一種基于大規(guī)模知識庫的語義相似性計算方法
2017-12-08 05:59:22張立波孫一涵羅鐵堅
計算機(jī)研究與發(fā)展 2017年11期
張立波 孫一涵 羅鐵堅
1(中國科學(xué)院軟件研究所 北京 100190) 2(中國科學(xué)院大學(xué) 北京 101408)
(zsmj@hotmail.com)
一種基于大規(guī)模知識庫的語義相似性計算方法
張立波1孫一涵2羅鐵堅2
1(中國科學(xué)院軟件研究所 北京 100190)2(中國科學(xué)院大學(xué) 北京 101408)
(zsmj@hotmail.com)
人類知識總量不斷增加,依靠人類產(chǎn)生的結(jié)構(gòu)化大數(shù)據(jù)進(jìn)行語義分析在推薦系統(tǒng)和信息檢索等領(lǐng)域都有著重要的應(yīng)用.在這些領(lǐng)域中,首要解決的問題是語義相似性計算,之前的研究通過運(yùn)用以維基百科為代表的大規(guī)模知識庫取得了一定突破,但是其中的路徑并沒有被充分利用.研究基于人類思考方式的雙向最短路徑算法進(jìn)行單詞和文本的相似性評估,以充分利用知識庫中的路徑信息.提出的算法通過在維基百科中抽取出顆粒度比詞條更細(xì)密的節(jié)點(diǎn)之間的超鏈接關(guān)系,并首次驗證了維基百科之間的普遍連通性,并對2個詞條之間的平均最短路徑長度進(jìn)行評估.最后,在公開數(shù)據(jù)集上進(jìn)行的實(shí)驗結(jié)果顯示,算法在單詞相似度得分上明顯優(yōu)于現(xiàn)有算法,在文本相似度的得分上趨于先進(jìn)水平.
大規(guī)模知識庫;語義相似性;維基百科;最短距離;連通性
利用計算機(jī)進(jìn)行語義相似度評估是人工智能領(lǐng)域的一個瓶頸問題,這個問題的核心是如何讓計算機(jī)模擬人類的思考方式.然而人類思維模式復(fù)雜,難以模仿,但一個基本事實(shí)是,人類的思考模式是基于自身的經(jīng)歷和經(jīng)驗所形成的知識來進(jìn)行推理、分析和決斷.因此,利用大規(guī)模的知識庫賦予計算機(jī)一種類似人類的知識結(jié)構(gòu)模型,是一個根本的解決途徑.人類根據(jù)自身掌握的知識進(jìn)行聯(lián)想,對2個單詞、段落或文本之間的相似性進(jìn)行判斷,本文通過提取維基百科中的雙向最短路徑來模擬人類的聯(lián)想機(jī)制進(jìn)行相似性評估.
語義相似度在自然語言處理和信息檢索領(lǐng)域中一直都有著重要的應(yīng)用,例如問答系統(tǒng)、拼寫檢查、文本翻譯等領(lǐng)域[1].傳統(tǒng)方法主要基于單詞重疊度來評估語義相關(guān)性,這在論文查重系統(tǒng)中有著廣泛應(yīng)用,但如果使用不同的單詞表示同樣的含義時,這類方法明顯無法適用,它的缺陷在于簡單地將單詞作為評估對象,而沒有考慮單詞之間的內(nèi)在聯(lián)系[2].概率潛在語義分析等方法利用了文章中的單詞和主題的關(guān)系,但是沒有考慮到單詞在知識結(jié)構(gòu)中的關(guān)系[3].近些年來,一些新的算法考慮到可以利用包含人類知識結(jié)構(gòu)的大規(guī)模知識庫,例如百科全書和語料庫進(jìn)行語義相似性評估[4],具體來說,它們利用百科中2個詞條頁面中包含的文本和鏈接捕獲真實(shí)世界的知識結(jié)構(gòu),進(jìn)而評估語義相似度.
在人類編撰形成的知識庫中,大英百科全書和維基百科全書最具有代表性,它們經(jīng)過人工的梳理和編輯,構(gòu)成以詞條為單位的人類知識寶庫.相比大英百科,維基百科在保證了同等正確率的同時,包含了更多的詞條量.我們將維基百科詞條中含有鏈接的單詞稱為節(jié)點(diǎn),節(jié)點(diǎn)之間的最短路徑能夠反映出人類聯(lián)想機(jī)制,為了驗證這一點(diǎn),我們提出了一種基于最短路徑對語義相關(guān)性進(jìn)行評估的算法.與之前的算法不同,本文第1次對維基百科中詞條之間的連通性進(jìn)行驗證,證明了維基百科中的詞條具有普遍聯(lián)系,2個節(jié)點(diǎn)之間一定存在一條通路,即從一個概念出發(fā),經(jīng)過有限次數(shù)的跳轉(zhuǎn)鏈接可以到達(dá)另一個任意節(jié)點(diǎn).在相關(guān)的研究論文中,研究者假設(shè)任意2個詞條之間都可以建立路徑關(guān)系,但是缺乏證明;最新的一些論文使用隨機(jī)游走算法尋找路徑,而我們使用了最短路徑.傳統(tǒng)的有關(guān)最短路徑的算法是基于詞條所屬分類間的最短路徑,而我們使用了更細(xì)密的節(jié)點(diǎn);大部分對維基進(jìn)行的研究都將其限定在100萬節(jié)點(diǎn)左右,而我們使用了1 200萬節(jié)點(diǎn)進(jìn)行更加細(xì)致的探究.本文提出了一種基于維基百科節(jié)點(diǎn)的最短路徑進(jìn)行語義相似性分析的算法,并驗證了通過最短路徑能夠模擬人類的聯(lián)想機(jī)制對語義相似性進(jìn)行評估.
1 相關(guān)工作
傳統(tǒng)語義關(guān)系的分析需要依靠人類自身知識和經(jīng)驗的背景進(jìn)行推理和聯(lián)想,而這對計算機(jī)一直是難以克服的障礙.為了探索2個詞條之間的關(guān)系,計算機(jī)必須獲取大量相關(guān)領(lǐng)域的背景知識,而之前的相關(guān)工作更多地依靠統(tǒng)計而忽略了背景知識;另外一些基于背景知識進(jìn)行語義相關(guān)的研究由于知識總量的限制無法取得很好的效果;一些論文基于網(wǎng)頁鏈接對語義進(jìn)行分析,取得了一定的突破,但是由于網(wǎng)頁中的知識顆粒度較粗,并且知識含量較為稀疏,因此不能夠反映出某個知識點(diǎn)的全貌.2005年,Giles[5]指出,維基百科的廣度和深度都值得信任,從此之后,開啟了基于維基百科進(jìn)行語義分析的熱潮.
