基于抽樣學(xué)習(xí)的關(guān)聯(lián)挖掘算法設(shè)計(jì)
2018-03-07 08:49:10謝笑盈徐應(yīng)濤
謝笑盈, 徐應(yīng)濤, 張 瑩
(1.浙江師范大學(xué) 經(jīng)濟(jì)與管理學(xué)院,浙江 金華 321004;2.浙江師范大學(xué) 行知學(xué)院,浙江 金華 321004;3.浙江師范大學(xué) 數(shù)理與信息工程學(xué)院,浙江 金華 321004)
0 引 言
關(guān)聯(lián)規(guī)則[1]是Agarwal于1994年首次提出的、旨在分析購(gòu)物籃中各商品之間關(guān)聯(lián)性的數(shù)據(jù)分析方法,該方法能從數(shù)據(jù)集中找到滿足最小支持度(minsup)和最小置信度(minconf)閾值的規(guī)則.按照Agarwal的原始提法,要在數(shù)據(jù)集中提取出關(guān)聯(lián)規(guī)則,需要計(jì)算每個(gè)可能規(guī)則的支持度和置信度,這種方法的時(shí)空代價(jià)太高,因?yàn)橐粋€(gè)包含d個(gè)屬性的數(shù)據(jù)集中能提取的可能規(guī)則的個(gè)數(shù)為r=3d-2d+1+1,若最小支持度為20%,最小置信度為50%,則80%以上的規(guī)則將被丟棄,使得大部分的計(jì)算是無(wú)用的.為了提高挖掘效率,避免進(jìn)行不必要的計(jì)算,統(tǒng)計(jì)學(xué)界及計(jì)算機(jī)學(xué)界的學(xué)者紛紛提出了不同的解決方法.
抽樣技術(shù)是統(tǒng)計(jì)學(xué)中常常被用來(lái)獲取有效信息的經(jīng)典方法,近十幾年來(lái),抽樣的方法也開始被許多學(xué)者用來(lái)提高關(guān)聯(lián)挖掘的效率.這些研究主要包含兩大類:一類是靜態(tài)抽樣的方法,即根據(jù)數(shù)理統(tǒng)計(jì)的方法計(jì)算出一個(gè)能代替總體進(jìn)行關(guān)聯(lián)分析的樣本容量,再用隨機(jī)抽樣的方法抽得該樣本;另一類是動(dòng)態(tài)抽樣(常分為累進(jìn)抽樣和自適應(yīng)抽樣)的方法,即容量從小到大不斷地從總體中抽出樣本,同時(shí)為抽樣設(shè)計(jì)一個(gè)停止抽取的規(guī)則,當(dāng)樣本的容量達(dá)到抽樣停止閾值時(shí),停止抽樣,獲得的樣本被稱為最優(yōu)樣本,將作為總體的替代數(shù)據(jù)集進(jìn)行關(guān)聯(lián)分析.這種描述樣本容量與模型準(zhǔn)確度之間關(guān)系的曲線稱為動(dòng)態(tài)抽樣的學(xué)習(xí)曲線[2],如圖1所示.
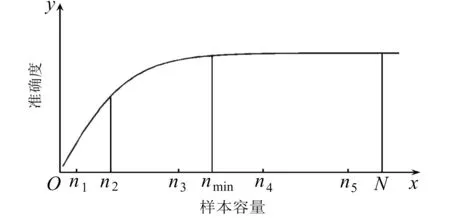
圖1 動(dòng)態(tài)抽樣的學(xué)習(xí)曲線
學(xué)習(xí)曲線的橫軸代表一個(gè)樣本序列,縱軸代表樣本序列對(duì)應(yīng)的準(zhǔn)確度值.典型的學(xué)習(xí)曲線分為3個(gè)演變階段:坡度陡峭階段、坡度相對(duì)平緩階段和坡度為零階段.其中,第2和第3階段的連接點(diǎn)nmin代表的樣本容量通常被稱為最優(yōu)樣本容量OSS(optimal sample size),對(duì)應(yīng)的樣本被稱為最優(yōu)樣本OS(optimal sample).因?yàn)樗腥萘看笥趎min的樣本的準(zhǔn)確度不再有顯著提升,而所有容量小于nmin的樣本的準(zhǔn)確度都比它小,所以繪制學(xué)習(xí)曲線的目的就是要找到nmin,并用它對(duì)應(yīng)的樣本完成挖掘任務(wù).要找到nmin并不是容易的事情,就關(guān)聯(lián)挖掘而言,學(xué)者們就如何設(shè)置高效簡(jiǎn)便的抽樣停止規(guī)則做了很多研究,下面就一些有代表性的抽樣方法進(jìn)行綜述.
