基于多視角缺失補全算法的數據挖掘研究
2018-04-13 08:28:04黃裕
計算技術與自動化 2018年2期
關鍵詞:機器學習
黃裕


摘要:針對數字化信息復雜度帶來的海量多視角數據問題,并考慮到在大量的多視角數據的獲取過程中,由于收集的難度、高額成本或設備故障等情況,往往會導致多視角數據出現視角缺失。提出了一種基于核回歸的多視角數據缺失補全方法,采用離線核回歸模型學習和在線多視角缺失數據補全構建了算法框架,通過引入高斯核核函數的方式,建立視角間的非線性回歸模型,結合訓練數據的線性組合來表示回歸系數的最優解,以完成挖掘多視角數據間的互補相關性,有效實現缺失視角的補全。最后通過模擬三類數據集來驗證基于多視角缺失補全算法的性能。
關鍵詞:機器學習;多視角數據;視角缺失;核回歸;核函數
中圖分類號:TP391.6
文獻標識碼:A
0 引言
近年來,隨著在圖像、醫療保健、社交網絡、傳感器網絡、多感知設備等數字化信息建設的快速發展,多視角數據(Multi-view Data)[1]的產生和收集變得更加方便和容易。所謂多視角數據是指[2],對于同一個語義對象,從不同角度、層面觀察可以形成不同視角的數據、不同維度的特征集,或從多個源頭得到的數據集。例如:醫學診療中,可以利用核磁共振(MRD、正電子成像技術(PED、或其它生物標記(如CSD對阿茲海默病(Alzheimer)進行綜合診斷、對數字圖像利用不同技術手段提取的多種特征等等[3]。研究如何合理利用針對同一對象廣泛存在的多個視角信息,實現對由多視角所刻畫的對象的深度分析與理解,已成為當前機器學習領域的研究熱點[4]。這類以面向多視角數據為研究對象的機器學習方法目前己被普遍接受為一種新的學習方式,即多視角學習(Multi-view-Leaming,MVD[5]。
在面臨著多視角數據視角全部屬性缺失時,簡單地將不同視角串聯,利用傳統單視角數據缺失補全方法進行補全,并沒有從多視角數據間具有的互補性考慮。通常多視角數據能夠對同一個語義對象進行細致的描述,其本質在于多視角數據間具有較強的互補信息。由此挖掘多視角數據間的互補性,有利于提高對語義對象的理解。由于不同視角數據橫跨異構空間,視角間并沒有顯示的對應關系,為此本文提出了一種基于核回歸的多視角數據缺失補全方法,該方法通過引入核函數,建立視角間的非線性回歸模型,挖掘多視角數據間的互補相關性,有效實現缺失視角的補全。
1 算法框架
圖l所示為本文提出的基于核回歸的多視角數據缺失補全框架圖。其主要由兩部分組成:
(1)離線核回歸模型學習:針對多視角訓練訓練樣本X與Y,通過核函數,建立多視角數據視角間非線性回歸模型,獲得最優回歸系數W*。
(2)在線多視角缺失數據補全:針對多視角缺失數據{x,yα},基于上述離線所建立的核回歸模型,實現多視角缺失數據的補全。
2 多視角數據缺失補全的核回歸
2.1 核方法
在離線核回歸模型學習中,需通過核方法建立多視角數據間的非線性回歸模型,實現缺失視角數據的補全,在此本文首先介紹核方法。
核方法(Kernel Method)[6]是解決非線性模式分析問題的一種有效途徑,其核心思想是:首先,通過某種非線性映射函數φ將原始數據x嵌入到合適的高維特征空間H;然后,利用通用的線性學習器[7]在這個新的高維特征空間中分析和處理模式。此時這個高維特征空間中的線性學習器相當于原空間是非線性的,即對原空間中的數據進行了非線性分析和處理。
而通常在處理非線性問題過程中的一項關鍵技術是核技巧(Kernel Trick)[8],即將輸入樣本對在高維特征空間內的點積運算可替換成關于輸入樣本對的函數k(x(i),y(i)),這里的函數k(x(i),y(i))就
2.2 模型學習
由于視角yc屬性值完全缺失時,簡單地將不同視角串聯,利用傳統單視角數據缺失補全方法進行補全,并沒有從多視角數據間具有的互補性考慮。同時由于不同視角數據橫跨異構空間,多視角數據并沒有顯示的對應關系,為此,本文引入核函數建立視角間非線性關系模型[12]。其模型的核函數本質上描述了同一語義對象橫跨異構空間內數據的互補相關性。
3 實驗結果與分析
3.1 數據集說明
采用NASA數據集、電影評分數據集和路透社(Reuters)數據集來驗證基于核回歸的多視角數據缺失補全方法的性能。