本文系統(tǒng)地收集了在維基百科的基礎(chǔ)上提出的利用人類知識庫進(jìn)行語義分析的方法,如表1所示.傳統(tǒng)的方法主要有2類:1)基于內(nèi)容的方法;2)基于鏈接的方法.Gabrilovich等人[6]提出一種名為顯示語言分析的方法,這種方法通過維基百科收集概念,將文本中的內(nèi)容與收集的概念建立矩陣關(guān)系,但缺乏對人類知識體系的使用.Zesch等人[7]證明了使用維基百科能夠提高之前方法的效果,但性能的提升受到制約.Hassan等人[8]衡量2個概念之間的跨越關(guān)系,并通過顯示語言分析來建立概念的矢量表述.Syed等人[9]將維基百科詞條作為本體,使用3種方式將關(guān)鍵詞、主題與文本結(jié)合,但是缺乏對詞條路徑關(guān)系的考慮.Coursey等人[10]建立了概念和分類關(guān)系圖,提出了一個自動化的主題分類方法,但是無法解決分類數(shù)量有限和概念從屬多種分類的問題.Gabrilovich等人[11]通過建立一個語義轉(zhuǎn)換器對概念建立權(quán)重矢量,并通過矢量之間的比較進(jìn)行語義相關(guān)性評估,這種方法僅基于文本內(nèi)容,在概念之間的關(guān)系上只考慮了所屬分類之間的關(guān)系,而忽視了超鏈接形成的路徑.
另外一些研究,利用路徑信息進(jìn)行語義相似度評估,例如Ponzetto等人[12]將概念映射到所屬的分類中,通過2個分類之間的路徑長度對2個概念的相關(guān)性進(jìn)行評估,但是分類之間的路徑關(guān)系僅僅是簡單的樹形結(jié)構(gòu).Milne等人[13-16]通過計算詞條所包含鏈接的重復(fù)率進(jìn)行相關(guān)性評估,這種方法無法對概念之間的關(guān)系進(jìn)行精確計算.與Yeh等人[14]的方法類似,有研究者提出了一種基于維基漫步方法, Yazdani等人[4]提出一種訪問概率的方法來計算節(jié)點(diǎn)之間的距離,這種方法僅僅基于概念所屬分類的路徑關(guān)系,或者是特定2個詞條包含超鏈接的重疊性.劉均等人[17]設(shè)計了一種利用維基百科鏈接關(guān)系的13維特征適量來進(jìn)行關(guān)系抽取,但是缺乏對節(jié)點(diǎn)之間通路的考慮.Singer等人[18]使用了一種維基游戲,通過人們的點(diǎn)擊來尋找2個詞條之間的路徑關(guān)系,然而由于游戲的特殊性質(zhì),會對參與測試的人們造成時間壓力,因此無法準(zhǔn)確模擬人類的思考模式.Niebler等人[19]注意到了無約束航行數(shù)據(jù),維基百科點(diǎn)擊流數(shù)據(jù)[20]記錄了人們在一個維基詞條中如何進(jìn)行下一次鏈接點(diǎn)擊.Dallmann等人[15]基于這個數(shù)據(jù)集,使用隨機(jī)游走的算法模擬了人類的超鏈接點(diǎn)擊行為,但是隨機(jī)游走往往無法獲取最佳路徑,而最短路徑才對人類的決策最有意義.
與傳統(tǒng)方法中利用詞條中的鏈接關(guān)系不同,我們通過尋找2個節(jié)點(diǎn)之間的鏈接通路,來描述它們之間的關(guān)系.本文提出一種新的方法,通過結(jié)構(gòu)化的維基百科節(jié)點(diǎn)中的最短路徑關(guān)系,對2個詞條之間的關(guān)系進(jìn)行刻畫.
2 主要工作
2.1預(yù)處理
互聯(lián)網(wǎng)百科全書是當(dāng)前能夠隨意查閱的最大的、最完整的人類知識庫,其中維基百科是人類共同參與編撰的規(guī)模最大的互聯(lián)網(wǎng)多語言百科全書,其與專業(yè)人士編撰的大英百科全書具有相近的正確率,但由于編撰自由,發(fā)展更加迅速.截至2016年7月25日,英文維基百科總計擁有5 201 640篇文章、39 827 021個頁面,覆蓋了人類的大部分知識領(lǐng)域,詞條為最小知識單元,以鏈接跳轉(zhuǎn)表現(xiàn)知識之間的聯(lián)系.維基百科本身的鏈接結(jié)構(gòu)是人類經(jīng)過時間積累的智慧結(jié)晶,編撰結(jié)構(gòu)和人類的思考方式高度吻合,因此本文選取維基百科作為基本數(shù)據(jù)集.我們使用原始數(shù)據(jù)集是完整的維基百科版本(2016-06-01),解壓后得到一個53.4 GB的XML文件.這個XML文件包含了所有的詞條,而每個詞條中都包含了指向其他詞條的超鏈接.傳統(tǒng)的算法主要關(guān)注詞條之間的關(guān)系,而我們希望能從更小的維度進(jìn)行觀察,本文將每個詞條中的超鏈接對應(yīng)的單詞作為研究對象,稱之為節(jié)點(diǎn), 該數(shù)據(jù)集包含了所有節(jié)點(diǎn)之間的鏈接關(guān)系.我們處理后所使用的節(jié)點(diǎn)數(shù)量為1 200萬,這是傳統(tǒng)算法中研究對象數(shù)量的5~10倍.
本文的預(yù)處理工作主要包括5個步驟:
1) 在原始XML文件中,先抽取詞條本身和其文本中超鏈接對應(yīng)的單詞.這個數(shù)量遠(yuǎn)大于詞條, 我們稱之為節(jié)點(diǎn).
2) 規(guī)整詞條格式,在節(jié)點(diǎn)中去除不合法的鏈接和詞條,例如詞條包含的錨鏈接等.
3) 刪除空指向的詞條.
4) 因為文件中有些節(jié)點(diǎn)首字母為小寫,而在維基百科網(wǎng)頁中,全部詞條的首字母均為大寫,因此將文檔中節(jié)點(diǎn)的小寫首字母轉(zhuǎn)化為大寫.
5) 在節(jié)點(diǎn)構(gòu)成的網(wǎng)絡(luò)中,用Hadoop集群將單項鏈接轉(zhuǎn)化為雙向鏈接,即把鏈接構(gòu)成的有向圖轉(zhuǎn)化為無向圖.
2.2節(jié)點(diǎn)普遍聯(lián)系的驗證
在基于路徑的語義分析的研究中,利用超鏈接尋找從一個詞條到另一個詞條的通路,都是建立在存在通路的假設(shè)前提下.雖然根據(jù)經(jīng)驗可以基本判斷維基百科的詞條間應(yīng)該是普遍連通的,但是缺乏有力驗證.我們在預(yù)處理的基礎(chǔ)上對維基百科中節(jié)點(diǎn)的普遍聯(lián)系進(jìn)行驗證,利用廣度優(yōu)先搜索算法在節(jié)點(diǎn)構(gòu)成的無向圖中生成連通分量.
