基于認(rèn)知診斷的協(xié)同過濾試題推薦①
2018-04-21 01:37:50單瑞婷羅益承
計(jì)算機(jī)系統(tǒng)應(yīng)用 2018年3期
單瑞婷, 羅益承, 孫 翼
1(北京郵電大學(xué) 國(guó)際學(xué)院,北京 100876)
2(北京郵電大學(xué) 信息與通信工程學(xué)院,北京 100876)
3(中國(guó)科學(xué)院大學(xué) 計(jì)算機(jī)與控制學(xué)院,北京 100049)
隨著電子商務(wù)和大數(shù)據(jù)的快速發(fā)展,為了能為不同用戶提供其真正感興趣和需要的個(gè)性化服務(wù),推薦系統(tǒng)在這樣的背景下被提出來,不需要用戶額外提供信息,只需利用用戶的歷史行為,便能挖掘出海量數(shù)據(jù)背后有用的信息. 其中,協(xié)同過濾算法是應(yīng)用最廣泛的一種推薦技術(shù),根據(jù)用戶的歷史行為數(shù)據(jù),來對(duì)每個(gè)人的近鄰用戶進(jìn)行推薦,不需要考慮項(xiàng)目的具體內(nèi)容,也不需考慮項(xiàng)目涉及的領(lǐng)域知識(shí),且隨著用戶時(shí)間的推移,用戶的歷史行為數(shù)據(jù)增多,可不斷修正算法的準(zhǔn)確率和性能.
在個(gè)性化教育系統(tǒng)中,推薦系統(tǒng)已逐漸受到越來越多教育者的關(guān)注,如何在有限時(shí)間內(nèi)從大量試題資源中給不同學(xué)習(xí)者推薦真正需要的試題,是一個(gè)急需解決的關(guān)鍵問題. 推薦系統(tǒng)在電子商務(wù)領(lǐng)域已十分成熟[1],但是電子商務(wù)領(lǐng)域的關(guān)鍵技術(shù)無法直接移植于個(gè)性化教育系統(tǒng),應(yīng)該在電子商務(wù)領(lǐng)域的域的基礎(chǔ)上考慮教育領(lǐng)域的獨(dú)特性,并根據(jù)相似學(xué)習(xí)者的歷史行為數(shù)據(jù),進(jìn)行個(gè)性化的試題推薦. 另外,針對(duì)協(xié)同過濾算法忽略學(xué)習(xí)者的知識(shí)點(diǎn)掌握情況(學(xué)習(xí)狀態(tài))的問題,本論文改進(jìn)了個(gè)性化教育系統(tǒng)中已有的試題推薦算法,引入了認(rèn)知診斷模型(Cognitive Diagnosis Model,CDM)的概念.
CDM廣泛用于教學(xué)評(píng)估、心理鑒定等科學(xué)、教育、醫(yī)療診斷方面. 認(rèn)知診斷,即通過可觀察的歷史行為來分析被試者不可觀察的內(nèi)部狀態(tài). 認(rèn)知診斷模型的主要任務(wù)是分析個(gè)體差異,挖掘被試者更多的內(nèi)部狀態(tài),以此來對(duì)被試者間的共同點(diǎn)來建模. 個(gè)性化教育系統(tǒng)中的認(rèn)知診斷引入了Q矩陣的概念[2],Q矩陣具體說明了題目-屬性之間的關(guān)系,從被試者對(duì)于不同項(xiàng)目(試題)的響應(yīng)情況,可以推斷出應(yīng)答者對(duì)不同試題所要求的知識(shí)點(diǎn)的掌握程度[3].
在此項(xiàng)目中,將結(jié)合認(rèn)知診斷模型中對(duì)于學(xué)習(xí)者的知識(shí)點(diǎn)掌握情況,與推薦算法中的協(xié)同過濾算法一道,對(duì)相似表現(xiàn)情況的學(xué)習(xí)者進(jìn)行相似度分析,并根據(jù)相似學(xué)習(xí)者之間的知識(shí)點(diǎn)掌握情況來對(duì)另一相似學(xué)習(xí)者作出試題推薦. 總結(jié)本文的主要工作及改進(jìn)如下:
(1)結(jié)合認(rèn)知診斷模型,該算法考慮了教育領(lǐng)域的獨(dú)特性,根據(jù)學(xué)生的歷史做題數(shù)據(jù),對(duì)其知識(shí)點(diǎn)的掌握情況進(jìn)行了考慮,并綜合相似學(xué)生掌握知識(shí)點(diǎn)的相似度來對(duì)試題做出推薦,同時(shí)考慮了相似群體的共性和個(gè)體的獨(dú)特性. 實(shí)驗(yàn)結(jié)果可信度高,結(jié)果解釋性好,且覆蓋更為全面,且可擴(kuò)展性和性能要優(yōu)于普通的協(xié)同過濾算法,更符合個(gè)性化教育系統(tǒng)中的需求.
(2)一方面,通過該算法可以給目標(biāo)用戶提供個(gè) 性化試題推薦,另一方面,也可以對(duì)未知用戶但已知部分做題狀況作出分析,依靠其相似用戶的表現(xiàn)來對(duì)剩余的做題情況作出預(yù)測(cè).
1 相關(guān)工作
1.1 認(rèn)知診斷
CDM是被試項(xiàng)目的反應(yīng)函數(shù),將被試可觀察的反應(yīng)模式(ORP)轉(zhuǎn)化為被試知識(shí)狀態(tài)(KS)的數(shù)學(xué)模型[4].認(rèn)知診斷模型不同于普通的紙筆測(cè)驗(yàn)或者計(jì)算機(jī)自適應(yīng)測(cè)驗(yàn),雖然三者都能產(chǎn)生對(duì)被試者測(cè)驗(yàn)結(jié)果的能力報(bào)告,但是認(rèn)知診斷模型還能產(chǎn)生被試者對(duì)所考察知識(shí)點(diǎn)的詳細(xì)掌握情況,通過認(rèn)知診斷模型,從被試者角度,可以直接了當(dāng)?shù)目吹阶约褐R(shí)點(diǎn)的缺漏和不足,并為今后的學(xué)習(xí)提供指導(dǎo),從教師角度,可以掌握不同學(xué)生對(duì)于知識(shí)點(diǎn)的掌握情況,從而因材施教[5].
