客戶流失管理研究現狀及展望①
2018-01-08 03:11:12張珠香駱念蓓
計算機系統應用 2017年12期
張珠香,駱念蓓
(福州大學 經濟與管理學院,福州 350108)
客戶流失管理研究現狀及展望①
張珠香,駱念蓓
(福州大學 經濟與管理學院,福州 350108)
梳理了客戶流失和客戶流失管理的定義,客戶流失問題的研究內容、應用場景,客戶流失預測算法及特征選擇方法,模型評估的常用技術與度量等方面的研究現狀,指出當前研究的不足,并提出未來的研究方向.
客戶流失管理; 研究現狀; 展望
隨著信息技術的高速發展,客戶對產品或服務的信息獲取越來越充分,顧客的需求也因此更加多樣化.尤其電子商務的興起,客戶對產品有了更多的選擇,激烈的市場競爭,使得客戶流失已經成為許多企業不可避免的問題[1]. 而開發一個新客戶的成本往往比保留一個老客戶的成本高得多[2],例如銀行客戶流失率每降低5%,利潤就會增長85.5%[3],這一數據根據行業的不同而有所不同. 為了應對客戶流失,很多企業從過去的以產品為導向向以客戶保留、減少流失做戰略轉型[4].
雖然投放大量廣告或不斷優化產品是簡單易行的保留措施,但是,這種毫無針對性的客戶保留會使企業面臨浪費資源的風險[5],有針對性地對潛在流失客戶進行挽留已經成為企業客戶關系管理的重要內容. 大數據時代的到來使得客戶交易數據更易被記錄搜集,利用數據建立預警模型來識別潛在的流失客戶,為企業更有效率地理解客戶消費行為與應對市場需求變化提供了新的路徑.
本文從多個方面梳理了客戶流失管理的現狀研究,并指出當前研究的不足,提出了未來可研究的方向,為深入研究客戶流失理論、方法和應用提供參考.
1 客戶流失和客戶流失管理的定義
客戶流失是指客戶放棄使用某種產品或服務,轉而使用市場上另一競爭企業的產品或服務[6,7]. Hadden等[1]將流失的客戶分為兩種,一種是自愿流失,一種是非自愿流失. 非自愿流失是由于濫用服務或者未對服務付費等原因被企業撤銷的用戶,非自愿流失的客戶容易識別. 而自愿流失是指客戶主動決定和這個企業結束關系,轉向和另一個企業合作的流失行為,自愿流失的客戶是企業流失管理的重點對象. 對于不同行業,流失客戶的定義是不同的. Larivière 等[8]將客戶關閉其金融賬戶時視為流失. Coussement等[9]和 Huang等[10]是把電信客戶銷號作為離網流失客戶. 張瑋等[11]將電信客戶報停、預銷、強關、銷號等八種狀態確定為離網狀態. Hadiji等[12]將7天內沒有玩該款網絡游戲的玩家視為流失客戶. Jahromi等[5]把某電子商務網站半年內沒有任何行為的客戶視為流失客戶. 與基于消費頻率的定義方法不同,Miguéis等[13]對于零售公司的流失客戶是根據消費金額定義的,如果客戶在第t個時段內的購買金額小于第t-1個時段消費總額的40%,視為流失客戶.
客戶流失管理是指通過客戶的歷史信息來對客戶將來的流失行為進行預測,通過計算客戶流失概率,將高流失概率的客戶作為客戶保留戰的對象[9]. Datta等[14]于2000年提出客戶流失管理的框架,主要包括研究數據的選取、數據和業務的理解、特征選擇、預測模型的建立和模型驗證. Lima等[15]將客戶流失管理過程分解為 6 個步驟: 業務理解; 數據理解; 數據預處理; 建模;評估; 部署. 文獻[5,16,17]認為高流失概率的客戶不一定是給企業帶來最大收益的客戶,僅依據流失概率選擇目標保留客戶不一定會增加企業盈利,因此,流失概率預測只是客戶流失管理的一部分. 總體而言,學者們對于客戶流失管理的內涵有較為一致的認識: 客戶流失管理是一個復雜的過程,而核心工作就是對潛在的流失客戶進行識別并采取保留措施.
2 客戶流失問題的研究內容
客戶流失問題是一個混沌、時滯、非線性、非對稱的復雜系統[18],并具有以下特點[6,19]: (1)屬于典型的二分類問題,即流失與非流失. (2)分類結果要有較高的準確性. (3)客戶數據集極端不平衡,流失客戶和非流失客戶樣本數目往往不是一個數量級. (4)客戶行為數據是海量的,而且維數比較高,數據類型涉及結構化、半結構化和非結構化,并含有噪聲.
