電網數據存儲技術選型的研究
2018-05-25 06:37:05李成嶺鄭雨翔洪祎祺李雯郭慧敏
電信科學 2018年5期
李成嶺,鄭雨翔,洪祎祺,李雯,郭慧敏
(1.國網上海市電力公司浦東供電公司,上海 200122;2.上海中興電力建設發展有限公司,上海 200122)
1 引言
國網遼寧省電力有限公司全業務統一數據中心數據分析域非結構化數據接入方面涉及非結構化數據管理平臺中電子文件管理系統、檔案系統、電網GIS地理空間信息系統、營銷業務系統、安監系統、PMS2.0、協同辦公系統、電力交易系統、ERP、計量生產調度平臺、營銷GIS、基建管理信息系統等 34個業務系統接入非結構化數據管理平臺的非結構化數據。綜合考慮,主要通過測試80 GB文件的寫入、讀取場景過程中分布式文件系統性能各種指標的不同數量大小,如節點數量的大小、備份因子的大小、數據塊的大小,對國網公司大數據平臺分布式文件系統(基于HDFS優化封裝)的讀寫性能進行測試。
2 非結構化數據存儲
2.1 節點數量對讀寫性能的影響
下面以測試節點數量對分布式文件系統讀寫性能的影響作為用例來說明。為保障測試結果的準確性,所有的測試節點的物理配置需保持一致,且在一個分布式集群下,數據塊大小統一默認為128 MB,其他參數都保持一致。在統一的測試環境下,實施測試操作:跨節點遠程寫入和讀取80 GB文件,分別記錄耗時;分別在不同工作節點上本地寫入和讀取80 GB文件,分別記錄耗時;重復以上步驟,分別測試2個、3個DataNode的HDFS集群環境,跨節點遠程寫入文件、節點本地寫入文件耗時,測試結果如下所示。
(1)1個DataNode的HDFS集群
1個DataNode的HDFS集群的測試結果見表1。
(2)2個DataNode的HDFS集群
2個DataNode的HDFS集群的測試結果見表2。
(3)3個DataNode的HDFS集群
3個DataNode的HDFS集群的測試結果見表3。
集群的規模增大,在DataNode上讀取數據的性能優勢將越來越小,因為數據塊分布越來越稀疏,在一個數據節點上能夠取得的數據塊越來越少,需要通過網絡進行傳輸的數據越來越多。另外,隨著集群規模的增大,客戶端讀寫的速率有遞減的趨勢。

表1 1個DataNode的HDFS集群的測試結果
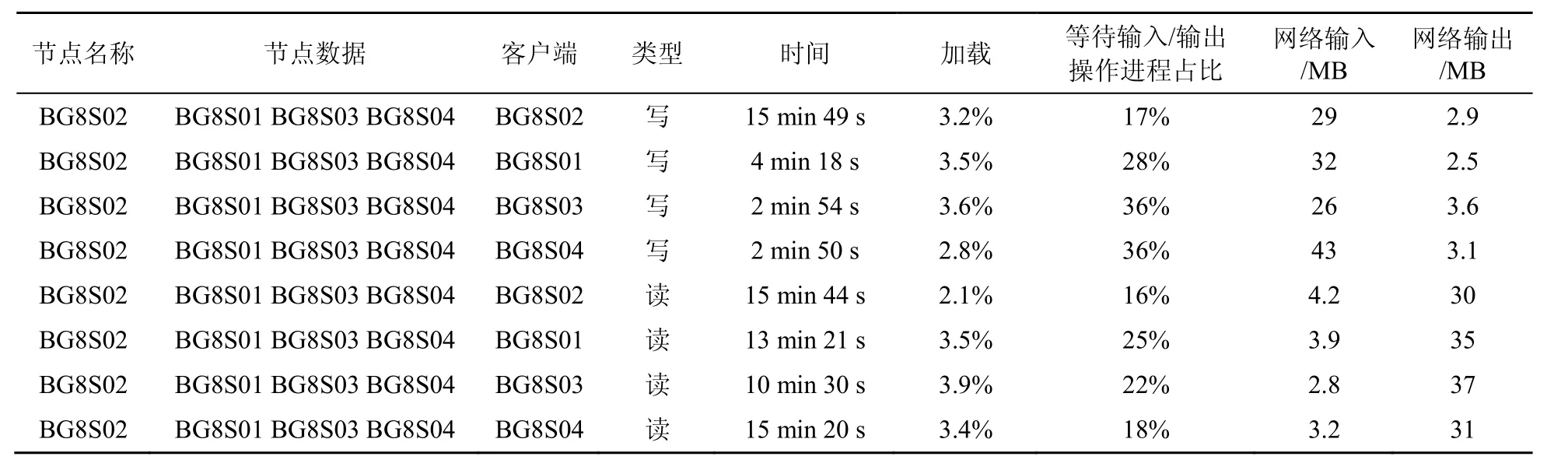
表3 3個DataNode的HDFS集群的測試結果
2.2 備份因子數對讀寫性能的影響
