Redis集群可靠性的研究與優化
2018-05-30 01:26:11顧乃杰黃增士任開新
計算機工程 2018年5期
李 燚,顧乃杰,黃增士,任開新
(1.中國科學技術大學 a.計算機科學與技術學院; b.先進技術研究院,合肥 230027; 2.安徽省計算與通信軟件重點實驗室,合肥 230027)
0 概述
Redis[1]是一種基于鍵值對存儲的內存數據庫,能夠提供高速的數據庫訪問,并實現了復制備份和數據持久化的功能。相比于其他內存數據庫,例如Memcached[2],Redis支持多種數據類型。由于具有高性能、多數據類型支持、數據安全性等優勢,Redis近年來發展迅速,并得到了廣泛應用。已經有很多互聯網企業使用Redis,例如新浪、GitHub、Pinterest[3]等。Redis應用領域也很廣泛,例如做動態緩存[4]、可視化數據庫[5]、云數據庫[6]等。
Redis集群能夠彌補單線程的Redis節點性能上的不足,還可以提供數據冗余、結構冗余的特性。在Redis集群中,數據分布存儲在各個節點,單點故障問題不可避免。發生故障后集群的容錯機制決定了集群恢復的效率,也就影響到集群對外服務的可靠性。Redis集群現有的容錯機制效率比較低,在實際使用過程中,當主要節點發生故障時,恢復過程緩慢,集群可靠性還有待提升。提升集群可靠性,一方面可以推動Redis的發展,另一方面可以降低集群故障給用戶帶來的損失。
影響集群可靠性的因素主要有集群架構、網絡通信質量、軟硬件可靠性、集群容錯機制、數據恢復機制等。目前對于分布式集群的架構和可靠性的研究非常多。文獻[7]提供一種在TCP連接層對集群可靠性進行優化的方法。通過使用冗余的TCP棧實現套接字遷移,來保證服務端節點的TCP連接的可靠性。這種方法只是在網絡連接層降低了發生單點故障的概率,如果是因為其他原因導致節點故障,仍然需要通過容錯機制進行集群恢復。文獻[8]研究了數據冗余和硬件冗余對集群可靠性的影響,并提出一種結合了節點互備份和冗余節點備份的恢復機制,其中冗余節點備份類似于Redis的主從模式。文獻[9]介紹一種新的復制備份方案NRDT,該方案通過在鄰接點間進行數據備份來提高集群可靠性,即一個節點的服務數據復制備份到鄰居節點上。但是發生多節點故障時,這種冗余方法容易導致個別節點的負載較重,影響集群的性能。文獻[10]實現了針對UCWW系統的Redis集群架構。該架構使用ZooKeeper對Redis節點進行管理,需要的ZooKeeper節點個數與Redis節點個數相關。該集群方案需要額外的監測節點,而且架構的設計針對于UCWW系統,不具有通用性。
相比于現有的研究方案,本文對Redis集群可靠性的研究和優化集中在通信層。通過對Redis集群的容錯機制進行階段劃分,針對各個階段進行分析。基于對各階段通信過程的研究,提出一種集群節點間的通信模型,并在此模型基礎上,實現一種通信負載均衡的優化方法。
1 Redis研究背景
1.1 Redis集群結構
Redis節點可以主從方式構成集群,從節點對主節點進行復制備份,相當于一種冗余結構[11]。集群節點兩兩之間建立了P2P的TCP連接,以發送和接收消息的方式進行通信,構成全網狀的網絡拓撲結構[1]。圖1是6個節點組成的Redis集群,最小的Redis集群只有3個主節點。作為一種分布式的結
構,Redis集群中實現了一種基于Gossip協議的一致性通信算法,來完成消息的消息傳播、數據交換和狀態同步[12]。使用Gossip協議既能有效保證集群的一致性,又避免了通信負載指數級的增長。

圖1 6個節點組成的一主一從Redis集群
