話題感知下的跨社交網絡影響力最大化分析*
2018-05-09 08:49:55任思禹申德榮聶鐵錚
計算機與生活 2018年5期
任思禹,申德榮,寇 月,聶鐵錚,于 戈
東北大學 計算機科學與工程學院,沈陽 110819
1 引言
社交網絡影響力最大化是指在社交網絡上,通過一個影響傳播模型,選擇k個種子用戶使其得到最大化預期的影響傳播范圍。其核心是設計可靠的影響傳播模型和有效的搜索算法,能夠在有限的預算范圍內有效地宣傳新產品。
現有的影響力傳播研究工作[1-10]主要面向靜態的單一社交網絡,通過分析社交內用戶之間的影響力傳播,找出最具有影響力的用戶集合。實際上,面向多個社交網絡的影響力最大化研究也具有重要意義,因為單一網絡可能不能滿足廣度需求,且單一網絡的傳播廣度不如跨社交網絡的傳播范圍。為此呈現出有關跨社交網絡影響力最大化研究[11-13],即在多個社交網絡上進行用戶的影響力分析。然而,當前研究具有如下局限性:(1)跨社交網絡之間通過錨點對進行簡單鏈接,影響傳播精度;(2)沒有考慮話題因素,制約了種子選擇的精準性。有關話題感知的影響力分析研究主要面向單社交網絡,但由于不同網絡的話題不同,處理多個網絡上的話題具有一定難度。
本文研究基于話題感知的跨社交網絡的影響力最大化模型M-TLT(multiple-topic linear threshold)。例如,為擴大旅游推廣范圍,一個旅行社希望在人人網、微博等社交網絡上推廣一條歐洲行的旅游路線,即在多個社交網絡上找到對旅游話題感興趣的且影響范圍最大的一組用戶進行推廣。本文的主要貢獻如下:
(1)提出了一種基于話題的跨社交網絡圖構建方法。利用用戶關注的事物之間的聯系,將多個網絡聯系到一起,并通過用戶的話題得到用戶之間邊的傳播概率,最終形成一個基于話題的跨社交網絡圖。
(2)提出了一個在線性閾值模型下融合話題因素的M-TLT模型,并證明了M-TLT模型的合理性。
(3)設計了一種基于M-TLT模型的改進的啟發式種子用戶選擇算法。首先,基于潛力大小排序來減少候選種子集合及邊緣增益的計算量;然后,利用CELF(cost-effective lazy-forward)隊列進行種子用戶的選擇,在選擇過程中更新候選種子集合保證最終能夠得到k個種子用戶。
(4)設計了對比實驗,證明所提出的模型能夠更準確地建模潛在的影響力傳播過程,在時間復雜度上優于對比算法。
2 相關工作
Richardson等人[14-15]首先提出了口碑效應(word-ofmouth)概念,研究基于“病毒式營銷”的影響力最大化模型。Kempe等人[1]首次把影響最大化問題建模為在傳播模型上尋找影響力最大的k個節點的離散優化問題。他們提出了兩種常用的影響力傳播模型:線性閾值模型(linear threshold model,LT)和獨立級聯模型(independent cascade model,IC)。基于這兩個模型的影響力最大化算法,提出了能近似達到最優解(1-1/e)的貪心算法,該算法每一輪選擇邊緣收益最大的節點,計算代價大,不適用于大規模網絡。為了改善貪心算法的低效性,Leskovec等人[2]通過挖掘影響函數的子模特性,提出了CELF算法,減少了種子影響范圍次數。進一步,Goyal等人[3]提出了CELF算法的優化算法CELF++算法,效率提高了35%~55%,但同樣不適用于大規模網絡。接下來,提出了很多基于IC和LT模型的高效啟發式算法。例如,Chen等人[4]提出了基于IC模型的利用節點局部樹狀結構近似影響傳播的MIA(maximum influence arborescence)算法;Goral等人[5]提出了在LT模型下的SIMPATH算法。SIMPATH算法在運行時間、內存損耗和影響范圍方面都具有很好的性能。上述方法都沒有考慮話題因素,制約了種子用戶選擇的精準性。
