基于深度學習的多維特征微博情感分析
2018-05-30 06:19:49金志剛胡博宏張瑞
中南大學學報(自然科學版) 2018年5期
金志剛,胡博宏, 2,張瑞
?
基于深度學習的多維特征微博情感分析
金志剛1,胡博宏1, 2,張瑞1
(1. 天津大學 電氣自動化與信息工程學院,天津,300072;2. 天津大學 國際工程師學院,天津,300072)
提出1種基于卷積神經網絡的多維特征微博情感分析新機制;利用詞向量計算文本的語義特征,結合基于表情字符的情感特征,利用卷積神經網絡挖掘特征集合與情感標簽間的深層次關聯,訓練情感分類器;結合微博文本的語義和情感特征,同時利用卷積神經網絡的抽象特征提取能力,進而改善情感分析性能。研究結果表明:引入表情字符的情感特征模型可使情感分析準確率提高2.62%;相比基于詞典的機器學習模型,新機制將情感分析準確率與度量分別提升21.29%和19.20%。
情感分析;卷積神經網絡;微博短文本;表情字符
隨著互聯網的飛速發展,越來越多的用戶樂于在網絡上發布自己的觀點、分享個人的生活狀態,同時獲取實時新聞、資訊,社交平臺也因此發展迅猛。新浪微博作為一個基于用戶關系信息分享、傳播以及獲取的平臺,改變了傳統社交網絡交流方式,給用戶提供更為便捷獲取豐富信息的方式,迅速成為了極具人氣的社交網絡平臺與新媒體平臺。由于微博平臺的開放性,多數突發事件都是第一時間由身處現場的目擊者發布到微博平臺,并因此引發網友的高度關注,例如“巴黎恐怖襲擊事件”、“上海浦東機場疑似爆炸事件”、“英國退歐”等。互聯網用戶通過微博第一時間了解熱點事件,關注事態發展;相關部門通過微博通報事件最新進展,澄清事實,安撫民眾情緒。因此對微博平臺內容進行準確分析具有重要意義。Twitter作為國外著名的社交平臺,已成為學術界的熱門研究對象。用于Twitter情感分析的傳統方法是基于詞典的情感分析,使用包含情感極性、否定以及程度副詞的詞典計算句子的情感傾向[1?2]。PANG等[3]基于學習的情感分析方法,將文本情感分析看作文本分類問題,利用從情感詞選取的大量嘈雜的標簽文本作為訓練集直接構建分類器。大量基于學習的情感分析方法過于依賴特征工程,例如MOHAMMAD等[4]利用大量手工挑選的特征取得了當時的最佳分類性能,但手工特征需要大量的語法構詞等專業知識,同時成本極高。因此,國內外研究者開始將深度學習模型應用于Twitter情感分析問題。SEVERYN等[5]使用詞向量表示文本的語義特征,并使用卷積神經網絡提取深層次特征訓練分類器;TANG等[6]構建神經網絡模型學習包含情感特征與語義特征的詞向量表示,并與手工特征結合作為復合特征,訓練分類器。此外,國內外研究者也將深度學習模型應用于英語短文本處理。KIM等[7]使用卷積神經網絡對短文本進行建模,并在多個數據集上進行了多組實驗,完成了句子級別的文本分類任務。ZHANG等[8]提出了字符級別的卷積神經網絡模型并用于文本分類,該模型適用于多種語言,且其性能不亞于詞袋模型、N-grams、TFIDF等傳統模型,以及基于詞組的卷積神經網絡模型和循環網絡模型。WANG等[9]提出將卷積神經網絡與-means算法融合的半監督學習模型,使用少量帶標簽數據對短文本進行聚類。XU等[10]提出了利用卷積神經網絡與-means聚類算法結合的短文本聚類模型,該模型是自學習框架,無需任何標簽數據。英語語料相比中文語料具有已分詞的天然優勢,此外,中英文在文化以及使用習慣上也具有很大差別。針對中文短文本的情感分析并不多,大部分通過提取文本的情感和統計等特征,進而使用機器學習中的分類算法完成情感分析任務。黃發良等[11]提出基于隱含狄利克雷分布(LDA)主題模型的結合表情符號與用戶性格特征的多特征融合模型,實現了微博文本的主題與情感傾向的同步檢測。張冬雯等[12]通過word2vec工具擴充情感詞典,根據情感詞特征與詞性特征,使用支持向量機訓練文本情感分類模型。黃仁等[13]也通過word2vec工具擴展情感詞典,使用基于情感特征詞的統計模型對文本進行情感評分。通過情感詞典提取情感特征對情感詞典要求嚴格。一方面,模型往往需要多種詞典,如情感詞詞典、程度副詞詞典和否定詞詞典等;另一方面,互聯網新詞、網絡用語日新月異,更新和維護詞典也是一個難題。而統計特征的提取依賴自然語言的研究分析,需要語法構詞等專業知識。當前,將深度學習模型應用于中文微博情感分析的研究不多。本文作者一方面使用word2vec工具計算詞向量,提取短文本的語義特征,另一方面保留微博文本中的表情字符,作為情感特征,共同構成特征集合;再通過卷積神經網絡模型提取深度抽象特征,訓練分類器完成情感分類任務。
1 基于卷積神經網絡的多維特征微博情感分析新機制
本文作者提出1種多維特征微博情感分析新機制。圖1所示為多維特征微博情感分析新機制流程圖。
微博文本的多維度特征包括語義特征與情感特征。語義特征通過對大規模語料進行無監督學習訓練,計算詞組的詞向量表示。詞向量不僅將詞組映射至高維空間中實現向量化表示,同時詞向量在高維空間中的余弦距離也表示詞組間的相似度,蘊含了詞組間的深層語義聯系。情感特征由微博文本中的表情字符表示。對微博文本中的表情字符提取與轉換,并進行隨機向量化以匹配語義特征的詞向量表示,共同構成微博文本特征集合。
將特征集合作為卷積神經網絡的輸入,通過卷積與池化運算,捕獲局部特征并對局部特征進行篩選,所得特征作為情感分類器的輸入,訓練微博文本情感分類器。