在流失原因方面,目前的文獻多采用定性和實證的方法進行研究. Jamil等[25]認為預測模型的準確度可能并不是企業最關注的,企業更想知道顧客是因為什么原因流失. Keaveney[26]較早地對客戶流失問題進行研究,通過對服務行業500個客戶進行調查,得出重要結論: 導致客戶流失的最主要原因是不好的服務質量,價格反而不是最主要的因素. 此后,便出現了很多客戶流失原因的研究,考慮因素包括客戶的統計學特征、價格、市場競爭程度、產品升級、客戶的社會地位以及客戶滿意度和服務質量等[27]. 盛昭瀚等[28]認為產生客戶流失危機的內部因素包括企業創新能力下降、經營不善、觀念滯后、戰略決策失誤等,外部因素包括政治、經濟政策、科技發展、市場需求和競爭條件等外部經營條件的突變或惡化. 內部因素可控性較強,是企業自身矛盾的結果; 外部因素幾乎難以控制,是經營環境矛盾的結果,但客戶流失危機往往又是二者綜合的結果和體現. Hadden等[1]分析了導致客戶流失的內因和外因,例如,競爭對手的產品升級了或是價格上更優惠了; 自己的服務不到位導致顧客的體驗差等等. 于小兵等[29]根據電子商務的交易過程,提出客戶流失指標體系,包括技術、網頁、銷售產品、物流、服務5個一級指標和10個二級指標,并用模糊直覺法評估各流失原因的重要性. 李婷婷[30]采用實證的方法分析技術、物流、產品、售后服務、網絡安全5個因素對客戶流失的影響程度.
在挽救策略方面,學者們多采用數學建模的方法進行研究. 在流失預警系統報告高危流失群后,決策者并不會對所有的潛在流失客戶進行挽留,也不會簡單的依據流失概率高低選擇高概率的客戶進行挽留,因為企業的挽留利潤不僅與流失概率有關,也與客戶的價值、客戶被成功挽留的概率、挽救人數、企業的成本等息息相關[17]. Neslin等[16]基于流失概率、流失成本等參數構建了挽救利潤函數. Glady等[31]基于客戶生命周期構建了挽救利潤函數. 胡理增等[32]研究了用于挽救的總經費有限的條件下,如何確定各組客戶的挽救比例、費用和次序,實現全體流失客戶價值總和的最大化. 之后,胡理增等[33]又研究了無資源約束下的最優化挽救方案數學模型. 羅彬等[34,35]建立了客戶挽留周期計算模型、客戶挽留價值計算模型、客戶流失挽留評估模型以及客戶挽留順序選擇模型. 與上述文章思路不同的是,Chen 等[21]和 Tamaddoni等[36]在預測模型建立時,就使用了挽留最大利潤(MP)作為對模型的評估標準.
總的來說,客戶流失問題涵蓋了流失客戶的預測識別、流失原因分析以及挽救策略三方面內容,但是,目前對于客戶流失問題的研究重點主要放在提高預測模型準確度上,對流失原因及挽救策略的研究較少.
3 客戶流失問題的應用場景
3.1 電信業
Coussement等[9]采用歐洲電信運營商的30104個客戶數據,其中,流失客戶占 4.52%,數據包含 956 個變量,涉及客戶通話行為、客戶和運營商的交互行為、套餐訂閱以及人口統計學特征,通過Logit模型進行客戶流失預測. Huang等[10]使用104199個客戶的電信數據集,其中流失客戶占比5.8%,數據包含121個變量,涉及客戶的人口統計學信息、賬號信息、通話信息,通過基于K-means的混合模型進行預測. 張瑋等[11]對某電信公司184761個客戶數據,其中流失客戶占比7.3%,數據包含15個變量,通過CART與Boosting集成后的模型進行客戶流失預測. Masand等[37]以GTE公司20個最大的手機通信市場的客戶為研究對象,使用簡單回歸、最近鄰分類、決策樹和神經網絡進行客戶流失預測. 丁君美等[38]收集了某電信公司2013年9月至2014年2月的7913條客戶數據,其中,流失客戶占比3.3%,通過改進的隨機森林算法對客戶流失進行預測. 羅彬等[18]通過將BP神經網絡、RBF神經網絡、ELMAN神經網絡和廣義回歸神經網絡4個子分類器進行線性集成,并采用人工蜂群算法優化線性組合的權重,以此對某電信企業20000個客戶數據進行分析.
3.2 金融業
Nie 等[3]抽取了某銀行信用卡 5456 條,其中,非流失客戶占8.1%,流失客戶占91.1%,包含135個變量,涉及信用卡持有人信息、信用卡信息、交易信息、異常使用信息等,使用 Logit和決策樹進行預測. Larivière等[8]使用生存分析研究比利時金融服務機構的客戶流失問題. 應維云等[6]使用改進的支持向量機對深圳市某銀行個人信貸部的客戶信貸數據進行研究,客戶數據共計12萬條,每條記錄有16個變量,且包括文本型變量.
3.3 電子商務
Gordini等[39]研究了意大利某公司在2013年1月至2014年1月期間的80000個客戶數據,其中,流失客戶占比10%,數據變量涉及注冊信息、交易信息、訪問信息,使用改進的支持向量機進行預測.Yu等[40]利用中國某電子商務網站50000個客戶的注冊信息、登陸信息、交易信息、網站日志信息建模,通過改進的支持向量機進行預測. Jahromi等[5]使用Logit、決策樹、Boosting等多個模型研究了澳大利亞某B2B電子商務平臺的客戶流失問題. 由于B2B數據的獲取渠道比B2C有限,因此在客戶流失方面的研究集中在B2C方面[5].