Gossip協議是在大規模并行環境內部建立穩定、可靠的通信機制的一種有效方案,廣泛地應用到P2P網絡中。在Gossip協議中,節點以一種類似疫情傳播的方式進行數據交換、消息通信[13]。Gossip協議是一種最終一致性算法,即弱一致性算法,不能保證在某個時間點整個集群的所有節點達到一致的狀態,但可以保證隨著時間的推移,集群最終會達到一致性的狀態。
1.2 容錯機制
在集群運行過程中,如果存在主節點因為軟硬件原因離線,需要通過容錯機制來確定離線的主節點,并進入故障轉移過程來指派新的主節點。如圖2所示,下線檢測和故障轉移是集群容錯機制的2個主要階段。如果按照節點狀態和集群狀態進行劃分,又可分為PFAIL階段、FAIL階段和RECOVER階段。PFAIL和FAIL來源于節點的狀態,分別對應疑似下線和下線。
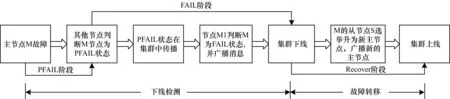
圖2 容錯機制下的宕機恢復過程
1.2.1 下線檢測
集群中的每個節點和其他節點進行周期性的間隔通信。這種周期性通信消息,即心跳消息在集群間傳遞節點狀態以及可用性的信息[14]。周期性通信的方法記為F,執行周期記為HZ。Redis集群中心跳消息主要包括PING、PONG,一次PING、PONG通信簡化過程的等待超時時間記為T。
發送方節點通過以下2種方式選取需要發送PING消息的節點:
1)每隔1 s隨機性地選取一個節點,向其發送心跳消息。
2)每次執行F,一次性選出上次通信距現在超過T/2的節點,向這些節點發送心跳消息,從而保證每隔T/2的時間都和其他節點通信一次。
每條心跳消息(PING、PONG)包含發送方節點的狀態信息和GossipSection。GossipSection包含若干條Gossip數據,每條Gossip數據對應一個Redis節點,包含該節點的狀態信息,即發送方節點將集群中若干節點的信息隨心跳消息發送給接收方。GossipSection中節點的選取具有隨機性。如圖3所示,接收方收到PING、PONG消息后,首先解析消息提取發送方的信息進行更新,然后解析GossipSection中的每條數據,更新到本地。
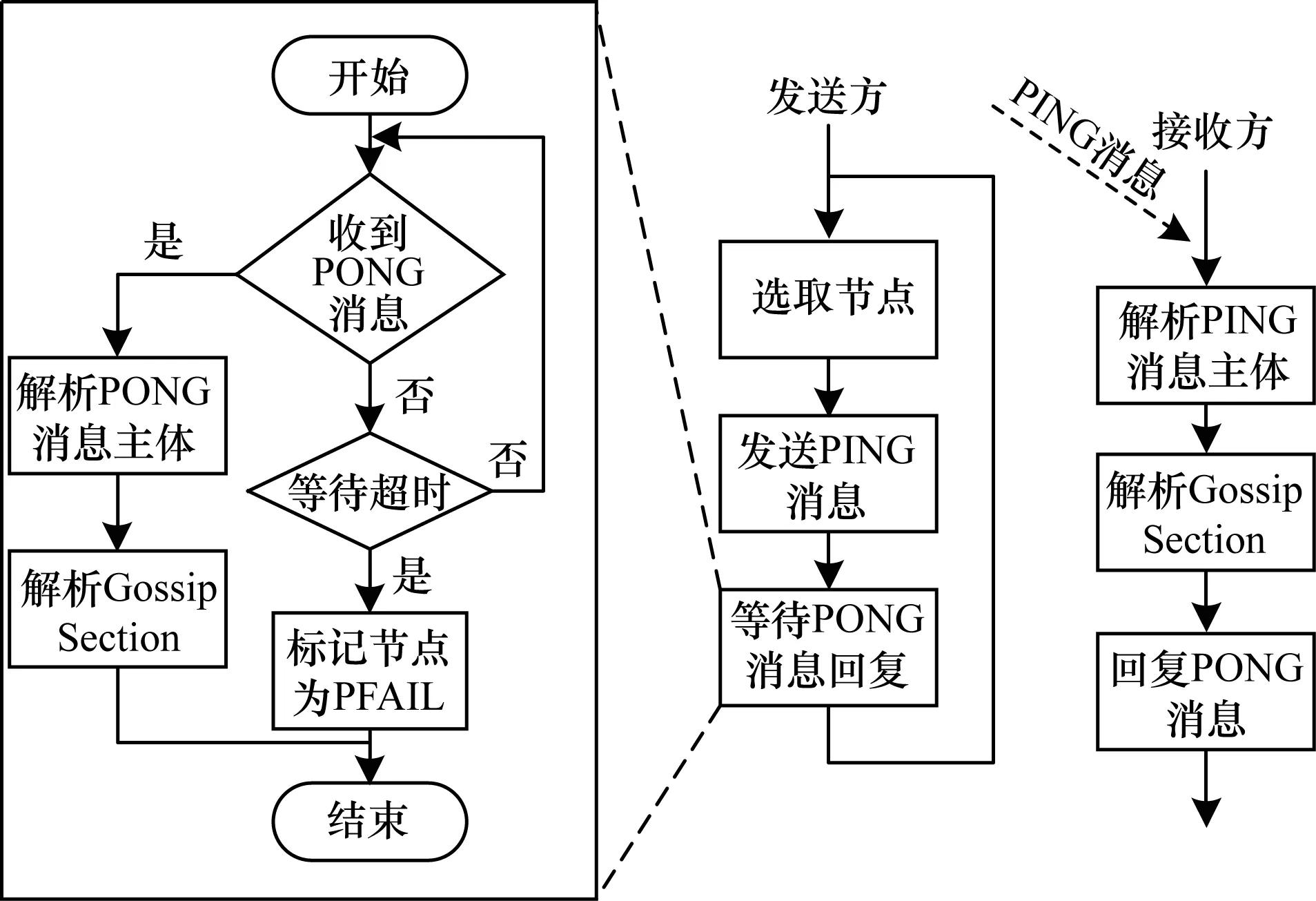
圖3 節點間PING、PONG通信過程
如圖3發送PING消息后,在超時時間T內未收到PONG回復,就將對應節點標記為PFAIL狀態,對應圖2的PFAIL階段。節點間不斷進行心跳消息的通信,隨著時間的推移,在節點間對于PFAIL狀態節點的判斷逐漸形成一致性的認識,在此過程中如果超過半數主節點都標記某個節點為PFAIL,就確定該節點下線,對應圖2的FAIL階段(GossipSection中解析的PFAIL標記有2T的有效時間,超時后不能用來判斷FAIL狀態)。所以FAIL狀態是集群中多數節點協同得到的一致性結果。通過PFAIL階段和FAIL階段就完成了下線檢測的過程。
1.2.2 故障轉移過程
故障轉移是在主節點故障后進行主從切換的過程[15]。在通過下線檢測過程確認主節點宕機后,其從節點就會通過Raft選舉算法獲得多數主節點的認可,當選為新的主節點。首先從節點在集群中發起選舉進入故障轉移的過程。選舉信息在集群中廣播,收到選舉信息的主節點給該從節點投票,當從節點得到的票數超過主節點總數一半時,可當選為新的主節點并廣播當選信息,集群恢復上線。
1.3 技術優勢
根據對集群結構和集群容錯機制的分析,Redis集群有以下3點優勢:
1)多冗余功能:Redis的主從集群結構,給自身提供了硬件和結構冗余的功能,從節點對主節點的復制備份的功能提供了數據冗余的功能。
2)自動容災:集群發生故障時,在集群內部能夠自動完成下線檢測、故障轉移的過程,不需要額外的監控節點協助完成。
