基于應用技術實現語言處理研究
2018-05-13 15:17:34郭建偉燕娜陳佳宇
中阿科技論壇(中英文) 2018年4期
郭建偉,燕娜,陳佳宇
(北京市科學技術情報研究所信息資源部,北京 100044)
互聯網搜索的查詢被劃分成少數幾個關鍵詞而不是以自然語言表述的實際的問題。人們可以用基于社區的問答系統通上下文獲得更為明確的理解而給出更好的回答。相比而言,一個互聯網搜索引擎對于一段很長的查詢只能給出很差的返回結果或不返回任何有價值的東西。人們只能將他們的問題轉化成一個或幾個貼切的關鍵詞去嘗試相對貼切的回復。信息檢索研究的長期目標是開發檢索模型來為更長、更專門的查詢提供精確的結果。因此需要更好的理解文本信息。嚴格來說,自然語言處理[1][2](Natural Language Processing),包括自然語言理解和自然語言生成兩部分。
一、語言處理
自然語言就是人交流用的語言。自然語言處理的研究方向包括以下幾種[2]:
規則方法:可以用規則的方法預先準備好一些先驗知識。然后用統計的方法來處理未知的情況。把些人工經驗放入規則庫。很多時候,人講話并不是按概率來的,除非是隨便說說。比如說,怎么減肥,只能說吃那么幾樣減肥的食品。
統計方法:語料庫就是一個文檔的樣本庫。需要有很大的規模,オ有概率統計的意義,可以假設很多詞和句子都會在其中出現多次。
計算框架:算法設計是一件非常困難的工作,需要有很好的數據結構基礎,采用的算法設計技術主要有迭代法、分治法、動態規劃法等,互聯網搜索經常面臨海量數據,需要分布式的計算框架來執行對網頁重要度打分等計算。
語義庫:自然語言中的語義復雜多變,如:在“買玩偶送女友”中,“送”這個詞不止一個義項,Opence 提供了OWL 格式的英文知識庫。
二、語言文法分析
自動句法分析[3]主要有兩種模式:一是短語結構語法,二是依存語法,依存語法更能體現句子中詞與詞之間的關系。StanfordParser 實現了一個基于要素模型的句法分析器,其主要思想就是把一個詞匯化的分析器分解成多個要素(factor)句法分析器。Stanford Parser 將一個詞匯化的模型分解成一個概率上下文無關文法(PCFG)和一個依存模型,Sharpnlp 可以圖形化顯示句法樹,它是用C#實現的,可以利用依存關系改進一元分詞,也可以利用依存關系改進二元分詞等。
三、語言文檔排重
互聯網給人們提供了數不盡的信息和網頁,其中有許多是重復和多余的,這就需要文檔排重[4]。比如,央行的征信中心會收到來自不同銀行申請貸款的客戶資料,需要合并重復信息,并整合成一個更完整的客戶基本信息,這就可以通過計算信息的相似性合并來自不同數據來源的數據。文檔排重的方法中語義指紋是可行的方法之一。在具體的針對句子做抄襲性檢測的實踐中,可以按句子生成Simhash,然后根據生成的文檔指紋信息對文檔分類。
同義詞替換:“年糕”也叫作“切糕”,如果有人聽不懂某個詞,可以換個說法再重復一遍。需要把說法統一,例如把“國家稅務局”替換成“國稅局”,“國稅局”是“國家稅務局”的縮略語企業的簡稱和全稱可以看成是語義相同的。一般來說,可以用長詞替換短詞。在地址方面有時會有各種不同的寫法和行政區域編碼,這時同義詞替換的方法之一是可以把門牌號碼中文串轉成阿拉伯數字。例如:“甘家口一號樓”轉換成:“甘家口1 號樓”。漢語中構造縮略語的規律很詭異,目前也沒有一個定論。初次聽到這個問題,幾乎每個人都會做出這樣的猜想:縮略語都是選用各個成分中最核心的字,比如“海關檢查”縮成“海檢”“人民法官”縮成“法官”等。不過,反例也是有的,“郵政編碼”就被縮成了“郵編”,但“碼”無疑是更能概括“編碼”一詞的。當然,這幾個縮略語已經逐漸成詞,可以加進詞庫了。
四、信息抓取
信息抓取(Information Extraction,IE),是把文本里包含的信息進行結構化處理[5],變成表格一樣的組織形式。在信息抓取系統中,輸入的是原始文本,輸出的是固定格式的信息點。這些被抓取的信息點以統一的形式集成在一起。這就是信息抽取的主要任務。例如草莓價格上漲,櫻桃價格下跌,語義標注出草莓和櫻桃都是水果,得到關鍵詞“水果”。信息抽取技術并不試圖全面理解整篇文檔,只是對文檔中包含相關信息的部分進行分析。在信息抽取中,要完成指代消解的任務,從網頁中如何抓取有用的信息并將其歸類的方法。比如,如何從一個大的正確詞表中找和輸入詞編輯距離小于k 的詞集合,使用了兩個有限狀態機求交集的方法。

圖1 關鍵詞提取流程圖
關健詞提取是文本信息處理的一項重要任務,例如可以利用關鍵詞提取來發現新聞中的熱點題。和關鍵詞類似,很多政府公文也有主題詞描述,上下文相關廣告系統也可能會用到關鍵詞提取技術,統計詞頻和詞在所有文檔中出現的總次數。TF(Term Frequence)代表詞頻,IDF(Invert Document Frequence)代表文檔頻率的倒數。比如說“的”在100文檔中的40 篇文檔中出現過,則文檔頻率DF(Document Frequence)是40,IDF 是140。“的”在第一篇文檔中出現了15 次,則TFWIDI(的)=15*140-0.375。另外一個詞“反腐數”在這100 篇文檔中的5 篇文檔中出現過,則DF 是5,IDF 是15。“反腐敗”在第一篇文檔中出現了5 次,則TF*IDF(反腐敗)=5*1/5=1,結果是:TF*DF(反腐敗)TF+DF(的)。