圖1 多維特征微博情感分析新機制流程圖
2 卷積神經網絡模型
卷積神經網絡是深度學習中的常用模型之一,已經在圖像和語音分析領域取得了可觀的效果。該模型受生物視覺系統啟發,通過池化和權值共享減少了網絡中權值的數量,降低了網絡模型的復雜度。池化操作利用了自然文本的統計特性即局部的統計特性同樣適用于其他部分的原理。同時,卷積神經網絡對平移、比例縮放、傾斜或者共他形式的變形具有高度不變性。
2.1 模型概況
本文作者借鑒文獻[7]中使用的卷積神經網絡模型,所用的模型可分為3個部分,如圖2所示。
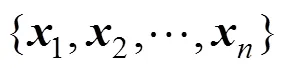
第2部分為卷積層,主要由卷積和池化運算構成。使用卷積層是為了提取微博文本的深層次情感模式特征,同時配合池化運算減少計算量,歸一化特征長度。模型使用不同長度的卷積核提取不同的特征,每個卷積核是一個×的矩陣,其中是卷積核的長度。使用卷積核對微博文本進行卷積,該過程可表示為

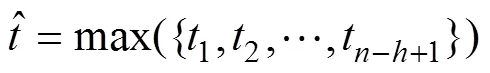
經過池化操作,即可保證使用多個不同長度卷積核對微博文本卷積生成長度統一的特征向量。
第3部分是分類層。將上一層生成的特征向量輸入至全連接的softmax層,計算屬于各類別的概率分布:

2.2 正則化
模型使用反向傳播算法進行訓練,采用隨機梯度下降算法(SGD)計算梯度,使用Adadelta算法[14]自動更新學習率。此外,模型引入Batch Normalization算法對各層神經網絡的輸入進行正則化處理。通過在各層計算激活值前加入一個Batch Normalization歸一化網絡層,能夠減少內部協變量偏移的影響,進而加速參數更新的收斂與網絡的訓練[15]。

(a) 輸入層;(b) 卷積層;(c) 分類層
本模型中加入了2處Batch Normalization歸一化網絡層。一是在卷積運算后,對單個卷積核對應的卷積特征進行歸一化,再進行池化運算;二是在全連接分類層中計算激活值之前加入歸一化層,激活值計算公式為
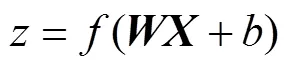
引入歸一化層后,激活值計算公式為