在眾多認(rèn)知診斷模型中,最常見的、應(yīng)用最廣泛的是 DINA 模型 (Deterministic Inputs,Noisy “And”gate; Junker & Sijtsma,2001)和規(guī)則空間模型(RSM;Tatsuoka,1995,2009). 其中,DINA模型依據(jù)被試者的表現(xiàn)引入了兩個(gè)評(píng)價(jià)因子: 失誤和猜對(duì)因子,使得測(cè)試結(jié)果更接近被試者的真實(shí)響應(yīng)狀態(tài),另外,DINA模型運(yùn)用了Q矩陣[6],判斷出被試者的知識(shí)域或者說被試者對(duì)知識(shí)點(diǎn)的掌握程度[7,8].
對(duì)于DINA模型而言,題目反應(yīng)矩陣R可以由學(xué)生掌握屬性集合矩陣A和題目-屬性矩陣Q[9]得到,并且,我們發(fā)現(xiàn),反應(yīng)矩陣R其中任一元素R(某測(cè)試學(xué)生i,某題目j)可以表示成以下方式:
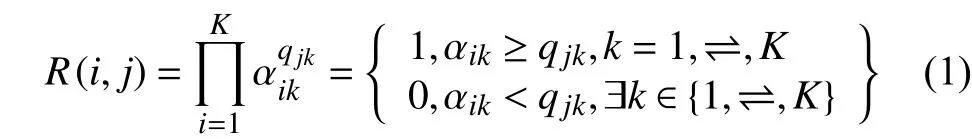
雖然上式給出了題目反應(yīng)矩陣R與學(xué)生的知識(shí)狀態(tài)矩陣A與題目-屬矩陣Q的關(guān)系,但在實(shí)際情況中學(xué)生對(duì)題目的反應(yīng)矩陣是唯一的可觀測(cè)量,而矩陣A與矩陣Q作為隱藏變量無法從數(shù)據(jù)中直接得到. 也就是說,至今的理論基本上都是建立于Q矩陣為事先定義好的[10,11]. 從而,基于觀察數(shù)據(jù)中的Q矩陣和學(xué)生對(duì)知識(shí)點(diǎn)的掌握情況,由任一已知的另一批學(xué)生知識(shí)點(diǎn)掌握情況或者另一套題目對(duì)于知識(shí)點(diǎn)的必需與否情況,來對(duì)另一批學(xué)生對(duì)同一套題的答題情況或者同一學(xué)生群體對(duì)于不同套題目的答題情況進(jìn)行預(yù)測(cè). 以此,根據(jù)該預(yù)測(cè)情況通過個(gè)性化學(xué)習(xí)系統(tǒng)對(duì)于學(xué)生的薄弱知識(shí)點(diǎn)方面進(jìn)行重點(diǎn)指導(dǎo).
1.2 協(xié)同過濾推薦算法
在個(gè)性化教育中,協(xié)同過濾算法應(yīng)用的核心是通過學(xué)生的做題情況,以此分析學(xué)生對(duì)某些特定知識(shí)點(diǎn)的掌握情況,并綜合不同學(xué)生對(duì)不同題目的得分來評(píng)測(cè)學(xué)生的相似性,并以此來預(yù)測(cè)相似學(xué)生掌握某知識(shí)點(diǎn)的程度,并基于相似學(xué)生之間的相似度,并結(jié)合相似度評(píng)價(jià)標(biāo)準(zhǔn)來對(duì)學(xué)生未掌握的知識(shí)點(diǎn)(題目)做出題目推薦.
協(xié)同過濾主要分為基于近鄰的協(xié)同過濾方法和基于模型的協(xié)同過濾方法[12]. 基于近鄰的協(xié)同過濾方法根據(jù)學(xué)生的答題情況來計(jì)算不同學(xué)生之間的相似度,以找到與目標(biāo)學(xué)生相似度最高的學(xué)生,通過該相似學(xué)生的得分對(duì)目標(biāo)學(xué)生進(jìn)行得分預(yù)測(cè),并以此進(jìn)行試題推薦[13-16]. 基于近鄰的協(xié)同過濾方法又可分為基于項(xiàng)目(試題)和基于用戶的協(xié)同過濾,從題目或者學(xué)生的不同的角度來考慮其相似度,兩者都可以不對(duì)推薦項(xiàng)目的具體內(nèi)容(知識(shí)點(diǎn))進(jìn)行考慮; 基于模型的協(xié)同過濾應(yīng)用最為廣泛,通過忽略學(xué)生響應(yīng)矩陣中重要性較小的值,來對(duì)原本的高維矩陣進(jìn)行降維,學(xué)生和試題都看作一對(duì)影響因子,刻畫學(xué)生和試題在低維空間中的表現(xiàn)程度,并據(jù)此來預(yù)測(cè)學(xué)生在試題上的得分,進(jìn)一步根據(jù)預(yù)測(cè)的得分進(jìn)行試題推薦[3].文獻(xiàn)[15]和文獻(xiàn)[17]表明,基于模型的協(xié)同過濾方法能根據(jù)用戶的歷史數(shù)據(jù)構(gòu)建模型,克服了數(shù)據(jù)稀疏性問題,同時(shí)具有很好的精確度和擴(kuò)展性,具體方法如奇異值分解(Singular Value Decomposition,SVD)[18,19].
