關聯規則應用下的高校圖書館圖書推薦服務*
2018-01-30 08:35:29陳淑英徐劍英劉玉魏
圖書館論壇 2018年2期
陳淑英,徐劍英,劉玉魏,山 潔
0 引言
圖書館信息服務模式正從面向館藏資源的普惠信息服務向面向讀者的個性化信息服務轉變[1]。圖書推薦服務是現代圖書館以讀者為核心的個性化服務的重要內容。面對用戶,如何將豐富的圖書資源推薦給用戶是圖書館一直思考的問題。大學生是高校圖書館的主要服務對象,圖書館通過動態跟蹤用戶在4年學習中的借閱數據,可以掌握不同專業用戶處在不同年級時期的興趣變化,預測用戶偏好,進而進行圖書推薦[2]。本文以某高校2011級大學4年圖書借閱數據為依據,從看似雜亂無序的信息中提取有價值的信息,以關聯規則進行數據挖掘,試圖通過不同專業用戶在不同年級時的圖書關聯規則分布情況,探索以專業為單位用戶群體的有效的和有針對性的圖書推薦服務策略,為用戶提供個性化服務。
1 研究背景
數據挖掘是提取隱藏信息的過程[3],利用數據挖掘技術分析讀者借閱數據,探尋讀者需求規律,以實現圖書推薦服務。關聯規則由Agrawal等在1993年首次提出[4],是數據挖掘中重要的數據分析方法,通過對數據處理挖掘出數據集中項之間的聯系,建立數據之間的相互依賴關系。關聯挖掘技術是現代圖書館發展的關鍵技術,運用關聯挖掘技術可以對讀者的借閱數據進行分析,適時調整館藏方向,使圖書館信息資源體系更加合理化;還可以發現讀者的借閱模式和借閱偏好,為讀者提供個性化的信息服務[5]。目前應用關聯規則在圖書借閱數據研究主要集中在兩方面:一是對讀者借閱圖書種類數據關聯分析算法的建立過程,以介紹方法為主[6-8];二是對關聯規則方法的改進與推薦模型的研究[9-11]。其中,大多研究都是對關聯規則技術問題的算法研究、模型的建立和通過實驗驗證推薦的準確性和可用性,而對于考慮屬性之間的類別層次關系、時態關系、多維挖掘等其他屬性的研究較少。本文以讀者屬性數據和借閱記錄為基礎,以時間維度為主線進行數據關聯挖掘,在數據挖掘過程中,不僅關注關聯規則的算法和結果,更加注重的是對結果進行分析。通過分析,發現數據中存在的各種有用信息,如用戶閱讀變化趨勢及存在問題,提出相應的對策,改變現有的工作方式,開展圖書推薦服務。
2 研究過程
2.1 研究流程
根據用戶4年的借閱數據,應用關聯規則沿著時間主軸跟蹤挖掘分析用戶學科專業、圖書類型之間的關聯關系,得出不同專業用戶在不同年級借閱圖書之間的關聯性,通過關聯規則分析掌握以專業為單位的群體用戶的閱讀傾向、偏好和需求,并以此作為開展圖書推薦服務的依據和決策支持。通過行之有效的圖書推薦策略展開圖書推薦服務工作,讓圖書資源發揮最大效用,讓圖書館的服務貫穿于用戶四年的學習過程中,使用戶在四年的學習中,不斷提高自身的學習能力、實踐創業水平以及綜合素質。具體流程見圖1。