3)一致性保證:在容錯機制中使用Gossip通信協議維持集群狀態的一致性,保證下線檢測的準確性。在故障轉移過程中,使用Raft一致性算法,保證主從切換的唯一。
2 優化方案分析與設計
2.1 優化方案分析
通過對Redis集群容錯機制中節點通信過程的分析,考慮在集群中對于PFail狀態進行疫情傳播的通信模型,可結合疫情傳播的易受感染(Susceptible Infective,SI)模式進行分析。假設集群的主節點個數為N,將集群中的節點分為2種:1)感知態,感知態節點已經知道PFail狀態節點,下一步需要進行傳播;2)未知態,未知態節點沒有感知PFail狀態節點。
初始時只有一個感知態節點,每次隨機選取一個節點進行狀態傳播,記為一輪。則在一輪過后,增加一個感知態節點的概率為1-1/N。在下一輪,所有感知節點都分別再進行一輪狀態傳播。傳播過程記為{I(k),k≥0},I(k)表示k輪傳播后感知態節點的個數,其中I(0)=1。
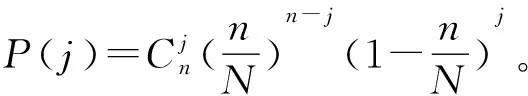
(1)
使用二項式定理和組合數公式簡化后得到下式:
(2)
解二次遞推公式得到下式:
(3)
式(3)給出了在k輪消息傳播后感知態節點的個數。當感知態個數達到N時,集群達到一致狀態;當感知態個數達到N/2+1時,能夠完成下線檢測。對于后者,根據式(3)得到PFail狀態傳播輪數k:
(4)
在上述通信模型中,k是狀態傳播經過的輪數,每次傳播一個節點。對于每次狀態傳播發送多條消息的情況,按照上述過程難以得到簡化結果。可以簡化考慮:將發送的每條消息看作狀態傳播的一輪。對Redis集群,假設消息發送頻率為k′,則感知態個數達到N/2+1的耗時為t=k/k′。
根據第1節對集群通信過程的介紹,假設集群通信消息發送頻率為m,由于心跳消息的GossipSection包含PFail狀態有一定隨機性,假設包含PFail狀態的概率為p(0 (5) 所以按照一條心跳消息作為一輪狀態傳播的過程考慮,PFail狀態傳播N/2+1個節點時,集群能夠完成下線檢測,耗時t和mp成反比關系。而結合第1節對通信過程的分析,存在以下問題: 1)節點發送心跳消息的頻率m較低。由目標節點的選取和發送消息的時機分析,理論上每隔T/2的時間,會有一次心跳消息集中發送的現象發生,產生消息發送的峰值點,非峰值點的消息發送頻率比峰值點要低很多,導致消息通信在時間上的負載不均衡。這種不均衡也通過測試結果得到了驗證。 2) GossipSection節點選取的隨機性導致p較小。在發送的心跳消息中,添加到GossipSection的節點的選取有隨機性,不能保證PFAIL狀態的節點添加到GossipSection,降低了有效PFail狀態的心跳消息的發送頻率。 所以根據以上分析,可以從兩方面對Redis集群容錯機制的FAIL階段進行優化:1)通信負載均衡,既不增加通信負荷,又能提高非峰值點的消息發送頻率m;2)GossipSection節點的選取,優先添加PFAIL狀態的節點,增加心跳消息中有效消息占的比例p。 根據第1節的介紹,原始的心跳消息發送過程可以分為2個部分:周期定量發送,T/2時刻批量補發送,導致心跳消息的發送在時間上分布不均。通過使用通信負載均衡的方法可以消除峰值,增加非峰值點的發送頻率。 簡化消息發送過程,實現負載均衡,要考慮以下3個問題: 1)節點心跳消息的通信量在時間上均勻分布,保證通信負載均衡; 2)既要保證集群節點之間的通信量:在T/2時間內單個節點和其他節點至少通信一次,又不能增加通信負載,對集群性能產生太大影響; 3)避免和某些節點產生較長的通信空白,所以需要按照一定的優先級調度通信節點。 