基于Storm的車輛實時展示系統
2018-01-20 06:42:04張博
電腦知識與技術 2018年31期
張博


摘要:隨著汽車保有量的不斷增長,城市交通網絡也變得日益臃腫。如何實時準確地掌握交通現狀,減少交通擁堵,提高出行效率,是智慧交通的核心所在。該文針對傳統車輛分析平臺實時性較差、呈現方式不直觀等缺點,設計了一種基于大數據實時流式處理技術的三維展示系統。系統分為數據采集、數據分發、實時處理以及三維展示幾個部分。為保證系統并發量,采用高吞吐量的Kafka作為數據分發模塊,同時引入Storm對Kafka中數據進行消費、處理,通過WebSocket推送至Web頁面,頁面采用WebGL技術將車輛數據實時展示。與傳統系統相比,該系統具有高吞吐、低延時、準確直觀等特點,可幫助解決一系列交通問題。
關鍵詞:實時處理;三維;Storm;WebGL
中圖分類號:TP311? ? ? 文獻標識碼:A? ? ? 文章編號:1009-3044(2018)31-0101-03
1 背景
社會的飛速發展促進了城市車輛的需求增加,隨之帶來了車輛數據的爆發式增長。我們雖可借助Hadoop相關技術完成車輛數據的大規模處理,但是分批次處理作業的模式使得其很難實現秒級的延時。針對批量處理數據存在的問題,實時處理方式應運而生。
Twitter的Storm是一個開源的實時流式計算框架,比其他流計算產品更具優勢。該文基于Storm設計并實現了一種車輛實時展示系統,可實時處理并展示大量車輛數據。
2 相關技術
2.1 Storm流式處理框架
Storm是一套分布式、可靠、可容錯的用于處理流式數據的框架,其流式處理作業被分發至不同類型的組件,每個組件負責一項簡單的、特定的處理任務。相對于Hadoop,Storm能夠實現可靠的無邊界流式數據的實時處理,彌補了Hadoop批處理所不能滿足的實時要求。同時,Storm還具有以下幾個特點:
1)編程簡單:開發人員只需要關注應用邏輯,類似于Hadoop提供的Map和Reduce原語,Storm也對數據的實時計算提供了簡單Spout和Bolt原語。
2)高性能,低延遲:相比較批處理框架,可毫秒級響應數據。
3)分布式:可以輕松應對單個節點無法處理的海量數據。
4)可擴展:Storm的處理作業是分布在多個節點之間,隨著數據量和計算量的增長,可水平擴展系統。
5)容錯:如果某個節點出現故障,主節點會將任務重新分配至其他可用節點。
6)消息不丟失:Storm會保證每條消息均被處理,如果失敗,會嘗試重新處理此消息。
2.2 WebGL
WebGL是一種3D繪圖協議,這種繪圖技術標準允許把JavaScript和OpenGL ES 2.0結合在一起,從而為HTML5 Canvas提供硬件3D加速渲染,這樣Web開發人員就可以借助系統顯卡來在瀏覽器里更流暢地展示3D場景和模型,還能創建復雜的導航和數據視覺化。WebGL技術標準免去了開發網頁專用渲染插件的麻煩,可被用于創建具有復雜3D結構的網站頁面,甚至可以用來設計3D網頁游戲等等。
3 系統設計
根據系統需求,對系統進行分層設計,主要包括數據采集、數據分發、實時處理以及三維展示,系統架構如圖1所示。
1)數據采集:前端設備所采集到的車輛原始數據。
2)數據轉發:Kafka順序存儲了采集設備發送來的消息,并按不同Topic分類,等待著Storm進行拉取消費。
3)實時處理:Storm消費Kafka中數據,并進行數據標準化、數據推送、數據存儲等幾個步驟。
4)三維展示:Web頁面接收到WebSocket推送的數據后,實時繪制車輛。
4 系統實現
4.1 數據采集
數據采集層主要功能為匯聚前端采集設備的原始數據,并通過TCP長連接將數據推送至Kafka集群中。在發送消息之前,會對消息進行分類,即指定Topic。在發送消息的過程中,加入了監聽、異常處理等機制,避免數據重發、漏發,保證數據準確性。
4.2 數據分發
數據分發層向下接收采集設備推送的海量數據,向上又要及時為高性能、低延時的Storm集群提供數據,因此對消息框架的吞吐能力有很高要求。最終該系統采用Kafka作為數據分發層的實現。Kafka是一個高吞吐量的分布式發布訂閱消息系統。類比Kafka官網圖例,數據分發層結構如圖2所示。
一個Kafka集群會包含producer,broker,consumer等角色。broker為消息中間處理節點,一個Kafka節點就是一個broker,多個broker組成了Kafka集群。producer為生產者,負責發布消息到broker,對于該系統,采集設備即為producer。consumer為消費者,向broker讀取、消費消息,該系統中的consumer為Storm集群。
在數據分發層與實時處理層之間,還有一層分布式協調服務Zookeeper。通過Zookeeper的集群協調,可以充分保證大型集群的良好運行。
4.3 實時處理
實時處理層會不停去拉取、消費Kafka中的數據,并對多種Topic類別的數據進行標準化、推送、入庫等處理。為應對海量數據的高并發,該系統并沒有使用傳統的JAVA多線程等方式,而是采用了Storm實時流處理系統。類似Hadoop集群,Storm也有一些基本組件。Storm集群分為控制節點(Master)和工作節點(Worker),在這兩種節點上分別運行著后臺程序Nimbus和Supervisor。Nimbus負責分配任務(也就是Topology)給各個工作節點,Supervisor則負責管理每個具體的工作節點。實際在工作節點上運行的是Spout或Bolt。系統中Storm的處理流程如圖3所示。
Spout從外部源讀取數據,并用Storm中的數據結構Tuple將數據發給Bolt,Bolt為邏輯處理單元,進行一系列處理后,再調用emit()方法將數據以Tuple格式發射出去。