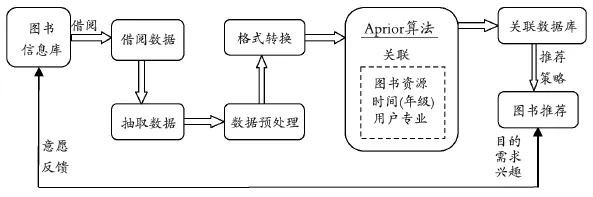
圖1 研究流程
2.2 數據獲取
本文以某高校圖書館為例,采用分層抽樣方法,按照分層抽樣調查的比例要求,每個專業的抽樣比例在30%左右。從2011級本科生中選取1200名用戶,在圖書館圖書借閱管理系統跟蹤被抽樣本用戶從大一到大四在圖書借閱系統的日志數據,共獲取借閱數據27905條。抽樣用戶覆蓋文學、理學、工學、醫學、法學、管理學、經濟學等學科的71個專業,時間從2011年9月入學到2015年6月畢業,通過分析2011級本科生不同專業的借閱數據,探究以專業為單位的圖書借閱規律,并結合2011級教學計劃中課程設置,開展圖書推薦服務。
2.3 數據處理
根據研究流程,對抽樣的1200名用戶數據主要選取讀者證號、專業、借閱年級(操作日期)、圖書類型(中圖分類號)及題名等,通過數據清理集成,預處理后得到相關整合數據,詳見表1。
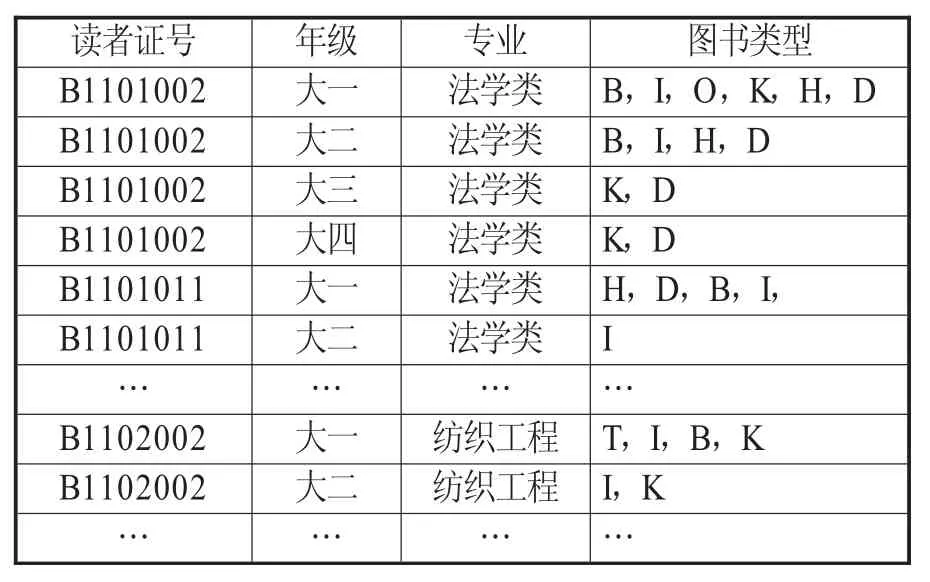
表1 每個用戶4年借閱圖書的預處理后數據
2.4 Apriori算法
Apriori算法最初僅用于單一維度下布爾型數據的關聯規則挖掘。對圖書借閱行為中的3個維度——用戶、圖書及時間,除關注不同圖書類型關聯外,還對年級和圖書類型的關聯感興趣,需要進行多維關聯規則分析。如果將多維屬性的謂詞集看作是維度內同屬性的項集,可以藉由經典的單維關聯規則算法處理多維屬性間的關聯[12]。在進行關聯分析時,對讀者所借閱的圖書類型、圖書類型和專業、圖書類型和年級之間等方面挖掘這些數據之間的關聯規則。Apriori算法是挖掘強關聯規則的方法,主要功能是找出頻繁項集。具體步驟為:(1)對于預處理數據,用Apriori關聯算法,找出全部的頻繁項集;(2)對頻繁項集進行連接步和剪枝步;(3)得到最大頻繁項集,去掉沒有超過最小支持度的,剩下的又滿足最小置信度,就是強關聯規則[13]。
強關聯規則可以挖掘隱藏在歷史數據背后的有用的規則和潛在的信息。本文重點跟蹤挖掘分析從入學到畢業的一個學習周期中,不同專業的用戶群體在不同年級借閱圖書的規律,發現在不同年級的讀書興趣、偏好和需求,如經常看的書籍,又如用戶在借閱本學期開設課程相關圖書時,還會去借閱的圖書類別等。
3 結果分析與討論
3.1 研究結果
2011級本科生中1200名用戶連續4年的借書記錄共計27905條,其中借閱了22類圖書,密度為0.1725318。最常借閱的圖書類型為I、K、H、T、B。155人的借閱數據為只借閱一類圖書,202人的借閱數據為借閱兩類圖書。使用Apriori算法,設置最小支持度0.01和最小值置信度0.1,按年級(時間)維排序,構建以專業為單位的圖書與年級(時間)的關聯規則,并抽取有代表性的幾個專業。具體結果如表2所示。