下面以測試備份因子數對分布式文件系統讀寫性能的影響作為用例來說明。為保障測試結果的準確性,所有的測試節點的物理配置需保持一致,節點數量為3。在統一的測試環境下,實施測試操作:設置備份因子數為1,跨節點遠程寫入和讀取80 GB文件,分別記錄耗時;分別在不同工作節點上本地寫入和讀取80 GB文件,分別記錄耗時;重復以上步驟,分別測試備份因子為2、3的HDFS集群環境中跨節點遠程讀寫文件、節點本地讀寫文件耗時,測試結果如下所示。
(4)備份因子為1~3情況下的寫性能測試
備份因子為 1~3情況下的寫性能測試結果見表4。
(2)備份因子為1~3下的讀性能測試
備份因子為 1~3情況下的讀性能測試結果見表5。
備份因子的改變不影響客戶端的讀寫性能,客戶端的 I/O瓶頸依然是交換機的傳輸速率。備份因子數增加時,客戶端寫的時間有小幅度的增加,這是因為要把同一個塊寫到不同的機器上,增加了寫的開銷。備份因子的增加使本地寫文件性能下降,本地讀文件性能提高。
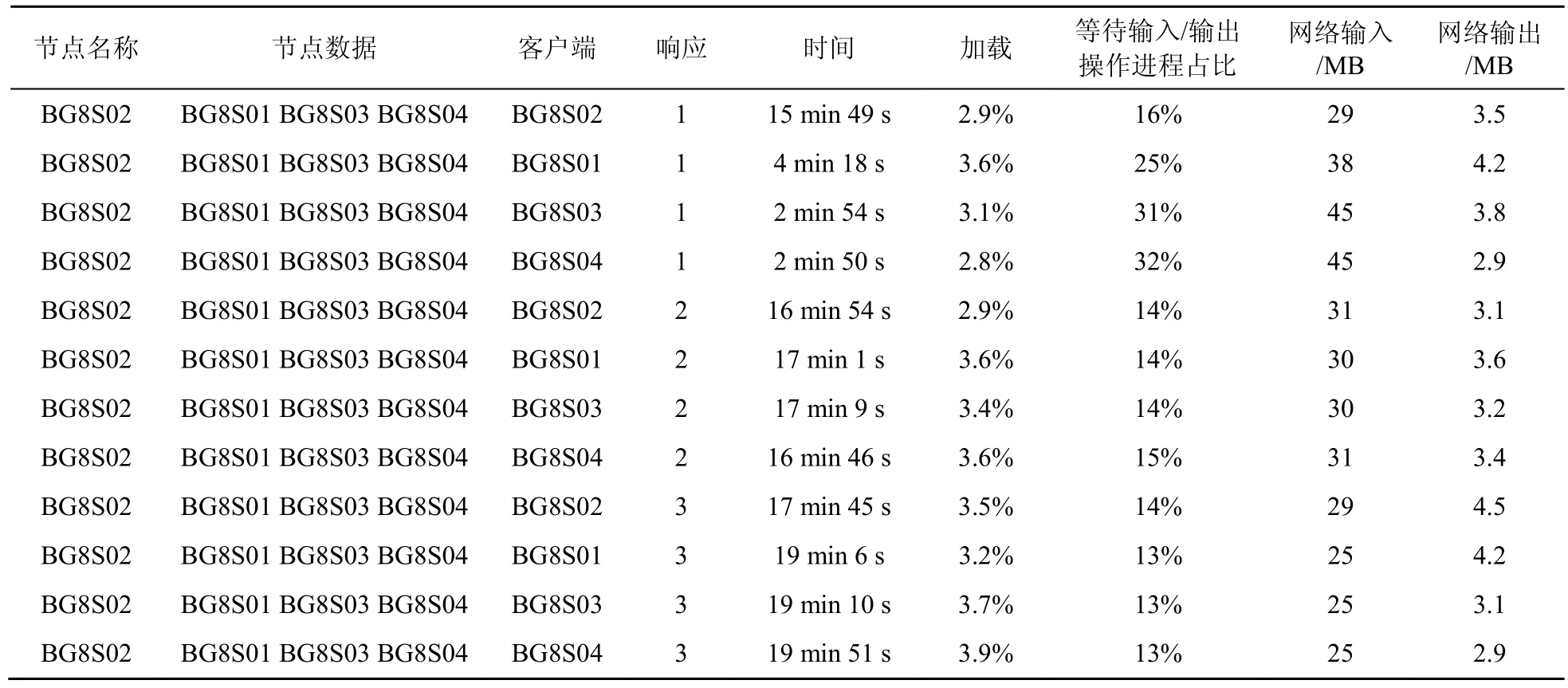
表4 備份因子為1~3情況下的寫性能測試結果
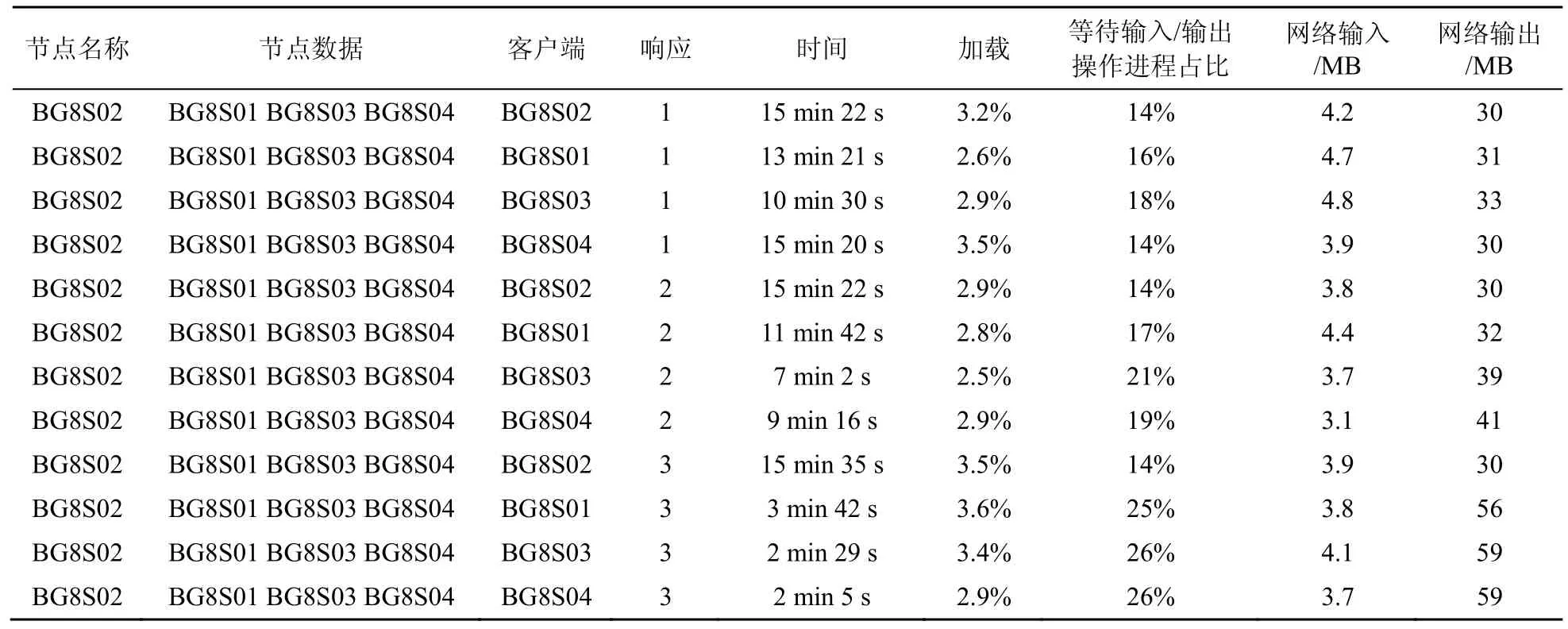
表5 備份因子為1~3情況下的讀性能測試結果
2.3 數據塊大小對寫入性能的影響
下面以測試數據塊的大小對分布式文件系統讀寫性能的影響作為用例來說明。為保障測試結果的準確性,同上一項測試設置相同,節點數量為3個,備份數為3。在統一的測試環境下,實施測試操作:設置設置塊大小為4 MB,跨節點遠程寫入80 GB文件,記錄耗時;重復以上步驟,分別測試備份因子為4 MB、8 MB、16 MB、32 MB、64 MB、128 MB、256 MB、512 MB、1 024 MB時的HDFS集群環境,跨節點遠程讀寫文件、節點本地讀寫文件耗時,測試結果如下所示。
經測試,當數據塊逐漸增大,寫入時間在總體上是一個遞減的趨勢,但當塊增大到一定程度之后,寫入時間趨于平穩,即數據塊的增大只能在一定的范圍內影響HDFS的讀寫性能,如果把數據塊的大小設置為更大的,那對性能的影響就微乎其微。
分布式文件系統功能方面主要需測試分布式文件系統的負載均衡、節點動態拓展。
2.4 負載均衡
下面以測試分布式文件系統負載均衡的功能作為用例來說明。為保障測試結果的準確性,測試節點在1個分布式集群下,集群上已有一定數據存儲負載,測試新添節點后執行負載均衡。在統一的測試環境下,實施測試操作:搭建一個2個節點的 HDFS統集群;寫入一定量數據,查看HDFS監控頁面,查看并記錄每個節點中塊的數量;集群新添加一個節點,執行負載均衡命令,過20 min后,查看每個節點中塊的數量;多次執行負載均衡,過20 min后,查看每個節點塊的數量測試結果如下所示。
