基于機器學習的日志解析系統設計與實現
2018-04-12 05:51:06郭淵博
計算機應用 2018年2期
關鍵詞:系統
鐘 雅,郭淵博
(1.信息工程大學 網絡空間安全學院,鄭州 450001; 2.數學工程與先進計算國家重點實驗室,鄭州 450001)(*通信作者電子郵箱1183316762@qq.com)
0 引言
為了保證系統與系統信息安全,日志幾乎內建于所有的系統中,它被用于記錄系統運行時產生的信息,如日常操作、網絡訪問、系統警告、系統錯誤等事件的相關屬性與信息。這些信息對了解系統的運行情況起著非常重要的作用,因此常用于異常檢測。隨著計算機系統規模與復雜性的增長,日志數量隨之增加,開發者或維護者能夠根據豐富的日志信息監視系統運行時的行為,并以此進一步跟蹤尋找系統異常問題的源頭;但是由于計算機系統龐大,并且大多數系統日志是非結構化的原始文本,當實際問題出現時,面對這些規模龐大的日志數據,測試者往往束手無策。如何在最短時間內高效又精準地對海量日志數據進行解析并提取有用信息成為一個亟待解決的重要問題[1]。
近年來,日志解析得到了越來越多的關注與快速發展[2]。在傳統的日志解析方法中,開發者通常根據自己的認知手動檢查系統問題或者創建正則表達式來定期維護,但是,這類方法對專家經驗知識依賴性強,通常不具備從歷史經驗中主動學習知識的能力,當新的格式日志出現時,解析規則很容易就變得過時,因此,靈活多變的自動日志解析方法成為一種需求。近些年,越來越多的研究者致力于對日志進行自動化解析。Nagappan等[3]提出了一種具有線性運行時間與空間的離線日志解析方法;Prewett[4]提出了一種基于規則的方法處理控制臺日志;薛文娟[5]提出了一種基于層次聚類的日志分析方法;馬文等[6]設計了一種基于頻繁模式增長(Frequent Pattern-Growth, FP-Growth)算法的安全日志分析系統。但是這些方法仍存在如下缺陷:1)只適用于嚴格的格式化、結構化日志,其性能嚴重依賴日志信息的格式與結構特征;2)依賴于源程序對日志文本的約束,適用性不強;3)日志格式的非結構性導致解析精度不高;4)對日志管理員要求較高,相關規則需要日志管理員預先寫成腳本,管理員需要對系統或者代碼有深刻的理解,否則難以寫出有效的腳本。
針對以上問題,主要有兩種主流日志解析方法:基于聚類的方法和基于啟發式的方法。基于聚類的日志解析方法以日志關鍵字提取(Log Keywords Extraction, LKE)和LogSig(Log Signature)為典型代表[7]。它們首先計算日志之間的距離,然后采用聚類技術組成不同的日志集群(簇),最后,事件模板從每一個集群(簇)中生成。基于啟發式的日志解析方法則以簡單日志聚類工具(Simple Log Clustering Tool, SLCT)為典型代表。每一個日志位置的每個項被計數,然后選擇出現頻繁的項來組成事件候選者,最后,候選者被選擇作為日志事件。以上兩種方法中,LKE方法因為其自身特點不能應用于數據量較大的處理任務中;SLCT雖然也能實現高解析精度,但是在系統異常問題檢測時,它處理的解析結果通常會帶來更多的錯誤警報。