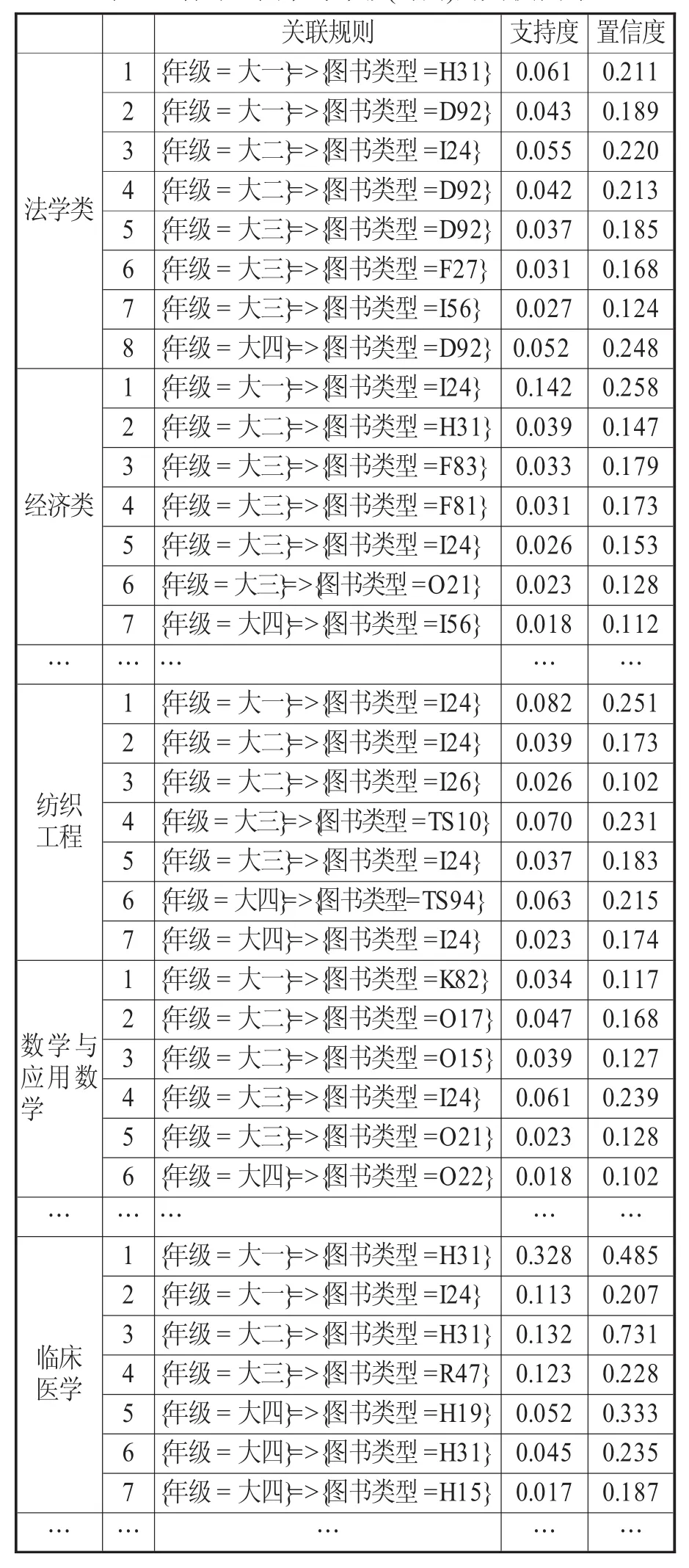
表2 各專業圖書與年級(時間)的關聯規則
3.2 結果分布
3.2.1 整體分布
在4年學習中,各個專業在不同年級時借閱圖書關聯程度較高的圖書類型各不相同。
例如,紡織工程專業的用戶:
{年級=大一}=>{圖書類型=I24}
{年級=大二}=>{圖書類型=I24、I26}
{年級=大三}=>{圖書類型=TS10、I24}
{年級=大四}=>{圖書類型=TS94、I24}
而數學與應用數學專業的用戶:
{年級=大一}=>{圖書類型=K82}
{年級=大二}=>{圖書類型=O17、O15}
{年級=大三}=>{圖書類型=I24、O21}
{年級=大四}=>{圖書類型=O22}
據此,可以得出結論:專業不同,關聯程度高的圖書種類也有所不同,這是開展針對不同專業用戶進行圖書推薦服務的主要依據。
3.2.2 階段分布
同一專業的用戶在4年學習生活中,關聯程度較高的借閱圖書類型分布顯示,用戶在不同年級時期感興趣的圖書有區別,但也有一些其他類型的圖書貫穿在整個學習過程中。比如紡織工程專業的用戶,在大一、大二、大三及大四關聯程度較高圖書的有I24類,因此圖書推薦工作應有長期目標和短期目標。
3.2.3 專業分布
各專業除在I類和H類圖書顯示關聯程度較高,同時顯示出和本專業圖書有較高的關聯性,如法學類專業的用戶在大一、大二、大三及大四關聯程度較高的都有D92,說明專業類圖書的學習對用戶很重要。
3.3 結果討論
用戶在4年學習過程中,會根據興趣、偏好和學習要求等借閱不同類型的圖書,但根據表2關聯數據顯示,關聯程度高的圖書種數與館藏文獻資源種類及總量相比卻是微不足道的。究其原因,主要有以下幾方面。
3.3.1 用戶圖書借閱缺乏系統指導
用戶4年讀書生活中,借閱數據總的趨向較符合其學習過程,但借閱圖書的種類還是比較單一,在某一時間段借閱圖書比較盲目,與其學習過程不太相符。
比如經濟類專業的用戶:
{年級=大一}=>{圖書類型=I24}
{年級=大二}=>{圖書類型=H31}
{年級=大四}=>{圖書類型=I56}
數據顯示,用戶在一年級、二年級以及四年級學習過程中,關聯程度高的借閱圖書種類分別僅有I24、H31和I56。因此,可以通過分析數據,給出有針對性、合理性和系統性的指導,主動提供圖書推薦服務,從而提高用戶的借閱質量。
3.3.2 用戶興趣偏好缺乏積極引導
從表2中可知,關聯程度高、概率較大的圖書種類中,最常借閱的圖書類型為I、K、H等。I類圖書占的比例最大,用戶在大一期間盡管專業不同,但借閱的大多以I24為主,并且在大二、大三及大四期間都有I類圖書借閱的傾向。因此,應根據用戶的興趣愛好,對B、H、I、K等種類圖書借閱給予積極引導。
3.3.3 用戶專業學習積極性不夠