我們獲得了節(jié)點(diǎn)中連通分量的分布,如表2所示,維基百科中節(jié)點(diǎn)構(gòu)成的網(wǎng)絡(luò)中,一共包含10 441個連通分量,這些連通分量一共含有12 280 497個節(jié)點(diǎn).其中最大聯(lián)通分量中含有12 269 222個節(jié)點(diǎn),可以清楚地看出,99.91%的節(jié)點(diǎn)都包含在最大聯(lián)通分量中.經(jīng)過觀察,其他聯(lián)通分量包含的節(jié)點(diǎn)是一些特殊字符,因此我們將最大聯(lián)通分量視為研究對象.這就意味著,如果我們將整個維基百科網(wǎng)絡(luò)視為無向圖,任意2個節(jié)點(diǎn)之間都存在著通路.
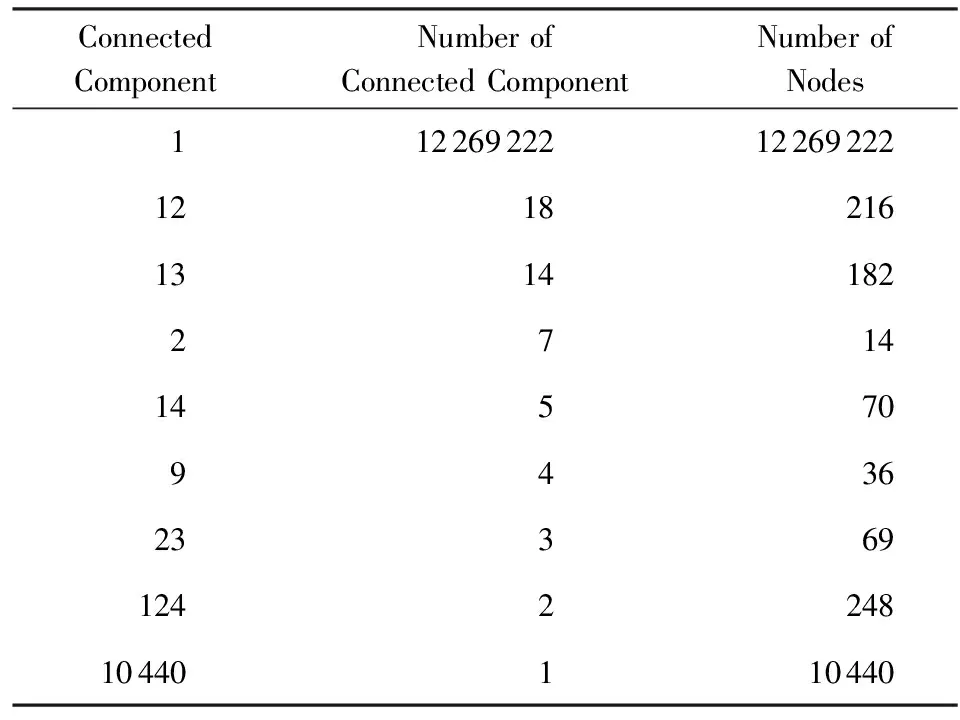
Table 2 Connected Component Number and the
2.3維基百科節(jié)點(diǎn)間的最短路徑
維基百科是由詞條構(gòu)成,詞條文本中含有節(jié)點(diǎn)間的鏈接關(guān)系.每一個維基百科詞條的頁面中,都包含了與之相關(guān)的其他詞條,通過這些詞條對其進(jìn)行解釋,因此我們可以直接使用維基百科而無需對文本做深層次的語義理解.圖1顯示了維基百科詞條間的鏈接關(guān)系,圓點(diǎn)代表詞條,顏色代表詞條距離選定詞條的不同層級,虛線圓代表處于同一層級的詞條,紅色箭頭代表詞條間通過超鏈接的跳轉(zhuǎn).具體來說,紅色圓圈代表選定的初始節(jié)點(diǎn);綠色圓圈代表與初始節(jié)點(diǎn)存在直接鏈接關(guān)系的詞條,也就是從初始節(jié)點(diǎn)出發(fā),可以通過一次鏈接到達(dá)綠色節(jié)點(diǎn),我們把這些綠色節(jié)點(diǎn)定義為第1層節(jié)點(diǎn).
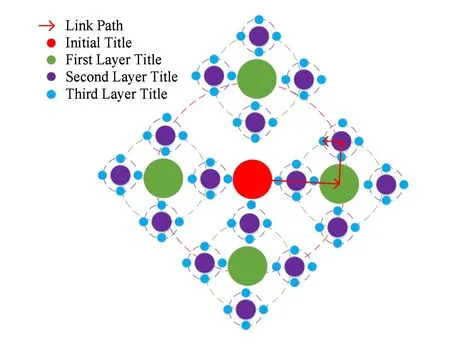
Fig. 1 The hyperlink relationship in Wikipedia nodes圖1 維基百科中節(jié)點(diǎn)的鏈接關(guān)系
類似地,從綠色節(jié)點(diǎn)詞條經(jīng)過一次跳轉(zhuǎn),可以到達(dá)紫色節(jié)點(diǎn),我們把紫色節(jié)點(diǎn)定義為初始節(jié)點(diǎn)的第2層節(jié)點(diǎn).以此類推,我們把藍(lán)色節(jié)點(diǎn)定義為初始節(jié)點(diǎn)的第3層節(jié)點(diǎn).需要額外說明的是,在計算第n層節(jié)點(diǎn)的詞條時,先排除處于n層中但與n層之前重復(fù)的部分詞條.我們認(rèn)為2個節(jié)點(diǎn)之間的最短路徑越短,表明他們之間的關(guān)系越密切;2個節(jié)點(diǎn)之間的路徑越長,則表明他們之間的關(guān)系越遙遠(yuǎn).這個觀點(diǎn)也與人類的思維模式相同,面對一個具體問題,人類首先會聯(lián)想到與這個問題最相關(guān)的因素,之后再深入到每個因素之中.舉個例子,當(dāng)提到“Milk”時,人們首先會想到有關(guān)的產(chǎn)品,例如“Cheese”等;通過“Cheese”會深入聯(lián)想到制作所需的材料,例如“Pepper”等.而這和維基百科的構(gòu)建方式剛好吻合,在維基百科中,詞條“Cheese”和“Pepper”,分別是詞條“Milk”的第1層和第2層上的節(jié)點(diǎn).