本文主要結合LogSig算法相關理論知識,設計并開發了一個可從非結構原始日志文本中生成系統日志事件的日志解析系統。該系統包括原始數據預處理、日志解析、聚類分析評價和聚類結果散點圖顯示四大功能,系統處理的結果可轉換為日志數據挖掘任務與網絡入侵檢測所需的日志事件序列。該系統在VAST 2011挑戰賽的開源防火墻日志數據集上進行了測試,結果顯示其日志解析平均精度可達85%以上。實驗表明,對原始LogSig算法增加數據預處理步驟后,與原始LogSig算法相比,解析精度提高了60%;同時,通過與聚類結果評價模塊相結合,用戶能夠更加直觀地觀察本系統日志解析效率。
1 日志解析系統
1.1 日志解析
日志是由不變部分與可變部分組成的純文本,大多數系統日志是非結構化的原始文本。日志解析的主要目的是把原始日志文本中的不變部分從可變部分分離出來并形成一個良好的結構化日志事件。圖1為日志解析的一個實例。

圖1 日志解析實例Fig. 1 Example of log parsing
1.2 聚類分析
聚類分析又稱群分析,是一種無監督學習方法。它按照事物的某種屬性,將一組樣本對象劃分成簇,使簇內樣本對象具有盡可能高的相似性,而簇間對象具有盡可能小的相似性。其主要目的是將若干無標記對象進行劃分,使之成為有意義的聚類。聚類分析預先不知道目標數據集存在多少類,需要以某種距離度量為基礎,對所有的對象進行聚類,使得同一聚類之間距離最小,而不同聚類之間距離最大。聚類分析可在幾乎無任何相關數據先驗信息可用的情況下分析數據點的內在關系以作進一步研究。如圖2中以二維空間的來表示樣本對象,圖2(a)表示的是一組輸出對象,圖2(b)則是所期望的聚類。

圖2 聚類示例Fig. 2 Example of clustering
1.3 聚類結果評估
聚類評價包括聚類過程評價和聚類結果評價兩個方面。前者主要考察聚類算法的屬性,后者只需要考慮給定的聚類結果是否合理與有效。一般比較常見的聚類結果評價(聚類評價指標)分為外部度量、內部度量和相對度量三大類。內部度量利用數據集的固有特征和量值來評價聚類算法結果,通常用于數據集結構未知、無標簽的聚類評價;相對度量側重于聚類算法的有效性。本文中數據集結構已知,且側重聚類算法的精度,故采用外部度量作為聚類評價指標。外部度量假設聚類算法的結果是基于一種人工預先指定的結構,這種結構反映了人們對數據聚類結構的一種直觀認識,對每個數據項進行人工標注,聚類結果與人工越吻合越好。外部度量的常用指標有F_measure和Rand index。
1.4 LogSig日志解析算法
LogSig日志解析算法由Tang等[7]提出,其目的主要是選取文本日志信息中具有代表性的簽名組成系統事件模板,進而將日志分成不同類。算法能處理各種類型的日志數據,并實現較高的解析精度。
2 日志解析系統設計
基于規則匹配的方法是最常見的日志解析方法[8-9],操作者主要通過正則表達式從日志中提取模式,而后對抽取模式進行簡單的分類。此類系統維護較為困難,但相比傳統文本模式,它在一定程度上提高了解析效率與精度。研究發現,LogSig算法并沒有明確原始日志文本的處理,這樣導致日志項對生成與遍歷日志項對的時間開銷較大;同時,日志信息中個別無關日志項會影響日志分類,降低日志解析精度。
因此,本文考慮將模式匹配與LogSig算法相結合,在其基礎上基于機器學習原理進行擴展,改進日志解析算法,增加數據預處理功能和聚類結果評價,并設計開發了一個日志解析系統。為了便于用戶使用與后期維護,該系統分為原始數據預處理模塊、日志解析模塊、聚類結果評價模塊和聚類結果散點圖模塊,它們的主要功能如下:
1)數據預處理模塊主要對原始日志數據進行相關處理以提高解析效率與精度;
2)日志解析模塊主要實現LogSig算法,完成日志項對生成、日志聚類和日志模板生成;
3)聚類結果評價模塊則利用聚類的評估指標精度(Precision)、F_measure、Rand index對本系統功能進行評估;
4)聚類結果散點圖模塊則采用散點圖形式直觀反映日志解析的外部度量參數。
2.1 數據預處理模塊
數據預處理是數據挖掘前的準備工作,它既能保證挖掘數據的有效性和正確性,又能通過對數據格式和內容進行調整,從而使數據更符合挖掘的需要[10]。其主要任務是根據背景知識中的約束性規則對數據進行檢查,通過清理和歸納等操作,生成供數據挖掘算法使用的目標數據。
隨著存儲技術的發展,收集到的日志與實際有效日志之間的矛盾日漸突出;同時,未處理的原始日志必然導致日志解析代價增加,因此,本文將數據預處理與LogSig算法相結合。數據預處理模塊是提高解析精度的關鍵,也是本文系統的創新點。
2.1.1位置固定無關項的去除
原始日志數據中通常有一些固定不變的項,且它們在每條日志中出現的位置一樣,如日志數據集中代表日志產生日期的2011- 04- 14;或者雖然變化,但是屬性一樣,如08:00:00與08:00:06雖然不同但都是時間。這些項不僅對日志分類沒有幫助,而且會造成代價的增加。
2.1.2位置不定無關項的去除
日志中還有一些項,它們的屬性一樣,但是出現位置并不固定,因此不能通過去除位置固定無關項的方法去除,如IP地址、端口號等。所以,本文考慮通過拆分每一條日志,利用匹配子串的原理采用正則表達式來去除。
2.2 日志解析模塊
日志解析模塊是本系統的核心部分,也是主要難點。一個好的同類事件評判標準往往能達到一個好的聚類結果。該模塊采用具體函數值作為評判劃分同一類事件的衡量標準,通過不斷迭代提高分類精確度。基本步驟包括項對的生成、日志聚類以及日志事件模板的生成。
2.2.1項對的生成
日志以空格為拆分符可拆分成N個字符串,每一個字符串為日志的一個項,每兩個項組成一個項對,一條日志的所有項對為第1項依次與后面的第2,3,…,N項組合為N-1個項對(1,2)、(1,3)、(1,4)、…、(1,N),第2項依次與后面的第3,4,…,N項組合為N-2個項對(2,3)、(2,4)、(2,5)、…、(2,N),……,第N-1項與后面的第N項組合為1個項對(N-1,N)。
將每條日志信息轉換成多組項對。具體來說,基于預處理部分每條日志,文中采用遍歷方式,日志中每兩個項組成一個項對。
2.2.2日志聚類
日志聚類是日志解析的核心步驟。聚類的目的是將原始日志文本中同一類日志事件分為一類,從而用一個日志事件模板來描述它。查閱相關文獻發現,機器學習中聚類方法的中心思想能滿足本文研究的需求(詳見本文1.2節)。根據聚類算法原理,首先將原始日志分成k組,然后基于日志的項對,計算每條日志從一個組到另一個消息組后的潛在函數的值,其計算公式為:
(1)
其中:在日志文本C中,對于一個項對r∈R(C),N(r,C)指的是C中包含項對r的日志數量,p(r,C)=N(r,C)/|C|表示在C中含有項對r的日志部分所占比率。
