基于子類問題分類能力度量的特征選擇方法
2018-05-07 03:50:21鄭陶然趙晨飛王淑琴何茂偉
天津師范大學學報(自然科學版) 2018年2期
劉 磊,鄭陶然,趙晨飛,劉 林,王淑琴,何茂偉
(1.天津師范大學 計算機與信息工程學院,天津300387;2.天津工業大學 計算機科學與軟件學院,天津 300387)
特征選擇與特征抽取是維數約簡中2個主要的方法[1],是構造分類器中關鍵的數據預處理步驟,其結果直接影響分類器的準確率.在當今大數據時代,數據呈數量巨大且紛繁復雜的特點,使得特征選擇方法的研究尤為重要[2].特征選擇是指根據一些評價標準在原有的特征集合上選擇對分類有意義的特征子集,而去除無關或冗余特征,從而將原空間的維數降至遠小于原維數的m維.特征選擇方法分為Wrapper、Filter和Embedded 3類[3-4].Wrapper和Embedded方法通常用分類器的準確率來評價選擇的特征子集[5-7],而Filter方法不依賴于分類器,只考慮特征的分類能力.Filter方法運算速度快,適用于大數據.Filter方法可以分為對各個特征單獨評價和對特征子集評價2類[8],前者可以獲得所有特征的得分排序,而后者根據某種搜索策略獲得特征子集,本文方法屬于前者.
近年來,國內外學者對特征選擇方法做了大量的研究.大多特征選擇方法有一個共同之處,即各種分類能力度量方法都是針對一個特征或特征子集給出描述該特征或特征子集的分類能力大小的一個分值,如卡方檢驗、信息增益、互信息、增益比、Relief、相關性、Fisher評分等指標[9-13].這些方法通常認為分值大的特征比分值小的特征的分類能力強,因而分值大的特征也就會被優先選擇.然而,一些研究已經表明一些分值小的特征也應該被選擇,而且一些有較高分類能力值的特征組合也不總是能得到好的分類結果[8,14-15].以單一值表示特征分類能力大小僅僅是對這個特征分類能力的綜合評價,而忽略了特征對于不同類別的分類能力評價.
針對上述問題,本文既考慮各個特征對不同子類問題的分類能力,又考慮各特征總的分類能力,進而提出了一個新的特征分類能力排序方法.該方法既能確保總分類能力強的特征被選擇,也能確保對子類問題分類能力強但總分類能力不強的特征被選擇,從而獲得特征分類能力更合理的排序,以提高分類準確率.
1 基于子類問題分類能力度量的特征選擇方法
本文提出的基于子類問題分類能力度量的特征選擇方法,簡記為RRSPFS(Round-Robin and subproblem based feature selection).首先計算所有特征對各子類問題的分類能力,并按分類能力降序排列所有特征;然后采用Round-Robin[16]方法計算各子類問題中特征的并集.
1.1 相關定義
2個特征X和Y的信息增益IG(X,Y)為
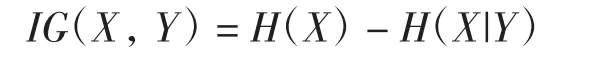
2個特征X和Y的信息增益比GR(X,Y)為
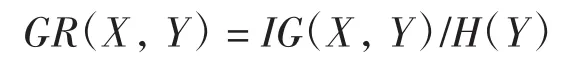
給定具有m個特征k類n個樣本的分類問題D=(F,C),F={f1,f2,…,fm}為特征集合,C={c1,c2,…,cn}為類別特征,ci∈{1,2,…,k}.采用 1-vs-1 形式將其轉化為由任意兩類組成的s個二分類子問題,s=k(k-1)/2,其中每個二分類子問題稱為子類問題或子問題.