模糊匹配問題:從用戶查詢詞中挖掘正確提示詞表,一般不需要提示沒有任何用戶搜索過的詞,可以輸入任何詞,然后自動機可以基于是否和目標詞的編輯距離最多不超過給定距離從而接收或拒絕它。而且,由于FSA 的內在特性,可以在O(n)時間內實現。這里,m 是測試字符串的長度。而標準的動態規劃編輯距離計算方法需要O(m*)時間,這里m 和n 是兩個輸入單詞的長度。因此編輯距離自動機可以更快地檢查許多單詞和一個目標詞是否在給定的在最大距離內。
五、語言自動摘要
所謂自動摘要,就是利用計算機自動地從原始文獻中提取摘要[6]。比如,手機顯示屏的大小是有限的,因此智能手機上顯示新聞的短摘要。對于論壇中長篇的帖子,有的網友會求摘要。最簡單的自動生成摘要的方法是返回文格的第一句,稍微復雜點的方法是首先確定最重要的幾個句子,然后根據最重要的幾個句子生成摘要。
六、語義文本分類
文本分類就是讓計算機對一定的文本集合按照一定的標準進行分類。比如,小李是個足球迷,喜歡看足球類的新聞,新聞推薦系統使用文本分類技術為小李自動推薦足球類的新聞。文本分類程序把一個未見過的文檔分成已知類別中的一個或多個,例如把新聞分成國內新聞和國際新聞。利用文本分類技術可以對網頁分類,也可以用于為用戶提供個性化新聞或者垃圾郵件過濾把給定的文檔歸到兩個類別中的一個叫作兩類分類,例如垃圾郵件過濾,就只需要確定“是”還是“不是”垃圾郵件。分到多個類別中的一個叫作多類分類,例如中圖法分類目錄把圖書分成22 個基本大類文本分類主要分為訓練階段和預測階段。訓練階段得到分類的依據,也叫作分類模型。預測階段根據分類模型對新文本分類。訓練階段一般先分詞,然后提取能夠作為分類依據的特征詞,最后把分類特征詞和相關的分類參數寫入模型文件。提取特征詞這個步驟叫作特征提取。早期經常采用樸素貝葉斯的的文本分類方法,后來支持向量機方法成為首選。除此之外,還可以對人的行為聚類。90 年代末期,美國S.Reis 教授通過對2300 多名被試者的300 多種行為所做的因素分析表明,人類的所有行為可以聚類為15 種行為。
七、語音類型識別
語音識別技術[7],也被稱為自動語音識別(Automatic Speech Recognition,ASR),它是一種交叉學科,與人們的生活和學習密切相關,其目標是將說話者的詞匯內容轉換為計算機可讀的輸入,例如按鍵、二進制編碼或者字符序列。比如,將來打銀行的客服電話,可以直接和銀行系統用口語對話,而不是“普通話請按1”這樣把人當成機器的詢問,實現語音交互。初學者不會寫代碼,有經驗的程序員可以口述代碼,然后讓初學者把代碼敲進去,為了節約程序員的時間,可以用語音識別代碼根據語音翻譯成文字,進一步,還可以根據識別出的文字識別語意,這樣可以讓機器和人交流。兒童識別圖片后,可以說出這個圖是老虎還是大象。系統使用語音識別技術判斷孩子回答是否正確。對于不正確的,系統自動給出提示。開放式語音識別做好不容易,可以輔助人工輸入字幕,類似語音輸入法。Julius是日本京都大學和一家日本公司開發的大詞匯量語音識別引弊,是一種高性能、與語音相關的研究和開發的解碼器軟件,基于字的N-gram 和上下文相關的HMM 模型,目前已經應用于日語和漢語的大規模連續語音識別。在Juis 系統中存在連個模型:語言模型和聲學模型。
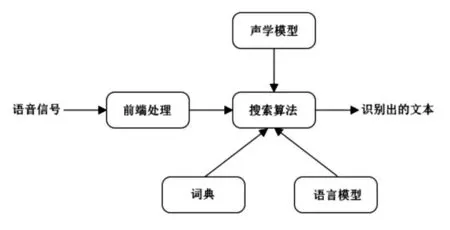
圖2 語音識別結構
八、總結
自然語言處理技術包括很多方面,如文本分類、對話系統、機器翻譯等。人們經常用到的查詢功能使用的是搜索引擎技術,用戶在搜索引擎中輸入較長的問題時,計算機要能夠給出準確的答案。在幾乎是所有的我們從電影或電視上看到的未來,搜索引擎已經進化到類似人類助手一樣能回答針對任何事物的復雜問題的程度。然而,盡管互聯網搜索引擎能夠導航非常巨大的知識范圍,但是我們要達到智能助手的能力還很遠。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13

- 中阿科技論壇(中英文)的其它文章
- The Potentials,Challenges and Path for Achieving Science and Technology Cooperation between China and Arab States under the Background of the Belt and Road Initiative
- Enterprise Asset-backed Securitization:Legal Structure Is Not So Vulnerable
- Development of Automatic Transfer Device for Tie Line between Substation Areas in View of Carrier Communication
- Computer Aided Design of Straw Checkerboard Sand Barriers Paving Machines
- Research on Abnormal Increase of Metro Track Potential
- Analysis of Reasons on Tripping of Electrolysis Series Causing by Misoperation