Tang等人[6]研究了用戶間topic-wise影響強度的問題,闡述了用戶通常只能在某一個領域具有很大的影響力。Aslay等人[7]研究了話題感知的影響力最大化問題(topic-aware influence maximization,TIM),對有限數量可能查詢進行預先計算,然后使用樹基指數(INT)方法建立索引,有效地改善了查詢性能。Barbieri等人[8]提出的話題感知模型中,側重關注用戶權威性和主題的興趣,沒有考慮用戶-用戶的影響,使傳播模型的參數數量急劇減少,從而提高效率。Chen等人[9]提出的話題感知影響力最大化查詢中,利用MIA模型近似計算影響傳播,并對貪心階段邊緣算法提出了多種優化方法,在時間、影響范圍上均優于前幾種算法。上述方法考慮了話題因素,但僅在單網上進行研究。
Nguyen等人[11]研究了多社交網絡上最小花費的影響力問題,提出了一個利用多種耦合方案將多網問題降到單網解決的模型表示。隨后文獻[12]在之前研究的基礎上進行改進,提出了星式耦合網絡,通過減少額外的頂點和邊來提高性能。李國良等人[13]研究了多社交網絡上的影響力最大化問題,通過自傳播將多個網絡建立聯系,首次提出了針對多社交網絡上節點對實體的影響計算模型來評估多網下節點間的影響計算問題,并在獨立級聯影響模型下提出了多種解決方案,具有較好的伸縮性和時間性能。
與已有工作比較,本文工作具有如下優勢:(1)利用社交網絡中的文本信息將多個社交網絡聯系起來,并通過用戶的話題分布結合用戶之間邊的權重評價用戶之間的影響概率,使其更加具有可靠性;(2)跨社交網絡傳播模型中融合了話題因素,提高了種子用戶選擇的精準性;(3)利用3個優化策略減少了種子用戶選擇的時間復雜度。
3 問題定義
下面主要介紹本文對跨社交網絡影響力最大化的定義。表1為本文使用的符號。
影響力最大化問題是獲得網絡中信息的傳播過程,并以最大限度提高網絡中信息的傳播范圍。首先,給出相關概念;之后,給出基于話題感知的跨社交網絡影響力最大化的問題描述。

Table 1 Symbols used in this paper表1 本文使用的符號
定義1(種子用戶)用戶v∈V作為社交圖中Gi影響傳播的來源,被稱為一個種子用戶。種子用戶集合由S表示。
定義2(活躍用戶)如果用戶是種子用戶或者在影響力傳播模型下從已活躍的用戶v∈V(a)接收了信息,則稱為活躍用戶。用戶一旦變為活躍狀態則添加到V(a)中。
定義3(傳播范圍)給出一個影響力傳播模型,種子用戶集合的影響傳播范圍用S最終能影響到的用戶數量表示,記為Γ(S)。
基于話題感知的影響力最大化問題在文獻[13]中被提出。例如,一個用戶的話題分布為<乒乓球:0.5,游泳:0.3,電子:0.7>,假設人們想推廣乒乓球和游泳,那么給出一個話題查詢向量(<0.4,0.6,0>,2),即要找到兩個種子節點,乒乓球話題占查詢40%比重,游泳占查詢60%比重,且影響范圍最大。
定義4(基于話題感知的影響力最大化)給出一個話題查詢Q=(γ,k),基于話題感知的影響力最大化是在社交網絡上找到k個種子用戶集合S,使集合S在此查詢下的Γ(S)最大。
問題1(基于話題感知的跨社交網絡影響力最大化)給出m個基于用戶話題分布的社交圖Gi(i=1,2,…,m),并給出一個TIM查詢Q=(γ,k),找到一組種子用戶集合,使其對網絡上其他用戶的總影響力最大,即Γ(S|γ)最大。
4 基于話題感知的M-TLT模型
4.1 M-TLT傳播模型
M-TLT傳播模型核心包括跨社交網絡構建、影響概率計算和影響力傳播過程三部分。
4.1.1 跨社交網絡構建
不失一般性,以兩個社交網絡為例,介紹本文的模型。
跨社交網絡構建的核心是如何模型化社交網絡間的關聯關系。給定網絡G1、G2的同一實體1和實體2(同一個實體指不同網絡上的同一個用戶),如果實體1將信息從G1傳到G2,需要考慮同一實體的鄰居用戶在跨網絡間的某種聯系。例如,首先在文本信息中抽取或自定義like匹配對,如<歌手,歌曲>、<演員,電影>等。如圖1所示,情況1:G1中實體1 follow的用戶1 like的歌手/演員與G2中實體2 like的歌曲/電影相對應,說明實體的follow用戶可能不通過G1上的用戶與G2的影響鏈接產生影響,而形成一條跨網影響的單向鏈接,即圖中influence鏈接。情況2:兩個實體的follower用戶2和用戶3同時喜歡同一個匹配對,那么當跨網實體用戶傳遞信息時,其follower之間產生間接的影響,則形成相似similarity的雙向鏈接。這些鏈接的話題分布與對應實體共同喜歡的話題有關。