3.4 其他
還有一些例如人才流失研究[41]、網絡游戲方面的客戶流失研究[12,42]、保險業的客戶流失[43]等.
在該階段,政府根據當前的經濟發展需求以及科技進步需求即社會福利最大化來決策新能源汽車的CAFC得分效率θ1。本文中的社會福利為生產者、消費者剩余與科技進步成果之和。有學者提出,生產者剩余應包含積分出售所得收益[15],本文認為,所出售的積分是被市場中那些節能減排技術不達標的企業或者是新能源汽車生產比例不達標的企業所購買的。在積分交易的過程中,只是發生了資金轉移,整個汽車市場中的生產者、消費者剩余之和并未發生改變,同時也未產生科技進步成果,因此,積分出售所得收益不能算入社會福利函數之中。在本文中政府的目標函數,即社會福利函數為:
總體上看,目前客戶流失的研究多集中于電信、金融、電子商務,尤其以前兩者居多,而最新的一些研究開始將客戶流失拓寬至網絡游戲等新領域. 此外,客戶流失問題涉及的客戶數據規模大,維數高,預測復雜程度高,因此,通常需要使用多個模型進行預測.
4 客戶流失預測算法及特征選擇方法
4.1 客戶流失預測算法
由于客戶流失問題的復雜性,傳統的經驗時間閾值法、RFM法等均難以奏效,Schmittlein等[44]于1987年提出了預測客戶交易行為的概率模型組Pareto/NBD模型,是首個考慮到客戶流失現象的客戶重復購買預測模型[45]. 之后,Fader等[46]對其進行改進,提出了BG/NBD模型. 客戶流失預測研究開始于20世紀90年代,我國學者在21世紀初開始研究客戶流失預測方法[47],目前用于客戶流失預測的算法主要包括以下幾種:
(1) 基于傳統統計學的方法. 傳統統計學分類器包括Logit模型、線性/二次判別器. 前者是通過假設服從Logistic分布,后者是通過假設服從高斯分布,二者均是通過極大似然估計求出參變量,估計條件概率. 樸素貝葉斯也是通過求條件概率進行分類. 基于傳統統計學的方法都是較為基礎的算法.
(2) 基于遞歸分割方法. 遞歸分割的典型代表是決策樹,屬于機器學習領域的方法. 主要包括ID3、J48、C4.5、C5.0等算法.
(3) 基于統計學習理論. 典型代表是支持向量機.SVM從數學的角度看與人工神經網絡密切相關,但其起源于統計學習理論.
(4) 基于人工智能的預測. 典型代表是仿照人腦學習的人工神經網絡,其中,多層感知器是最流行的人工神經網絡.
(5) 基于集成分類器的預測. 集成分類器是利用各個子分類器之間的互補性,按照一定的規則將各子分類器的輸出結果進行融合,以提高其性能[22]. Bagging,Boosting和隨機森林是典型的集成方法. 不同集成模型的共同點在于都是由一些基本的模型構成,通過集成實現將弱分類器轉變為強分類器,不同之處就在于使用的基本模型的不同以及集成規則的不同,因此有線性判別法的集成方法[48,49],決策樹的集成方法[50],支持向量機的集成方法[20],神經網絡的集成方法[18],Hu等[51]將決策樹、貝葉斯網絡和神經網絡等多個分類器共同集成,Kim[52]將 Logit和 ANN 共同集成等. 另外還有使用旋轉集成的算法進行客戶流失預測,如旋轉森林和RotBoost[22].
(6)其他方法. 除了上述分類,還有很多其他方法,如Amin等[7]用模糊粗糙集做客戶流失預測的研究.Huang等[10]提出基于K-means的有監督和無監督混合模型. Lu[53]和 Larivière 等[8]使用生存分析估計客戶即將流失的時間. Adebiyi等[54]使用馬爾科夫鏈對尼日利亞的電信客戶流失進行預測. 袁旭梅等[55]根據RFM標準劃分顧客群體,利用馬爾可夫鏈構建動態CRM模型. 文獻[56-58]使用社會網絡分析方法,根據客戶與客戶之間的通話記錄構建電信客戶關系網絡,研究客戶流失. 文獻[59-61]使用控制圖法研究電信客戶流失. Chen[62]提出控制圖法與貝葉斯分層模型結合的混合模型,動態監測電子商務客戶流失.
