基于大腦情感學習模型和自適應遺傳算法的混沌時間序列預測?
2018-05-08 02:03:28梅英1譚冠政1劉振燾3武鶴2
物理學報 2018年8期
梅英1)2) 譚冠政1) 劉振燾3) 武鶴2)
1)(中南大學信息科學與工程學院,長沙 410083)
2)(湖南文理學院電氣與信息工程學院,常德 415000)
3)(中國地質大學自動化學院,武漢 430074)
(2017年9月22日收到;2018年2月8日收到修改稿)
1 引 言
混沌時間序列預測在地磁活動預測[1]、天氣預測[2]、太陽黑子數預測[3]等方面應用廣泛.近年來,國內外學者提出了多種混沌預測模型,如:人工神經網絡(回聲狀態網絡[4,5]、極限學習機[6]和遞歸神經網絡[7])等、局部多項式模型[8]、自回歸模型[9]和支持向量機[10]等.混沌系統往往具有高度的非線性特性,而神經網絡由于具有良好的非線性運算能力已成為混沌預測的有力工具.然而,隨著系統復雜度的不斷增加,傳統神經網絡在混沌預測中的運算速度與準確性難以滿足要求.因此,需要借助神經科學上的新發現,發展準確高效的神經網絡新模型,為系統的下一步決策提供科學指導.
神經心理學研究表明[11],情感是人類智能的重要組成部分.目前,情感智能為新一代人工智能的發展提供了新思路.根據神經生理學上的研究發現[12],大腦中的杏仁體能根據感官刺激信息產生情感并鞏固記憶,避免重復學習.2001年,Balkenius和Morén[13]提出了大腦情感學習(brain emotional learning,BEL)模型,該模型根據哺乳動物大腦邊緣系統的結構,模擬了杏仁體和眶額皮質之間的情感學習機制,具有結構簡單、計算復雜度低和運算速度快的優點.近年來,BEL模型在混沌時間序列預測領域取得了廣泛的應用.Babaie和Karimizandi[14]設計了基于BEL模型的地磁風暴預警系統.Abdi等[15]將BEL模型用于短時交通預測.Sharaf i等[16]和Milad等[17]將BEL模型用于混沌時間序列預測.盡管這些工作取得了一定的效果,但在BEL模型應用中,均采用了一種基于獎勵信號的強化學習方法調節模型參數,使得BEL模型的輸出對獎勵信號有明顯的依賴性,而關于獎勵信號的設定方法,目前尚沒有統一的規定.以上研究者只是根據不同的應用提出了不同的獎勵信號設定方法,而這些方法缺乏通用性.
為了增強BEL模型的通用性,提高模型精度,研究者們提出采用智能算法優化其參數.Dorrah[18]采用粒子群算法優化BEL控制器參數,實驗結果表明優化后的BEL控制器在魯棒性和響應時間方面優于傳統比例-積分-微分(proportion integration dif f erentiation,PID)控制器,但當待優化參數過多時算法容易陷入局部最優.Mei等[19]采用遺傳算法優化BEL模型參數,優化后的BEL模型在分類正確率方面明顯提高,但在處理高維多分類數據時收斂速度變慢.Lotf i和Akbarzadeh[20]設計了競爭型BEL模型并采用遺傳算法優化其參數,增強了BEL模型處理高維多分類數據的能力,但當優化目標模型較復雜時,遺傳算法容易出現局部收斂.遺傳算法由于交叉與變異概率固定,其靈活度不高,搜索能力受限.
為了克服遺傳算法的缺點,本文提出采用自適應遺傳算法(self-adaptive genetic algorithm,AGA)優化BEL模型,即自適應遺傳算法和大腦情感學習模型結合形成AGA-BEL模型用于混沌時間序列預測.在自適應遺傳算法中,通過設計合理的自適應交叉概率和變異概率,讓染色體能夠根據適應度值自適應地進行交叉與變異操作,優化調節BEL模型中杏仁體和眶額皮質的權值和閾值.該方法可以提高算法的靈活性,增強算法的全局和局部搜索能力.因此,AGA-BEL模型一方面可以充分利用自適應遺傳算法在廣域空間中的尋優功能,另一方面又能利用BEL算法的快速學習能力引導自適應遺傳算法向最優解快速逼近,從而獲得最佳的模型參數.將AGA-BEL模型用于Lorenz混沌時間序列和實際地磁Dst指數序列的仿真預測,實驗結果表明,AGA-BEL模型的預測結果能有效地反映混沌時間序列的變化趨勢,預測精度高,且計算速度和穩定性明顯優于傳統神經網絡.
2 大腦情感學習模型
大腦中的邊緣系統是負責調節情感的主要部位[12],邊緣系統中控制情感反應的一個重要組織叫杏仁體,它可以接收來自不同感覺聯合區的信息,負責產生情感并鞏固記憶.感官刺激可以通過兩條長短不同的反射通路到達杏仁體,在長反射通路中,感官刺激經過丘腦到達視覺皮層,被深度加工處理后到達杏仁體;在短反射通路中,感官刺激到達丘腦后直接送往杏仁體.
受神經生理學研究的啟發,Balkenius和Morén[13]提出了大腦情感學習模型,該模型主要由丘腦、感官皮質、眶額皮質和杏仁體四大部分組成,如圖1所示.杏仁體和眶額皮質是兩個主要組成部分.情感學習主要發生在杏仁體內,杏仁體負責根據刺激產生情感輸出并促進情感記憶,避免重復學習;眶額皮質主要對杏仁體的學習起輔助調節作用,避免出現過學習和欠學習現象.

圖1 大腦情感學習模型結構框圖Fig.1.Framework of brain emotional learning model.
由圖1可知,杏仁體接收丘腦信號Ath、感官輸入信號SI(sensor inputs)及獎勵信號Rew(reward);眶額皮質接收獎勵信號Rew及感官輸入信號SI.大腦情感學習模型的輸出是對感官輸入信號的響應,情感學習的過程即為大腦情感學習模型的權值調節過程.根據大腦情感學習模型的定義[13],杏仁體和眶額皮質的權值調節規律分別為
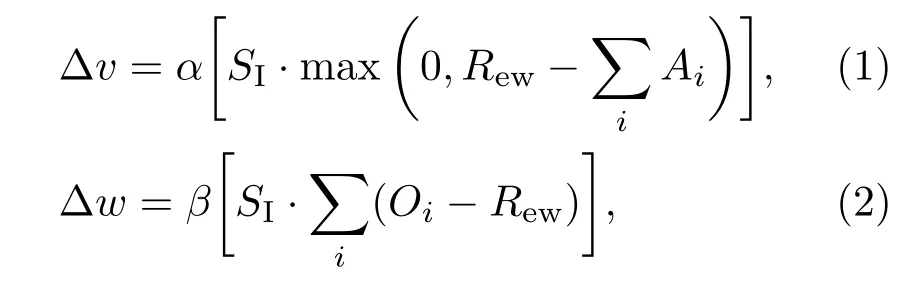
式中?v表示杏仁體權值變化率;?w表示眶額皮質權值變化率;i是表示感官輸入信號個數的變量;Ai和Oi分別表示杏仁體和眶額皮質的輸出節點;α和β表示學習率,分別控制杏仁體和眶額皮質的學習速度.