其中:為歸一化函數。由于歸一化運算對于偏置無效,因此省略偏置項。
3 微博文本多維度特征提取
3.1 基于詞向量的語義特征
已有的研究表明,在無法對大規模帶標簽數據進行監督學習的情況下,使用無監督學習的方式初始化神經網絡的輸入值,是一個有效改善訓練效果、加速訓練收斂的方法[16?17]。因此,本文作者使用word2vec工具計算微博文本的詞向量,作為卷積神經網絡輸入的初始化值。
word2vec工具[18]是Google上一款開源的高效計算分布式詞向量的工具。此工具以語料庫為輸入,計算出詞向量表示。它以由文本數據構建的詞匯表為訓練數據,然后學習詞組的高維向量表示,即將詞組映射至有限維的高維空間中。與傳統的One-hot表示模型相比,詞向量是稠密的向量表示,并且更易計算向量間的距離度量,因此更適用于自然語言處理和機器學習,同時對微博文本的簡短性和隨意性具有更好的魯棒性。
word2vec工具包含2個計算詞向量的模型即連續詞袋模型(CBOW)和Skip-Gram模型。該工具基于神經網絡語言模型,通過刪除隱層以及利用分層softmax和負采樣等技巧減少計算復雜度,同時優化訓練結 果[19?20]。通過word2vec工具對分詞后的中文語料進行訓練,可計算每個詞組的指定維度的向量表示。利用詞組的詞向量可以方便地計算詞向量的余弦距離作為詞組間的相似度度量,因此詞向量表示了語料中詞組間的深層語義聯系。
3.2 基于微博表情字符的情感特征
微博平臺為用戶提供了大量的默認表情字符,幫助用戶更生動地表達當下的感受和體會。圖3所示為微博默認表情。直觀上,這些表情字符也是微博文本情感傾向的重要組成部分。由于傳統的自然語言處理大多針對新聞、博客等正式語料,因此只關注對于文本的研究與處理,在文本預處理階段只過濾出文本信息,而刪除網頁鏈接、特殊字符等數據,導致微博文本情感特征的缺失。

圖3 微博默認表情
通過研究發現,微博平臺的默認表情字符是由HTML圖像標簽構成。因此,在數據預處理階段,對圖像標簽進行提取與轉換,并將轉換后的表情字符插入所屬微博文本的原位置,然后用方括號對表情字符進行標注,以區分微博中的文本與表情,例如“[哈哈]”。將處理后的表情字符采用隨機初始化的方式轉換成詞向量,與語義特征保持一致,進而實現語義特征與情感特征的結合。
4 實驗與分析
4.1 數據集
實驗所用數據集包含word2vec訓練語料與微博數據集。
word2vec訓練語料使用搜狗實驗室整理提供的新聞數據[21],包含全網新聞數據與搜狐新聞數據共 2 706 229條新聞語料。選取新聞預料中新聞正文進行分詞處理,作為word2vec工具的訓練數據,并設置詞向量長度=300。訓練完成后,共包含565 345個詞組。對于未出現在詞向量集合中的詞組,將對其進行隨機初始化。
對于微博數據集,由于模型需要考慮微博中的表情字符,并未發現合適的公開數據集,因此通過自行采集的方式獲取了約10 000條微博文本,通過人工標注的方式將其分為積極和消極2類,其中積極類微博3 100條,消極類微博3 800條。最終,隨機選擇3 000條積極類和3 000條消極類微博作為數據集。表1所示為實驗所用微博樣本示例。