哪一種預測模型精度更高?這個問題目前還沒有定論. 客戶流失的模型精度通常是基于特定的樣本數據而言,同樣的模型在不同的研究中會有不一樣的表現. 因此,學者們對于哪一種預測模型精度更高沒有一致的看法. Nie等[3]認為Logit回歸優于J48決策樹.Mozer等[63]認為 Adaboost和 boostd neural network 比其他模型好. 盡管支持向量機是處理高度非線性分類問題的高級方法[64],但是它是一種黑箱模型,只能給出分類結果,而無法給出模型所學習到的知識[25].Masand等[37]使用簡單回歸、最近鄰分類、決策樹和神經網絡進行客戶流失預測,結果顯示神經網絡的效果最好. Kirui等[65]認為樸素貝葉斯和貝葉斯網絡在召回率上比C4.5決策樹好. Rehman等[58]的結果顯示社會網絡分析比多種決策樹算法精度高了8%-10%.Amin等[7]認為粗糙集處理未知分布的數據比機器學習更有效. Gordini等[39]認為其改進的支持向量機在處理有噪聲、不平衡、非線性的電子商務數據時比Logit、神經網絡、經典的支持向量機效果更好. Neslin等[16]認為Logit和決策樹在流失預測的實際應用中最為廣泛,在流失預測中應作為基礎模型先行試驗. Chen[62]認為現有的很多模型在建模時是基于某段時間內的客戶信息,相對靜態,因此需要定期建模,而他提出的控制圖法與貝葉斯分層混合模型可以實現客戶流失的動態監測.
總之,用于客戶流失預測的算法很多,既包括統計學的方法,也包括機器學習的方法,還有一些其他方法.每一種方法都具有自己的特點從而適用于不同的條件,表1對最常用的幾種預測方法進行了總結.
4.2 特征選擇方法
由于客戶流失數據集里包含了很多無關的多余的變量,過多的變量會帶來多重共線性、過擬合、過參數化甚至欺騙性的結果等問題[62],所以在建立預測模型之前,需要進行變量選擇. De等[22]使用主成分分析、獨立成分分析、稀疏隨機投影三種特征提取方式研究模型. Nie等[3]先對變量做相關性分析,將相關性程度很強的變量做刪除,再用逐步回歸篩選變量.Masand等[37]先使用決策樹進行屬性選擇,再使用遺傳算法降維. Amin等[24]使用mRMR進行特征選擇.Fathian等[66]認為使用主成分分析進行預處理后的數據更適合建模. 文獻[67-69]通過粗糙集方法約簡模型解釋變量. 張瑋等[11]利用直方圖檢驗和卡方檢驗相結合的方法對模型變量進行篩選.

表1 客戶流失常用預測方法
5 模型評估的常用技術與度量
5.1 模型評估的常用技術
評估分類器性能的常用技術有3種. 保持方法是最常用的方法,在這種方法中,給定的數據集隨機地劃分成兩個獨立的集合: 訓練集和測試集. 使用訓練集建立模型,使用測試集檢驗模型. 例如 Vafeiadis等[20]使用2/3的數據作為訓練集,1/3的數據作測試集.Coussement等[9]將原始數據分為學習集(50%)、選擇集(20%)、驗證集(30%),其中,學習集用于建立模型,選擇集用于預處理和建模過程的參數選擇,驗證集用于檢驗模型性能.
k折交叉驗證法是將初始數據隨機地劃分成k個互不相交的子集或“折”,每個折的大小大致相等.k-1份作為訓練集,1份作為驗證集,依次輪換訓練集和驗證集迭代k次,總準確率取每次迭代準確率的平均值.例如Vafeiadis等[20]采用100折交叉驗證; Moeyersoms等[23]采用10折交叉驗證; Huang等[10]采用5折交叉驗證; De 等[22]采用 2 折交叉驗證.
與上面兩種方法不同,自助法是用小樣本估計總體值的一種非參數方法,它是從給定訓練集中有放回的均勻抽樣. 最常用的一種是.632自助法: 假定給定的數據集有d個元組,那么從該數據集中有放回地抽樣d次,產生的自助樣本集作為訓練集,沒有進入訓練集的元組作為測試集,計算該次迭代的準確率,繼續這樣迭代k次,模型的總體準確率用下式估計:
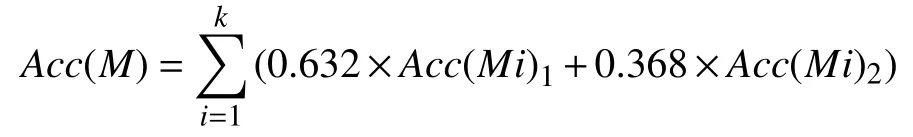
其中,Acc(Mi)1是自助樣本i得到的模型用于測試集i的準確率,Acc(Mi)2是自助樣本用于原數據元組集的準確率. Holtrop等[70]和丁君美等[38]即是采用了Bootstrap抽樣.
5.2 模型評估度量
最常用的評估度量包括精度(Precision)、召回率(Recall)或稱敏感度 (Sensitivity)、特效性(Specificity)、準確率(Accuracy)、F值(F-measure);ROC曲線和AUC值; 提升度(Lift)和Gini系數.