從(1)式和(2)式可以看出,獎勵信號Rew對杏仁體和眶額皮質的權值調整起重要作用.因此,大腦情感學習的效果對獎勵信號有明顯的依賴性,而關于獎勵信號的設定方法,目前尚沒有統一的規定.為了增強大腦情感學習模型的通用性,提高模型精度,本文采用自適應遺傳算法優化調節其權值,具體方法見下一節.
3 AGA-BEL實現方法
3.1 大腦情感學習算法
采用基于自適應遺傳算法的監督學習代替基于獎勵信號的強化學習,能優化調節大腦情感學習模型中杏仁體和眶額皮質的權值,因此需要對基本大腦情感學習模型進行改進,去掉獎勵信號.此外,為了防止神經元在學習過程中出現飽和狀態,可以根據大腦中杏仁體和眶額皮質間的交互機制,在杏仁體和眶額皮質神經元中添加閾值,分別為ba和bo.杏仁體和眶額皮質是負責情感學習的主要組成部分,對于任意輸入模式,都是在二者的共同學習作用下形成輸出模式.基于大腦情感學習模型的改進網絡如圖2所示.
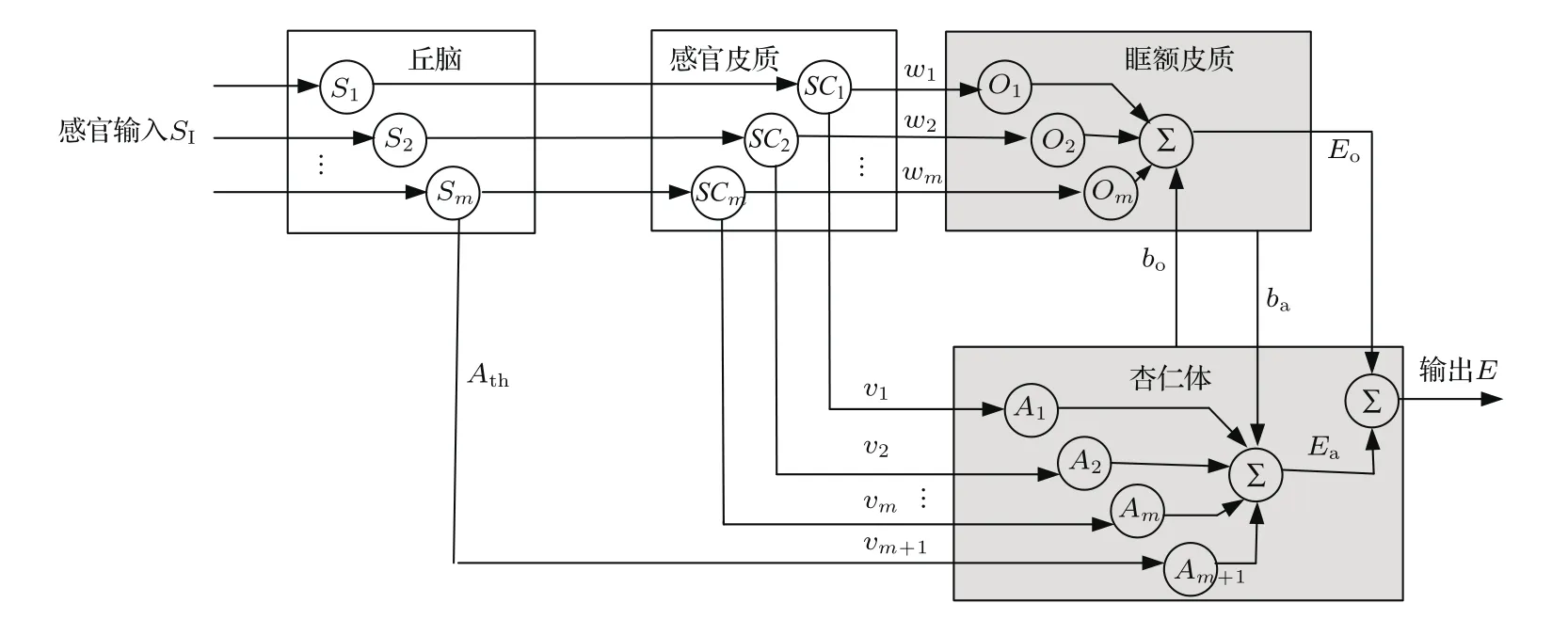
圖2 改進大腦情感學習網絡Fig.2.Improved brain emotional learning network.
在圖2所示的網絡中,代表情感刺激的所有感官輸入信號SI表示為
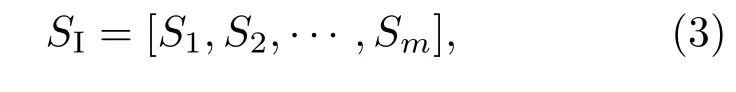
其中m表示感官輸入信號數目.
根據大腦中的情感信息處理機制,在短反射通路中,感官輸入信號SI中的最大值通過丘腦傳遞給杏仁體,表示為
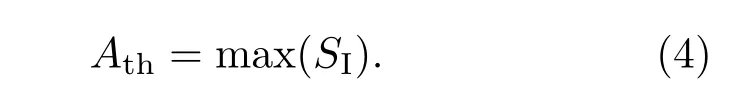
對于每個感官輸入信號Si,杏仁體中總存在相應節點Ai接受信號,表示為

其中vi表示杏仁體各節點間的權值,Ath表示丘腦信號.
杏仁體接收每個感官輸入信號Si、丘腦信號Ath及閾值ba,則杏仁體的內部輸出表示為
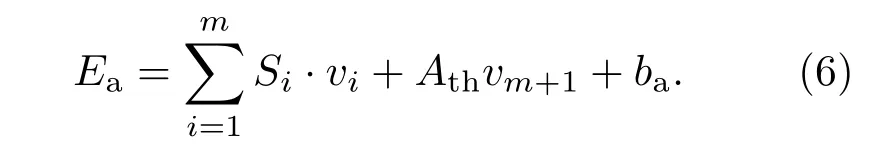
在眶額皮質單元中,也存在相應節點Oi接受每個感官輸入信號Si,表示為
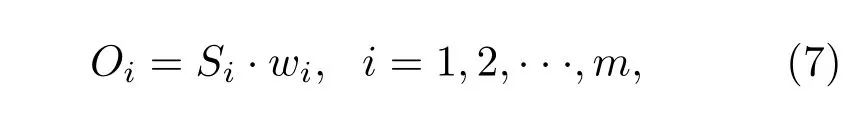
其中wi表示眶額皮質各節點間的權值.