表2數據顯示,每個專業關聯程度高的專業圖書的比例比較低,用戶在大二、大三及大四時多轉向專業書籍,但是關聯程度高的圖書卻不多,專業圖書的借閱還是缺乏理想的閱讀量。如臨床醫學專業,從大一到大四,關聯度高的基本是H類,除了大三有R47類型圖書,其他都是非本專業書籍,四年的專業圖書閱讀總量令人擔憂。這就要求圖書館要仔細分析相關數據,根據用戶專業的具體要求,了解用戶的需求和興趣點,做出準確的判斷,進行專業圖書的推薦,以滿足專業用戶的大學專業知識的學習和掌握。
綜上,除了要建設更加合理化的信息資源體系,更重要的是掌握和了解讀者的借閱模式和借閱偏好,通過圖書關聯規則的數據結果,為讀者提供相關信息資源或引導讀者查找所需資源,為讀者提供優質的個性化的信息服務。因此,高校圖書館要認真分析用戶的借閱數據,了解用戶的需求,主動采用多種圖書推薦服務模式,調動用戶的閱讀興趣。圖書館要從被動等待用戶借閱,轉變為積極主動的深入到用戶中去,實施圖書推薦服務,拓展圖書館的工作方式和服務內容。
4 圖書推薦服務策略
本次研究是通過對高校圖書館用戶的直接調查,從用戶借閱數據→關聯規則→數據分析→信息需求→推薦服務的過程中,高校圖書館充分發揮教育和信息服務職能,為用戶推薦所需的圖書,同樣也為館藏圖書尋找用戶。圖書館根據關聯規則分析結果,從以下幾個方面開展工作,實現為讀者提供優質的圖書推薦服務。
4.1 制定每個專業四年的圖書閱讀規劃
從表2關聯規則可獲知,用戶四年的學習中,借閱圖書較缺乏系統性、科學性及規律性。用戶在大二、大三和大四階段,課程設置中基本上都是專業必修課和專業選修課,在這個學習階段用戶要完成正常的專業課程學習、考研準備、課程設計、畢業論文及設計等等,基本上以借閱專業類圖書為主,在這個時期,如果圖書館購置的專業類圖書本專業的用戶都不積極借閱,那么還會有其他專業的用戶借閱嗎?因此,圖書館要為購置的每本圖書定位,找到其目標人群,這就需要分析研究用戶閱讀特征,包括用戶來源、專業報考第一錄取率和閱讀傾向等,整合用戶閱讀興趣及偏好,做到在用戶四年學習的每個階段都能給予較專業到位的幫助和指導。無論用戶是出國深造、考研,還是就業,圖書館可以充分掌握其發展目標,與相應的院系聯合,結合每個專業的教學計劃,為圖書尋找用戶,建立以用戶專業為單位的四年的圖書閱讀規劃。
4.2 實施圖書需求推薦
大一時期的用戶,從高中進入大學,躊躇滿志,為了擴展視野和提高文化素質往往讀書的熱情很高,但進入高年級,由于需求發生變化,用戶有了個人的發展規劃,對閱讀的內容會有新的需求。因此,圖書館要對用戶4年的圖書借閱情況進行系統梳理和分析,結合用戶不同年級的課程需求以及興趣需求,在用戶學習、生活、創新實踐及提高個人素養等方面,及時給予指導。當讀者借閱某類文獻時,圖書館館員可以將與其強關聯的某類文獻有目的、有準備、有策略地推薦給讀者,并可據此建立相應的館藏推薦系統,力求所采購的每一本書都能滿足用戶的需求。對不同專業用戶和在不同年級時期進行定位,尋找所需的圖書,實施圖書需求推薦。