雖然Accuracy在模式分類中是最主要的衡量指標,但是在客戶流失方面,AUC和Lift是常用的指標[22].Masand等[37]指出雖然Accuracy常用來評價模型的性能,但是并不適合市場環境,因此他對于模型的評估采用了Lift而不是Accuracy. Accuracy是需要指定固定閾值計算而得,而AUC是不受閾值變化影響的,相比Accuracy,AUC具有較強的魯棒性,因此能較為客觀衡量分類模型的性能[71,72]. Chen等[21]也認為Accuracy不適合用來評估正負樣本不平衡的數據. 盡管如此,Hand[73]提出了AUC存在最大的缺點是對于不同的分類器沒有采用統一的誤判成本分布,對于同一個問題,正樣本誤判成本與負樣本誤判成本的倍數關系是固定的,而AUC卻在不同的分類器上采用了不同的倍數關系.
在大部分研究中,學者們通常使用上述多種指標共同評估分類器對所用樣本的分類能力. Vafeiadis等[20]采用Precision、Recall、Accuracy、F-measure比較SVM、BPN、決策樹、樸素貝葉斯、Logit及SVM集成、BPN集成、決策樹集成的模型效果. Coussement等[9]使用AUC和Top-decile Lift評估Logit模型效果.De 等[22]使用 Accuracy,AUC 和 Top-decile Lift三個指標衡量模型效果. Neslin 等[16]和 Holtrop 等[70]使用 Topdecile Lift和 Gini系數作為衡量指標. Lima 等[15]使用Accuracy、Sensitivity、Specificity、AUC作為評價標準. Jahromi等[5]采用 ROC 和 Lift對 Logit、決策樹、Boosting 進行評價. 夏國恩等[74]使用 Accuracy、Precision、Recall、Lift評估SVM、人工神經網絡、C4.5決策樹、Logit回歸、貝葉斯分類器的分類效果.
除此之外,還有一些其他的評估標準,如Hand[73]于2009年提出了H-measure的評估指標. 丁君美等[38]認為在不平衡分類中,分類精度并不能作為衡量分類性能的評價指標,因此.提出了生命價值比(LVR)的評估指標. Chen 等[21]除了使用 Accuracy、Sensitivity、Specificity、AUC、Lift指標,同時考慮 H-measure、MP(最大利潤)對H-MK-SVM、MK-SVM、SVM模型進行評價. Tamaddoni等[36]認為現有的評估標準都關注模型準確率,卻忽視了企業利潤,因此,他除了使用Lift,也使用了 MP(最大利潤). Lessmann 等[75]除了使用 Accuracy,AUC,Gini系數,還將 H-measure,Brier Score,KS統計量作為評估指標.
6 不足和未來的研究方向
(1) 流失客戶的定義研究. 流失客戶的定義常見有基于消費頻率和基于消費金額兩種方法. 對于不同行業,流失客戶的定義不同,電信業的客戶屬于契約型客戶,其流失定義較為明確,終止契約即可視為流失,但是對于諸如電子商務、零售業等非契約型應用場景,無法準確判斷客戶是否真的流失,流失客戶的定義全憑研究者決定,導致研究結果帶有一定主觀性. 現有文獻中對如何合理定義流失客戶還未總結出系統的經驗指導. 因此,探索如何對流失客戶進行合理定義有其必要性.
(2) 客戶流失原因及挽救方案的研究. 目前對于客戶流失問題的研究主要集中在提高預測模型準確度上,對流失原因及挽救策略的研究較少. 但是,一個好的流失管理系統不應只預測潛在流失客戶,也應包括對流失原因的分析以及挽救措施的實施,因此,客戶流失原因及挽救是客戶流失管理的重要研究方向.
(3) 客戶流失問題的方法研究. 從研究方法上看,目前用于流失客戶的預測模型很多,但是大多數預測模型都只是對單個客戶的流失行為進行預測,對特征客戶群的預測研究較少. 而流失原因分析多以定性和實證分析為主,缺乏量化研究. 挽救策略多采用數學建模的方法,但由于挽救行動的利潤計算涉及的變量較多,包括客戶生存時間、流失速率、流失概率、潛在流失數量、客戶的價值、客戶被成功挽救的概率、挽救人數、企業的成本等等,很容易遺漏變量導致研究結果失真.
(4) 客戶流失預測模型的評估度量研究. 對于客戶流失預測模型的評估度量有很多,Accuracy、AUC和Lift是常用的指標,但這些傳統的指標均聚焦于準確性上,忽視了企業利潤,而企業進行客戶流失管理就是為了實現利潤最大化,因此,探索一些新的評估度量,例如將企業利潤因素考慮到度量中,使得模型效果的評判更加有意義.
(5) 客戶流失應用場景研究. 從應用場景上看,目前客戶流失問題研究多集中于電信、金融、電子商務,尤其以前兩者居多. 但事實上,“客戶”的概念是廣義的,客戶流失問題廣泛存在于各行各業,可以考慮將現有的客戶流失研究場景拓寬至其他行業,例如網絡游戲玩家的流失、人才流失等等.
1Hadden J,Tiwari A,Roy R,et al. Computer assisted customer churn management: State-of-the-art and future trends. Computers & Operations Research,2007,34(10):2902–2917.
