動態流形方法在多文檔文摘模型上的應用
2018-03-20 09:10:16劉美玲鄭德權王慧強
計算機技術與發展 2018年3期
劉美玲,鄭德權,王慧強,于 洋
(1.東北林業大學 信息與計算機工程學院,黑龍江 哈爾濱 150040;2.哈爾濱工業大學 教育部-微軟語言語音重點實驗室,黑龍江 哈爾濱 150001;3.哈爾濱工程大學 計算機科學與技術學院,黑龍江 哈爾濱 150001)
0 引 言
在Web2.0時代,網絡上的各種新聞、論壇、博客、在線聊天等信息跟靜態網頁信息相比體現出非常明顯的動態演化性。網絡信息隨著時間的變化而出現、發展直至消亡,一個話題在不同的時刻具有不同的側重點,而不同時刻的話題內容之間具有關聯性,如何針對這類持續發展變化的話題或者事件提供動態摘要已經成為一個新的研究方向。
傳統的多文檔文摘[1]技術是一種靜態文摘,即針對某個封閉的靜態文檔集生成摘要,不考慮文檔集的對外聯系。動態文摘是傳統靜態文摘的延伸和擴展,除了需要保證文摘信息的主題相關性和內容的低冗余性之外,還需要針對內容的動態演化性分析已出現信息和新出現信息的關系,使文摘隨話題的演化而動態更新。動態文摘與靜態文摘的最大區別在于分析已出現信息和新出現信息的關系,從而對內容的動態演化性進行建模。
TAC2008的評測任務中Update Summarization作為文摘研究的標準備受關注,文中對動態多文檔文摘動態演化的內容選擇問題展開進一步的研究。流形排序(manifold-ranking)是經典的排序方法,之前在話題相關文摘中的應用效果不錯,但該方法并不能捕捉時間片進化的信息。文中以動態信息的模擬演化為目標,通過建立動態流形排序模型來為動態多文檔文摘話題相關的內容選擇提供重要性排序。
提出了一種動態流形排序模型(dynamic manifold ranking model,DMRM),將其用于動態多文檔文摘的研究中,使文摘同時融入了文檔的流形結構和動態演化性。在動態多文檔文摘領域,對相關文檔集進行特征抽取是文摘技術的核心。主流思想是以信息顯著性和信息新穎性為主要特征,根據句子信息顯著度和信息新穎度對句子加權排序,抽取排序值最高的句子作為文摘句;對已經提取的文檔集特征,根據信息顯著度對句子加權排序,進而根據信息新穎度過濾句子,過濾掉信息新穎度低的句子,最后從剩余的句子集合中抽取排序值高的句子作為文摘句。在上述兩種思想中,都把文檔集中的句子看成是孤立的,認為句子之間沒有關聯,這是一種錯誤的假設。文檔集中的句子,有相當一部分相互之間具有關聯性。
文中提出的動態流形排序思想彌補了上述兩種模型的不足,基于動態分析,考慮了句子之間的相關性。動態流行排序是一種迭代算法,考慮了句子集合中數據點的流行結構,經迭代后,相似的句子趨向于具有相同的排序值,同類的句子趨向于具有相同的排序值,克服了常規文摘方法的缺點。
1 相關工作
1.1 動態多文檔文摘和流行排序的相關研究
美國NIST[2]承辦的Document Understanding Conference (DUC) 2007[3]首次提出了動態文摘任務,在IARPA[4]的支持下于2007年舉行了第一屆評測會議,并且在Text Analysis Conference (TAC)2008[5]中仍然被作為重要的評測任務之一。在時序信息高速演化的背景下,快速的動態信息獲取技術成為數據挖掘和自然語言處理的研究重點。
國內很多學者在文摘方面的研究效果顯著,例如,靜態文摘和動態文摘相結合就是一種基于改進文摘模型的動態文摘解決方法。張瑾等[6]提出了一種基于模糊隸屬度的文檔過濾模型。該方法從對動態內容的建模入手,通過模式識別和傳統文摘生成方法,對動態內容進行提取和分析。在動態網絡演化信息中,句子選擇和排序也需要動態變化,因此需要解決如何在排列策略中體現動態內容的演化性問題。文中主要對信息顯著度(information significance,IS)[7]和信息新穎度(information novelty,IN)兩種指標進行評估和分析,在此基礎上改進設計一種基于動態時序內容的句子排列流形策略。