眶額皮質接收每個感官輸入信號Si和閾值bo,則眶額皮質的內部輸出E表示為

在杏仁體和眶額皮質的相互學習下,產生大腦情感學習模型的總體輸出E,表示為

根據以上描述,大腦情感學習主要包括杏仁體和眶額皮質的學習,學習過程即為二者權值和閾值的調節過程,其協同工作的結果決定大腦情感學習模型的總體輸出.采用不同的方法調整權值和閾值,將會使大腦情感學習的效果產生很大的差別.本文將自適應遺傳算法引入改進后的大腦情感學習網絡,實現了杏仁體和眶額皮質權值與閾值的優化調整.
3.2 自適應遺傳算法
為了使遺傳算法具有更強的自適應性能,需要對遺傳參數動態化以提高算法的靈活性,這樣改進的遺傳算法稱為自適應遺傳算法[21].本文根據染色體的適應度值設計自適應交叉概率和變異概率,具體遺傳操作見以下描述.
3.2.1 染色體編碼
在自適應遺傳算法中,將待優化的參數編碼形成的字符串稱為染色體.由于BEL網絡中的每個權值與閾值為實數,本文采用實數編碼方式以提高參數的提取精度.將BEL網絡中待優化的參數按順序排列在染色體基因序列上,以第3.1節中圖2所示的BEL網絡為例,染色體編碼格式為其中v1,···,vm+1表示杏仁體各節點間的權值;ba為杏仁體神經元閾值;w1,···,wm表示眶額皮質各節點間的權值;bo為眶額皮質神經元閾值;m表示感官信號數目,每條染色體包含的基因數為2m+3.

3.2.2 適應度函數
適應度函數(fitness function)用于指導自適應遺傳算法的搜索進程,該函數的設計關系到算法的收斂速度和預測精度.一般而言,適應度函數由目標函數轉換而成.本文AGA-BEL模型的預測誤差越小表明染色體分配的參數越優,而求目標函數問題是最小值問題.因此,定義適應度函數為

式中n表示樣本數量;yl表示第l種輸入模式下模型的預測值;?yl表示第l種輸入模式下模型的輸出期望值;F(Ch)表示以染色體Ch為網絡參數時的平均預測誤差.根據適應度函數選出的最優染色體,即為杏仁體和眶額皮質權值與閾值的最佳組合.
3.2.3 遺傳算子
在選擇操作中,采用輪盤賭和最優個體保留策略選擇交配組[19].在輪盤賭方法中,每條染色體被選擇的概率與其適應度值成正比.設第j條染色體的適應度值為fj,則該個體被選擇的概率pj表示為
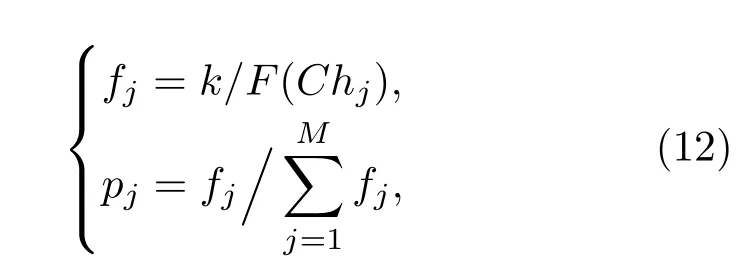
式中M表示種群大小;k表示相關系數;F(Chj)可以根據適應度函數計算出來.由于概率選擇存在隨機性誤差,為了提高遺傳算法的收斂性,采用最優個體保留策略,其思想是讓適應度最高的個體直接參與下一步遺傳操作.
在自適應交叉操作中,交叉概率pc計算公式為
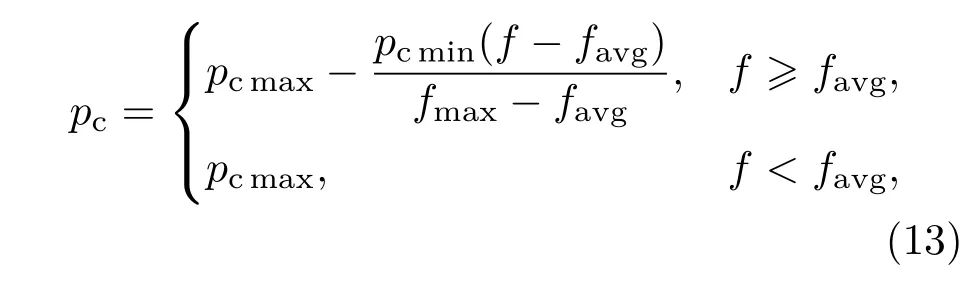
式中pcmax和pcmin分別為預先設定的最大交叉概率和最小交叉概率;fmax和favg分別為群體最大適應度值及平均適應度值;f為當前父代雙親中適應度值較大者.
在交叉操作中,采用算術交叉方式,表示為
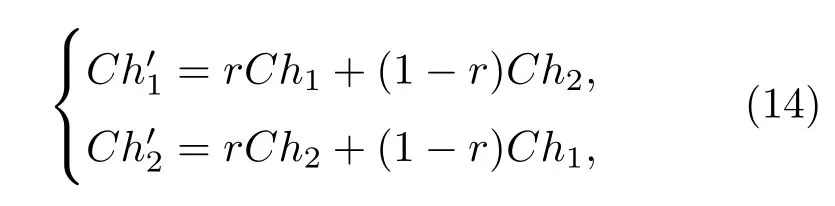
式中Ch1和Ch2代表兩個父個體;代表兩個子個體;r為隨機數,取值范圍為[0,1].
在自適應變異操作中,首先判斷每條染色體是否需要變異,如果需要,則根據父個體的適應度值確定變異概率pm,表示為

式中pmax和pmin分別為預先設定的最大變異概率和最小變異概率;fmax和favg分別為群體最大適應度值與平均適應度值;f′為需要變異個體的適應度值.
在上述遺傳操作中,交叉和變異過程隨著個體的適應度值動態改變,從而增強了算法的靈活性,加快了算法的收斂速度與精度.經過自適應遺傳操作選出的最優染色體,代表了BEL網絡中杏仁體和眶額皮質最佳權值與閾值的組合,將其更新至BEL網絡中,通過網絡訓練,即能得到預測結果.
3.3AGA-BEL算法步驟

AGA-BEL算法的偽代碼如下.
4 仿真預測實驗
實驗中采用Intel CPU Core i7-3770處理器,主頻3.4 GHz,8 GB內存,64位Windows 7操作系統,Matlab 2014b編程環境.