本文采用特征對類別特征的信息增益比作為特征的分類能力值,特征fi對第j個子問題的分類區分能力 fca(i,j)為
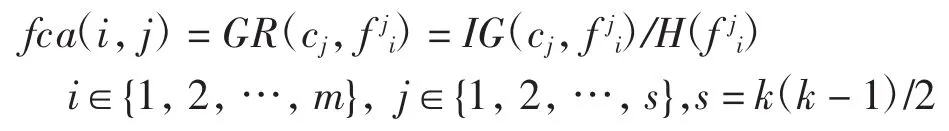
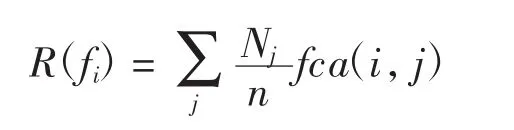
其中:Nj為第j個子問題中所含樣本的個數.特征fi的總分類能力R(f)i是它對各個子問題的分類能力的加權平均.
1.2 RRSPFS特征選擇方法
對于分類問題D=(F,C),計算每個特征fi對第j個子問題的分類區分能力fca(i,j),獲得各個特征對各個子問題的分類能力矩陣(fac(i,j))m×s,將每個子問題中的所有特征按照其分類能力進行降序排列,即可得到各子問題中分類能力由高到低的特征的排列.
采用Round-Robin方法計算各子問題中特征的并集,即首先依次選擇各子問題中排在第一且未被選擇的特征,再選擇排在第二且未被選擇的特征,依此類推,直到所有子問題中特征都被選擇.其中對于屬于各子問題同一等級的特征的選擇次序,按照其總分類能力降序進行.
按照上述方法就得到了各特征的分類能力的降序序列.具體算法流程如下.
算法:特征選擇方法RRSPFS.
輸入:具有n個樣本、m個特征、k類的訓練集D=({fi1,…,fim,c)i}ni=1,F={f1,…,fm},ci∈{1,2,…,k}.
輸出:按分類能力降序排列的特征集合Fm.
令s=k(k-1)/2,Fm= ,T= ;對F中的每一個特征 fi和每個子問題 j,計算 fca(i,j);對每個子問題j,按分類能力 fac(i,j)降序排列所有特征.

對集合T中的特征按照R(f)i降序排列;

2 結果與分析
2.1 數據集
為了驗證RRSPFS算法的正確性和有效性,在4個數據集 Breast、Cancers、GCM 和 Leukemia3 上進行了實驗,它們均下載自http://www.ccbm.jhu.edu/[17].表1給出了這些數據集中含有的類別數(numberofclassifications)k、特征數(number of features)m 及樣本數(number of samples)n.采用傳統的客觀評價指標,即分類預測準確率測試算法的性能.分類預測準確率是將選擇的特征子集作為分類器的輸入獲得的準確率.將本方法與現有的特征分類能力排序算法InfoGain、GainRation、ReliefF進行比較,并使用樸素貝葉斯(NB)、支持向量機(SVM)、K近鄰(KNN)、決策樹(C4.5)、隨機森林(RandomForest)、簡單邏輯回歸(Simple Logistic)和簡單分類與回歸樹(SimpleCart)等 7種分類器進行分類預測.
表1 多類基因表達數據集Tab.1 Multiclass gene expression datasets
2.2 實驗結果及分析
為合理比較這些方法的實驗結果,選擇每種方法獲得的特征排序結果中相同個數的特征,分別使用上述7種分類器在4個數據集上進行分類預測,相應實驗結果見圖1~圖4,橫坐標為排在前面的特征的個數(m),縱坐標為選擇特征后使用上述7種分類器進行分類預測獲得的準確率的平均值(average of accuracies,AACC).