流形這個概念最早產生于人類對感知的研究[8],最初階段關系到與物理世界(地球的表面)和幾何公理研究有關的多維參數思想的分析[9]。從拓撲學角度出發,流形表示一個局部為歐幾里德的拓撲空間。局部歐幾里德特性意味著對于空間上任一點都有一個鄰域,在這個鄰域中的拓撲與Rm空間中的開放單位圓相同,Rm表示m維歐氏空間,從拓撲空間的一個開集(鄰域)到歐氏空間的開子集的同胚映射,使得每個局部可坐標化。它的本質是分段線性處理[10]。流形學習的主要目標是從非線性高維數據中發現嵌入其中的低維光滑流形,以進行維數約簡和數據分析。
流形排序[11-12]在話題相關的靜態多文檔文摘中得到了很好的應用,在傳統文摘技術中應用流形排序學習算法中得到了啟發。文中面向動態多文檔文摘領域,提出了一種面向查詢的動態流形排序模型,該模型更好地體現了文檔的流行結構和動態演化性。
1.2 主流的評測方法
目前在時序多文檔文摘的評價方面完全沿用傳統靜態多文檔文摘的評價方法,包括自動評價ROUGE[10]、BE[13]方法和人工評價金字塔(PYRAMID)[14]方法。文摘評價主要面向文摘的內容選擇和語言質量。自動評價針對文摘的內容選擇進行評測,而人工評價則針對文摘的內容選擇、語言質量和整體的反映度(綜合考慮面向話題的覆蓋度和流利度)進行評測。
TAC是多文檔文摘領域最有影響的國際評測會議,由美國國家技術標準局(national institute of standards and technology,NIST)主辦的DUC和TREC中的問答評測演化而來。TAC評測由美國IARPA(intelligence advanced research projects activity)資助,每年由NIST的信息技術研究室中的信息檢索組主辦,由來自政府、企業和學術界的顧問委員會監督。Update summarization評測面向英語,測試語料主要來自TREC中QA評測的AQUAINT-2數據集。
2 DMRM多文檔文摘模型
2.1 動態流形排序思想
經典流形排序主要用于數據點查詢問題中,即數據挖掘領域。其主要排序特征是查詢數據點,查詢數據點一般來說是靜態的,這是經典流形排序為靜態模型的原因。在動態多文檔文摘領域,其主要的排序特征是信息顯著性和信息新穎性。具體而言,信息顯著性包括的特征有:句子與所有其他句子相似度累加值特征;句子在文檔中的位置特征;句子的長度特征。信息新穎性包括的特征有:與歷史文摘的相似度值,相似度愈小,新穎性愈強;句子的時間特征。文中提出的動態流行排序模型主要使用這五個特征對句子加權,進行文摘內容的選擇和排序。
2.2 DMRM的算法流程
DMRM的算法流程如圖1所示。

圖1 DMRM的算法流程
2.3 DMRM的建立
2.3.1 句子相似度矩陣W
該模型的第一步為相似度矩陣的建立,用來度量句子集合中句子之間的相關性,是動態流行排序思想的基礎。相似度矩陣的建立過程也是為文檔集中的句子集建立帶權無向圖的過程。該矩陣的建立要依賴于兩句子之間的相似度算法,所以相似度算法的選擇至關重要。雖然該領域中已存在不少相似度算法,但是其在該模型中的應用效果均不佳。基于此,文中提出了基于TII的句子相似度計算算法,其算法公式如下:
(1)
其中,W為句子si和sj中的同現詞;Weight(w)=TF(w)*IDF(w)*ISF(w)為詞語W的權重,其中TF(w)表示詞語W的頻率,IDF(w)表示詞語W的反文檔頻率,ISF(w)表示詞語W的反句子頻率。此三值的統計范圍均為當前文檔集句子集合,其中IDF(w)=1/DF(w),DF(w)為整個文檔集合中包含詞W的文檔數,ISF(w)=1/SF(w),SF(w)為整個文檔集中包含詞W的句子數;length(si)和length(sj)分別表示si和sj的長度。
運用該相似度算法對文檔集句子集合中所有句子其相互之間的相似度值進行計算,即可建立相似度矩陣W。
2.3.2 句子顯著度向量A