文獻(xiàn)[3]設(shè)計(jì)了一種基于動(dòng)態(tài)抽樣的關(guān)聯(lián)分析方法,這個(gè)方法的新穎之處在于設(shè)計(jì)了動(dòng)態(tài)樣本的關(guān)聯(lián)規(guī)則相似度Sim(d1,d2),d1,d2是前后抽取的2個(gè)樣本.當(dāng)這2個(gè)樣本的相似度值接近1時(shí),2個(gè)樣本上產(chǎn)生的關(guān)聯(lián)規(guī)則不再有變化,進(jìn)一步的抽樣也不會(huì)再產(chǎn)生新的關(guān)聯(lián)規(guī)則,此時(shí)就可以認(rèn)為找到了可以代替總體進(jìn)行關(guān)聯(lián)規(guī)則挖掘的樣本了.
文獻(xiàn)[4]提出了一種針對(duì)關(guān)聯(lián)分析的兩步抽樣法.第1步,隨機(jī)抽取一個(gè)容量較大的初始樣本,并計(jì)算出該樣本中各個(gè)項(xiàng)的支持度;第2步,以前一步計(jì)算的支持度作為閾值去刪除“孤立點(diǎn)”,留下具有代表性的項(xiàng),構(gòu)成一個(gè)能較好反映總體統(tǒng)計(jì)性質(zhì)的容量較小的最終樣本.在這個(gè)最終樣本上的關(guān)聯(lián)分析結(jié)果被證明能較好地反映總體上的關(guān)聯(lián)規(guī)則.
文獻(xiàn)[5]設(shè)計(jì)了一種被稱為抽樣錯(cuò)誤估計(jì)(sampling error estimation(SEE))的動(dòng)態(tài)抽樣方法,認(rèn)為:隨著樣本容量的不斷增加,在樣本上進(jìn)行關(guān)聯(lián)分析產(chǎn)生的錯(cuò)誤將不斷減少,如果將所有頻繁項(xiàng)在樣本上的支持度和它在總體上的支持度之差的均方根定義為錯(cuò)誤度量值,那么,當(dāng)這個(gè)均方根的值不再有顯著變化時(shí),就可以認(rèn)為找到了代替總體進(jìn)行關(guān)聯(lián)分析的最優(yōu)樣本.
除上述的方法以外,文獻(xiàn)[6]設(shè)計(jì)了Epsilon Approximation Sample Enabled(EASE)的抽樣方法;文獻(xiàn)[7]設(shè)計(jì)了EASIER方法,對(duì)EASE進(jìn)行了改進(jìn);文獻(xiàn)[8]利用馬爾科夫鏈建立網(wǎng)絡(luò),并通過隨機(jī)游走的方法抽取網(wǎng)絡(luò)上的節(jié)點(diǎn)進(jìn)入樣本,解決了關(guān)聯(lián)規(guī)則挖掘中項(xiàng)集提取的問題;文獻(xiàn)[9-10]設(shè)計(jì)了一種基于序列插值的累進(jìn)抽樣法來(lái)提高關(guān)聯(lián)挖掘的效率;文獻(xiàn)[11]設(shè)計(jì)了一種基于新的累進(jìn)抽樣的方法,提高了關(guān)聯(lián)挖掘的效率;文獻(xiàn)[12]設(shè)計(jì)了從特征空間抽取隨機(jī)樣本序列的方法,以確定關(guān)聯(lián)規(guī)則的方向性;文獻(xiàn)[13]設(shè)計(jì)了micro-randomized方法,獲得隨機(jī)的關(guān)聯(lián)項(xiàng)集,改進(jìn)了Apriori方法的執(zhí)行效率;文獻(xiàn)[14]設(shè)計(jì)了Gibbs-sampling方法,減少了參加關(guān)聯(lián)挖掘的項(xiàng)集個(gè)數(shù),并在精簡(jiǎn)的特征空間中進(jìn)行隨后的關(guān)聯(lián)挖掘.這些方法在尋找最優(yōu)樣本的過程中大多數(shù)都需要多次執(zhí)行關(guān)聯(lián)挖掘,可能會(huì)使抽樣引起的開銷大于其為挖掘帶來(lái)的效率.