2.4基于雙向最短路徑的語義相似性算法
在使用維基百科評估語義相似度的方法中,大多都利用了2個單詞之間超鏈接所構(gòu)建的路徑[18].傳統(tǒng)算法將單詞A到單詞B的路徑長度和單詞B到單詞A的路徑長度看作是等同的,并隨機(jī)地從單詞A和單詞B中選取一個單詞作為起始點(diǎn),然后在這種模式下探尋到達(dá)另一個單詞的超鏈接路徑.但是這種路徑方式有很大的局限性,因為大部分情況下,2種方向的路徑長度并不相同,可以通過一個顯而易見的例子進(jìn)行說明:當(dāng)提到單詞“成都”時,人們會自然地想到“中國”;但是當(dāng)提到“中國”時,卻很難想到成都.從這個例子可以明顯看出,從“成都”到“中國”和從“中國”到“成都”的距離(聯(lián)想難度)明顯不同.我們進(jìn)一步通過維基百科的鏈接結(jié)構(gòu)進(jìn)行解釋,如圖2所示為傳統(tǒng)算法考慮路徑時鏈接路徑的模式,給定的2個單詞“Night”和“System”,可以通過一個“Energy”頁面進(jìn)行中轉(zhuǎn),于是這2個單詞的最短距離是2.傳統(tǒng)算法的思考模式將整個維基的鏈接網(wǎng)絡(luò)看成一個無向圖,任選一個單詞作為起點(diǎn)并不會影響最短路徑的長度.本文算法的靈感來自于對人類思維模式的思考:當(dāng)人類考慮單詞A和單詞B相似性時,不會采用單方向的思考方式,而是采用雙向的思考模式,正向距離和反向距離都會影響思考過程.我們將整個維基鏈接結(jié)構(gòu)視為有向圖,在有向圖中尋找最短路徑.
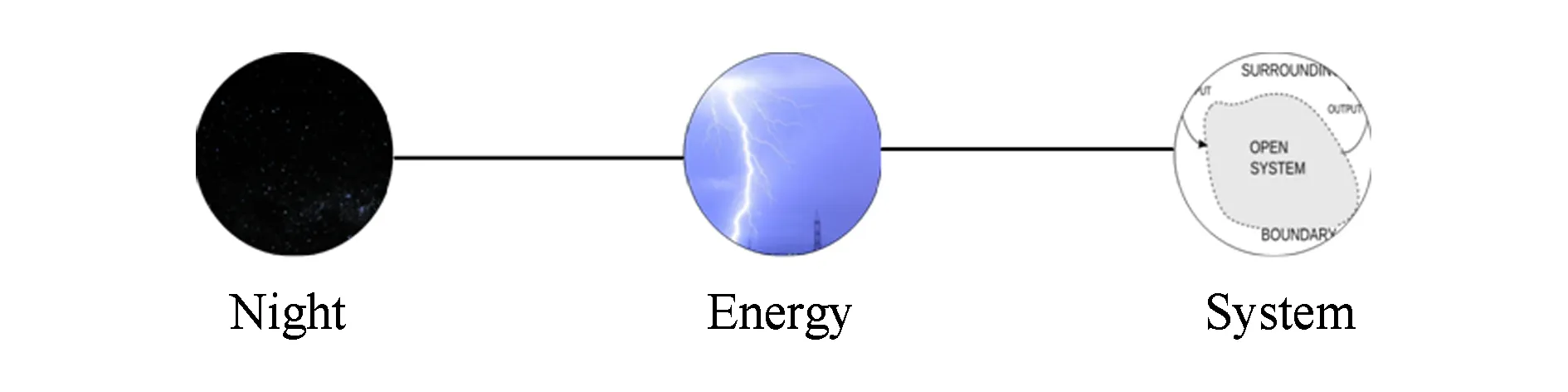
Fig. 2 The representation of traditional shortest link path圖2 傳統(tǒng)鏈接最短路徑表示
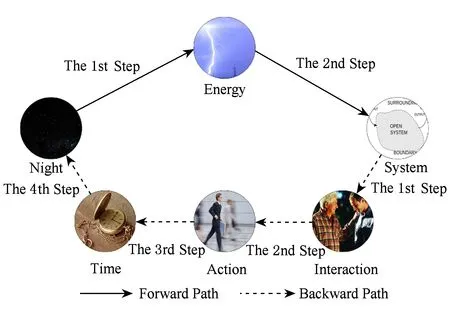
Fig. 3 The representation of bidirectional shortest link path圖3 雙向鏈接最短路徑表示
如圖3所示,人類聯(lián)想2個單詞相關(guān)性的最優(yōu)解法是通過雙向最短路徑(我們稱之為前向路徑和反向路徑),這是因為維基百科中2個單詞會因為起點(diǎn)和終點(diǎn)的轉(zhuǎn)換引起最短路徑的長度不同.具體來說,前向路徑中從“Night”出發(fā),經(jīng)過“Energy”1次跳轉(zhuǎn)后到達(dá)“System”;反向路徑中從“System”出發(fā),依次經(jīng)過“Interaction”,“Action”,“Time”3次跳轉(zhuǎn)后到達(dá)“Night”.由此看出,“Night”和“System”中的前向最短路徑長度為2,反向最短距離為4.
我們使用維基百科有2個原因:
1) 維基百科包含多種語言,其中英文版本約有500萬的詞條和1 000萬的標(biāo)題,是現(xiàn)今人類在網(wǎng)絡(luò)中最大的知識倉庫,它由人類經(jīng)過結(jié)構(gòu)化編撰而成,正確率和權(quán)威性已經(jīng)得到了普遍認(rèn)可;
2) 維基百科具有良好的成長性,在每個知識的寬度和深度上,隨著時間穩(wěn)步增長.
我們定義2個單詞之間的最短路徑長度:
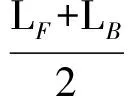
其中,LF為前向最短路徑長度,LB為反向最短路徑長度.在通過雙向最短路徑進(jìn)行語義相似性評估時,有一個需要解決的核心問題:如何設(shè)定最短路徑的步長上限.因為盡管在我們驗證了節(jié)點(diǎn)的普遍聯(lián)通性,但是尋找2個節(jié)點(diǎn)間的最短路徑時,仍會遇到路徑過長的問題.為了解決這個問題,我們設(shè)計了一個實(shí)驗:隨機(jī)選取300 000個單詞對,用廣度優(yōu)先搜索算法找到每對單詞的前向最短路徑長度,最后求得2個節(jié)點(diǎn)間的平均最短路徑長度值E(L)=3.84,標(biāo)準(zhǔn)偏差σ=1.73.根據(jù)切比雪夫不等式:
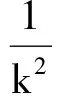
令k=3可得平均路徑長度L≥9.03的概率小于19,因此我們將最短路徑的步長上限設(shè)置為8,即超過8步就認(rèn)為2個單詞不存在相似性.
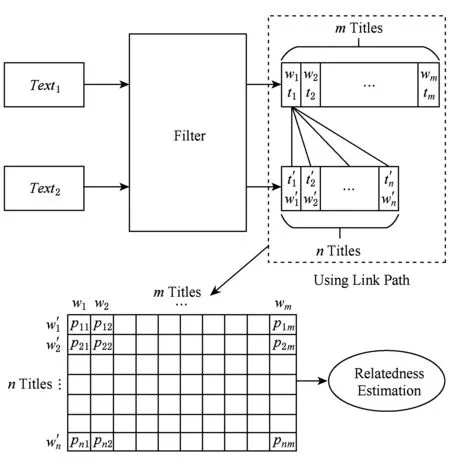
Fig. 4 The similarity evaluation of texts based on bidirectional shortest path圖4 基于雙向最短路徑的文本相似性算法
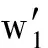
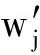
下面我們通過矩陣分塊來計算Text1文本和Text2文本的相關(guān)性:
1) 我們對矩陣進(jìn)行重排,假設(shè)|A∩B|=p,重排元組A和B使得:
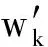
這是將A和B中共有的單詞排列于各自元組的前端,并保證下標(biāo)相同.