動態流行排序模型的第二步為句子特征值的提取。定義向量A,其元素表示當前文檔集句子集合中相應句子與所有其他句子的相似度累加值,這個值是衡量句子重要性的一個特征。這種思想基于投票原理:句子集合中的句子之間具有關聯性,這種關聯性的強弱可通過其與其他句子間的相似度大小來體現,同時與其具有關聯性的句子數量同樣能體現出這種關聯性強弱。綜合考慮以上兩項因素,文中提出用句子間的相似度累加值作為衡量句子關聯性的參數,若某句子擁有相當大的關聯性度量值,即表示該句子所含信息的顯著度值很大,那么該句子將成為一重要的候選文摘句,因此該特征將成為候選文摘句選擇的一重要指標。計算某句子sent相似度累加值的公式如下:
(2)
其中,n表示當前文檔集中句子的總數;Sim(sent,si)可由式(1)的計算方法得到,表示句子sent和句子si之間的相似度。
運用該算法計算句子集合中所有句子的相應值,即可建立向量A。
2.3.3 句子冗余度向量B
向量B中的元素表示句子與歷史文摘中所有句子的相似度累加值,這個值是衡量句子信息新穎度的一個參數值。基于上述投票原理,句子與歷史文摘句子集合的相似度累加值愈大,該句子與歷史文摘中的句子具有的關聯性愈大,表明該句子包含更多冗余信息。在動態流形排序模型中使用此特征可過濾掉信息冗余度高的句子,這是動態流形排序模型動態性的表現之一。文中提出的計算公式如下:
(3)
其中,n表示歷史文摘中的句子總數;Sim(sent,si)同式(2)。
運用該公式計算當前文檔句子集合中所有句子的相應值,即可得到向量B。
2.3.4 動態特征選擇
(1)句子時間特征向量C的建立。
由于句子時間特征是文摘動態性的一個重要體現,因此系統融入了對其的考慮。直接考慮每個句子的時間特征涉及到時間短語的提取和歸一化,這是時序多文檔文摘的研究內容,考慮起來過于復雜,而且該系統的研究內容為動態多文檔文摘,與時序多文檔文摘有一定的區別,沒有必要考慮所有的時間短語。所以該系統將避開直接考慮句子級的時間特征,而從文檔集整體角度去考慮時間特征,這為問題的解決提供了方便。考慮到文檔集中各個文檔的出版時間有先有后,以及動態多文檔文摘具有動態演化特性,所以出版時間靠前的文檔具有小的新穎性,出版時間靠后的文摘具有大的新穎性。基于此原理,文中以文檔在文檔集合中出現的時間順序來衡量該文檔的新穎性,進而衡量該文檔中句子的新穎性。句子信息新穎性度量值計算公式如下:
Time_Weight(sent)=i
(4)
其中,Time_Weight(sent)為句子sent的時間特征權值;i為句子sent所屬文檔在文檔集中根據時間排序的排序值。
運用該公式即可計算當前文檔句子集合中所有句子的相應值,形成時間特征權重向量C。
(2)句子位置特征向量D的建立。
句子的位置特征對于多文檔文摘系統是不可或缺的。句子在文檔中的位置決定了其重要性,根據文章的規律,位置靠前和靠后的句子比在中間的句子具有更高的重要性,加入句子位置特征能使文摘系統具有更好的性能。所以文中在動態流形排序模型算法中加入句子的位置特征,其計算公式如下:
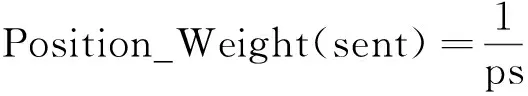
(5)
其中,Position_Weight(sent)表示句子sent的位置特征值;ps表示句子sent在所屬文檔中的位置值。
利用該公式即可計算當前文檔中所有句子的相應值,從而建立句子位置特征向量D。
(3)句子長度特征。
無論對于靜態多文檔文摘系統,還是動態多文檔文摘系統,句子長度特征都是必不可少的。若句子太短,則該句子不具有很高的重要性;若句子太長,即使重要,由于占用文摘的空間太大,也不利于文摘的效果的提高,因為在動態多文檔文摘中,文摘是有字數限制的。例如,TAC是國際上著名的文摘評測會議,其update summary任務是專門針對動態多文檔文摘評測的,其要求文摘字數在一百字以內,因而對句子長度的考慮是必須的。文中按如下方法使用該特征:當句子長度大于n1與小于n2時,考慮該句子;否則舍去。該模型算法中,設置n1為10,n2為25。在算法設計階段沒有用到句子長度特征,而在文摘句優選階段考慮句子長度特征,有助于動態流形排序算法的實現。
2.3.5 動態流形排序思想的核心