3.1.1 NASA數據集
該數據庫是美國宇航局蘭利研究中心大氣科學數據中心所提供[14]。該數據集是通過衛星采集整理的中美洲區域(由24×24經緯度網格所覆蓋的區域)的氣象數據,包括溫度(表面和空氣),臭氧,空氣壓力和云量(低,中和高)等7個指標的觀察值,其中上述觀測數據均為1995年1月至2000年12月的每月平均值,一共72條氣象記錄。如表l所示,本文選取同一經度(113.8W)下的兩個不同緯度(36.2N、33.8N)所采集的數據構成多視角數據集NASA_W驗證本文基于核回歸視角缺失補全算法的補全性能。
3.1.2 電影評分數據集
該數據集是由業內專業人士和觀眾分別對30個電視節目所作的平均評分數據庫[15]。觀眾評分來自低學歷、高學歷和網絡調查三種,而業內專業人士評分來自包括演員和導演在內的藝術家、發行與業內各部門主管三種。如表2所示,針對該數據庫,本文選取觀眾評分作為視角X,專家評分作為視角Y來構造Movie_l多視角數據集驗證本文基于核回歸視角缺失補全算法的補全性能。
3.1.3路透社數據集
路透社(Reuters)數據庫是1987年路透通訊社的文檔數據集,包含135個類別,一共21578個文檔,對每個文檔分別提取96維和100維的特征數據形成兩個視角的描述。本文選取其中10類共7757個文檔進行實驗,如表3所示,本文通過兩個特征數據集構造多視角數據集Reuters_l驗證本文基于核回歸視角缺失補全算法的補全性能。
3.3 多視角缺失數據補全性能分析
3.3.1 NASA數據集的視角缺失補全性能分析
針對NASA時間序列數據集所構造的多視角數據集NASAW,從時間序列樣本中選擇整個時間段的前800/0的樣本作為訓練集,后20%的樣本作為測試集,記為[80%,20%]。同理,還可構造[85%,15%]、[90%,10%]、[95%,5%]、[98%,2%]等實驗數據進行補全實驗。
為驗證基于核回歸的多視角數據缺失補全性能,本章設置測試樣本{x,yc)的視角數據為完全缺失,即缺失視角缺失部分的比例設為(s -l)/s=100%。
從圖2中可以看出,與其他的算法相比,本文基于核回歸的多視角數據缺失補全算法取得最優補全性能,證明了利用多視角數據視角間的互補相關性可有效提高數據缺失補全性能。
3.3.2 電影評分數據集的視角缺失補全性能分析
針對電影評分數據庫所構造的多視角數據集Movie_ 1,從樣本中隨機選擇70%的樣本作為訓練集,剩余30%的樣本作為測試集,即[70%,30%]。同時,本實驗還構造[80%,20%]、[90%,10%]等實驗數據進行實驗。
在電影評分數據庫構造的多視角數據集Movie l上,不同算法在缺失視角缺失部分的比例為(s - l)/s=100%的補全性能對比如圖3所示。
從圖3中可看出本文基于核回歸視角缺失補全算法的明顯優勢,證明非線性模型可有效捕捉多視角數據間的相關互補性,可進一步增強數據缺失補全性能。
3.3.3 路透社數據集的視角缺失補全性能分析
針對路透社數據庫所構造的多視角數據集Reuters_l,本實驗構造[70%,30%、[80%,20%]、[90%,10%]等實驗數據進行實驗。
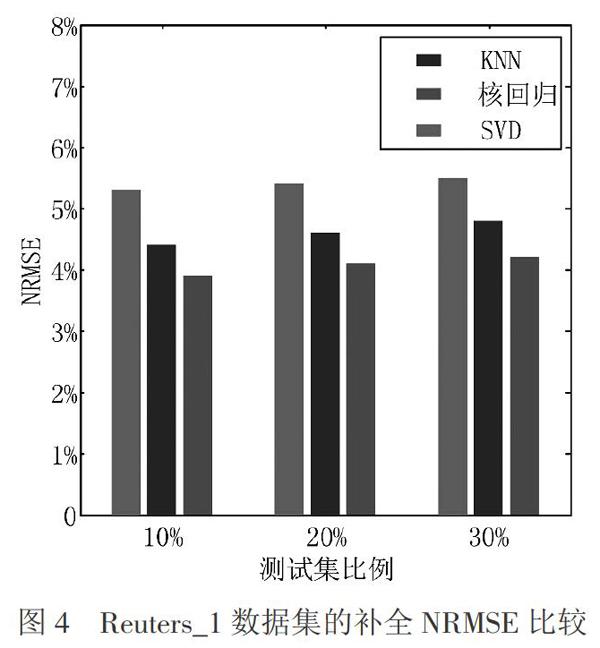
在路透社數據庫構造的多視角數據集Reuters 1上,不同算法在缺失視角缺失部分的比例為(s -l)/s=100%的補全性能對比如圖4所示。
從圖4中可以看出本文提出的基于核回歸的多視角數據缺失補全算法的補全性能優于其他方法,這也間接證明傳統的單視角數據缺失補全方法并不能很好地處理多視角缺失數據問題。
從上述針對NASA數據集、電影評分數據集以及路透社數據集視角缺失補全的實驗可以看出,本文基于核回歸補全算法明顯優于其他算法的補全性能。由于多視角數據間的異構性,使得多視角數據間的近鄰不具有可逆性,使得KNN方法的補全性能較差。在SVD缺失數據補全中,由于奇異值分解需要完整的矩陣,因此在補全缺失數據時,需對矩陣缺失的元素預填充為0值,進而通過矩陣分解實現缺失數據的補全,然而,這時補全的值更為接近0值,使得補全的性能較差。在NMF缺失數據補全中,由于進行非負矩陣分解,要求矩陣的元素均為非負數值,因此針對含有負值數據的數據集,例如路透社數據庫,該方法將無法進行;同時,針對視角數據完全缺失時,由于多視角數據視角間的異構性,簡單的將視角串聯并分解補全,最終導致補全性能較差。和其他單視角補全方法相比,本文基于核回歸的多視角數據缺失補全算法通過利用多視角數據間的互補性建立非線性回歸模型有效增強補全性能。本文基于核回歸補全算法針對時間序列數據庫,還可通過對未來時刻的缺失數據補全進行預測,例如在NASA數據庫上的補全實驗。