2Roberts JH. Developing new rules for new markets. Journal of the Academy of Marketing Science,2000,28(1): 31–44.[doi: 10.1177/0092070300281004]
3Nie GL,Rowe W,Zhang LL,et al. Credit card churn forecasting by logistic regression and decision tree. Expert Systems with Applications,2011,38(12): 15273–15285.[doi: 10.1016/j.eswa.2011.06.028]
4Blattberg RC,Kim BD,Neslin SA. Database Marketing:Analyzing and Managing Customers. New York: Springer,2008.
5Jahromi AT,Stakhovych S,Ewing M. Managing B2B customer churn,retention and profitability. Industrial Marketing Management,2014,43(7): 1258–1268. [doi: 10.1016/j.indmarman.2014.06.016]
6應維云,覃正,趙宇,等. SVM 方法及其在客戶流失預測中的應用研究. 系統工程理論與實踐,2007,27(7): 105–110.
7Amin A,Anwar S,Adnan A,et al. Customer churn prediction in the telecommunication sector using a rough set approach. Neurocomputing,2017,(237): 242–254.
8Larivière B,Van Den Poel D. Investigating the role of product features in preventing customer churn,by using survival analysis and choice modeling: The case of financial services. Expert Systems with Applications,2004,27(2):277–285. [doi: 10.1016/j.eswa.2004.02.002]
9Coussement K,Lessmann S,Verstraeten G. A comparative analysis of data preparation algorithms for customer churn prediction: A case study in the telecommunication industry.Decision Support Systems,2017,95: 27–36. [doi: 10.1016/j.dss.2016.11.007]
10Huang Y,Kechadi T. An effective hybrid learning system for telecommunication churn prediction. Expert Systems with Applications,2013,40(14): 5635–5647. [doi: 10.1016/j.eswa.2013.04.020]
11張瑋,楊善林,劉婷婷. 基于 CART 和自適應 Boosting 算法的移動通信企業客戶流失預測模型. 中國管理科學,2014,22(10): 90–96.
12Hadiji F,Sifa R,Drachen A,et al. Predicting player churn in the wild. IEEE Conference on Computational Intelligence and Games. Dortmund,Germany. 2014. 1–8.
13Miguéis VL,Van Den Poel D,Camanho AS,et al. Modeling partial customer churn: On the value of first product-category purchase sequences. Expert Systems with Applications,2012,39(12): 11250–11256. [doi: 10.1016/j.eswa.2012.03.073]
14Datta P,Masand B,Mani DR,et al. Automated cellular modeling and prediction on a large scale. Artificial Intelligence Review,2000,14(6): 485–502. [doi: 10.1023/A:1006643109702]
15Lima E,Mues C,Baesens B. Monitoring and backtesting churn models. Expert Systems with Applications,2011,38(1): 975–982. [doi: 10.1016/j.eswa.2010.07.091]
16Neslin SA,Gupta S,Kamakura W,et al. Defection detection:Measuring and understanding the predictive accuracy of customer churn models. Journal of Marketing Research,2006,43(2): 204–211. [doi: 10.1509/jmkr.43.2.204]
17Lemmens A,Gupta S. Managing churn to maximize profits.Boston,MA: Harvard Business School,2013.
18羅彬,邵培基,羅盡堯,等. 基于粗糙集理論—神經網絡—蜂群算法集成的客戶流失研究. 管理學報,2011,8(2):265–272.
19于小兵,曹杰,鞏在武. 客戶流失問題研究綜述. 計算機集成制造系統,2012,18(10): 2253–2263.
20Vafeiadis T,Diamantaras KI,Sarigiannidis G,et al. A comparison of machine learning techniques for customer churn prediction. Simulation Modelling Practice and Theory,2015,55: 1–9. [doi: 10.1016/j.simpat.2015.03.003]
21Chen ZY,Fan ZP,Sun MH. A hierarchical multiple kernel support vector machine for customer churn prediction using longitudinal behavioral data. European Journal of Operational Research,2012,223(2): 461–472. [doi: 10.1016/j.ejor.2012.06.040]
22De Bock KW,Van Den Poel D. An empirical evaluation of rotation-based ensemble classifiers for customer churn prediction. Expert Systems with Applications,2011,38(10):12293–12301. [doi: 10.1016/j.eswa.2011.04.007]
23Moeyersoms J,Martens D. Including high-cardinality attributes in predictive models: A case study in churn prediction in the energy sector. Decision Support Systems,2015,72: 72–81. [doi: 10.1016/j.dss.2015.02.007]
24Amin A,Anwar S,Adnan A,et al. Comparing oversampling techniques to handle the class imbalance problem: A customer churn prediction case study. IEEE Access,2016,(4): 7940–7957. [doi: 10.1109/ACCESS.2016.2619719]
25Jamil S,Khan A. Churn comprehension analysis for telecommunication industry using ALBA. 2016 International Conference on Emerging Technologies (ICET) Islamabad,Pakistan. 2016. 1–5.
26Keaveney SM. Customer switching behavior in service industries: An exploratory study. Journal of Marketing,1995,59(2): 71–82. [doi: 10.2307/1252074]
27Padmanabhan B,Hevner A,Cuenco M,et al. From information to operations: Service quality and customer retention.ACM Trans. on Management Information Systems,2011,2(4): 1–21.