通過比較當前日志移動前后潛在函數的值以確定日志是否移動,若函數值增大,則更新日志分組消息,通過不斷迭代,選擇更大的潛在函數值,直到最后一次迭代中,沒有任何一條日志有日志潛在值的增加,則可將當前分組確定為日志事件歸類的最終分組。
2.2.3日志事件模板生成
消息簽名是在每組中每條日志都具有高匹配得分的序列項。日志事件模板生成操作中,首先需要構建日志信息簽名。具體實現方法為:保存日志信息劃分組中每條日志每個項出現的頻率,選擇每組中出現次數超過一半的項作為候選項,即消息簽名;然后,將每條日志中含有的候選項組成日志事件候選,每組中出現頻率最高的日志事件候選為當前組的最終日志事件模板輸出。
2.3 聚類結果評價模塊
聚類的典型形式化目標函數是為了實現高的集群(簇)內相似性(群(簇)內的文件是相似的)和低的集群(簇)間相似性(不同集群的文件不一樣)。這是聚類質量的一個內部標準,但良好的內部標準分數并不一定是轉化成應用中良好效果的必要條件。內部標準的另一種選擇是直接評估應用程序的利益。最直接的聚類搜索結果評估方法就是衡量用戶采用不同聚類算法找到答案所花費的時間,但它的花費很大,特別是在需要大量研究時更為突出。
因此,在聚類結果評價模塊采用外部度量作為聚類評價指標,這里主要選取:準確率(Precision)、綜合評價標準F_measure和Rand index。本文實驗中通過運行程序50次來避免聚類自身性質帶來的誤差。
2.3.1Precision
準確率是檢索出的相應文檔占檢索出的總文檔數量的比率,衡量的是系統的查準性。采用信息檢索與統計學分類的準確率與召回率(Recall)思想,數據所屬的類t可以看作集合Nt中等待查詢的項,Nk是簇Ck的大小,Ntk是簇中類t的數量[11]。對于類t與簇Ck的準確率計算公式如下:
Precision(t,Ck)=Ntk/Nk
(2)
結合本文研究的任務要求,此處將其轉化為:
Precision=TP/(TP+FP)
(3)
其中:TP(True Positive)為被正確劃分正例的個數,即兩個相似樣本劃分到同一集群(簇);FP(False Positive)為被錯誤劃分為正例的個數,即兩個不同樣本劃分到同一集群(簇)。
2.3.2F_measure
簇索引與統計任務中,準確率與召回率越高越好,但是兩者通常情況下是相互矛盾的,這就需要綜合考慮它們,最常見的方法就是F_measure,它是Precision與Recall的加權調和平均[12]。其計算公式如下:
(4)
其中Recall的計算公式為:
Recall(t,Ck)=Ntk/Nk
(5)
同樣按任務要求可轉換為:
Recall=TP/(TP+FN)
(6)
其中,FN(False Negatives)為被錯誤劃分為負例的個數即兩個相同樣本劃分到不同集群(簇)。
2.3.3Rand index
Rand index[13]通常用來衡量聚類結果與樣本數據外部標準類之間的一致程度,其計算公式如下:
Rand_index=(TP+TN)/(TP+FP+TN+FN)
(7)
其中,TN(True Negatives)為被正確劃分為負例的個數,即兩個不同樣本劃分到不同集群(簇)。Rand_index范圍為[0,1],其數值越大,代表兩種劃分的一致性越高,聚類準確性越高,聚類結果與真實情況越吻合。
2.4 聚類結果散點圖模塊
