觸發詞擴展、神經網絡及依存分析相結合的事件研究
2018-02-01 00:28:08王紅斌郜洪奎
軟件導刊 2018年1期
王紅斌+郜洪奎

摘要:
事件抽取包括兩大任務:識別事件和事件要素抽取。對于事件抽取的傳統方法是模式匹配和機器學習。模式匹配包含規則有限,機器學習需要大量語料和眾多特征。針對傳統方法的不足,提出了結合觸發詞擴展、神經網絡及依存分析相結合的方法。該方法利用觸發詞擴展增加觸發詞數量,利用神經網絡選擇特征進行事件分類,利用依存分析挖掘詞之間關系。實驗證明該方法可行,在事件識別和事件要素抽取方面得到了較好結果。
關鍵詞:
機器學習;事件識別;事件要素抽取;依存分析;神經網絡
DOIDOI:10.11907/rjdk.172075
中圖分類號:TP301
文獻標識碼:A文章編號文章編號:16727800(2018)001001903
Abstract:Event extraction consists of two tasks: identifying the extraction of events and event elements. Traditionally, pattern matching and machine learning methods are used for event extraction. Pattern matching involves limited rules. Machine learning requires a large number of corpus and many features. In view of the shortcomings of traditional methods, this paper proposes a combination of triggering word extension, neural network and dependency analysis. The method can increase the number of trigger words by using the trigger word extension, use the neural network to select the feature to classify the event, and use the dependency analysis to dig the relationship between the words. Experiments show that this method is feasible and has achieved good results in event recognition and event element extraction.
Key Words:machine learning; event recognition; event element extraction; dependency analysis; neural network
0引言
中國交通事故發生頻繁,突發性災難事件研究受到重視。事故處理部門關心事故發生時間、地點、人員傷亡情況,以及哪個路段、哪個時間容易發生事故,從而采取措施最大限度地減少傷亡[1]。對事件的研究不僅具有理論價值,還具有實際應用前景。