(1)新增測試節點前每個節點中塊的數量情況
搭建的兩個節點:BG8S01和BG8S03,新增測試節點前每個節點中塊的數量分別為458和457。
(2)新增節點后,執行負載均衡每個節點中塊的數量情況
新增節點后,執行負載均衡每個節點中塊的數量情況如圖1所示。
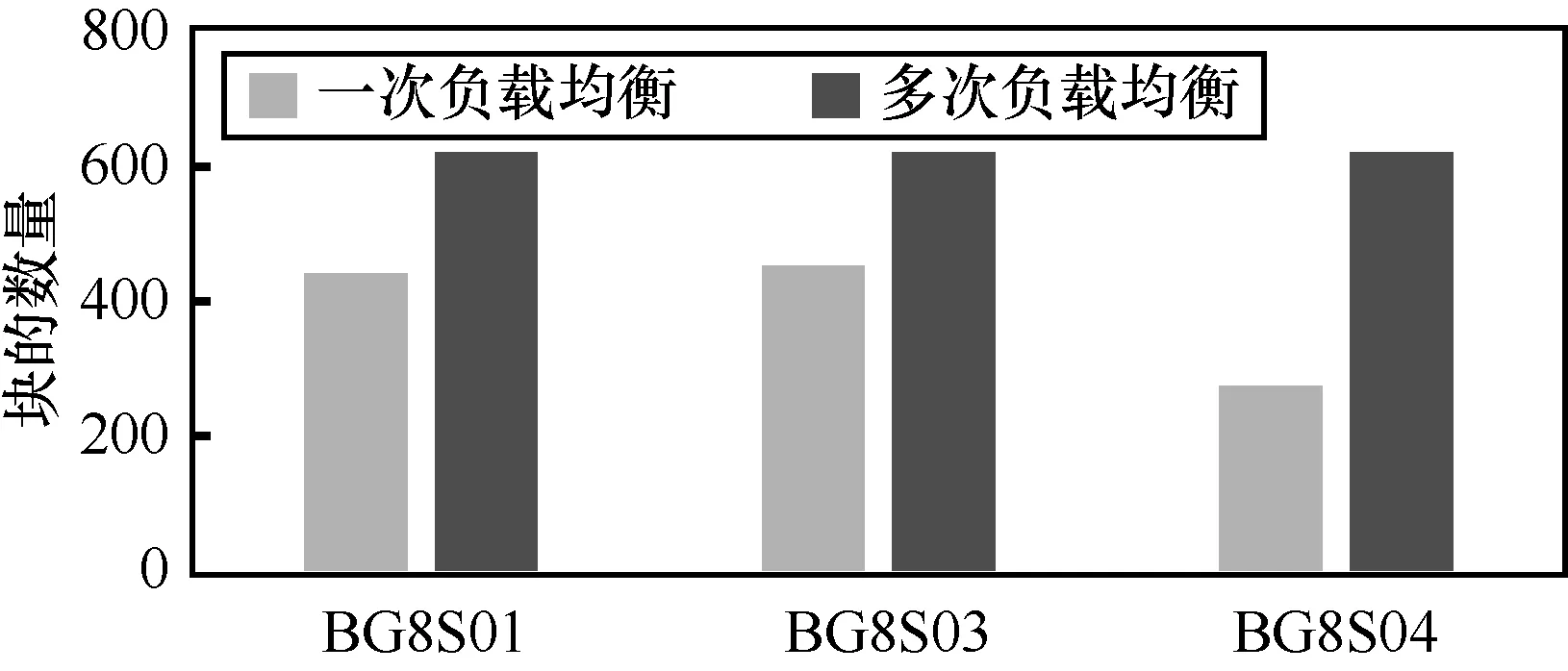
圖1 執行負載均衡每個節點中塊的數量情況
負載均衡的目的雖然是平衡數據,但它并不追求畢其功于一役,而是事先設定目標,每一次執行只實現預設目標,即只是縮小了過載/負載節點與集群平均使用率的差值,而通過反復多次的執行使集群內的數據逐漸趨于均衡。可見,分布式文件系統能通過搭建分布式節點實現系統的負載均衡。
2.5 節點動態拓展
分布式文件系統具備良好的擴展性,能夠動態增加節點,并能保持數據的分布均衡和存儲空間的擴容。
3 實時數據存儲
大數據平臺分布式列式數據庫基于 Hadoop HBase優化封裝,HBase是基于Hadoop的NoSQL數據庫,能夠為大數據提供實時的讀/寫操作,能夠利用 HDFS的分布式處理模式,并通過MapReduce獲取強大的離線處理或批量處理能力,同時能夠融合key/value存儲模式,以實現實時查詢能力。HBase是一個分布式、可擴展、面向列的數據庫,因此可部署在廉價的PC服務器集群上處理大規模的海量數據。
3.1 節點數量對讀寫性能的影響
下面以測試節點數量對HBase讀寫性能的影響作為用例來說明。為保障測試結果的準確性,節點的物理配置一致,測試節點在同一個分布式集群下;HBase配置參數均為默認值。在統一的測試環境下,實施測試操作:寫入1 000萬條數據,其中,每條數據300 byte;rowkey為散列值,長度為12;列族下有3個字段,字段名分別為TN、MP、TO。完成寫入后,計算寫入總時間;對上述表進行讀取性能測試,測試指定rowkey方式單次讀取的速率;重復上述步驟,分別測試在2、3個工作節點的 HBase分布式集群環境下的讀寫性能,測試結果如下所示。

表6 HBase寫入數據測試結果
(1)HBase寫入數據測試
HBase寫入數據測試結果見表6。
(2)HBase讀取數據測試
HBase讀取數據測試結果如圖2所示。
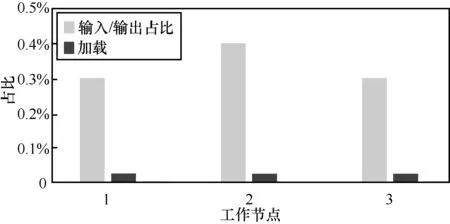
