一種高性能高可靠的混合客戶端緩存系統
2017-12-08 05:59:18李楚馮丹王芳
計算機研究與發展 2017年11期
關鍵詞:故障
李 楚 馮 丹 王 芳
(武漢光電國家實驗室(華中科技大學) 武漢 430074) (信息存儲系統教育部重點實驗室(華中科技大學) 武漢 430074)
(lichu@hust.edu.cn)
一種高性能高可靠的混合客戶端緩存系統
李 楚 馮 丹 王 芳
(武漢光電國家實驗室(華中科技大學) 武漢 430074) (信息存儲系統教育部重點實驗室(華中科技大學) 武漢 430074)
(lichu@hust.edu.cn)
現代數據中心普遍使用網絡存儲系統提供共享存儲服務.存儲服務端通常使用獨立冗余磁盤陣列(RAID)技術保障數據可靠性,如可以容單雙盤錯的RAID56.相比于傳統磁盤,固態盤具有更低的訪問時延和更高的價格,因此將固態盤作為存儲客戶端緩存成為一種流行的方案.寫回法可以充分發揮固態盤的優勢加速存儲讀寫性能,然而一旦固態盤發生故障,寫回法無法保證數據的一致性和持久性.寫直達法簡化了一致性模型,但是無法減小寫時延.設計并實現一種新的混合客戶端緩存(hybrid host cache, HHC),HHC通過使用廉價的日志磁盤鏡像存放固態盤上的臟數據來提高可靠性,并且利用寫屏障語義保證數據的可靠性和一致性.分析表明,HHC的平均無故障時間遠遠高于后端存儲系統.最后實現了一個原型系統并使用Filebench進行性能評估,結果表明在不同負載下,HHC性能與傳統的寫回法接近,遠遠超過寫直達法.
固態盤;客戶端緩存;緩存管理;可靠性;性能
現代數據中心普遍使用網絡存儲系統提供海量存儲服務,如網絡附加存儲(network attached storage,NAS)和存儲區域網絡(storage area network, SAN)等. 存儲應用程序,如郵件服務器、文件服務器等分布在計算節點對外提供服務,并通過網絡訪問后端共享存儲服務器.存儲服務器通常使用獨立冗余磁盤陣列(redundant array of independent disks, RAID)[1]技術保障存儲系統的可靠性.比如RIAD5/6分別可以容單盤和雙盤故障,既滿足高性能高可靠需求,又能提供較高的存儲利用率,在存儲服務器中得到廣泛應用[2].
隨著固態盤(solid-state drive, SSD)存儲密度的提高以及價格的不斷降低,數據中心節點中部署SSD已成為較為普遍的做法.相對于DRAM,SSD具有大容量、非易失等優勢;相對于傳統的磁盤(hard disk drive, HDD),SSD有著更高隨機訪問性能.計算節點上利用SSD作為緩存設備,不僅可以減少對后端存儲的訪問競爭,而且能夠大大降低應用的訪問時延.因此,近幾年工業界紛紛使用基于SSD的存儲客戶端緩存來提高存儲服務能力[3-5].寫直達法(write through)和寫回法(write back)是2種基本的緩存寫策略.寫直達法會將寫請求寫入后端存儲然后寫入緩存;寫回法只將寫請求的數據寫入緩存就返回,緩存中的臟數據由緩存管理模塊選擇合適的時機刷回到后端存儲.寫直達法可以減小讀請求的時延,但因寫請求的同步寫回,寫性能無法得到改善.然而最近的研究表明:企業級工作負載含有大量寫操作,且寫/讀比例有增加的趨勢[6-8],在這種負載下,采用寫回法能夠得到比寫直達法好得多的性能[9],這在我們后面的實驗中也得到了證實.
盡管寫回法能更好地發揮SSD緩存的讀寫優勢,但同時也面臨著嚴峻的挑戰:現代SSD中大量使用的多層單元(multi-level cell, MLC)閃存芯片擦除次數只有10 000次,可靠性遠低于后端的RAID5/6.我們通過對可靠性的定量分析發現,單塊SSD設備與多塊磁盤構成的RAID5/6相比,其平均無數據丟失時間(mean time to data loss, MTTDL)少了2個數量級以上.那么當SSD發生不可恢復的故障時,采用傳統的寫回法將帶來2個問題:1)臟數據異步刷回機制破壞了原來的寫入順序,因此無法保證存儲服務器端的數據一致性;2)緩存數據的丟失使得原本被認為持久化的數據并沒有寫入后端存儲,這樣就無法保證數據的持久性,尤其是目前的SSD容量不斷提升,一旦SSD出現故障將造成大量數據不可恢復的丟失,這是很多存儲應用以及用戶無法容忍的.因此,如何克服這些問題成為近幾年的研究熱點.
為了解決寫回法帶來的問題,研究人員提出了各種方案,按照實施的層次可分為2類:1)提高SSD緩存層的可靠性,從而降低緩存層失效的概率.其方法主要是使用 RAID技術組織多個SSD,利用冗余數據保證緩存層的可靠性,如Oh等人[10]提出的SRC(SSD RAID cache)以RAID5方式管理多塊SSD緩存數據,Arteaga等人[9]則使用RAID1來構建SSD緩存層.盡管這種方式確實可以大大提高SSD緩沖層的可靠性,但是同時也導致成本大幅增加,而且RAID帶來的冗余數據增加了SSD的擦寫次數,加速了SSD的磨損,更嚴重的是均勻的磨損分布增加了多個SSD同時失效的風險[11-12].2)通過提出基于寫回法的新緩存策略來應對SSD失效問題.如Koller等人[13]提出了2種緩存策略:Ordered Write-back和Journaled Write-back,可以保證臟數據的刷回順序與應用程序寫入的順序完全相同.雖然這種方式保證了SSD緩存設備失效時存儲服務端的數據一致性,但是并不能保證數據的持久性.Qin等人[14]提出Write-back Flush策略,利用文件系統、數據庫等存儲應用提供的寫屏障(write barrier)機制, 在SSD緩存層實現寫屏障操作的語義來保證數據的一致性和持久性.寫屏障會阻塞隨后的寫請求,直到緩存中所有臟數據被持久化存儲,文件系統等存儲應用通過該機制保證數據的寫入順序[15].在Write-back Flush策略中,寫屏障操作會觸發緩存管理程序將SSD中所有臟數據刷回到網絡存儲系統,這使得寫屏障時延較長,因此對于寫密集尤其是同步密集型(如fsync,該操作會觸發寫屏障)負載,頻繁的數據刷回操作直接影響到存儲應用的響應時間.
本文提出一種新的混合客戶端緩存(hybrid host cache, HHC)架構.HHC由SSD和廉價的HDD組成,緩存管理模塊選擇性地將SSD緩存中的臟數據以日志方式順序寫入HDD,一方面保證了緩存層的可靠性,另一方面充分利用磁盤順序寫的帶寬優勢,盡可能減小冗余的寫入操作對前臺寫請求的影響.另外,在寫回法的基礎上,HHC利用寫屏障機制實現新的緩存策略,通過結合精心設計的日志管理策略保證數據的一致性和可靠性.最后我們實現原型系統并使用Filebench[16]對I/O吞吐率進行測試和分析.實驗結果表明,在讀密集型負載websearch下HHC與其他緩存策略表現相當,在寫密集型負載fileserver下HHC相對于寫直達可以提高75.4%~388.2%,相對于Write-back Flush提高了48.2%~173.4%;在同步密集的負載varmail下比寫直達提高了3.7~8.2倍,相對于Write-back Flush提高了5.5~10.2倍.