4.1 數據處理
采用神經網絡進行混沌時間序列預測時,為了獲得更好的預測效果,需要對預測數據進行歸一化和反歸一化處理[22].設一時間序列原始數據X=(x1,x2,···,xN),X∈RN,進行歸一化的方法為
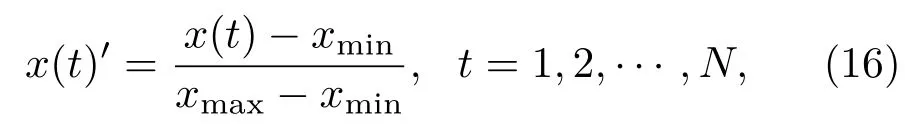
式中N為時間序列的總長;x(t)表示原始值;x(t)′表示歸一化后的值,x(t)′∈[0,1];xmin表示原始數據序列中的最小值;xmax表示最大值.
設神經網絡的仿真輸出為Y=(y1,y2,···,yN),Y∈[0,1],進行反歸一化的方法為
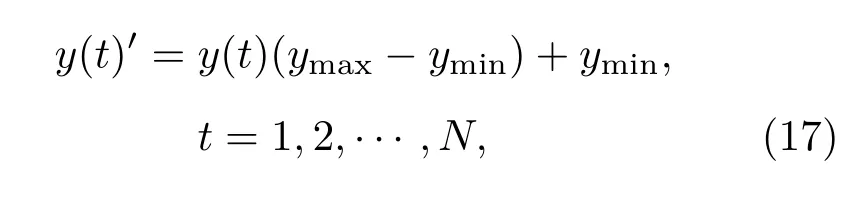
式中y(t)表示仿真輸出值;y(t)′表示反歸一化后的值,y(t)′∈RN;ymin表示仿真輸出數據中的最小值;ymax表示最大值.
相空間重構即通過一維時間序列反向構造出原系統的相空間結構.Takens定理[23]中說明了系統中任一分量的演化都是由與之相關的其他分量決定的.設x為觀測到的分量,x(t),t=1,2,···,N為要研究的混沌時間序列,其重構的相空間表示為:X(t)={x(t),x(t?τ),···,x[t?(m?1)τ]},t=(m?1)τ+1,···,N,選擇合適的延遲時間τ和嵌入維數m,可以預測未來t+η時刻的值x(t+η),其中,η為預測步長,當η=1時,為單步預測;當η>1時,為多步預測.本文對混沌時間序列開展單步預測的仿真實驗研究.
4.2 預測器性能評價
本文主要驗證AGA-BEL模型在預測精度、運算速度和穩定性方面的性能.預測精度采用平均絕對誤差(mean absolute deviation,Mad)[24]、均方誤差(mean square error,Mse)[25]、平均絕對百分比誤差(mean absolute percentage error,Mape)[24]和相關系數(correlation coefficient,Cor)[25]4個指標來衡量.設y(t)為模型的預測值,?y(t)為混沌時間序列的實際觀測值,n為樣本數量,4個指標計算如下:
1)平均絕對誤差Mad

4)相關系數Cor

關于模型的運行效率,可以采用在相同的計算環境下,執行同樣任務所需的時間來評價;關于模型的穩定性,可以采用在相同的計算環境下重復性實驗結果的統計方差來評價[24].
4.3 Lorenz混沌時間序列預測
Lorenz系統可以作為許多混沌系統的精確模型,此模型的動力學方程式為一組三元常微分方程[3],表示為

當選取參數a=10,b=8/3,c=28,x(0)=?1,y(0)=0,z(0)=1時,(22)式具有混沌特性.取采樣時間為0.05,采用四階Runge-Kutta法迭代產生6000組混沌時間序列.本文使用前4000組數據作為訓練樣本,后2000組數據作為測試樣本,驗證AGA-BEL模型對Lorenz-x(t)的單步預測效果.
4.3.1 參數設置
首先對Lorenz混沌時間序列進行歸一化處理和相空間重構.根據飽和關聯維數法和互信息函數法[24]分別確定嵌入維數m=4,延遲時間τ=1.采用單步預測方式,設置預測步長η=1.構造一個輸入數據形式為[x(t),x(t?1),x(t?2),x(t?3)]的四維向量作為AGA-BEL預測模型的輸入信號,模型輸出用一維向量表示為x(t+1).
AGA-BEL模型參數設計包括BEL網絡參數設計與AGA遺傳參數設計兩部分.采用十折交叉驗證法得到模型的最佳參數.在BEL神經網絡設計中,輸入層和輸出層的節點數分別由輸入和輸出數據的維度確定,因此設置輸入節點數為4,輸出節點數為1,隱含層節點數由經驗公式和交叉驗證確定為9,網絡初始權值和閾值的取值范圍為[?1,1].在自適應遺傳算法設計中,取種群大小為100,最大進化代數為100,染色體長度為11,設定最大交叉概率和最小交叉概率分別為pcmax=0.8和pcmin=0.3,最大變異概率和最小變異概率分別為pmax=0.1和pmin=0.001.經過網絡訓練,將仿真數據進行反歸一化處理,最后得到Lorenz-x(t)的預測值.
4.3.2 Lorenz序列預測結果
在Lorenz-x(t)混沌預測中,圖3(a)代表4000個訓練數據的Lorenz-x(t)預測曲線,從圖中可以看出,綠色的預測曲線可以很好地擬合藍色的實際曲線,均方誤差Mse為0.0001537.對應地,圖3(b)代表4000個訓練數據的預測誤差曲線,從圖中可以看出,各點預測誤差均在零點附近的較小范圍內波動,說明AGA-BEL模型的預測誤差小.
圖4(a)代表2000個測試數據的Lorenz-x(t)預測曲線,從圖中可以看出,綠色的預測曲線可以很好地擬合紅色的實際曲線,均方誤差Mse為0.0001336.對應地,圖4(b)代表2000個測試數據的預測誤差曲線,從圖中可以看出,各點預測誤差均在零點附近的較小范圍內波動,說明AGA-BEL模型對Lorenz-x(t)預測的有效性.
從圖3和圖4所示的Lorenz-x(t)預測曲線和誤差曲線可以看出,無論對訓練數據還是測試數據,預測曲線都可以很好地擬合實際曲線,說明AGA-BEL模型的預測結果能有效地反映混沌時間序列的變化趨勢,預測精度高,魯棒性好.
圖5表示AGA-BEL模型對Lorenz-x(t)混沌時間序列數據的擬合性能,Cor值表示模型預測值與觀測值之間的相關系數.從圖5(a)和圖5(b)中可以看出,在訓練集與測試集上的相關系數分別為0.9989和0.9999,說明AGA-BEL模型對Lorenzx(t)混沌時間序列數據具有很好的擬合性能.
