基于電子舌的摻假羊奶快速定量預(yù)測模型
2018-03-11 02:37:32王志強(qiáng)李彩虹馬澤亮國婷婷殷廷家
食品與機(jī)械 2018年12期
韓 慧 王志強(qiáng) 李彩虹 馬澤亮 國婷婷 殷廷家
(山東理工大學(xué)計算機(jī)科學(xué)與技術(shù)學(xué)院,山東 淄博 255049)
辨別羊奶質(zhì)量檢測經(jīng)常使用的分析方法有感官評價分析法,但經(jīng)常受到人們主觀因素的影響,具有重復(fù)性差、成本高等缺點(diǎn)。高效氣相色譜法、高效液相色譜法這些傳統(tǒng)的檢測方法所需儀器設(shè)備體積大、價格昂貴、分析時間長,無法達(dá)到對羊奶快速、客觀、全面的檢測。電子舌是模仿人體味覺感知系統(tǒng)而設(shè)計的一種新型的現(xiàn)代化智能分析檢測設(shè)備,它檢測簡易方便、檢測時間短、客觀性強(qiáng)、成本低。目前,電子舌已廣泛應(yīng)用于環(huán)境[1]、藥品[2-3]、食品[4-6]等領(lǐng)域。近年來,國內(nèi)外專家也投入大量精力研究解決羊奶的質(zhì)量檢測問題。例如金嫘等[7]采用電子鼻檢測羊奶中的牛奶摻入;王二丹等[8]利用非線性化學(xué)群集成分分析法對摻雜在羊奶中的牛奶和馬奶含量進(jìn)行了定量分析;賈茹等[9]利用電子鼻檢測系統(tǒng)結(jié)合化學(xué)計量法對羊奶中蛋白質(zhì)摻假進(jìn)行了識別。但至今尚未有利用電子舌對羊奶摻假進(jìn)行定性定量分析的相關(guān)報道。
本研究擬以摻假羊奶為檢測對象,利用自行搭建的電子舌檢測系統(tǒng)對6種混入不同比例牛奶的羊奶進(jìn)行檢測分析。本研究采用離散小波變換DWT對響應(yīng)信號進(jìn)行特征提取,最后在此基礎(chǔ)上,采用主成分分析法對不同摻假比例的羊奶進(jìn)行定性辨別、采用粒子群優(yōu)化極限學(xué)習(xí)機(jī)對不同摻假比例的羊奶進(jìn)行定量預(yù)測。旨在為摻假羊奶的定性辨別和定量預(yù)測提供新的理論依據(jù)及技術(shù)支持。
1 材料與方法
1.1 樣本制備
新鮮羊奶、新鮮牛奶:購于山東省淄博市本地大型超市,均在保質(zhì)期之內(nèi),并在試驗前密封保存,防止其氧化變質(zhì)。
1.2 電子舌系統(tǒng)
USB6002數(shù)據(jù)采集卡、自主研發(fā)的信號處理模塊、傳感器陣列、以及配套的上位機(jī)組成的電子舌系統(tǒng)如圖1所示。首先虛擬儀器軟件LabVIEW產(chǎn)生脈沖激勵信號,該信號經(jīng)過數(shù)據(jù)采集卡進(jìn)行模數(shù)轉(zhuǎn)換,轉(zhuǎn)換后的信號還需要通過信號處理模塊中的恒電位電路進(jìn)行調(diào)理,最后才將處理后的信號施加于傳感器陣列。傳感器表面會發(fā)生電化學(xué)反應(yīng)并產(chǎn)生微弱電流響應(yīng)信號,由于不同傳感器吸附分子能力的不同,得出的電信號也不同,從而導(dǎo)致傳感器與標(biāo)準(zhǔn)電極之間電勢差發(fā)生改變。信號調(diào)理模塊對該信號進(jìn)行I/V(電流/電壓)轉(zhuǎn)換和信號放大及其濾波,之后傳送到USB6002數(shù)據(jù)采集卡進(jìn)行AD轉(zhuǎn)換,最終送到上位機(jī)進(jìn)行數(shù)據(jù)預(yù)處理和模式識別[10]。