本文從數(shù)據(jù)挖掘中分類器性能比較的度量方法上得到啟發(fā),將這種度量方法引入到累進(jìn)抽樣的學(xué)習(xí)曲線構(gòu)建中,在不執(zhí)行關(guān)聯(lián)挖掘的前提下,設(shè)計(jì)了一種新穎的累進(jìn)抽樣方法,利用關(guān)聯(lián)規(guī)則的支持度找到一個(gè)能代替總體進(jìn)行關(guān)聯(lián)分析的最優(yōu)樣本.
1 理論與方法分析
在利用分類模型對(duì)不平衡數(shù)據(jù)進(jìn)行分類挖掘時(shí),通常需要對(duì)挖掘結(jié)果進(jìn)行評(píng)價(jià).對(duì)于二元分類,稀有類通常記為正類,而多數(shù)類記為負(fù)類.表1顯示了匯總分類模型正確和不正確預(yù)測(cè)的實(shí)例數(shù)目的混淆矩陣.其中:真正數(shù)(f+,+(TP))(或簡(jiǎn)稱TP)是指被分類模型正確預(yù)測(cè)的正樣本數(shù);假負(fù)數(shù)(f+,-(FN))(或簡(jiǎn)稱FN)是指被分類模型錯(cuò)誤預(yù)測(cè)為負(fù)類的正樣本數(shù);假正數(shù)(f-,+(FP))(或簡(jiǎn)稱FP)是指被分類模型錯(cuò)誤預(yù)測(cè)為正類的負(fù)樣本數(shù);真負(fù)數(shù)(f-,-(TN))(或簡(jiǎn)稱TN)是指被正確預(yù)測(cè)的負(fù)樣本數(shù).

表1 二元分類問題的混淆矩陣
為了評(píng)價(jià)分類模型的分類效果,構(gòu)造了準(zhǔn)確率(P)、召回率(R)和F1度量3個(gè)指標(biāo),即
(1)
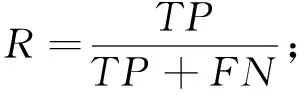
(2)
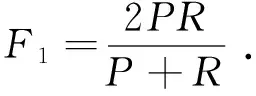
(3)
式(1)~式(3)中:P反映被分類模型預(yù)測(cè)為正類的樣本中實(shí)際為正類的樣本所占的比例;R反映所有的正類中能被分類模型正確預(yù)測(cè)的樣本所占的比例.要使分類模型的性能良好,通常會(huì)平衡準(zhǔn)確率和召回率的值,因?yàn)榍罢咴酱螅讣僬惖腻e(cuò)誤就越小;后者越大,犯假負(fù)類的錯(cuò)誤就越小.因此,將P和R合并成另一個(gè)度量,稱為F1度量,該度量是準(zhǔn)確率與召回率的調(diào)和平均數(shù).
從式(1)和式(2)容易看出,P,R其實(shí)就是2個(gè)條件概率,可表示為
P=p(L=+/Z=+),R=p(Z=+/L=+).
進(jìn)一步得,TP,FP,TN,FN服從參數(shù)為(λTP,λFP,λTN,λFN)的多項(xiàng)分布,即
P(D=(TP,FP,TN,FN))=
λTP+λFP+λTN+λFN=1.