1 混合客戶端緩存HHC
1.1設計目標
在設計HHC時,我們致力于達到4個目標:
1) 持久性.當SSD設備發生故障時,將導致所有的緩存數據不可用.由于使用基于寫回法的緩存策略,緩存中的數據塊主要有2種:干凈緩存塊和臟緩存塊.干凈緩存塊是當讀不命中時從后端讀入緩存的數據塊,而臟緩存塊是由應用程序寫入緩存且未被刷回后端存儲服務器的數據塊.由于干凈緩存塊在后端有同樣的副本,因此不需要額外的保護.而對于臟緩存塊應當提供與后端RAID5/6相當級別的可靠性保障[9].HHC使用磁盤來鏡像地存放SSD緩存中的臟數據,通過定量的可靠性分析發現:當使用1塊磁盤時HHC可達到超過RAID5的可靠性級別;而當使用2塊磁盤做鏡像時,HHC的可靠性可以超過RAID6(見第2節,可靠性分析).因此,可以根據后端存儲的RAID級別使用不同的HHC配置.
2) 一致性.存儲應用通常會利用寫屏障請求來實現原子操作和持久化操作(如fsync)等,從而確保數據的一致性[14].當存儲應用發出寫屏障請求時,存儲設備會將其緩存中的所有臟數據持久化到設備之后才返回到應用,這樣使得寫屏障之前與之后的寫操作的順序性得到保證.需要注意的是,對于寫屏障之后的寫操作,存儲系統并不保證其持久化到存儲設備,即在2個寫屏障之間的寫操作并不需要強制保證其持久化到存儲設備時的順序.HHC在緩存層實現寫屏障語義,當來自存儲應用的寫屏障請求到達時,HHC一方面將對SSD設備發送寫屏障以確保緩存數據和緩存索引的持久化,另一方面確保SSD中的臟緩存塊全部持久化到磁盤日志.因此即使SSD或HDD出現故障,仍然能保證寫屏障時所有數據不會丟失,從而保證寫屏障語義的正確實施.
3) 高性能.存儲應用程序發送的寫屏障操作要求將所有SSD中的臟數據持久化到磁盤日志,為了降低寫屏障的時延, HHC在內存中維護多個內存緩沖區,對應到磁盤上的日志段,存儲應用的寫請求被寫入內存緩沖區,并采用流水線的方式異步地寫回到磁盤日志.這樣既可以避免因臟數據累積過多而增加寫屏障的開銷,又可以充分利用磁盤順序寫的帶寬優勢.研究表明大量的負載都有著突發性特征,I/O空閑期廣泛存在[17],因此為了保證充足的日志空間,HHC在系統空閑的時間進行日志回收操作,從而盡可能避免日志回收帶來的開銷.
4) 低成本.盡管SSD的價格逐步降低,然而其單位存儲的價格仍然比磁盤高出10倍左右.因此使用額外的磁盤并不會帶來成本的顯著增加,而且由于數據中心的計算節點常常會有備用的磁盤處于空閑狀態,HHC可以將這些磁盤作為日志盤使用,進一步降低存儲系統的成本.
表1給出了5種不同緩存策略的對比,依次是寫直達法(WT)、寫回法(WB)、Ordered Write Back(WB-Ordered)、Write-back Flush(WB-Flush)以及我們的HHC.WB能夠提供最好的性能,但是它既不能保證一致性也不能保證持久性;WB-Ordered在不同的負載下都有很好的性能,但是同樣不能提供持久性;WT和WB-Flush能夠保證一致性和持久性,但是對于寫密集型和同步密集型(如郵件服務器等)的存儲應用,并不能充分發揮SSD的讀寫優勢;而HHC在不同負載下能夠達到或接近WB的性能,同時能夠保證數據的一致性和持久性.
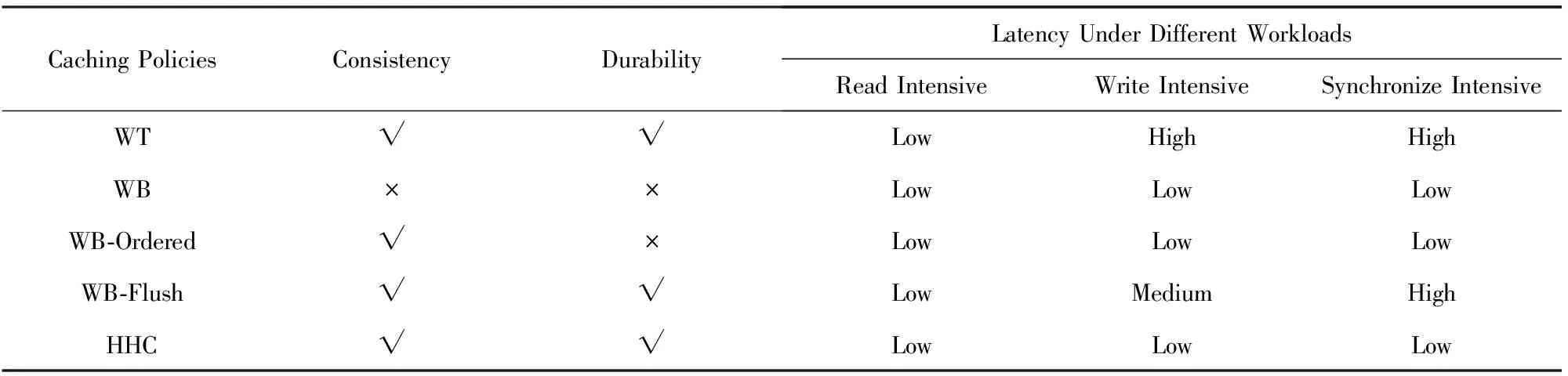
Table 1 Comparison of Different Policies表1 不同緩存策略的對比
Note:“√” means support; “×” means nonsupport.
1.2HHC系統架構概述
如圖1所示,根據后端存儲服務可靠性的不同,HHC在傳統的固態盤緩存層添加一個或多個磁盤,多個磁盤將以鏡像的方式存儲數據,從而保證可靠性需求.固態盤作為讀寫緩存使用,其緩存策略可以選擇傳統的LRU方式,也可以使用近年來提出的一些針對固態盤特性的選擇性緩存策略等.固態盤緩存中的數據按照緩存狀態可分為2類:1)干凈緩存塊,即緩存塊中的數據在后端存儲中有相同的副本;2)臟緩存塊,即由應用程序寫入的新數據,尚未寫回到后端存儲.為了充分發揮固態盤緩存帶來的性能提升,以及充分利用磁盤優秀的順序寫性能,HHC采用異步的方式將固態盤中的臟緩存塊寫入附加的磁盤中,磁盤數據以日志的方式進行組織,即所有的寫操作都是追加寫,最大程度上減小磁盤的尋道時延和旋轉時延.
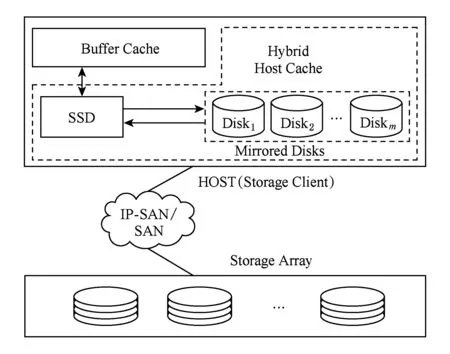
Fig. 1 Architecture of HHC圖1 HHC架構圖
HCC主要包含3個模塊:固態盤緩存管理模塊、磁盤日志管理模塊和故障處理模塊.固態盤緩存管理模塊主要用來響應上層應用程序的讀寫請求、管理緩存空間、緩存塊的狀態以及與后端存儲上的映射關系等;磁盤日志管理模塊負責管理磁盤上的日志空間,其功能主要包括日志的寫入、垃圾回收等;故障處理模塊負責當發生故障時,根據故障類型執行相應的故障恢復工作,保證存儲系統的數據一致性和持久性.