圖1 電子舌結(jié)構(gòu)框圖與實(shí)物圖Figure 1 The block diagram and physical diagram of electronic tongue
1.3 試驗方法
摻假羊奶樣本配制:將牛奶按0%,10%,20%,30%,40%,50%的比例混入羊奶中,配制純度為100%,90%,80%,70%,60%,50%的摻假羊奶。配置好溶液后,為防止溶液變質(zhì),迅速貼好標(biāo)簽放入冰箱0~6 ℃冷藏。檢測試驗在室溫環(huán)境下進(jìn)行。每次測量前后,對8個工作電極都進(jìn)行電化學(xué)清洗和拋光處理。從配置好的待檢測溶液中依次量取50 mL摻假羊奶進(jìn)行檢測。每次量取完之后將配置好的溶液密封好再次放入冰箱冷藏。利用上位機(jī)控制傳感器陣列對配置好的溶液進(jìn)行重復(fù)檢測(20次),每次檢測完需對電極陣列進(jìn)行電化學(xué)清洗,確保每個電極表面光如鏡面且無殘留物,以防止對下次檢測結(jié)果造成影響。每檢測1次,可得到8 000個數(shù)據(jù)點(diǎn),最終可得到120×8 000的數(shù)據(jù)矩陣。
1.4 數(shù)據(jù)處理與分析
1.4.1 小波分析 在脈沖激勵信號的激發(fā)下,通過8種特定的貴金屬電極獲取的響應(yīng)信號數(shù)據(jù)融合后,除了包含溶液特征信息,還包含有一些冗余和高頻噪聲信息,對后期模式識別造成巨大干擾[11]。為了降低系統(tǒng)的處理難度,減少處理時間,應(yīng)對電子舌的原始數(shù)據(jù)進(jìn)行特征提取,因此采用離散小波變換DWT對數(shù)據(jù)進(jìn)行壓縮和降噪預(yù)處理。它是時頻的局部化分析,最終達(dá)到高頻處時間細(xì)分,低頻處頻率細(xì)分,在去除高頻干擾的同時有效地減少了冗余信息,從而提取出特征點(diǎn),因此有效地壓縮了數(shù)據(jù),降低了后期模式識別的復(fù)雜度,是一種有效的數(shù)據(jù)預(yù)處理方式。
1.4.2 主成分分析 主成分分析是一種分析簡化數(shù)據(jù)、探索數(shù)據(jù)結(jié)構(gòu)以及進(jìn)行數(shù)據(jù)降維的多元統(tǒng)計分析方法。少數(shù)幾個能充分反映總體信息的指標(biāo)從原來的多個指標(biāo)中被組合出來。少數(shù)的幾個指標(biāo)就能充分反映總體信息,保留了重要信息且避開了變量間共線性問題[12]。主成分分析不僅保留了原始變量的主要信息,而且將多個指標(biāo)問題轉(zhuǎn)換成少數(shù)幾個綜合指標(biāo)問題,有效地起到降維與簡化問題的作用,更容易抓住所研究問題的主要矛盾。主成分分析結(jié)果一般通過得分圖和載荷因子圖表示。主成分得分圖中每個點(diǎn)代表1個樣品,通過點(diǎn)與點(diǎn)之間的距離來反映樣品之間特征差異的大小[13]。
1.4.3 粒子群優(yōu)化極限學(xué)習(xí)機(jī)
