海量病案信息的快速關聯查閱算法設計與實現
2018-01-10 05:49:19陳皇宇陳海云
微型電腦應用 2017年12期
陳皇宇, 陳海云
(南京軍區南京總醫院,南京 210000)
海量病案信息的快速關聯查閱算法設計與實現
陳皇宇, 陳海云
(南京軍區南京總醫院,南京 210000)
為了解決傳統關聯規則查閱算法,在挖掘海量病案數據過程中,存在滯后以及偏差高的缺陷,結合海量病案數據多維多層次屬性,設計一種基于病案多維數據立方體的快速管理查閱算法。采用多維多層次的挖掘結構對病案數據采用關聯規則,設計了OLAP的關聯規則挖掘模型,解決了基于OLAP關聯規則挖掘模型需要頻繁掃描數據集的弊端。對挖掘獲取的關聯規則實施匯總和研究,得到隱藏在病案數據中病人的職業、年齡與疾病間的聯系。依據基于OLAP關聯規則挖掘模型獲取了病案數據集。實驗結果說明,所設計算法面向海量病案數據,具有較高的查閱性能,能夠提高患者就診的滿意度。
海量病案; 信息快遞; 關聯規則; 挖掘算法
0 引言
當前由于數據庫技術以及信息技術的高速發展,醫院信息系統在醫院中的應用價值不斷提升。并且醫院信息系統中的病案數據呈現爆炸式增長,采用有效方法從海量病案信息中,快速查閱出有價值數據,成為相關人員研究的重點[1]。而傳統關聯規則查閱算法,挖掘海量病案數據過程中,存在的滯后性以及偏差高的缺陷。面向該種問題,文章設計并實現了基于病案多維數據立方體的快速管理查閱算法,增強病案信息查閱的效率和精度。
1 基于病案多維數據立方體的查閱算法設計
2.1 海量病案數據挖掘流程設計
數據挖掘即從大量數據中通過一定的算法,提取信息的過程,而數據挖掘模塊包括數據預處理、數據挖掘分析以及知識分析兩個過程。具體數據挖掘流程如圖1所示。
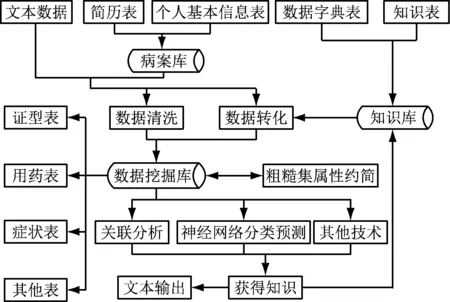
圖1 數據挖掘模塊流程圖
(1) 數據預處理
數據預處理時,在數據庫中采集數據,用數據預處理的方法對病案信息進行匯總分析以及量化分割等操作,獲取有價值數據。操作如下:把選好的數據用“數據清洗”的方法,做刪除缺省值和錯誤等處理[2];通過“數據轉化”,即把醫學表述的數據參照知識庫中的數據字典表用SQL語句轉成機器學習上能處理的數據。并且,系統可以把數據從橫向轉化成縱向,在數據挖掘庫里保存轉化后的數據,方便今后的研究使用。還有另一種數據預處理的方式,它是用粗糙集屬性約簡的方法,約簡數據的屬性:約簡后的屬性通過MIBARK算法被分割出來,放到數據挖掘庫里。