事件抽取研究已取得較多成果,研究大致分為兩類:基于規則的方法[24]和機器學習方法。基于規則的方法是事先制定一個字典,然后用待選詞與字典進行匹配。Ahn D[5]采用二元分類器和多元分類器方法進行事件抽取研究,并在ACE英文語料庫進行了實驗,取得較好結果;吳平博等[6]采用預先定義的模版制定規則,從處理的文本中抽取事件信息來填充句型模板中的槽。結合上述事件抽取發現,基于規則方法在一定范圍內效果不錯,但它依賴具體環境,可移植性差,對于一些沒有統計到字典的詞識別不出來,而且字典的制定費時費力,需要領域專家指導,機器學習方法則可以解決這些問題。機器學習相關研究有:文檔相關性的研究方法 [7],跨越不同事件的推理演繹方法[8]。楊爾弘[9]根據中文特點,采用語句聚類方法獲得事件的信息結構(事件模板),并以此為標準抽取事件;趙妍妍等[10] 結合 Ahn等[11] 的工作,對機器學習需要的特征進行了改進;付劍鋒等[12] 采用依存分析,深入挖掘詞與詞間的句法關聯性,李培峰等[13]采用語義進行推理,對事件缺失信息進行還原和補充。但是機器學習方法需要大量的語料和眾多特征作為支持,現今語料資源的缺乏和特征的選取影響了機器學習的提高,而且這兩種抽取方法均沒有考慮詞語間詞性特征及詞語之間的依賴性和事件之間的關聯。
針對上述情況,本文提出了一種新的事件抽取方法,充分考慮了上下文、核心詞和其它詞語的特征、觸發詞擴展和詞語間的依存性。實驗表明本文方法在事件識別和事件要素提取方面均有明顯提高。
1事件識別和事件要素
事件反映自然界中的運動以及產生和變化的行為,是人類進行探索和發掘知識的基本單位。在自然語言處理和信息檢索領域,檢索的主題被稱作事件。事件是話題的子集,多個事件共同組成一個話題。 事件表示為在“特定時間特定地點發生”。國際ACE評測大會認為,事件通常是一種狀態轉向另一種狀態,并把“事件”定義為含有參與者、時間、地點等特征的集合。事件的定義包括行為(一般由動詞、名詞或動名詞來描述)、事件的參與者、事件發生的地點和時間等要素。下面給出事件和事件要素的定義。
定義1事件(Event):特定時間特定地點發生、由參與者參與、表現出若干動作。
例如:2016年8月14日,在市中心,一輛公交車與多輛小轎車發生追尾,小轎車司機當場死亡,公交車司機受重傷。
定義2事件觸發詞[14](Event Denoter):文本中清晰表示發生事情的詞語,即事件的動作要素。文獻表明事件觸發詞一般為動詞、名詞、動名詞。endprint
例如:北京時間2016年8月16日,澳大利亞發生了5.7級地震。
定義3事件要素(Event Elements):文本中時間、地點、人物等要素,具體描述事件。
例如:7日夜晚,昆湖高速公路上一輛大巴車與一輛大貨車相撞,截至8日,這起事故已造成8人死亡,2人受傷。
2觸發詞擴展和依存關系
2.1語料
本實驗所用語料是ACE2005中文語料資源,其中ACE2005定義的事件共有8大類,每大類下面又分33個小類事件。對語料的2/3標記事件觸發詞及相應的事件類別。
2.2觸發詞擴展
本實驗所用系統是觸發詞識別抽取系統。根據標注的訓練語料構建一個字典,在此基礎上根據中文觸發詞擴展系統及方法進行觸發詞擴展[15],從而得到含有大量觸發詞的字典,使觸發詞不斷擴展。最后,根據得到的字典把帶有觸發詞的事件句與字典進行匹配,得到大量候選事件集合。
2.3事件句
在事件識別和事件抽取兩大任務中,事件識別起到決定性作用。例如:張三患上了高血壓,癱瘓在床。
