
基于SVR預測的可逆數據庫水印技術
2018-01-03 01:54:54龍曉泉
計算機應用與軟件 2017年12期
龍 曉 泉
(中移互聯網有限公司 廣東 廣州 510640)
基于SVR預測的可逆數據庫水印技術
龍 曉 泉
(中移互聯網有限公司 廣東 廣州 510640)
頻繁模式樹(FP-tree)的關聯規則是利用數據挖掘算法來確定受保護的屬性和其他數據庫之間存在的關系,支持向量回歸方法(SVR)用來預測每個受保護的屬性值。提出通過嵌入原始數據庫的重要特征來檢測數據庫是否被篡改過的實現方法。通過對比差值擴展(DE)的原始值和預測值之間的差異,數據庫管理員可以在受保護的數據庫中嵌入數字水印,如果受保護的數據庫是扭曲的,在SVR功能下仍然是可以預測保護值的。FP-tree挖掘方法用于降低SVR的訓練時間,如果該數據庫已被篡改,我們可以從受保護的數據庫中提取水印,來驗證并定位篡改元組,恢復原來的屬性值,如果該數據庫沒有遭到攻擊,我們也可以利用水印保護數據庫。因此,提出的數據庫的電子水印方式可以有效地驗證數據庫的完整性和保護數據庫的安全性。
數據庫水印 差值擴展 支持向量回歸 FP-tree挖掘
0 引 言
在現實生活中,個人和組織都喜歡將一些數字信息存儲在數據庫中,便于管理。由于這些信息包含與重要決策相關的數據,因此保護數據庫免受篡改是一個重要的問題[1]。近年來,研究人員已經開發了數據庫水印技術,把數字水印嵌入數據庫中,使得數據庫中的保護列將允許檢測是否被篡改。
在數據庫中嵌入數字水印,應確保和保護通過使用水印技術存儲在數據庫中的所有列的決策數據的正確性和一致性。然而,如果數字水印嵌入在列中,并且列中的值需要修改,那么數字決策數據可能會失真,這將導致出現不正確的決策數據[2]。
在數據庫中,存儲的數字決策數據不允許失真,并且決策數據庫中的數據不能隨意修改。雖然目前的嵌入式水印技術可以驗證列的正確性,但是不能恢復原始的數字數據[3]。因此,本文針對SVR技術,將數字水印嵌入在數字決策數據庫中,驗證是否可以恢復原來的數字數據。
有些人通過使用獨特的特征來表示關系數據,給數字水印帶來新的挑戰。通過提取嵌入的數字水印來檢測數據庫是否被篡改[4-5]。嵌入的水印可以用于任何關系數據庫。然而,如果發生篡改攻擊,向數據庫插入新屬性,那么提取的水印可能不正確。