(2) 數據挖掘和知識分析
數據挖掘知識時,篩選待挖掘知識的類別,對于進行過標準操作的,癥狀數據集、證型數據集、中藥數據集,依次采用基于病案多維數據立方體的數據挖掘算法,挖掘出關聯分析知識以及神經網絡分類預測知識。關聯分析知識挖掘時,通過系統封裝的算法文件,從已有的支持度閥值、置信度閥值參數中得到可用的關聯規則[3]。關聯結果呈現出的順序列表為“前件?后件支持度 置信度”。
塑造出基于OLAP的關聯規則挖掘模型,預測被選擇測試的樣本將識別率以及識別結果輸出。知識分析過程時,融合得到的挖掘知識和知識庫中的知識,獲取醫藥方劑配伍規律、癥狀與用藥之間的聯系和癥狀-證型的辯證辨別規律。
1.2 病案多維數據立方體的體系結構設計
塑造病案數據倉庫可從醫院信息系統中海量歷史病案數據內獲取有用信息,多維數據是分析數據倉庫的基本數據單位,文章采用SQLServer2005中的Mic:osoftAnalysisServer塑造病案數據分析的維度以及多維數據集。Microsoft Analysis Server體系結構圖,如圖2所示。
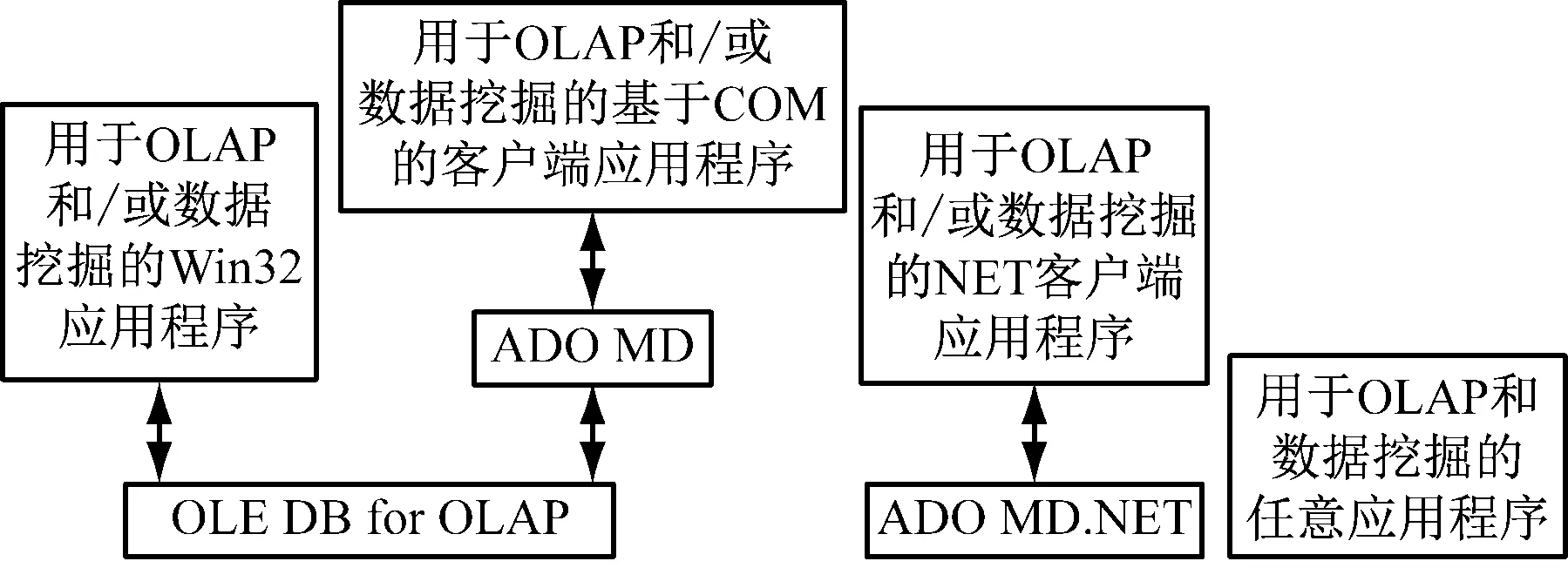

圖2 Microsoft Analysis Server體系結構圖
Microsoft Analysis Server系統是用于OLAP的中間層服務器,其由服務端以及客戶端構成。服務端組件可對多維數據結構實施塑造以及維護,同時產生多維數據,為客戶端檢索提供服務。其能夠對OLAP數據實施素質和控制,通過透視表(PivotTable)向客戶端提供數據支撐的性能,需要從詳細的依據關系型數據庫的數據倉庫內塑造多維數據立方體,并將其保存到多維立方體結構以及關系數據庫中。關系數據庫內的存儲單元內保存著多維立方體結構。透視表服務是客戶端的重點內容,其是應用程序訪問Microsoft Analysis Server的接口,Microsoft Excel以及其它應用程序采用該接口獲取服務器中的數據,并向用戶程序反饋相關結果。基于透視表服務還能夠塑造本地多維數據集[4],該服務可同Analysis Server連接,向用戶以及客戶端應用程序創造相關的接口,從服務端采集OLAP數據。Analysis Server具有較強的OLAP環境,其具有的功能是:塑造完多維層次結構后,向多維立方體中融入病案數據倉庫內的數據,塑造同病案數據倉庫數據源BA-DW的數據連接,基于多維層次模型塑造數據源視圖,病案數據倉庫內的病案事實表、病人信息表以及疾病診斷表導入對應的表格信息。