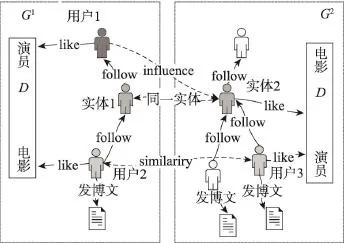
Fig.1 Cross-network connection圖1 跨社交網絡連接
對于跨社交網絡之間沒有直接聯系的兩個用戶,若興趣相似,他們之間可以產生間接的聯系,那么similarity鏈接具有合理性。因此需要計算在不同的話題查詢下兩個用戶的話題相似度sim(θu,θv|γ),當sim(θu,θv|γ)>ε時,建立用戶的“鏈接”邊。本文利用余弦相似度計算用戶話題的相似度,見式(1):
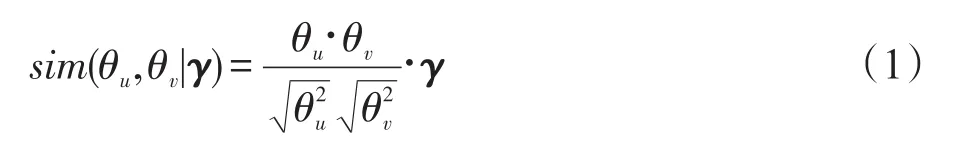
基于上述思想,跨社交網絡構建過程見算法1。
算法1跨社交網絡構建算法newTopicGraph
輸入:Gi=(V,F,ω,ξ),Num,θ,ε,D,話題查詢Q=(γ,k),網絡之間實體匹配對Alignment。
輸出:跨社交網絡G。
1.for everyu∈Gido
2.for everyv∈Gido
3. if((u,v)∈Alignment)do
4. 在u、v之間建立邊;
5. 獲取u、v的內向鄰居集和外向鄰居集InN(u)、InN(v)、OutN(u)、OutN(v)
6. /*建立influence邊*/
7. for everyi∈OutN(u)do
8. 建立i到v的單向influence邊;
9. end for
10. for everyi∈OutN(v)do
11. 建立j到u的單向influence邊;
12. end for
13. /*建立similarity邊*/
14. for everyi∈InN(u)do
15. for everyj∈InN(v)do
16. 計算i和j的話題相似度sim(i,j);
17. if(sim(i,j)>ε)do
18. 建立i和j間雙向similarity邊
19. end if
20. end for
21. end for
22. end if
23.end for
24.end for
其中,第1~5行遍歷不同網絡中的用戶,若兩個用戶是同一個實體,則生成一個雙向鏈接,得到u和v的外向鄰居用戶集合OutN(u)、OutN(v)以及內向鄰居用戶集合InN(u)、InN(v)。第7~12行,建立influ-ence邊。判斷InN(u)是否與v有相同的like匹配對,若存在且匹配對的數量大于數值Num,則建立一個單向的influence鏈接,其方向指向v。第13~21行建立similarity邊。遍歷OutN(u)和OutN(v),若當前話題相似度sim(θu,θv|γ)>ε,建立一個雙向similarity鏈接。對不同的鏈接邊標記不同的flag值,實體用戶flag=0,similarity以及influence鏈接,flag=1。第22~24行,若兩個用戶不是同一實體,繼續遍歷網絡中其他用戶。
4.1.2 鏈接上的影響概率計算
鏈接上的影響概率按類型采用不同的計算方法。相同實體之間的傳播概率設置為:轉發文本的數量除以文本的總數量。而對于網絡內的follow以及網絡間的influence和similarity鏈接來說,當計算用戶u對v的影響力時,用戶v對用戶u的話題接受度通常不同,因此不能用統一的影響概率來表示,應該對不同的話題有不同的影響概率。利用文獻[10]中用戶之間的不同話題影響力大小計算公式,如式(2)所示:
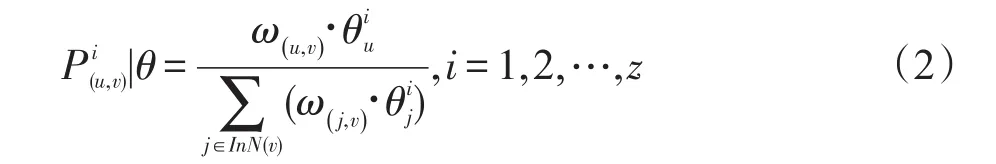
其中,ω(u,v)、ω(j,v)是用戶之間邊權重;是用戶u在話題i下的話題比重。
4.1.3 影響力傳播過程
本文的影響力傳播過程基于線性閾值模型。給定m個用戶話題分布社交圖Gi、初始種子集合S和話題查詢Q=(γ,k),那么影響力傳播過程描述如下:在第t步,所有在前t-1步已經被激活的節點仍然處于活躍狀態,任意一個用戶u接收到的總影響力為,若Wt(u)≥ξu,即用戶收到影響力大于本身閾值,則用戶u被激活,為活躍狀態。持續這個過程直到沒有可被激活的節點。