1.3固態盤緩存管理
固態盤緩存管理將固態盤分為2個區域,即元數據區和數據區.元數據區記錄緩存塊的狀態以及邏輯地址映射信息等,容量較小,通常可全部放入DRAM中以加速緩存查找.數據區用來存放緩存數據,以固定大小劃分,默認選用4 KB.該模塊對上主要提供3種操作:讀、寫和寫屏障操作.
對于讀請求,首先以請求的邏輯塊地址為關鍵字在緩存中查找是否命中,如命中則根據緩存元數據信息中的映射關系,從相應的緩存塊讀出完成讀操作;如不命中,則從后端存儲服務器讀取數據塊,并申請緩存塊寫入固態盤緩存,同時在內存中添加相應的元數據信息.對于寫請求,與讀請求類似,首先在緩存中查找,如果命中則寫入緩存,否則申請新的緩存塊將數據寫入并修改元數據信息.元數據信息被同步刷回到固態盤,使得即使客戶端重啟,緩存中的數據塊和其狀態仍然能夠正確恢復.事實上以上也是傳統的寫回法緩存處理流程.當申請緩存塊的時候,如果緩存塊已滿則需要進行緩存替換操作,為了減小緩存替換時的延遲時間,HHC采用LRU的方式優先替換干凈緩存塊以避免寫回操作.為了保證以上緩存替換過程的順利進行,在后臺執行臟數據塊刷回操作,使得SSD緩存中臟數據塊的數量不超過一定的閾值.刷回操作在后臺執行,并且根據負載密集程度調整優先級.當負載較輕或空閑時,提高刷回優先級使得更多緩存塊可用;當負載較重時,降低刷回優先級以減小對前臺應用I/O的影響.當刷回操作完成時,同時會向磁盤日志管理模塊發送相應的revoke通知,日志會記錄相應的撤銷塊,這種機制有利于日志盤的空間利用以及降低日志操作開銷.
另外,HHC對于寫操作增加了異步提交日志的操作.當數據寫入緩存的同時,并行地將其提交給磁盤日志管理模塊,該模塊負責將其異步地寫入磁盤以提供可靠性保證.HHC提供的另一個特殊的操作為寫屏障操作, 該操作將會觸發日志寫入操作,直到SSD緩存中的臟數據都被寫到磁盤寫屏障才會返回,這樣可以保證寫屏障操作的語義.即該操作完成后,保證所有數據持久化到存儲設備.為了保證異步提交日志機制的正確執行,HHC在SSD緩存塊元數據信息中加入了一個標記位Logged_Flag,表示該數據塊是否已提交給磁盤日志管理模塊.日志管理的具體流程將在1.4節給出.
需要注意的是,寫屏障操作并不會改變SSD緩存塊狀態,原來的臟緩存塊仍然保留臟塊的標記,否則可能會導致數據丟失而破壞寫屏障語義.例如,寫屏障操作使得臟緩存塊D被寫入HDD日志中,然后將其標記為干凈,隨后緩存塊D被替換出緩存,此時假如HDD出現故障,緩存塊D的數據將無法恢復.
1.4磁盤日志管理
為方便進行日志管理,磁盤采用如下組織方式:磁盤開頭存放日志超級塊,剩余部分被分成固定長度的段(segment),每個段有一個頭部(header)記錄該段日志的元數據信息.當采用多個磁盤時,由于采用鏡像方式,所以各個磁盤上的劃分是一樣的.磁盤日志管理主要包含2個方面:1)日志的寫入;2)日志的回收.日志的管理我們采用類似文獻[18]中Everest store的設計,但是根據新的應用場景進行了一些修改和優化.
1.4.1 關鍵數據結構
日志超級塊用來記錄日志的基本信息,如日志頭和尾的位置、日志塊大小、每個段的長度等.在HHC的設計中,日志超級塊主要是用來在故障恢復時定位日志起始位置,從而減少掃描日志所需要的時間,超級塊并不需要頻繁地持久化到磁盤,而只在系統空閑時間或周期性地寫入日志盤,因此并不會影響日志寫入的性能.日志段是真正存放日志數據塊的地方,分為段頭部和數據區,段的頭部主要包含6個字段:
1) SegmentID.當前的段號,編號從0開始.
2) SequenceID.表示該段的序列號,每當寫入新的日志段時,該值加1.
3) Barrier_Flag.當該日志段是針對寫屏障操作的最后一個日志段時,將該標記位置1.
4) Checksum.日志數據的校驗和,主要用來保證日志段的完整性,在恢復時可以根據校驗和判斷該日志段是否寫入成功.
5) Log_LBA_Table.記錄該段中日志塊對應的原來邏輯塊地址.例如,假如第1個日志塊對應的后端存儲的LBA(logicalblockaddress)為8192,那么Log_LBA_Table的第1項就寫入8192.
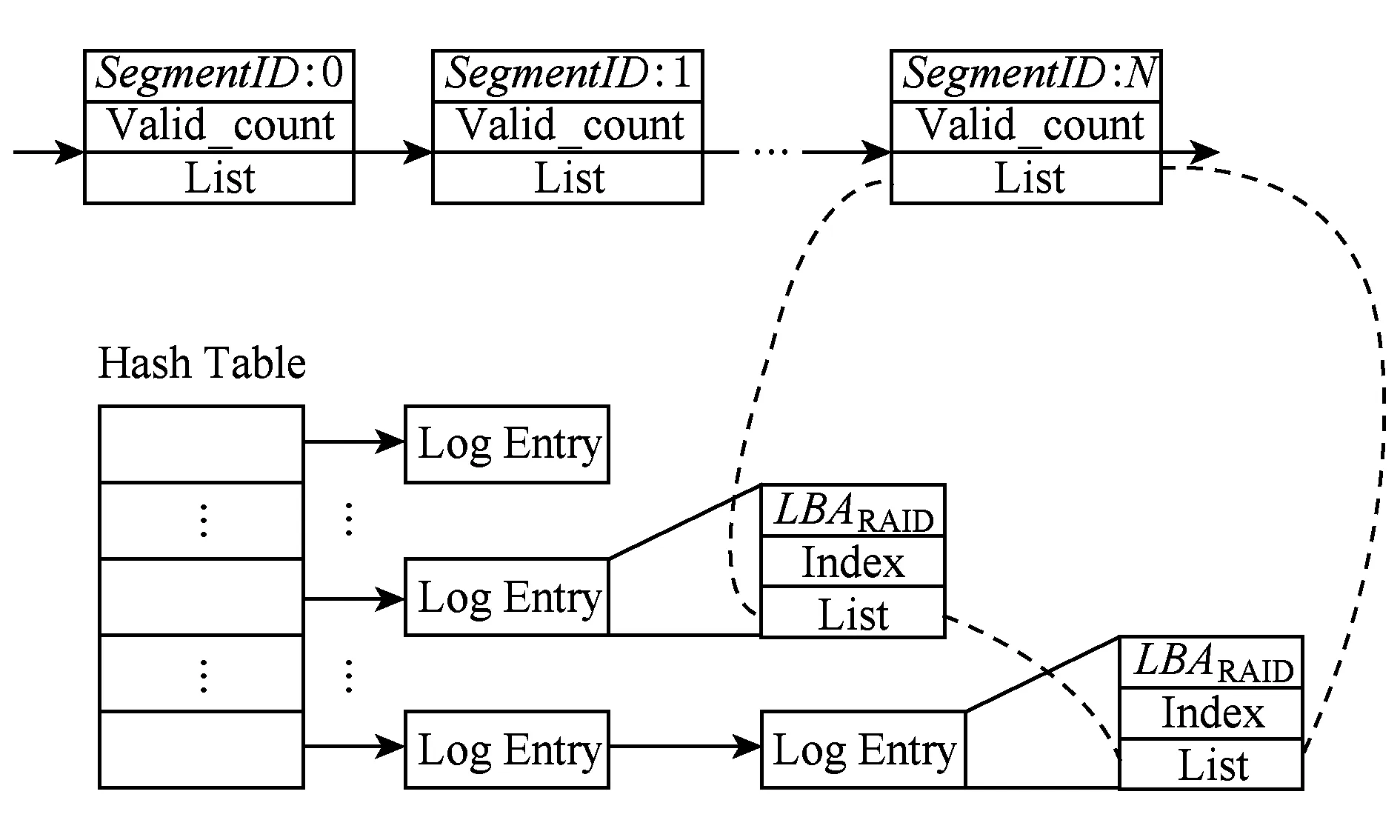
Fig. 2 In-memory structure for log blocks圖2 內存中的日志塊索引結構
HHC在內存中維護日志盤的當前狀態,如當前日志的起始和結束位置、當前日志段的序列號等.Log Entry結構記錄一個數據塊在日志中的位置,即所在日志的段和在數據區中的塊索引號.屬于相同日志段的Log Entry結構被串聯起來以方便日志回收.所有的Log Entry以Hash鏈表的方式組織起來,以加速日志塊的查找,如圖2所示.另外內存中維護一個緩沖池,用來緩沖新來的日志數據塊.緩沖池中包含多個緩沖區,每個緩沖區跟日志磁盤上的一個段大小一樣,緩沖區頭部對應日志段頭部,緩沖區數據區對應日志段中的數據塊.日志段大小設置存在一個權衡的問題.如果設置太小,則無法充分發揮磁盤大塊寫的帶寬優勢,而且會增加日志元數據的存儲開銷;如果設置過大,則當寫屏障請求到達時需要等待的時間可能會比較長,對于fsync操作密集的負載會增加訪問時延.因此管理員需要根據實際的負載特征使用合理的設置.