(1) 極限學(xué)習(xí)機(jī):它(extreme learning machine,ELM)是單隱層前饋神經(jīng)網(wǎng)絡(luò)SLFN學(xué)習(xí)算法的一種,它使用簡單、有效。人們所熟悉的BP神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)算法使用前,需要提前對眾多的網(wǎng)絡(luò)訓(xùn)練參數(shù)進(jìn)行設(shè)定,而且容易生成局部最優(yōu)解[14]。極限學(xué)習(xí)機(jī)是有監(jiān)督的機(jī)器學(xué)習(xí)算法,可用來解決回歸、二分類、多分類問題。極限學(xué)習(xí)機(jī)在算法的執(zhí)行過程中不需要調(diào)整網(wǎng)絡(luò)的輸入權(quán)值以及隱含層偏置,隨機(jī)初始化生成輸入層和隱含層之間的權(quán)重和隱含層節(jié)點(diǎn)的閾值。只需要設(shè)置網(wǎng)絡(luò)的隱層節(jié)點(diǎn)個數(shù),就能獲得唯一的最優(yōu)解。
雖然在大部分情況下,極限學(xué)習(xí)機(jī)ELM具有良好的性能,但是極限學(xué)習(xí)機(jī)的精度與偏置閾值b、連接權(quán)值W、隱含層節(jié)點(diǎn)數(shù)目密切相關(guān)。通過計算輸入權(quán)值矩陣和隱含層的偏置來獲得輸出權(quán)值矩陣,隱含層節(jié)點(diǎn)有時候無效,會導(dǎo)致輸入權(quán)值矩陣和隱含層偏置為零。這樣的話就表明實(shí)際運(yùn)用時,為了達(dá)到預(yù)期的效果,更多的隱含層節(jié)點(diǎn)需要被設(shè)置。隱含層節(jié)點(diǎn)如果設(shè)置過多,網(wǎng)絡(luò)會更加復(fù)雜,ELM的泛化能力會降低,產(chǎn)生擬合現(xiàn)象,造成預(yù)測的穩(wěn)定性不足[15]。
(2) 粒子群:粒子群算法(PSO)是源于對鳥群捕食行為的研究而設(shè)計的一種群智能算法。在區(qū)域里只有一塊食物。鳥群中的鳥兒們并不知道食物的存放在哪里,最佳的解決策略就是通過搜尋當(dāng)前離食物最近的鳥的周圍區(qū)域從而獲得食物。粒子群算法(PSO)就是用粒子來模擬鳥群中的鳥兒,將每個優(yōu)化問題當(dāng)作是D維搜索空間上的一個點(diǎn),也就是“粒子”。粒子移動的快慢用速度V來表示,粒子移動的方向用位置X表示。每個粒子在搜索空間中搜尋最優(yōu)值Pbest,并且將個體極值Pbest共享給粒子群里的其他粒子,最優(yōu)的個體極值稱之為整個粒子群的當(dāng)前全局最優(yōu)值Gbest,粒子們追隨當(dāng)前的最優(yōu)粒子在空間中搜索[16]。
(3) 粒子群優(yōu)化極限學(xué)習(xí)機(jī):為了解決上文提到的極限學(xué)習(xí)機(jī)的缺點(diǎn),粒子群優(yōu)化極限學(xué)習(xí)機(jī)是將粒子群優(yōu)化和極限學(xué)習(xí)機(jī)結(jié)合得到的學(xué)習(xí)算法。主題思想是極限學(xué)習(xí)機(jī)的輸入層權(quán)值和隱含層偏置通過粒子群優(yōu)化算法來進(jìn)行最優(yōu)化,以此得到一個最佳網(wǎng)絡(luò)[17]。也就是說將極限學(xué)習(xí)機(jī)的輸入權(quán)值和隱含層偏置當(dāng)作粒子群算法中的粒子。利用極限學(xué)習(xí)機(jī)算法計算輸出權(quán)值矩陣,從而減少隱含層節(jié)點(diǎn),依靠較少的隱含層節(jié)點(diǎn)獲得較高的精度[18]。