4.2 M-TLT模型性質
如果Γ(S|γ)是單調子模函數,那么使用貪心算法進行最大邊際增益的近似最優達到(1-1/e)結果。
定理1M-TLT模型下的Γ(S|γ)是單調子模函數。
證明在特定TIM查詢Q=(γ,k)下,任意兩個用戶u、v之間的邊,均有,即對于任意一條邊在特定的TIM查詢下,都是一個固定值,即特定TIM查詢下,用戶之間的影響力是確定的。M-TLT模型下的影響力最大化可以看作普通的單網上的影響力最大化問題。根據文獻[3],M-TLT模型下Γ(S|γ)是單調子模函數。
定理2M-TLT問題是NP-難問題。
證明可以用z=1的話題分布的條件構建一個M-TLT問題的一個實例,解決M-TLT問題就是解決常規LT模型下的影響力最大化問題。傳統影響力最大化問題是NP-難,因此證明了M-TLT問題也是NP-難問題。
5 M-TLT模型下種子用戶選取算法
由前文討論可知,可采用貪心算法選擇種子用戶。首先,需要建立從用戶u到用戶集合V中所有的影響模型;然后,迭代計算S中每個用戶u的邊緣影響。邊緣影響是當前種子集合S下,用戶u加入種子集合與S總的影響范圍與S產生的影響范圍之差,計算方式為δu(S)=δ(S∪{u})-δ(S)。可見,采用該類貪心算法計算代價大,為此本文采用啟發式算法選擇種子用戶。
本文利用CELF啟發算法[4]來優化算法。由于CELF不能保證在最壞情況下減少運行時間,為了有效降低CELF算法的運行時間,本文提出了如下3種優化策略:一是基于節點潛力(見M-Potentiality算法)減少計算代價;二是候選集C的選擇優化(見MCandidate算法),因為CELF算法迭代過程中會計算大量不必要計算的節點的邊緣增益,所以提出了定理3,大大降低了不必要計算的邊緣增益;三是減少邊緣增益的計算代價。
5.1 優化策略
5.1.1 基于用戶潛力的優化
用戶潛力是指用戶能夠激活其他用戶的能力,用戶最終可能影響到的節點越多,其潛力越大。用戶u的潛力評價方法為u以及其所有外向鄰居邊上的影響傳播概率和查詢話題的乘積之和與用戶本身閾值之比,如式(3)所示:
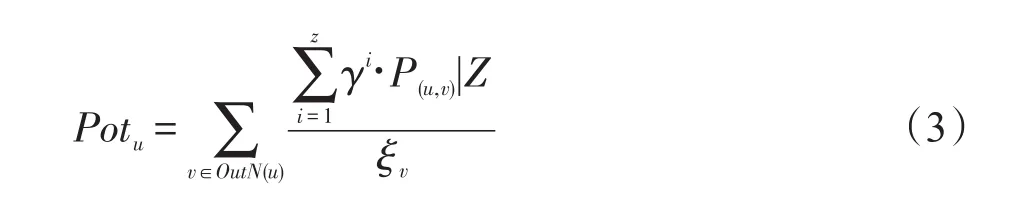
通過忽略有較小潛在邊緣收益的用戶,只關注具有較高潛力的用戶,來減少節點邊緣增益的計算次數。
用戶潛力(M-Potentiality)算法見算法2。
算法2M-Potentiality
輸入:Gi=(V,F,ω),話題查詢Q=(γ,k),用戶閾值ξ。
輸出:按潛力值進行排序的節點集合P。
1.for allu∈Vdo
2. 計算Potu;
3.end for;
4.根據Potu對節點u進行排序;
5.1.2 候選集選擇的優化
CELF算法在迭代過程中會計算所有非種子節點的邊緣增益,然而被當前種子集合激活節點的邊緣增益為0,因此不需要計算其邊緣增益。下面給出定理及證明。
定理3當前種子集合激活的點的邊緣增益為0。
證明如圖2所示,假設當前種子集合激活點的邊緣增益不為0,即δa(S)≥1(其中a為被當前種子集合S激活的任意節點)。那么必然至少存在一個點q,使得種子集合為S時不能激活q,而當種子集合為S∪{a}時能激活節點q。若當前種子集合為S,假設在第t步激活了節點a,那么在t步之后,根據線性閾值過程[3],節點a也將作為活躍節點影響其他節點,即在t步之后,a將與種子集合S中的節點一起影響其他節點,記為S′=S∪{a,…}。根據假設當種子集合為S∪{a}時能激活節點q以及定理1,M-TLT傳播模型下的影響力最大化是單調的,因此S′也能激活節點q,這與假設種子集合為S時不能激活q相矛盾,假設不成立,從而當前種子集合激活節點的邊緣增益為0。
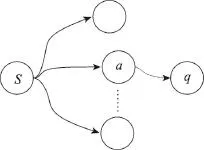
Fig.2 Influence spread of seed set S圖2 種子集合S的影響傳播
根據定理3可知,所有被當前種子集合激活節點的邊緣增益為0,因此在計算候選節點的邊緣增益時,不需要計算已被當前種子集合影響到節點的邊緣增益,即可以將被當前種子集合激活的節點從候選集合中刪除。