4.3.3 與其他方法比較
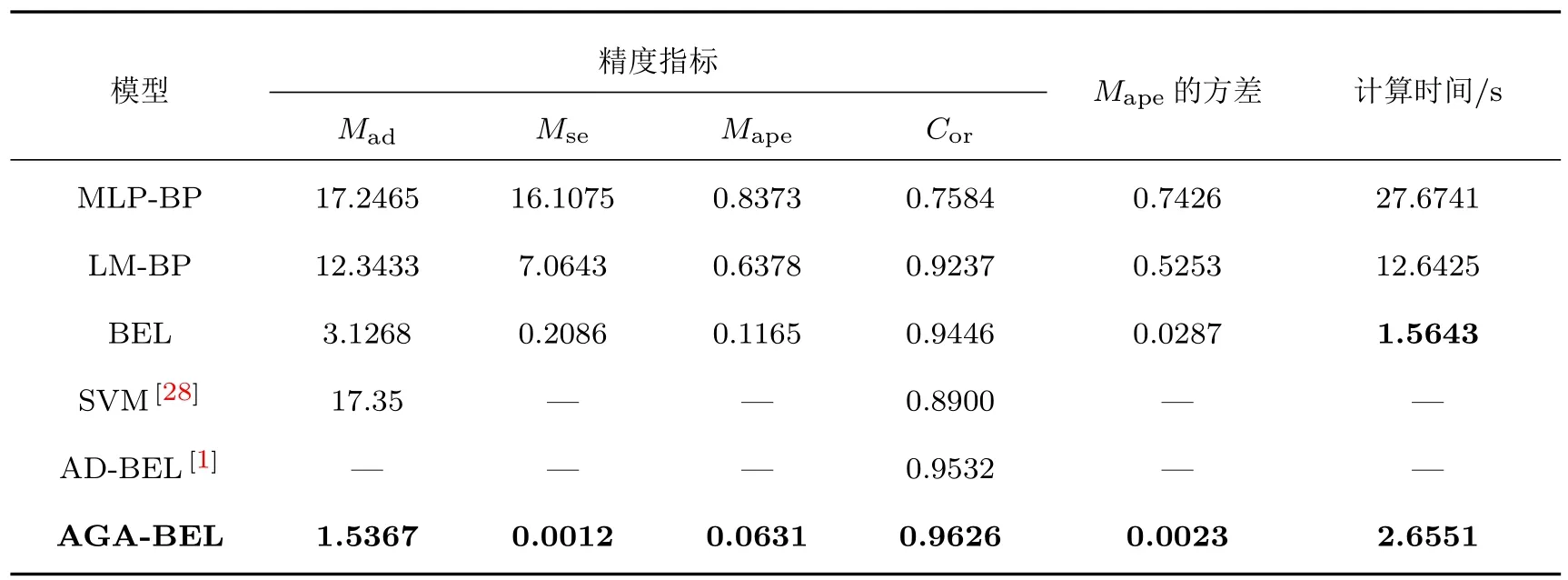
為了在預測精度、速度和穩定性上對比驗證AGA-BEL模型的性能,在相同的實驗條件下,分別采用MLP-BP[26],LM-BP[27]和基本BEL模型[13]對Lorenz時間序列進行單步預測.每種模型獨立運行50次,統計得到平均絕對誤差Mad,均方誤差Mse,平均絕對百分比誤差Mape,線性相關度Cor及計算時間的平均值.其中,Mape是反映預測值與實際值之間偏離程度的重要指標,模型的穩定性采用Mape的方差來評價[24].表1給出了不同模型對Lorenz時間序列的預測結果.
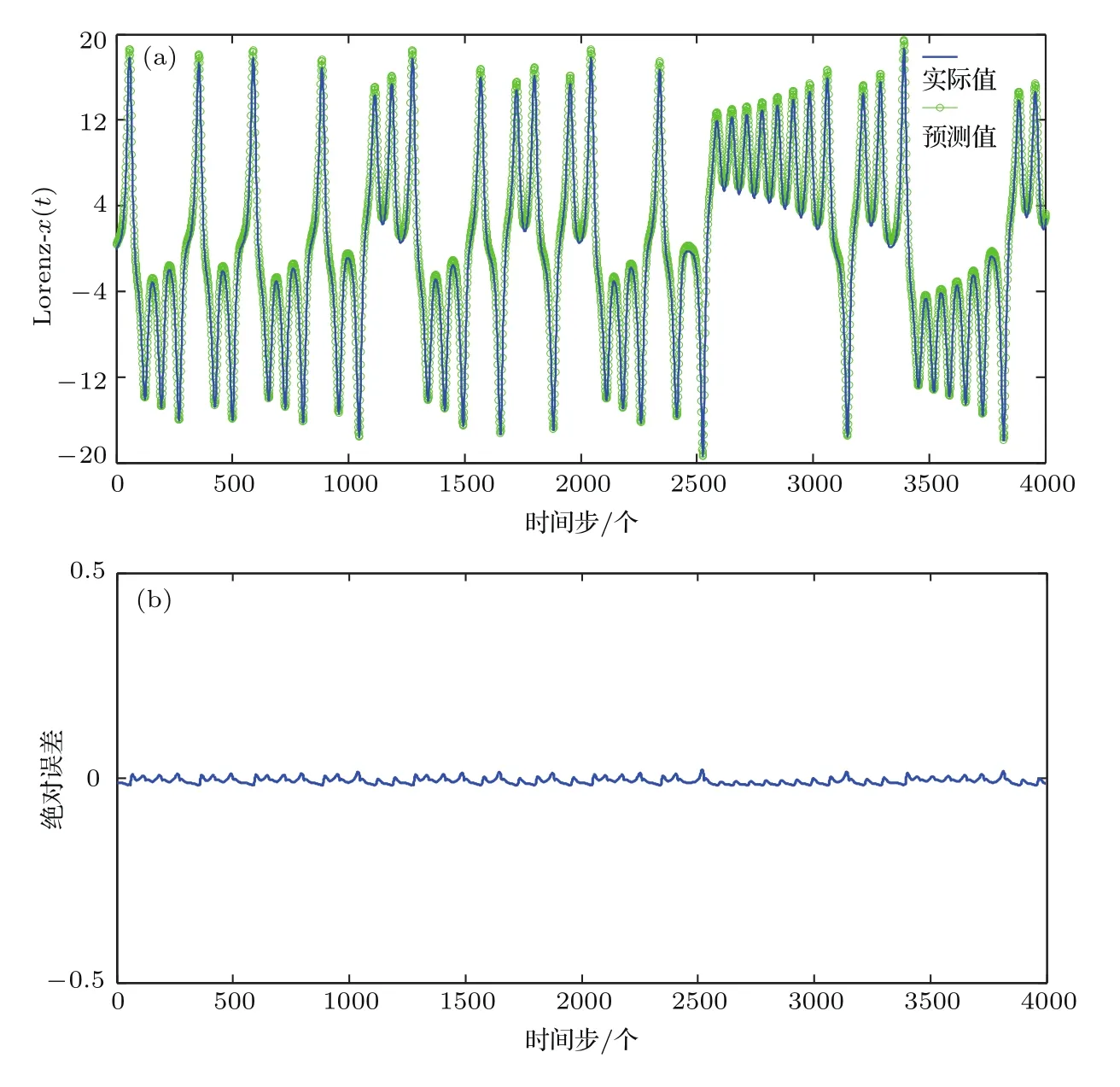
圖3 Lorenz-x(t)時間序列訓練集預測結果 (a)預測曲線;(b)誤差曲線Fig.3.Result of Lorenz-x(t)prediction on training datas:(a)Prediction curve;(b)error curve.