其中:λTP,λFP,λTN,λFN分別表示分類挖掘結(jié)果中TP,FP,TN,FN實(shí)例數(shù)目占所有實(shí)例數(shù)目的比例.由多項(xiàng)分布的邊緣分布和條件分布的性質(zhì),可寫出P的似然函數(shù)為
L(p)=P(D|p)∝pTP(1-p)FP.
根據(jù)貝葉斯規(guī)則和先驗(yàn)分布假設(shè)可推出
其中,λ是形狀參數(shù).
1.1 基于抽樣學(xué)習(xí)的關(guān)聯(lián)規(guī)則算法設(shè)計(jì)
為了提高關(guān)聯(lián)分析的效率,從總體中抽出一個(gè)樣本,理想的,若抽到的樣本中各個(gè)n-項(xiàng)集的頻繁性與它們?cè)诳傮w中的頻繁性相同,頻繁度相似,則樣本所產(chǎn)生的關(guān)聯(lián)規(guī)則與總體產(chǎn)生的關(guān)聯(lián)規(guī)則基本相同.但尋找和比較所有的項(xiàng)集是沒有必要的,因?yàn)轭l繁項(xiàng)集具有向下覆蓋性(若1-項(xiàng)集是非頻繁的,則包含它的2-,3-,…項(xiàng)集都是非頻繁的),所以只需要考察所有1-項(xiàng)集的頻繁度即可.在總體D中設(shè)置一個(gè)最小支持度閾值minsup(D),同時(shí)為最終的樣本設(shè)置一個(gè)最小支持度閾值minsup(S),總體D中的1-項(xiàng)集在隨機(jī)抽樣后以某個(gè)概率P進(jìn)入樣本S,相應(yīng)的會(huì)產(chǎn)生4種情況:1)在D中頻繁而在S中不頻繁;2)在D中不頻繁而在S中頻繁;3)在D和S中都頻繁;4)在D和S中都不頻繁.根據(jù)表1所介紹的分類模型的混淆矩陣評(píng)估抽樣的效果,抽樣后對(duì)樣本中的1-項(xiàng)集的頻繁性產(chǎn)生了一個(gè)“預(yù)測(cè)”:第1種情況可表述為FN,第2種情況可表述為FP,第3種情況可表述為TP,第4種情況可表述為TN.由此可設(shè)計(jì)一個(gè)讓抽樣學(xué)習(xí)停止的規(guī)則,并由該規(guī)則計(jì)算出停止抽樣的閾值.由此,產(chǎn)生了一個(gè)可代替總體進(jìn)行關(guān)聯(lián)挖掘的最優(yōu)樣本OS,該樣本的容量即為最優(yōu)樣本容量OSS.本文設(shè)計(jì)的抽樣停止規(guī)則表述為
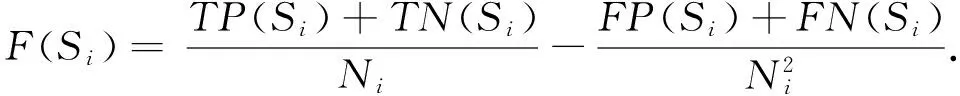
(4)
1.2 基于抽樣學(xué)習(xí)的關(guān)聯(lián)規(guī)則算法實(shí)現(xiàn)
本文所設(shè)計(jì)的基于累進(jìn)抽樣的關(guān)聯(lián)分析算法簡(jiǎn)單,只需瀏覽數(shù)據(jù)總體一次,且不必重復(fù)執(zhí)行關(guān)聯(lián)規(guī)則挖掘,在動(dòng)態(tài)的抽樣學(xué)習(xí)過程中獲得最優(yōu)樣本,且只在最終的樣本上執(zhí)行一次關(guān)聯(lián)分析,無(wú)論在時(shí)間還是空間上都大大提高了挖掘的效率.以下給出該算法的描述:
輸入:進(jìn)行過簡(jiǎn)單預(yù)處理的數(shù)據(jù)總體
輸出:最優(yōu)樣本OS
步驟1:遍歷數(shù)據(jù)總體D以產(chǎn)生一個(gè)容量為ni=n0+200*i的隨機(jī)樣本序列{Si},i=1,2,3,…,同時(shí)計(jì)算所有1-項(xiàng)集的支持度(包括總體和各個(gè)樣本中的1-項(xiàng)集).