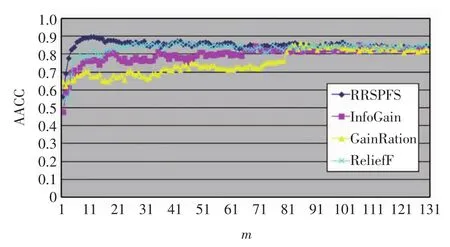
圖1 Breast數據集上的準確率比較Fig.1 Accuracy comparison on Breast dataset
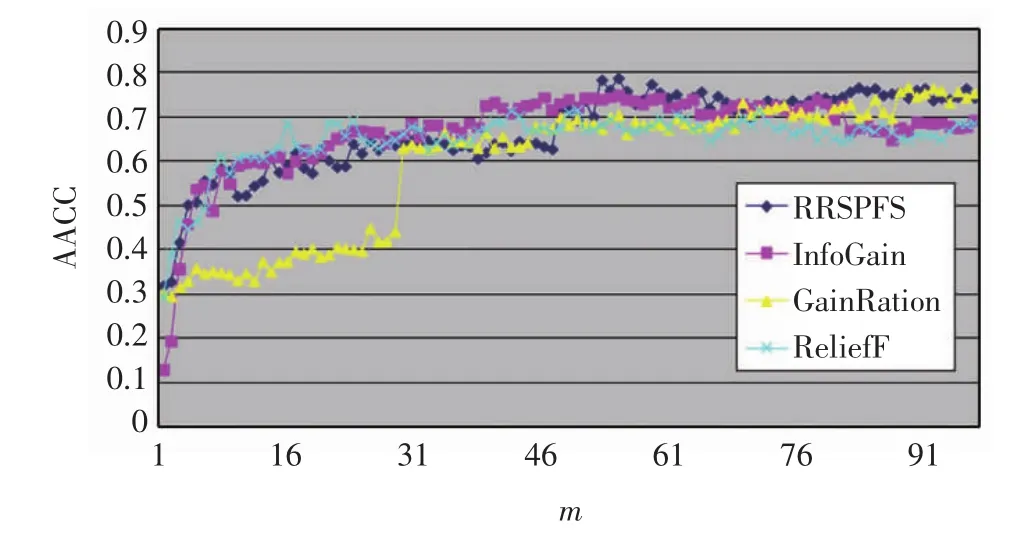
圖2 Cancers數據集上的準確率比較Fig.2 Accuracy comparison on Cancers dataset
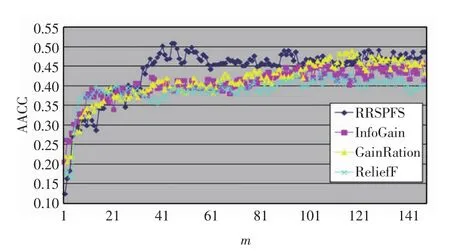
圖3 GCM數據集上的準確率比較Fig.3 Accuracy comparison on GCM dataset
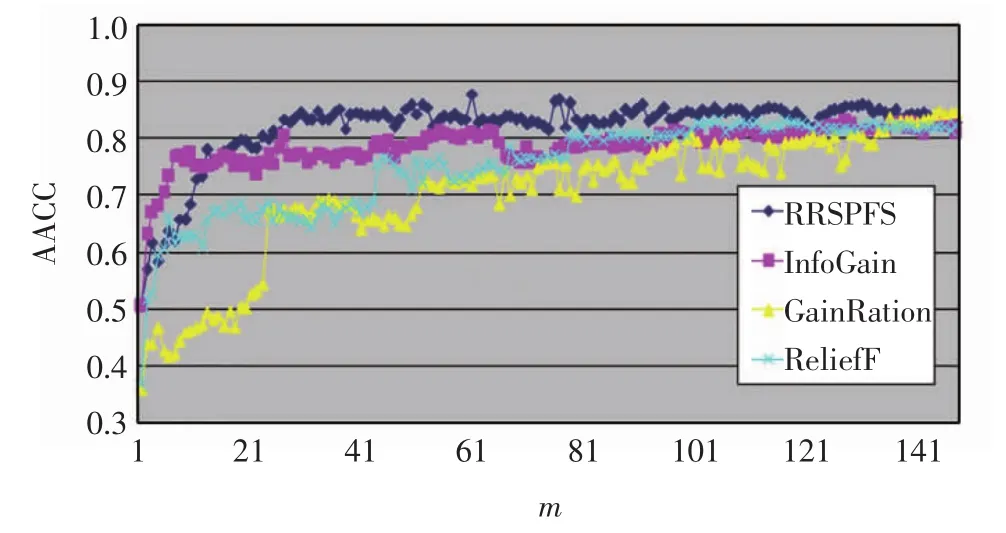
圖4 Leukemia3數據集上的準確率比較Fig.4 Accuracy comparison on Leukemia3 dataset
由圖1~圖4可以看出,RRSPFS與其他3種算法相比,不僅在多數情況下獲得的分類預測準確率更高,而且也能最快獲得最高的準確率.4種算法獲得最高準確率(the highest accuracy,HACC)及其選擇的特征數比較見表2.這些結果表明RRSPFS優于另外3種,能獲得更準確的特征分類能力的排序,并提高了分類器的預測準確率.