1.4.2 日志寫入
在進行日志寫入時,HHC首先將日志塊寫入到內存中的緩沖區,更新日志Hash表中相應的Log Entry結構,并且將SSD緩存數據塊元數據信息中的Logged_Flag標志位置1.當緩沖區寫滿或寫屏障請求到達時,將該緩存區寫入當前日志尾部對應的日志段,對于由寫屏障觸發的最后一個日志段需要將頭部的Barrier_Flag標記位置1,代表本次寫屏障操作完成,在日志恢復時需要用到該標記位.固態盤緩存臟數據的刷回操作會使得舊的日志塊無效,此時如果對應的日志塊尚處在內存緩沖區中,則只需要在內存中刪除該日志塊,否則將該日志塊對應RAID中的邏輯塊地址記錄到緩沖區中的Revoke_Table,最后將該塊對應的Log Entry從內存Hash表中刪除.注意,對緩沖區中的日志塊進行更改時可以在內存中進行原地更新,而為了避免產生隨機I/O增加時延,一旦緩沖區被持久化到日志段,HHC將不會對日志段進行更新操作,而是通過維護內存中的日志Hash表來記錄有效的日志塊信息.
由于緩沖池中包含多個緩沖區,當一個緩沖區在刷回磁盤時,新來的日志數據可以寫入另一個緩沖區,這樣的并行處理可以最大程度提高日志盤的寫入帶寬.盡管目前的SSD寫入帶寬高于磁盤,通常情況下,緩沖池中的數據仍然可以及時刷回到日志盤而不會造成緩沖池緊缺,原因主要有2個方面:1)SSD緩存盤作為讀寫緩存設備,其負載包含了讀和寫,再加上SSD的讀寫干擾問題[19]使得其寫帶寬遠達不到其飽和值;2)SSD的寫入操作主要有2部分組成:1)讀不命中時從后端存儲載入數據;2)寫入臟數據.而第1類寫操作并不產生日志數據,因此這也降低了日志數據的產生頻率.然而對于極端情況,比如當寫操作非常密集時,仍然有可能會造成緩沖池不足的情況,這時對于新來的日志數據并不做處理,當有空緩沖區時,從SSD緩存元數據中遍歷Logged_Flag=0的臟緩存塊,將其讀入日志緩沖區,隨后的操作與前面描述的一致.
1.4.3 日志回收
由于日志總是順序地追加到日志尾部,日志盤的可用空間會持續減小.而為了保證日志的順利寫入就需要在合適的時間進行日志回收操作.由于有效日志塊以Log Entry及Hash表方式存儲在內存,且相同日志段的日志塊被串聯在一起,HHC可以很方便地識別待回收的日志塊,加速日志回收過程.考慮到HHC只緩存SSD緩存中的臟數據等特點,我們將日志回收分為主動回收和被動回收2種.
主動回收是指將日志頭部的有效日志塊遷移到日志尾部從而釋放日志空間.與傳統的日志回收不同的是,HHC并不需要從日志磁盤中讀取數據,而是選擇從SSD緩存中讀取相應的數據塊.這是由HHC的日志管理機制決定的,因為當SSD中緩存塊變為干凈狀態時,會向日志管理模塊發送revoke通知,使得日志中對應的日志塊變無效,也就是說日志塊中的有效塊必然在SSD緩存中有相同的副本.這樣就可以充分利用SSD的讀優勢,而且避免了傳統日志回收對日志寫入的負面影響.
被動回收是指利用緩存本身的特點進行自我回收.其原理是考慮到日志管理的特點和負載特征.在HHC的日志管理中,有2種情況下會將之前的日志塊置無效,一種是SSD緩存塊的覆蓋寫,一種是周期性的臟塊刷回操作.最近寫入的數據位于更靠近日志尾部的日志段,而很久未被修改的臟數據位于更靠近日志頭部的段.這樣日志段事實上就形成一種天然的LRU排序方式.考慮到負載的局部性特征,通常緩存的刷回操作也采用LRU的方式進行,隨著將日志尾部所在日志段中的臟數據刷回后端緩存,日志頭部索引向尾部靠近,從而釋放日志空間.HHC充分利用緩存特點和日志管理模式,結合主動回收和被動回收2種方式,降低日志回收帶來的開銷.
1.5故障處理
HHC的特點之一就是混合緩存層的高可靠性.對于非設備故障如斷電重啟,由于固態盤緩存的元數據信息已經被持久化,因此不會影響數據的一致性.對于設備故障,如果是日志盤故障,同樣不影響數據的一致性,因為所有緩存數據仍然在SSD緩存中.
當固態盤失效時,需要從日志盤中恢復出最近一次寫屏障操作之前的所有臟數據,寫回到后端存儲.其恢復過程主要分3個步驟:
步驟1. 讀取日志盤的超級塊找到需要恢復的日志起始和結束位置.日志結束位置是指最近一次成功執行寫屏障操作的日志段,這是通過從日志頭順序掃描日志段頭部直到下一個SequenceID小于當前段,然后反向查找離該段最近的一個Barrier_Flag被置位的段并通過校驗和確保該段寫入完整,否則繼續往前查找.
步驟2. 根據讀上來的日志元數據信息,順序地從日志盤讀取相應的數據塊寫入后端存儲.
步驟3. 重新初始化將日志盤完成數據恢復工作.
如果SSD和所有HDD都失效,那么不可避免地會導致緩存數據的丟失.不過通過我們對HHC的可靠性分析可以發現,HHC的可靠性甚至高于后端存儲通常采用的RAID5/6,因此全部失效的概率是極低的.具體分析在第2節給出.
2 HHC可靠性分析
為了保證緩存數據不丟失,就需要使得緩存層盡可能地滿足高可靠性.HHC的一個設計原則就是保證混合緩存層的可靠性不低于后端存儲的可靠性.RAID5/6作為底層存儲廣泛應用于數據中心以及云存儲環境下,因此這里只對HHC和RAID5/6的可靠性進行定量分析和比較.