為了更加直觀地展示系統對日志解析任務的解析精度,本文設計了聚類結果散點圖模塊。該模塊主要調用python matplotlib模塊相關函數來顯示解析后的Precision、F-measure與Rand index的散點圖,X軸為當前實驗次數,Y軸為本次實驗的Precision、F-measure與Rand index。
3 系統測試
本章主要對系統結果進行定向分析,采用anaconda運行系統,利用VAST 2011挑戰賽的開源防火墻日志數據集分析數據預處理部分的劃分簇數、正則表達式對日志解析精度的影響。
3.1 平均解析精度
實驗分別采用包含400,800,1 200條日志的三個樣本數據進行實驗,測量50次解析任務后的平均Precision、F_measure以及Rand index,結果如圖3和表1所示。
圖3顯示,在本組實驗中,聚類評價值數據較為集中,且基本都在85%以上。表1數據顯示,不管日志數量大小,無論是使用分類指標Precision還是聚類指標F_measure、Rand index衡量,日志解析系統50次實驗的平均解析精度均能達到90%以上。
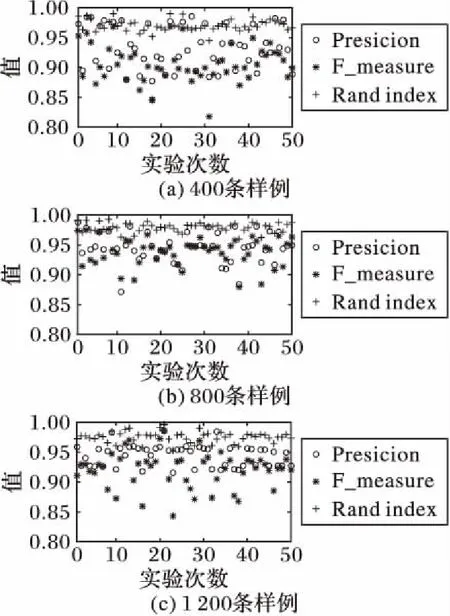
圖3 不同日志數量樣例實驗結果Fig. 3 Experimental results of different number of log samples

表1 50次實驗的平均日志解析準確率 %Tab. 1 Average log parsing accuracy of fifty experiments %
3.2 劃分簇數對聚類結果的影響
劃分簇的大小決定最終日志事件模板的個數,本文通過分析真實事件個數為14的400條日志樣例,分別設置明顯少于真實事件個數(6)、明顯高于真實事件個數(26)以及接近真實事件個數(16)的劃分簇數,而其他參數項相同來研究劃分簇數對解析精度F_measure、Precision、Rand index的影響。表2為不同劃分簇下的平均評價。
表2數據顯示,劃分簇數會影響日志解析精度,尤其是當事件個數明顯小于真實事件個數時,日志解析精度相比接近事件真實值的劃分簇數,其三項指標Precision、F_measure、Rand index都有明顯降低。日志事件明顯大于真實日志事件個數時,日志的解析精度相比接近事件真實值的劃分簇數的精度Precision有些許升高,這是因為隨著日志事件個數的增加,同一類事件分到同一個劃分簇的幾率加大;但是其F_measure、Rand index都有所降低,總體而言三項指標差距不是很大。通過比較解析運行時間發現,劃分簇數為26時,其平均運行時間為劃分簇數為16時運行時間的1.4倍。這是因為當日志事件個數增加時,其用于日志聚類過程的花費將相應增加。所以,綜合以上結果,劃分簇數接近真實事件個數時能得到最好的實驗效果。
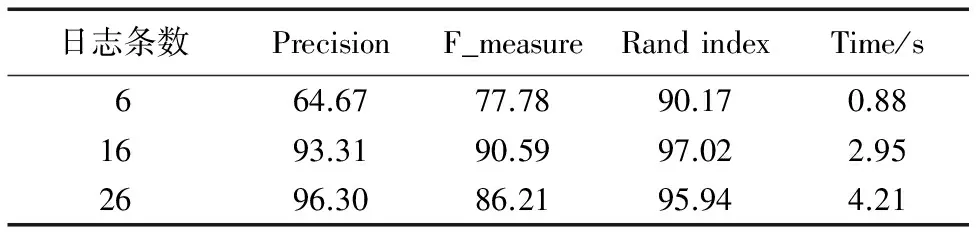
表2 不同劃分簇數對日志聚類結果的影響 %Tab. 2 Impact of different cluster numbers on log clustering results %
3.3 正則表達式對聚類結果的影響
正則表達式是數據預處理部分最關鍵的一個步驟,通過分析有無正則表達式對400條日志樣例解析任務的F_measure、Precision、Rand index的影響來進行討論。表3為有無正則表達式以及正則表達式是否合適的實驗結果。從表3實驗結果來看,數據預處理過程中正則表達式的選擇至關重要,不應該選擇日志中的敏感詞作為正則表達式匹配的對象,而應該選擇與其無關的詞作為匹配規則匹配對象,這樣才能達到顯著提高解析精度的目的。