圖2 HBase讀取數據測試結果
隨著集群的規模增大,HBase寫入性能呈線性遞增,單次rowkey讀取的速率近似相等。
3.2 列族數量對讀寫性能的影響
下面以測試列族數量對HBase讀寫性能的影響作為用例來說明。為保障測試結果的準確性,節點的物理配置一致,測試節點在同一個分布式集群下;HBase配置參數均為默認值。在統一的測試環境下,實施測試操作如同上一項測試步驟,測試結果如下所示。
(1)HBase寫入性能測試
HBase寫入性能測試結果如圖3所示。
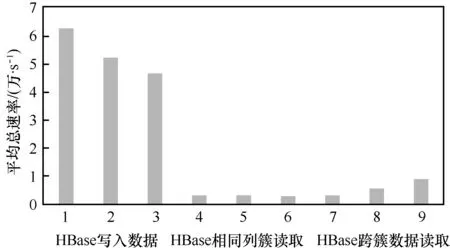
圖3 HBase寫入性能測試結果
列族的數量影響寫入的性能,數量越多則寫入性能越差。在相同列族上的讀取性能差別不大,如果跨列族讀取,列族數量越多則讀取性能越差。
3.3 列名及列族名長度對讀寫性能的影響
下面以測試列名及列族名長度對HBase讀寫性能的影響作為用例來說明。為保障測試結果的準確性,測試節點在 1個分布式集群下,HBase配置參數均為默認值。在統一的測試環境下,實施測試操作:搭建一個3個工作節點的HBase分布式集群環境;新建一張列族名長度為一個字符的HBase列族表,寫入1 000萬條數據,其中,每條數據300 byte;rowkey為散列值,長度為12;列族下有1個字段,字段名長度為1個字符。完成寫入后,計算寫入總時間;對上述表進行讀取性能測試,測試指定rowkey方式單次讀取的速率;重復上述步驟,分別測試在列族明長度為1,列名長度為2、3;以及列名長度為1,列族名長度為2、3的HBase分布式集群環境下的讀寫性能,測試結果如下所示。
(1)HBase 列名及列族名長度不同寫入測試
HBase 列名及列族名長度不同寫入測試結果見表7。
(2)HBase 列名及列族名長度不同讀取測試
HBase 列名及列族名長度不同讀取測試結果見表8。
列名、列族名的長度影響HBase的讀寫性能,長度越長則性能越差。
3.4 rowkey結構對讀寫性能的影響
下面以測試rowkey組成結構對HBase讀寫性能的影響作為用例來說明。為保障測試結果的準確性,測試節點在1個分布式集群下,HBase配置參數均為默認值。在統一的測試環境下,實施測試操作:搭建一個3個工作節點的HBase分布式集群環境;新建一張只有一個列族,列族名長度為一個字符的HBase表;寫入1 000萬條數據,其中,每條數據300 byte;rowkey為流水號散列值,長度為12;列族下有1個字段,字段名長度為1個字符。完成寫入后,計算寫入總時間;對上述表進行讀取性能測試,測試指定rowkey方式單次讀取的速率;重復上述步驟,分別測試rowkey的結構為不散列時在HBase分布式集群環境下的讀寫性能,測試結果如下所示。