平均無數據丟失時間(MTTDL)作為一個重要的可靠性指標,被廣泛用來衡量存儲系統的可靠性.假設磁盤故障、固態盤故障以及修復過程是獨立的,且服從參數分別為λ,φ,μ的指數分布,通過構造Markov鏈可以方便地計算存儲系統的MTTDL.
設N為陣列中的磁盤數,RAID5的MTTDL計算為
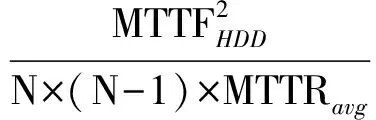
RAID6的MTTDL計算為
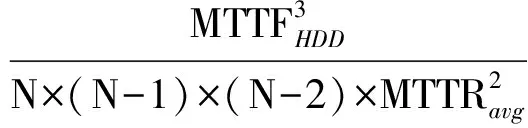
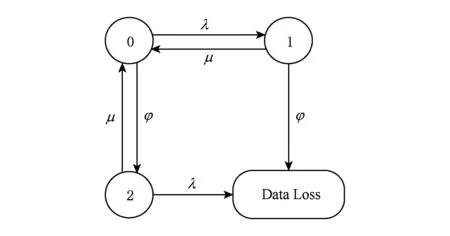
Fig. 3 State-transition probability diagram for HHC (M=1)圖3 HHC狀態遷移概率圖 (M=1)
為了計算HHC的MTTDL,首先假設磁盤數M=1,使用Markov模型構造狀態遷移概率圖,如圖3所示.狀態0表示磁盤和固態盤都正常工作;當磁盤失效時進入狀態1,若此時在恢復完成前固態盤失效則會導致緩存數據丟失;類似地處于狀態0時,當固態盤發生故障則進入狀態2,若在故障恢復前磁盤失效也會造成數據丟失.為描述該過程可通過構造Kolmogorov微分方程系統來實現[20]:
其中pi(t)代表HHC處于狀態i的概率,其初始條件為
對式(3)進行拉普拉斯變換得到:
由式(3)(4)最終得到HHC的MTTDL為
式(6)得到當磁盤數M=1時的MTTDL計算方法.當Mgt;1時,由于修復前平均時間(mean time to failure, MTTF)遠遠超過平均修復時間(mean time to repair, MTTR),可以用下面的方法近似計算出HHC的MTTDL.首先計算出M個磁盤作為整體的MTTDLMirror-M,那么該整體的故障率將服從參數為λ′的指數分布,將λ′代入式(6)即可得到新的MTTDL.這里僅以M=2為例給出計算過程,λ′的計算公式如下:
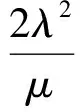
將式(6)中的λ替換為式(7)中得到的λ′即可得到MTTDLHHC-2,鑒于結果過于冗長,這里不給出推導后的公式,而是用圖來給出更為直觀的對比結果.參考目前主流設備的數據表(datasheet),實驗中使用的參數取值如表2所示.
圖4(a)中給出了使用一個磁盤時HHC與RAID5的MTTDL對比圖,為方便比較,圖4也給出了SSD設備的MTTF.圖4中x坐標軸表示后端RAID5陣列使用的磁盤數;y坐標軸表示故障修復平均需要的時間;z坐標軸代表最終計算出的MTTDL,該值越大代表可靠性越高.從圖4中可以看出,SSD的可靠性最低,遠低于后端存儲,這也再次證實了提高緩存可靠性的必要性;RAID5的可靠性隨磁盤數的增加而下降;隨著平均修復時間的增加,HHC和RAID5的可靠性都有所下降,但是可以清晰地看到,HHD的可靠性始終遠高于RAID5(注意圖4中的z軸使用的是對數坐標).圖4(b)給出了使用2塊磁盤做鏡像時HHC與RAID6的MTTDL對比圖.可以看到與圖4(a)類似地趨勢,HHC-2的可靠性遠遠超過了RAID6,而隨著后端磁盤數的增加,優勢會更加明顯.

Table 2 Main Parameters for Reliability Analysis表2 可靠性分析中的主要參數表
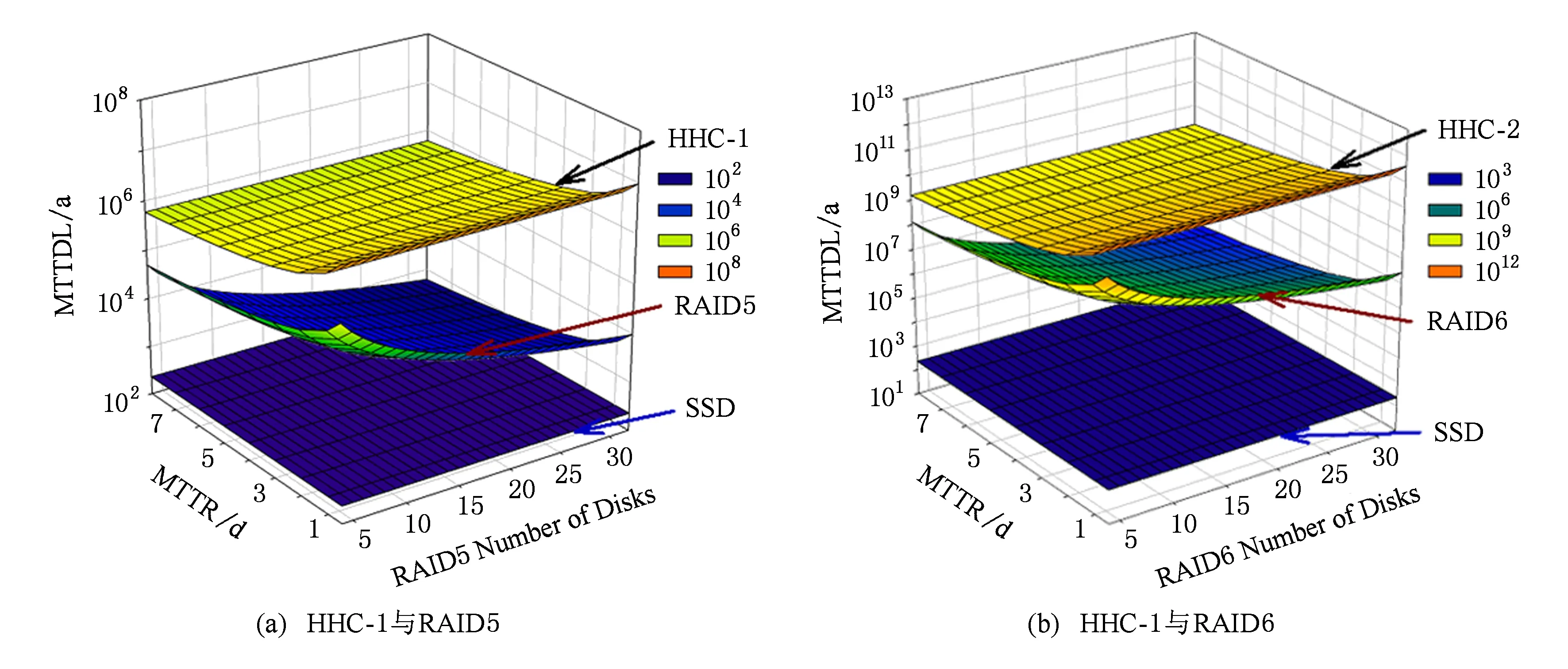
Fig. 4 MTTDL Comparison of HHC and RAID5/6圖4 HHC與RAID5/6的MTTDL對比
3 實驗結果與分析
我們在Linux系統中實現了HHC緩存架構內核模塊,使用LRU替換算法,支持基本的寫直達法(WT)、寫回法(WB)以及本文提出的緩存策略(WB-HHC).同時實現了最近提出的Write-back Flush(WB-Flush)緩存策略.使用通用測試工具對比測試在不同負載環境下各種緩存策略所能提供的性能.為了展示緩存在網絡存儲環境中帶來的優勢,實驗也給出不使用SSD緩存Raw時的性能作為對比.由于HHC中磁盤是以鏡像方式組織的,日志采用完全并行的方式寫入,使用兩塊盤的時候僅對可靠性帶來提升,對性能并沒有太大影響,因此在本節實驗部分只對單磁盤架構下的HHC進行性能測試.