經典流形排序思想主要用于早期的數據點查詢問題,描述如下:令f表示一個排序函數,其賦予每一個節點xi一個排序值fi,如此,f可表示為一個向量f=[f1,f2,…,fn]T。同時,定義向量y=[y1,y2,…,yn]T,若xi是一個查詢,則令yi=1;否則,令yi=0。首先定義相鄰矩陣W={Wij|i,j=1,2,…,n},其中Wij表示從xi到xj的相似度。再定義另外一個矩陣S,其計算公式為S=D-1W,其中D為對角陣,其第(i,i)個元素等于W第i行之和,其他值均為0,矩陣S稱拉普拉斯矩陣,其值Sij即為從xi到xj的轉移概率。在矩陣拉普拉斯矩陣S的基礎上,句子x1,x2,…,xn的重要性權重f可由與之相鄰的其他句子推導出來。f的計算公式可以遞歸地表示為:
f(t+1)=α*S*f(t)+(1-β)*y
(6)
其中,α和1-α分別表示相鄰節點和初始的查詢數據點的排序值對當前排序值的相對貢獻。
分析經典流形排序模型算法可知,整個算法只使用了一個特征,即查詢數據點。因為對數據查詢問題就只依賴于這一個特征,所有元素的排序值都由此特征決定。動態多文檔文摘的目的是抽取最重要的指定數量的句子作為文檔集的文摘,其排序對象是當前文檔集的句子集合。由前面的分析可知,句子的重要性程度依賴于五個特征:與當前文檔集中句子集合的相似度累加值;與歷史文摘中句子集合的相似度累加值;句子的位置特征;句子的時間特征;句子的長度特征。由于動態流形排序算法暫不考慮句子的長度特征,故還有四個需考慮的特征,根據這四個特征建立了四個向量。其中句子與當前文檔集中句子集合相似度累加值向量A和句子位置特征向量D的加入意味著在句子排序值中加入了句子的信息顯著度;句子與歷史文摘中句子集合相似度累加值向量B和句子時間特征向量C的加入意味著在句子排序值中加入了信息新穎度,體現了該動態流形排序模型的動態性。
動態流形排序思想的核心-迭代計算句子的排序值向量f(t)受經典流形排序思想的啟發,文中提出的動態流行排序迭代算法公式為:
f(t+1)=α*S*f(t)+β*A-γ*B+η*C+λ*D
(7)
其中,f(t)和f(t+1)分別表示一次迭代前后的排序值;α為相鄰點對該句子排序值的貢獻;β為當前文檔集中與之相似的句子集合對該句子排序值的貢獻;γ為歷史文摘中與之相似的句子對該句子的懲罰;η為該句子時間特征對之排序值的貢獻;λ為句子位置特征對該句子排序值的貢獻。
該公式計算完成之后的f(t+1)的最終值記為向量f,其第i個元素為句子senti的權重,也就是Weigth(senti)。
由式(7)可知,該算法基于迭代算法,算法的迭代次數理所當然地會影響實驗結果。迭代次數過多,句子集合中的所有句子排序值差異將非常小,那么對后面的其他算法,很小的參數波動都會使得實驗結果有很大的差異性;評測語料的不同也會使實驗結果產生很大的差異性,使算法的穩定性變差。迭代次數過少,句子之間的關聯性所起的作用就相當小,達不到動態流形排序原本的目的。因此,迭代次數的確定也是算法的一個重要環節。
2.3.6 文摘句優選算法
動態流形排序的優點是考慮了句子之間的關聯性,使重要的句子之間互相推薦,使得抽取的文摘句都具有很高的重要性;缺點恰巧也在此,因為該算法導致抽取的句子都是相互之間有很高相似度的句子,用此句子集合形成的文摘具有很高的冗余性,使得文摘的概括面非常窄,導致結果不理想。若想通過此模型得到好的文摘,必須解決文摘句的優選問題。傳統的MMR文摘句優選算法,句子之間的相似度計算基于詞頻統計方法,由于該算法不能很好地計算句子之間的相似度,傳統的MMR文摘句優選算法的效果不佳。基于此,文中提出了一種新的文摘句優選算法,其計算公式如下:
New_Weight(sent)=α*Old_Weight(sent)-
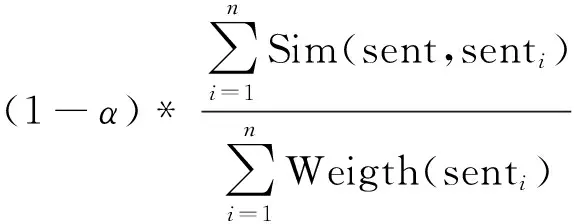
(8)
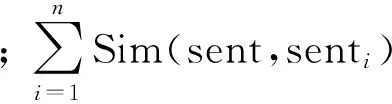
3 實 驗
3.1 實驗語料及評測方法