表1 微博文本示例
4.2 對比實驗
對比實驗包含2個部分:第1部分是與傳統基于詞典的機器學習模型的對比;第2部分是與無表情字符的卷積神經網絡模型對比。
第1部分的對比實驗采用基于情感詞典與詞性特征的機器學習情感分類算法。參考文獻[12],使用word2vec工具計算詞組相似度,進而對由HowNet詞典和IAR詞典組合構成的情感詞典進行擴充,同時使用{形容詞,副詞,動詞}的詞性組合作為文本的詞性特征,將提取的情感特征與詞性特征進行主成分分析(PCA)降維處理,最終通過支持向量機對特征進行訓練,完成中文情感分類任務。
為了驗證微博文本中表情字符對情感分析的促進效果,設計關于表情字符的對比實驗,即在文本預處理階段將表情字符去除作為對比實驗,其余設置與主模型相同。
4.3 結果與討論
實施3組情感分析實驗。第1組為本文提出的微博情感分析新機制,記為有情感特征的深度學習模型其參數通過在小批量數據集上進行交叉驗證后確定,如表2所示。第2組為無感情特征的基于卷積神經網絡的模型,即在本文作者提出模型的基礎上,去除表情字符,記為無情感特征的深度學習模型。第3組為基于情感詞典的機器學習模型,記為機器學習模型。
采用準確率與值作為分類效果的度量。對于本文所屬的二分類問題,設類別分別為積極和消極,令P為原本屬于積極且分類正確的數量,P為原本屬于積極但分類錯誤的數量,N為原本屬于消極但分類錯誤的數量,N為原本屬于消極且分類正確的數量。則準確率acc、精確率prec、召回率recall和值的計算如下:

表2 實驗參數

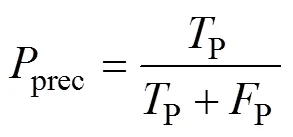
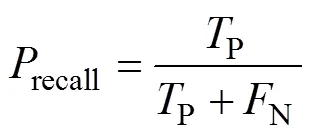

