算法偏重考慮候選特性之間的MI。為此β的選擇較為困難,且目前也沒有選擇參數β的合適方法。
為了解決上述問題,本文提出一種均衡考慮相關性和冗余性的新型MIFS算法(BMIFS),在第2項中引入了候選特征與類別之間的互信息,且不再需要人為設置一個額外的參數,即利用1/|S|代替β。BMIFS從一個初始特征集中選擇出具有最大化I(C;fi)并最小化冗余的特征,表達式如下:
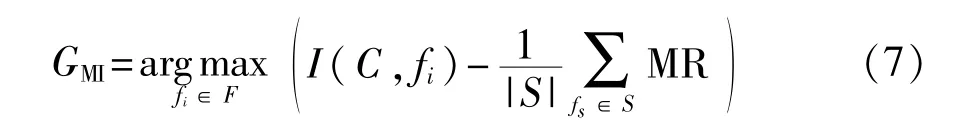
式中|S|為已選擇特征的數量,MR表示在已選特征集S中,特征fi對于特征fs的相對最小冗余,定義如下:
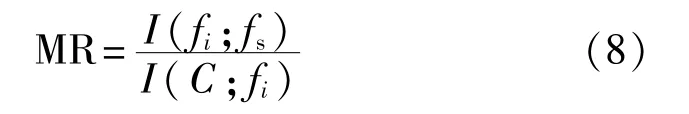
當I(C;fi)=0 時,特征fi可被丟棄。 如果對于類C,fi和fs之間高度相關,那么fi也將是冗余的。為此,需要設定一個閾值Th=0來與GMI進行比較。如果GMI≤0,則當前特征fi對于類C是無關緊要的,其將會降低所選擇的特征集S與類C之間的MI,并將其從S中刪除。如果GMI>0,則將特征fi作為候選特征。BMIFS選擇特征的過程如算法1所示。
算法1:BMIFS特征選擇
輸入:特征集F={fi,i=1,2,…,n}
輸出:選擇的特征集S
開始
1)初始化S=φ
2)為每個特征計算I(C;fi)
3)設置nf=n,根據下式選擇特征fi:
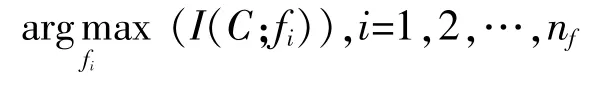
設置F←F/{fi};S←S∪{fi};nf=nf-1
4)WhileF≠φdo
根據式(7)計算GMI,找到fi,i∈{1,2,…,nf}
設置nf=nf-1;F←F/{fi}
If(GMI>0) then
S←S∪{fi}
End if
End while
5)根據S中每個特征的GMI對特征進行排序
6)返回
4 基于LSSVM的入侵分類
4.1 LSSVM模型
在傳統LSSVM中,設定訓練數據為{xi,yi}ni=1,xi為輸入數據,yi為輸出類別[11]。 為在非線性映射 φ(x)構成的特征空間中估計最優擬合函數 y(x)=ωTφ(xi)+b,需將LSSVM轉換為如下線性方程組:
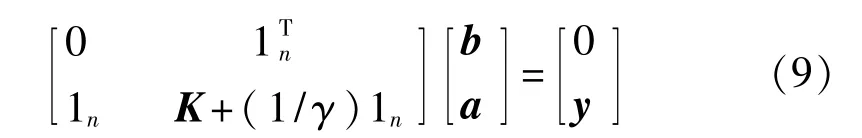
式中 y=[y1,y2,…,yn],1n=[1,1,…,1]T,K=φ(xi)Tφ(xj)=K(xi,xj),γ為正則化參數。 LSSVM 分類器的表達式為

式中K(x,xi)為LSSVM的核函數,通常情況下選擇徑向基函數(RBF)作為核函數,其表達式為