還有些人提出了一種通過在數據庫中建立附加信息的索引表來嵌入水印的數據庫水印技術[6-7]。通過改變索引表中的序列而不改變數據表中內容的值來嵌入水印。因此,在數據庫中的內容不會受影響,并且在嵌入水印之后無需修改。然而,由于索引值是在數據庫內容上的附加信息,如果索引值被刪除或重新建立,水印有可能是錯誤的或可能會完全消失[8]。
為了解決上述問題,本文所提出的方法是,通過使用FP-tree的數據挖掘來保護數字決策數據庫中的重要列,從而過濾掉受保護列和其他列之間的關系。在許多用于數據挖掘技術的方法中,FP-tree的數據挖掘在實際運行中已經顯示出高水平的效率。因此,FP-tree技術已成為最常見的數據挖掘方法。FP-tree的數據挖掘技術主要統計數據庫中列的出現次數[9]。列出現的次數越多,說明越重要。我們需要做的就是選定重要的列,建立一個樹形結構以防止多次掃描、節省時間[10]。
接著,在SVR中,通過FP-tree的數據挖掘中所選擇列的值來計算保護列的預測值。通過預測值和原始保護列之間的差異,以及回歸差值擴展(RDE),將水印嵌入保護列中。該方法的優點在于區分有數字水印的數字數據庫和原始數據庫之間的微小差異[11]。因此,該方法可確定決策數據庫中的值是否已被惡意篡改,并確定已被篡改的列。相反,如果嵌入有水印的數字決策數據庫沒有被篡改,則列中的值可以恢復為具有RDE的原始值。這種方法具有非常好的檢出率。
1 解決方案
在該方案中,通過使用FP-tree的數據挖掘改進了數據庫表中重要特征。然后,將挖掘結果中受保護字段的相關重要特征進一步由SVR來預測保護。因此,可以計算每條記錄中保護字段的預測值和原始值之間的差。另一方面,DE是一種可逆的隱藏方案。提出了基于DE可逆水印的基本方法來選擇嵌入目標值。通過這個目標值和最低有效位(LSB)的替換方式,將結果更新到表中。所提出的技術方案如圖1所示。
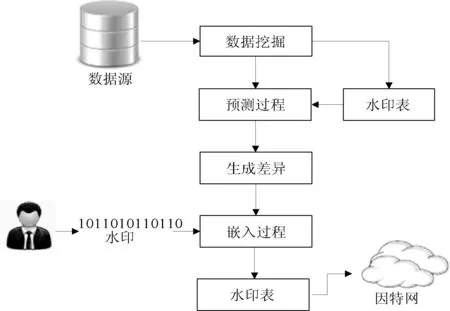
圖1 SVR培訓和嵌入程序圖
1.1 FP-tree 特征挖掘
在開始階段,原始數據庫O的重要特征是選擇使用FP-tree的數據挖掘技術。FP-tree結構可以找出受保護屬性的關聯特征。首先,計算特征的數量。其次,為頻繁屬性創建樹形結構。
步驟1計算每個屬性值的頻率。
步驟2為數據庫O構建FP-tree。
表1是在超市中交易表的例子;編號列表示不同購買者;購買項目代表交易數據;頻繁項使用統計后的支持度閾值方法進行過濾。假設最小支持度閾值為3。支持度模式為a,其中a表示一組項目,是包含在事務數據庫中的事務數目。