不同的維表基于自身的ID號同病案事實表,塑造一定的關聯性,將相關度量信息以及維表中的關鍵字信息存儲到病案事實表中,可塑造病案多維數據集結構。數據倉庫數據不斷調整過程中,病案多維數據集無法對病案數據倉庫的數據波動狀態進行及時反應,病案數據倉庫實施數據修正以及刷新后,應對多維立方體數據實施再次修正和操作。
上述塑造的病案多維數據立方體,可從不同維度以及層次對病案數據實施匯總研究,文章為了實現海量病案信息的快速并聯查閱,基于病案多維數據立方體,將關聯規則挖掘應用到病案數據分析,設計并實現多維多層次的關聯規則挖掘模型。
1.3 基于OLAP的關聯規則設計
在數據倉庫中,很多的數據是在數據倉庫和OLAP技術研究提高的基礎上,通過整合以及預處理的。用戶的需求是從數據庫中篩選出各類有關聯的數據,研究各種各樣的細節層次,用不同方式顯示知識。OLAP挖掘是能應用在不同數據集、不同的細節上的挖掘[5],因此能實施切片、切塊、展開、過濾等操作。結合部分可視化的工具,數據挖掘的靈敏度以及性能得到了突飛猛進的進步。下面,對多層和多維關聯規則進行闡釋。
(1) 多層關聯規則
因為數據分布的分散性,大多數的應用在數據最細節的層次上不容易察覺出部分強關聯規則。若在高層次上實施挖掘,可導入概念層次[6]。高層次上獲取的規則信息價值度較低,無法滿足用戶的興趣要求。數據挖掘應有這樣在多個層次上實施挖掘的性能。“支持度-可信度”的構造同樣適用于多層關聯規則的挖掘。
(2) 多維關聯規則
上述為同字段的值間的關聯的探究,例如病人所患有的疾病間的關聯。單維或多維的關聯規則即為多維數據庫的語言,它們挖掘于交易數據庫。而多維數據庫中,還有一類多維的關聯規則。如:
年齡(X,“40—50”)and性別(X,“女”)患有(X,“營養性貧血”)
其中提到三個維年齡、性別以及疾病的資料。若不允許維重復出現,則為維間的關聯規則,若允許維在規則的左右同時出現,則為混合維關聯規則,則有:
年齡(X,“40—50”)and患有(X,“營養性貧血”)?患有(X,“溶血性貧血”)
多維關聯規則是一種混合維關聯規則,對這類規則實施挖掘時應分析不同字段是連續型還是離散型。
1.3.1 病案數據關聯規則挖掘模型設計
從關聯規則算法的分析中得知,必須提前產生大規模的候選集和頻繁的對事務數據庫做掃描,是實施關聯規則挖掘的阻礙,要想明顯的減少頻繁項集形成時間以及減少對事務數據庫的掃描次數,就要把OLAP立方體中的大量聚集數據運用起來。以下通過根據病人主題域的病案多維數據立方體設計關聯規則挖掘模型。