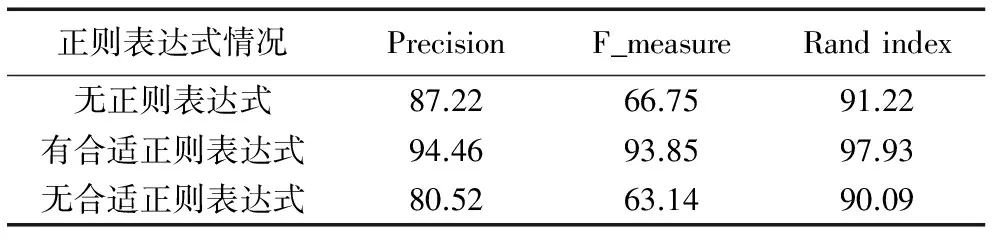
表3 有無正則表達式對日志聚類結果的影響 %Tab. 3 Impact on log clustering results with or without regular expression %
3.4 日志大小對解析時間的影響
最后,通過對比100,101,102,103,104,105KB大小日志數據的解析運行時間來討論日志大小對本文系統運行時間的影響,結果如圖4所示。從圖4可以看出,日志解析運行時間隨著日志大小的增加而增加,并且增長幅度逐漸增加,這主要是因為日志大小影響聚類的時間復雜度。這也為本文系統的后期優化提供了一個方向。
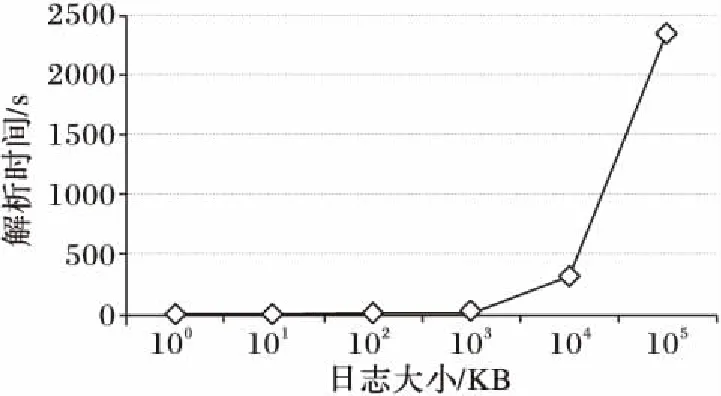
圖4 日志大小對日志解析運行時間的影響Fig. 4 Impact of log size on parsing runtime
3.5 本文算法與原始LogSig算法對比
原始LogSig算法沒有明確提出預處理部分的具體設計,本文采用真實事件個數為14的400條日志樣例,通過設置有無、預處理部分的日志解析任務來進行對比,結果如表4所示。由表4可以看出,通過關聯規則與LogSig相結合,本文系統比原LogSig算法的各項指標值都有所提高,綜合評價參數F_measure提高了60%;同時,系統運行時間大大減少,僅為原先的25%,提高了解析效率。

表4 本文系統與原始LogSig算法對比Tab. 4 Comparsion of the proposed algorithm and original LogSig algorithm
4 結語
計算機系統的發展、日志數量的增加以及日志在各類數據挖掘任務中起到的作用使得自動化日志解析成為一種必然趨勢[14]。目前,日志的處理方式多種多樣,但是缺乏一個系統性的處理平臺。本文主要設計開發了一個日志解析系統,它能高效快速地從日志文本中解析出日志事件,系統實現了原始數據預處理、日志解析、聚類分析評價和聚類結果散點圖顯示四大功能,集數據處理與結果分析于一體,提供了更好的用戶體驗。通過VAST 2011挑戰賽的開源防火墻日志數據集驗證了系統的可行性,并分析了數據預處理部分的劃分簇數、正則表達式對日志解析精度的影響。實驗中也發現,日志大小會影響聚類的時間復雜度,因此在接下來的工作中可考慮實現程序運行的并行性等。目前該系統聚類的簇數是基于小型數據集實驗得到的,后續研究可以考慮結合自適應的聚類算法以提高系統性能。
參考文獻(References)
[1]張宏鑫,盛風帆,徐沛原,等.基于移動終端日志數據的人群特征可視化[J].軟件學報,2016,27(5):1174-1187. (ZHANG H X, SHENG F F, XU P Y, et al. Visualizing user characteristics based on mobile device log data [J]. Journal of Software, 2016, 27(5): 1174-1187.)