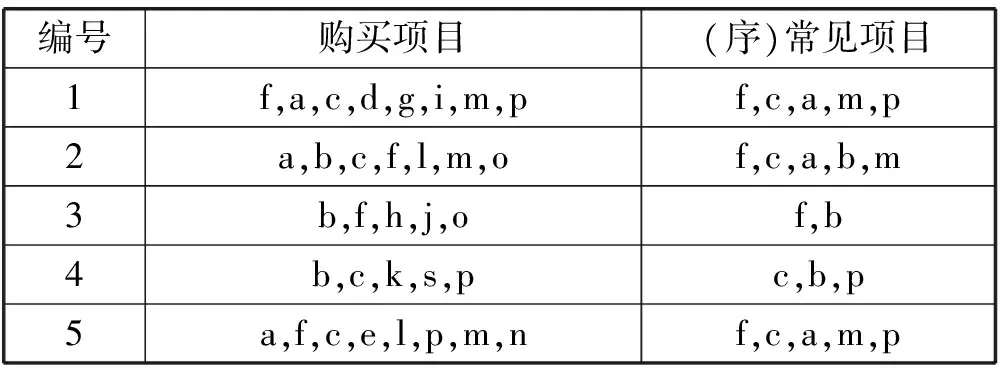
表1 事務表的例子
例如,集合收集頻繁項如下:
<(a:3),(b:3),(c:4),(d:1),(e:1),)(f:4),(g:1),(h:1),(i:1),(j:1),(k:1),(l:2),(m:3),(n:1),(o:2),(p:3),(s:1)>,在該集合中,c表示特征,數字4表示支持度。此購買項目的訂單很重要,因為樹的每個路徑都將遵循此順序。頻繁項會通過最小支持度閾值過濾。
首先,會對事務數據庫進行掃描導出一個頻繁項的列表。其次,會對一個空的樹創建根值。在編號1中插入這些頻繁項目集合<(f:1),(c:1),(a:1),(m:1),(p:1)>得到如圖2(a)所示的樹。在編號2中插入這些頻繁項目集合<(f:1),(c:1),(a:1),(b:1),(m:1)>得到如圖2(b)所示的樹。由于在路徑(f,c,a,m,p)中存在頻繁項目(f,c,a),所以頻繁項目列表中的每個節點的數目就增加1,新創建的(b:1)節點就作為(a:2)的子節點鏈接。
在編號5中插入這些頻繁項目集合<(f:1),(c:1),(a:1),(m:1),(p:1)>得到如圖2(c)所示的樹,并構造最終的FP-tree。
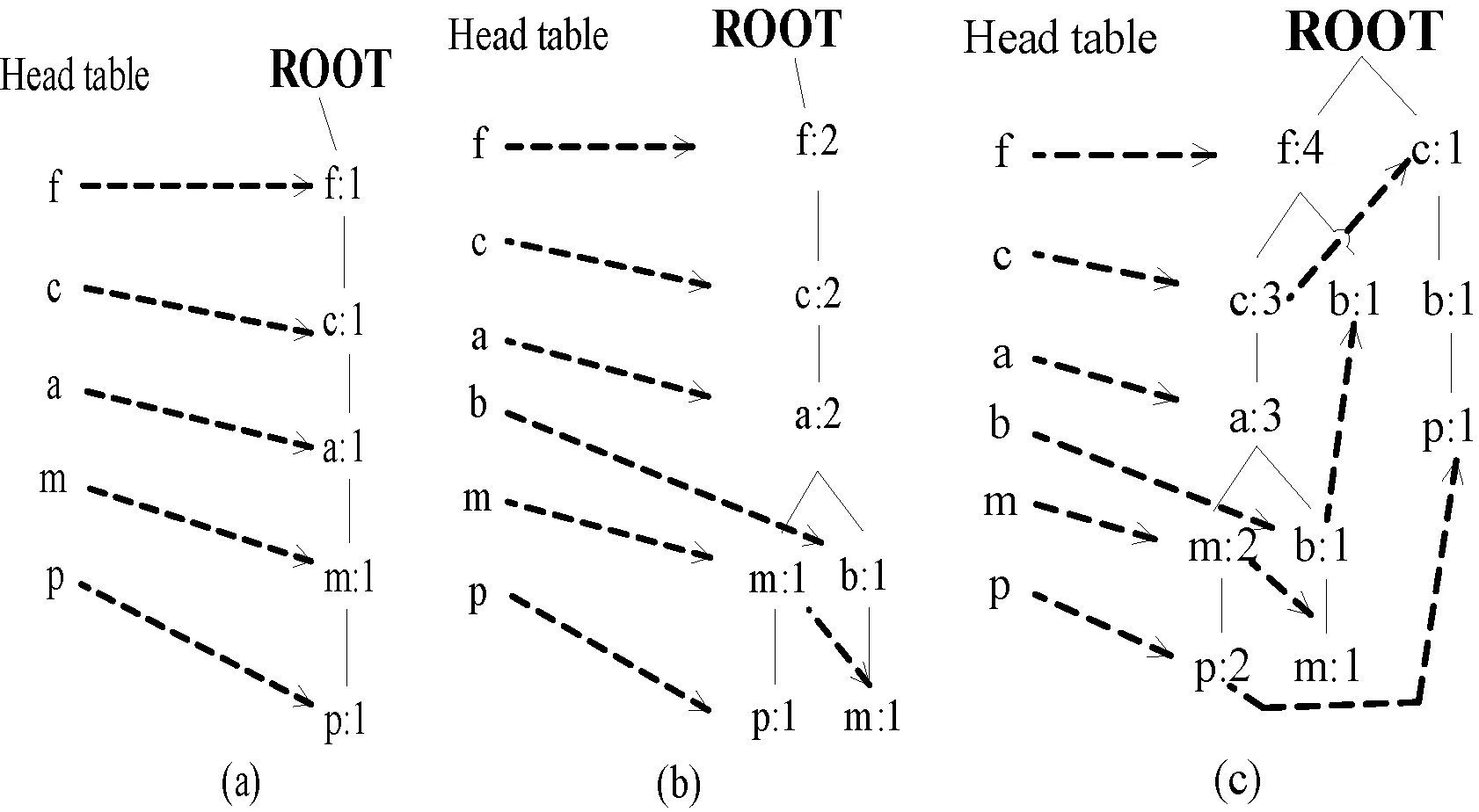
圖2 集合收集頻繁項目順序圖
1.2 SVR訓練算法
在上述理論基礎上,FP-tree中的屬性存儲在表X中。接下來,表X中的重要特征被選擇用于訓練過程。使用SVR可以涉及訓練樣本,并從SVR獲得訓練函數f(Y)。
輸入:數據庫O和表X與屬性A1,A2,…,Ag;
輸出:訓練后的SVR函數f(Y)。
步驟1使用表X中的屬性來預測數據庫O中的受保護屬性。訓練數據集T可以表示為:T={sj|sj={A1,j,A2,j,…,Ag,j},j=1, 2,…,n}。其中:sj被定義為數據庫O中的第j個選擇的訓練元組。
步驟2通過使用訓練元組T來訓練SVR模型以獲得SVR函數f(Y)。
1.3 數據庫水印的嵌入
在這個階段,對于數據庫O中的受保護目標屬性U,提出在水印嵌入過程使用數據庫O和SVR預測函數f(Y)中的目標屬性U使用差值擴展(DE)來嵌入水印。水印W可以被分成1-LSB位,2-LSB位或3-LSB位,用于嵌入到修改后的U中。
輸入:數據庫O,經過訓練的SVR函數f(Y)和水印W;
輸出:嵌入到數據庫O′。