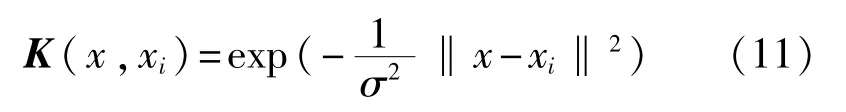
4.2 SPSO優化LSSVM模型參數
在LSSVM中,核函數寬度系數σ和正則化參數γ是影響LSSVM分類性能的關鍵參數。γ用來描述訓練過程中最大分類邊界和分類誤差之間的平衡關系。γ越大,分類正確性越高,但泛化能力降低。σ用來控制RBF核的寬度,σ過大會使其性能與一階多項式核相近,失去了RBF核的作用。為了獲得最優的參數組合(σ,γ),大多采用一些智能優化算法進行全局搜索。例如,遺傳算法、粒子群算法、模擬退火算法、蟻群算法等。然而,這些算法的計算量都較大,對LSSVM分類速度的影響較大,不適合應用在實時網絡入侵檢測中。
基于上述分析,本文采用了一種由文獻[12]提出的簡化粒子群優化(SPSO)算法,以分類準確性作為適應度函數,對LSSVM中的參數進行優化。SPSO算法在不降低求解質量的同時,大大降低了收斂時間,可適用于實時應用。
在傳統PSO算法中,基于從全局最優解和當前最優解的信息來更新每個粒子的位置,使其在每次迭代中都會向吸引子所引導的方向移動,最終獲得最優解。粒子的速度和位置更新公式為
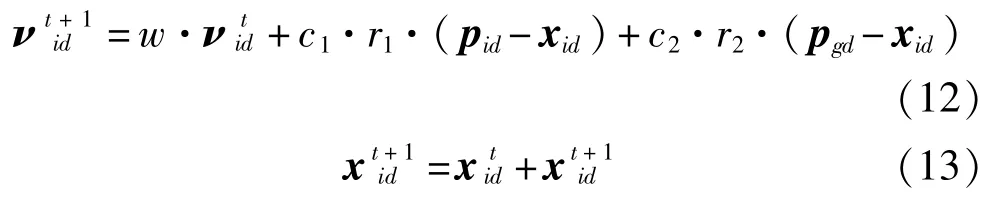
式中i=1,2,…,N,其中N為j維粒子數,xid表示第i個粒子在第d維的當前位置,νid表示速度向量,pid和pgd分別表示全局最優解和當前最優解。c1和c2通常設置為2。r1和r2是0和1范圍內的隨機數。w為慣性權重,通常設置為0.8。
文獻[12]通過分析生物模型和進化迭代過程,發現PSO的進化過程與粒子速度無關。另外,粒子速度的大小并不代表粒子能夠有效趨近最優解位置,反而可能造成粒子偏離正確方向,延緩后期收斂速度。為此,其將PSO進行改進,去掉了速度項,形成一種簡化粒子群優化(SPSO)算法。簡化后的粒子位置方程為
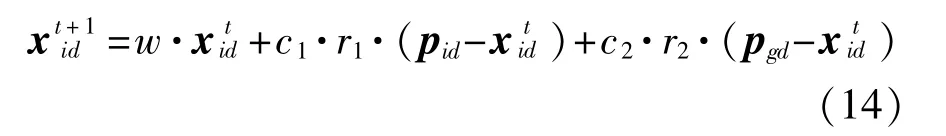
可以看出,簡化后的PSO位置方程由二階降到了一階,大大簡化了粒子進化過程和時間復雜度,使其能夠應用到實時網絡入侵檢測中。
5 仿真及分析
5.1 實驗設置
利用Matlab構建實驗環境,實驗中采用了NSLKDD和Kyoto 2006+數據集。其中,NSL-KDD數據集是2009年建立的,其是在KDD Cup99基準數據集基礎上移除了冗余和重復的記錄信息后構建的精簡數據集,包含了Probe、DoS、R2L和U2R攻擊。NSL-KDD數據集具有148517個網絡連接數據,其中有77 054個正常連接和71 463個異常連接。另外,所包含的網絡連接類型有TCP、UDP和ICMP協議,分別為121569、17614、9334個。每個連接數據有41個特征和一個類標簽,表1列舉了前14個特征及其描述。