28盛昭瀚,柳炳祥. 客戶流失危機分析的決策樹方法. 管理科學學報,2005,8(2): 20–25.
29于小兵,曹杰,張夢男. B2C電子商務客戶流失原因評估研究. 模糊系統與數學,2012,26(6): 166–172.
30李婷婷. 影響B2C電子商務企業客戶流失因素的實證分析. 對外經貿,2014,(1): 136–137.
31Glady N,Baesens B,Croux C. Modeling churn using customer lifetime value. European Journal of Operational Research,2009,197(1): 402–411. [doi: 10.1016/j.ejor.2008.06.027]
32胡理增,于信陽,張長賦,等. 基于經費約束和廣義客戶終身價值最大化的多客戶流失挽救模型. 系統工程理論與實踐,2009,29(2): 63–69.
33胡理增,陳建軍. 無約束條件下多客戶流失挽救最優化決策. 中國管理科學,2009,17(6): 39–43.
34羅彬,邵培基,羅盡堯,等. 基于競爭對手反擊的電信客戶流失挽留研究. 管理科學學報,2011,14(8): 17–33.
35羅彬,邵培基,羅盡堯,等. 基于預算限制和客戶挽留價值最大化的電信客戶流失挽留研究. 管理學報,2012,9(2):280–288.
36Tamaddoni A,Stakhovych S,Ewing M. Comparing churn prediction techniques and assessing their performance: A contingent perspective. Journal of Service Research,2015,19(2): 123–141.
37Masand B,Datta P,Mani DR,et al. CHAMP: A prototype for automated cellular churn prediction. Data Mining and Knowledge Discovery,1999,3(2): 219–225. [doi: 10.1023/A:1009873905876]
38丁君美,劉貴全,李慧. 改進隨機森林算法在電信業客戶流失預測中的應用. 模式識別與人工智能,2015,28(11):1041–1049.
39Gordini N,Veglio V. Customers churn prediction and marketing retention Strategies. An application of support vector machines based on the AUC parameter-selection technique in B2B e-commerce industry. Industrial Marketing Management,2016,62: 100–107.
40Yu XB,Guo SS,Guo J,et al. An extended support vector machine forecasting framework for customer churn in ecommerce. Expert Systems with Applications,2011,38(3):1425–1430. [doi: 10.1016/j.eswa.2010.07.049]
41Saradhi VV,Palshikar GK. Employee churn prediction.Expert Systems with Applications,2011,38(3): 1999–2006.[doi: 10.1016/j.eswa.2010.07.134]
42Runge J,Gao P,Garcin F,et al. Churn prediction for highvalue players in casual social games. IEEE Conference on Computational Intelligence and Games (CIG). Dortmund,Germany. 2014. 1–8.
43Günther CC,Tvete IF,Aas K,et al. Modelling and predicting customer churn from an insurance company.Scandinavian Actuarial Journal,2014,2014(1): 58–71. [doi:10.1080/03461238.2011.636502]
44Schmittlein DC,Morrison DG,Colombo R. Counting your customers: Who are they and what will they do next?Management Science,1987,33(1): 1–24. [doi: 10.1287/mnsc.33.1.1]
45馬少輝,劉金蘭. Pareto/NBD 模型實證與應用研究. 管理科學,2006,19(5): 45–49.
46Fader PS,Hardie BGS,Lee KL.“Counting your customers”the easy way: An alternative to the Pareto/NBD model.Marketing Science,2005,24(2): 275–284. [doi: 10.1287/mksc.1040.0098]
47夏國恩. 客戶流失預測的現狀與發展研究. 計算機應用研究,2010,27(2): 413–416.
48Xie YY,Li X. Churn prediction with linear discriminant boosting algorithm. 2008 International Conference on Machine Learning and Cybernetics. Kunming,China. 2008.228–233.
49應維云,藺楠,謝雅雅,等. 用 LDA Boosting 算法進行客戶流失預測. 數理統計與管理,2010,29(3): 400–408.
50Abbasimehr H,Setak M,Tarokh MJ. A comparative assessment of the performanceof of ensemble learning in customer churn prediction. The International Arab Journal of Information Technology,2014,11(6): 599–606.
51Hu XH. A data mining approach for retailing bank customer attrition analysis. Applied Intelligence,2005,22(1): 47–60.[doi: 10.1023/B:APIN.0000047383.53680.b6]
52Kim YS. Toward a successful CRM: Variable selection,sampling,and ensemble. Decision Support Systems,2006,41(2): 542–553. [doi: 10.1016/j.dss.2004.09.008]
53Lu JX. Predicting customer churn in the telecommunications industry—An application of survival analysis modeling using SAS. SAS User Group International (SUGI27) Online Proceedings. http://www2.sas.com/proceedings/sugi27/p114-27.pdf. [2012/2017-02-28].
54Adebiyi SO,Oyatoye EO,Mojekwu JN. Predicting customer churn and retention rates in Nigeria’s mobile telecommunication industry using markov chain modelling. Acta Universitatis Sapientiae Economics and Business,2015,3(1):67–80.