步驟2:設(shè)置總體的最小支持度minsup(D),各個(gè)樣本的最小支持度minsup(Si)=pi5minsup(D),其中,pi=ni/N,N表示總體的容量.
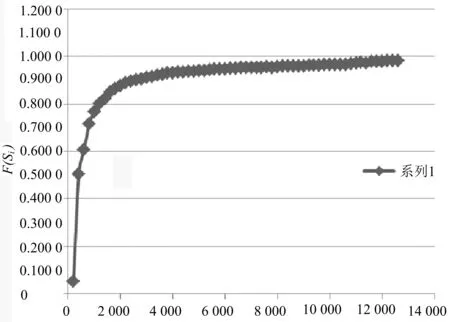
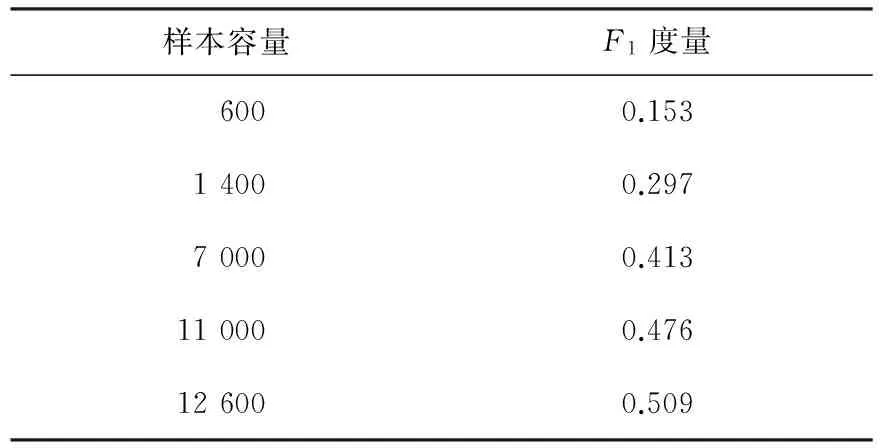
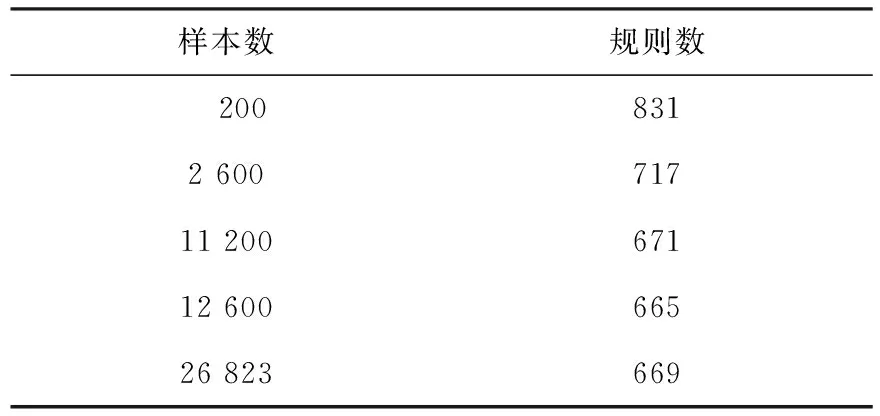
步驟3:從S1開始計(jì)算F(Si),當(dāng)F(Sm)=F(Sm+1)=F(Sm+2)≈1時(shí)(為了避免隨機(jī)情況的發(fā)生,對(duì)相同容量的樣本進(jìn)行若干次循環(huán),以求得最大的F(Si)值,同時(shí)該等式可適當(dāng)?shù)匮娱L(zhǎng)至Sm+l,m+l 步驟4:用Sm+l代替D進(jìn)行關(guān)聯(lián)分析,得到具有較強(qiáng)概率保證的關(guān)聯(lián)規(guī)則挖掘結(jié)果. 本算法在Windows 7系統(tǒng)下、8.00 G內(nèi)存、i7-5600 U處理器的PC機(jī)上進(jìn)行了效果測(cè)試,所用的數(shù)據(jù)來(lái)自2010年第6次全國(guó)人口普查浙江省人口普查長(zhǎng)表,共有26 823個(gè)樣本,17個(gè)屬性變量,這些變量都是人口普查表中個(gè)人填報(bào)的項(xiàng)目,包括年齡、性別、職業(yè)、婚姻狀況和受教育狀況等相關(guān)內(nèi)容.本文為了分析驗(yàn)證所設(shè)計(jì)的算法在關(guān)聯(lián)挖掘中的優(yōu)越性,以人口流動(dòng)與就業(yè)分布的關(guān)聯(lián)關(guān)系為挖掘目的,對(duì)該數(shù)據(jù)集進(jìn)行了必要的預(yù)處理,最終有26 823個(gè)樣本參加了關(guān)聯(lián)分析. 對(duì)比Apriori算法、EASE算法和EASEIER算法,可明顯看出該算法的優(yōu)越性.圖2是樣本容量以200為步長(zhǎng),從200到12 600時(shí)各個(gè)樣本與其對(duì)應(yīng)的F(Si)值形成的學(xué)習(xí)曲線,其中,橫坐標(biāo)表示樣本容量,縱坐標(biāo)表示F(Si)值.與圖1所顯示的學(xué)習(xí)曲線的特性完全相同:當(dāng)樣本容量在[0,2 600]時(shí),坡度陡峭,F(xiàn)(Si)值從0急速過度到0.902 1,這說(shuō)明總體中接近90%的1-項(xiàng)集的頻繁性被容量為2 600的這個(gè)樣本準(zhǔn)確地“預(yù)測(cè)”了,那么總體中與這些1-項(xiàng)集相關(guān)的關(guān)聯(lián)規(guī)則都可以由這個(gè)樣本來(lái)產(chǎn)生,換句話說(shuō),由這個(gè)樣本產(chǎn)生的關(guān)聯(lián)規(guī)則與總體產(chǎn)生的關(guān)聯(lián)規(guī)則的一致率約為90%;當(dāng)樣本容量在[2 600,11 200]時(shí),坡度相對(duì)平緩,F(xiàn)(Si)值從0.902 1緩慢地過度到0.973 1,說(shuō)明當(dāng)樣本容量到達(dá)11 200時(shí),總體中約97.31%的1-項(xiàng)集的頻繁性被這個(gè)樣本準(zhǔn)確地“預(yù)測(cè)”了,若用這個(gè)樣本代替總體進(jìn)行關(guān)聯(lián)挖掘,則準(zhǔn)確率能達(dá)到97%左右;當(dāng)樣本容量在[11 200,12 600]時(shí),學(xué)習(xí)曲線的坡度幾乎為零,F(xiàn)(Si)值從0.973 1緩慢地趨于1,理論上說(shuō),總體的F(Si)值就等于1.