例①小李在工作期間由于大意摔成癱瘓;②強大的暴雪致使公路癱瘓;③黑客攻擊網絡導致12306癱瘓。這3個例子,觸發詞都是癱瘓,但只有句子①才符合要求,才是真正事件。在事件識別中,對于包含觸發詞的事件統稱為候選事件。針對上述例子,本文所要解決的是從候選事件中選擇真正的事件句。漢語具有結構靈活多變、表達含義多樣性等特點,在事件識別和事件要素抽取中占到很高比例。因此,在中文事件識別和事件要素提取時不能孤立考慮句子,要結合上下文、依存分析,把觸發詞以及距離觸發詞相近的詞以及這些詞的詞性、位置信息、句子間的關聯性、依存關系等作為事件識別特征。
2.3.1候選事件識別的特征選擇
①詞性特征:候選事件中的觸發詞信息;②上下文特征:觸發詞左右兩邊3個詞的信息。
2.3.2神經網絡分類器
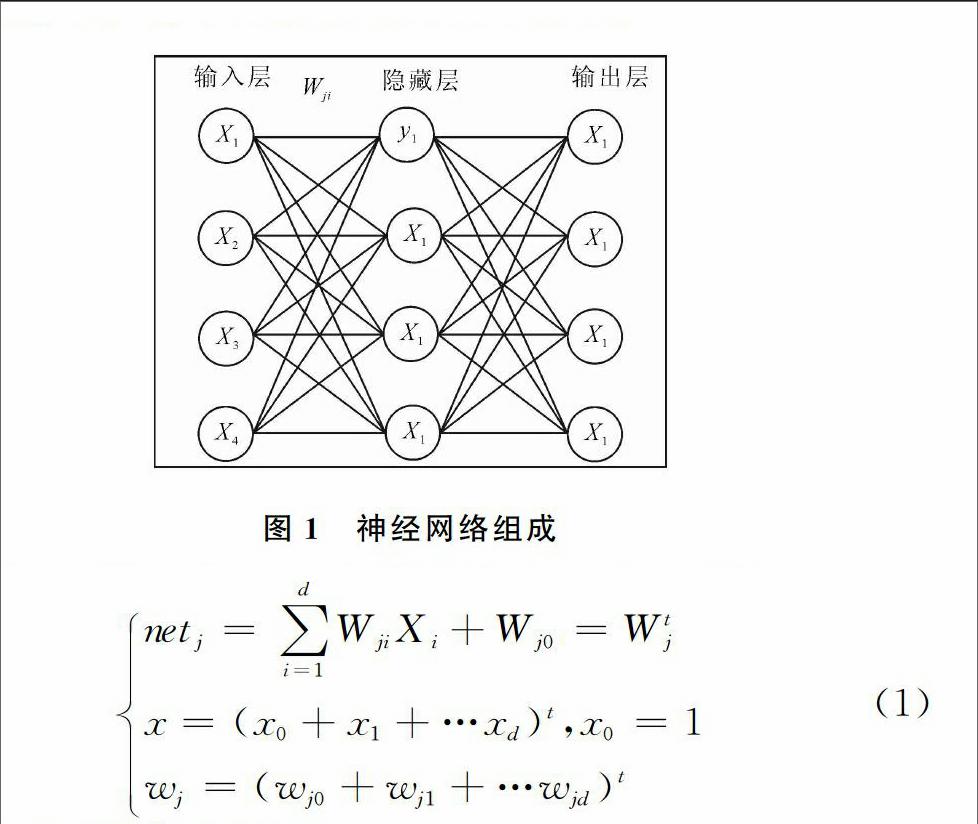
神經網絡(NeuralNetwork,縮寫NN),不僅是一種模仿生物神經網絡結構和功能的數學模型,而且是一種自我學習的神經網絡算法。神經網絡的目的是讓計算機具有和人的大腦一樣的能力。神經網絡由節點相互連接而成,由輸入層、隱藏層和輸出層組成。神經網絡按照老師教的方式學習,當提供新的特征時,神經網絡的各個神經元根據獲得的輸入產生連接權值,通過各層進行處理,最后產生輸出結果。神經網絡組成如圖1所示。
在用神經網絡進行事件句語義分類中,作為事件句的基本組成,詞向量具有重要作用。把事件句轉化為詞向量用于神經元的輸入層。神經網絡算法組成如下:
神經網絡輸入層:Xi、Xi表示輸入特征;
神經網絡的單元數量表示:d;
隱層的輸入表示:netj;隱層單元數量表示:nH
神經網絡輸出層:Yi;
i表示的激活函數為線性函數;
最后的輸出用yj表示,激活函數為非線性函數;
j的輸出:
輸入層的相關信息為:net;單元的數量為c:
k的輸出:
神經網絡算法描述如下:
(1)給定隱層單元及輸出層單元的激活函數,一個神經網絡就可以實現一個對輸入特征向量x的非線性映射。因此,神經網絡本質上是一個非線性函數。
(2)給定隱層單元及輸出層單元激活函數,該非線性函數所對應的映射關系完全由權系數決定。不同的權系數對應不同的非線性映射。
(3)神經網絡學習的目的,就是根據已知的訓練樣本,確定神經網絡的權系數,這一過程稱為訓練過程。在訓練過程結束后,對于新樣本x,根據神經網絡的輸出進行判決。
(4)對于分類問題,輸出結果為zk(x),k=1,…,c。
根據詞向量,采用word2vec工具轉換為相應詞向量,結合特征用于神經網絡分類器,最后選出真正的事件句并進行事件分類。
2.4依存關系
依存關系是進行句法分析的重要方法[17]。采用依存分析發現句子中心詞和其余詞語的關系,并且轉化為語義依存來描述。當前的主流方法是基于短語的句法分析。基于依存結構句法分析概念1984年由 Hudson首次提出,受到學者一致好評并廣泛推廣。依存關系主要包括核心詞、依賴詞。依存關系的基本原理是充分挖掘句子中詞與詞間的關系,轉化為描述自然語言的語法結構。詞語間有聯系和相互支配關系,反映出詞語間的不對等現象,這種相互間具有的方向性關系稱為“依存關系”。依存關系中,定義箭頭發出的是支配者,箭頭指向的就是從屬者。例如2016年9月4日,20國集團在中國杭州國際博覽中心召開峰會,依存分析表示如圖2所示。