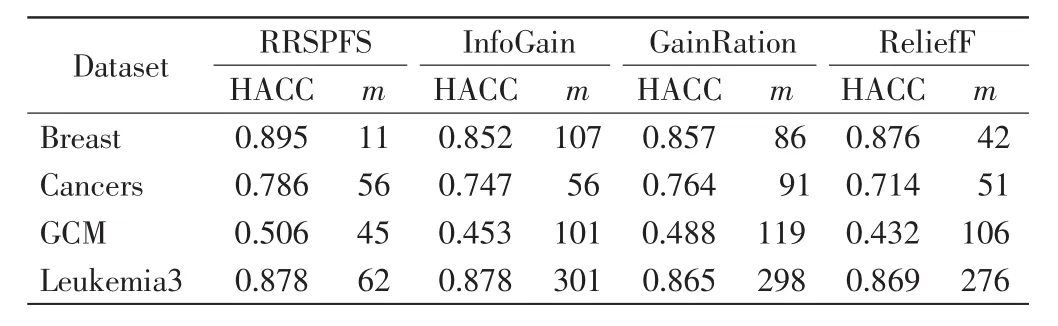
表2 最高準確率(HACC)及其選擇的特征數(m)比較Tab.2 Comparison of highest accuracy(HACC)and number of features(m)selected with highest accuracy
記錄了RRSPFS在Breast數據集上獲得的前21個特征的編號,以及這些特征在另3種算法中的相應排位,表3給出了這21個特征中在另3種算法排名靠后的部分特征.由表3可以看出,有些特征在另3種算法中排序在1000位以后,但它們對子問題的分類能力很強,因此被RRSPFS排在了前面,如特征44、17、115、632、124 等.由圖 1 可以看出,排序在前 21的特征的準確率都高于其他算法,這說明了總分類能力不強但子問題分類能力強的特征應該被排在前面.
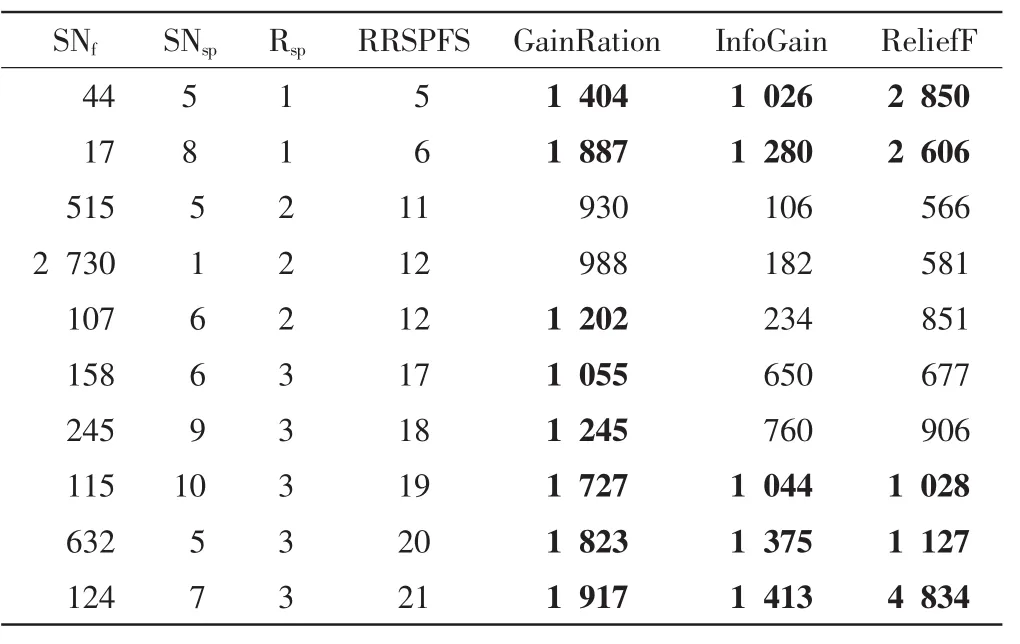
表3 Breast數據集中部分特征在各個方法中的排名比較Tab.3 Comparison of ranking of features selected by each method on Breast dataset
表4給出了Leukemia3數據集上RRSPFS排名前58但在其他算法中排名靠后的部分特征,可以看到特征 3 035、4 007、11 005、6 796、5 009、2 444、2 701 在其他3種算法中排名比較靠后,有的甚至在9 000位之后,而圖4顯示RRSPFS的特征排序得到了更好的準確率,這也表明RRSPFS獲得的特征排名更合理.