如果以損失一部分的準(zhǔn)確性為代價(jià)來(lái)提高挖掘效率,就可以選擇OSS=12 600,或者選擇更小的容量值. 樣本容量圖2 用F(Si)值刻畫的樣本學(xué)習(xí)曲線 本節(jié)將對(duì)抽樣結(jié)果的有效性和可靠性進(jìn)行評(píng)估:通過對(duì)抽樣序列的F1度量值對(duì)比來(lái)完成有效性的評(píng)估;通過對(duì)總體、最優(yōu)樣本和拐點(diǎn)樣本的關(guān)聯(lián)挖掘結(jié)果對(duì)比來(lái)完成可靠性評(píng)估. 從表2可以看出:隨著樣本容量的增加,樣本的F1度量值在逐漸增大,說(shuō)明在此變化過程中,樣本容量越大,樣本對(duì)總體的頻繁度信息保留就越多,特別是當(dāng)樣本容量達(dá)到由F(Si)值計(jì)算的最優(yōu)樣本容量時(shí),F(xiàn)1度量值達(dá)到最大,此時(shí)的準(zhǔn)確率P或者召回率R也將最大.因此,用樣本的F(Si)值作為抽樣停止的閾值這一抽樣策略是有效的. 從表3可以看出:對(duì)學(xué)習(xí)曲線上的幾個(gè)特殊點(diǎn)處的樣本進(jìn)行關(guān)聯(lián)挖掘時(shí),在相同的支持度和置信度評(píng)價(jià)前提下,隨著樣本容量的增加,樣本產(chǎn)生的1-項(xiàng)集,2-項(xiàng)集,…,6-項(xiàng)集的個(gè)數(shù)越來(lái)越接近于對(duì)總體進(jìn)行挖掘時(shí)產(chǎn)生的項(xiàng)集個(gè)數(shù),特別是當(dāng)樣本的F(Si)值接近于1時(shí),挖掘結(jié)果與總體幾乎完全一致,說(shuō)明在該樣本容量下,抽樣引起的頻繁項(xiàng)集丟失問題可以被忽略,用該樣本進(jìn)行關(guān)聯(lián)分析是可靠的. 表2 不同樣本容量下樣本的F1度量值對(duì)比 表3 學(xué)習(xí)曲線上特殊容量樣本產(chǎn)生的頻繁項(xiàng)集數(shù)對(duì)比 在相同的支持度閾值和置信度閾值下比較了學(xué)習(xí)曲線上各個(gè)特殊點(diǎn)樣本產(chǎn)生的規(guī)則個(gè)數(shù),結(jié)果如表4所示.從表4可以看出,容量為11 200和12 600的樣本產(chǎn)生的規(guī)則個(gè)數(shù)與總體產(chǎn)生的規(guī)則個(gè)數(shù)非常接近.這一結(jié)果表明:根據(jù)F(Si)值產(chǎn)生的最優(yōu)樣本可以代替總體進(jìn)行關(guān)聯(lián)分析,它們之間因?yàn)槌闃右鸬年P(guān)聯(lián)分析的誤差很小,用最優(yōu)樣本進(jìn)行關(guān)聯(lián)挖掘是可靠的. 表4 學(xué)習(xí)曲線上各樣本在相同支持度與置信度下產(chǎn)生的規(guī)則數(shù)對(duì)比 根據(jù)關(guān)聯(lián)挖掘的特點(diǎn)設(shè)計(jì)了一種新穎的累進(jìn)抽樣的方法,該方法將二元分類評(píng)估的混淆矩陣引入到因隨機(jī)抽樣引起的樣本1-項(xiàng)集頻繁性變動(dòng)的問題中.因?yàn)轭l繁1-項(xiàng)集的個(gè)數(shù)是關(guān)聯(lián)規(guī)則產(chǎn)生的基礎(chǔ),是所有后續(xù)關(guān)聯(lián)挖掘的前提,所以本文設(shè)計(jì)的方法以此為切入點(diǎn),針對(duì)抽樣后1-項(xiàng)集頻繁性變動(dòng)的4種可能結(jié)果,以保證最終樣本中的頻繁1-項(xiàng)集個(gè)數(shù)與總體中的頻繁1-項(xiàng)集的個(gè)數(shù)相同為抽樣學(xué)習(xí)的目標(biāo),設(shè)計(jì)了累進(jìn)抽樣的停止公式. 