假設在T/2時間內與其他所有節點通信次數為S,為了滿足負載均衡的目的,可以用減量均分的方法動態計算每次執行周期函數F時的消息發送量。設F周期為HZ,則T/2時間內執行次數為K;設第i次執行F發送消息量記為pi(p0=0),在T/2時間內,每次執行F,需要根據剩余消息量重新計算pi。 (6) (7) 為了避免同其他節點產生通信空白,使用優先級隊列保存所有節點,優先級設置為與該節點上次通信距離現在的時間,時間越長優先級越高,可以保證優先選取的目標節點是最久沒有通信過的。在集群建立時初始化2個優先級隊列Q1和Q2,Q1是待發送消息的目標節點,Q2是已發送消息的節點。每次從Q1隊列頭選取目標節點,發送消息后放入Q2隊列尾。每隔T/2,Q1和Q2完成一次交換。在集群規模發生變化時,也很容易通過更新Q1更新集群通信量。 負載均衡的消息發送過程如下所示: 1)集群建立時,初始化隊列Q1為空,Q2包含所有節點,初始化計數器i=1; 2)如果Q1為空且i=1,交換Q1和Q2; 3)結合式(6)計算消息發送量pi=Q1.length/(K-i+1); 4)從Q1中彈出pi個節點,發送心跳消息,并將節點壓入Q2,i=(i+1)%K; 5)周期函數下一輪從2)繼續執行。 通信過程具體實現如下: 1.//集群啟動時初始操作 2.i←0; 3.K←(T*HZ)/2 000; 4.InitPriorityQueue(Q1,null); 5.InitPriorityQueue(Q2,cluster_nodes); 6.… 7.//以下是循環過程 8.if Q1.empty() & i == 1 then 9. Swap(Q1,Q2); 10.end 11.size←Q1.length;//剩余節點數 12.pi←size/(K-i+1); 13.i←i % K+1; 14.for j=1 to pi do 15. node←Q1.pop(); 16. if node.ping_sent = =0 then 17. sendPingToNode(node); 18. end; 19. Q2.push(node); 20.end 第11行~第12行結合式(3)根據F執行次數和Q1的長度更新需要發送的消息個數pn,保證在T/2時間內和所有節點通信一次。第14行~第20行完成節點選取和發送消息的過程,第16行篩選掉已經發送的心跳消息,但沒有收到回復也沒有超時的節點,防止消息堆積。 原始的心跳消息GossipSection包含節點的選取具有隨機性。針對這個問題,改進Gossip單元選取過程,將處于PFAIL狀態的節點優先添加到Gossip單元中,根據式(2),此舉的目的是為了增加p的值。節點選取過程較簡單,主要需要考慮以下問題: 1)消除隨機性,絕對優先級選取PFail狀態的節點; 2)確定GossipSection的大小,使盡快完成節點狀態交換。 在集群中添加額外數據結構PFailNodes,使用自帶的字典結構實現,保存所有PFAIL狀態的節點。在更新節點狀態時,同步地更新PFailNodes。在添加PFail節點時,可以直接從PFailNodes中選取。 不考慮優先添加節點的情況,設添加到GossipSection的節點個數為n。對節點的PFAIL標記的有限期限為2T,在2T的時間內,能和單個節點完成4次PING/PONG通信,共8條消息。設集群大小為N,如果要在2T的有效時間內完成對所有節點的狀態信息交換,就需要在每條信息里添加N/8個節點的GossipSection數據,即n=N/8。 