
基于微博短文本的大數據分析方法探索與研究
2018-05-21 08:35:55宋嘯天姚家偉
江蘇通信 2018年1期
宋嘯天 姚家偉
鎮江市人民檢察院
0 引言
中國互聯網絡信息中心(China Internet Network Information Center,CNNIC)在2017年1月發布了第39次《中國互聯網絡發展狀況統計報告》,其中指出截至2016年12月,我國網民規模達7.31億,手機網民規模達6.95億,占比達95.1%,增長率連續3年超過10%。2017年5月,新浪微博發布2017年第一季度財報,截至3月31日,微博月活躍用戶達3.4億,位居世界第一。
國內在大數據分析領域的研究起步較晚,但是發展較快。中國社科院、人民日報社和國內多所大學于2006年就開始了相關研究,此外國內還有諸如中科點擊(北京)科技有限公司的軍犬網絡輿情監控系統、紅麥聚信(北京)軟件技術有限公司的unotice輿情系統、南京綠色科技研究院的CCLA網絡輿情分析系統等多個輿情分析軟件,取得了較大的進展。
微博是一種兼具流行和新興的社交方式,由于微博短文本中的語言表達較口語化,同時由于“未登錄詞”(沒有被收錄在分詞詞表中但必須切分出來的詞,如縮寫詞匯、專有名詞、新增詞等)的存在,導致大數據分析的難度較大。本文針對以上問題,首先對需要進行預處理的微博文本內容進行了闡述,隨后提出了一種基于“未登錄詞”的識別算法,并設計了面向微博短文本的聚類整合算法。
1 微博短文本預處理
短文本通常具有錯誤性大、時效性強、信息量少、詞語更新頻率快等特點。微博短文本除了具備以上共性特點外,還具備有語言符號化(以符號代替文字)、互動性強、詞語省略等特點。所以,為了進行微博短文本大數據的有效分析,需要首先對文本內容進行處理,處理流程如圖1所示。
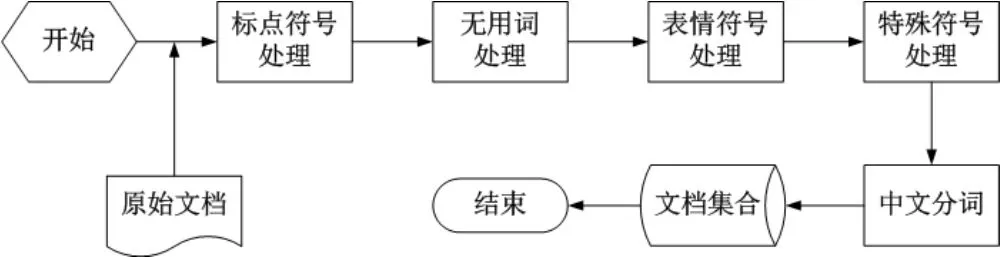
圖1 微博短文本預處理流程示意圖
(1)標點符號
在傳統的中文分詞方法中,會自動刪除標點符號后利用詞庫分詞。但是微博短文本與傳統文本不同,標點符號往往摻雜著作者的情感要素,需要單獨進行處理。例如:“?”一般表示疑惑或者疑問,“。”一般表示無感情的稱述,“!”一般表示語氣加重或者驚訝。
(2)無用詞
在一篇微博短文本中,會出現一些沒有任何明確意義和具體含義的詞語,本文將此類詞語稱為無用詞。由于無用詞的存在會極大的影響文本分析的效率和準確率,因此應當在預處理過程中對無用詞進行提取并刪除。無用詞主要包含亂碼、錯誤詞匯等。
(3)表情符號
微博官方為了豐富交互的多樣性,加入了大量的表情符號,這些表情符號有時甚至可以表達作者一整句話的內涵。在微博的文本數據中,表情符號位于<img>標簽的“title”屬性之中,且這些表情符號也有對應的文字表示,例如:用“[doge]”表示,用“[攤手]”表示。為了更加精確的進行微博短文本的處理,也需要將相關的表情符號單獨抽取出來進行隱藏價值的分析。
(4)特殊符號
在微博的短文本制作過程中,可以用到“@”和“##”這兩個基本功能。其中,“@”表示作者希望位于“@”字符后的用戶關注此條微博內容,“##”中間的詞語表示一個話題。由于“@”和“##”關聯的詞語無需進行詞義分離,所以在分詞前應將對應內容提取出來,并在后期整理時參與文本分析。