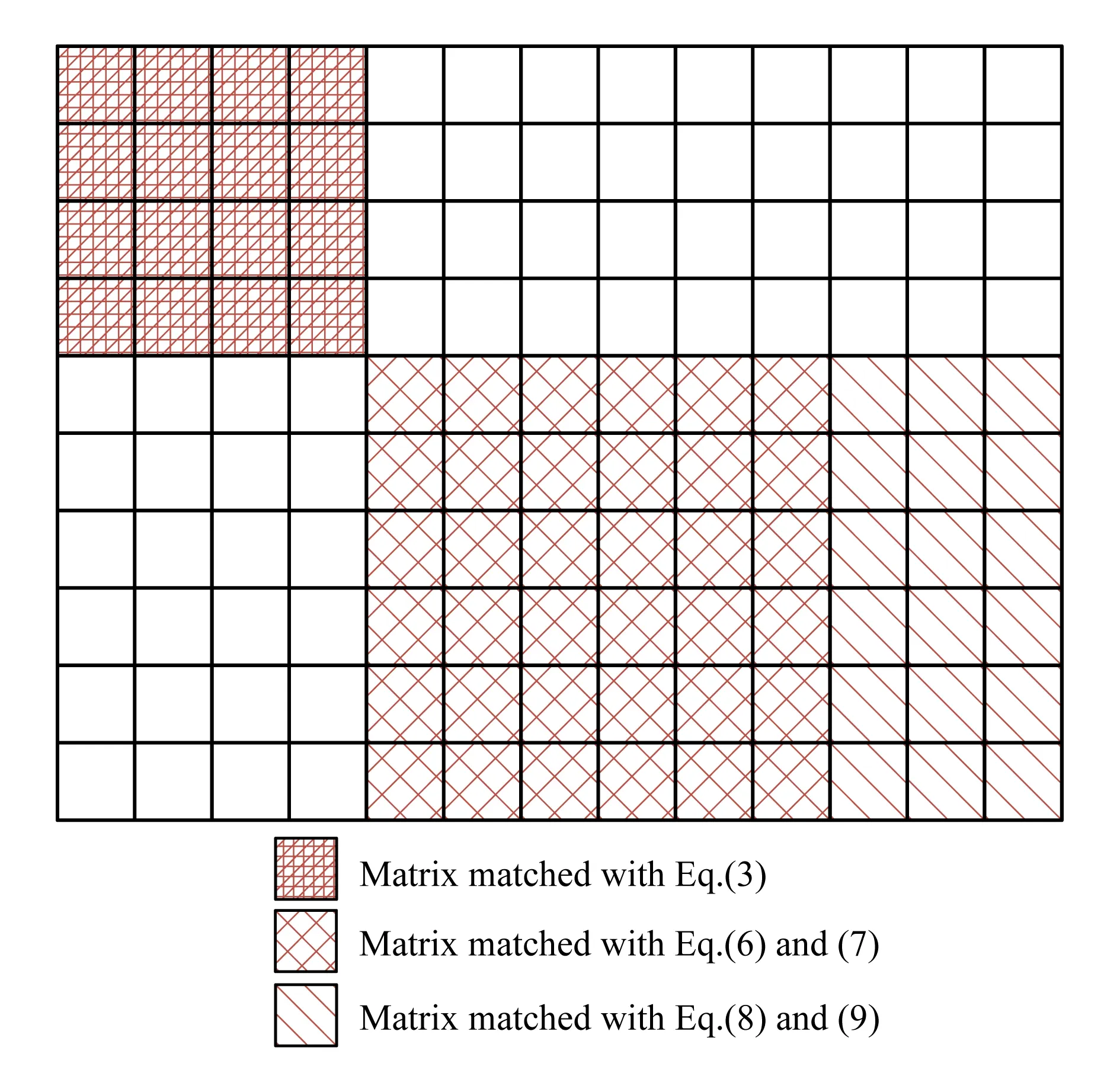
Fig. 5 Matrix partitioning圖5 矩陣分塊

3) 對子矩陣進(jìn)行重排,使得:
?(p+1)≤r≤s≤m,tr≥ts,
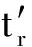
4) 令q=min(m,n),取:
我們進(jìn)一步得到一個q×q的方陣.
即相互匹配的元素下標(biāo)相同.
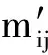
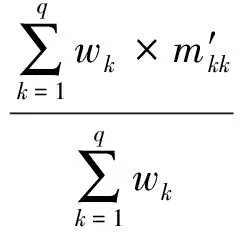
3 實(shí)驗評估
3.1WS-353Ex數(shù)據(jù)集
在語義相關(guān)性評估中,研究者通常會使用標(biāo)準(zhǔn)的黃金數(shù)據(jù)集WS-353[21](WordSimilarity-353).WS-353中包含了353對英語單詞,每一對都用一個范圍在0~10的分?jǐn)?shù)來表示它們的相關(guān)程度.每個分?jǐn)?shù)都是由16個人分別打出,最后取平均值而得到.WS-353是根據(jù)人類的聯(lián)想和判斷,確定對語義相似度的評估標(biāo)準(zhǔn).因此,我們可以通過與其結(jié)果的對比,判斷本文提出的算法能否與人類的聯(lián)想機(jī)制契合.
我們對WS-353進(jìn)行了改進(jìn),稱之為WS-353Ex(WS-353 extend version),這是因為其中一些單詞無法映射到維基百科的詞條中.之前的研究中一些研究者也發(fā)現(xiàn)了這一問題,但是一直沒有得到有效的解決.Milne等人[13]選擇直接刪除60個不合適的單詞.Singer 等人[18]也發(fā)現(xiàn)了這個問題,并給出了改進(jìn)版的數(shù)據(jù)集WikipediaSimilarity-353,將單詞對刪減到308個,但是Singer等人忽視了引起這個問題的真正原因.我們發(fā)現(xiàn),自從2002年WS-353提出之后,維基百科經(jīng)過14年的發(fā)展和變化,在數(shù)量級上發(fā)生了數(shù)十倍的增長,導(dǎo)致部分單詞無法映射到維基百科中進(jìn)行路徑探索的原因是WS-353中的一些單詞出現(xiàn)在重定向頁面和消歧義頁面.為了解決這個問題,我們做了2項工作:
1) 將重定向的單詞進(jìn)行替換,例如 “Diego Maradona”更換為“Maradona”,“theater”更換為“theatre”;
2) 將維基百科中無法查到的單詞刪除,例如“defeating”.
