基于RNN結構下的字母級別語言模型的研究與實現
2018-01-13 01:45:20郭邵忠
網絡安全技術與應用 2018年1期
◆劉 辰 郭邵忠 殷 樂
(信息工程大學四院 河南 450001)
0 引言
隨著人工智能技術的發展,RNN模型被廣泛應用在語音識別,機器翻譯和文本生成等領域,并取得了舉世矚目的效果。Recurrent Neural Network (RNN)是一種能學習向量到向量之間映射關系的強力模型,它適用于時序數據集上。但由梯度爆炸和梯度消失的問題的存在,使得RNN結構難于訓練。在學者們的努力下,提出了Long Short-Term Memory (LSTM)模型,解決了梯度消失的問題。梯度爆炸問題相對梯度消失復雜的多,Mikolov與Pascanu通過強制約束梯度范數解決了該問題。Cho 等人提出名為lstm的一種新的改進型Gated Recurrent Unit (GRU),在語言模型的實際應用背景中,兩種實現方法效果不分伯仲。
在natural language processing (NLP)任務中,語言模型是一項基礎工作。語言模型是一個單純的、統一的、抽象的形式系統,語言客觀事實經過語言模型的描述,比較適合于電子計算機進行自動處理,因而語言模型對于自然語言的信息處理具有重大的意義。
神經語言模型Neural Language Models (NLM)通過將詞的參數化作為向量,并將其用作神經網絡的輸入,取得了很好的效果。
雖然NLM比以往的基于統計的語言模型性能表現出色,但是該模型不能分辨出詞根,詞綴或者分詞等信息,例如 like和unlike兩詞應在embedding時候空間位置距離比較接近,這個功能上述模型無法實現。因此,訓練集中沒有或者出現幾率特別小的詞,模型無法理解。實際應用中,尤其在俄文語境下,詞態變化繁復,使得模型訓練成本增大,性能下滑。為了克服上述不足,本文設計了一種char-level語言模型,該模型的輸入是一個個字符。同Botha and Blunsom 2014; Lu-ong,Socher,andManning2013相比下,我們的模型不需要詞素標注,將字母一個個輸入模型就可以。同 Dos SantosandZadrozny 2014比較,我們的模型不需要word-embedding,只需要 char-embedding。我們的模型適用于多種語言,中文的漢字也可以視為char,此時在softmax函數中加入分層功能,運行速度會明顯提高。
1 模型
1.1 循環神經網絡語言模型
若V是所有word的集合,w是V中的任意一個元素(1個word),語言模型可以描述如下:若wi∶t= [w1,…,wt]是歷史出現的word序列,那么語言模型就是描述wt+1出現可能和各個可能的概率情況的工具。
數據首先經過向量化操作(char-embedding),而后經過Highway層,再經過RNN層后會通過一個softmax函數,它將計算輸出端的各個可能性大小,并通過評價函數和同訓練數據相匹配的正確結果來復核評估網絡輸出,最后通過bp算法來校正網絡參數。如圖1。

圖1 模型各模塊情況
1.2 循環神經網絡層
循環神經網絡是一種節點定向連接成環的人工神經網絡。這種網絡的內部狀態可以展示動態時序行為。不同于前饋神經網絡的是,RNN可以利用它內部的記憶來處理任意時序的輸入序列,這讓它可以更容易處理如不分段的手寫識別、語音識別等。神經網絡專家如 Jordan,Pineda.Williams,Elman等于上世紀 80年代末提出的一種神經網絡結構模型。即循環神經網絡(Recurrent Neural Network,RNN)。這種網絡的本質特征是在處理單元之間既有內部的反饋連接又有前饋連接。從系統觀點看,它是一個反饋動力系統,在計算過程中體現過程動態特性,比前饋神經網絡具有更強的動態行為和計算能力。在每個時間脈沖 t,需要輸入一個向量Xt,并結合上一時間脈沖t-1的隱藏狀態向量ht-1,計算出當前時間脈沖下的輸出向量ht。
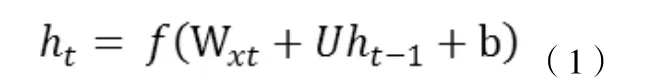
nn.Linear(inputDimension, outputDimension, [bias = true])
在理論上,RNN可以追溯所有的歷史隱藏狀態向量ht,并以之計算當前時間脈沖輸出。在實際應用時候,使用上述 vanilla RNN模型由于梯度下降和梯度爆炸等問題的存在,難以學習到long-range dependencies 。也就是說,這種模型在短句語義理解上較為出色,而且實現簡單,計算量小,但是遇到較長句,就容易丟失前序信息。Long short-term memory (LSTM)應運而生。該模型具體思想就是在 vanilla RNN模型內加入一個 cell向量,這樣,每一個時間脈沖下,LSTM模型就獲得了3個輸入向量:xt,ht-1,ct-1。簡明表達LSTM每個時間脈沖計算公式如下:
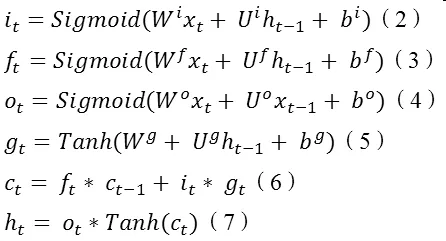
這里的Sigmoid運算符在torch框架上對應nn.Sigmoid,Tanh運算符對應nn.Tanh,‘*’運算符對應nn.CMulTable()(),ct等式中運算符‘+’對應nn.CAddTable()()。
1.3 Highway Network
當語言模型輸入端為字符時,在 RNN模型的基礎上使用Highway Network可以很大程度提高精度,當語言模型輸入為word時無明顯效果。在本文中,我們采用1或2層的Highway Network,具體公式如下:
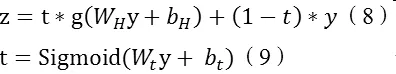
2 實驗設定
語言模型評價函數如下:

NNL是在網絡訓練過程產生的評價數據,T為訓練時間。English Penn Treebank (PTB),是一個標準的英語語言模型測試集,我們將在這個測試級上評估實驗結果。

表1 PTB測試集情況
實驗數據集如表 1所示,其中|V|是語料中的總詞匯量,|C|是字符數目,T是訓練集中的token數量。Data-s是Peen Treebank庫,Data-L是News-Commentary庫,該庫中有一些非英語符號,所以字符種類較多。
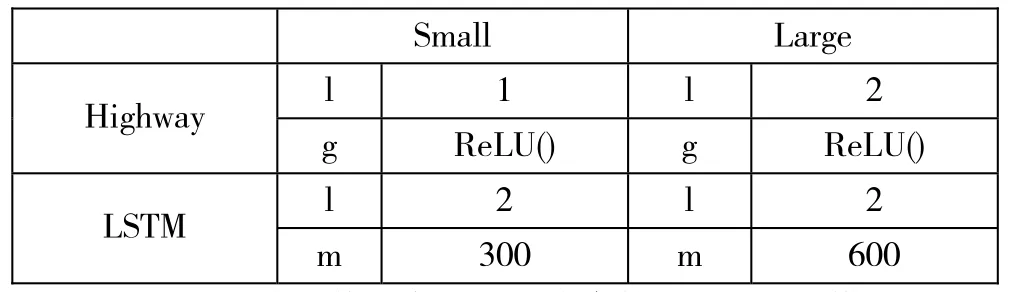
表2 各個網絡層參數配置
表2所示為實驗模型各層次網絡參數設置。Small模型采用1層的Highway激活函數是Relu(),而后通過LSTM模塊(2層,每層300單元)。Large模型Highway模塊設為2層,激活函數不變,LSTM模塊也是2層,每層設為600單元。
只有2G顯卡情況下,large數據集上lstm個數每層最大不能超過600,實驗結果也證實了每層600個lstm單元已經能夠滿足實驗需要,盲目加大數目對結果的影響不明顯。
本文考慮實驗的靈活性,將輸入模塊設計為兩種輸入模式:字符模式和單詞模式。該模型可以轉換為word-level 語言模型,只需更新參數轉換輸入,而后進行單詞級別的語言模型訓練。
實驗優化。在試驗中,遍歷25epochs訓練集,在Data-S訓練集中使用batch-size = 20,在Data-L中使用batch-size = 100,這兩組數字都是其他論文中使用該數據集的經驗數字,在本次試驗中效果良好。
在參數初始化階段,采取了隨機初始化,并且控制參數初始化的范圍在[-0.05,0.05]這樣可以避免產生的模型‘偏激’,難以訓 練 。 在 LSTM 的 input-to-hidden(highway之 后)和hidden-to-output(softmax()之前)使用了dropout規則,設定參數為 0.5,這樣提高了訓練精度。我們限定梯度更新的速率,避免訓練結果偏激,若梯度更新的L2范數大于5那么更新時最大可用更新幅度設為5.0。
3 實驗結果
圖2是訓練loss與測試loss對比圖(LSTM-Char in Data-S),圖中可見訓練過程中參數收斂正常,測試收斂正常,訓練效果顯著,在最后的全集測試中,取得(PPL=92.418545711755)的評價結果。
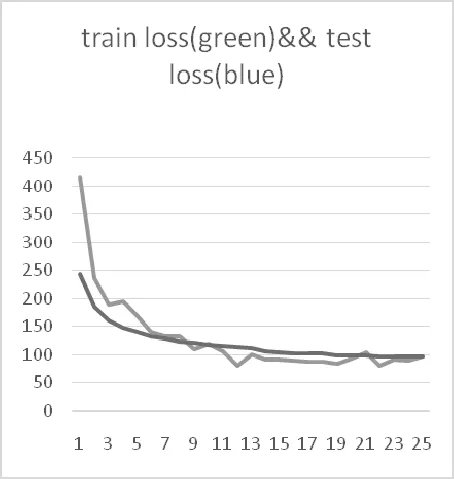
圖2 訓練以及測試曲線
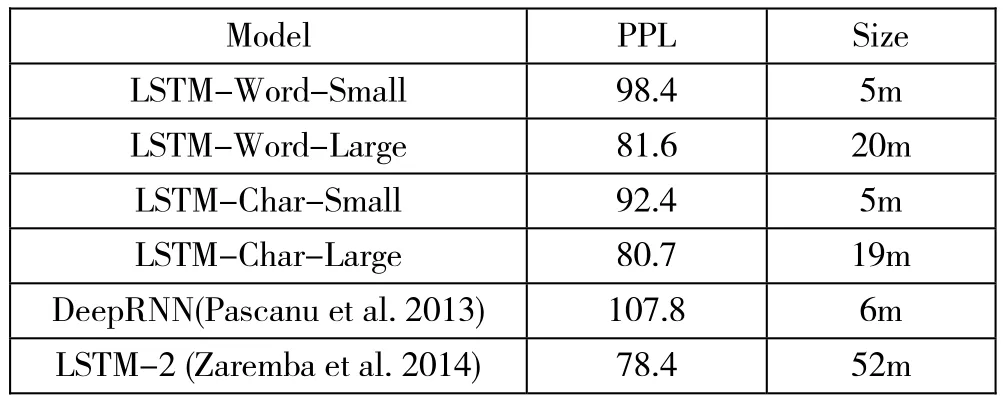
表3 訓練結果
表3所示為最終實驗結果(PPL數值越小越好)。其中前四行為本文所做工作,最后兩行為現階段經典模型實驗結果。從模型的評價來看,我們實現的 LSTM-Word-Large模型稍遜色于LSTM-2 (Zaremba 2014)但我們使用的lstm單元個數少于他們。整體結果來看,我們模型實現已經達到了上游水平。
4 結論
本文實現了一種char-level的語言模型,語言模型是自然語言處理的一個基礎工作,是學習深度學習框架入門的良好課題。一些trciks在提高結果精度顯得特別重要,可以說有些操作直接影響到了結論。想要做一個好用的語言模型比較困難,具體應用的語境下必須取得好的數據,再結合結構的研究和一些技巧才能達到可用的要求,而好用的要求更需要深入的研究和探索。本實驗更換輸入數據也會輸出一些有意思的東西,例如輸入唐詩300首,也可以自動做唐詩,其結果也是剛剛達到了‘說人話’的水平。下一步的改進目標是嘗試在模型中加入更多網絡信息,類似于Net Embedding的做法。Word Embedding與Net Embedding相互借鑒是一個趨勢。