4.3 實施圖書創意推薦
用戶往往會根據自身的需求和興趣借閱相關的圖書。比如,通過對數學與應用數學專業的用戶借閱數據進行分析,發現大一學生較多借閱K82類的圖書,多屬于用戶興趣;大二學生較多借閱O17、O15類圖書,該專業大二正好開設與此類圖書相關課程;大三時多借閱I24、O21類和大四時多借閱O22類圖書也是此類情況。因此,圖書館要充分挖掘不同專業用戶的行為、需求和興趣,結合廣泛的閱讀推廣活動和特定的主題元素,如節日、紀念日、專業學習階段以及專業實習和實訓,舉辦讀書節,開展專題、專業閱讀和書會等,并以此為契機進行創意推薦,打造自己的品牌[14],吸引用戶。
4.4 實施專業圖書目標推薦
通過表2進一步分析還發現,有些用戶在4年的學習生活中,借閱數據不盡人意,專業書籍的閱讀比較少,這就給圖書館提出了很高要求。首先要了解學校的專業學科設置和專業教學計劃,細分目標群體,與院系合作建立學科館員制度。其次可定期到院系舉辦書會,開展類似“主題資源指引”“主題館藏選介”“學科主題資源”等推薦活動[15],介紹相關專業圖書信息資源,與用戶積極溝通,搭建互動平臺,實施專業圖書目標推薦。
4.5 完善借閱數據分析管理和館員業績激勵制度
每年定期將每個專業的用戶借閱圖書關聯分析結果和上屆同期數據進行比對,及時了解用戶的目的、需求和興趣,根據用戶意愿反饋及時調整每個專業的圖書閱讀規劃和相應的圖書推薦內容。在深入做好借閱數據分析的同時要做好數據管理,把圖書館內部信息與數據管理起來,為了使數據處理更科學、系統和統一,要加強工作流程的管理,力求實現相關業務流程計算機管控和自動化管理,降低人為因素,固化管理流程。圖書館要逐步形成自己的管理系統,采用智能管理的數據挖掘系統,實現圖書借閱數據分析的智能化,既為用戶提供有效的推薦服務,也為圖書館提供有效和準確的分析決策依據。為此,館員業績激勵制度的健全就顯得尤為重要,這樣才能面向全校用戶,合理分配館員,發揮圖書館員的專業特長,向用戶提供服務,為用戶推薦所需圖書。同時為提高館員工作的積極性,應及時統計圖書借閱情況,查看館員的業績,對館員工作的質量和成效做客觀、全面的評估。
5 結語
高校圖書館利用關聯規則挖掘技術分析借閱信息,可以準確判斷用戶的借閱行為,了解和掌握不同專業用戶群體在不同年級階段的興趣特征、現實需求以及潛在需求;同時可根據該學校的專業結構、學科建設和用戶特點進行以專業為單位的圖書推薦服務,并讓推薦模式更適合現代讀者的個性化的習慣,吸引讀者訪問圖書館[16]。圖書館為用戶做好圖書推薦服務,是圖書館由被動轉向主動服務模式的體現,但如何將研究方法和圖書推薦在圖書館推廣應用成為一種常態業務工作,是本研究團隊今后進一步研究的內容。