在TAC2008中,Update Summarization任務的測試語料由來自AQUAINT-2的48個話題組成,每個話題包含兩個時間片,且均由10個文檔組成。評價標準采用文摘評測領域著名的ROUGE工具,其中最主要的兩個指標ROUGE-2和ROUGE-SU4*是評價Update文摘的。
3.2 實驗結果及分析
迭代算法中的所有參數都影響系統的性能。不同的參數設置,相應的實驗結果差異性很大,因此針對文中提出的模型,測試了以下的參數設置。
做了三組實驗,第一組比較信息新穎度和信息顯著度對_DMRM的貢獻,第二組比較不同的迭代次數對_DMRM的影響,第三組比較DMRM性能與TAC2008 Update,分別如表1~3所示。
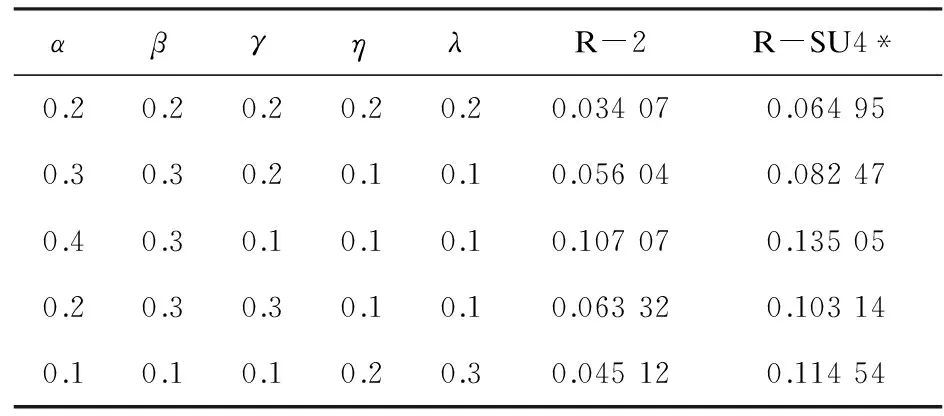
表1 不同參數設置的比較
從表1可以看出,當α=0.4,β=0.3,γ=0.1,η=0.1,λ=0.1時,文摘性能最好。最好效果出現在α=0.4的參數設置上,表明了句子集合中句子之間的關聯性對文摘句抽取影響很大,由得分可以看出動態流行排序在動態多文檔文摘領域中具有一定適用性。

表2 不同迭代次數的比較
從表2可以看出,當迭代次數為50時,ROUGE-2(R-2)和ROUGE-SU4(R-SU4)得分最高,即文摘性能最好,說明此模型的時間復雜度適中,系統運行起來速度較快。
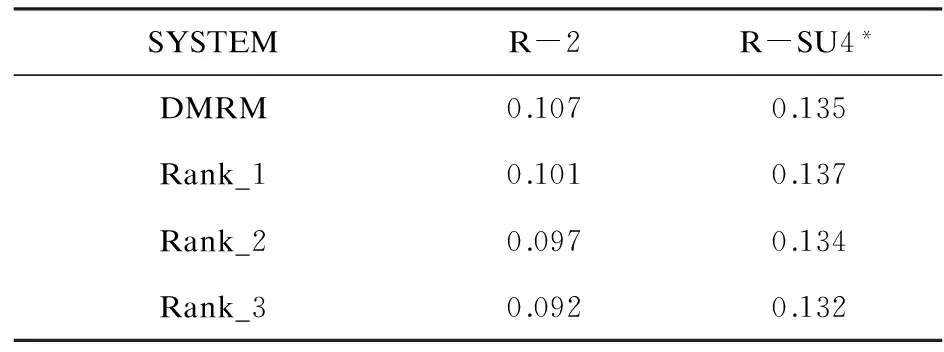
表3 與TAC2008發布結果的比較
TAC2008總共發布了73個系統分數,表3中列出了前三名系統的ROUGE-2和ROUGE-SU4打分,與此分數比較,本模型在TAC2008的發布結果中排名第1,說明動態流行排序模型很有潛力,是一種不錯的動態多文檔文摘建模方法。
綜上,在動態多文檔文摘領域,動態流行排序思想值得研究,是一種有效的動態多文檔文摘方法。
4 結束語
在認真研究國內外多文檔文摘領域最新發展的基礎上,創新性地對動態內容的演化關系進行了差異性分析。考慮到文摘句的信息新穎度和信息顯著度對文摘的重要性,運用流行排序思想整合信息新穎度和信息顯著度對句子集合中所有句子進行排序,根據排序值抽取句子形成文摘。同時融入對句子歷史信息特征的懲罰和時間特征的獎勵后,還能實現對文檔集所含信息動態演化性的建模,使文摘具有動態性,對于推動動態多文檔文摘領域的發展起到了一定的作用。下一步將是研究如何與其他模型更好地融合,使動態文摘具有更好的顯著性和新穎性。
[1] NENKOVA A,MASKEY S,LIU Y.Automatic summarization[C]//Proceedings of the 49th annual meeting of the association for computational linguistics.Stroudsburg,PA,USA:Association for Computational Linguistics,2001.
[2] ALLAN J,JIN H,RAJMAN M,et al.Topic-based novelty detection[R].Baltimore:Center for Language and Speech Processing,Johns Hopkins University,1999.
[3] TRIPATHY A,AGRAWAL A,RATH S K.Classification of sentimental reviews using machine learning techniques[C]//Proceedings of 3rd international conference on recent trends in computing.[s.l.]:[s.n.],2015:821-829.
[4] ALLAN J,PAPKA R,LAVRENKO V.On-line new event detection and tracking[C]//Proceedings of the 21st annual international ACM SIGIR conference on research and development in information retrieval.New York,NY,USA:ACM,1998:37-45.