基于算法3獲取初始候選集,其中候選集的大小通過參數候選集規模p進行確定,返回2p×k個節點作為候選集。
算法3M-Candidate
輸入:按潛力值排序的節點集合P,候選集規模p。
輸出:將集合P中前2p×k個元素添加到候選集C中。
1.將集合P中前2p×k個元素添加到候選集C中;
2.將集合P中前2p×k個元素從P中刪除;
3.返回候選集C;
若在當前候選集中選不出k個種子用戶,需要對候選集合進行擴展。算法4是候選集更新算法,增益節點集合是將當前增益最大節點新激活的節點集合。如果隊列QC的大小小于2p-1×k個,那么執行第3~5行。新加入的節點采用lazy策略,不計算新加入節點的邊緣增益,直接賦值為CELF隊列QC中用戶邊緣增益的最小值。
算法4M-Candidate-Update
輸入:CELF隊列QC,增益節點集合M,按潛力值排序的節點集合P,候選集合規模p。
輸出:更新后的CELF隊列QC。
1.將M中的節點從QC和P中刪除;
2.if(|QC|< 2p-1×k));
3.從集合P中取前2p-1×k個元素放到QC中;
4.將取出的2p-1×k個元素從P中刪除;
5.返回CELF隊列QC;
5.1.3 邊緣增益計算代價的優化
種子集合S能夠激活節點,那么種子集合S∪{a}也一定可以激活。然而在計算節點a的邊緣增益δa(S)時,往往需要重新從S∪{a}開始一步一步地迭代計算,導致已經確定能被激活的點被重復計算。因此使用一個集合O來存儲當前種子集合能夠影響到的節點的集合,那么節點a的邊緣增益為δa(S)=δ(S∪O∪{a})-δ(S),從而降低了邊緣增益的計算量。
5.2 基于貪心的種子用戶選擇算法
最后,采用貪心算法M-TLTGreedy算法(見算法5)找到大小為k的種子用戶集合S。其中,第1行初始化種子用戶集合、CELF隊列以及活躍節點集合M。第2~4行連接多個基于話題的社交網絡并計算用戶的潛力值和候選種子用戶集合。第5~8行計算候選集合中用戶的影響力大小并插入到隊列QC中。若此時種子集合大小小于k,計算隊頭用戶的影響力大小,直到u仍然在CELF隊列QC的隊頭(第9~13行)。若沒有增益返回種子集合S,將用戶u加入種子集合中,更新候選集合,直到得到k個種子用戶算法停止。
算法5M-TLTGreedy算法
輸入:Gi=(V,F,ω),D,Num,p,話題查詢Q=(γ,k),用戶閾值ξ。
輸出:大小為k的種子用戶集合S。
1.初始化S←? ,CELF隊列QC←? ,活躍節點集合M←?;
2.G←newTopicGraph(Gi,Num,θ,ε,D,Q);
3.P←M-Potentiality(Gi,Q(γ,k));
4.C←M-Candidate(P,p);
5.foru∈Cdo
6. 計算δu(S);
7. 將u插入到隊列QC中;
8.end for
9.while(|S|<k)do
10.repeat
11.u←QC.top;
12. 重新計算δu(S);
13.until1u仍然在CELF隊列QC的頂端;
14.if(δu(S)≤ 0)then
15. returnS;
16.end if
17.S←S?{u};
18.獲取節點u的活躍節點集合M;
19.QC←M-Candidate-Update( )QC,M,P,p;
20.end while
6 實驗與結果
下面基于M-TLT模型,在兩組數據集(微博-知乎和Twitter-Facebook[16])上測試了本文提出的算法。
6.1 數據集
本文使用兩組數據集,真實的微博-知乎數據集和Twitter-Facebook數據集,具體的統計信息見表2和表3。微博-知乎(Weibo-Zhihu)數據集包括微博以及抓取的知乎信息,其中也包括作為話題提取的文本信息。本文采用STRM(social-relational topic model)[17]算法來計算用戶的話題分布。Twitter-Facebook數據集沒有文本信息,本文隨機生成了用戶的話題分布。由于現有的數據集中無法獲得用戶的閾值信息,在實驗中統一設置為0.5。隨機生成話題查詢。