[1]盛宇.基于微博的學科熱點發現、追蹤與分析——以數據挖掘領域為例[J].圖書情報工作,2012(8):32-37.
[2]馬文峰.數字圖書館個性化信息服務的探索[J].圖書館雜志,2003(5):30-32.
[3]周肆清,歐陽烽.數據挖掘在高校數字圖書館應用的可行性分析[J].高校圖書館工作,2007,27(5):36-38.
[4]Han J M,Kamber M.Data Mining Concepts and Techniques[M].北京:機械工業出版社,2010.
[5]任賢姬.關聯規則挖掘技術在圖書借閱服務中的應用研究[J].情報科學,2010(5):729-731.
[6]彭儀普,熊擁軍.關聯挖掘在文獻借閱歷史數據分析中的應用[J].情報技術,2005(8):40-44.
[7]丁雪.基于數據挖掘的圖書智能推薦系統研究[J].情報理論與實踐,2010(5):107-110.
[8]茹文,忻展紅.圖書館借閱數據分類信息的關聯性研究[J].北京郵電大學學報(社會科學版),2016(1):14-19.
[9]李默,梁永全.基于標簽和關聯規則挖掘的圖書組合推薦系統模型研究[J].計算機應用研究,2014(8):2390-2393.
[10]李勝,王葉茂.一種基于本體和位置感知的圖書館書籍推薦模型[J].現代圖書情報技術,2015(3):58-65.
[11]馬宏惠,張平.圖書館流通信息多層關聯規則挖掘法的優化與應用[J].圖書情報工作,2008(7):94-97.
[12]鐘勇,秦小麟,包磊.一種基于多維集的關聯模式挖掘算法[J].計算機研究與發展,2006(12):2117-2123.
[13]Yin Z,Gupta M,Weninger T.A unified framework for link recommendation with user attributes and graph structure[C].International Conference on World Wide Web,2010:1211-1212.
[14]姚顯霞.基于讀者問卷調查的高校閱讀推廣活動評價與分析[J].圖書館論壇,2013(3):144-147.
[15]覃麗金,吉家凡,唐朝勝,等.主題式學科化服務模式研究——結合海南大學圖書館的案例分析[J].圖書館論壇,2014(4):23-29.
[16]馬仲兵.基于關聯規則的高校圖書館個性化推薦模型[J].新世紀圖書館,2013(7):42-44.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
小太陽畫報(2018年1期)2018-05-14 17:19:25
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