第一步將目標值Ui與訓練的SVR函數值f(yi)進行比較。如果Ui小于f(yi),則定義di=f(yi)-Ui,并且轉到第二步;否則定義di=Ui-f(yi)并轉到第三步。實驗數據假定Ui為16,f(yi)為7,則di為9。

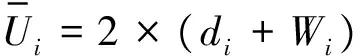
第四步重復第一步至第三步,直到所有的水印信息都嵌入到數據庫O中,并獲得水印數據庫O′。
1.4 數據庫水印的提取
在我們提出的方案中,為了驗證數據庫的內容,通過數據挖掘可以發現重要的特征,并且使用SVR來預測f(Y)。我們使用DE的概念從受保護的目標值中提取嵌入的水印。并獲得水印和目標值。如果水印已經被破壞,則該數據庫被篡改。否則,數據庫將顯示原始值。數據庫水印提取的過程如圖3所示。

圖3 檢測與恢復過程圖
輸出:懷疑的水印W′。
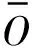
第二步訓練SVR模型通過訓練元組集T′獲得SVR函數f(Y)。

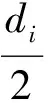

第七步將提取的水印和原始水印進行比較,以確定數據庫是否被篡改。

2 實驗結果與分析
在實驗結果中,兩個不同的數據庫虹膜(Iris)和鮑魚(Abalone),被用作測試數據庫。其中第二個鮑魚是使用FP-tree數據挖掘進行測試。使用FP-tree數據挖掘方法可以極大提升檢出率。
采用的SVR工具是LIBSVM。虹膜數據庫有150個元組和5個屬性。訓練參數包括可平衡參數C(C=3)和最小擬合誤差ε(ε=0.1);訓練元組的數目為150。這些屬性包括:萼片長度、萼片寬度、花瓣長度、花瓣寬度和類別。實驗結果如表2所示。

表2 改裝“Iris數據庫”的實驗結果
鮑魚數據庫的元組數為4 096,有8個屬性。屬性包括:性別、長度、直徑、高度、整體重量,、脫殼重量、臟器重量和殼重。平衡參數C(C=3)和最小擬合誤差ε(ε=0.1),訓練元組數為1 000。實驗結果如表3所示。
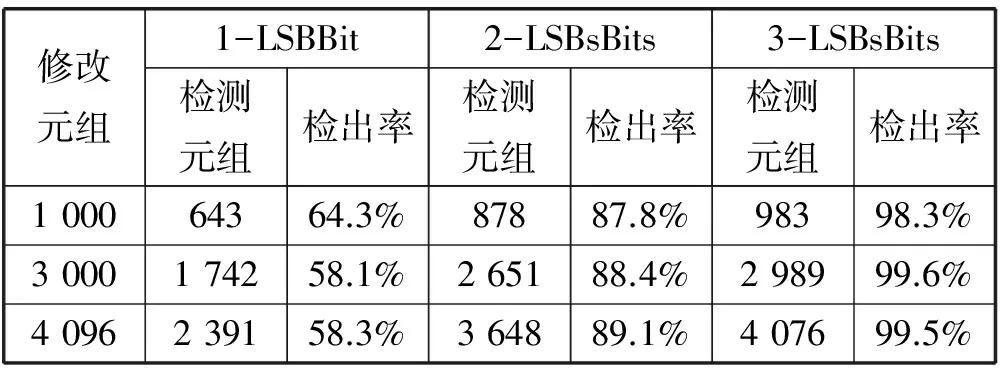
表3 改裝“Abalone數據庫”的實驗結果
由表2、表3的結果得出,在Abalone數據庫的中,嵌入1-LBS的水印平均檢測率為58.5%;嵌入2-LBS的水印接近88%;嵌入3-LBS的水印接近98.8%。與Iris數據庫相比,它在元組復雜度提高26倍的情況下,依然大大提升了檢出率(參見圖4)。

圖4 實驗結果對比(以2-LSBsBits為例)