[2]廖湘科,李姍姍,董威,等.大規模軟件系統日志研究綜述[J].軟件學報,2016,27(8):1934-1947. (LIAO X K, LI S S, DONG W, et al. Survey on log research of large scale software system [J]. Journal of Software, 2016, 27(8): 1934-1947.)
[3]NAGAPPAN M, WU K, VOUK M A. Efficiently extracting operational profiles from execution logs using suffix arrays [C]// Proceedings of the 2009 International Symposium on Software Reliability Engineering. Piscataway, NJ: IEEE, 2009: 41-50.
[4]PREWETT J E. Analyzing cluster log files using Logsurfer [C]// Proceedings of the 4th Annual Linux Showcase & Conference. Atlanta: [s.n.], 2003: 169-176.
[5]薛文娟.基于層次聚類的日志分析技術研究[D].濟南:山東師范大學,2013. (XUE W J. Research on log analysis technology based on hierarchical clustering [D]. Jinan: Shandong Normal University, 2013.)
[6]馬文,朱志祥,吳晨,等.基于FP-Growth算法的安全日志分析系統[J].電子科技,2016,29(9):94-97. (MA W, ZHU Z X, WU C, et al. Security log analysis system based on FP-Growth algorithm [J]. Electronics Technology, 2016, 29(9): 94-97.)
[7]TANG L, LI T, PERNG C S. LogSig: generating system events from raw textual logs [C]// Proceedings of the 2011 ACM International Conference on Information and Knowledge Management. New York: ACM, 2011: 785-794.
[8]XU W, HUANG L, FOX A, et al. Detecting large-scale system problems by mining console logs [C]// SOSP 2009: Proceedings of the 2009 ACM Symposium on Operating Systems Principles. New York: ACM, 2009: 117-132.
[9]周平,馬斌,韓冰,等.基于大數據平臺的日志分析預警技術研究[J].電腦知識與技術,2016,12(32):266-268. (ZHOU P, MA B, HAN B, et al. Research on log analysis and early warning technology based on large data platform [J]. Computer Knowledge and Technology, 2016, 12(32): 266-268.)
[10]袁漢寧,王樹良,程永,等.數據倉庫與數據挖掘[M].北京:人民郵電出版社,2015. (YUAN H N, WANG S L, CHENG Y, et al. Data Warehouse and Data Mining [M]. Beijing: People’s Posts and Telecommunications Press, 2015: 31-34.)
[11]張惟皎,劉春煌,李芳玉.聚類質量的評價方法[J].計算機工程,2005,30(20):10-12. (ZHANG W J, LIU C H, LI F Y. Evaluation method of clustering quality [J]. Computer Engineering, 2005, 30(20): 10-12.)
[12]向培素.兩種聚類有效性評價指標的Matlab實現[J].西南民族大學學報(自然科學版),2013,30(6):1002-1005. (XIANG P S. Matlab implementation of two cluster validity evaluation indexes [J]. Journal of Southwest Nationalities University (Natural Science Edition), 2013, 30(6): 1002-1005.
[13]周開樂,楊善林,丁帥,等.聚類有效性研究綜述[J].系統工程理論與實踐,2014,34(9):2417-2431. (ZHOU K L,YANG S L, DING S, et al. Research on clustering validity [J]. System Engineering — Theory & Practice, 2014, 34(9): 2417-2431.)
[14]趙慶永.基于數據挖掘算法的日志分析系統的設計與實現[D].青島:青島大學,2009. (ZHAO Q Y. Design and implementation of log analysis system based on data mining algorithm [D]. Qingdao: Qingdao University, 2009.)
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