我們對2002年的數(shù)據(jù)集WS-353進(jìn)行了改進(jìn)和修正,形成WS-353Ex,最后保留了344對單詞.如表3所示,WS-353在最初的3個維度(Word1,Word2,human mean)的基礎(chǔ)上,增加了3個新的維度:前向最短路徑長度f、反向最短路徑長度b和平均最短路徑長度a.以“tiger”和“cat”舉例,人類對2個單詞相似性的打分是7.35,從“tiger”出發(fā)經(jīng)過2步能夠鏈接到“cat”,從“cat”出發(fā)經(jīng)過3步能夠鏈接到“tiger”, “tiger” 與“cat”的平均最短路徑為2.5.
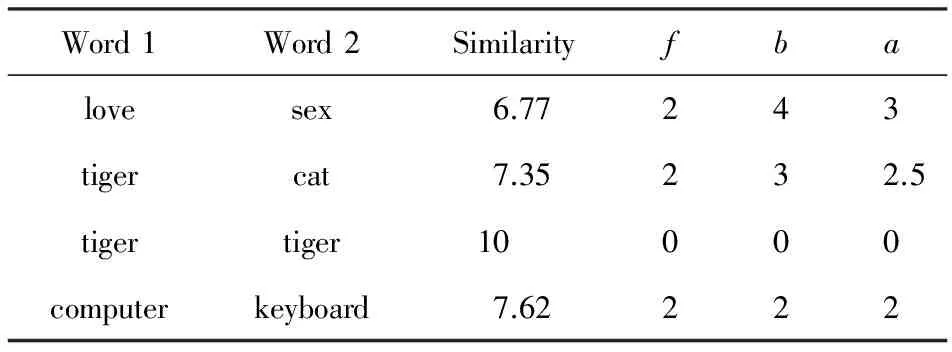
Table 3 Demonstration of WS-353Ex Dataset表3 WS-353Ex數(shù)據(jù)集樣例
3.2語義相似性評估
在本節(jié)中,我們分別使用WS-353Ex和Lee[22]數(shù)據(jù)集來驗證算法在單詞和文本相似度評估的有效性.首先使用WS-353Ex數(shù)據(jù)集進(jìn)行單詞相似度評估,具體步驟如下:
1) 基于在3.1節(jié)中相關(guān)方法所計算出的WS-353Ex中每對單詞之間的f和b,求出:
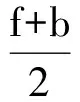
2) 采用嶺回歸方法,分別使用單詞對的f,b,a與對應(yīng)的人類打分進(jìn)行擬合:
其中,h代表人類的打分,w=(w1,w2,…, wp) 代表系數(shù),w0代表截斷我們使用嶺回求解:
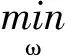
其中,α是復(fù)雜性系數(shù),α的值越大, 收縮性越好,也就使得系數(shù)擁有更強(qiáng)的魯棒性.
3) 我們采用斯皮爾曼等級相關(guān)系數(shù)、皮爾遜相關(guān)系數(shù)和谷本系數(shù)[1,4]來評價預(yù)測擬合模型的正確性,評估的分?jǐn)?shù)區(qū)間為0~1,越趨近于1說明該方法的準(zhǔn)確度越高.實(shí)驗結(jié)果驗證了通過最短路徑算法進(jìn)行相似性評估的準(zhǔn)確性.
本文設(shè)計了3組實(shí)驗,分別使用f,b,a與人類打分值進(jìn)行組合預(yù)測:實(shí)驗隨機(jī)選取了測試集和驗證集(分別采用3:7,5:5,7:3的比例),重復(fù)500次取平均值.實(shí)驗結(jié)果如表4所示,單獨(dú)使用f和b最高只能達(dá)到0.51和0.53的分?jǐn)?shù),而使用a能夠?qū)⒎謹(jǐn)?shù)穩(wěn)定在0.84.為了進(jìn)一步的評估,我們將本文的算法與之前的一些重要相關(guān)研究結(jié)果作了比較,如表5顯示,Milne等人[13]所提出的一種基于超鏈接相似度的方法可以將分?jǐn)?shù)提高到0.78.在本文基本方法的基礎(chǔ)上,我們觀察到在WS-353Ex數(shù)據(jù)集中有一些明顯錯誤樣本數(shù)據(jù),人工刪除這些誤差樣本后重新進(jìn)行評估,能夠?qū)?zhǔn)確率提高到0.90.從表5中可以看出,通過本文提出的算法與8種傳統(tǒng)算法的比較,驗證了所述算法在單詞相似度計算的有效性上明顯超越現(xiàn)有算法.
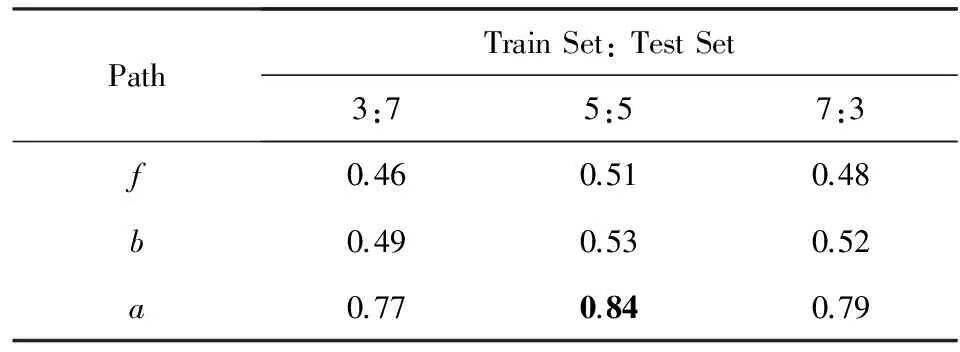
Table 4 Comparison of Word Similarity Using Three Kinds of Shortest Path
為了探究在評估文本相似度的效果,我們基于雙向最短路徑算法在Lee數(shù)據(jù)集[26]上進(jìn)行了驗證,這個數(shù)據(jù)集包含了50個文本,以及每一對文本對應(yīng)的人類打出的相似性分?jǐn)?shù).實(shí)驗中隨機(jī)抽取1 000對文本進(jìn)行實(shí)驗,得到分?jǐn)?shù)的平均值.如表6所示,Hassan等人[8]提出基于小規(guī)模語料庫進(jìn)行訓(xùn)練的LSA算法,能夠得到0.69的分?jǐn)?shù).Gabrilovich等人[11]提出了ESA算法,并得到0.75的分?jǐn)?shù).本文通過雙向最短路徑算法進(jìn)行文本相似性分析,能夠得到0.77的分?jǐn)?shù).基于雙向最短路徑的算法在單詞相似性的評估上取得了很好的效果,但是在文本相似度上效果與之前的算法效果相當(dāng),我們認(rèn)為這主要因為訓(xùn)練集較小,僅基于數(shù)據(jù)集WS-353Ex,只包含344對單詞;另一個影響因素是我們僅通過文本在維基百科網(wǎng)絡(luò)中的鏈接關(guān)系進(jìn)行評估,沒有結(jié)合其他更多的屬性.