為了對比使用FP-tree前后對數據庫防篡改的實際效果,作者對虹膜和鮑魚兩個數據庫O1和O2分別實施了兩組對照實驗。我們關注三個指標的對比分析:
檢測率 = 成功檢出的篡改數量/總篡改數量
誤報率 = 誤報為異常的數量/總事件數
漏檢率 = 漏報未檢出的篡改數量/總事件數
我們人為制造對目標數據庫的篡改,對兩個數據庫進行了多組實驗測試,選取兩組典型測試數據,第一組數據為使用了FP-tree算法訓練,第二組數據未使用FP-tree算法訓練,兩組的操作總數均為100次,實驗結果如表4、表5所示。

表4 虹膜數據庫O2的實驗結果

表5 鮑魚數據庫O2的實驗結果
在實驗結果中,兩個不同的數據庫兩組對照實驗數據對比非常明顯,在虹膜數據庫中,應用了FP-tree算法的檢測率提升12.25%,誤報率降低2%,漏檢率降低8%。在另一組鮑魚數據庫的實驗結果中,應用了FP-tree算法訓練的實驗結果較比未應用FP-tree算法的實驗數據檢測率提升22.12%,誤報率降低1%,漏檢率降低7%。
這意味著幾乎所有被篡改的數據都可以被成功檢測和定位。實驗結果表明,上述提出的方法確實可以保持數據庫內容的完整性。值得注意的是,通過前面的數據挖掘,我們可以減少SVR在后續步驟中的訓練時間。假設數據維度是相當高的,我們要找出重要的特征。可以先在數據沒有被篡改的情況下,建議通過程序來恢復原始值。在恢復過程中,可以通過預測值和li來獲得原始的目標屬性。總的來說,恢復數據庫的內容是這個新方法中最重要的特征。它可以有效地降低管理成本。
3 結 語
在本文中,我們提出了一種基于SVR預測的可逆水印算法,該算法使用FP-free的數據挖掘方法,用來驗證數據庫的內容。首先,使用FP-free關聯規則挖掘重要特征,關聯規則將會選擇最相關的一個數據。此數據的特征將被用于SVR的預測,這種方法的主要目的是為了防止在SVR預測期間維度很高時,訓練時間會變得太長。因此,通過關聯規則的挖掘,該方法可以大大減少因SVR訓練造成的時間浪費。在計算SVR預測與原始值之間差異時,我們可以使用DE方法作為嵌入數字水印的基本概念。如果數據庫受到攻擊并被惡意篡改,則SVR預測值可能會產生差異;我們可以用這種方法提取水印,然后計算和定位被攻擊的記錄。在不被攻擊的情況下,可以通過提取水印來恢復原始數據庫。
[1] 王奎,孫天凱,丁賓.脆弱水印技術在關系數據庫保護中的應用研究[J].福建電腦,2012,28(11):16-17.
