基于相關性密度的多變量時間序列屬性選擇
2018-01-03 01:58:49張坤華丁立新萬潤澤
計算機應用與軟件 2017年12期
關鍵詞:分類
張坤華 丁立新 萬潤澤
(武漢大學計算機學院 湖北 武漢 430072)
基于相關性密度的多變量時間序列屬性選擇
張坤華 丁立新 萬潤澤
(武漢大學計算機學院 湖北 武漢 430072)
屬性選擇是一種有效的數據預處理方法。為了移除多變量時間序列屬性集中的冗余屬性和噪聲屬性,選擇出包含足夠原始信息并能提高精度的屬性子集,提出一種基于相關性密度的屬性選擇算法。該算法使用相關性矩陣表示原多變量時間序列,定義每個屬性的局部密度來表示屬性的代表性,定義屬性的判別距離作為該屬性與其他屬性間的區分度。最后根據決策圖的分布來篩選具有較大代表性和區分度的屬性。使用SVM分類器對UCI數據庫中的4種不同數據集進行實驗,實驗結果表明該算法相比已有算法在分類準確度和時間效率上均有一定的優越性。
多變量時間序列 相關性矩陣 決策圖 密度 屬性選擇
0 引 言
時間序列是指一組按時間順序排列的數據,并廣泛應用于眾多領域,如金融股市預測[1]、醫療數據記錄[2]、氣象預報[3]和工業產品質量控制分析[4]等。根據時間序列中記錄的變量個數,時間序列又分為單變量時間序列UTS(Univariate Time Series)和多變量時間序列MTS(Multivariate Time Series)[5]。相比單變量時間序列,多變量時間序列同時具有時間維和變量維的信息,提供的數據信息更豐富,但給后續的針對多變量時間序列的挖掘研究分析和數據挖掘任務提高了難度,因此對多變量時間序列降維預處理是十分必要的。多變量時間序列的降維,主要分為特征表示和屬性選擇,特征表示將原時間序列映射到另一低維空間,并盡可能地表達原時間序列信息[6],但卻失去了與原空間特征間的一一對應關系和實際物理意義,不便于后續理解和認知。屬性選擇是從原時間序列的高維空間中挑選出一組最有代表性的變量屬性[7],在篩選后的屬性子集中進行后續操作,以提高效率和精度。本文主要針對多變量時間序列的變量維數約簡,即屬性選擇。
目前很多學者對多變量時間序列屬性選擇作了深入研究,并提出了一些優化算法。文獻[8]提出了基于度量學習的無監督屬性選擇算法。文獻[9]提出了基于分形維數計算和離散粒子群優化的屬性選擇算法。文獻[10]提出了基于RFE的屬性選擇算法。相對經典的算法是文獻[11]提出了基于公共主成分屬性選擇算法(CleVer)。該算法基于以下假設:在所有的多變量時間序列中存在一個由正交向量構成的公共子空間,各序列在該公共子空間上的投影能夠最大程度地體現出差異性,投影后獲得與所有序列主成分最接近的描述公共主成分,根據每個屬性對描述公共主成分的貢獻度進行排名,從排名高的屬性集中篩選屬性子集,但在實際情況中,一個MTS數據集會存在多個不同的類別,將不同類別的子空間投影為一類,造成了信息損失[12]。文獻[13]提出基于互信息和類可分離性的屬性選擇算法(CSFS),由類可分離性引申出屬性可分離性,將其定義為屬性間離散矩陣和已選屬性子集離散矩陣的比值,用于評估屬性間的冗余度,使用互信息對MTS進行特征提取后,根據冗余度降序排列進行屬性選擇。