(1) 病案數據挖掘對象分析及算法選擇
病人主題域的多維數據集包括病人的基本情況以及疾病分類信息等幾個維度。事務表信息依據病人的基本信息塑造,病人住院時的疾病診斷都在其中,可用來研究疾病間的關系以及相應的約束程度。病人情況等維作為輸入信息,建立數據挖掘模型,進而對病人的基本信息(年齡、性別、職業、出生地等)對患得疾病的干擾實施研究。依據對關聯規則算法的研究得出,對事務型數據實施單層單維的布爾型關聯規則挖掘可用Apriori算法,該種算法在多維多層的病案數據挖掘中使用較少[7]。文章實施病案數據挖掘所用的方法是MICrosoft關聯規則算法,這種算法在對關系數據庫實施關聯規則挖掘時起到了重要作用。它能通過OLAP多維數據集實施多維多層次的關聯規則挖掘,有效運用病案多維數據立方體中的聚集型數據,以達到快速搜索頻繁項集的目的。其挖掘頻繁項集時[8],為了加快頻繁項集的生成效率,可依據MDX語句對病案多維數據立方體內的聚集信息實施檢索,進而獲取頻繁項集;關聯規則的閥值是在頻繁項集形成的相關規則基礎上,設置最小支持度(Minimum_Support)、最小置信度(Minimum_Probability)和最小興趣度(Minimum_Importance)而形成,有靈活和準確的優點。
(2) 病案數據挖掘模型設計
關聯規則挖掘的事例表能夠看成是疾病診斷維表,該表的輸入列為入院日期維、病人信息維和出生地維維度的信息,通過構建的OLAP病案多維數據立方體的聚集信息,實施多維多層次的關聯規則挖掘。基于病人主題域的挖掘結構,塑造病人主題域的挖掘模型[9-11],如圖3所示。
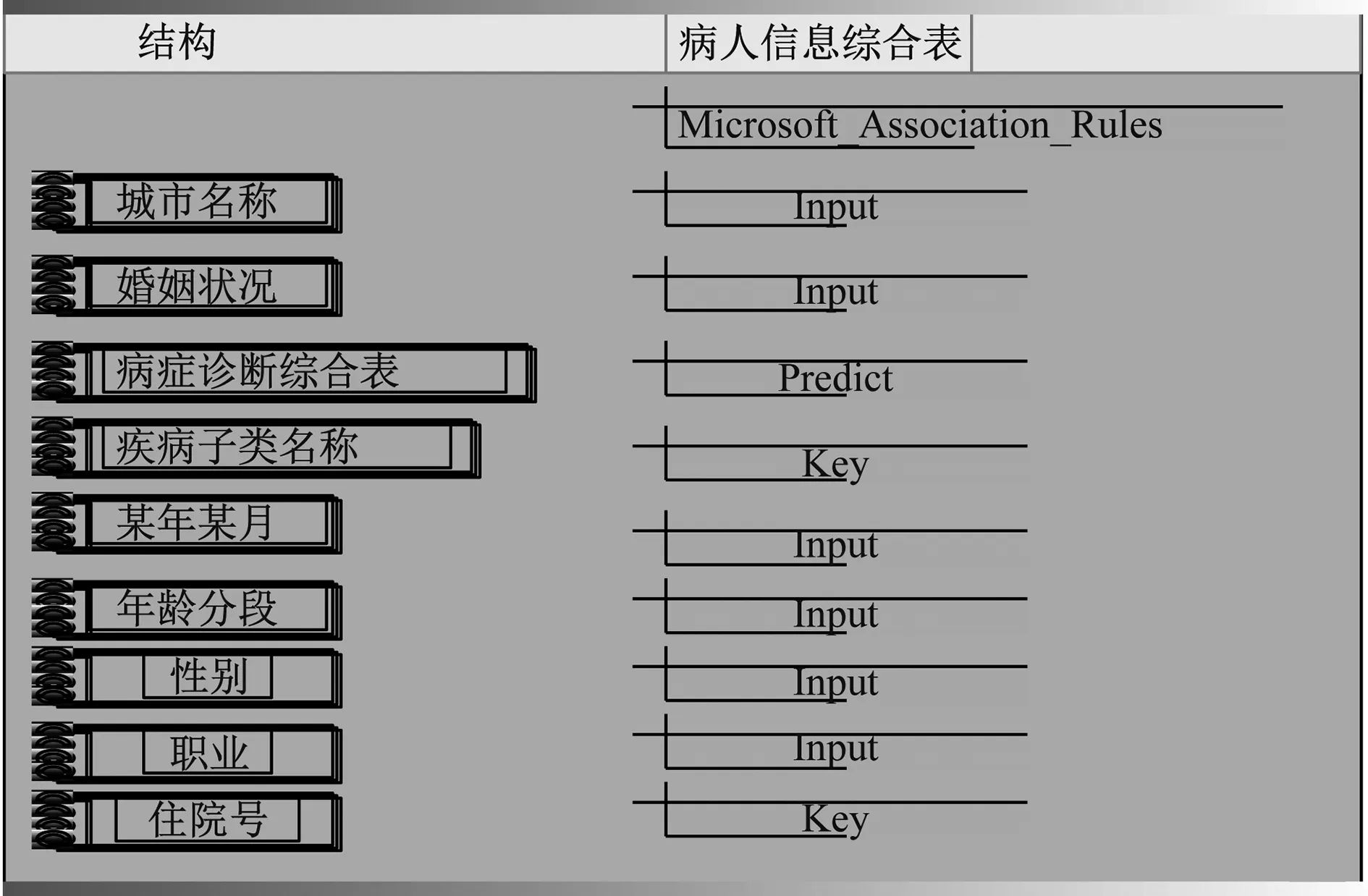
圖3 病人主題域的挖掘模型圖
其可能夠研究病人的性別、年齡和職業等信息特點以及所患疾病,目的是研究疾病間的關系和病人的情況特點是否對疾病關系起作用[12]。
1.3.2 基于關聯規則Apriori的數據挖掘算法設計
文章采用基于云計算的MapReduce模式的快速管理規則Apriori數據挖掘算法,解決基于OLAP關聯規則挖掘模型需要頻繁掃描病案多維數據立方體的弊端,進一步提高海量病案信息查閱的效率。