2 結(jié)果與討論
2.1 小波信號預(yù)處理
本研究選用Coiflets、haar、Daubechies、Symlets作為小波基函數(shù),對采集到的響應(yīng)信號數(shù)據(jù)進(jìn)行預(yù)處理,并根據(jù)響應(yīng)信號的幾何波形特征確定小波壓縮層數(shù)。壓縮重構(gòu)信號和原始信號之間的相似程度隨著壓縮層數(shù)的增多而遞減,如果壓縮層數(shù)過多,雖然能夠?qū)υ紨?shù)據(jù)進(jìn)行壓縮,但也必然會造成了大量特征信息的丟失,對原始信號特征的表達(dá)非常不利[19]。本研究綜合考慮壓縮率以及減小數(shù)據(jù)分析處理難度,采用MATLAB2014a軟件中Coiflets、haar、Symlets等小波函數(shù)對采集數(shù)據(jù)進(jìn)行多次預(yù)處理試驗。得到的近似系數(shù)重構(gòu)信號與原始信號進(jìn)行比較,選擇最佳的小波分解層數(shù)和小波基函數(shù)。通過試驗對比,發(fā)現(xiàn)選擇sym4為小波基函數(shù),原始數(shù)據(jù)經(jīng)過6層壓縮效果最佳。可以有效地刪除無用的高頻干擾和冗余信息,保留原始信號有效成分。將8 000個原始數(shù)據(jù)壓縮至67個數(shù)據(jù),實(shí)現(xiàn)數(shù)據(jù)的有效預(yù)處理,如圖2所示。
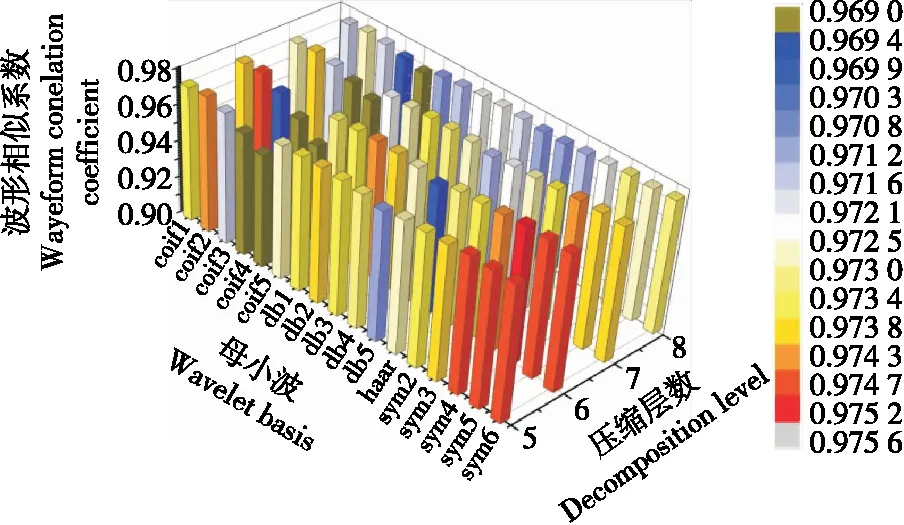
圖2 不同母小波和壓縮層數(shù)對相似系數(shù)的影響Figure 2 Effects of different mother wavelets and compression layers on similarity coefficient
2.2 摻假羊奶定性辨別
經(jīng)過小波離散變換預(yù)處理后,用PCA對數(shù)據(jù)進(jìn)行分析。經(jīng)過20次平行檢測后,得到其主成分得分值點(diǎn)分布情況如圖3所示。從圖3中可以看到,第1主成分的貢獻(xiàn)率為72.8%,第2主成分的貢獻(xiàn)率為21.1%,累計貢獻(xiàn)率為93.9%,基本能夠代表樣品的整體信息,說明電子舌的原始特征數(shù)據(jù)通過主成分分析很好地進(jìn)行了說明;6種純度的羊奶樣品分布在不同的區(qū)域,相互沒有重疊。說明應(yīng)用主成分分析法PCA可以將不同濃度的羊奶準(zhǔn)確地區(qū)分開來,從而進(jìn)行了有效的辨識。
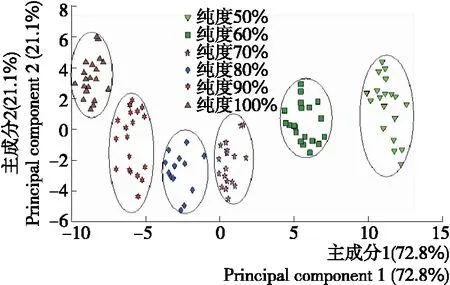
圖3 主成分分析圖Figure 3 The principal component analysis
2.3 摻假羊奶定量預(yù)測
為實(shí)現(xiàn)摻假羊奶的定量預(yù)測,采用PSO-ELM方法建立摻假羊奶定量預(yù)測模型。選取90個樣本作為訓(xùn)練集用于模型的建立以及參數(shù)的優(yōu)化。其中90個樣本包含6組不同純度樣本,其中每一組又包含15個相同濃度樣本。剩余30組(6組純度,每種純度5個)作為預(yù)測集,用于模型的驗證。