“2016年9月4日,20國集團在中國杭州國際博覽中心召開峰會”的事件句中,Root是全句核心節點。HED代表核心詞,核心詞是“召開”;“召開”也是本事件句的觸發詞。依存關系表示中,COO表示并列關系,LAD表示左附加關系,SBV表示主謂關系,ATT表示定中關系。詞語間的依存關系是用帶箭頭的有向弧表示。箭頭的發起端代表的詞是依存詞,箭頭的指向端代表的詞是核心詞。在這個事件句中,中國、杭州、國家博覽中心都是表示地點的事件要素。經過分析可知,只有國際博覽中心是真正的地點要素。依存分析表示地點詞按照核心詞和依賴詞順序排列,真正的地點要素是后面的依賴詞。中國是杭州的核心詞、杭州是國際博覽中心的核心詞。根據依存關系,只要出現最終地點要素均是依賴詞。依存分析依賴于分詞之上,因此分詞的效率直接影響依存分析結果。本文采用的分詞工具是中科院的ICTCLAS,依存分析采用斯坦福大學的Stanford。
3實驗
3.1事件識別
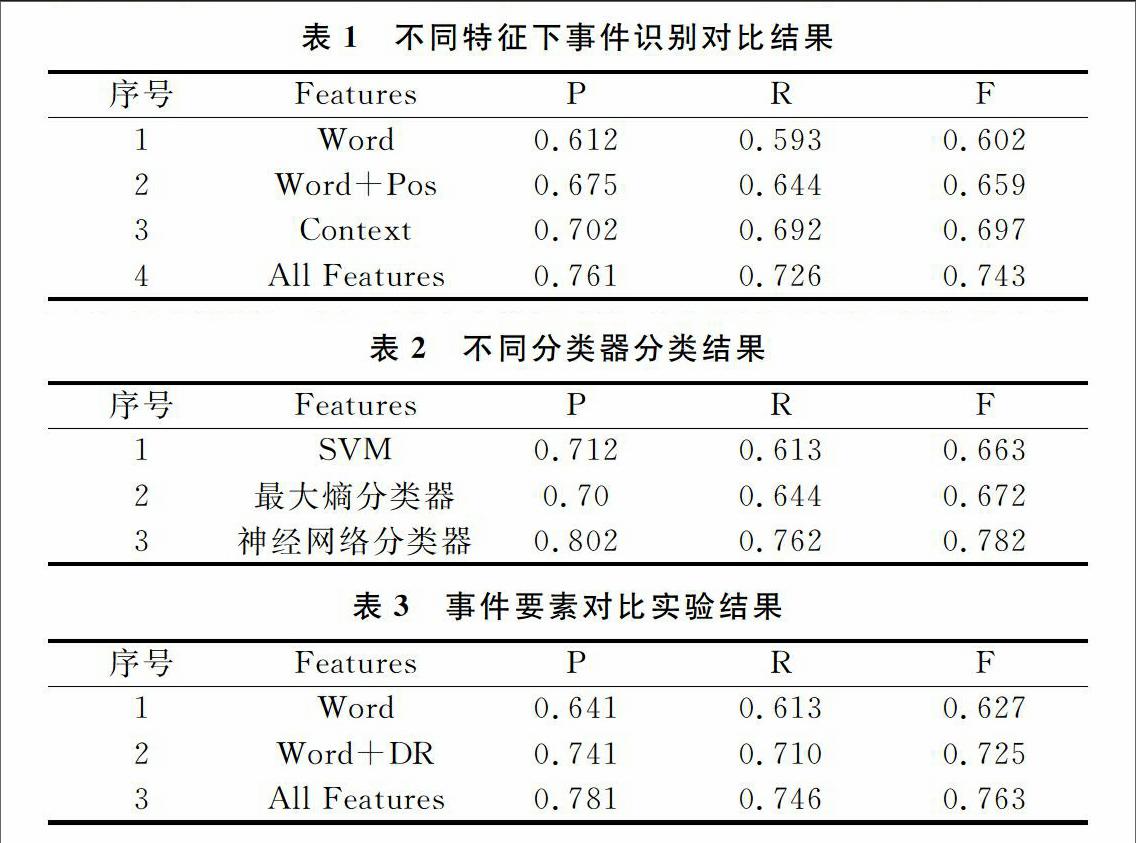
本實驗先進行事件識別,然后在此基礎上進行事件要素抽取。實驗用的訓練語料和測試語料是CEC語料,采用準確率(P)、召回率(R)、F值作為評價指標。事件識別對比實驗結果如表1所示:①以詞(Word)作為特征;②以詞和詞法(Word+POS)作為特征;③以上下文(Context)作為特征;④上述全部特征(All Features)作為特征。endprint
從表1可知,選擇觸發詞及詞法和上下文這些特征來識別事件效果,好于單獨用詞作為特征識別事件。
將上面選出的事件作為候選事件句,選擇分類器進行真正事件的選擇,表2為不同分類器對事件進行分類的結果。
從表2可以得出,采用神經網絡分類器進行事件分類效果好于最大熵和SVM分類器。
3.2事件要素抽取
采用準確率(P)、召回率(R)、F值作為評價指標。事件要素抽取對比實驗結果如表3所示:①以詞(Word)作為特征;②以詞和依存關系(Word+DR)作為特征;③上述全部特征(All Features)作為特征。
從上述3組實驗可知,采用依存關系可以提高事件要素抽取效率。
4結語
本文提出了一種結合觸發詞擴展、神經網絡及依存分析的事件識別和事件要素抽取方法。實驗結果表明,該方法在事件識別和事件要素抽取中可以提高事件識別準確率和召回率以及F值。同時,從分析結果發現以下問題:①事件觸發詞數量不足,導致事件識別效率不高;②語料資源不足;③事件要素識別的人稱代詞沒有具體指明所屬。因此,下一步將結合神經網絡對上述問題進行研究。
參考文獻:
[1]軒小星.事件及事件要素的提取研究[D].淮南:安徽理工大學,2015.
[2]RILOFF E. Automatically generating extraction patterns from untagged text[C]. In: Proc. of the AAAI96. Palo Alto: AAAI Press, 1996:10441049.
[3]STEVENSON M, GREENWOOD M. A semantic approach to IE pattern induction[C]. In: Proc. of the ACL 2005. Stroudsburg: ACL, 2005:379386.
[4]PATWARDHAN S, RILOFF E. Effective information extraction with semantic affinity patterns and relevant regions[C]. In: Proc. of the EMNLPcoNLL 2007. Stroudsburg: ACL, 2007: 717727.