相對于消息通信量,GossipSection的增加對通信負載的影響小得多,所以在優先添加PFail節點的情況下,可以適量地放寬n的值。設GossipSection的大小為n+PFailNodes.size(),后者是PFail狀態節點的個數。每次構造心跳消息選取GossipSection節點的過程如下: 1)添加PfailNodes中所有節點到GossipSection;這樣能夠保證發送的每條心跳消息都包含PFail節點,即p=1,達到最大值; 2)在剩余節點中,隨機選取n=N/8和節點添加到GossipSection,并保證GossipSection節點互異。 具體實現為:n是添加到GossipSection的非PFAIL狀態的節點個數,gossipcount是已經添加的節點個數,msg是構造的消息。先遍歷PFailNode,將其中節點添加到GossipSection。然后隨機選取n個節點添加到GossipSection,并保證GossipSection中節點的不重復。 1.n←Max(N/8,3); 2.gossipcount←0; 3.for i=1 to PFailNodes.size() do 4. node←PFailNodes[i]; 5. AddNodeToGossipSection(msg,node); 6. gossipcount←gossipcount+1; 7.end 8.for i=1 to n do 9. node←getRandomNode(); 10. … 11.for j=1 to gossipcount do 12. if node = msg→gossipsection[j] then 13. continue; 14. end 15. end 16. AddNodeToGossipSection(node,msg); 17. gossipcount = gossipcount+1; 18.end 測試的Redis版本分別是Redis-3.0.7穩定發布版本以及在Redis-3.0.7上的優化版本,本文中原版、優化前版本都是指Redis-3.0.7。測試用到2臺物理主機,每臺有48核、256 GB內存,CPU型號為Intel(R) Xeon(R) CPU E5-2690 v3@2.60 GHz;測試集群規模為30個主節點、一主兩從,共90個節點。為了對優化效果進行驗證,以及說明優化后產生很小的通信負載,而且這部分通信負載的產生對集群的性能不會產生明顯影響,分別從以下3點進行測試:1)集群宕機恢復過程的耗時對比;2)優化前后單個節點對其他節點的通信量對比;3)優化前后集群的吞吐量和操作延時的對比。 集群恢復時間的測試能夠體現出集群對于故障宕機的處理效率,能夠體現集群處理故障的可靠性。本文將集群宕機恢復過程分為3個階段進行測試,即PFAIL階段、FAIL階段、RECOVER階段,各階段耗時依次記為t1、t2、t3。階段劃分參考圖2。 宕機恢復總時間=t1+t2+t3。t1≈T(默認15 000 ms),t3和節點選取過程有關。因為優化方案主要針對于FAIL階段,所以為了測試優化后宕機恢復過程效率的提升,在測試集群中人為宕機1個~14個主節點(超過主節點總數一半的話,不能恢復),分別對優化前后的FAIL階段耗時t2和恢復總時間進行對比分析。 測試結果對比如圖4和圖5所示。由圖4可以看出,優化后的Redis集群在FAIL階段的效率有很大提升;相對于原版的Redis集群,FAIL階段宕機判斷的效率提升了80%以上,優化效果很明顯。圖5顯示了FAIL階段的優化對于宕機恢復整體過程的影響,優化后的集群在宕機恢復的效率即恢復總時間上,相比于原版有28%以上的提升。 