然而利用互信息計算相關性時,計算變量間的概率密度函數是十分困難的,需要借助其他函數估計互信息值,時間復雜度較高[14],且基于類可分離性是一種監督方法,在數據缺失類標信息時,該算法得不到較好的應用。文獻[15]提出一種增量互相關過濾式屬性選擇算法(ICF),該算法通過滑動點積計算兩個傳感器時間序列的偏移量作為屬性間冗余度,設定冗余度閾值去除冗余屬性和噪聲屬性,最后基于迭代應用程序中的一組選擇消除規則進行前向式屬性選擇,但如何選取最優的閾值尚未明確。
基于密度的快速聚類算法[16]由Rodriguez等提出,該算法認為聚類中心具有較高的局部密度和與其他高密度樣本較遠的特點,通過構建樣本點和類之間的隸屬關系,發現任意維度和形狀的樣本中最大密度點群。Liu P等[17]使用該算法進行文本聚類,實驗結果表明該算法在提高文本聚類性能和降低誤報率上均取得明顯效果。Chen等[18]利用該算法實現纖維束的自動分割,通過聚類圖像獲取感興趣的光纖束,聚類結果與描述纖維束顯示了高度一致性。Sun等[19]利用該算法完成高光譜圖像波段篩選,將篩選后的波段完成地物分類,并驗證有效性。
本文在快速聚類算法基礎上,提出一種有效的多變量時間序列屬性選擇算法,具有以下特點:1) 將原多變量時間序列轉為相關性矩陣,降維同時獲取屬性間的相關關系;2) 提出基于屬性相關性密度排序的屬性子集選擇方法ACDR(attribute subset selection based on attribute correlation density ranking),定義多變量時間序列屬性的局部密度表示該屬性的代表度,定義屬性的判別距離表示與其他屬性的區分度,根據上述兩個量繪制出決策圖,根據決策圖的分布篩選出最優屬性子集。將篩選后的屬性子集代替原屬性集,并與文獻[11-13]中所提算法在分類準確率上和時間效率上進行對比。
1 多變量時間序列屬性選擇方法
1.1 多變量時間序列表示
一個多變量時間序列X可以使用n×m的矩陣表示,記為X=(X1,X2,…,Xm)=(xij)n×m。
式中:m代表變量維度即屬性個數,n代表時間維度,Xi表示第i維長度為n的屬性序列,t=1,2,…,n,xij表示第j維屬性在第i時的記錄值,且一般情況下n?m,當m=1時,該時間序列為單變量時間序列。
1.2 多變量時間序列相似性度量
假設存在兩個多變量時間序列(MTS),分別為Xn1×m1和Xn2×m2。通常在同一個數據集中,這兩個MTS包含的屬性個數相同,但是時間長度可能不同,即m1=m2,n1≠n2。此時計算兩個MTS之間的相似度存在以下問題: 1) 當兩個MTS長度不相等時不能直接使用歐式距離度量公式計算其相似性,而使用DTW算法[20]雖然支持伸縮時間軸,但計算復雜度高,當序列維度較大時適用性不強;2) 多變量時間序列不是多個單變量時間序列的簡單組合,屬性之間往往存在重要關聯,若直接拼接成行向量,會造成屬性間相關信息的丟失。為克服以上問題,本文使用相關性矩陣代替原時間序列,具體步驟如下:
1.2.1 計算MTS屬性間相關性
定義1Xi和Xj分別為MTS的第i維和第j維屬性,Xi=(x1i,x2i,…,xni)T,Xj=(x1j,x2j,…,xnj)T,則它們之間的相關性可表示為:

(1)

(2)
(3)
R(Xi,Xj)值取-1到1之間,正值表示兩個屬性間正相關,負值表示負相關,零表示無相關性,即兩個屬性是獨立的。
1.2.2 計算相關性矩陣
通過計算MTS中屬性間相關性,一個數據集中第j個MTS即可表示為Mj(j=1,2,…,n),即:
通常一個有意義的多變量時間序列觀察值n?m,原多變量時間序列轉化為相關性矩陣后維度由n×m降為m×m,數據規模大大減小,且保留了屬性間相關關系信息,相關性矩陣大小只與屬性個數有關,與時間長度無關,有利于非等長MTS間相似性度量。使用相關性矩陣表示的兩個MTS間的相似度為:
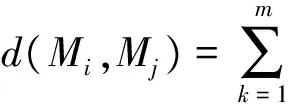
(4)
式中:m為MTS的屬性維度,‖*‖為歐氏距離。
1.3 屬性的代表度和區分度
樣本間的相似度表示除了距離度量、信息度量、還有相關性度量和一致性度量[21],本文使用屬性間的相關性來衡量其相似度。
定義2一個多變量時間序列任意兩個屬性間的相似度為:
d(Xi,Xj)=R(Xi,Xj)
(5)
式中:R(Xi,Xj)為式(1)中的計算結果。
定義3屬性Xi序列的局部密度ρi定義為:
(6)
(7)
也可以用高斯核函數形式表示:
(8)
式中:dij表示屬性Xi到屬性Xj間的相似度距離,dc表示截斷距離,Rodriguez等[16]指出dc值的選擇標準為:使每個樣本點近鄰數約為樣本總數的1%~2%時聚類效果較好,本文實驗中取2%,局部密度ρi越大,表示該屬性在局部鄰域內越稠密,屬性的代表度越高。
定義4定義屬性Xi序列的判別距離δi為:
(9)
δi為該屬性到比該屬性局部密度更大屬性的最小距離,當屬性Xi的具有最大局部密度時,δi=maxj(dij),δi越大表示,該屬性與其他屬性間的區分度越大,說明屬性Xi與屬性Xj的冗余度越小。
1.4 決策圖
計算出局部密度ρi和判別距離δi后,根據這兩個值繪制決策圖。選取UCI數據庫中的BCI數據集,該數據集屬性個數為28個,該數據集屬性生成的決策圖如圖1所示。
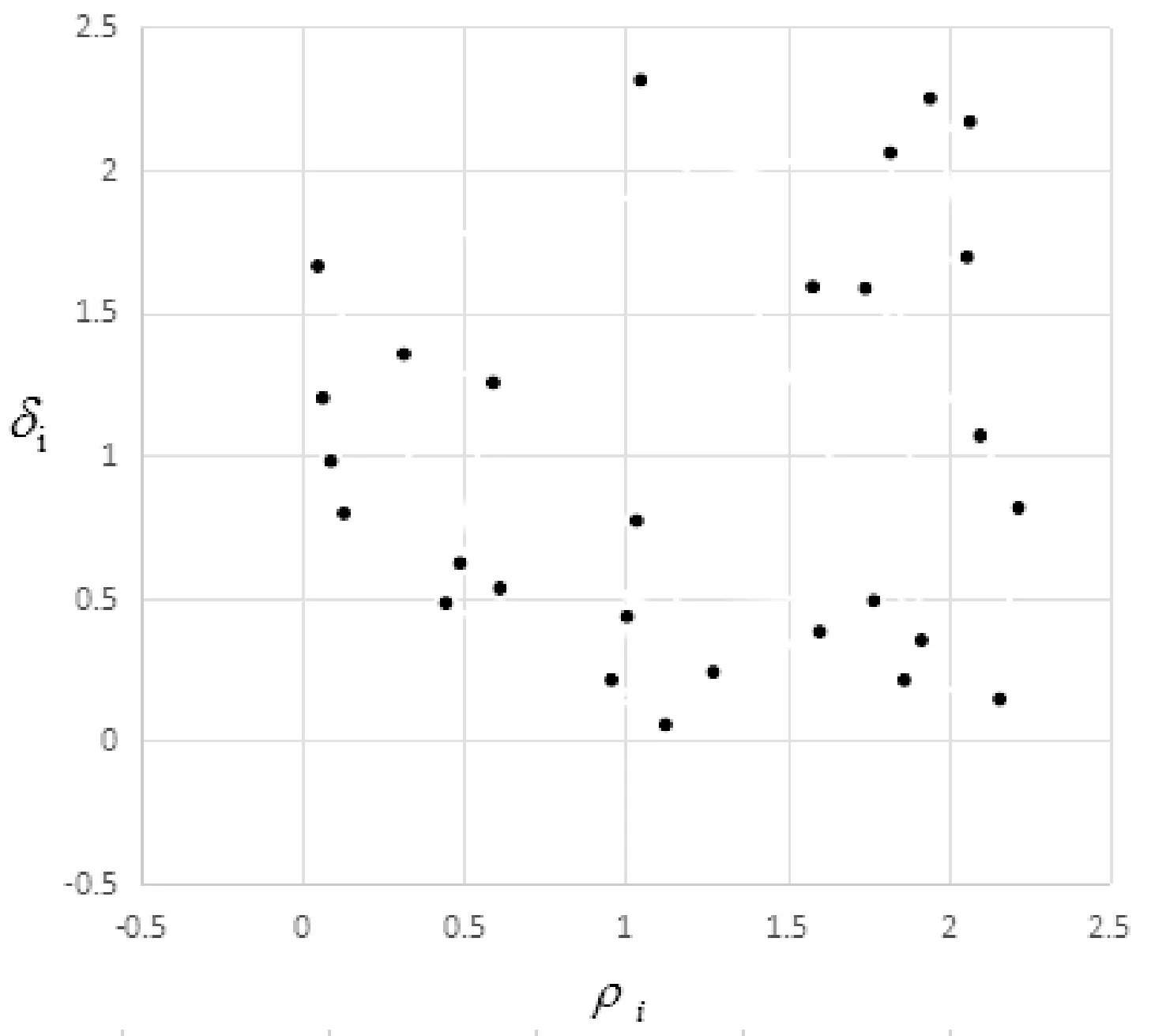
圖1 BCI數據集決策圖
根據定義3和定義4可知,具有較高代表度、區分度的屬性,位于決策圖中的右上區域。
定義5選擇參考指數ri
從決策圖中可以直觀地看出重要度不同的屬性位置相差較大,我們需要的是選取同時具有較大δi值和較大ρi值的屬性作為特征屬性,如果手動選取則會非常耗時,為此,本文定義了參考指數ri,計算δi和ρi乘積作為選擇參考指數,表示為:
ri=δi×ρi
(10)
按照ri的降序排列,依次選取選取前k個屬性構成屬性子集。

