日本面料企業(yè)推廣的重點(diǎn)面料
2022-04-15 19:08:52
紡織服裝周刊 2022年13期
關(guān)鍵詞:企業(yè)
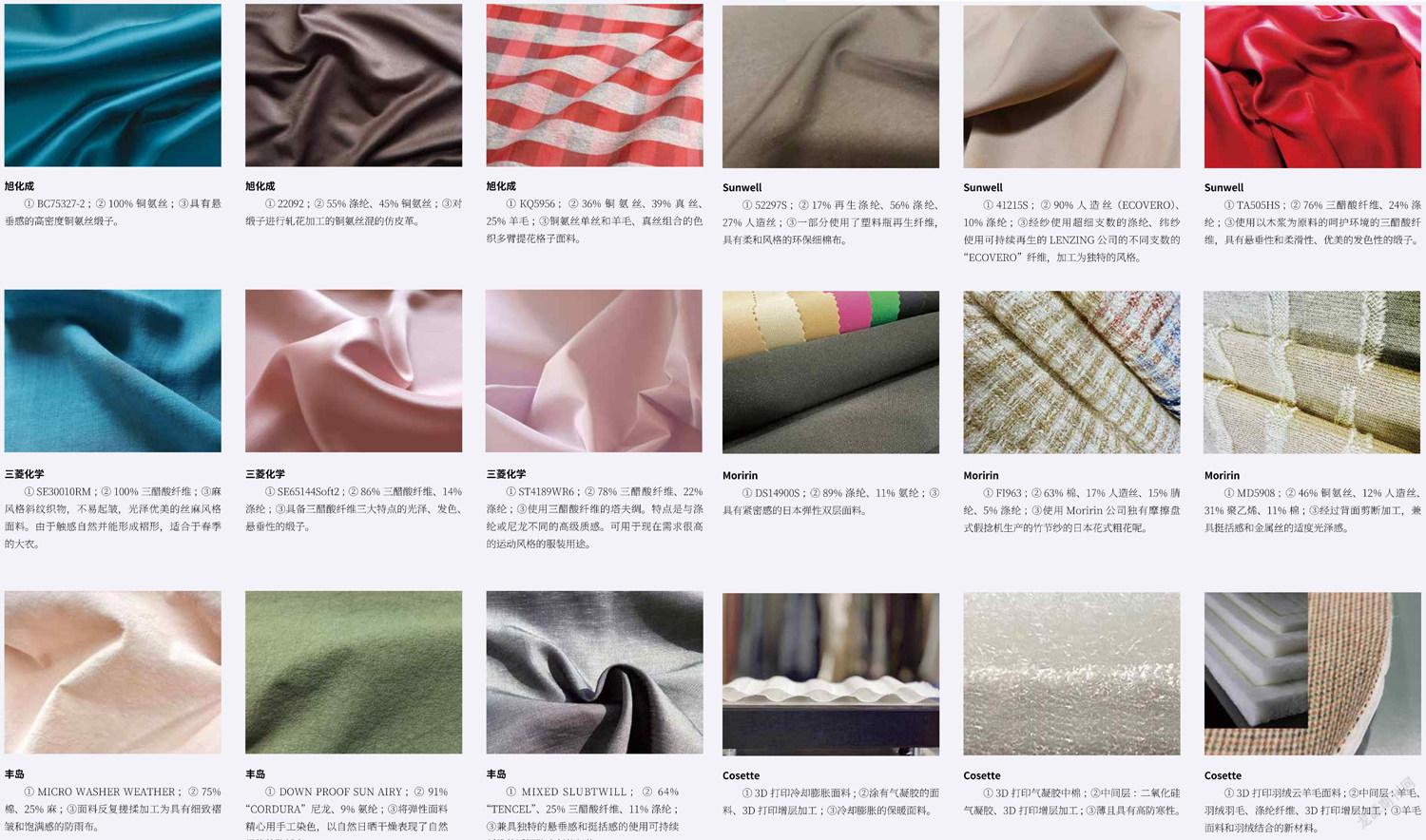
圖片說明:①商品名稱或型號;②材料;③特點(diǎn)。
猜你喜歡
當(dāng)代水產(chǎn)(2022年8期)2022-09-20 06:44:30
當(dāng)代水產(chǎn)(2022年6期)2022-06-29 01:11:44
當(dāng)代水產(chǎn)(2022年5期)2022-06-05 07:55:06
當(dāng)代水產(chǎn)(2022年4期)2022-06-05 07:53:30
當(dāng)代水產(chǎn)(2022年1期)2022-04-26 14:34:58
當(dāng)代水產(chǎn)(2022年3期)2022-04-26 14:27:04
當(dāng)代水產(chǎn)(2022年2期)2022-04-26 14:25:10
當(dāng)代水產(chǎn)(2021年5期)2021-07-21 07:32:44
當(dāng)代水產(chǎn)(2021年4期)2021-07-20 08:10:14
云南畫報(bào)(2020年9期)2020-10-27 02:03:26