3.1實驗環境及測試方法
測試平臺主要由2部分構成,即存儲客戶端(host)和存儲服務端(server),通過1 GB以太網連接.Host配備2個2.4 GHz的Intel Xeon E5620 CPU,1塊120 GB的SATA接口SSD作為緩存,2塊1 TB SATA2接口的HDD,其中1塊安裝CentOS release 5.4系統,另外1塊HDD與SSD一起構成混合緩存.存儲客戶端使用3.12.9內核版本.為了減少Host端操作系統的頁高速緩存帶來的影響,我們將其內存設置為512 MB或1 GB.存儲服務端配備2個2.13 GHz的Inter Xeon E5606 CPU,16 GB內存.5塊1TB的HDD使用Linux的MD模塊構成軟RAID5通過iSCSI為存儲客戶端提供存儲服務.為了體現陣列的真實性能,存儲服務端禁用緩存.
存儲客戶端使用iSCSI發起程序將target端連接到本地,并格式化成Ext4文件系統,使用ordered日志模式.為了測試在不同負載下的性能,我們使用Filebench生成不同類型的負載.主要使用3種測試負載:websearch, fileserver, varmail,分別代表讀負載密集型、寫負載密集型以及同步操作密集型(fsync操作).websearch代表Web服務器的負載,讀寫比例設置為10∶1,文件平均大小為16 KB,文件數為100 000工作集大約為1.6 GB.本實驗中該負載使用40個線程并發進行I/O操作,包括隨機讀取整個文件,追加寫入日志文件,追加塊平均大小也為16 KB.fileserver模擬多用戶的文件服務器負載,每個用戶對應到一個測試線程,獨立地訪問屬于該用戶的目錄,主要操作包括創建、刪除、讀、寫等.其讀寫比例為1∶2,本實驗采用的負載大小約為2.2 GB.varmail模擬電子郵件服務器的負載,與Postmark類似,但Filebench使用多線程的方式進行一系列操作,主要包括讀整個文件、追加寫以及頻繁的fsync操作,本實驗中其工作集大小設置約為1.6 GB.以下每次測試時間為15 min,每項測試都執行3次取平均,測試指標為吞吐率(IOPS).如果參數有所改變,會在相應地方給出說明.
3.2不同負載下的性能及分析
我們在SSD上劃分4 GB空間作為緩存,圖5顯示使用3種負載以及使用不同緩存策略的性能.其中Raw代表不使用緩存,WB表示寫回法,WT表示寫直達法,這3種緩存策略作為基準.WB-HHC是本文提出的緩存策略,WB-Flush作為最近提出的一種提供可靠性保證的緩存策略,是我們主要的對比對象.
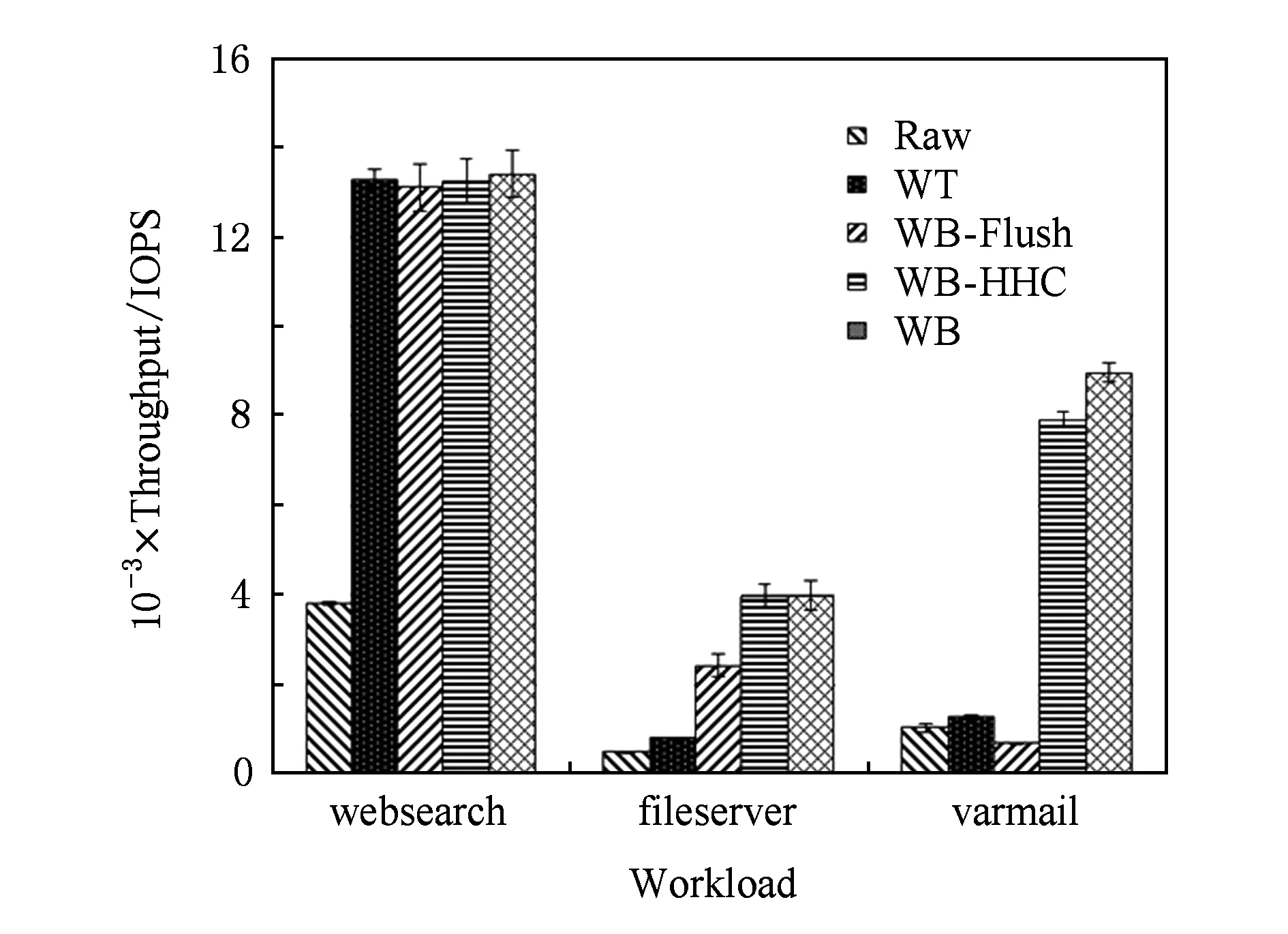
Fig. 5 IOPS under different caching policies圖5 不同緩存策略的IOPS
從圖5可以看出,由于SSD的速度優勢,使用SSD緩存確實能帶來明顯的性能提升.對于websearch負載來說,由于其主要以讀請求為主,因此5種緩存策略性能幾乎沒有差異.當使用fileserver負載時,WB-HHC的性能比WT和WB-Flush分別提高了388.2%和63.1%.這是由于fileserver負載中寫操作比較多,使得緩存中累積大量的臟數據,EXT4周期性的commit會觸發寫屏障操作,從而使得WB-Flush從SSD中讀出所有臟數據寫回RAID5陣列.這部分開銷使得其性能低于WB.WB-HHC異步地將臟數據順序寫入本地磁盤日志,大大緩解了WB-Flush中的寫屏障開銷,使得其性能基本上可以達到WB的水平.在varmail負載中,可以看到WB-Flush的性能甚至低于Raw和WT,分析發現這主要是因為varmail使用大量的線程并發操作,且使用了大量的fsync操作,這就使得寫屏障操作非常密集.而對于寫Raw和WT來說,臟數據會直接從內存寫入到RAID5,而WB-Flush則需要先從SSD讀出,然后寫入后端陣列,由于頻繁的fsync使得這部分開銷無法被忽略.盡管WB-HHC也受到一些影響,但是相對于WT和WB-Flush分別提高了5.1倍和10.2倍.