圖2 BCI屬性參考指數排序圖
通過以上分析,本文算法具有以下幾個特點:1) 使用相關性矩陣表示原多變量時間序列,保留多變量時間序列屬性間相關關系并降低時間復雜度,提高后續計算效率;2) 該算法是無監督屬性選擇算法,在缺少類標信息的時間序列中也能得到應用,克服缺少類標簽或獲取代價較大的缺點;3) 首次將快速聚類算法[16]應用于多變量時間序列的屬性選擇,根據選擇參考指數排名來篩選屬性;4) 無需進行子集搜索,可以在短時間內完成計算,避免子集搜索引起的局部最優;5) 可以通過下降值的拐點來確定最優屬性子集的個數。
2 算法流程
問題描述:給定一個多變量時間序列集合X=(X1,X2,…,Xm),包含m種屬性,且每種屬性對應一個時間序列,尋找時間序列X的屬性子集X′,使其滿足:
X′={X1,X2,…,Xk}?X={X1,X2,…,Xm},k?m
算法基于相關性密度的多變量時間序列屬性選擇
輸入:多變量時間序列X
輸出:X的屬性子集X′
1:計算該時間序列每個屬性和其他屬性間相關性R(Xi,Xj)
2:得到該時間序列的相關性矩陣M
3:計算時間序列每個屬性的局部密度ρi
4:計算時間序列每個屬性的判別距離δi
5:計算每個屬性選擇參考指數ri=δi×ρi
6:對ri排序,選取相關性矩陣M中前k個屬性構成屬性子集
3 實驗結果和分析
3.1 實驗數據
本文使用的數據是來自UCI數據庫中的4種數據集,分別為EEG、BCI、JV、Wafer。其中EEG為一組醉酒者和正常人群通過采樣頻率為256 Hz在受試者頭部放置的64個采樣點采集時長為1 s的腦電圖數據,BCI為一組采集左右手運動對應的28個皮層電位信息數據,JV為一組記錄9位日本男性的12個LPC同態普數據描述的發音過程數據,Wafer為一組記錄晶硅體生產過程放置的6個傳感器記錄的微電子序列數據,表1為4種數據集的詳細信息描述。采用LIBSVM[22]程序包實現的線性核支持向量機(SVM)作為分類器,采用10倍交叉驗證,將每個數據集分成訓練和測試數據集,以準確率作為分類結果評價指標。準確率定義如下:
準確率=正確分類的樣本數/總樣本數
為消除實驗結果的偶然性和平臺環境的不穩定性對實驗結果造成的影響,每次實驗都是重復10次并取平均值,本文的所有實驗均在表2所示的實驗環境中完成。

表1 數據集描述

表2 實驗環境及配置
3.2 實驗結果及分析
將本文算法ACDR與已有的3種多變量時間序列屬性選擇算法CleVer[11]、CSFS[13]、ICF[15]在表1中4種數據集上進行實驗,通過比較分類準確率和運行時間來評估本文算法的有效性和優越性。4種算法在不同數據集中的分類準確率結果分別如圖3-圖6所示,橫坐標表示選擇屬性的個數,縱坐標為分類準確率。4種算法的最優分類準確率和平均分類準確率如表3所示,各算法的運行時間如表4所示,其中粗體表示最優結果。

圖3 EEG數據集分類結果

圖4 BCI數據集分類結果

圖5 JV數據集分類結果

圖6 Wafer數據集分類結果

數據集算法最優準確率/%平均準確率/%EEGACDR98.4292.43CSFS97.9692.04ICF97.5090.15CleVer95.6087.02BCIACDR78.3174.54CSFS77.2873.80ICF70.9166.78CleVer67.4759.77JVACDR72.4871.63CSFS74.1772.02ICF71.2270.10CleVer72.6069.50WaferACDR90.8776.15CSFS84.8179.11ICF85.3173.70CleVer84.8171.29