圖4 FAIL階段耗時對比 圖5 宕機恢復總時間對比 本文提出并實現的優化方案對節點發送心跳消息的過程進行優化,使得消息發送的過程在時間上均勻分布,達到負載均衡的目的,避免消息發送過程中出現周期性的峰值。通過提取消息發送日志,對優化前后單個節點在60 s內的消息發送過程進行統計,結果如圖6所示。由圖6對比可以看出,優化后的集群節點在發送消息時在時間上的分布均勻,沒有出現明顯的峰值。 圖6 消息發送時間分布對比 通過對圖6中60 s內的消息發送總量進行統計發現,優化前發送消息總量為717條,優化后為723條,通信負載增加幅度在0.84%左右,通信負載的增加可以忽略。 使用redis-benchmark對Redis集群的常用操作命令進行測試,測試指標包括集群執行每條操作的時延以及集群的吞吐量(QPS:每秒鐘處理的請求數)。分別對每種操作在優化前后的時延(ta和tb)、吞吐量(qa和qb)進行對比,計算時延、吞吐量的變化Δt和Δq,結果如表1、表2所示。其中,Δt=(ta-tb)/ta,Δq=(qb-qa)/qa。 表1 優化前后時延對比 表2 優化前后吞吐量對比 根據表1和表2的數據可以看出,通過redis-benchmark測試得出的時延和吞吐量,優化前后對比性能有升有降,變化幅度大小不一。其實原始版本Redis集群的吞吐量和時延在進行測試時,也會在一定范圍內波動。在相同的測試條件下,表1和表2體現出優化后的Redis集群的性能波動,在可接受的誤差范圍之內,所以總體來說對集群的吞吐量、時延的影響可以忽略不計。 本文通過對Redis集群通信層進行研究,對集群間基于心跳消息的通信過程進行優化,提出了一種適用于大規模集群的消息傳輸模型。通過通信負載均衡的方法以及對消息的Gossip字段的優先級選取,在不帶來額外的通信負載、不影響集群性能的情況下,提升了集群宕機恢復過程的效率,使得Redis集群宕機恢復過程的效率有了28%以上的提升,并增強了Redis集群的可靠性。 Redis集群只能在宕機主節點數少于主節點總數一半時才能從故障中恢復,這是由Redis本身實現的選舉算法決定的。下一步工作是通過對選舉算法進行分析改進,使得多數主節點故障宕機時集群也能夠成功恢復,提升Redis集群對宕機節點數目的容忍度。 [1] Redislabs.Redis cluster specification[EB/OL].[2017-03-13].http://redis.io/topics/cluster-spec/.2016 April. [2] FITZPATRICK B.Distributed caching with memcached[EB/OL].[2017-03-13].http://www.linuxjournal.com/article/7451. [3] SHARMA V,CARROLL J,KHUNE A.Scaling deep social feeds at pinterest[C]//Proceedings of IEEE International Conference on Social Computing.Washington D.C.,USA:IEEE Press,2013:777-783. [4] CIDON A,EISENMAN A,ALIZADEH M,et al.Dynacache: dynamic cloud caching[C]//Proceedings of the 7th USENIX Conference on Hot Topics in Cloud Computing.New York,USA:ACM Press,2015:19. [5] 焦 健,李 巖.