通常采用關聯規則的Apriori算法挖掘海量病案數據,該算法通過逐層建設迭代受到基于K項集實施(K+1)項集的查詢,對基于OLAP關聯規則挖掘模型獲取的病案數據集實施檢索后[13],產生頻繁1-項集L1,基于L1實施獲取頻繁項集L2,通過持續迭代受到直到頻繁項集是空集。頻繁項集中的任意一個子集都是頻繁項集,可降低檢索區域,提高頻繁項集產生效率。通過K次信號檢索后,海量病案數據的挖掘過程是:(1)對JOIN(連接)指令實施處理,要求Lk-1形成候選集Ck,同時實施連接處理;(2)基于Apriori性質實施支持度匯總以及剪枝處理,要求Ck形成頻繁集Lk。但是該種算法對數據庫實施大量檢索操作,最終得到全部頻繁項集,挖掘海量病案數據過程中,存在挖掘效率低以及耗能高的缺陷。因此,文章基于云計算平臺的分布式運算屬性,塑造Hadoop架構保存檢索數據庫,獲取頻繁項集得到的關聯規則,檢索處理將不同DataNode節點(病案多維數據立方體)內實施并行處理[14],得到不同運算節點中的局部頻繁項集。最終通過Master獲取真實的全局支持度、頻繁項集匯總結果,降低挖掘時間以及能耗,極大提高了病案數據的挖掘效率。
上述描述的Apriori算法Map/Reduce化的詳細過程如圖4所示。
2 實驗分析
實驗對某醫院2009—2013年期間的病案信息實施查閱檢測,檢測本文設計并實現的海量病案信息快速關聯查閱算法的性能。
2.1 試驗關聯參數的設計
本文數據挖掘算法融合先驗知識,采用合理的參數閥值,獲取有價值的規則,主要有:
(1) 病人的職業與各類疾病之間的相互聯系
患者職業同疾病間存在一定的關聯性,對這些關聯性實施分析,為醫生實施診斷提供依據,如表1、表2所示。

圖4 Map/Reduce化的Apriori挖掘算法的實現流程

置信度興趣度規則前項規則后項0.6130.52精神以及行為障礙,呼吸系統疾病循環系統疾病0.7240.58精神以及行為障礙,內分泌,營養以及代謝疾病循環系統疾病0.6170.52精神以及行為障礙,神經系統疾病循環系統疾病0.6070.52泌尿生殖系統疾病,呼吸系統疾病循環系統疾病0.6570.54內分泌、營養以及代謝疾病,呼吸系統疾病循環系統疾病0.6870.57神經系統疾病,泌尿生殖系統疾病循環系統疾病0.640.55神經系統疾病,內分泌、營養以及代謝疾病循環系統疾病0.5860.51血液及造血器官疾病,泌尿生殖系統疾病循環系統疾病

表2 腎小球疾病患者同職業間的關聯
分析表1能夠看出,患有腎小球疾病的患者,受到職業的影響,其患有腎衰竭疾病的概率存在一定的差異,具體情況用表2描述,從中能夠看出腎衰竭疾病同患者工作強度具有較高的關聯性,勞累對腎衰竭疾病具有不利干擾。