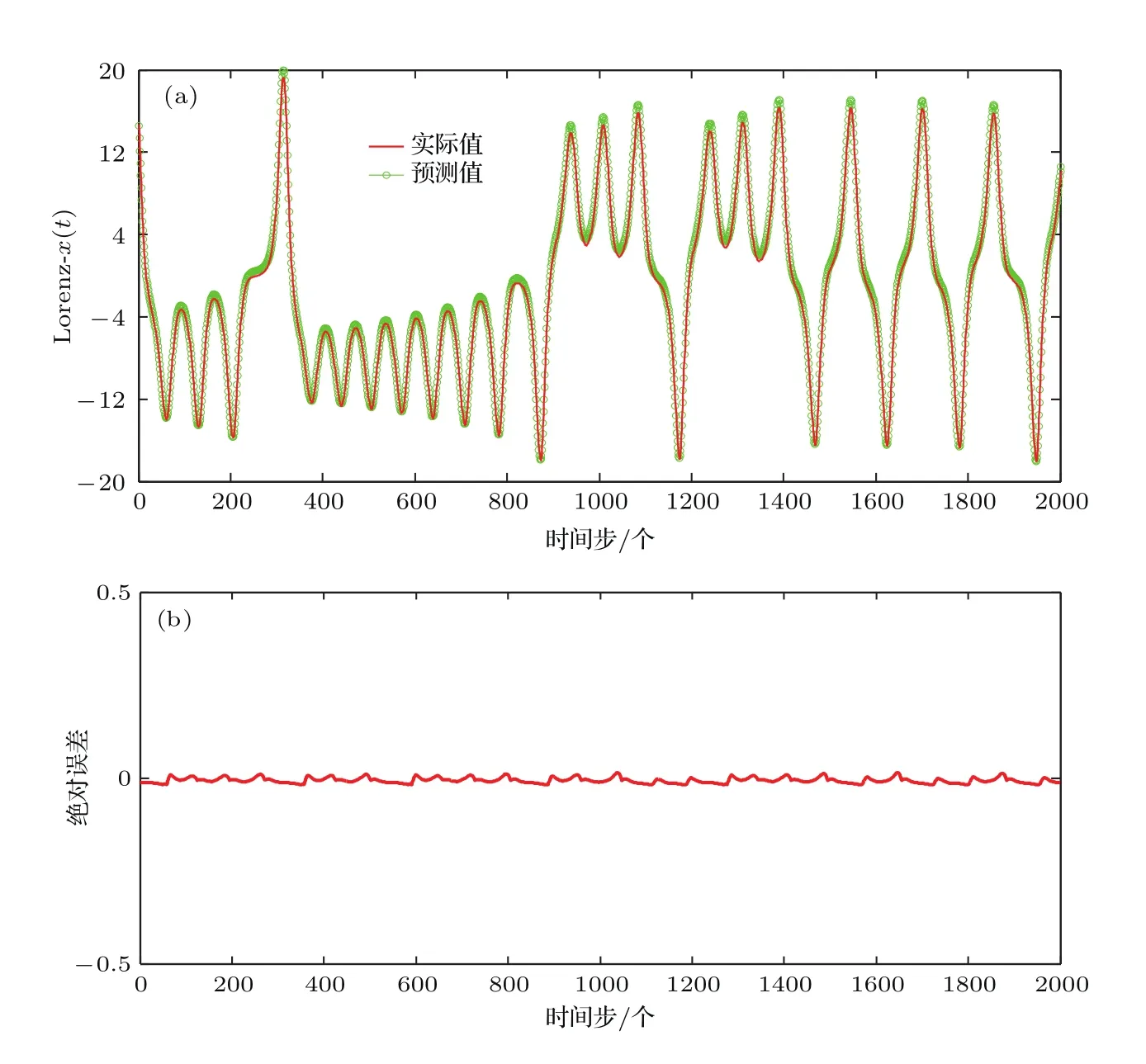
圖4 Lorenz-x(t)時間序列測試集預測結果 (a)預測曲線;(b)誤差曲線Fig.4.Result of Lorenz-x(t)prediction on testing datas:(a)Prediction curve;(b)error curve.
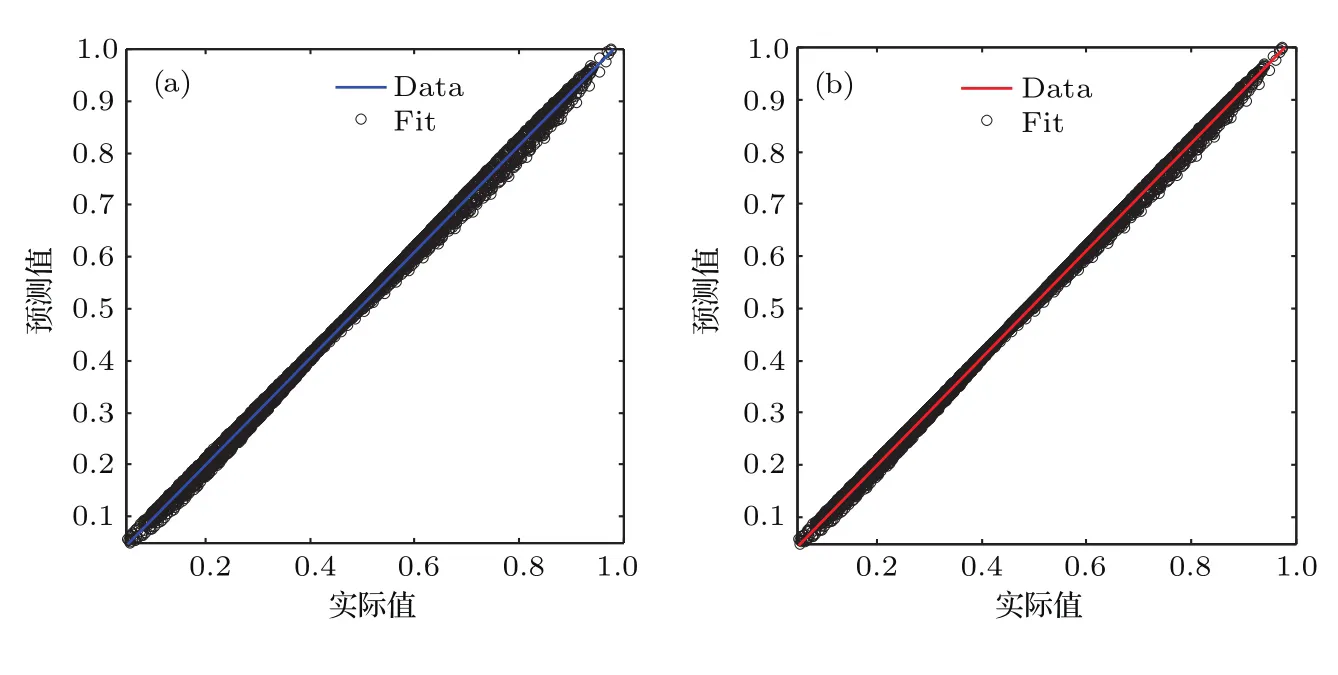
圖5 Lorenz時間序列預測線性相關性 (a)訓練集;(b)測試集Fig.5.Linear correlation of Lorenz time series prediction:(a)Training datas;(b)testing datas.