3.4 模型參數的影響
本文基于核回歸的多視角數據缺失補全實驗主要由以下參數影響補全性能:核回歸的正則參數A、高斯核函數的寬度σ。
以NASA_W多視角數據集為例,在基于核回歸補全的實驗中,當高斯核函數寬度σ=5時,回歸正則參數λ對補全性能的影響如圖2所示。當回歸正則參數λ= 0.1時,高斯核函數寬度σ對補全性能的影響如圖5所示。
圖5表明,λ取值在0.1左右時,取得最優補全性能。當λ取值過大或過小時都會降低核回歸補全算法的性能。圖6表明,σ取值在5左右時,取得最優補全性能,若σ取值過大或過小會導致補全性能較差。
4 結論
針對視角完全缺失的多視角數據,提出了基于核回歸的多視角數據缺失補全方法。方法通過引入核函數,建立視角間的非線性回歸模型,挖掘多視角數據間的互補相關性,有效實現缺失視角的補全。
參考文獻
[1]馮昌,廖士中,大規模核方法的隨機假設空間方法[J],計算機科學與探索,2017,(03):1-9.
[2]劉正,張國印,陳志遠,基于特征加權和非負矩陣分解的多視角聚類算法[J].電子學報,2016,(03):535-540.
[3]劉望舒,陳翔,顧慶,等,一種面向軟件缺陷預測的可容忍噪聲的特征選擇框架[J].計算機學報,2016,(39):1-16.
[4]楊金鴻,鄧廷權.基于距離度量學習的半監督多視角譜聚類算法[J].四川大學學報:工程科學版,2016,(ol):146-151.
[5]孫瑞麗,陳盛雙,李石君,改進SVM算法的電商行業競爭對手識別[J],河南科技大學學報:自然科學版,2016,(O1):46-50+7.
[6]張丹丹,鄧趙紅,王士同.面向多視角數據的極大熵聚類算法[J].計算機科學與探索,2016,(04):554-564.
[7]王偉,任建華,劉曉帥,等,基于混合隸屬度的模糊簡約雙支持向量機研究[J].計算機工程與應用,2015,(10):36-41.
[8]劉春燕,王堅,基于幾何聚類指紋庫的約束KNN室內定位模型[J].武漢大學學報:信息科學版,2014,(ll):1287-1292.
[9]譚姍姍,張培倩,李再興,基于迭代加權回歸的推薦算法[J].數學理論與應用,2014,(03):38-47.
[10]劉中健,趙知勁,尚俊娜.快速NMF盲源分離算法[J].信號處理,2014,(06):699-705.
[11]王懷宇,李景麗.網絡海量數據中隱私泄露檢測方法仿真[J].計算機仿真,2014,(06):429-432.
[12]盧煒良,江開勇,林俊義.無編碼全局控制點多視角三維數據拼接[J].光電工程,2014,(05):57-62.
[13]黃煒,劉坤.面向信息特征模式識別的核方法研究綜述[J].現代情報,2014,(03):168-176.
[14]俞翔,朱岱寅,張勁東,等,基于設計結構化Gram矩陣的ISAR運動補償方法[J].電子學報,2014,(03):452-461.
[15]俞曉群,馬翱慧.基于Kriging空間插補海表葉綠素遙感缺失數據的研究[J].測繪通報,2013,(12):47-50.
[16]毛金蓮,自適應多視角學習及其在圖像分類中的應用[J].計算機應用,2013,(07):1955-1959.
[17]陳中杰,蔡勇,蔣剛.復高斯小波核函數的支持向量機研究[J].計算機應用研究,2012,(09):3263-3265.
[18]閆鵬程,孫華剛,毛向東,等.基于EMD與SVD的齒輪箱分形診斷方法研究[J].電子測量與儀器學報,2012,(05):404- 412.
[19]汪廷華,陳峻婷.核函數的選擇研究綜述[J],計算機工程與設計,2012, (03):1181-1186.
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