Kyoto 2006+數據集包含了由京都大學部署服務器從2006年11月至2009年8月收集的連接數據。此數據集中的每個連接有24個不同的特征。
在訓練LSSVM分類器之前,需要通過提出的BMIFS選擇出5個類的特征集。由于LSSVM是二進制分類器,所以要分別訓練5個LSSVM分類器,最后融合成一個檢測模型。其中,本研究采用了一對多(one-vs-all,OVA)的訓練方式來訓練分類器。
另外,在利用SPSO優化LSSVM參數(σ,γ)時,設置σ的取值范圍為[2-5,25],步長為2-5,粒子編碼為5位二進制數。γ的取值范圍為[2-1,210],步長為2-1,粒子編碼同樣為5位二進制數。設置SPSO算法的種群數量N=30。通過實驗表明,SPSO算法大約迭代25次后就能收斂到最優解,比傳統PSO快了近一倍。為此,這里設置最大迭代數量Tmax=50。

表1 NSL-KDD數據集中連接數據的特征舉例
5.2 性能指標
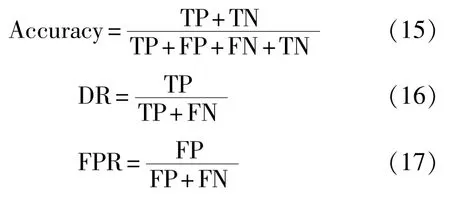
每次實驗中,統計IDS入侵檢測的真陽性(TP)、假陽性(FP)、真陰性(TN)和假陰性(FN)。 實驗中采用3種性能指標,分別為準確度(accuracy),檢測率(detection rate,DR)和誤報率(false positive rate,FPR),表達式如下:
5.3 性能分析
首先,為了驗證提出的BMIFS特征選擇方法的有效性,將其與傳統MIFS和MIFS-U進行比較。將NSL-KDD和Kyoto 2006+數據集中20%作為訓練集,利用上述3種方法進行特征選擇。其中,對于MIFS和MIFS-U,文獻[9]認為當β=0.3時效果最佳。表2和表3為3種方法所選擇出的最優特征及排序。可以看出,提出的BMIFS所選擇出的特征數量最少。

表2 NSL-KDD數據集上選擇的特征及排序
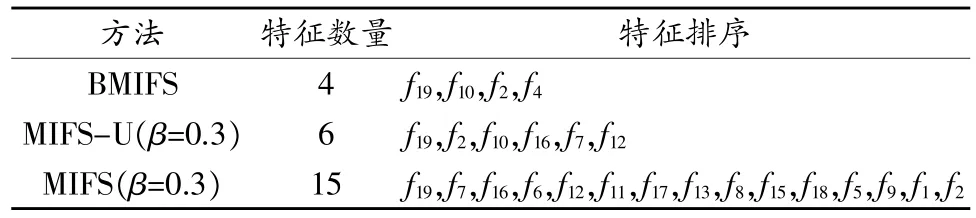
表3 Kyoto 2006+數據集上選擇的特征及排序
在選擇出特征之后,將NSL-KDD和Kyoto 2006+數據集的80%作為測試集,進行5次分類實驗。為了公平比較,分類器都采用SPSO優化的LSSVM分類器(LSSVM(SPSO)),分類性能比較結果如表 4所示,其中數據為5次實驗的平均值。另外,表4還給出了沒有采用SPSO優化的LSSVM性能,以此來驗證SPSO算法的優化作業。