表1 不同模型對Lorenz-x(t)單步預測的結果比較Table 1.Lorenz-x(t)prediction comparisons of dif f erent models(1-step).
從表1中可以看出,相對于其他方法,在預測精度方面,AGA-BEL預測模型的Mad,Mse及Mape均最小,Cor最高,說明AGA-BEL在混沌時間序列的預測精度上具有明顯的優勢.在預測穩定性方面,AGA-BEL的平均絕對百分比誤差Mape的方差最小,說明其預測的穩定性最好.在計算時間方面,BEL模型與AGA-BEL模型所用的計算時間遠遠少于傳統的BP網絡,由于AGA-BEL中執行了遺傳算法的迭代運算,所以計算時間較基本BEL模型長.總體看來,在Lorenz混沌時間序列預測中,較其他傳統方法,AGA-BEL模型在預測精度、運行速度和穩定性上均具有明顯優勢.
4.4 磁暴環電流Dst指數預測
磁暴環電流(disturbance storm time,Dst)指數[1]作為一種通用表征磁暴強度的地磁指數,在地磁擾動研究中具有重要作用,對防御空間天氣災害方面具有重要價值.本文的Dst指數數據集來自于世界地磁數據中心(http://wdc.kugi.kyotou.ac.jp).選取發生在2000年間的1000個磁暴環電流指數Dst數據序列作為測試數據,時間間隔為1 h,這是一個典型的混沌時間序列.本文通過研究Dst指數的變化規律,建立提前1 h預報Dst指數的方法.
4.4.1 參數設置
采用AGA-BEL模型對Dst指數時間序列進行單步預測.首先按上個實驗的方法對Dst數據進行歸一化處理和相空間重構.根據飽和關聯維數法和互信息函數法[24]確定嵌入維數m=4和延遲時間τ=1.采用單步預測方式,設置預測步數η=1.采用代表Dst指數的時間序列:Dst(t),Dst(t?1),Dst(t?2),Dst(t?3),預測t+1時刻的Dst指數值Dst(t+1).在構造BEL網絡時,設置網絡輸入層的神經元為4個,輸出神經元為1個.構造一個輸入數據形式為[Dst(t),Dst(t?1),Dst(t?2),Dst(t?3)]的四維向量作為感官輸入信號,預測模型輸出用一維向量Dst(t+1)表示.基于AGA-BEL的Dst指數預測網絡簡化表示如圖6所示.

圖6 基于AGA-BEL的Dst指數預測模型Fig.6.AGA-BEL prediction model for Dst index.
設置輸入節點數為4,輸出節點數為1,隱含層節點數由經驗公式和交叉驗證確定為10,網絡初始權值的取值范圍為[?1,1].在自適應遺傳算法設計中,取種群大小為100,最大進化代數為50,染色體長度為11,設定最大交叉概率和最小交叉概率分別為pcmax=0.6和pcmin=0.1,最大變異概率和最小變異概率分別為pmax=0.1和pmin=0.003.經過網絡訓練,將仿真數據進行反歸一化處理,得到Dst指數序列的預測結果.
4.4.2 Dst指數預測結果
根據磁暴的4個級別:?50 圖7 Dst指數預測結果Fig.7.Result of Dst index prediction. 由圖8所示的誤差曲線可以看出,各點的預測誤差在零點附近的較小范圍內波動,說明預測誤差小,從而驗證了AGA-BEL模型在磁暴事件預測問題上的有效性. 圖8 Dst指數預測誤差曲線Fig.8.Error curve of Dst index prediction. 為了進一步量化評估AGA-BEL模型的預測性能,計算了預測模型的均方誤差Mse以及預測值與實際值的相關系數Cor.圖9代表均方誤差曲線,當算法進化到第50代時網絡完全收斂,均方誤差Mse為0.0011859. 圖10表示在Dst指數預測中的線性相關性,其中,Y表示模型預測值,T表示Dst指數的實際值,Cor表示二者之間的相關系數.從圖10(a)和圖10(b)中可以看出,在訓練集與測試集上的相關系數分別為0.9555和0.9697,說明AGA-BEL模型對于Dst指數數據集具有很好的擬合性能. 圖9 Dst指數預測均方誤差曲線Fig.9.Mseof Dst index prediction. 圖10 Dst指數預測線性相關性 (a)訓練集;(b)測試集Fig.10.Linear correlation of Dst index prediction:(a)Training datas;(b)testing datas. 為了在精度、速度和穩定性上對比驗證AGA-BEL的性能,在相同的實驗條件下,分別采用MLP-BP[26],LM-BP[27]和基本BEL模型[13]對Dst指數進行單步預測.每種模型獨立運行50次,統計得到Mad,Mse,Mape,Cor及計算時間的平均值.根據文獻[24],模型的穩定性采用Mape的方差來評價.表2給出了不同模型對Dst指數的預測結果. 表2 不同模型對Dst指數單步預測的結果比較Table 2.Dst index prediction performance comparisons of dif f erent models(1-step). 從表2可以看出,相對于其他方法,AGA-BEL預測模型的Mad,Mse及Mape均最小,Cor最大,說明AGA-BEL模型的預測精度最高.在預測穩定性方面,AGA-BEL模型Mape的方差最小,說明其預測的穩定性最好.在計算時間方面,BEL模型與AGA-BEL模型所用時間遠遠少于傳統的BP網絡.AGA-BEL模型中因執行了遺傳算法的迭代運算,所以計算時間比基本BEL模型稍長.總體看來,AGA-BEL模型在地磁Dst指數預測問題上的準確性、穩定性和速度均優于傳統模型.