55袁旭梅,康鍵,張昕. 動態CRM模型在電子商務中的應用.中國管理科學,2003,11(S1): 343–347.
56Richter Y,Yom-Tov E,Slonim N. Predicting customer churn in mobile networks through analysis of social groups. Proc.of the 2010 SIAM International Conference on Data Mining.Columbus. 2010. 732–741.
57Verbeke W,Martens D,Baesens B. Social network analysis for customer churn prediction. Applied Soft Computing,2014,14: 431–446. [doi: 10.1016/j.asoc.2013.09.017]
58Rehman A,Ali AR. Customer churn prediction,segmentation and fraud detection in telecommunication industry.ASE Science Division Conferences. Cambridge,MA,USA.2014. 1–9.
59Pettersson M. SPC with applications to churn management.Quality and Reliability Engineering International,2004,20(5): 397–406. [doi: 10.1002/(ISSN)1099-1638]
60Jiang W,Au T,Tsui KL. A statistical process control approach to business activity monitoring. IIE Trans.,2007,39(3): 235–249. [doi: 10.1080/07408170600743912]
61Samimi Y,Aghaie A. Monitoring usage behavior in subscription-based services using control charts for multivariate attribute characteristics. IEEE International Conference on Industrial Engineering and Engineering Management. Singapore,Singapore. 2008. 1469–1474.
62Chen SH. The gamma CUSUM chart method for online customer churn prediction. Electronic Commerce Research and Applications,2016,17: 99–111. [doi: 10.1016/j.elerap.2016.04.003]
63Mozer MC,Wolniewicz R,Grimes DB,et al. Predicting subscriber dissatisfaction and improving retention in the wireless telecommunications industry. IEEE Trans. on Neural Networks,2000,11(3): 690–696. [doi: 10.1109/72.846740]
64Brandusoiu I,Toderean G. Churn prediction in the telecommunications sector using support vector machines. Acta Technica Napocensis,2016,57(1): 27–30.
65Kirui C,Hong L,Wilson C,et al. Predicting customer churn in mobile telephony industry using probabilistic classifiers in data mining. IJCSI International Journal of Computer Science Issues,2013,10(2): 165–172.
66Fathian M,Hoseinpoor Y,Minaei-Bidgoli B. Offering a hybrid approach of data mining to predict the customer churn based on bagging and boosting methods. Kybernetes,2016,45(5): 732–743. [doi: 10.1108/K-07-2015-0172]
67柳炳祥,盛昭翰. 一種基于Rough集的客戶流失風險分析方法. 中國管理科學,2002,10(S1): 130–133.
68朱幫助. 基于SMC-RS-LSSVM的電子商務客戶流失預測模型. 系統工程理論與實踐,2010,30(11): 1960–1967. [doi:10.12011/1000-6788(2010)11-1960]
69琚春華,盧琦蓓,郭飛鵬. 融入個體活躍度的電子商務客戶流失預測模型. 系統工程理論與實踐,2013,33(1): 141–150. [doi: 10.12011/1000-6788(2013)1-141]
70Holtrop N,Wieringa JE,Gijsenberg MJ,et al. No future without the past? Predicting churn in the face of customer privacy. International Journal of Research in Marketing,2016,34(1): 154–172.
71Provost FJ,Fawcett T,Kohavi R. The case against accuracy estimation for comparing induction algorithms. Proc. of the 15th International Conference on Machine Learning. Morgan Kaufmann,San Francisco,USA. 1998. 98. 445–453.
72Langley P. Crafting papers on machine learning. Proc. of the 17th International Conference on Machine Learning. San Francisco,CA,USA. 2000. 343–354.
73Hand DJ. Measuring classifier performance: A coherent alternative to the area under the ROC curve. Machine Learning,2009,77(1): 103–123. [doi: 10.1007/s10994-009-5119-5]
74夏國恩,金煒東. 基于支持向量機的客戶流失預測模型. 系統工程理論與實踐,2008,28(1): 71–77.
75Lessmann S,Baesens B,Seow HV,et al. Benchmarking state-of-the-art classification algorithms for credit scoring:An update of research. European Journal of Operational Research,2015,247(1): 124–136. [doi: 10.1016/j.ejor.2015.05.030]
Current Situation and Prospect of Customer Churn Management
ZHANG Zhu-Xiang,LUO Nian-Bei
(School of Economics and Management,Fuzhou University,Fuzhou 350108,China)
This paper summarizes the literature about the following aspects: the definitions of customer churn and customer churn management; research contents and application scenarios of customer churn issues; customer churn prediction algorithms and feature extraction methods; the evaluation technologies and measurements. In the end,we point out the shortcomings of the current research and put forward some future research directions.
customer churn management; current situation; prospect
張珠香,駱念蓓.客戶流失管理研究現狀及展望.計算機系統應用,2017,26(12):9–17. http://www.c-s-a.org.cn/1003-3254/6086.html
2017-03-10; 修改時間: 2017-03-27; 采用時間: 2017-03-29
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