Table 2 Statistics of Weibo-Zhihu datasets表2 微博-知乎數據集統計
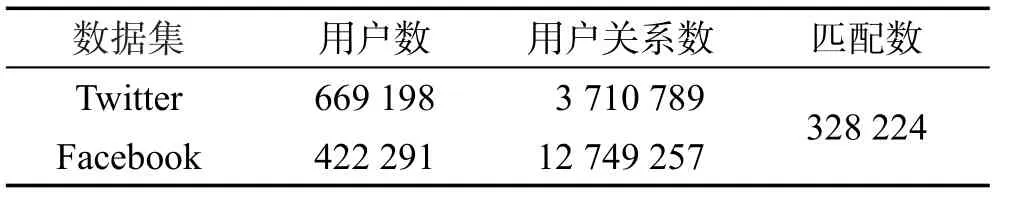
Table 3 Statistics of Twitter-Facebook datasets表3 Twitter-Facebook數據集統計
所有的對比實驗中各個算法均使用相同的數據集、用戶閾值和話題查詢,不會對實驗結果產生影響。
6.2 實驗設置及對比實驗
將本文提出的M-TLTGreedy算法與已有的算法進行對比。評價指標:一是影響范圍,范圍越大表明種子用戶的質量越好;二是運行時間,時間越短表明種子用戶選擇的算法越好。本文比較了幾種算法在以上兩個數據集上的影響范圍和運行時間。
CELF:用CELF[6]進行優化的貪心算法。由于CELF算法不適用于基于話題的跨網影響力計算,將算法1生成的網絡圖作為單一網絡用CELF算法進行計算。
SIMPATH:該算法提出了兩個優化,一是利用最大頂點覆蓋減少第一次迭代中的調用次數,二是用參數l在迭代開始選擇最有前途的候選種子,l取值4。
HighDegree[3]:該算法把度數高的節點作為有影響力的節點,選出k個最高出度的節點作為種子集。
M-TLTGreedy-no3:不用邊緣增益優化策略進行優化的M-TLTGreedy算法。
CELF-3:計算邊緣增益時,利用本文的邊緣增益優化策略進行優化的CELF算法。
CELF-2:用本文的候選集選擇優化策略進行優化的CELF算法。
實驗環境:Intel?Xeon?CPUE3-1226v3@3.30GHz,內存16 GB;操作系統:CentOS Linux release 7.3.1611(Core)。
6.3 實驗和結果
以下通過4個實驗來驗證本文算法的性能。前3個實驗都是在固定候選集規模p=4條件下進行。
6.3.1 優化策略比較
(1)用戶潛力優化策略的作用
用戶潛力優化策略旨在尋找有較高可能成為種子節點的用戶。只計算具有較高潛力用戶的邊緣收益,從而降低了CELF算法第一次迭代過程中的計算量。實驗比較了M-TLTGreedy算法和CELF算法在第一次迭代中的運行時間,其中M-TLTGreedy算法參數為p=4,k=100,實驗結果如表4所示。可以看出,因為M-TLTGreedy算法只計算部分節點的邊緣收益,所以運行時間要明顯小于CELF算法。
(2)候選集選擇優化策略的作用
候選集選擇優化旨在降低計算邊緣增益節點的數量。實驗比較了CELF算法和CELF-2算法的運行時間,其中微博-知乎數據集的用戶閾值設置為0.4,Twitter-Facebook數據集的用戶閾值設置為0.3。從圖3中可以看出,隨著k的增加,候選集優化的效果越來越明顯。
(3)邊緣增益優化策略的作用
實驗比較了M-TLTGreedy和M-TLTGreedy-no3、CELF-3和CELF算法的運行時間。從圖4中可以看出,在兩個數據集下,邊緣增益計算優化策略均使兩個算法的運行時間降低,且隨著k值的增大,優化效果越明顯。這是因為隨著種子節點個數的增加,重復計算量也會增大。
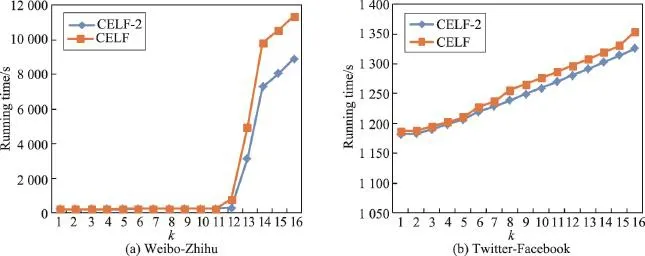
Fig.3 Running time comparison of candidate optimization strategy圖3 候選集選擇優化運行時間比較
6.3.2 影響范圍比較
實驗比較了M-TLTGreedy、CELF、HighDegree、SIMPATH算法在種子集合大小為10~100時的影響范圍。從圖5中可以看出:在微博-知乎和Twitter-Facebook兩個數據集上,在任意種子集合大小下,MTLTGreedy算法的影響范圍趨近于CELF、SIMPATH算法的影響范圍,明顯優于HighDegree算法的影響范圍,說明本文算法保證了精度。
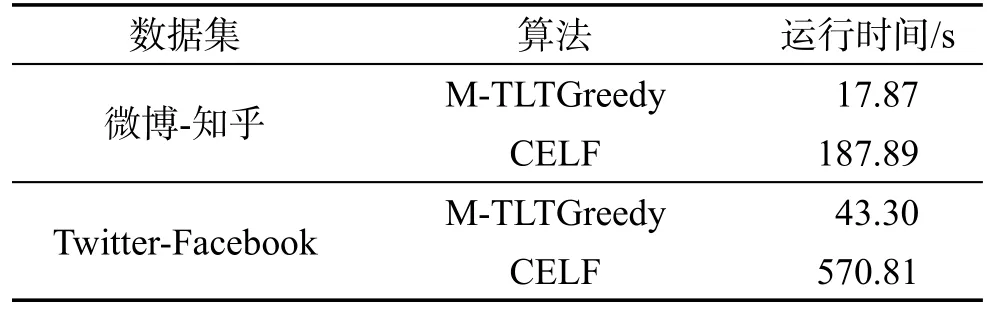
Table 4 Running time comparison of potentiality optimization strategy表4 用戶潛力優化策略運行時間比較