2 基于矩陣分解的協(xié)同過濾算法
2.1 算法介紹
針對(duì)目前大多數(shù)協(xié)同過濾算法普遍存在的可擴(kuò)展性和抗稀疏性問題,聯(lián)合傳統(tǒng)的SVD的基礎(chǔ)上提出了基于SVD的協(xié)同過濾算法,大大減輕了傳統(tǒng)協(xié)同過濾算法的可擴(kuò)展性和稀疏性問題[20]. 在本文中給定的R矩陣為具有m個(gè)測(cè)試學(xué)生,n道測(cè)試題目的學(xué)生做題評(píng)分矩陣,且R∈{0,1}. R=0代表測(cè)試者答錯(cuò)或未作答,R=1代表測(cè)試者答對(duì)題目. 用SVD算法來分解一個(gè)m×n的評(píng)分矩陣R,其中m、n均為正整數(shù),可分解成為m×m的正交矩陣U矩陣,m×n的對(duì)角矩陣Σ和n×n的正交矩陣V矩陣的轉(zhuǎn)置的乘積,可形象的表示為:
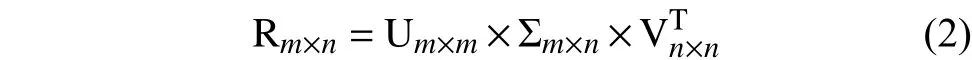
其中,U、V矩陣分別稱作左奇異矩陣、右奇異矩陣,Σ矩陣是一個(gè)對(duì)稱矩陣,矩陣內(nèi)的元素為奇異值,在對(duì)角線上由上至下依次遞減,而且矩陣內(nèi)奇異值降低的很快,在很多情況下,前10%的奇異值的和就占了總奇異值和的99%以上.
以此,我們可以通過Σ矩陣的前r個(gè)奇異值的方法來對(duì)R矩陣進(jìn)行降維,保留其r個(gè)最大奇異值的右奇異矩陣組成一個(gè)r維空間(r×n),對(duì)降維后的R矩陣近似R矩陣進(jìn)行分析,消除算法冗余度. 可以通過高維上的特征值分解,可通過Σ矩陣的前r個(gè)特征向量來預(yù)測(cè)矩陣的主要變換方向,以此來預(yù)測(cè)近似矩陣. 近似矩陣R'可表示為:

式中的r的取值原則為,在奇異值盡可能大的情況下截取r的值,在接下來的研究中,我們留下相鄰r距離不超過50%的奇異值,而截取的r越接近于n,我們得到的R’矩陣也就越接近于原始矩陣R.
2.2 算法步驟
算法1. 傳統(tǒng)的基于SVD的協(xié)同過濾算法
輸入: 學(xué)生-題目評(píng)分矩陣R∈{0,1}
輸出: 目標(biāo)學(xué)生近似(預(yù)測(cè))評(píng)分矩陣R'
步驟:
(1)對(duì)于給定的R矩陣,若學(xué)生答對(duì)題則記1分; 若答錯(cuò)則不得分,記0分; 對(duì)于R矩陣中的缺失值,同時(shí)記為0分,于是得到了規(guī)范矩陣Rnorm;
(2)將規(guī)范矩陣Rnorm進(jìn)行SVD分解,得到U、Σ、V矩陣;
(3)對(duì)稱矩陣Σ降維,抹去相鄰距離小于50%的奇異值,得到降維后的矩陣
(4)參照矩陣Σ'的維度可簡(jiǎn)化U、V矩陣,分別得到簡(jiǎn)化的矩陣U和V,于是就可得到R矩陣的近似矩陣R'=U'×Σ'×V',R'≈R;
如果原始學(xué)生-題目評(píng)分矩陣為稀疏度較高的高維矩陣,得到的簡(jiǎn)化矩陣的維數(shù)r遠(yuǎn)小于原始維度n,經(jīng)過降維后的相似性比較只需對(duì)兩個(gè)一維量進(jìn)行比較,這大大提高了運(yùn)算效率,同時(shí)也提高搜索精度,因此降低了原始數(shù)據(jù)的稀疏性,進(jìn)而使推薦結(jié)果更為準(zhǔn)確.
3 相似用戶評(píng)價(jià)標(biāo)準(zhǔn)
為了求得用戶間的相似性以對(duì)相似用戶做出試題推薦,對(duì)降維后的學(xué)生-題目評(píng)分矩陣進(jìn)行相似度計(jì)算,根據(jù)學(xué)生與學(xué)生、題目與題目之間的相似度來對(duì)目標(biāo)學(xué)生做出試題推薦.
3.1 基于SVD分解的相似度比較
對(duì)于學(xué)生-題目評(píng)分矩陣R(m×n),進(jìn)行SVD分解得到的矩陣Σ代表多維空間中在各個(gè)維度上的權(quán)重,可對(duì)Σ進(jìn)行降維處理. 從公式(4)中看出,令Σ變?yōu)閞行r列的對(duì)角矩陣,于是,矩陣U變?yōu)閙×r,其行代表學(xué)生,每一行代表每一個(gè)學(xué)生在r維空間中的一個(gè)向量. 矩陣V變?yōu)閚×r,其行代表題目,每一行代表每一個(gè)學(xué)生在r維空間中的一個(gè)向量.
令r=2即降維到二維,則每個(gè)學(xué)生向量每個(gè)題目向量看成二維空間中的一個(gè)點(diǎn). 因此,通過對(duì)每一個(gè)學(xué)生的響應(yīng)矩陣R進(jìn)行降維,每一道題目被映射成了r維空間中的一個(gè)向量,可以通過衡量向量間的距離來判斷學(xué)生與學(xué)生,題目與題目之間的各種距離來判斷是否相似從而進(jìn)行推薦.
3.2 相似度的評(píng)價(jià)
在使用SVD分解后的距離來衡量相似度時(shí),我們嘗試了多種距離,用實(shí)際的數(shù)據(jù)進(jìn)行比較,來尋找一種最為準(zhǔn)確的距離進(jìn)行推薦. 在實(shí)驗(yàn)中考慮的是基于用戶的協(xié)同過濾推薦,于是可以通過計(jì)算矩陣U中向量Ui和Uj的距離(余弦距離)來判斷第i個(gè)學(xué)生和第j個(gè)學(xué)生是否相似,距離越小說明相似程度越低. 通過大量數(shù)據(jù)的實(shí)驗(yàn),可以求出一個(gè)閾值σ(實(shí)驗(yàn)中為0.05),相似度閾值σ則可以通過大量數(shù)據(jù)進(jìn)行實(shí)驗(yàn)測(cè)得,當(dāng)距離小于閾值σ時(shí),說明兩個(gè)學(xué)生在學(xué)習(xí)狀態(tài)上是相似的,故可以依據(jù)相似學(xué)生的做題情況進(jìn)行題目的推薦.反之,說明兩個(gè)學(xué)生學(xué)習(xí)狀態(tài)有差異.