3.3緩存大小對性能的影響
緩存策略與緩存大小有關,本節使用fileserver負載來深入理解不同緩存大小對性能帶來的影響.考慮到實際環境下的DRAM/SSD容量比,本實驗中客戶端內存大小設置為512 MB,緩存大小為1~3 GB,負載為2.2 GB.從圖6的測試結果可以看出,隨著緩存的增加,IOPS逐漸增高,當緩存達到2 GB以上時性能趨于飽和;隨著緩存的增加,WB-Flush相對WT有著越來越明顯的性能優勢,因為延遲的刷回操作減少了對前臺寫操作的影響;然而WB-HHC在不同緩存大小下的性能仍然能夠接近WB策略,相對于WT性能提高了75.4%~355.6%,比WB-Flush提高了48.2%~173.4%.
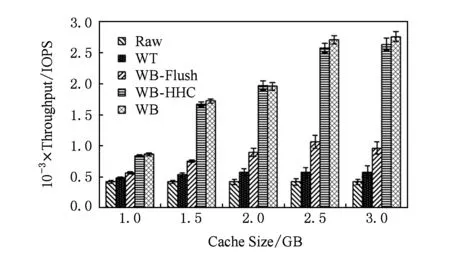
Fig. 6 Sensitivity to different cache sizes圖6 不同緩存大小對性能的影響
3.4負載強度對性能的影響
本節討論不同的負載強度對緩存策略帶來的影響.為此我們使用同步密集型的varmail負載,通過調整負載的并發線程數來模擬不同強度的郵件訪問場景.考慮到一般郵件服務器的工作集不會太大,實驗中使用的負載大小約為1.6 GB,緩存大小設置為4 GB,客戶端內存設置為512 MB.圖7顯示了負載線程數從2~32時不同緩存策略的測試結果.
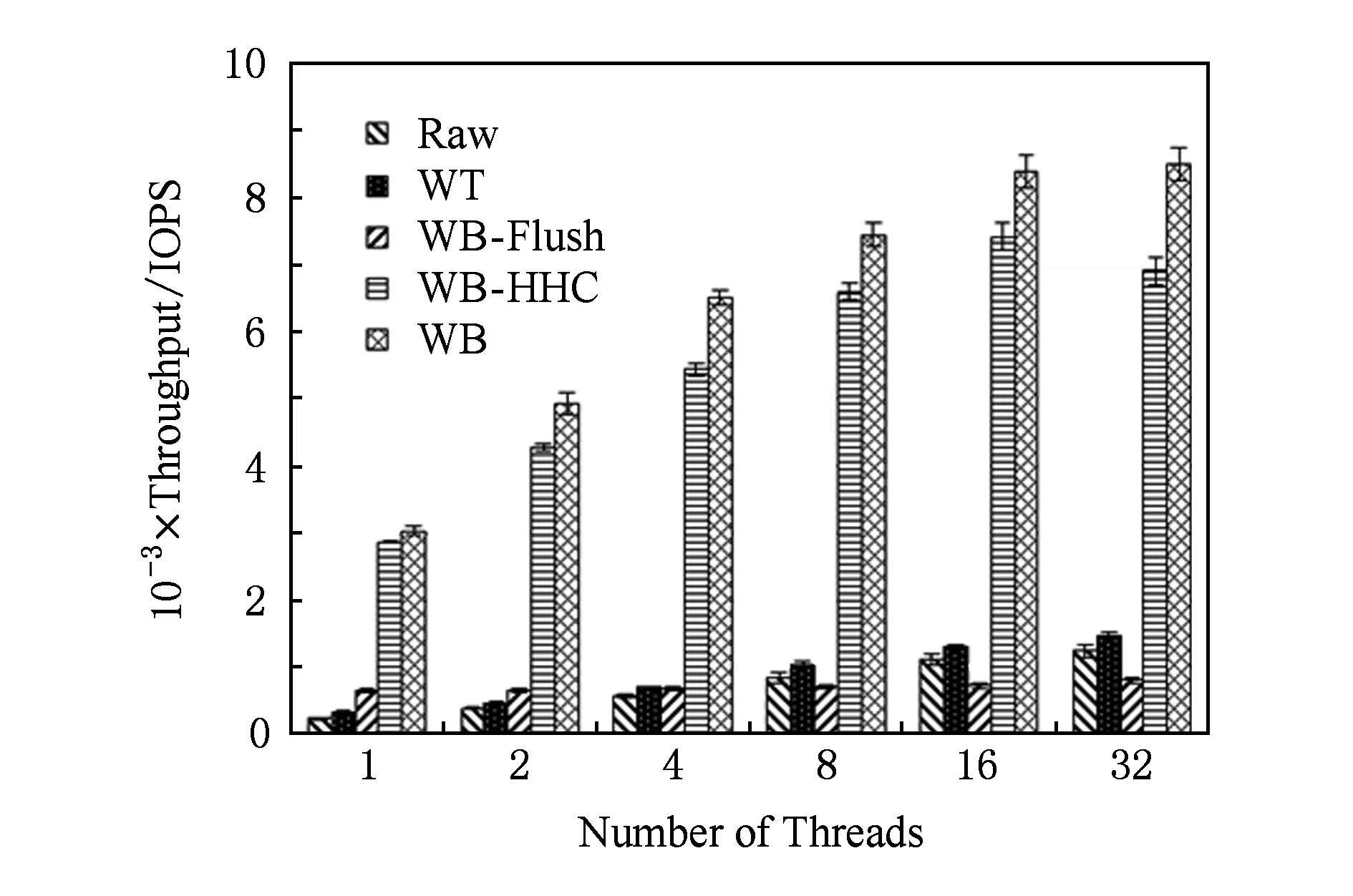
Fig. 7 Sensitivity to different number of threads圖7 不同線程數對性能的影響
從圖7中可以看出,隨著線程數的增加各種緩存策略的性能也有所增加,然而WB-Flush的增加幅度小于其他緩存策略,這使得在負載較重時(線程數不低于8),其性能甚至低于WT和Raw.其原因是大量的fsync操作導致密集的寫屏障,WB-Flush需要頻繁地從SSD讀取臟數據寫入RAID5,增加了fsync操作的延時,這種開銷隨著負載強度的增加會愈加明顯.對于WB-HHC來講,頻繁的寫屏障操作使得臟數據在內存中的聚集時間變短,降低了日志盤批量寫回的優勢,因此隨著線程數的增加,WB-HHC與WB的差距會愈發明顯.但是相比于WT和WB-Flush,WB-HHC的性能分別提高了3.7~8.2倍和5.5~9.1倍.
3.5HHC內存開銷分析
HHC的內存開銷主要來自于2個方面:固態盤緩存在內存中的元數據信息;用于日志管理的額外的內存開銷.
1) 所有緩存策略所共有的、對于4 KB緩存塊大小而言,每個緩存塊在內存中的元數據信息主要包括其在固態盤及磁盤陣列中的邏輯塊地址、緩存塊狀態以及用于索引結構的指針等,一共約20 B,因此其內存開銷與固態盤容量的比例約為0.49%.