(2) 病人年齡與各類疾病之間的相互聯系
病人年齡同疾病存在一定的關聯性,如表3所示。
分析表3可以看出腎衰竭病人同時患有高血壓病的概率大小同年齡相關,患有腎衰疾病的老年人容易出現高血壓病。

表3 腎衰竭疾病同患者年齡間的關聯
2.2 原數據集大小變化時的性能
如果向實驗病案信息中融入新的數據集d大小是0.2G,支持度是20%,則原病案信息發生變化時,本文算法和傳統關聯規則算法的查閱結果,如圖5所示。
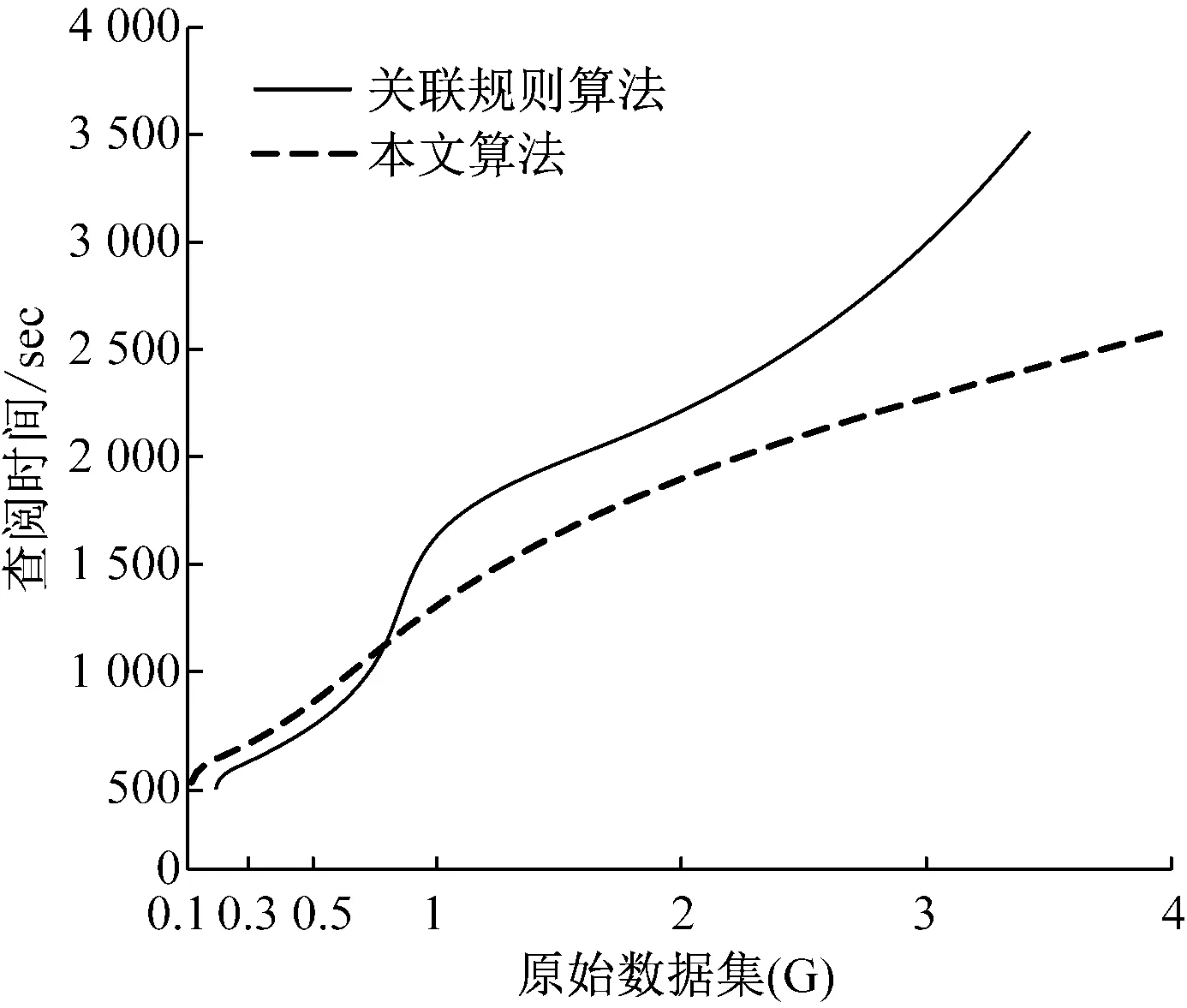
圖5 原數據集波動情況下的查閱性能
分析圖5可得,相同軟硬件配置狀態時,如果原病案信息量較低,兩種算法的查閱性能基本一致,隨著原病案信息量的不斷提升,傳統關聯規則算法的性能顯著降低,當病案信息量是4G時,傳統關聯規則算法不能完成病案信息的查閱,主要是因為此時其對內容調用失敗。但是本文算法的性能隨著原病案信息的提高而持續提升,其面向海量病案信息時,具有較強的查閱優勢。
2.3 新增數據集大小變化時的性能
若原病案數據集D的容量是1G以及2G,支持度是20%,則當新增數據集容量不斷變換時,不同算法的差異性能,如圖6所示。
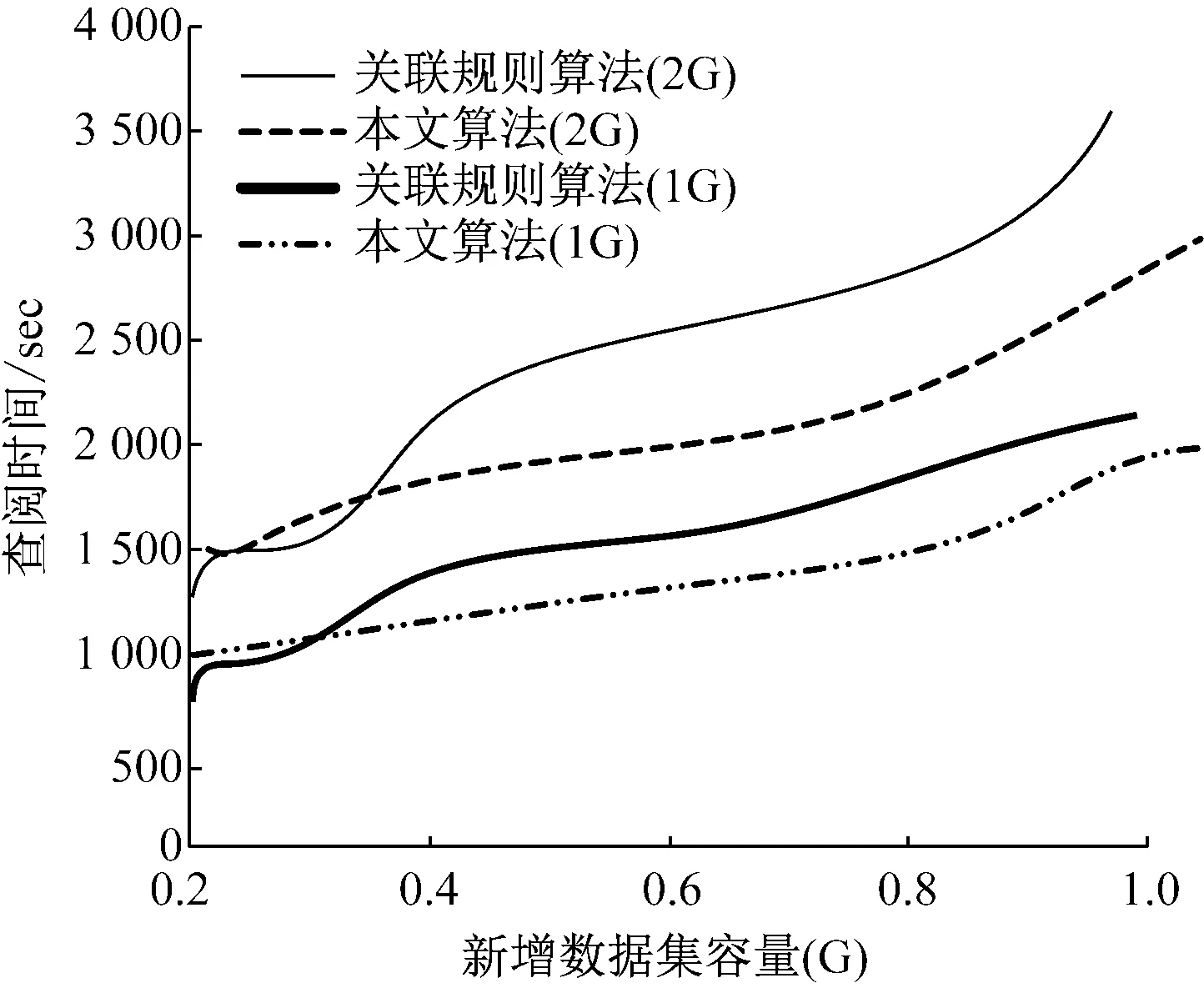
圖6 新增數據集大小波動情況下的性能
分析圖6能夠得出,如果原病案數據集的容量是低于0.4G,傳統關聯規則算法比本文算法性能優,主要是因為本文算法對于大規模數據的并行運算具有較高的優勢,如果病案數據集較低,本文算法需要耗費較高的調度代價,而當病案數據集容量較高情況下,本文算法耗費較低的調度代價。因此,當原病案數據集容量是0.8G,本文算法的查閱性能顯著優于傳統關聯規則算法,當新增數據集容量是1G時,傳統關聯規則算法不能繼續運行。因此能夠看出,面向海量病案數據時,本文算法的性能優于傳統關聯規則算法。
2.4 完全分布環境下的性能比較
實驗塑造1個DataNode、2個DataNode、3個DataNode以及4個DataNode組建的分布環境的病案信息集群,檢測本文算法在這些集群中實施關聯查閱,以及關聯規則算法的查閱時間,結果如圖7所示。

圖7 關聯規則算法以及本文算法集群的對比