4 實(shí)驗(yàn)
4.1 數(shù)據(jù)集介紹
對(duì)于實(shí)驗(yàn)數(shù)據(jù),我們采用了三組數(shù)據(jù)對(duì)比,三組數(shù)據(jù)均為真實(shí)實(shí)驗(yàn)的數(shù)據(jù). 關(guān)于三組數(shù)據(jù)集的相關(guān)信息表1所示.
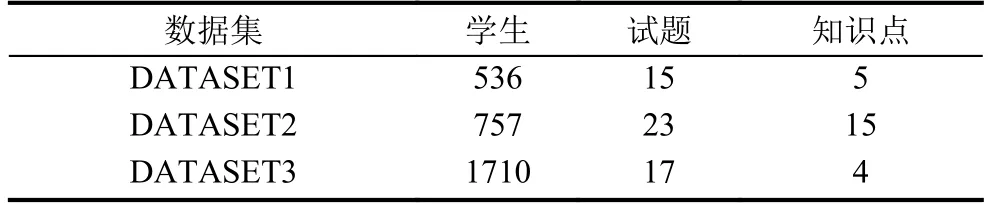
表1 三組實(shí)驗(yàn)數(shù)據(jù)的詳細(xì)數(shù)據(jù)
DATASET1: 對(duì)應(yīng)536名中學(xué)生對(duì)于15道減法題的答題情況,15道題總共考察了5個(gè)知識(shí)點(diǎn),其Q矩陣(試題-知識(shí)點(diǎn))的熱力圖如圖1所示. DATASET1在三類數(shù)據(jù)集中擁有最少的測(cè)試者人數(shù),且試題、知識(shí)點(diǎn)個(gè)數(shù)也較為偏少,試題-知識(shí)點(diǎn)關(guān)系也由圖1給出,可以觀察到此數(shù)據(jù)集較為簡(jiǎn)單,且不同題目所需的知識(shí)點(diǎn)也較為分散,說明不同題目間所涵蓋知識(shí)點(diǎn)的差距較大,可看做初級(jí)教育中對(duì)于相關(guān)初級(jí)知識(shí)點(diǎn)(如分配律、結(jié)合律等)的綜合考查. 對(duì)于該數(shù)據(jù)集,需要仔細(xì)設(shè)定相似度截取標(biāo)準(zhǔn),避免出現(xiàn)過多的相似用戶從而影響推薦結(jié)果. 該數(shù)據(jù)還最早用于K. Tatsuoka(1990)的研究中,其后用于C. Tatsuoka (2002) 和de la Torre and Douglas (2004)等的論文中.DATASET2: 對(duì)應(yīng)757名學(xué)生對(duì)于23道數(shù)學(xué)題的答題情況,23道題總共考察了15個(gè)知識(shí)點(diǎn),其Q矩陣
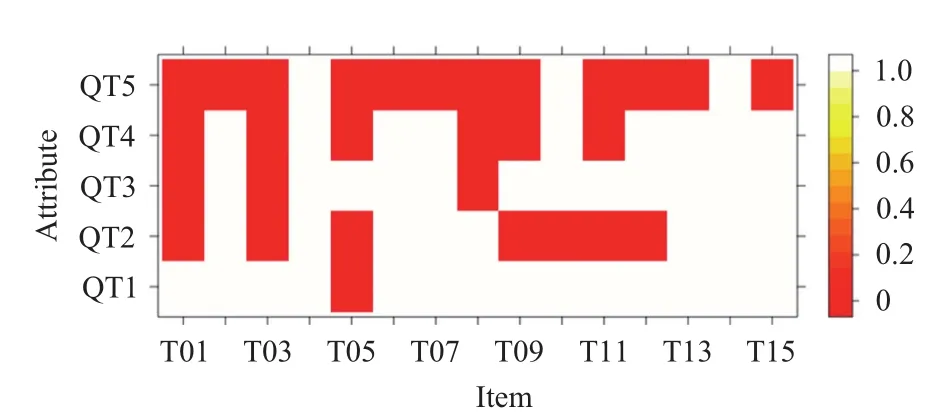
圖1 DATASET1的Q矩陣熱力圖
(試題-知識(shí)點(diǎn))的熱力圖如圖2所示. DATASET2在三類數(shù)據(jù)集中所測(cè)試的學(xué)生數(shù)居中,而試題數(shù)、知識(shí)點(diǎn)數(shù)最多,由圖2可知,各個(gè)試題考查知識(shí)點(diǎn)數(shù)較少且較為分散,而每道試題未考查的知識(shí)點(diǎn)大多有所涵蓋,說明該數(shù)據(jù)集主要針對(duì)中高級(jí)不相關(guān)知識(shí)點(diǎn)的一個(gè)考察,
更接近于現(xiàn)實(shí)情況的真實(shí)數(shù)據(jù). 對(duì)于DATASET2,需要稍微調(diào)整相似度截取標(biāo)準(zhǔn),實(shí)驗(yàn)證明只有很少的相似度接近與目標(biāo)用戶的相似度. 該數(shù)據(jù)最早用于Su et al.(2013)的TIMSS 2003小學(xué)數(shù)學(xué)測(cè)試.