本文設(shè)計(jì)的抽樣停止公式以抽樣的真正數(shù)、假正數(shù)、真負(fù)數(shù)、假負(fù)數(shù)為基礎(chǔ),以真正數(shù)和真負(fù)數(shù)最大化為獲取閾值的臨界點(diǎn).根據(jù)抽樣過程中F(Si)值相對(duì)于樣本容量的變化關(guān)系來(lái)刻畫累進(jìn)抽樣的學(xué)習(xí)曲線,然后根據(jù)學(xué)習(xí)曲線找到抽樣停止的樣本容量,并以該樣本作為代替總體進(jìn)行關(guān)聯(lián)挖掘的最優(yōu)樣本. 為了驗(yàn)證本文設(shè)計(jì)的抽樣學(xué)習(xí)公式是有效的、可靠的,用二元混淆矩陣的F1度量值進(jìn)行評(píng)估.F1度量是抽樣的準(zhǔn)確率(P)與召回率(R)的調(diào)和平均值,當(dāng)F1度量值接近于穩(wěn)定值時(shí),準(zhǔn)確率或者召回率將達(dá)到最優(yōu),穩(wěn)定值的選擇取決于召回率或準(zhǔn)確率.實(shí)踐表明該抽樣方法是有效的、可靠的. 在未來(lái)的研究中,還有以下幾個(gè)方面的挑戰(zhàn):一是在刻畫累進(jìn)抽樣的學(xué)習(xí)曲線時(shí)如何產(chǎn)生抽樣序列,使得學(xué)習(xí)曲線的行為更良好;二是如何處理低支持度且高置信度規(guī)則的未入樣問題. [1]Agarwal R,Srikant R.Fast algorithms for mining association rules[J].Journal of Computer Science and Technology,1994,15(6):619-624. [2]Provost F,Jensen D,Oates T.Efficient progressive sampling[C]//Proc of the 5th Conf on Knowledge Discovery and Data Mining.New York:ACM Press,1999:23-32. [3]Parthasarathy S,Zaki M J,Ogihara M,et al.Parallel data mining for association rules on shared memory system knowledge and information system[J].Knowl Inf Syst,2001,3(1):1-29. [4]Chen B,Haas P,Scheuermann P.A new two phase sampling based algorithm for discovering association rules[C]//The 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.Edmonton:ACM Press,2002:462-468. [5]Chuang K T,Chen M S,Yang W C.Progressive sampling for association rules based on sampling error estimation[J].Lecture Notes in Computer Science,2005,3518(1):505-515. [6]Dash M,Haas P,Haas P,et al.Efficient data reduction with EASE[C]//Proc of the 9th International Conference on KDD.Washington:ACM,2003:59-68. [7]Wang S,Dash M,Chia L T.Efficient sampling:Application to image data[C]//Advances in Knowledge Discovery and Data Mining of the 9th Pacific-Asia Conference.Hanoi:ACM,2005. [8]Fang