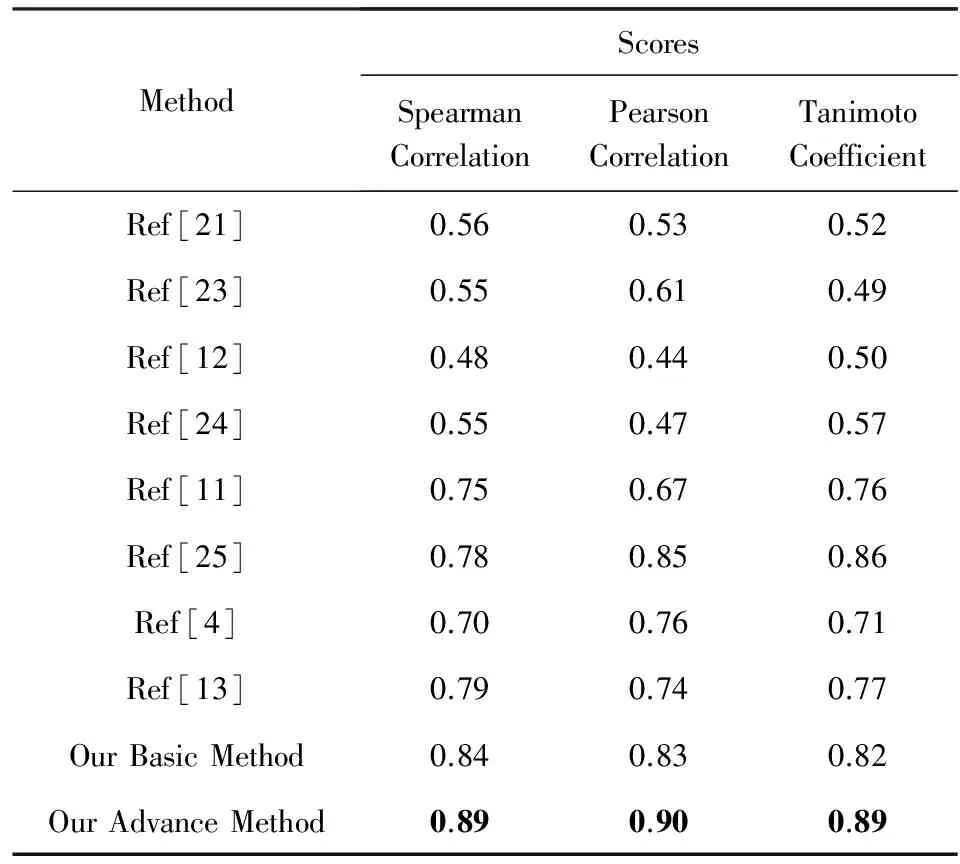
Table 5 Comparison of Word Similarity Scores with
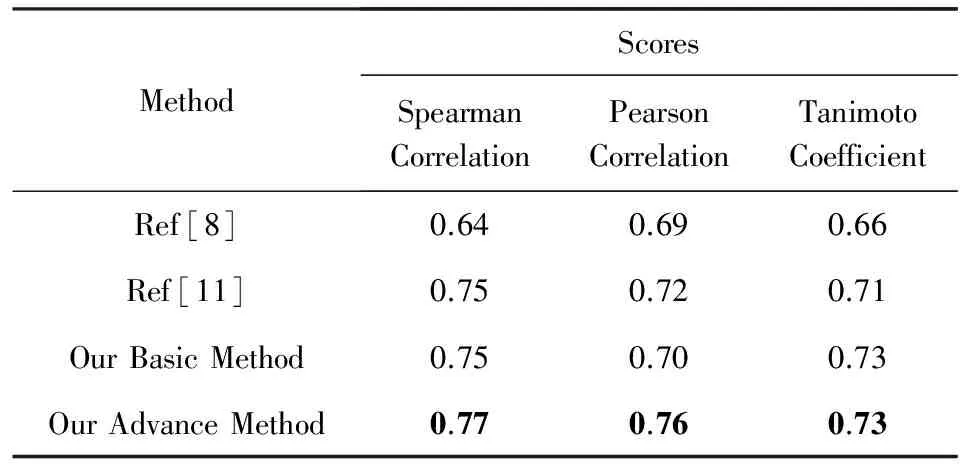
Table 6 Comparison of Text Similarity Scores with
4 總 結(jié)
本文提出了一種基于維基百科中超鏈接結(jié)構(gòu)進(jìn)行語義相似性評估的方法.這是首次在論文中考慮到2個單詞之間雙向路徑的不同,并證明了維基百科中詞條的普遍連通性,發(fā)現(xiàn)了它們之間的平均最短路徑長度約為3.84.考慮到人類雙向思維的方式,我們應(yīng)用雙向最短路徑長度設(shè)計了一種新的算法,該算法能夠充分利用維基百科結(jié)構(gòu)中的潛在人類特性.本文使用提出的算法分析單詞相似性,取得了很好的效果,在此基礎(chǔ)上提出一種使用矩陣分解進(jìn)行文本相似性分析的方法,取得了良好的效果.另外,我們對傳統(tǒng)的WS-353進(jìn)行了修正和升級.本文最大的貢獻(xiàn)在于:在僅使用維基百科中鏈接關(guān)系和數(shù)量較少的訓(xùn)練數(shù)據(jù)的情況下,取得了出色的評估效果.在未來的工作中,我們希望能夠結(jié)合其他文本特征,并增加更多訓(xùn)練數(shù)據(jù)來改進(jìn)評估模型.