因此,AGA-BEL模型在空間災害的預警系統中具有巨大的潛力和廣闊的應用前景. 結合大腦情感學習模型和自適應遺傳算法,提出了一種混沌時間序列預測的新模型.利用大腦情感學習模型模擬大腦邊緣系統中的情感學習機制,有效地克服了傳統神經網絡收斂速度慢的缺點.進一步,采用基于自適應遺傳算法的監督學習代替基于獎勵信號的強化學習,使預測模型能根據實際輸出和期望輸出的差值來優化調節杏仁體和眶額皮質的權值與閾值,增強了大腦情感學習模型的通用性,提高了模型精度.在Lorenz標桿問題和實際地磁Dst指數的預測中,實驗結果表明了本文所提出的AGA-BEL預測模型具有預測精度高、收斂速度快和穩定性強的優點,而且模型結構簡單,計算復雜度低,便于用于實際的預測系統,如地下水位預測系統、天氣預測系統等. [1]Lotf iE,Akbarzadeh T M R 2014Neurocomputing126 188 [2]Singh S,Gill J 2014Int.J.Intell.Syst.Appl.6 55 [3]Tian Z D,Gao X W,Shi T 2014Acta Phys.Sin.63 160508(in Chinese)[田中大,高憲文,石彤.2014物理學報63 160508] [4]Li D,Han M,Wang J 2012IEEE Trans.Neural Netw.Learn.Syst.23 787 [5]Shi Z W,Han M 2007IEEE Trans.Neural Netw.18 359 [6]Wang X Y,Han M 2015Acta Phys.Sin.64 070504(in Chinese)[王新迎,韓敏 2015物理學報64 070504] [7]Han M,Xi J H,Xu S G 2004IEEE Trans.Signal Process.52 3409 [8]Su L Y 2010Comput.Math.Appl.59 737 [9]Su L Y,Li C L 2015Discrete.Dyn.Nat.Soc.2015 329487 [10]Tian Z D,Li S J,Wang Y H,Gao X W 2015Acta Phys.Sin.64 030506(in Chinese)[田中大,李樹江,王艷紅,高憲文2015物理學報64 030506] [11]Mayer J D,Roberts R D,Barsade S G 2008Annu.Rev.Psych.59 507 [12]Ledoux J E 1991Concepts Neurosci.2 169 [13]Balkenius C,Morén J 2001Cybern.Syst.32 611 [14]Babaie T,Karimizandi L 2008Soft.Comput.12 857 [15]Abdi J,Moshiri B,Abdulhai B 2012Eng.Appl.Arti.Intell.25 1022 [16]Sharaf iY,Setayeshi S,Falahiazar A 2015J.Math.Comput.Sci.14 42 [17]Milad H S A,Farooq U,Hawary M,Asad M U 2016IEEE Access23 569 [18]Dorrah H T 2011J.Adv.Res.2 73 [19]Mei Y,Tan G Z,Liu Z T 2017Algorithms10 70 [20]Lotf iE,Akbarzadeh T M R 2016Inf.Sci.3 369 [21]Srinivas M,Patnaik L M 2002IEEE Trans.Syst.M.Cyber.24 656 [22]Guo Y Y 2013M.S.Thesis(Harbin:Harbin Institute of Technology)(in Chinese)[郭圓圓 2013碩士學位論文(哈爾濱:哈爾濱工業大學)] [23]Takens F 1981Lecture Notes in Mathematics(Berlin:Springer-Verlag)p366 [24]Yang F 2012Ph.D.Dissertation(Beijing:Beijing University of Posts and Telecommunications)(in Chinese)[楊飛2012博士學位論文(北京:北京郵電大學)] [25]Lotf iE,Akbarzadeh T 2013Cybernet.Syst.44 402 [26]Amani J,Moeini R 2012Sci.Iran.19 242 [27]Li J,Feng J,Wang W 2016Sci.Geog.Sin.36 780 [28]Peng Y X,Lü J Y,Gu S J 2016Chin.J.Space Sci.36 866(in Chinese)[彭宇翔,呂建永,顧賽菊 2016空間科學學報36 866]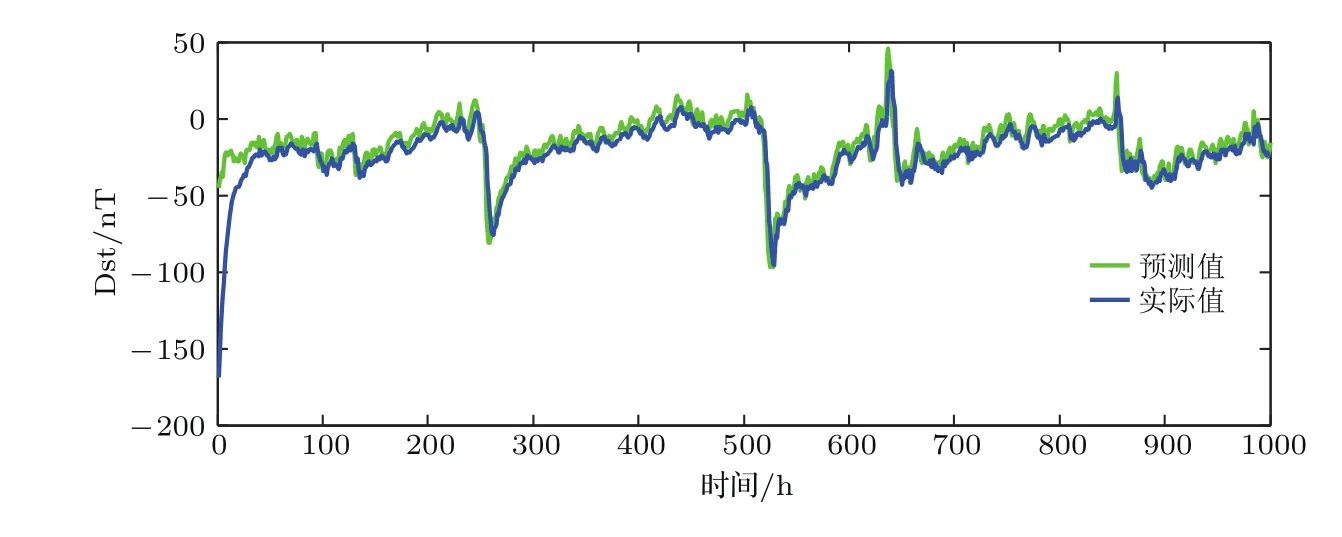



4.4.3 與其他方法比較
5 結 論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
家庭醫學(下半月)(2020年4期)2020-05-30 12:42:50
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年6期)2016-08-21 13:49:38