但是,微博的詞語更新頻率較快,目前大多數分詞系統的詞庫無法做到100%的未登錄詞識別,這就導致分詞結果正確率會隨著未登錄詞占比的上升而下降。所以,本文針對微博短文的未登錄詞提出了一種智能的識別算法。
2 微博未登錄詞的識別算法研究
目前常見的UW(Unknown Word,未登錄詞)算法主要是基于統計的CRF(Conditional Random Field,條件隨機場)、SVM(Support Vector Machine,支持向量機)等方法。基于有監督方法的基本原理如下:
(1)對比模型和樣本參數提取新詞,如HMM(Hidden Markov Model,隱馬爾可夫模型)和VA(Viterbi Algorithm,維特比算法);
(2)統計涉及新詞的詞句出現次數,并根據閾值判斷新詞的使用程度,如獨立字概率方法。
而無監督方法是當循環統計中發現新詞的重復次數大于實驗計算得出的標準值時,則將新詞確認為UW。
兩種方法的挖掘過程如圖2所示。

圖2 UW挖掘方法圖
在分析微博短文本的特點時,可以直接提取“##”和“【】”中間的文本(話題文本)。微博正文則采用文本分詞法進行劃分處理,UW的確認步驟可簡單的分為以下三步:
(1)確認候選詞;
(2)通過計算MI(Mutual Information,互信息)方法篩選候選詞;
(3)確認UW。
具體流程如圖3所示。
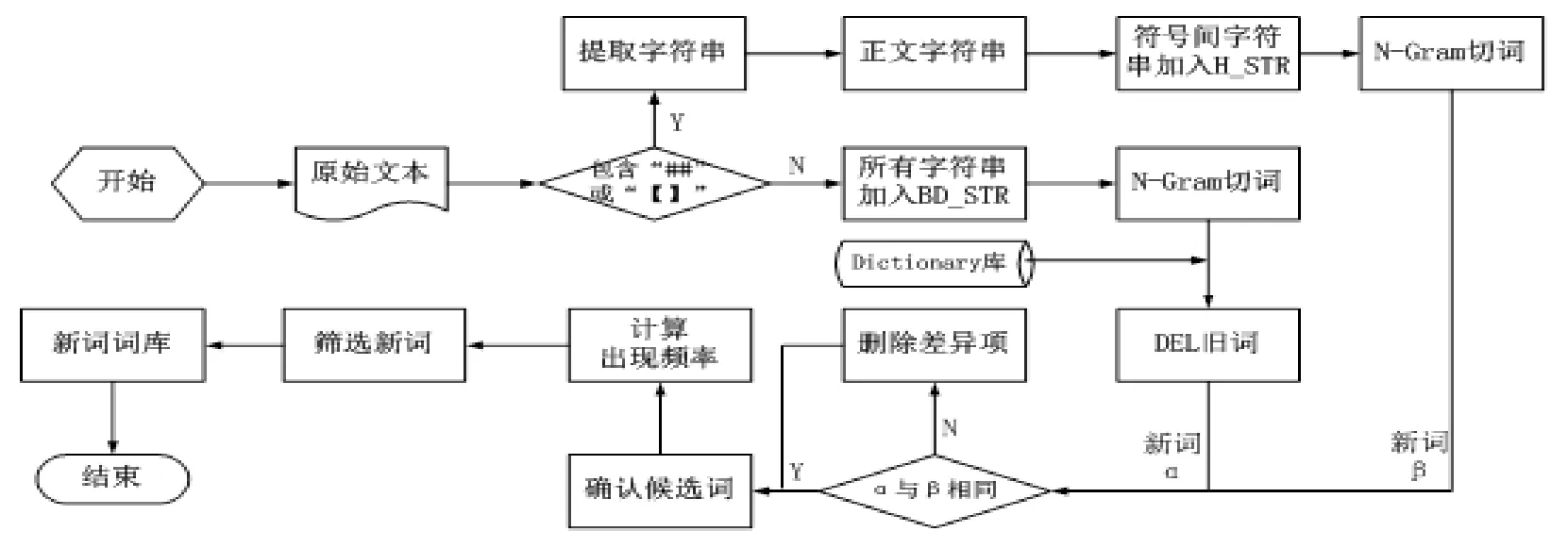
圖3 UW識別算法流程示意圖
其中,N-Gram是指一種N元的切詞方法,即將字符串分割為長度為 N ( 2 ≤ N ≤ 5 ) 的子串,并得到分割詞匯,隨后通過篩選確認較為重要的詞匯,最后在篩選詞中確認候選詞。差異項的刪除過程可分為以下十步:
(1)匹配詞庫和切詞的結果;
(2)刪除已存在詞匯;
(3)刪除 H _ S T R 中 不存在于 B D _ S T R 中的詞匯;
(4)詞典遍歷;
(5)刪除舊詞;
(6)計算候選詞出現頻率;
(7)刪除出現頻率低于標準值的詞匯;
(8)利用MI技術和AS(Adjacent String,相鄰串)過濾候選詞;
(9)當詞匯間包含PS(Public String,公共字串),例如“檢察機關公訴”和“察機關公訴處”,將以上兩個詞匯分別記做 A和 B,當頻率計算時發現 和 均存在且頻率相同,則將A和B進行組合為聯合詞匯 AB,即“檢察機關公訴處”,反之則刪除頻率詞匯;
(10)利用MI技術計算AB能否構成UW。
當算法的過濾層次越高時,UW的識別準確率也越高。當詞庫本身不健全或是判斷范圍沒有覆蓋短文本全部內容時,將導致識別準確率有一定幅度的下降,但是本文提出的算法在計算速度和準確率上仍有較好的保證。
3 面向微博短文本的聚類整合算法
在微博短文本大數據分析的框架體系內,文本聚類是其中的一項基礎工作。微博短文本信息主題分散、長度不一、沒有較為顯著的共性規律。為了在這些大量錯綜復雜的文本信息中挖掘出具備價值的內容,是聚類算法需要參與其中的主要因素之一。
傳統的基于文檔主題生成模型(Latent Dirichlet Allocation,LDA)的K-MEANS算法可用于對文本模型進行聚類計算,算法框架如圖4所示。
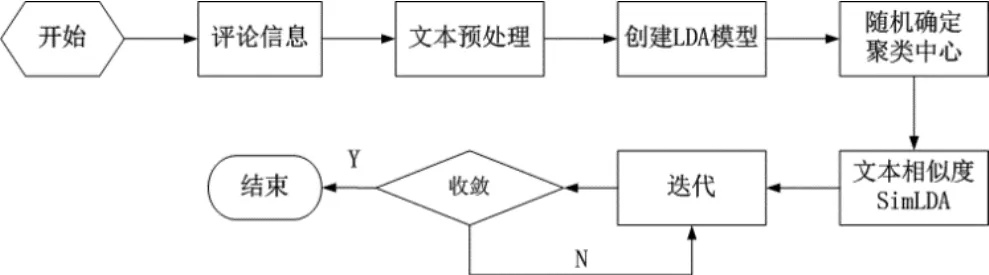