表中可以看出,特征選擇操作對分類性能具有很大的影響,其中所有特征+LSSVM(SPSO)方法的性能最低,這表明在沒有進行特征選擇時,大量的冗余特征會降低分類精度。另外,MIFS-U特征選擇方法的性能比傳統MIFS具有一定的改善。而本文提出的BMIFS在檢測率、誤報率和準確率方面都具有最高的性能。另外,對比LSSVM(SPSO)和傳統LSSVM的性能可以看出,LSSVM的參數選擇對分類性能具有一定的影響,采用SPSO優化后的LSSVM性能有所提高。
在上述實驗進行過程中,統計了各種方法的訓練和測試時間,結果如表5所示。可以看出,提出的BMIFS+LSSVM(SPSO)的訓練和測試時間都最小,這是因為采用了BMIFS,在保持分類準確性下選擇出最少數量的所需特征,有效降低了LSSVM分類器的計算量,從而縮短了訓練和測試時間。
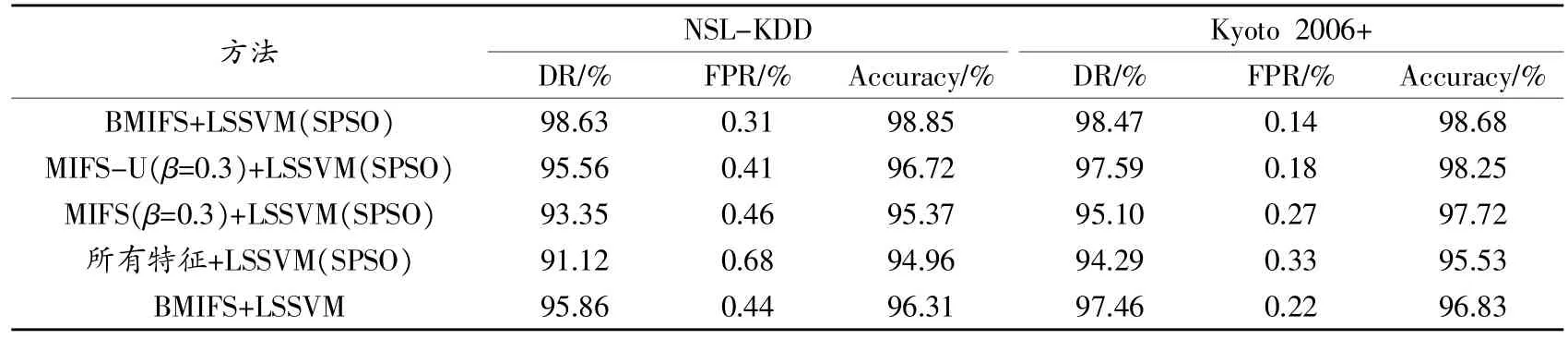
表4 各種方法的分類性能比較
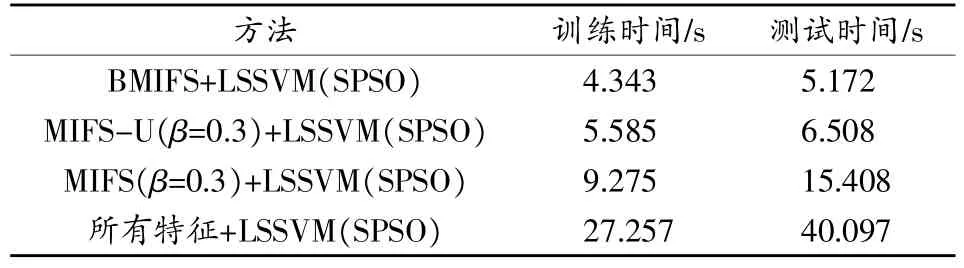
表5 各種方法的時間復雜性比較
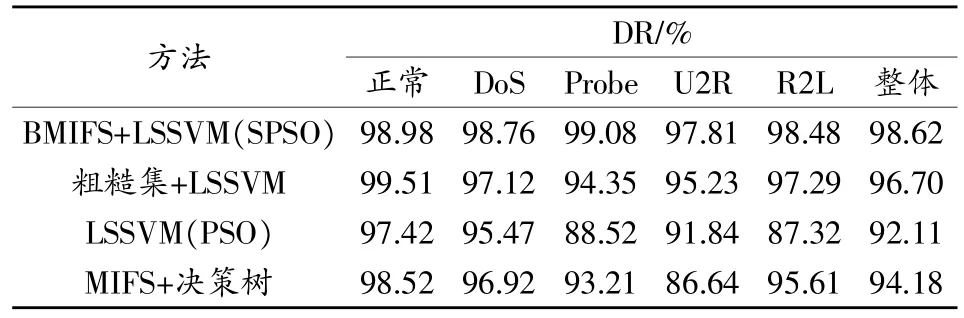
表6 各種IDS在NSL-KDD數據集上的性能比較
為了進一步驗證提出方法的有效性,將提出的BMIFS+LSSVM(SPSO)與文獻[13]提出的粗糙集特征選擇+LSSVM、文獻[6]提出的 LSSVM(PSO)方法、文獻[14]提出MIFS+決策樹分類器方法在NSL-KDD數據集上進行比較。各種方案的檢測率結果如表6所示。可以看出,提出的方法整體檢測率最高。這是因為,本文采用了BMIFS提取出了最佳特征,避免了特征冗余,這一定程度上有助于后續分類器的分類。另外,采用了SPSO算法對LSSVM參數進行了優化,有效提高了其分類性能。
6 結束語
本文提出一種基于互信息特征選擇和LSSVM的入侵檢測系統。為解決現有互信息特征選擇中的缺陷,提出一種綜合考慮特征相關性和冗余性的互信息選擇方法(BMIFS),以此為分類器選擇最小數量的有效特征集。采用了LSSVM作為分類器,考慮到算法的運行時效問題,使用SPSO算法來優化LSSVM的參數提高其分類能力。在NSL-KDD和Kyoto 2006+數據集上進行了實驗,并與相關方法進行了比較。結果證明了提出的BMIFS能夠選擇出最少數量的有效特征,同時也表明了BMIFS+LSSVM(SPSO)方案的可行性和有效性。
[1]田志宏,王佰玲,張偉哲,等.基于上下文驗證的網絡入侵檢測模型[J].計算機研究與發展,2013,50(3):498-508.