(1)不同結構的rowkey寫HBase性能測試
不同結構的rowkey寫HBase性能測試結果如圖4所示。
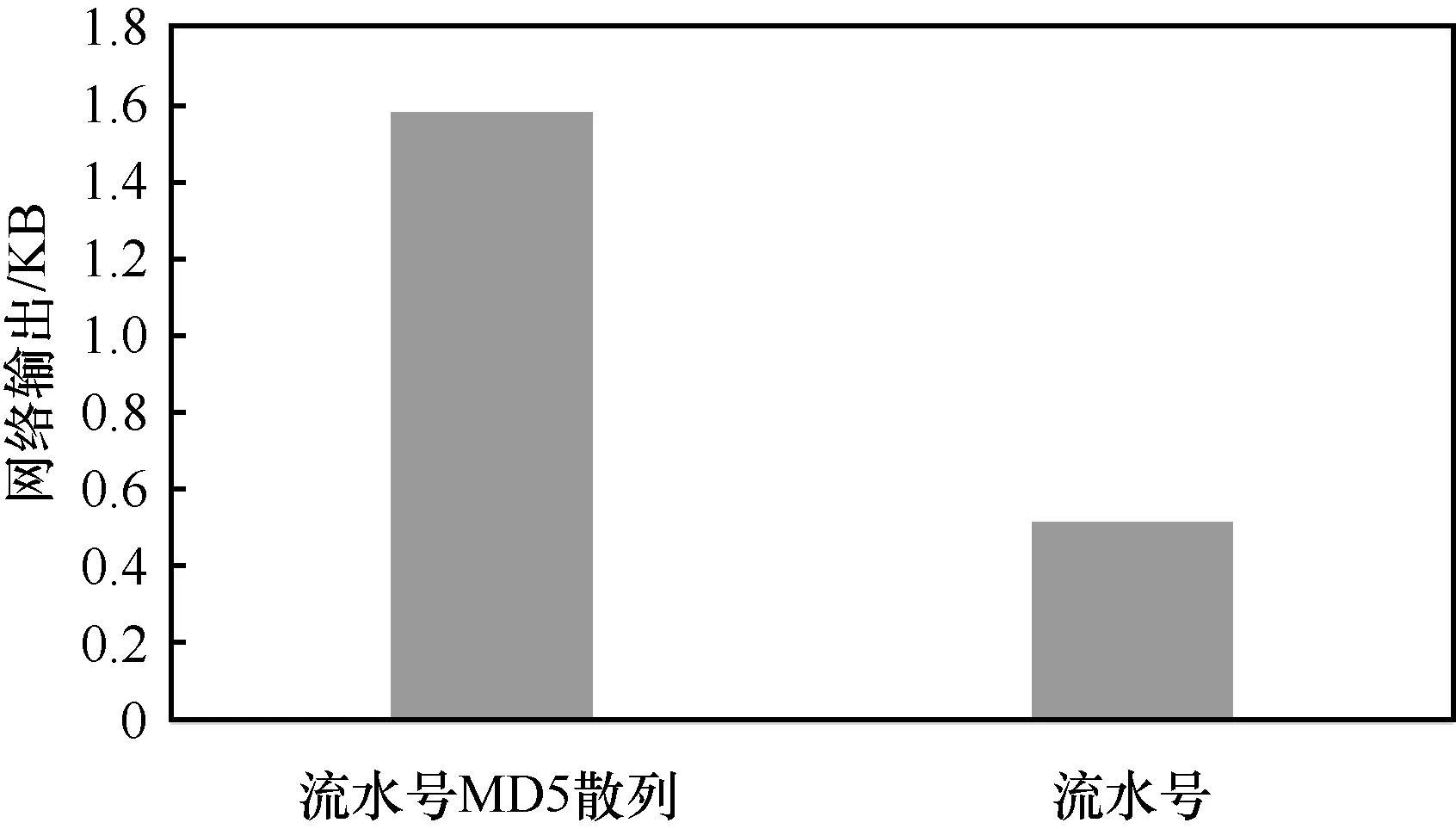
圖4 不同結構的rowkey寫HBase性能測試結果
(2)不同結構的rowkey 讀HBase性能測試
不同結構的rowkey讀HBase性能測試結果如圖5所示。
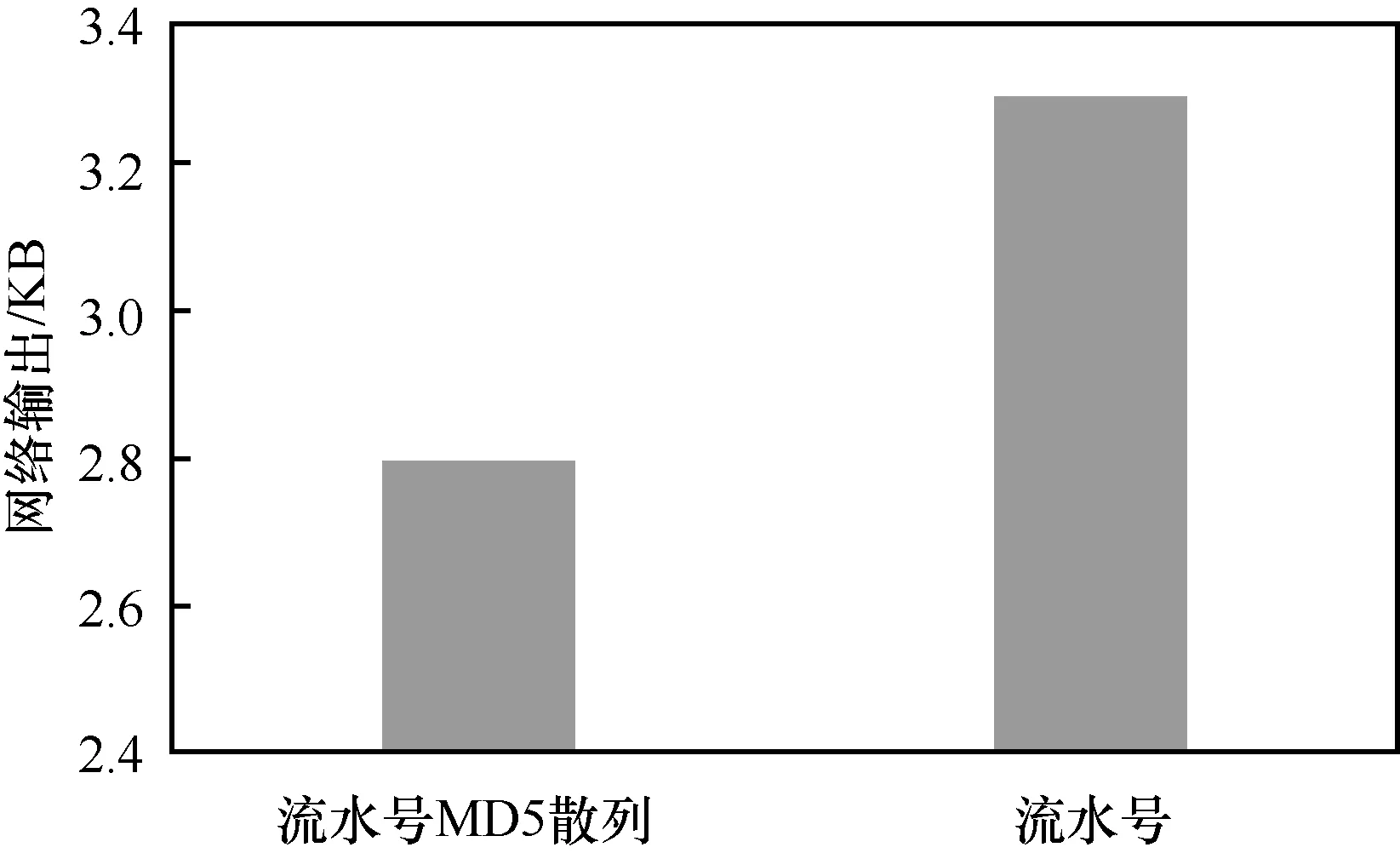
圖5 不同結構的rowkey讀HBase性能測試結果

表7 HBase 列名及列族名長度不同寫入測試結果
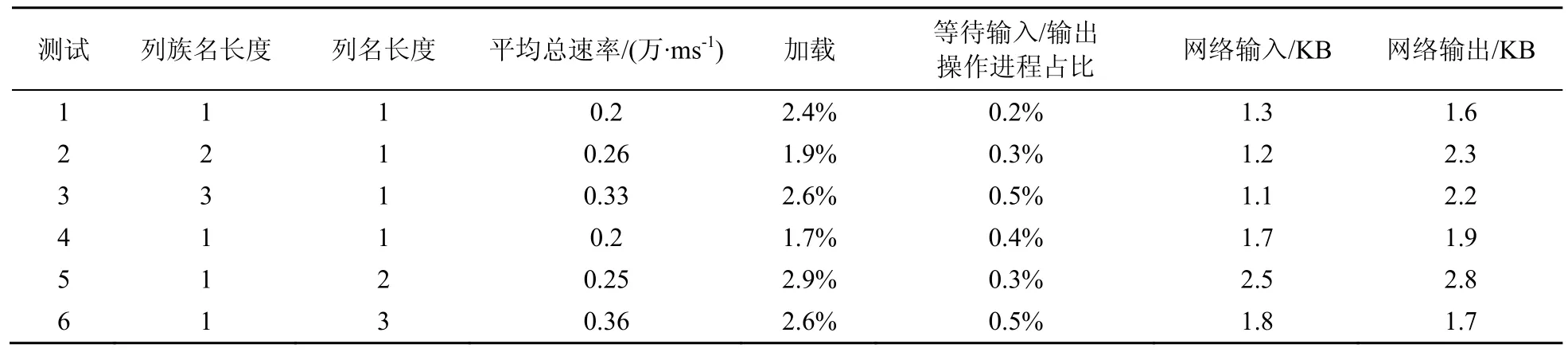
表8 HBase 列名及列族名長度不同讀取測試結果
rowkey結構設計得越離散,讀寫出吞吐量越高,速度越快。
3.5 rowkey長度對讀寫性能的影響
下面以測試rowkey長度對HBase讀寫性能的影響作為用例來說明。為保障測試結果的準確性,測試節點在1個分布式集群下,HBase配置參數均為默認值。在統一的測試環境下,實施測試操作同上一項測試步驟,重復上述步驟,分別測試在rowkey的長度為20、30在HBase分布式集群環境下的讀寫性能,測試結果如下所示。
(1)不同長度的rowkey 寫HBase性能測試
不同長度的rowkey 寫HBase性能測試結果如圖6所示。
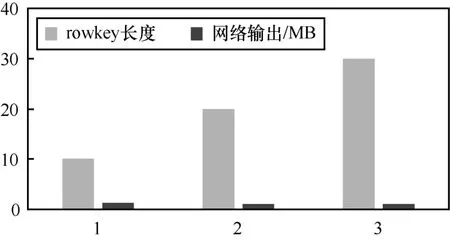
圖6 不同長度的rowkey寫HBase性能測試結果
(2)不同長度的rowkey 讀HBase性能測試
不同長度的rowkey 讀HBase性能測試結果如圖7所示。
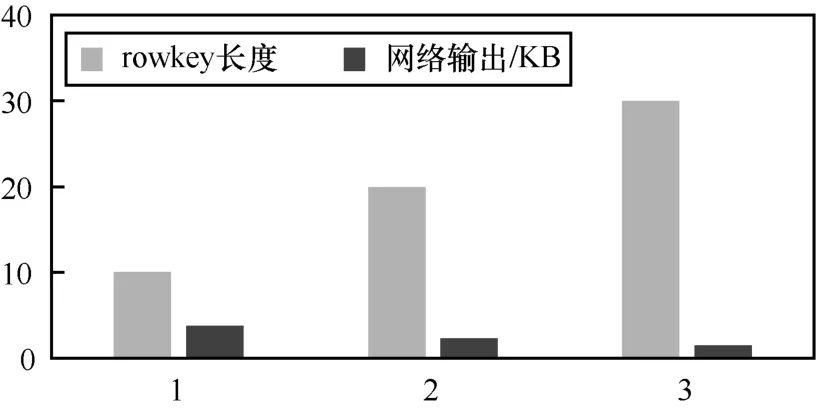
圖7 不同長度的rowkey讀HBase性能測試結果
rowkey的長度影響存取的性能,長度越長則性能越差。
3.6 批量操作對讀寫性能的影響
下面以測試批量操作對HBase讀寫性能的影響作為用例來說明。為保障測試結果的準確性,測試節點在1個分布式集群下,HBase配置參數均為默認值。在統一的測試環境下,實施測試操作同上項測試步驟,對上述表進行讀取性能測試,測試指定rowkey方式單次讀取一條的速率,重復上述步驟,分別測試批量100條、1 000條、10 000條在HBase分布式集群環境下的讀寫性能,測試結果如下所示。