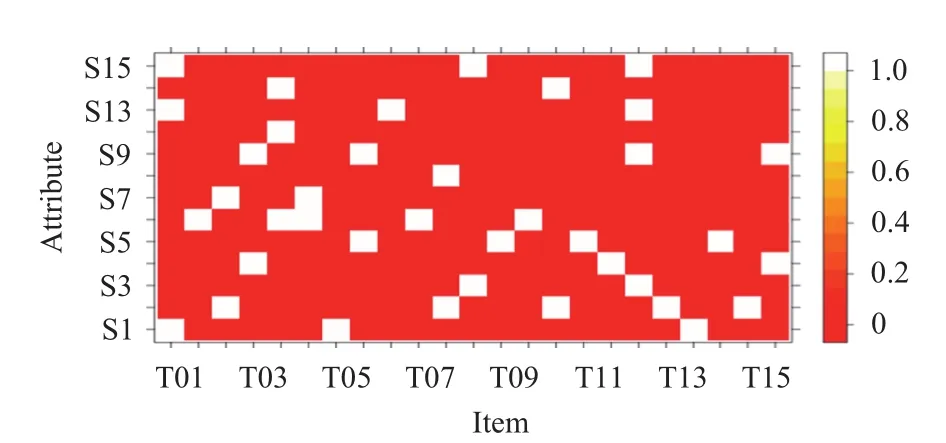
圖2 DATASET2的Q矩陣熱力圖
DATASET3: 對(duì)應(yīng)1710名中學(xué)生對(duì)于17道題的答題情況,17道題總共考察了4個(gè)知識(shí)點(diǎn),分別是:CM(批評(píng)的方法)、II(識(shí)別改進(jìn))、PP(保護(hù)對(duì)象)、DG(辨識(shí)一般性). 其Q矩陣(試題—知識(shí)點(diǎn))的熱力圖如圖3所示. DATASET3擁有最多的學(xué)生數(shù),但所考察知識(shí)點(diǎn)數(shù)較少,試題數(shù)適中,由圖3可知,部分題目考察知識(shí)點(diǎn)無交叉,該數(shù)據(jù)集適用于考察大數(shù)據(jù)集下初級(jí)教育中不相關(guān)知識(shí)點(diǎn)(如加減乘除)的單獨(dú)做題情況. 由于數(shù)據(jù)集較大,如何對(duì)數(shù)據(jù)進(jìn)行降維又不影響對(duì)各學(xué)生所掌握知識(shí)點(diǎn)的分析是一大難點(diǎn). 該數(shù)據(jù)來源于Jurich和Brad- shaw (2014)對(duì)于SDA6的研究.
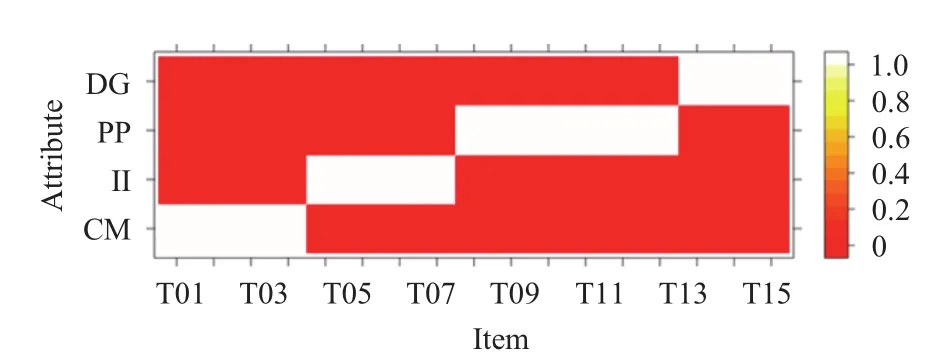
圖3 DATASET3的Q矩陣熱力圖
通過學(xué)生對(duì)于題目的響應(yīng)情況,結(jié)合Q矩陣我們可以判斷學(xué)生對(duì)于題目所要求知識(shí)點(diǎn)的掌握情況. 例如,從熱力圖中可看出,深色代表做對(duì)題目不需要掌握該知識(shí)點(diǎn),白色代表題目考查此知識(shí)點(diǎn). 對(duì)于DATASET1中的第一題(T01)來說,做對(duì)該題需要具備知識(shí)點(diǎn)QT1;對(duì)于DATASET2中的第一題(M012001)來說,做對(duì)該題需要同時(shí)具備知識(shí)點(diǎn)S1、S13、S15.
4.2 實(shí)驗(yàn)評(píng)測(cè)指標(biāo)
4.2.1 精確率
精確率(precision),表示推薦結(jié)果當(dāng)中推薦正確的程度. 其定義式如下所示:
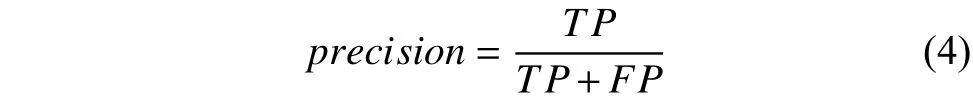
其中TP為推薦試題中學(xué)生真正正確作答的個(gè)數(shù),FP表示推薦試題中學(xué)生錯(cuò)誤作答的個(gè)數(shù).
4.2.2 召回率
召回率(recall),針對(duì)原本的數(shù)據(jù)樣本而言,表示的是樣本中的正例被預(yù)測(cè)正確的程度. 其定義式如下所示:

其中TP為推薦試題中學(xué)生真正正確作答的個(gè)數(shù),FN表示待推薦試題中學(xué)生真正正確作答的個(gè)數(shù).