[5]AHN D.The stages of event extraction[C].Proceedings of the COLINGACL 2006 Workshop on Annotating and Reasoning About Time and Eyents.2006:18.
[6]吳平博,陳群秀,馬亮.基于事件框架的事件相關文檔的智能檢索研究[J].中文信息學報,2003,17(6):2530.
[7]PATWARDHAN S, RILOFF E. A unified model of phrasal and sentential evidence for information extraction[C]. In: Proc. of the EMNLP Stroudsburg: ACL, 2009:151160.
[8]JI H, GRISHMAN R. Refining event extraction through crossdocument inference[C]. In: Proc. of the ACL 2008. Stroudsburg: ACL,2008:254262.
[9]楊爾弘.突發事件信息提取研究[D].北京:北京語言大學,2005.
[10]AHN D. The stages of event extraction[C]. In: Proc. of the Workshop on Annotating and Reasoning about Time and Events (ARTE 2006). Stroudsburg: ACL, 2006:18.
[11]ZHAO YY, QIN B, CHE WX,et al. Research on Chinese event extraction[J]. Journal of Chinese Information Processing, 2008,22(1):38.(in Chinese with English abstract).
[12]FU JF, LIU ZD, FU XF, et al. Dependency parsing based eventrecognition[J]. Computer Science, 2009,36(11):217219.(in Chinese with English abstract).
[13]李培峰,周國棟,朱巧明.基于語義的中文事件觸發詞抽取聯合模型[J].軟件學報,2016(2):280294.
[14]軒小星,廖濤,高貝貝.中文事件觸發詞的自動抽取研究[J].計算機與數字工程,2015(3):457461.
[15]李培峰,朱巧明.中文事件觸發詞的擴展方法及系統[J].北京大學學報:自然科學版,2016(1):156159.
[16]GROSZ B, ARAVIND J, SCOTT W. Centering: a framework for modeling the local coherence of discourse[J]. Computational Linguistics,1995,21(2):202225.
[17]高源,李弼程.基于依存句法分析與分類器融合的觸發詞抽取方法[J].計算機應用研究,2016(5):14071410.
(責任編輯:杜能鋼)endprint
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