(1)不同批量操作數對HBase寫性能的影響
不同批量操作數對HBase寫性能的影響的測試結果見表9。
(2)不同批量操作數對HBase讀性能的影響
不同批量操作數對HBase讀性能的影響的測試結果見表10。
合適的批量數能夠有效提升讀寫性能,并能達到一個最優效率。然后隨著批量數的增大,性能逐步下降。
分布式列式數據庫功能方面主要需測試分布式列式數據庫的負載均衡、數據壓縮功能。
3.7 負載均衡
下面以測試HBase在負載均衡方面的功能作為用例來說明。為保障測試結果的準確性,測試節點在1個分布式集群下,集群上已有一定數量的表(region數超過節點數),測試過程中新添加節點。在統一的測試環境下,實施測試操作:搭建一個2個工作節點的分布式文件系統集群,并觀察region的數量及分布情況;集群新添加1個工作節點,等待5 min(balancer默認定期檢查時間)查看region分布情況,同2個工作節點的情況比較,測試結果如下所示。

表9 不同批量操作數對HBase寫性能的影響的測試結果

表10 不同批量操作數對HBase讀性能的影響的測試結果
HBase負載均衡測試結果如圖8所示。

圖8 HBase負載均衡測試結果
HBase定期檢查,并平衡各工作節點的region數量。
3.8 數據壓縮
下面以測試HBase數據壓縮的功能作為用例來說明。為保障測試結果的準確性,測試節點均在分布式集群下,兩次寫入數據的數據量大小一樣。在統一的測試環境下,實施測試操作:搭建一個只有1個工作節點分布式文件系統集群;未開啟數據壓縮,新建HBase數據表,寫入一定量的數據,查看集群的磁盤利用率;配置LZO數據壓縮,將相應JAR文件放到HBase的lib文件夾下,新建HBase數據表并設置LZO數據壓縮,清空集群數據,寫入相同的數據,查看磁盤的利用率,測試結果如下所示。
數據壓縮的測試結果見表11。
數據壓縮功能能夠有效地壓縮數據大小,減少磁盤的空間使用。
3.9 節點動態擴展
下面以測試分布式文件系統的擴展性作為用例來說明。為保障測試結果的準確性,測試節點均在分布式集群下,兩次寫入數據的數據量大小一樣。在統一的測試環境下,實施測試操作:搭建一個只有1個工作節點的HBase集群,觀察HBase的region的數量及分布情況;集群新添加1個工作節點,等待5 min(balancer默認定期檢查時間)查看region分布情況,同只有1個工作節點的情況比較;查看集群的可用空間,測試結果如下所示。