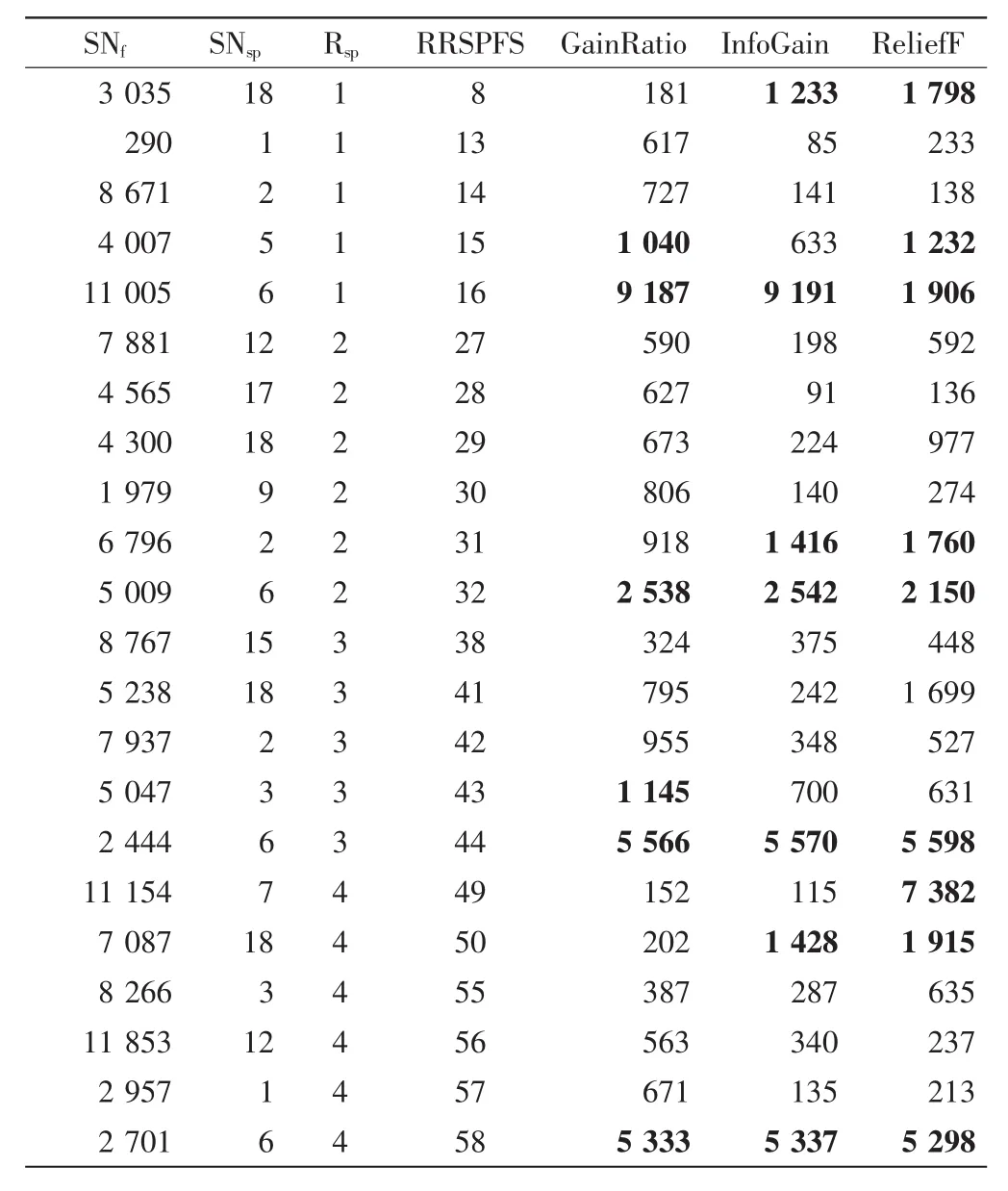
表4 Leukemia3數據集中部分特征在各個方法中的排名比較Tab.4 Comparison of ranking of features selected by each method on Leukemia3 dataset
參考文獻:
[1]JAIN A K,DUIN R P W,MAO J C.Statistical pattern recognition:A review[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(1):4-37.