采用網(wǎng)格搜索法優(yōu)化極限學(xué)習(xí)機(jī)(GS-ELM)、遺傳算法優(yōu)化極限學(xué)習(xí)機(jī)(GA-ELM)與粒子群優(yōu)化極限學(xué)習(xí)機(jī)(PSO-ELM)進(jìn)行比較分析,從而對PSO-ELM摻假羊奶的預(yù)測模型效果進(jìn)行驗證。分別按式(1)~(3)計算均方根誤差(RMSE)、平均絕對誤差(MAE)、相關(guān)系數(shù)(R2),并對這3種ELM模型進(jìn)行評價。
(1)
(2)
(3)
式中:
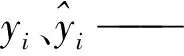

N——樣本量。
RMSE、MAE、R2范圍在 [0,1]內(nèi),并且這3個值可以反映模型的預(yù)測性和進(jìn)度。RMSE、MAE值距離0越近越好,R2距離1越近越好。不同參數(shù)優(yōu)化下的羊奶純度預(yù)測模型如圖4所示。
從圖4和表1中可以得出,網(wǎng)格搜索法建模集中RMSE為0.022 7、R2為0.896、MAE為0.356,驗證集中RMSE為0.028 6、R2為0.862、MAE為0.368,相對于遺傳算法及粒子群算法預(yù)測效果不好,可能是網(wǎng)格搜索法雖然能夠通過逐步搜索尋找出滿足精確度的參數(shù)組合,但需要不斷縮小參數(shù)區(qū)間且計算量大、效率低所造成的。進(jìn)一步比較遺傳算法及粒子群算法發(fā)現(xiàn),粒子群算法預(yù)測效果最好,這是因為遺傳算法受適應(yīng)度函數(shù)、初值的影響,而粒子群算法具有速度快、效率高,算法簡單等優(yōu)點(diǎn)。因此相對于網(wǎng)格搜索算法及其遺傳算法,PSO粒子群具有更佳的靈活和適應(yīng)性,可以快速準(zhǔn)確地尋找最優(yōu)的ELM參數(shù)組合,因此PSO-ELM羊奶純度預(yù)測模型精度較高。

圖4 不同濃度羊奶樣本的ELM預(yù)測圖Figure 4 The ELM prediction of goat milk samples withdifferent concentrations

表1 ELM模型性能指標(biāo)在不同參數(shù)優(yōu)化方法下的對比Table 1 Performance comparison of PLSR and SVM model based on different parameter optimization methods
3 結(jié)論
本研究采用PCA對不同摻假濃度的羊奶進(jìn)行了識別,不同摻假濃度的羊奶各自落在不同的區(qū)域,相互之間隔離比較遠(yuǎn),因此電子舌可以將不同摻假濃度的羊奶進(jìn)行有效的區(qū)分。采用粒子群優(yōu)化極限學(xué)習(xí)機(jī)對不同摻假比例的羊奶進(jìn)行定性預(yù)測,PSO-ELM羊奶摻假比例預(yù)測模型具有較高的預(yù)測精度。該算法綜合了極限學(xué)習(xí)機(jī)ELM和粒子群PSO的優(yōu)點(diǎn),具有參數(shù)調(diào)整簡單、泛化性好的優(yōu)點(diǎn)。試驗結(jié)果表明,電子舌能夠?qū)⒉煌瑩郊贊舛鹊难蚰谭酆芎玫貐^(qū)別開來。電子舌作為一種新型的現(xiàn)代化智能感官儀器,下一步在牛奶及其羊奶奶粉的品質(zhì)以品牌區(qū)分以及摻假鑒別等方面具有巨大潛力。
猜你喜歡
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
電子制作(2018年11期)2018-08-04 03:25:42