4.2.3 F1值
F1值和精確率、召回率密切相關(guān),是綜合這二者指標(biāo)的評(píng)估指標(biāo),用于綜合反映整體的指標(biāo),其定義式如下所示:

4.3 實(shí)驗(yàn)過程及相關(guān)算法
4.3.1 對(duì)目標(biāo)用戶進(jìn)行試題推薦
算法2. 基于認(rèn)知診斷的協(xié)同過濾算法
輸出: 目標(biāo)學(xué)生的相似用戶、試題推薦
步驟:
(1) 抹去R矩陣中目標(biāo)用戶的部分值(實(shí)驗(yàn)得到4為最優(yōu)抹去值),設(shè)置為-1,將處理后的矩陣R記做矩陣RQES;
(2) 將矩陣RQES進(jìn)行SVD分解,分解得到的三個(gè)矩陣分別記為U、Σ、V矩陣;
(3) 截取U矩陣、V矩陣的兩列(截取維數(shù)r=2),于是每道題目都可以映射成二維空間的一個(gè)向量;
(4) 根據(jù)截取后的二維空間,計(jì)算目標(biāo)用戶與周圍用戶之間的相似度,并進(jìn)行升序排序,相似度越接近1,說明與目標(biāo)用戶越相似;
(5) 將(1)步抹去的值與(4)步得出的相似用戶的對(duì)應(yīng)值進(jìn)行比較,準(zhǔn)確度能達(dá)到90%,證明算法可靠性;
(6) 根據(jù)相似用戶的做題表現(xiàn)來進(jìn)行試題推薦. 對(duì)于目標(biāo)用戶做錯(cuò)的題,認(rèn)為目標(biāo)用戶未掌握該題相關(guān)知識(shí)點(diǎn),對(duì)用戶做出推薦; 對(duì)于目標(biāo)用戶做對(duì)、相似用戶做錯(cuò)的題,認(rèn)為目標(biāo)用戶有未掌握該題相關(guān)知識(shí)點(diǎn)的可能,也對(duì)用戶做出推薦.
4.3.2 預(yù)測(cè)不完整評(píng)分矩陣并推薦試題
當(dāng)然我們還可以利用此算法對(duì)未知表現(xiàn)狀態(tài)的學(xué)生進(jìn)行答題情況的預(yù)測(cè),或者對(duì)于學(xué)生漏做的題目進(jìn)行答題情況的預(yù)測(cè). 說明第一種情況,當(dāng)出現(xiàn)一個(gè)新的學(xué)生,且我們知道其部分答題的狀況時(shí),也可以使用SVD分解得到其在r維空間中的向量,再進(jìn)行新學(xué)生與其他已知表現(xiàn)的學(xué)生進(jìn)行相似度比較,從而進(jìn)行題目推薦. 可通過以下幾步完成:
算法3. 預(yù)測(cè)新學(xué)生的評(píng)分矩陣
輸入: 新學(xué)生不完整的評(píng)分矩陣R∈{0,1}
輸出: 目標(biāo)用戶的相似用戶、新學(xué)生完整的評(píng)分矩陣
步驟:
(1) 已知新學(xué)生的評(píng)分矩陣,設(shè)其為R1×n′;
(2) 則此學(xué)生的r維空間中的向量為U′=R′×V×S-1;
(3) 通過U′計(jì)算該學(xué)生與其他學(xué)生的相似度;
(4)根據(jù)相似度來推薦題目.
4.4 實(shí)驗(yàn)結(jié)果分析
4.4.1 不同缺失值對(duì)推薦準(zhǔn)確率的影響
表2表示抹去R矩陣中同一目標(biāo)用戶不同數(shù)量的缺失值作為測(cè)試集,目標(biāo)用戶原本的答題狀態(tài)作為驗(yàn)證集,實(shí)驗(yàn)數(shù)據(jù)顯示,算法得出的相似用戶個(gè)數(shù)會(huì)隨著缺失值個(gè)數(shù)的增加而增多,而當(dāng)缺失值個(gè)數(shù)為4的時(shí)候推薦結(jié)果最為準(zhǔn)確,也就是說,當(dāng)未知學(xué)生的評(píng)分矩陣缺失值個(gè)數(shù)為4時(shí),我們預(yù)測(cè)的該用戶的完整R矩陣最接近真實(shí)值. 同時(shí),也驗(yàn)證了基于SVD的協(xié)同過濾算法的可靠性.

表2 同一目標(biāo)用戶不同缺失值個(gè)數(shù)的測(cè)試集對(duì)推薦準(zhǔn)確率的影響
4.4.2 不同算法下推薦評(píng)測(cè)指標(biāo)的比較
接下來我們根據(jù)不同測(cè)試集,對(duì)傳統(tǒng)的認(rèn)知診斷模型里的DINA模型和基于認(rèn)知診斷的協(xié)同過濾算法進(jìn)行實(shí)驗(yàn)比較,實(shí)驗(yàn)結(jié)果如表3所示. 我們有以下結(jié)論:
(1) 可以觀察到,考慮了學(xué)生對(duì)知識(shí)點(diǎn)掌握程度的協(xié)同過濾算法準(zhǔn)確率和召回率均優(yōu)于傳統(tǒng)的認(rèn)知診斷模型,并結(jié)合目標(biāo)用戶的相似用戶的知識(shí)點(diǎn)掌握情況來給學(xué)生推薦題目,算法更具可靠性和說服性;
(2) 隨著學(xué)生數(shù)量的增加,基于認(rèn)知診斷的協(xié)同過濾算法的性能越來越優(yōu)越,說明對(duì)于現(xiàn)實(shí)生活中大量的學(xué)生得分情況數(shù)據(jù),該算法能高效準(zhǔn)確的對(duì)學(xué)生掌握知識(shí)點(diǎn)的狀態(tài)進(jìn)行分析,并結(jié)合協(xié)同過濾算法對(duì)不同學(xué)生做出個(gè)性化試題推薦;
(3) 測(cè)試集試題比率較少時(shí),傳統(tǒng)的認(rèn)知診斷模型無法準(zhǔn)確對(duì)學(xué)生知識(shí)點(diǎn)狀態(tài)進(jìn)行推斷,此時(shí)推薦結(jié)果波動(dòng)幅度大,主要原因?yàn)橛?xùn)練數(shù)據(jù)的減少導(dǎo)致DINA方法中對(duì)于學(xué)生知識(shí)點(diǎn)掌握狀態(tài)的誤差較大.