[5] GILLICK D,FAVRE B.A scalable global model for summarization[C]//Proceedings of the workshop on integer linear programming for natural language processing.[s.l.]:[s.n.],2009:10-18.
[6] 張 瑾,許洪波.基于動態內容的文摘方法研究[C]//全國信息檢索與內容安全學術會議.出版地不詳:出版者不詳,2007.
[7] XIE X,LIU Y,LE W,et al.S-looper:automatic summarization for multipath string loops[C]//International symposium on software testing and analysis.New York,NY,USA:ACM,2015:188-198.
[8] SEUNG H,LEE D D.The manifold ways of perception[J].Science,2000,290(5500):2268-2269.
[9] 陳惠勇.流形概念的起源與發展[J].太原理工大學學報:社會科學版,2007,25(3):53-57.
[10] 徐 蓉,姜 峰,姚鴻勛.流形學習概述[J].智能系統學報,2006,1(1):44-51.
[11] NASTASE V.Topic-driven multi-document summarization with encyclopedic knowledge and spreading activation[C]//Conference on empirical methods in natural language processing.Stroudsburg,PA,USA:Association for Computational Linguistics, 2008:763-772.
[12] SILVEIRA S B,BRANCO A.Extracting multi-document summaries with a double clustering approach[M]//Natural language processing and information systems.Berlin:Springer,2012:70-81.
[13] LIN C Y,HOVY E.Automatic evaluation of summaries using n-gram cooccurrence statistics[C]//Proceedings of the 2003 conference of the North American chapter of the association for computational linguistics on human language technology.Stroudsburg,PA,USA:Association for Computational Linguistics,2003:71-78.
[14] FERREIRA R,CABRAL L D S,FREITAS F,et al.A multi-document summarization system based on statistics and linguistic treatment[J].Expert Systems with Applications,2014,41(13):5780-5787.
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