分析圖7能夠得出,如果原病案數據集容量較低,則本文算法的處理效率以及傳統關聯規則的處理效率一致。主要是本文算法實施并行運行過程中,通過OLAP多維數據集實施多維多層次調度需耗費較多的能量,如果原病案數據集較少,耗費的能量占總體算法能耗的較高比例,使得算法處理效率降低。但是隨著原病案數據集的提高,本文算法集群的運行效率顯著優于傳統關聯規則算法。本文算法具有較高的集群并行運算性能和較強的運算能力。分析圖7可得,相對于傳統關聯規則算法,本文算法的可伸縮性能高,隨著數據集的提高,算法的運行時間呈現線性提升。
2.5 基于門診病案的診斷關聯挖掘分析
實驗對2010年某省級醫院門診病案數據實施挖掘分析,通過本文算法對門診病案實施多維多層的數據分析,獲取內在問題,尋求合理的解決措辭。基于HIS的門診掛號信息、LIS檢驗信息以及PACS檢測信息等實施數據挖掘,基于門診病案數據源,融合掛號信息數據集,實施病案數據關聯查閱。采用本文算法頻繁掃描以門診患者為粒度的門診數據集,將患者掛號信息同科室信息相對應。關聯規則:口診患者各科室各環節時間分析,分析不同科室平均各環境耗費時間,獲取平均值以及耗時高的科室分布情況。
AVG(Sum(各環節時間))
Group By 患者掛號所在科室
不同環節耗費時間比例(%)=各環境耗費時間/就診耗費總時間×100%
基于該關聯規則,采用本文算法依據科室分類運算出各患者在就診時不同環境耗費的時間,結果如圖8所示。
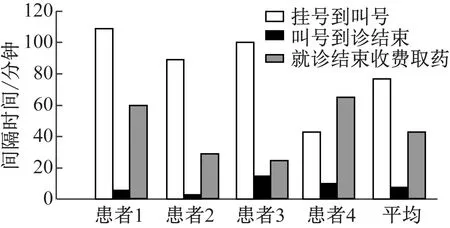
圖8 就診流程時間排列分析
采集從掛號到就診終止耗費時間高于60分鐘的患者信息,采集匯總后實施挖掘分析,獲取相關的控制方案。
采用本文算法基于設置的關聯規則挖掘門診患者的就診信息,研究患者就診耗費的時間,實現不同資源的有效調配,并提出相關的處理措施,降低排隊時間,提高患者滿意度。
綜合分析上述實驗結果可得,采用本文設計的海量病案信息快速關聯查閱算法,能夠挖掘出有價值信息,對門診病案數據實施多維度多層挖掘分析,能夠獲取問題根源,實時調控管理方案,提高患者就診的滿意度,具有較高的應用價值。
3 總結
文章基于病案數據多維多層次屬性,設計并實現基于病案多維數據立方體的快速管理查閱算法,采用多維多層次的挖掘結構對病案數據實施關聯規則挖掘,通過基于關聯規則Apriori的數據挖掘算法,解決基于OLAP關聯規則挖掘模型需要頻繁掃描病案多維數據立方體的弊端,進一步提高海量病案信息查閱的效率。
[1] 吳曉云, 鄭銀雄, 馮笑玲. 基于數據庫的醫院病案信息SQL查詢[J]. 中國衛生統計, 2014, 31(1):144-145.