在該系統中,KafkaSpout為數據源,它從Kafka集群中讀取消息,并發送給carNormalizerBolt;因為數據來源于Kafka中的不同Topic,格式有所不同,所以在carNormalizerBolt里做數據標準化的處理。我們定義一個標準的Car類JavaBean,將消息的各個字段賦值給Car類,并進行字段補全或是丟棄等異常處理,之后將Car類發射給carSourceBolt;在carSourceBlot里,主要調用http接口將Car類發送至頁面對應的Web后臺,同時將Car類發射給carSaveBolt;carSaveBolt通過獲得數據庫連接池中的實例,將Car類持久化存儲至MySQL數據庫,方便Web頁面查詢展示。
構建處理流程的拓撲代碼如下:
//配置Kafka集群信息
BrokerHosts brokerHost = new ZkHosts(zkHost);
SpoutConfig carSpoutConfig = new SpoutConfig(brokerHost, carTopic, zkRoot, "data-car");
carSpoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
//使用Kafka數據源作為Spout
KafkaSpout carSpout = new KafkaSpout(carSpoutConfig);
//新建一個Topology
TopologyBuilder builder = new TopologyBuilder();
//建立拓撲結構
builder.setSpout("kafkaCarSpout", carSpout, 3);
builder.setBolt("carNormalizerBolt", new CarNormalizerBolt(), 2)
.shuffleGrouping("kafkaCarSpout");
builder.setBolt("carSourceBolt", new CarSourceBolt(),2)
.shuffleGrouping("carNormalizerBolt");
builder.setBolt("carSaveBolt", new CarSaveBolt(), 2)
.shuffleGrouping("carSourceBolt");
4.4 三維展示
為能更準確、直觀的展示實際路況的車輛信息、流量信息等,展示層通過WebGL模擬實際的三維場景,并實時繪制車輛。系統展示層采用B/S架構,前后端分離設計。展示層邏輯如圖4所示。
Storm集群將標準化的數據以Http接口方式傳遞給后臺,后臺程序接收到數據后,通過WebSocket把數據推送至前端頁面。js腳本取得數據后,調用車輛繪制接口完成實時展示功能。繪制接口由WebGL相關js封裝成類,向外提供。同時,頁面還具有查詢功能,即通過調用后臺接口,將Storm集群存儲至MySQL的數據以表格方式展現。
5 系統測試
通過系統測試,我們可以與系統的需求進行比較,從而發現系統的缺陷與不足。
5.1 功能測試
首先進行功能測試。功能測試主要有兩點:
1)測試系統是否能從采集設備獲取到車輛數據,并通過Storm標準化并實時展示在三維場景中。登錄系統,等待三維場景加載完成后,采集到的車輛信息(如車型、車輛顏色等)實時展示在場景中,功能截圖如圖5。
2)測試系統是否能從MySQL數據庫中查詢到采集的車輛數據。在頁面中選擇時間段、車輛類型、采集設備等相關條件,點擊查詢,即可查到采集的車輛數據。數據查詢結果界面如圖6。
從功能測試結果來看,該系統已完成了匯聚采集設備數據、標準化數據并實時三維展示、數據存入數據庫并可查詢等一系列功能。
5.2 性能測試
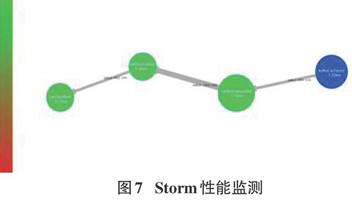
通過查看Storm集群提供的性能監測頁面我們可以發現,kafkaCarSpout、carNormalizerBolt、carSourceBolt及carSaveBolt處理每條Tuple的速度分別為3.29ms、1.16ms、0.38ms和0.73ms,如圖7所示。可見Storm能以10ms內的響應速度處理采集設備的每條采集數據。
6 總結與展望
該文主要介紹在海量數據的應用背景下,如何利用大數據技術解決傳統車輛分析平臺存在的問題。最終,該文采用Kafka、Storm等大數據框架傳輸、處理數據,通過WebGL對道路車輛的實時繪制,為大數據車輛分析,緩解擁堵等決策提供有力支持。
參考文獻:
[1] 楊杰, 朱邦培, 吳宏偉. 基于Storm的高速公路實時交通指數評估方法的研究與實現[J]. 計算機應用研究, 2017, 34(9): 2707-2713.
[2] 亓開元, 趙卓峰, 房俊, 等. 針對高速數據流的大規模數據實時處理方法[J]. 計算機學報, 2012, 35(3):? 476-490.
[3] 王雅瓊, 楊云鵬, 樊重俊. 智慧交通中的大數據應用研究[J]. 物流工程與管理, 2015, 37(5): 107-108.
[4] 張春風, 申飛, 張俊, 等. 基于 Storm 的車聯網數據實時分析系統. 計算機系統應用, 2018, 27(3): 44-50.
[5] Maarala AI, Rautiainen M, Salmi M. et al. Low latency analytics for streaming traffic data with Apache Spark[C]. IEEE International Conference on Big Data. Santa Clara, CA, USA.2015: 2855-2858.