表4 4種算法的運行時間
由圖3~圖6可以看出,在EEG數據集中,當屬性維數為1~35時,本文算法性能與其他3種算法相差無幾,當屬性維數為36~64時,本文算法優勢逐漸顯著。在BCI數據集中,除個別維數外,本文算法分類準確率上均高于其他3種算法。在JV數據集中,本文算法的分類效果較為平穩,分類效果整體上優于ICF算法和CleVer算法,當屬性個數為1~5時,分類準確率僅次于CSFS算法,當屬性個數為6~12時,準確率和CSFS算法、CleVer算法相持平。在Wafer數據集中,本文算法性能不太穩定,當屬性個數為2~3時,本文算法性能低于CSFS算法,屬性個數為4時,分類性能低于CSFS算法和ICF算法,但當屬性個數為5時,卻達到了最優準確率,當屬性個數為6時,性能與其他3種算法趨于一致。
由表3可知,本文算法在EEG和BCI數據集中均取得了最高的最優分類準確率和平均分類準確率。在JV數據集中,分類性能僅次于CSFS算法,準確率分別高出ICF算法1.26%、1.53%,平均分類性能高于CleVer算法3.13%。在Wafer數據集中,本文算法獲得了最優分類準確率,平均分類準確率僅次于CSFS算法,準確率分別高于ICF算法5.56%、2.45%,CleVer算法6.06%、4.86%。綜合可知,在四種算法中,本文算法和CSFS算法相對于ICF算法和CleVer算法分類性能有較明顯的優勢,并在不同數據集中分別獲得了最優分類性能。
由表4可知,4種算法中,CSFS算法的平均時間開銷最大,CleVer次之,本文算法和ICF算法相差無幾。本文算法在4種數據集上的平均運行時間分別為CSFS算法平均運行時間的19.52%、CleVer算法平均運行時間的43.79%,ICF算法93.02%,并在BCI數據集和Wafer數據集中取得了最優時間效率。
綜合以上可知,在分類準確率上,本文算法和CSFS算法在不同數據集中均明顯優于ICF算法和CleVer算法。在運行效率上,本文算法和ICF算法明顯優于CSFS算法和CleVer算法。由于CSFS是一種監督的屬性選擇算法,平均分類準確率雖較高,但時間開銷大,而ICF算法運行效率高,但在4種數據集中的準確率均不如本文算法,故本文算法在綜合分類準確率和時間效率整體性能上較其他3種算法更優。
4 結 語
針對現有的多變量時間序列屬性選擇算法準確率不高、時間復雜度高的情況,提出了一種基于相關性密度的多變量時間序列屬性選擇算法,將原多變量時間序列轉為相關性矩陣,根據屬性相關性密度進行選擇,選擇的過程可以被看作是聚類過程,聚類中心可以作為屬性集的代表屬性,并與其他屬性具有較少的冗余度,根據定義計算出屬性的局部密度和判別距離后繪制決策圖并根據參考指數排名選擇屬性。對UCI數據庫中4種數據集的實驗結果分析表明,在綜合分類準確率和時間效率整體性能上,本文算法是一種有效的多變量時間序列屬性選擇方法。此外,屬性參考指數排序圖中可以看出有明顯的拐點,在接下來的工作中,將圍繞確定圖中下降值的拐點來選擇時間序列最優屬性子集的個數。
[1] Sun X,Chen H,Wu Z,et al.Multifractal analysis of Hang Seng index in Hong Kong stock market[J].Physica A Statistical Mechanics & Its Applications,2001,291(1-4):553-562.
[2] Peng C K,Havlin S,Stanley H E,et al.Quantification of scaling exponents and crossover phenomena in nonstationary heartbeat time series[J].Chaos An Interdisciplinary Journal of Nonlinear Science,1995,5(1):82-87.
[3] Temme C,Ebinghaus R,Einax J W,et al.Time series analysis of long-term data sets of atmospheric mercury concentrations[J].Analytical & Bioanalytical Chemistry,2004,380(3):493.
[4] 張延華,王國剛,李朋輝.基于時間序列的挖掘算法在流程工業產品質量控制模型中的應用[J].數學的實踐與認識,2010,40(5):87-90.
[5] Vlachos M,Hadjieleftheriou M,Gunopulos D,et al.Indexing Multidimensional Time-Series[J].The VLDB Journal,2006,15(1):1-20.
[6] Wang X,Mueen A,Ding H,et al.Experimental comparison of representation methods and distance measures for time series data[J].Data Mining and Knowledge Discovery,2013,26(2):275-309.
[7] Mao Y,Zhou X B,Xia Z,et al.Survey for study of feature selection algorithms[J].Pattern Recognition & Artificial Intelligence,2007,20(2):211-218.
[8] 鄭寶芬,蘇宏業,羅林.無監督特征選擇在時間序列數據挖掘中的應用[J].儀器儀表學報,2014,35(4):834-840.
[9] 吳虎勝,張鳳鳴,徐顯亮,等.多變量時間序列的無監督屬性選擇算法[J].模式識別與人工智能,2013,26(10):916-923.
[10] Lal T N,Schr?der M,Hinterberger T,et al.Support vector channel selection in BCI.[J].IEEE Transactions on Biomedical Engineering,2004,51(6):1003-1010.
[11] Yoon H,Yang K,Shahabi C.Feature Subset Selection and Feature Ranking for Multivariate Time Series[J].IEEE Transactions on Knowledge & Data Engineering,2005,17(9):1186-1198.
[12] Li H.Accurate and efficient classification based on common principal components analysis for multivariate time series[J].Neurocomputing,2015,171(C):744-753.