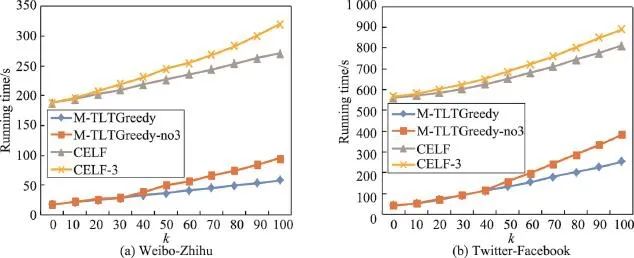
Fig.4 Running time comparison of margin gain optimization strategy圖4 邊緣增益優化策略運行時間比較
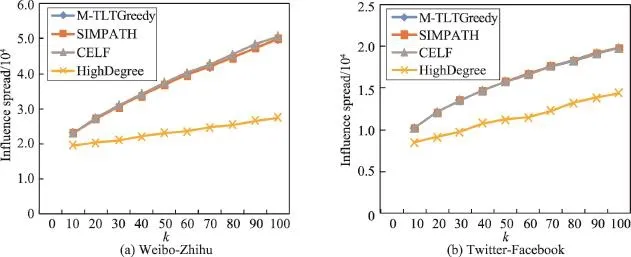
Fig.5 Influence spread comparison圖5 影響范圍比較
6.3.3 運行時間比較
實驗比較了M-TLTGreedy、CELF、SIMPATH、High-Degree算法在種子集合為0~100時的運行時間。從圖6中可以看出:因為HighDegree算法不需要計算節點的邊緣增益,只需要數據集中每個節點的出度,所以HighDegree算法的運行時間非常短;M-TLTGreedy算法要明顯低于CELF算法的運行時間,因為CELF算法在計算增益過程中需要計算圖中所有節點用戶的增益,并在之后的計算過程中計算了一些不必計算的節點,而M-TLTGreedy算法通過計算用戶潛力,得到一個候選種子集合,只對候選集中的節點進行增益計算,同時通過邊緣增益優化算法減少了重復計算,所以大大減少了計算時間。SIMPATH算法和M-TLTGreedy算法都針對貪心算法的問題進行了改進。可以看出:在k值小的情況下本文算法所花費的時間更短,隨著k值的增大,SIMPATH算法的運行時間稍微優于本文算法。
6.3.4 候選集規模的影響
測試候選集規模p取值對M-TLTGreedy算法影響范圍以及運行時間的影響。圖7顯示了p=2,4,6,8,10時,在兩個數據集下的影響范圍大小的對比。顯然,固定種子集大小,在微博-知乎數據集以及Twitter-Facebook數據集上p=2,4,6影響范圍有小幅度增加,p=6之后影響范圍基本相同,說明候選集規模對種子用戶影響范圍的影響不大。
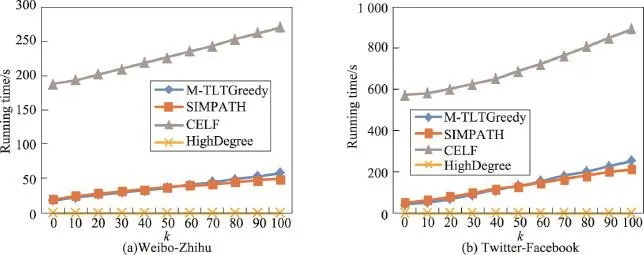
Fig.6 Running time comparison圖6 運行時間比較
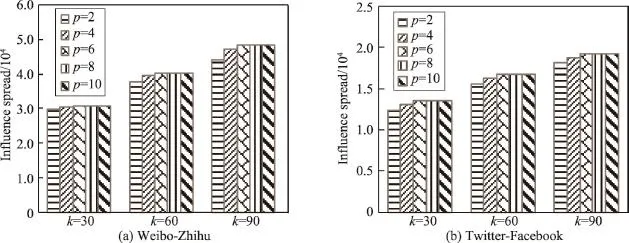
Fig.7 Candidate scale vs.influence spread圖7 候選集規模-影響范圍
圖8 顯示了分別在不同種子集合大小(k=30,60,90)下,隨著候選集規模p的增大,運算時間也會大幅增加。這是因為隨著p值的增大,候選集規模也在增大,需要計算的邊緣增益的節點數也會大幅增加。
總體看本文提出的M-TLTGreedy算法表現出較高的性能,能夠得到一定的影響范圍,并在運行時間上優于對比算法。
7 結束語
本文利用用戶關注的事物之間的聯系,將多個網絡聯系到一起,并進行影響力模型的建模,提出了M-TLT模型。設計了在M-TLT模型上尋找種子用戶集的算法,從而找到跨社交網絡上在話題下的影響力最大的k個種子用戶,解決了對于跨社交網絡的話題查詢下找到影響力最大的用戶集合需求。本文提出的影響力最大化方法主要是針對跨社交網絡基于話題的查找,提出的M-TLTGreedy算法實驗結果表明,本文算法在影響范圍和運行時間方面都能達到滿意的效果。下一步,將本文的影響力傳播模型擴展到動態的多個網絡上,使其更符合現實情況,并設計出更高效的種子選擇方法。
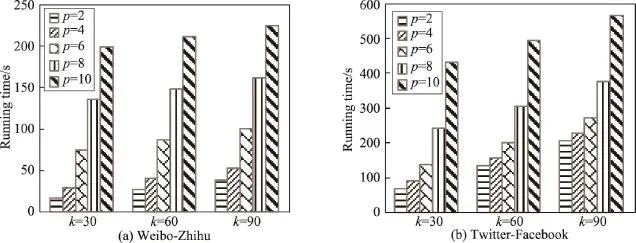
Fig.8 Candidate scale vs.running time圖8 候選集規模-運行時間
[1]Kempe D,Kleinberg J M,Tardos é.Maximizing the spread of influence through a social network[C]//Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Washington,Aug 24-27,2003.New York:ACM,2003:137-146.
