(2017年度“華蘇杯”獲獎論文三等獎)基于隨機森林回歸算法的電影評分預測模型
2018-05-21 08:35:53陸君之
江蘇通信 2018年1期
陸君之
中國電子科技集團第二十八研究所
0 引言
隨著人民生活水平的不斷提高,觀看電影已經成為了大家日常生活中不可或缺的娛樂方式之一。我國作為全球第二大電影市場,電影產業規模一直保持著每年30%左右的增長,煥發出旺盛的生命力和巨大的可持續發展潛力。然而整個市場的電影質量卻是參差不齊,每年都會有大量大家俗稱的“爛片”上映,并且各大電影評分網站存在制片公司雇傭“水軍”刷評分的現象,導致觀眾在觀看前沒有信息渠道真正判斷一部電影的好壞,電影評分預測模型可以對尚未上映的電影做出客觀的評分,供觀眾進行參考。
本文主要結構如下:第1節介紹本實驗所使用的相關技術和資源介紹;第2節介紹基于隨機森林算法的電影評分預測模型的建模過程;第3節是實驗內容與結果的分析,最后一節是總結與展望。
1 相關介紹
1.1 Spark MLlib
Spark是一個用來實現快速而通用的集群計算的開源簇運算框架。它擴展了廣泛使用的MapReduce計算模型,適用于各種原先需要不同分布式平臺的場景,大大減輕了原先需要對各種平臺分別管理的負擔。spark可以在內存中進行計算,因而它比MapReduce更加高效,即使在硬盤上進行運算,它也比MapReduce更快。
MLlib是Spark中提供機器學習函數的庫,它是專為在集群上運行的情況而設計的。MLlib可使用許多常見的機器學習和統計算法,這些算法用來在集群上針對分類、回歸、聚類、協同過濾等,簡化大規模機器學習時間。其中一些算法也可以應用到流數據上,例如使用普通最小二乘法或者K均值聚類(還有更多)來計算線性回歸。
1.2 豆瓣電影網
豆瓣電影網是國人最常用的對電影進行打分,寫影評的數據網站,相比于IMDB更能體現國人對于電影文化的理解。雖然近年來豆瓣電影也開始出現“水軍”刷分的現象,但是從“水軍”現象的根源來看這并不影響豆瓣電影以往評分的真實性和有效性,并且雖然有延時性,豆瓣電影網也會將“非正常打分”的行為進行判斷并不計入評分。
豆瓣電量評分的主旨和原則是“盡力還原普通觀影大眾對一部電影的平均看法”,是國內最公平公正的電影評分網站之一。國內相當多的電影評論節目,例如“暴走看啥片兒”,也將豆瓣電影評分作為衡量標準向觀眾推薦電影。它的電影數據也是符合本實驗需要的,本實驗用于數據分析實驗的數據從豆瓣電影網上爬蟲獲取。
2 基于隨機森林回歸算法的電影評分預測模型
本文選用隨機森林回歸算法來做實驗基于以下原因:
(1)電影中導演的評分、演員的評分、編劇的評分等輸入特征之間可能存在潛在的相關性,但對于這些相關性很難正確的去進行衡量,因此對于特征之間多重共線性十分敏感的算法是不適用的。隨機森林算法對于特征之間相關性并不敏感,也不需要對特征進行選擇,非常適用于本次回歸實驗。
(2)隨機森林算法魯棒性很好,對于離散數據點相對而言不敏感,由于電影信息多樣性,難免會有噪音數據,隨機森林算法可以有效的避免這些數據對于最終模型的影響。
(3)隨機森林算法可以評估所有輸入特征的重要性,為下一步研究向大眾推薦高質量電影打下基礎。
2.1 特征工程
特征工程是大規模機器學習中非常重要的一步,特征選取的好壞直接影響到算法的效率。信息豐富的輸入特征與將現有特征轉換為合適的向量都能夠極大的改進實驗結果。本實驗的特征選擇結合中國內地電影市場實際情況,選取導演、編劇、主演、類型、國家地區作為特征,如公式(1)所示:
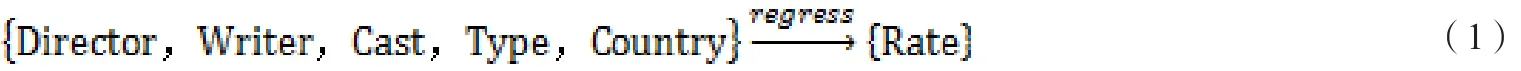
其中:Director表示導演執導水平特征,Writer表示編劇水平特征,Cast表示主演水平特征,Type表示影片類型特征,Country表示國家地區特征,Rate表示電影評分。
本節具體闡釋影響電影評分的重要因素并給出相應定義,為隨機森林回歸模型的建立做好準備。
(1)導演執導水平特征
導演是電影創作團隊的領導者和組織者,決定了電影藝術風格,對電影質量起到了非常重要的影響因素。本實驗中以導演之前執導電影所獲得的評分以及評分人數作為導演執導水平特征。考慮到雖然電影評分人數也是非常重要的維度,但是將電影評分人數單獨作為一個輸入特征引入的話,特征之間scale差距過大,會對收斂速度造成嚴重影響,所以我們將電影評分和電影評分人數作為一個特征組合來引入特征集中,作為對影人水平的綜合評分,如公式(2)所示:

n表示導演參與拍攝的所有電影作品中,距離該部電影上映最近的n部電影,n取值小于等于5;
Rk表示導演拍攝的第k部電影的評分;
Pk表示導演拍攝的第k部電影的評分人數。
(2)編劇水平特征
編劇是電影劇本的創作者,劇本是電影拍攝的基礎,決定了電影的上限。本實驗取編劇主創的所有電影劇本中,距離該部電影上映最近的n部電影,n取值小于等于5,如公式(3)所示:

Rk表示編劇創作的第k部電影的評分;
Pk表示編劇創作的第k部電影的評分人數。
(3)主演水平特征:
演員具有獨特的個人魅力,演員的發揮直接影響到一部電影口碑的好壞。考慮到大部分演員每年參演電影作品數量很多,對于演員的特征字段,本實驗會參考演員參與拍攝的所有電影作品中,距離該部電影上映時間最近的n部相同類型且由他主演的電影,n取值小于等于5,主演水平特征計算公式(見公式(4))及說明如下:
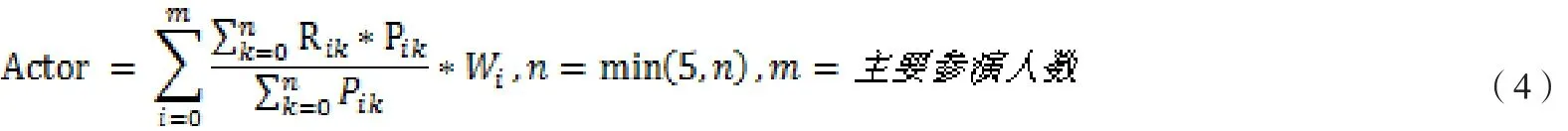
Rik表示第i位主演拍攝第k部電影的評分;
Pik表示第i位主演拍攝第k部電影的評分人數;
Wi表示第i位主演在此部電影的權重,這里本實驗權重設置如表1所示,參演人數多于4位,則從第5位開始不考慮其對電影的影響。
(4)影片類型
電影有愛情片、動作片、喜劇片等多種類型組合,觀眾在不同時期可能對電影的類型有不同的喜好。因此電影類型對于其口碑是非常重要的特征,電影類型決定了它內容的表現形式,觀眾基礎和影響力。因為一部電影經常會被貼上多種類型標簽,所以對于該特征本實驗需要綜合考慮各個類型的權重計算得到它的評分。本實驗取上一年此類型電影平均得分作為參考值,比如電影《寒戰》于2012年11月08號上映,則分別選取類型為劇情、動作、犯罪且上映時間范圍應該為
2011年11月08號到2012年11月08號的電影,計算得到此 類型電影的參考評分,見公式(5)與(6):

Rik表示第k部類型為i的電影的評分;
Pik表示第k部類型為i電影的評分人數;
Ri表示第i種類型電影綜合評分;
Wi表示第i種類型在此部電影中的權重。
(5)國家地區
根據制片公司所在國家或地區的不同,觀眾受個人的文化背景和社會背景影響對于該地區的電影的看法也是不同的,因此國家地區也是電影口碑重要的特征之一。本實驗取上一年此國家地區電影平均得分作為參考值,比如電影《寒戰》于2012年11月08號上映,則選取同為香港制作且上映時間范圍應該為2011年11月08號到2012年11月08號的電影,計算得到此電影的參考評分,見公式(7):

Rk表示第k部電影的評分;
Pk表示第k部電影的評分人數。
3 實驗和結果分析
3.1 數據獲取
本實驗基于SCRAPY框架,采用“深度優先”算法,爬蟲收集豆瓣電影網從2000年至2016年上映的所有電影數據作為本次實驗的數據集,首先從豆瓣電影網的各個標簽下的電影列表爬取獲取電影信息,然后獲取每一部電影相關推薦和影人代表作品中的電影加入到爬取隊列中去,最終共收集到8萬多條電影數據。經過整理,電影屬性如表2所示:

表2 電影屬性表
3.2 實驗過程
(1)隨機森林算法回歸建模:
本實驗利用spark mllib的randomforest包實現隨機森林回歸算法。首先將2015年以前出品的電影的評分數據作為訓練數據,2016年出品的電影數據作為測試數據。我們將處理好的特征字段和電影評分處理成Labeledpoint,LabeledPoint是spark中用來表示帶標簽的數據點,包含一個特征向量和一個標簽(由一個浮點數表示),本實驗中標簽為電影的評分,特征向量為上述特征工程所處理的,構造的LabeledPoint,見公式(8)
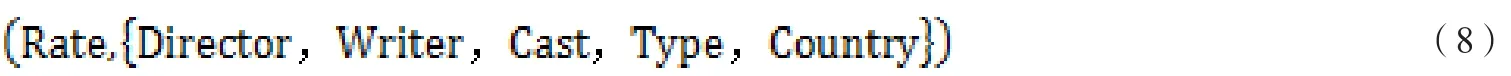
使用mllibtree.RandomForest的trainRegressor()方法來建立起隨機森林回歸模型。TrainRegressor()方法會返回一個weightedEnsembleModel對象,本實驗使用此對象的predict()方法對測試集預測對應的值,即電影評分。接下來的實驗中,將測試數據輸入到建立好的隨機森林中進行測試。
(2)誤差對比
本實驗除了給出使用隨機森林回歸算法模型的誤差,還采用了DT算法、GBDT算法、Isontonic算法進行對比,誤差比較如表3所示:
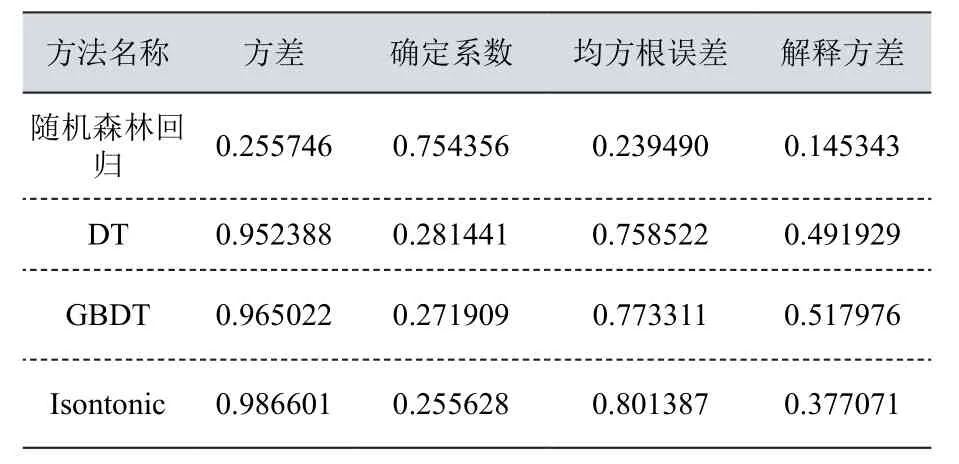
表3 算法誤差對照表
從上述對預測的誤差對比試驗可以看出,本文所使用的隨機森林回歸算法建立的模型預測性能明顯優于其他算法模型,在預測電影評分時相對誤差遠低于其他算法,同時它的確定系數也是最高的,說明這個模型在數據擬合上的表現是最好的。
本實驗部分電影預測結果如下表4所示:
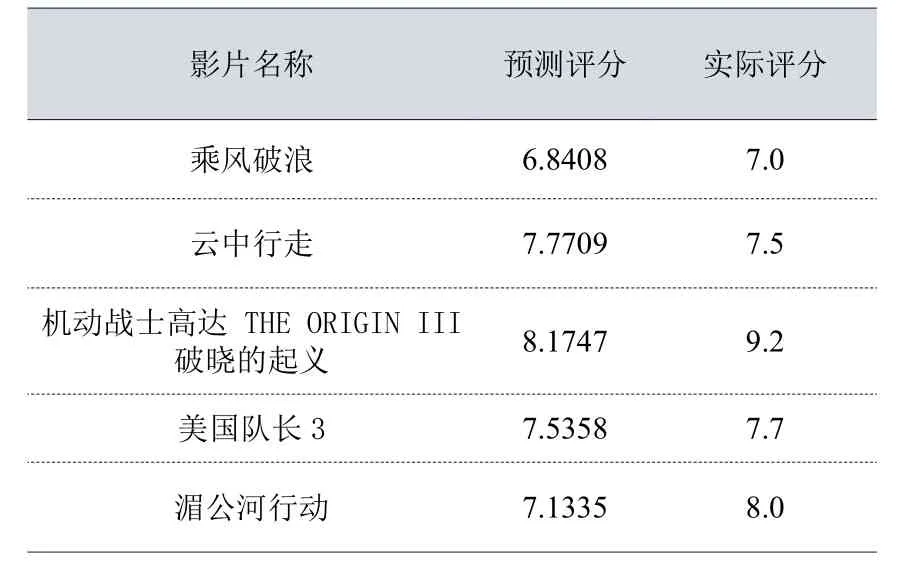
表4 部分電影評分預測結果表
4 總結和展望
本文從實際的中國電影產業市場出發,提出一種基于隨機森林回歸算法的電影評分預測模型,將機器學習應用于電影評分預測領域,通過將導演、編劇、主演、類型、發行國家地區作為影響電影評分的特征,對其進行特征工程處理。通過對比試驗,隨機森林回歸算法模型確實比其他算法在預測電影評分的相對誤差更低,同時預測的確定系數也更高。綜上所述,本文提出的基于隨機森林回歸算法的評分預測模型解決了電影評分預測精度不高的問題,能夠為大眾推薦電影提供有價值的參考,具有實際的意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