圖4 LDA-K-MEANS算法框架示意圖
由于該算法的初始中心是通過隨機或主觀經驗的方法進行設定,所以容易過早收斂,導致局部最優;并且該算法在分析詞匯間語義時會進行降維處理,這就使得文本的完整性受到影響。對此,本文設計了一種新型的面向微博短文本的聚類整合算法。主要從以下兩點進行調整:
(1)調整初始中心
為了改進傳統K-MEANS聚類算法初始中心選取客觀性較弱的問題,本文采取概率論理念對其加以改進。在調整后的初始中心選取算法中,本文將數據文本的相關主題內容表示為對應的關系矩陣,不同的主題對應的重要度也各不相同,重要度越高的主題越能反映文本的核心內涵。該算法主要可分為以下三步:
1)選取重要程度和關聯程度較高的主題;2)根據主題詞進行文本內容預處理;
3)獲取收斂中心并作為聚類文本的初始中心。
由于單一的主題詞沒有整體的評估價值,所以需要對主題詞的分布概率進行總結,并得出其在文本集合中的重要性。隨后對文本集合重要性由高至低排序并選取排名靠前的主題詞,運用K-MEANS算法對文本集合進行初始聚類,再計算被選取主題詞的相似度,得到對應的中心點,最后將這些中心點作為K-MEANS的初始中心點。
(2)調整相似度算法
傳統的K-MEANS算法中相似度的計算是基于“文本—主題”的語義關聯模型,但維度的降低將導致相似度的計算結果精確度較差。通過融合VSM(Vector Space Model,向量空間模型)的算法(L_VSM),可以在不損壞文本信息完整性的同時能夠在分析上挖掘出更深層次的關系,提升相似度算法準確性。由于采取了線性融合的方式,使得其準確率高于LDA算法和VSM算法,并且在計算過程中也保留了語義的關聯關系,使得面向微博短文本的聚類整合算法準確率較高、運算速度較快。面向微博短文本的聚類整合算法流程如圖5所示。
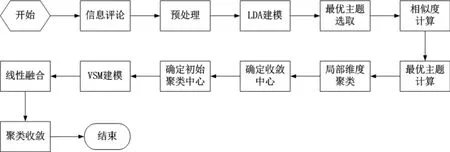
圖5 面向微博短文本的聚類整合算法流程示意圖
通過后續的模擬仿真測試,本文提出的面向微博短文本的聚類整合算法與LDA算法、VSM算法相比,其聚類F-Measure值(一種評價分類模型好壞的統計量)較高。初始中心杜絕了隨機選取過早收斂的問題,符合微博短文本的實際分布情況。面向微博短文本的聚類整合算法通過線性融合,在一定程度上緩解了LDA算法降維和VSM算法語義聯系弱帶來的影響,使得相似度計算的準確率較高,有助于提升微博短文本的聚類分析質量及成效。
4 結語
互聯網大數據的分析系統在國內外已經得到了較為廣泛的應用,但是如何針對微博短文本進行縱深的大數據分析,以及如何將分析得出的內容更加有效的在社會發展中發揮出應有的作用,仍是我們需要繼續深入研究的工作。由于微博在社交元素中擁有典型性,其用戶群體之間的關系也是潛移默化、盤根錯節的,本文將以此為切入點,在后續的研究中繼續開展深入分析。
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
電子制作(2018年18期)2018-11-14 01:48:06
山東醫藥(2017年35期)2017-10-10 02:45:28
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
語文知識(2014年1期)2014-02-28 21:59:13