M,Yin J,Zhu X.Supervised sampling for networked data[J].Signal Processing,2015,124(1):93-102. [9]Umarani V,Punithavalli M.Developing novel and effective approach for association rule mining using progressive sampling[C]//The 2nd International Conference on Computer and Electrical Engineering.Dubai:UAE,2009. [10]Umarani V,Punithavalli M.On developing an effectual progressive sampling based approach for association rule discovery[C]//International Conference on Information Management & Engineering.Chengdu:IEEE,2010. [11]Chakaravarthy V T,Pandit V,Sabharwal Y.Analysis of sampling techniques for association rule mining[C]//Database Theory:The 12th International Conference.Petersberg:ICDT,2009. [12]Lopez-Paz D,Muandet K,Sch?lkopf B,et al.Towards a learning theory of cause-effect inference[C]//The 32th International Conference on Machine Learning.Lille:JMLR,2015. [13]Rutterford C,Copas A,Eldridge S.Methods for sample size determination in cluster randomized trials[J].International Journal of Epidemiology,2015,44(3):1051-1067. [14]Qian G,Rao C R,Sun X,et al.Boosting association rule mining in large datasets via Gibbs sampling[J].Proceedings of the National Academy of Sciences,2016,13(18):4958-4963. [15]Goutte C,Gaussier E.A probabilistic interpretation of precision recall andF-score,with implication for evaluation[J].Chapman and Hall,1979,3408(2):345-359.2 實(shí)證分析
3 效果評(píng)估

4 結(jié)論與展望
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當(dāng)代陜西(2021年17期)2021-11-06 03:21:36
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:26:14
學(xué)苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
暨南學(xué)報(bào)(哲學(xué)社會(huì)科學(xué)版)(2016年9期)2017-01-15 13:52:02
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