HBase動態擴展測試結果如圖9所示。
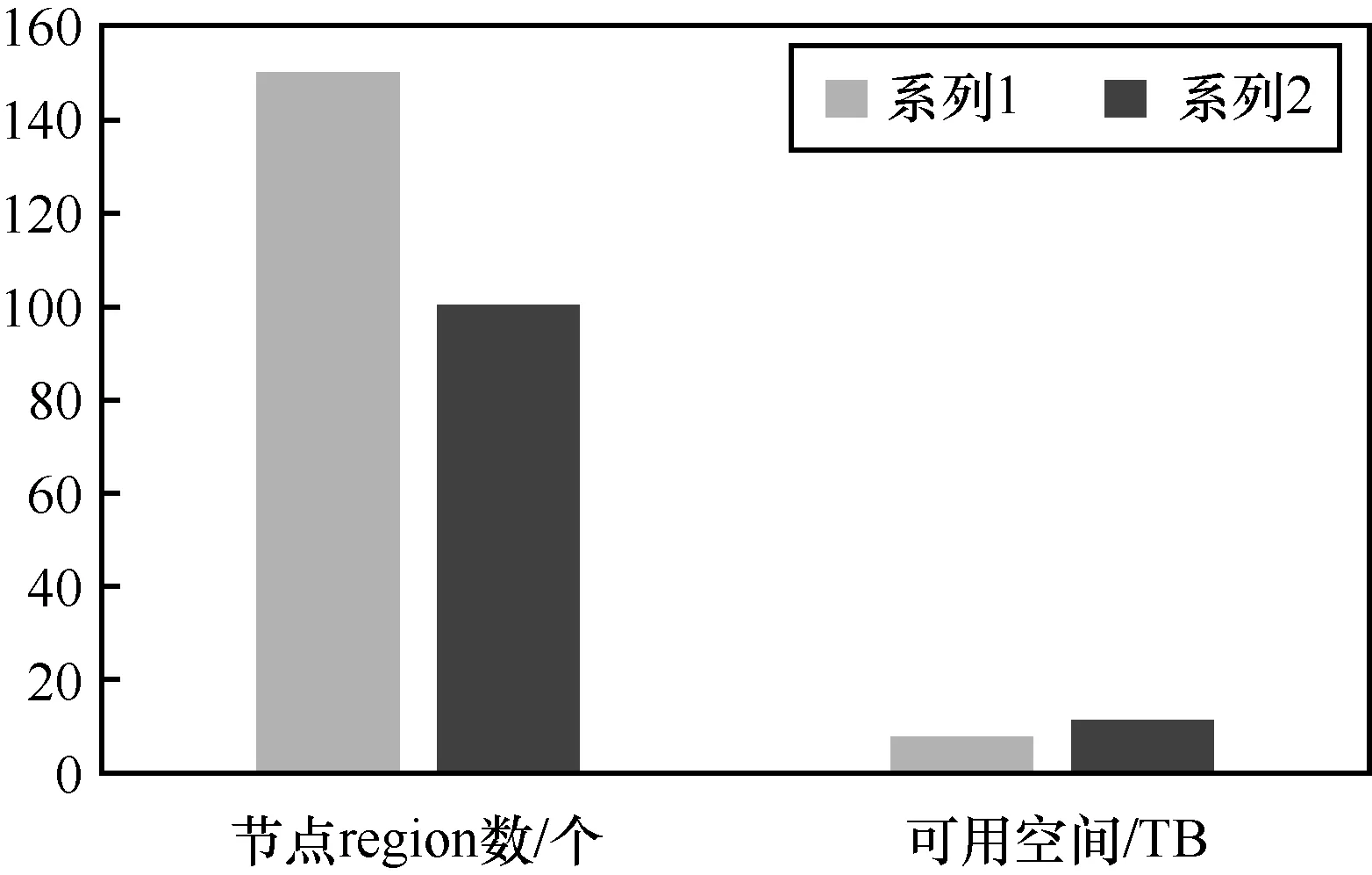
圖9 HBase動態擴展測試結果
HBase具備良好的擴展性,能夠動態增加節點,并能保持region分布均衡和存儲空間的擴容。

表11 數據壓縮的測試結果
4 結束語
HBase具備良好的擴展性,能夠動態增加節點,并能保持region分布均衡和存儲空間的擴容。集群的規模增大,在DataNode上讀取數據的性能優勢將越來越小,因為數據塊分布越來越稀疏,在一個數據節點上能夠取得的數據塊越來越少,需要通過網絡進行傳輸的數據越來越多。另外,隨著集群規模的增大,客戶端讀寫的速率有遞減的趨勢。
參考文獻:
[1]GEORGE L.HBase權威指南[M].代志遠, 劉佳, 蔣杰, 譯.北京: 人民郵電出版社, 2013.GEORGE L.HBase: the definitive guide[M].Translated by DAI Z Y, LIU J, JIANG J.Beijing: Posts & Telecom Press, 2013.
[2]蔡斌, 陳湘萍.Hadoop技術內幕: 深入解析Hadoop Common和 HDFS架構設計與實現原理[M].北京: 機械工業出版社,2013.CAI B, CHEN X P.Hadoop internals: in-depths study of common and HDFS[M].Beijing: China Machine Press, 2013.
[3]孟鑫, 馬延輝, 李立松.HBase企業應用開發實戰[M].北京:機械工業出版社, 2014.MENG X, MA Y H, LI L S.Enterprise application development with HBase[M].Beijing: China Machine Press, 2014.
[4]皮雄軍.NoSQL數據庫技術實戰[M].北京: 清華大學出版社, 2015.PI X J.NoSQL database technology combat[M].Beijing:Tsinghua University Press, 2015.