2) 內存開銷主要來源于日志塊索引(如圖2所示),由于HHC只在內存中維護有效日志塊信息,其數量等同于固態盤中臟緩存塊的個數(通常被限制在一定閾值之內,如不超過緩存塊總量的30%),而每個Log Entry的大小約為10 B,因此其內存開銷約為固態盤緩存容量的0.07%.從以上分析可以看出,HHC的總內存開銷約為固態盤緩存總容量的0.56%,盡管相比其他算法略有增加,但是在現代存儲系統中仍然是可以接受的.
4 結束語
現代數據中心普遍使用固態盤作為緩存加速對網絡存儲系統的訪問,寫直達法可以嚴格保證數據的一致性,但對于寫操作較多的負載,其性能遠低于寫回法.作為改進寫回法的Write-back Flush策略將存儲系統的寫屏障語義引入SSD緩存層,來保證數據的一致性和持久性,然而實驗發現對于同步操作密集型的負載,如郵件服務器,其性能甚至低于寫直達法.本文使用SSD和廉價的HDD構成混合客戶端緩存,避免了SRC帶來的高成本,同時降低了寫屏障操作的時延,實驗結果證實了HHC的優越性.
[1]Chen P, Lee E, Gibson G, et al. RAID: High-performance, reliable secondary storage[J]. ACM Computing Surveys, 1994, 26(2): 145-185
[2]Zhang Guangyan, Zheng Weimin, Li Keqin. Rethinking RAID-5 data layout for better scalability[J]. IEEE Trans on Computers, 2012, 61(11): 2816-2828
[3]Hensbergen V, Zhao Ming. Dynamic policy disk caching for storage networking[R]. Austin, TX: IBM, 2006
[4]Byan S, Lentini J, Madan A, et al. Mercury: Host-side flash caching for the data center[C]Proc of IEEE MSST’12. Piscataway, NJ: IEEE, 2012: 37-48
[5]Saab P. Releasing flashcache: Facebook blog[OL]. 2010 [2016-07-09]. https:www.facebook.comnotesmysql-at-facebookreleasing-flashcache388112370932
[6]Leung A, Pasupathy S, Goodson G, et al. Measurement and analysis of large-scale network file system workloads[C]Proc of USENIX ATC’08. Berkeley, CA: USENIX Association, 2008: 213-226
[7]Koller R, Rangaswami R. IO deduplication: Utilizing content similarity to improve IO performance[C]Proc of USENIX FAST’10. Berkeley, CA: USENIX Association, 2010: 211-224
[8]Roselli D, Anderson T. A comparison of file system workloads[C]Proc of USENIX ATC’00. Berkeley, CA: USENIX Association, 2000: 41-54
[9]Arteaga D, Zhao Ming. Client-side flash caching for cloud systems[C]Proc of the 7th ACM SIGOPS Int Systems amp; Storage Conf. New York: ACM, 2014: 7:1-7:11
[10]Oh Y, Choi J, Lee D, et al. Improving performance and lifetime of the SSD RAID-based host cache through a log-structured approach[C]Proc of the 1st Workshop on Interactions of NVMFLASH with Operating Systems and Workloads. New York: ACM, 2013: 5:1-5:8
[11]Balakrishnan M, Kadav A, Prabhakaran V, et al. Differential RAID: Rethinking RAID for SSD reliability[C]Proc of the 5th European Conf on Computer System. New York: ACM, 2010: 15-26
[12]Jeremic N, Muhl G, Busse A,et al. The pitfalls of deploying solid-state drive RAIDs[C]Proc of the 4th Annual Int Conf on Systems and Storage. New York: ACM, 2011: 14:1-14:13
[13]Koller R, Marmol L, Rangaswami R, et al. Write policies for host-side flash caches[C]Proc of the 11th USENIX FAST’13. Berkeley, CA: USENIX Association, 2013: 45-58
[14]Qin Dai, Brown D, Goel A. Reliable writeback for client-side flash caches[C]Proc of USENIX ATC’14. Berkeley, CA: USENIX Association, 2014: 451-462
[15]Fedora Documentation. Write barriers[OL]. [2016-05-21]. http:docs.fedoraproject.orgen-US-Fedora14htmlStorage_Administration_ Guidewritebarr.html
[16]Amvrosiadis G. Filebench: A model based file system workload generator[CPOL]. 2011[2015-11-11]. https:github.comfilebenchfilebench
[17]Mao Bo, Jiang Hong, Wu Suzhen, et al. HPDA: A hybrid parity-based disk array for enhanced performance and reliability[J]. ACM Trans on Storage, 2012, 8(1): 1-20
[18]Narayanan D, Donnelly A, Rowstron A. Write off-loading: Practical power management for enterprise storage[C]Proc of USENIX FAST’08, Berkeley, CA: USENIX Association, 2008: 253-267
[19]Chen F, Koufaty D A, Zhang X. Understanding intrinsic characteristics and system implications of flash memory based solid state drives[C]Proc of ACM SIGMETRICS’09. New York: ACM, 2009: 181-192
[20]Paris J, Amer A, Long D. Using storage class memories to increase the reliability of two-dimensional RAID arrays[C]Proc of the 17th Annual Meeting of the IEEEACM Int Symp on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems. Piscataway, NJ: IEEE, 2009: 1-8

LiChu, born in 1989. PhD in computer architecture from Huazhong University of Science and Technology, China. His main research interests include RAID system and flash memory.

FengDan, born in 1970. PhD, professor, PhD supervisor. Senior member of CCF. Her main research interests include computer architecture, massive storage systems, and parallel file systems.

WangFang, born in 1972. PhD, professor. Member of CCF. Her main research interests include distribute file systems, parallel I/O storage systems and graph processing.
AHighPerformanceandReliableHybridHostCacheSystem
Li Chu, Feng Dan, and Wang Fang
(Wuhan National Laboratory for Optoelectronics (Huazhong University of Science and Technology), Wuhan 430074) (Key Laboratory of Information Storage System (Huazhong University of Science and Technology), Ministry of Education, Wuhan 430074)
Modern date centers widely use network storage systems as shared storage solutions. Storage server typically deploys the redundant array of independent disks (RAID) technique to provide high reliability, e.g., RAID56 can tolerate onetwo disk failures. Compared with traditional hard disk drives (HDDs), solid-state drives (SSDs) have lower access latency but higher price. As a result, client-side SSD-based caching has gained more and more popularity. Write-back policy can significantly accelerate the storage IO performance, however, it fails to ensure date consistency and durability under SSD failures. Write-though policy simplifies the consistence model, but fails to accelerate the write accesses. In this paper, we design and implement a new hybrid host cache (HHC). HHC selectively stores mirrored dirty cache blocks into HDDs in a log-structured manner, and utilizes the write barrier to guarantee the data consistency and durability. Through reliability analysis, we show that the HHC layer has much longer mean time to data loss (MTTDL) than the corresponding backend storage array. In addition, we implement a prototype of HHC and evaluate its performance in comparison with other competitors by using Filebench. The experimental results show that under various workloads, HHC achieves comparable performance compared with the write-back policy, and significantly outperforms the write-through policy.
solid-state drive (SSD); host cache; cache management; reliability; performance
2016-11-02;
2017-02-06
國家“八六三”高技術研究發展計劃基金項目(2015AA015301);國家自然科學基金項目(61472153,61402189,61502191)
This work was supported by the National High Technology Research and Development Program of China (863 Program) (2015AA015301) and the National Natural Science Foundation of China (61472153, 61402189, 61502191).
馮丹(dfeng@hust.edu.cn)
TP334
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
汽車維護與修理(2016年10期)2016-07-10 08:17:41
鐵道通信信號(2016年4期)2016-06-01 12:10:19
電測與儀表(2016年5期)2016-04-22 01:13:50
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年8期)2015-04-17 03:32:52
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維修與保養(2015年7期)2015-04-17 02:12:40
汽車維修與保養(2015年2期)2015-04-17 01:30:34
汽車維護與修理(2015年2期)2015-02-28 12:15:39