[2] 黃東瑾, 謝玲珠, 鄭仰純,等. 基于病案首頁數據挖掘的老年糖尿病患者住院日影響因素分析[J]. 廣東醫學, 2016, 37(13):1952-1956.
[3] 林媛. 非結構化網絡中有價值信息數據挖掘研究[J]. 計算機仿真, 2017, 34(2):414-417.
[4] 包小源, 俞國培, 李巖. 病案首頁數據分布式集成管理平臺的設計與應用[J]. 中國醫院管理, 2014, 34(5):30-32.
[5] Davydov D, Young T D, Steinmann P. On the adaptive finite element analysis of the Kohn-Sham equations: methods, algorithms, and implementation[J]. International Journal for Numerical Methods in Engineering, 2016, 106(11):863-888.
[6] 高武奇, 岳鑫. 基于HBase的圖書借閱數據挖掘模型設計與實現[J]. 電子設計工程, 2017, 25(12):33-36.
[7] 米允龍, 米春橋, 劉文奇. 海量數據挖掘過程相關技術研究進展[J]. 計算機科學與探索, 2015, 9(6):641-659.
[8] 韓希先, 劉顯敏, 李建中,等. TMS:一種新的海量數據多維選擇Top-k查詢算法[J]. 計算機研究與發展, 2017, 54(3):570-585.
[9] Kirchner M, Xu B, Steen H, et al. libfbi: a C++ implementation for fast box intersection and application to sparse mass spectrometry data[J]. Bioinformatics, 2014, 2014(8):1166-1167.
[10] 鄧廣彪. 改進的粒子群算法在云計算下的數據挖掘中的研究[J]. 科技通報, 2017, 33(4):120-124.
[11] 陳炎龍, 段紅玉. 基于改進Hadoop云平臺的海量文本數據挖掘[J]. 湖南師范大學自然科學學報, 2016, 39(3):84-88.
[12] 周發超, 王志堅, 葉楓,等. 關聯規則挖掘算法Apriori的研究改進[J]. 計算機科學與探索, 2015, 9(9):1075-1083.
[13] 李雨童, 姚登舉, 李哲,等. 基于R的醫學大數據挖掘系統研究[J]. 哈爾濱理工大學學報, 2016, 21(2):38-43.
[14] Kovtoun S V. An Approach to the Design of Mass-correlated Delayed Extraction in a Linear Time-of-flight Mass Spectrometer[J]. Rapid Communications in Mass Spectrometry, 2015, 11(5):433-436.
[15] 趙艷青, 滕晶, 楊洪軍. 基于數據挖掘的現代中醫藥治療抑郁癥用藥規律分析[J]. 中國中藥雜志, 2015, 40(10):2042-2046.
TheDesignandImplementationoftheFastCorrelationAlgorithmofMassCaseInformation
Chen Huangyu, Chen Haiyun
(Nanjing General Hospital of Nanjing Military Region, PLA Nanjing, Jiangsu 210002, China)
In order to solve the defects of lag and high deviation in the process of mining mass medical data by using traditional association rule, a multi-dimensional data cube algorithm with a power of quick management and access is designed by incorporating with the multi-lecvel mining structure. We perform the association rule for the medical data, design association rule mining model for OLAP. It overcomes the disadvantage of OLAP association rules mining model does not requre frequently the data set. Besides, we conduct a comprehensive stuby of the association rule and get the hiddcn information of patients, such as the occupation, the age as well as the relationship between these data and differnt diseases. Data sets are obtained by mining model based on OLAP association rule mining. The experimental results show that the proposed algorithm can improve the patient's satisfaction by looking at the data of large number of cases.
Mass diseases; Information expressing; Association rules; Mining algorithms
1007-757X(2017)12-0053-05
陳皇宇(1984-),女,本科,技師,研究方向:病案管理,醫療信息管理。
陳海云(1977-),女,本科,護師,研究方向:醫保管理。
TP311.13
A
2017.10.17)
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