[5]DIMIDUK N, KHURANA A.HBase實戰[M].謝磊, 譯.北京: 人民郵電出版社, 2013.DIMIDUK N, KHURANA A.HBase in action[M].Translated by XIE L.Beijing: Posts & Telecom Press, 2013.
[6]蔣燚峰.HBase管理指南[M].北京: 人民郵電出版社, 2013.JIANG Y F.HBase administration cookbook[M].Beijing: Posts& Telecom Press, 2013.
[7]SHRIPARV S.Learning HBase[M].周彥偉, 婁帥, 蒲聰, 譯.北京: 電子工業出版社, 2015.SHRIPARV S.Learning HBase[M].Translated by ZHOU Y W,LOU S, PU C.Beijing: Publishing House of Electronics Industry, 2015.
[8]董西成.Hadoop技術內幕: 深入解析MapReduce架構設計與實現原理[M].北京: 機械工業出版社, 2013.DONG X C.Hadoop internals: in-depths study of MapReduce[M].Beijing: China Machine Press, 2013.
[9]GROVER M, MALASKA T, SEIDMAN J.Hadoop應用架構[M].郭文超, 譯.北京: 人民郵電出版社, 2017.GROVER M, MALASKA T, SEIDMAN J.Hadoop application architecture[M].Translated by GUO W C.Beijing: Posts &Telecom Press, 2017.
[10]王雪迎.Hadoop構建數據倉庫實踐[M].北京: 清華大學出版社, 2017.WANG X Y.Practice of Hadoop data warehouse[M].Beijing:Tsinghua University Press, 2017.
[11]WHITE T.Hadoop權威指南: 大數據的存儲與分析(第4版)[M].王海, 華東, 劉喻, 等譯.北京: 清華大學出版社, 2017.WHITE T.Hadoop: the definitive guide[M].Translated by WANG H, HUA D, LIU Y, et al.Beijing: Tsinghua University Press, 2017.