4.4.3 結(jié)果分析
在DATASET1中,我們抽取了學(xué)生A和學(xué)生B的做題情況對(duì)5個(gè)知識(shí)點(diǎn)(QT1、QT2、QT3、QT4、QT5)的掌握程度(正確做對(duì)需要掌握該知識(shí)點(diǎn)的題目個(gè)數(shù)/需要掌握該知識(shí)點(diǎn)的題目個(gè)數(shù))進(jìn)行分析比較,由圖4所示,可以看出,學(xué)生A對(duì)于知識(shí)點(diǎn)QT1、QT2、QT4的掌握程度較高,但是學(xué)生A完全沒掌握知識(shí)點(diǎn)QT5;然而學(xué)生B對(duì)于知識(shí)點(diǎn)QT5的掌握程度遠(yuǎn)遠(yuǎn)高于學(xué)生A,但是對(duì)于其余知識(shí)點(diǎn)的掌握程度都小于學(xué)生A.
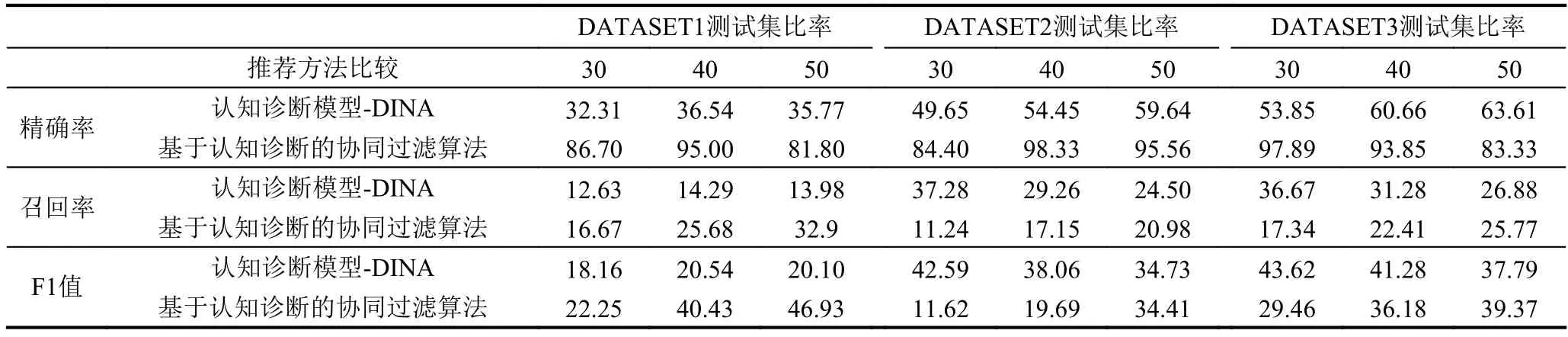
表3 傳統(tǒng)認(rèn)知診斷模型和基于認(rèn)知診斷的協(xié)同過濾算法對(duì)于不同測(cè)試集的比較(單位: %)

圖4 不同學(xué)生對(duì)知識(shí)點(diǎn)的掌握程度雷達(dá)圖
接下來,對(duì)學(xué)生A、B的R矩陣分別進(jìn)行SVD分解和數(shù)據(jù)降維,將左奇異矩陣和右奇異矩陣分別截取兩列,以此可將每道題目映射成二維空間的一個(gè)向量,并通過相似度排列找出對(duì)應(yīng)的相似用戶,依據(jù)相似用戶的行為來對(duì)目標(biāo)用戶做出試題推薦. 在DATASET1中,學(xué)生A、B的正確率均為50%,基于知識(shí)點(diǎn)掌握程度的認(rèn)真診斷方法傾向于對(duì)學(xué)生A集中推薦試題T04、T10、T14,解決學(xué)生A未能掌握知識(shí)點(diǎn)QT5的問題,因?yàn)樽鰧?duì)該三道題必須掌握知識(shí)點(diǎn)QT5,對(duì)其他4個(gè)知識(shí)點(diǎn)不作要求,結(jié)合協(xié)同過濾過濾算法中學(xué)生A的相似用戶的做題表現(xiàn),我們最終對(duì)學(xué)生A推薦試題T10、T14; 對(duì)于學(xué)生B,算法集中于推薦試題T02、T06、T07、T13、T15,主要考驗(yàn)除了知識(shí)點(diǎn)QT5以外的知識(shí)點(diǎn)相關(guān)題目,因?yàn)樽鰧?duì)該五道題必須同時(shí)掌握知識(shí)點(diǎn)QT1、QT2、QT3、QT4,結(jié)合協(xié)同過濾算法中學(xué)生B的相似用戶的做題情況,我們最終對(duì)學(xué)生B推薦試題T02、T06、T13、T15.
另外,為了避免目標(biāo)用戶與相似用戶間掌握的知識(shí)點(diǎn)程度的誤差,我們規(guī)定,對(duì)于目標(biāo)用戶答題正確但其相似用戶答題錯(cuò)誤的題,認(rèn)為目標(biāo)用戶有未掌握該題相關(guān)知識(shí)點(diǎn)的可能,對(duì)目標(biāo)用戶做出推薦; 而對(duì)于目標(biāo)用戶答題錯(cuò)誤但其相似用戶答題正確的題,認(rèn)為目標(biāo)用戶未掌握該題相關(guān)知識(shí)點(diǎn),也對(duì)用戶進(jìn)行推薦.
5 總結(jié)與展望
在此篇論文中,針對(duì)個(gè)性化教育系統(tǒng)中協(xié)同過濾算法無法考慮被試者知識(shí)點(diǎn)掌握情況的不足,提出了結(jié)合認(rèn)知診斷模型、奇異值分解方法(SVD)和近鄰模型來研究個(gè)性化學(xué)習(xí)領(lǐng)域下學(xué)生評(píng)分矩陣R的預(yù)測(cè)以及題目推薦. 實(shí)驗(yàn)分為以下三步: (1)根據(jù)目標(biāo)用戶的答題情況,可以結(jié)合認(rèn)知診斷模型當(dāng)中的題目—屬性Q矩陣來對(duì)學(xué)生掌握知識(shí)點(diǎn)的程度進(jìn)行計(jì)算分析,并將作為之后試題推薦的借鑒; (2)利用基于SVD的協(xié)同過濾算法對(duì)測(cè)試集中的R矩陣進(jìn)行分解、降維,得到了學(xué)生和題目在多維空間中的坐標(biāo),并利用相似度計(jì)算方法計(jì)算其他用戶與目標(biāo)用戶直接的相似度,找出相似用戶; (3)根據(jù)第(2)步中的相似用戶的答題狀態(tài)來對(duì)目標(biāo)用戶做出推薦,同時(shí)也要參考第(1)步中目標(biāo)用戶對(duì)各知識(shí)點(diǎn)的掌握程度. 從結(jié)果來看,在數(shù)據(jù)量較大的情況下,可以進(jìn)行正確判斷相似性并進(jìn)行推薦.實(shí)驗(yàn)驗(yàn)證,基于學(xué)生認(rèn)知狀態(tài)的試題推薦是合理且解釋性較高的,說明基于認(rèn)知診斷的協(xié)同過濾方法是合理可行的.