每組實驗均采用10折交叉驗證的方式進行。表3所示為各組實驗的實驗結果。

表3 對比實驗結果
由表3可知:與機器學習模型相比,本文作者提出的微博情感分析新機制情感分析準確率與值分別提升0.149 0和0.136 6,相對提升21.29%和19.20%。可以得出結論,卷積神經網絡與多維度文本特征的引入對微博情感分析的改善效果顯著。與無情感特征的深度學習模型相比,發現準確率與值分別提升0.021 7與0.014 8,相對提升2.62%與1.78%,考慮到并非所有微博文本都包含表情字符,該改善效果比較可觀,可見,引入微博表情字符有助于促進情感分析。
5 結論
1) 提出應用深度學習提取微博文本情感模式,且包含微博表情字符特征的情感分析新機制。通過詞向量提取文本的語義特征,對微博表情字符進行提取并作為微博文本的情感特征。
2) 與無情感特征的模型相比,基于表情字符的情感特征模型對情感分析的準確率提高2.62%。
3) 通過引入情感特征,利用卷積神經網絡的抽象特征挖掘能力,訓練情感分類器,使得本文提出模型的準確率與度量相對于傳統基于詞典的機器學習模型分別提升21.29%和19.20%。
[1] TABOADA M, BROOKE J, TOFILOSKI M, et al. Lexicon- based methods for sentiment analysis[J]. Computational Linguistics, 2011, 37(2): 267?307.
[2] THELWALL M, BUCKLEY K, PALTOGLOU G. Sentiment strength detection for the social web[J]. Journal of the American Society for Information Science & Technology, 2012, 63(1): 163?173.
[3] PANG Bo, LEE L, VAITHYANATHAN S. Thumbs up?: sentiment classification using machine learning techniques[C]// Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing. PA, USA: ACL, 2002: 79?86.
[4] MOHAMMAD S M, KIRITCHENKO S, ZHU Xiaodan. NRC-Canada: building the state-of-the-art in sentiment analysis of tweets[EB/OL]. 2013?08?28. https://arxiv.org/abs/1308.6242.
[5] SEVERYN A, MOSCHITTI A. Twitter sentiment analysis with deep convolutional neural networks[C]// The International ACM SIGIR Conference. Santiago, Chile: ACM, 2015: 959?962.
[6] TANG Duyu, WEI Furu, QIN Bing, et al. Coooolll: A deep learning system for twitter sentiment classification[C]//Proceedings of the 8th International Workshop on Semantic Evaluation. Dublin, Ireland: ACL, 2014: 208?212.
[7] KIM Y. Convolutional neural networks for sentence classification[EB/OL]. 2014?08?25. https://arxiv.org/abs/1408. 5882.
[8] ZHANG Xiang, ZHAO Junbo, LECUN Y. Character-level convolutional networks for text classification[C]// Advances in Neural Information Processing Systems. New York, USA: Curran Associates, Inc., 2015: 649?657.
[9] WANG Zhiguo, MI Haitao, ITTYCHERIAH A. Semi- supervised clustering for short text via deep representation learning[EB/OL]. 2016?02?22. http://arxiv.org/abs/1602.06797.
[10] XU Jiaming, WANG Peng, TIAN Guanhua, et al. Short text clustering via convolutional neural networks[C]// Proceedings of NAACL-HLT.Denver, Colorado, USA: ACL Anthology, 2015: 62?69.
[11] 黃發良, 馮時, 王大玲, 等. 基于多特征融合的微博主題情感挖掘[J]. 計算機學報, 2017, 40(4): 872?888. HUANG Faliang, FENG Shi, WANG Daling, et al. Mining topic sentiment in microblogging based on multi-feature fusion[J].Chinese Journal of Computers, 2017, 40(4): 872?888.
[12] 張冬雯, 楊鵬飛, 許云峰. 基于word2vec和SVMperf的中文評論情感分類研究[J]. 計算機科學, 2016, 43(S1): 418?421, 447. ZHANG Dongwen, YANG Pengfei, XU Yunfeng. Research of Chinese comments sentiment classification based on Word2vec and SVMperf[J]. Computer Science, 2016, 43(S1): 418?421, 447.
[13] 黃仁, 張衛. 基于word2vec的互聯網商品評論情感傾向研究[J]. 計算機科學, 2016, 43(S1): 387?389. HUANG Ren, ZHANG Wei. Study on sentiment analysis of internet commodities review based on word2vec[J]. Computer Science, 2016, 43(S1): 387?389.
[14] ZEILER M D. ADADELTA: an adaptive learning rate method[EB/OL]. 2012?12?22. https://arxiv.org/abs/1212.5701.
[15] IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift[EB/OL]. 2015?02?11. https://arxiv.org/abs/1502.03167.
[16] COLLOBERT R, WESTON J, BOTTOU L, et al. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research, 2011, 12(1): 2493?2537.
[17] SOCHER R, PENNINGTON J, HUANG E H, et al. Semi- supervised recursive autoencoders for predicting sentiment distributions[C]// Proceedings of the Conference on Empirical Methods in Natural Language Processing. Edinburgh, UK: ACL, 2011: 151?161.
[18] Google. Word2vec[EB/OL]. 2013?07?30. https://code.google. com/p/ word2vec/.
[19] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]// Advances in Neural Information Processing Systems. Lake Tahoe, USA: Curran Associates, Inc, 2013: 3111?3119.
[20] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. 2013?01?16. https://arxiv.org/abs/1301.3781.
[21] 搜狗實驗室. 新聞數據[EB/OL]. 2012?08?16. http://www. sogou.com/labs/resource/list_news.php.
(編輯 伍錦花)
Analysis of Weibo sentiment with multi-dimensional features based on deep learning
JIN Zhigang1, HU Bohong1, 2, ZHANG Rui1
(1. School of Electrical and Information Engineering, Tianjin University, Tianjin 300072, China; 2. Tianjin International Engineering Institute, Tianjin University, Tianjin 300072, China)
A new mechanism of Weibo sentiment analysis based on convolutional neural networks with multi- dimensional features was proposed. The proposed mechanism combines semantic features from word vectors with sentiment features from emoticons, in which convolutional neural networks was used to mine deep correlation between features and labels. The performance of Weibo sentiment analysis was improved through mining multi-dimensional features and utilizing abstract features extraction ability of convolutional neural networks. The results show that the accuracy of sentiment analysis model based on emoticons increases by 2.62%. The accuracy andmeasure increase by 21.29% and 19.20% respectively compared with that of machine learning model based on lexicon.
sentiment analysis; convolutional neural networks; Weibo short text; emoticons
10.11817/j.issn.1672-7207.2018.05.015
TP391
A
1672?7207(2018)05?1135?06
2017?05?21;
2017?06?30
國家自然科學基金資助項目(61571318);青海省科技項目(2015-ZJ-904);海南省科技項目(ZDYF2016153) (Project(61571318) supported by the National Natural Science Foundation of China; Project(2015-ZJ-904) supported by the Science Foundation of Qinghai Province; Project(ZDYF2016153) supported by the Science Foundation of Hainan Province)
張瑞,博士,講師,從事社交網絡數據挖掘研究;E-mail: hitchcockzhr@163.com
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