[2]李佳.基于AFSA-KNN選擇特征的網絡入侵檢測[J].計算機工程與設計,2014,35(8):2675-2679.
[3]KOC L, MAZZUCHI T A, SARKANI S.A network intrusion detection system based on a Hidden Na?ve Bayes multiclass classifier[J].Expert Systems with Applications,2012,39(18):13492-13500.
[4]陳天宇,吳凡,馬世杰,等.基于CS和LS-SVM的入侵檢測算法[J].計算機技術與發展,2016,26(5):99-103.
[5]LIU C.Network intrusion detection model based on genetic algorithm optimizing parameters of support vector machine[J].Advanced Materials Research,2014,98(9):2012-2015.
[6]QI F, XIE X, JING F.Application of improved PSOLSSVM on network threat detection[J].Wuhan University Journal of Natural Sciences,2013,18(5):418-426.
[7]陳健,陳雪剛,張家錄,等.杜鵑鳥搜索算法優化最小二乘支持向量機的網絡入侵檢測模型[J].微電子學與計算機,2013,30(10):29-32.
[8]高鵬.推薦系統中信息相似度的研究及其應用[D].上海:上海交通大學,2013.
[9]KWAK N,CHOI C H.Input feature selection for classification problems[J].IEEE Transactions on Neural Networks,2002,13(1):143-159.
[10]AMIRI F, REZAEI Y M, LUCAS C, et al.Mutual information-based feature selection for intrusion detection systems[J].Journal of Networkamp;Computer Applications,2011,34(4):1184-1199.
[11]王建國,楊云中,秦波,等.基于峭度與IMF能量融合特征和LS-SVM的齒輪故障診斷研究[J].中國測試,2016,42(4):93-97.
[12]SANTOS R P B D, MARTINS C H, SANTOS F L.Simplified particle swarm optimization algorithm[J].Acta Scientiarum Technology,2012,34(1):521-531.
[13]WANG F N, WANG S S, CHE W F, et al.Network intrusion detection method based on RS-LSSVM[J].Applied Mechanicsamp;Materials,2014,60(2):1634-1637.
[14]SONG J, ZHU Z, SCULLY P, et al.Modified mutual information-based feature selection for intrusion detection systems in decision tree learning[J].Chinese Journal of Computers,2014,9(7):1542-1546.
(編輯:李妮)
Network intrusion detection system based on mutual information feature selection and LSSVM
ZHUANG Xia
(Research Department,Civil Aviation Flight University of China,Guanghan 618307,China)
In order to improve the performance of network intrusion detection system (IDS), an intrusion detection scheme based on mutualinformation feature selection and LSSVM was proposed (BMIFS-LSSVM).First, the collected network connection data was normalized.Then, a new mutual information feature selection (BMIFS) method was proposed to balance the feature correlation and redundancy,and a effective feature set was selected from the network connection data.Then, the least squares support vector machine(LSSVM) was used to construct the classifier according to the extracted training sample feature set, and the simplified particle swarm optimization (SPSO) algorithm was used to optimize the kernel function width and regularization parametersof LSSVM.Finally, the trained classifierwasused forintrusion detection.The simulation results show that the proposed BMIFS can select the optimal feature set,make the BMIFS-LSSVM improve the intrusion detection accuracy and reduce the false alarm rate.
network intrusion detection; mutual information feature selection; least squares support vector machine;simplified particle swarm optimization
A
1674-5124(2017)11-0134-06
10.11857/j.issn.1674-5124.2017.11.026
2017-03-19;
2017-04-25
國家自然科學基金民航聯合基金重點項目(U1233202/F01)
莊 夏(1980-),男,四川廣漢市人,副教授,碩士,研究方向為計算機網絡安全。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