[1]Zhang Libo, Zhang Fei, Luo Tiejian. Knowledge structure evolution and evaluation method in computer science[J]. Journal of University of Chinese Academy of Sciences, 2016, 33(6): 844-850 (in Chinese) (張立波, 張飛, 羅鐵堅. 計算機(jī)科學(xué)知識體系演化與評估方法[J]. 中國科學(xué)院大學(xué)學(xué)報, 2016, 33(6): 844-850)
[2]Xin Yu, Yang Jing, Tang Chuheng, et al. An overlapping semantic community detection algorithm based on local semantic cluster[J]. Journal of Computer Research and Development, 2015, 52(7): 1510-1521 (in Chinese) (辛宇, 楊靜, 湯楚蘅, 等. 基于局部語義聚類的語義重疊社區(qū)發(fā)現(xiàn)算法[J]. 計算機(jī)研究與發(fā)展, 2015, 52(7): 1510-1521)
[3]Wang Junhua, Zuo Wanli, Yan Zhao. Word semantic similarity measurement based on Naive Bayes model[J]. Journal of Computer Research and Development, 2015, 52(7): 1499-1509 (in Chinese) (王俊華, 左萬利, 閆昭. 基于樸素貝葉斯模型的單詞語義相似度度量[J]. 計算機(jī)研究與發(fā)展, 2015, 52(7): 1499-1509)
[4]Yazdani M, Popescu-Belis A. Computing text semantic relatedness using the contents and links of a hypertext encyclopedia: Extended abstract[J]. Artificial Intelligence, 2013, 194: 176-202
[5]Giles J. Internet encyclopaedias go head to head[J]. Nature, 2005, 438: 900-901
[6]Gabrilovich E, Markovitch S. Computing semantic relatedness using Wikipedia-based explicit semantic analysis[C]Proc of the 20th Int Joint Conf on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 2007: 1606-1611
[7]Zesch T, Müller C, Gurevych I. Using Wiktionary for computing semantic relatedness[C]Proc of AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2008: 861-866
[8]Hassan S, Mihalcea R. Cross-lingual semantic relatedness using encyclopedic knowledge[C]Proc of Conf on Empirical Methods in Natural Language Processing. New York: ACM, 2009: 1192-1201
[9]Syed Z S, Finin T, Joshi A. Wikipedia as an ontology for describing documents[C]Proc of Int Conf on Weblogs and Social Media. Menlo Park, CA: AAAI, 2008
[10]Coursey K, Mihalcea R. Topic identification using Wikipedia graph centrality[C]Proc of Conf on the North American Chapter of the Association of Computational Linguistics. New York: ACM, 2009: 117-120
[11]Gabrilovich E, Markovitch S. Wikipedia-based semantic interpretation for natural language processing[J]. Journal of Artificial Intelligence Research, 2014, 34(4): 443-498
[12]Strube M, Ponzetto S P. WikiRelate! computing semantic relatedness using Wikipedia[C]Proc of the 19th National Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2006: 1419-1424
[13]Milne D, Witten I H. An open-source toolkit for mining Wikipedia[J]. Artificial Intelligence, 2013, 194: 222-239
[14]Yeh E, Ramage D, Manning C D, et al. WikiWalk: Random walks on Wikipedia for semantic relatedness[C]Proc of Workshop on Graph-Based Methods for Natural Language Processing. New York: ACM, 2009: 41-49
[15]Dallmann A, Niebler T, Lemmerich F, et al. Extracting semantics from random walks on Wikipedia: Comparing learning and counting methods[C]Proc of the 10th Int AAAI Conf on Web and Social Media. Menlo Park, CA: AAAI, 2016: 33-40
[16]Witten I, Milne D. An effective, low-cost measure of semantic relatedness obtained from Wikipedia links[C]Proc of AAAI Workshop on Wikipedia and Artificial Intelligence: An Evolving Synergy. Menlo Park, CA: AAAI, 2008: 25-30
[17]Wei Bifan, Liu Jun, Ma Jian, et al. Motif-based hyponym relation extraction from Wikipedia hyperlinks[J]. IEEE Trans on Knowledge and Data Engineering, 2014, 26(10): 2507-2519
[18]Singer P, Niebler T, Strohmaier M, et al. Computing semantic relatedness from human navigational paths: A case study on Wikipedia[J]. International Journal on Semantic Web amp; Information Systems, 2013, 9(4): 171-172
[19]Niebler T, Schl?r D, Becker M, et al. Extracting semantics from unconstrained navigation on Wikipedia[J]. Künstliche Intelligenz, 2016, 30(2): 1-6
[20]Ellery W, Dario T. Wikipedia Clickstream, v21.0[OL]. [2016-09-24]. https:meta.wikimedia.orgwikiResearch:Wikipedia_clickstream
[21]Finkelstein L, Gabrilovich E, Matias Y, et al. Placing search in context: The concept revisited[C]Proc of the 10th Int Conf on World Wide Web. New York: ACM, 2001: 406-414
[22]Lee M D. An empirical evaluation of models of text document similarity[JOL]. Cognitive Science, 2005 [2016-09-24]. https:core.ac.ukdownloadpdf22875578.pdf
[23]Jarmasz M. Roget’s thesaurus as a lexical resource for natural language processing[D]. Ottowa, Canada: University of Ottowa, 2012
[24]Hughes T, Ramage D. Lexical semantic relatedness with random graph walks[C]Proc of the 45th Conf on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Stroudsburg, PA: ACL, 2007: 581-589
[25]Agirre E, Alfonseca E, Hall K, et al. A study on similarity and relatedness using distributional and WordNet-based approaches[C]Proc of Conf on the North Americ Human Language Technologies. New York: ACM, 2013: 19-27
[26]Hoerl A E, Kennard R W. Ridge regression: Biased estimation for nonorthogonal problems[J]. Technometrics, 1970, 12(1): 55-67


SunYihan, born in 1994. PhD candidate. Her main research interests include recommendation system, information retrieval, machine learning and distributed storage system.

LuoTiejian, born in 1962. PhD, professor. Director of the Information Dynamic and Engineering Applications Laboratory. His main research interests include Web mining, large scale Web performance optimization and distributed storage systems.
CalculateSemanticSimilarityBasedonLargeScaleKnowledgeRepository
Zhang Libo1, Sun Yihan2, and Luo Tiejian2
1(Institute of Software, Chinese Academy of Sciences, Beijing 100190)2(University of Chinese Academy of Sciences, Beijing 101408)
With the continuous growth of the total of human knowledge, semantic analysis on the basis of the structured big data generated by human is becoming more and more important in the application of the fields such as recommended system and information retrieval. It is a key problem to calculate semantic similarity in these fields. Previous studies acquired certain breakthrough by applying large scale knowledge repository, which was represented by Wikipedia, but the path in Wikipedia didn’t be fully utilized. In this paper, we summarize and analyze the previous algorithms for evaluating semantic similarity based on Wikipedia. On this foundation, a bilateral shortest paths algorithm is provided, which can evaluate the similarity between words and texts on the basis of the way human beings think, so that it can take full advantage of the path information in the knowledge repository. We extract the hyperlink structure among nodes, whose granularity is finer than that of articles form Wikipedia, then verify the universal connectivity among Wikipedia and evaluate the average shortest path between any two articles. Besides, the presented algorithm evaluates word similarity and text similarity based on the public dataset respectively, and the result indicates the great effect obtained from our algorithm. In the end of the paper, the advantages and disadvantages of proposed algorithm are summed up, and the way to improve follow-up study is proposed.
large scale knowledge repository; semantic similarity; Wikipedia; shortest path; connectivity
his PhD degree in computer software and theory from the University of Chinese Academy of Sciences. Assistant research professor in the Institute of Software, Chinese Academy of Sciences. His main research interests include image processing, pattern recognition, knowledge graph and deep learning.
2016-08-10;
2017-02-20
中國科學(xué)院系統(tǒng)優(yōu)化基金項目(Y42901VED2,Y42901VEB1,Y42901VEB2)
This work was supported by the Foundation of System Optimization in Chinese Academy of Sciences (Y42901VED2, Y42901VEB1, Y42901VEB2).
TP391
猜你喜歡
大科技·百科新說(2021年6期)2021-09-12 02:37:27
好孩子畫報(2020年5期)2020-06-27 14:08:05
開放教育研究(2020年2期)2020-03-31 01:54:14
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
意林·全彩Color(2019年6期)2019-07-24 08:13:50
智慧少年·故事叮當(dāng)(2018年11期)2018-05-14 11:48:18
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
奧秘(2015年2期)2015-09-10 07:22:44
大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