[2]BOLóN-CANEDO V,SáNCHEZ-MARON~O N,ALONSO-BETANZOS A.Recent advances and emerging challenges of feature selection in the contextofbigdata[J].Knowledge-BasedSystems,2015,86(C):33-45.
[3]GUYON I,GUNN S,NIKRAVESH M,et al.Feature Extraction:Foundations and Applications(Studies in Fuzziness and Soft Computing)[M].New York:Springer,2006.
[4]SAEYS Y,INZA I,LARRAN~AGA P.A review of feature selection techniques in bioinformatics[J].Bioinformatics,2007,23(19):2507-2523.
[5]CHEN G,CHEN J.A novel wrapper method for feature selection and its applications[J].Neurocomputing,2015,159(C):219-226.
[6]RODRIGUES D,PEREIRA L A M,NAKAMURA R Y M,et al.A wrapper approach for feature selection based on Bat Algorithm and Optimum-Path Forest[J].Expert Systems with Applications,2014,41(5):2250-2258.
[7]WANG A G,AN N,CHEN G L,et al.Accelerating wrapper-based feature selection with K-nearest-neighbor[J].Knowledge-Based Systems,2015,83(C):81-91.
[8]YU L,LIU H.Efficient feature selection via analysis of relevance and redundancy[J].Journal of Machine Learning Research,2004,5(12):1205-1224.
[9]PENG H C,LONG F H,DING C.Feature selection based on mutual information:Criteria of max-dependency,max-relevance,and minredundancy[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(8):1226-1238.
[10]KONONENKO I.Analysis and extension of Relief[C]//Proceedings of theEuropeanConferenceonMachineLearning,Berlin:Springer,1994:171-182.
[11]FENG J,JIAO L C,LIU F,et al.Unsupervised feature selection based on maximum information and minimum redundancy for hyperspectral images[J].Pattern Recognition,2016,51(C):295-309.
[12]KOPRINSKA I,RANA M,AGELIDIS V G.Correlation and instance based feature selection for electricity load forecasting[J].Knowledge-Based Systems,2015,82:29-40.
[13]WANG J,WEI J M,YANG Z,et al.Feature selection by maximizing independent classification information[J].IEEE Transactions on Knowledge and Data Engineering,2017,29(4):828-841.
[14]WANG J Z,WU L S,KONG J,et al.Maximum weight and minimum redundancy:A novel framework for feature subset selection[J].Pattern Recognition,2013,46(6):1616-1627.
[15]WANG S Q,WEI J M.Feature selection based on measurement of ability to classify subproblems[J].Neurocomputing,2017,224(C):155-165.
[16]FORMAN G.A pitfall and solution in multi-class feature selection for text classification[C]//Proceedings of the 21st International Conference on Machine Learning,New York:ACM,2004:38-46.
[17]TAN A C,NAIMAN D Q,XU L,et al.Simple decision rules for classifying human cancers from gene expression profiles[J].Bioinformatics,2005,21(20):3896-3904.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