[13] Han M,Liu X.Feature selection techniques with class separability for multivariate time series[J].Neurocomputing,2013,110(8):29-34.
[14] Sakar C O,Kursun O.A method for combining mutual information and canonical correlation analysis:Predictive Mutual Information and its use in feature selection[J].Expert Systems with Applications,2012,39(3):3333-3344.
[15] Bacciu D.Unsupervised feature selection for sensor time-series in pervasive computing applications[J].Neural Computing and Applications,2016,27(5):1-15.
[16] Rodriguez A,Laio A.Clustering by fast search and find of density peaks[J].Science,2014,344(6191):1492-1496.
[17] Liu P,Liu Y,Hou X,et al.A Text Clustering Algorithm Based on Find of Density Peaks[C]//International Conference on Information Technology in Medicine and Education,2015:348-352.
[18] Chen P,Fan X,Liu R,et al.Fiber segmentation using a density-peaks clustering algorithm[C]//IEEE,International Symposium on Biomedical Imaging.IEEE,2015:633-637.
[19] Sun K,Geng X,Ji L.Exemplar Component Analysis:A Fast Band Selection Method for Hyperspectral Imagery[J].IEEE Geoscience & Remote Sensing Letters,2015,12(5):998-1002.
[20] Keogh E,Ratanamahatana C A.Exact indexing of dynamic time warping[J].Knowledge & Information Systems,2005,7(3):358-386.
[21] 王娟,慈林林,姚康澤.特征選擇方法綜述[J].計算機工程與科學,2005,27(12):68-71.
[22] Chang C C,Lin C J.LIBSVM:A library for support vector machines[J].ACM Transactions on Intelligent Systems and Technology,2011,2(3):1-27.
MULTIVARIATETIMESERIESATTRIBUTESELECTIONBASEDONCORRELATIONDENSITY
Zhang Kunhua Ding Lixin Wan Runze
(SchoolofComputerScience,WuhanUniversity,Wuhan430072,Hubei,China)
Attribute selection is an effective data preprocessing method. Aiming at removing redundant or noisy attributes from the multivariate time series attribute set and selecting an attribute subset containing enough original information to improve accuracy, an attribute selection algorithm based on correlation density is proposed. The algorithm employed in the correlation matrix to represent the original multivariate time series, the local density of each attribute to show its representative ability, the distance discriminant between attributes as their discriminant degree. Moreover, attributes with larger representativeness and discriminant degree were filtered according to the distribution of the decision graph. Experiments with SVM classifier on four different datasets from the UCI repository were performed. The experimental results demonstrate the great improvement of the proposed algorithm in classification accuracy and time efficiency when compared with the existing algorithms.
Multivariate time series Correlation matrix Decision graph Density Attribute selection
2017-02-23。湖北省自然科學基金面上項目(2015CFB405);湖北省教育廳科學技術研究項目(Q20153003)。張坤華,碩士生,主研領域:時間序列降維,相似度度量。丁立新,教授。萬潤澤,副教授。
TP391
A
10.3969/j.issn.1000-386x.2017.12.052
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