[1] Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult.[J]. IEEE Transactions on Neural Networks,1994.
[2]Surhone L M, Tennoe M T, Henssonow S F. Long Short Term Memory[J]. Betascript Publishing,2010.
[3]Pascanu R, Mikolov T, Bengio Y. On the difficulty of training recurrent neural networks[C]// International Conference on International Conference on Machine Learning. JMLR.org,2013.
[4] Chung J, Gulcehre C, Cho K H, et al. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling[J]. EprintArxiv,2014.
[5]Bengio Y, Schwenk H, Senécal J S, et al. Neural Probabilistic Language Models[J]. Journal of Machine Learning Research,2003.
[6] Mikolov T, Karafiát M, Burget L, et al. Recurrent neural network based language model[C]// INTERSPEECH 2010,Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, September. DBLP,2010.
[7] Botha J A, Blunsom P. Compositional Morphology for Word Representations and Language Modelling[J]. Computer Science,2014.
[8]Luong T, Socher R, Manning C D. Better Word Representations with Recursive Neural Networks for Morphology[C]// Conference,2013.
[9] Santos C N D, Guimar?es V. Boosting Named Entity Recognition with Neural Character Embeddings[J]. Computer Science,2015.
[10] Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult.[J]. IEEE Transactions on Neural Networks,1994.
[11] Srivastava R K, Greff K, Schmidhuber J. Training very deep networks[J]. Computer Science,2015.
[12]Marcus M P, Marcinkiewicz M A, Santorini B. Building a large annotated corpus of English: the penntreebank[M]. MIT Press,1993.
[13] Hinton G E, Srivastava N, Krizhevsky A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. Computer Science,2012.
[14]Zaremba W, Sutskever I, Vinyals O. Recurrent Neural Network Regularization[J]. EprintArxiv,2014.
[15]駱小所.語言的接緣性及其分支學科[J].云南師范大學學報(哲學社會科學版),1998.
[16]雷鐵安, 吳作偉, 楊周妮.Elman遞歸神經網絡在結構分析中的應用[J].電力機車與城軌車輛,2004.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