[2] 周飛,趙懷勛.基于混沌的DCT域關系數據庫水印算法[J].計算機應用研究,2012,29(2):786-788.
[3] 高領云.關系數據庫脆弱性數字水印技術的研究[D].湖南:湖南大學,2013.
[4] 劉芳,汪玉凱.一種基于差值直方圖平移的多層可逆水印算法[J].計算機應用與軟件,2014,31(1):303-307.
[5] 劉瑞.可逆水印技術及其在加密域的研究算法[D].北京:北京交通大學,2015.
[6] 陳進東,潘豐.基于在線支持向量回歸的非線性模型預測控制方法[J].控制與決策,2014(3):460-464.
[7] Clarke S M,Griebsch J H,Simpson T W.Analysis of Support Vector Regression for Approximation of Complex Engineering Analyses[C]//ASME 2003 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference.American Society of Mechanical Engineers,2005:1077-1087.
[8] Choi W Y,Choi D H,Cha K J.Robust estimation of support vector regression via residual bootstrap adoption[J].Journal of Mechanical Science & Technology,2015,29(1):279-289.
[9] 李少華,呂志旺,車德勇,等.基于有序FP-tree的最大頻繁項集挖掘算法[J].東北師大學報(自然科學),2016,48(2):65-69.
[10] 吳倩.基于壓縮FP-tree的頻繁項集快速挖掘算法研究[D].上海:華東理工大學,2015.
[11] 付冬梅,王志強.基于FP—tree和約束概念格的關聯規則挖掘算法及應用研究[J].計算機應用研究,2014,31(4):1013-1015.
REVERSIBLEDATABASEWATERMARKINGTECHNOLOGYBASEDONSVRPREDICTION
Long Xiaoquan
(ChinaMobileInternetCompanyLimited,Guangzhou510640,Guangdong,China)
The association rule of FP-tree (frequent pattern tree) uses data mining algorithm to determine the relationship between protected property and other databases. SVR (Support vector regression) method is used to predict each protected attribute value. We propose a method to detect whether the database has been tampered with by embedding the important feature of the original database. By comparing the difference between original and predicted values of the DE (difference expansion), the database administrator can embed digital watermark in a protected database. If the protected database is distorted, it is still possible to predict the protection value under the SVR function. In this paper, FP-tree mining method is used to reduce the training time of SVR. If the database has been tampered with, we can extract the watermark from the protected database to verify and locate the tampered tuples and restore the original attribute value. If the database is not under attack, we can also use the protection of database watermarking. Therefore, the database can effectively verify the integrity of the database and protect the security of the database.
Database watermarking Difference expansion Support vector regression FP-tree mining
2016-11-05。龍曉泉,碩士,主研領域:數據庫技術。
TP3
A
10.3969/j.issn.1000-386x.2017.12.012
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
大眾投資指南(2021年35期)2021-02-16 01:06:26
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電力與能源(2017年6期)2017-05-14 06:19:37
財經(2017年2期)2017-03-10 14:35:35
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