實(shí)驗(yàn)表明,SVD分解可以得到學(xué)生掌握知識(shí)的范圍,并且具有良好的魯棒性,計(jì)算出更多推薦信息的同時(shí)也保證了推薦的質(zhì)量. 該方法免除了計(jì)算學(xué)生或題目間相似度的過程,算法實(shí)現(xiàn)過程簡(jiǎn)單,但是不太容易解釋理解,推薦的精確度會(huì)受到一定影響. 從實(shí)驗(yàn)中可以看到,雖然對(duì)學(xué)生特征向量的降維提高了模型的預(yù)測(cè)精度,但是對(duì)計(jì)算機(jī)計(jì)算能力和內(nèi)存有一定消耗. 此外,訓(xùn)練用的學(xué)生題目維度較小,因此怎么優(yōu)化分解高維度下學(xué)生題目的響應(yīng)是還需研究探討的問題.
1魯?shù)? 個(gè)性化教育資源推薦系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)[碩士學(xué)位論文]. 上海: 華東師范大學(xué),2014.
2Tatsuoka KK. Rule space: An approach for dealing with misconceptions based on item response theory. Journal of Educational Measurement,1983,20(4): 345-354. [doi: 10.1111/jedm.1983.20.issue-4]
3De La Torre J,DINA model and parameter estimation: A didactic. DINA model and parameter estimation: A didactic.Journal of Educational and Behavioral Statistics,2009,34(1):115-130.
4丁樹良,毛萌萌,汪文義,等. 教育認(rèn)知診斷測(cè)驗(yàn)與認(rèn)知模型一致性的評(píng)估. 心理學(xué)報(bào),2012,44(11): 1535-1546.
5任群. 認(rèn)知診斷測(cè)驗(yàn)的應(yīng)用研究[碩士學(xué)位論文]. 合肥: 安徽大學(xué),2011.
6Liu JC,Xu GJ,Ying ZL. Learning item-attribute relationship in Q-matrix based diagnostic classification models.arXiv:1106.0721,2011.
7De La Torre J. An empirically based method of Q-matrix validation for the DINA model: Development and applications. Journal of Educational Measurement,2008,45(4): 343-362. [doi: 10.1111/jedm.2008.45.issue-4]
8De La Torre J,Chiu CY. A general method of empirical Q-matrix validation. Psychometrika,2016,81(2): 253-273.[doi: 10.1007/s11336-015-9467-8]
9Liu JC,Xu GJ,Ying ZL. Theory of self-learning Q-matrix.Bernoulli,2013,19(5A): 1790-1817. [doi: 10.3150/12-BEJ 430]
10Sun Y,Ye SW,Shi HY,et al. Maximum likelihood estimation based DINA model and Q-matrix Learning.International Conference on Behavior,Economic and Social Computing. Shanghai,China. 2014. 1-6.
11Romero SJ,Ordo?ez XG,Ponsoda V,et al. Detection of Q-matrix misspecification using two criteria for validation of cognitive structures under the least squares distance model.Psicológica,2014,35(1): 149-169.
12李改,李磊. 基于矩陣分解的協(xié)同過濾算法. 計(jì)算機(jī)工程與應(yīng)用,2011,47(30): 4-7. [doi: 10.3778/j.issn.1002-8331.2011.30.002]
13朱天宇,黃振亞,陳恩紅,等. 基于認(rèn)知診斷的個(gè)性化試題推薦方法. 計(jì)算機(jī)學(xué)報(bào),2017,40(1): 176-191. [doi: 10.11897/SP.J.1016.2017.00176]
14張瀟,沙如雪. 認(rèn)知診斷DINA模型研究進(jìn)展. 中國(guó)考試,2013,(1): 32-37.
15Koren Y,Bell R,Volinsky C. Matrix factorization techniques for recommender systems. Computer,2009,42(8): 30-37.[doi: 10.1109/MC.2009.263]
16Linden G,Smith B,York J. Amazon. com recommendations:item-to-item collaborative filtering. IEEE Internet Computing,2003,7(1): 76-80. [doi: 10.1109/MIC. 2003.11 67344]
17Salakhutdinov R,Mnih A. Probabilistic matrix factorization.Proceedings of the 20th International Conference on Neural Information Processing Systems. Vancouver,British Columbia,Canada. 2007. 1257-1264.
18Billsus D,Pazzani MJ. Learning collaborative information filters. Proceedings of the 15th International Conference on Machine Learning. San Francisco,CA,USA. 1998. 46-54.
19Desmarais MC,Naceur R. A matrix factorization method for mapping items to skills and for enhancing expert-based Q-matrices. In: Lane HC,Yacef K,Mostow J,et al.,eds.Artificial Intelligence in Education. Berlin,Heidelberg.Springer. 2013. 441-450.
20趙營(yíng). 結(jié)合SVD的協(xié)同過濾算法研究. 通訊世界,2016,(10): 255.
猜你喜歡
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
電影(2018年9期)2018-11-14 06:57:21
作文世界(小學(xué)版)(2018年4期)2018-10-16 17:13:34
快樂作文·低年級(jí)(2016年12期)2017-01-03 20:52:44
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
快樂作文·低年級(jí)(2016年6期)2016-06-24 18:58:40
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