[2]Leskovec J,Krause A,Guestrin C,et al.Cost-effective outbreak detection in networks[C]//Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,San Jose,Aug 12-15,2007.New York:ACM,2007:420-429.
[3]Goyal A,Lu Wei,Lakshmanan L V S.CELF++:optimizing the greedy algorithm for influence maximization in social networks[C]//Proceedings of the 20th International Conference on World Wide Web,Hyderabad,Mar 28-Apr 1,2011.New York:ACM,2011:47-48.
[4]Chen Wei,Wang Chi,Wang Yajun.Scalable influence maximization for prevalent viral marketing in large-scale social networks[C]//Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Washington,Jul 25-28,2010.New York:ACM,2010:1029-1038.
[5]Goyal A,Lu Wei,Lakshmanan L V S.SIMPATH:an efficient algorithm for influence maximization under the linear threshold model[C]//Proceedings of the 11th IEEE International Conference on Data Mining,Vancouver,Dec 11-14,2011.Washington:IEEE Computer Society,2011:211-220.[6]Tang Jie,Sun Jimeng,Wang Chi,et al.Social influence analysis in large-scale networks[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Paris,Jun 28-Jul 1,2009.New York:ACM,2009:807-816.
[7]Aslay ?,Barbieri N,Bonchi F,et al.Online topic-aware influence maximization queries[C]//Proceedings of the 17th International Conference on Extending Database Technology,Athens,Mar 24-28,2014:295-306.
[8]Barbieri N,Bonchi F,Manco G.Topic-aware social influence propagation models[C]//Proceedings of the 12th International Conference on Data Mining,Brussels,Dec 10-13,2012.Washington:IEEE Computer Society,2012:81-89.
[9]Chen Shou,Fan Ju,Li Guoliang,et al.Online topic-aware influence maximization[C]//Proceedings of the 41st International Conference on Very Large Data Bases,Kohala Coast,Aug 31-Sep 4,2015:666-677.
[10]Chu Yaping,Zhao Xianghui,Liu Sitong,et al.An efficient method for topic-aware influence maximization[C]//LNCS 8709:Proceedings of the 16th Asia-Pacific Web Conference on Web Technologies and Applications,Changsha,Sep 5-7,2014.Berlin,Heidelberg:Springer,2014:584-592.
[11]Nguyen D T,Zhang Huiyuan,Das S,et al.Least cost influence in multiplex social networks:model representation and analysis[C]//Proceedings of the 13th International Conference on Data Mining,Dallas,Dec 7-10,2013.Washington:IEEE Computer Society,2013:567-576.
[12]Zhang Huiyuan,Nguyen D T,Zhang Huiling,et al.Least cost influence maximization across multiple social networks[J].IEEE/ACM Transactions on Networking,2016,24(2):929-939.
[13]Li Guoliang,Chu Yaping,Feng Jianhua,et al.Influence maximization on multiple social networks[J].Chinese Journal of Computers,2016,39(4):643-656.
[14]Brown J J,Reinegen P H.Social ties and word-of-mouth referral behavior[J].Journal of Consumer Research,1987,14(3):350-362.
[15]Richardson M,Domingos P M.Mining knowledge-sharing sites for viral marketing[C]//Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Edmonton,Jul 23-26,2002.New York:ACM,2002:61-70.
[16]Cao Xuezhi,Yu Yong.ASNets:a benchmark dataset of aligned social networks for cross-platform user modeling[C]//Proceedings of the 25th ACM International Conference on Information and Knowledge Management,Indianapolis,Oct 24-28,2016.New York:ACM,2016:1881-1884.
[17]Guo Weiyu,Wu Shu,Wang Liang,et al.Social-relational topic model for social networks[C]//Proceedings of the 24th ACM International Conference on Information and Knowledge Management,Melbourne,Oct 19-23,2015.New York:ACM,2015:1731-1734.
附中文參考文獻:
[13]李國良,楚婭萍,馮建華,等.多社交網絡的影響力最大化分析[J].計算機學報,2016,39(4):643-656.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