基于Redis的SVG空間信息可視化數據庫[J].小型微型計算機系統,2015,36(6):1193-1198. [6] 阿里云.云數據庫Redis版[EB/OL].[2017-03-13].https://help.aliyun.com/document_detail/26342.html. [7] SHAO Zhiyuan,JIN Hai,CHEN Bin,et al.HARTs:high availability cluster architecture with redundant TCP stacks[C]//Proceedings of IEEE International Conference on Performance,Computing,and Communications.Washington D.C.,USA:IEEE Press,2003:253-260. [8] BASSEK C K,PIERRE S,QUINTERO A.Redundancy schemes for high availability computer clusters[J].Journal of Computer Science,2006,2(1):33-47. [9] DERIS M M,RABIEI M,NORAZIAH A,et al.High service reliability for cluster server systems[C]//Proceedings of IEEE International Conference on Cluster Computing.Washington D.C.,USA: IEEE Press,2003:281-288. [10] JI Zhanlin,GANCHEV I,O'DROMA M,et al.A distributed Redis framework for use in the UCWW[C]//Proceedings of International Conference on Cyber-enabled Distributed Computing and Knowledge Discovery.Washington D.C.,USA:IEEE Press,2014:241-244. [11] 黃健宏.Redis設計與實現[M].北京:機械工業出版社,2015. [12] KERMARREC A M,VAN STEEN M.Gossiping in distributed systems[J].Acm Sigops Operating Systems Review,2007,41(5):2-7. [13] 劉德輝,尹 剛,王懷民,等.分布環境下的Gossip算法綜述[J].計算機科學,2010,37(11):24-28. [14] ROBERTSON A.Linux-HA heartbeat system design[C] //Proceedings of the 4th Annual Linux Showcase & Conference.New York,USA:ACM Press,2000:20. [15] 張小芳,胡正國,鄭繼川,等.高可用性集群技術的研究和應用[J].計算機工程,2003,29(4):26-27.2.2 通信負載均衡
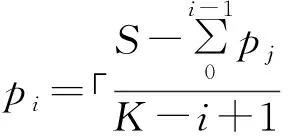
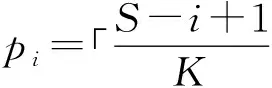
2.3 GossipSection節點的選取
3 測試結果
3.1 宕機恢復過程對比
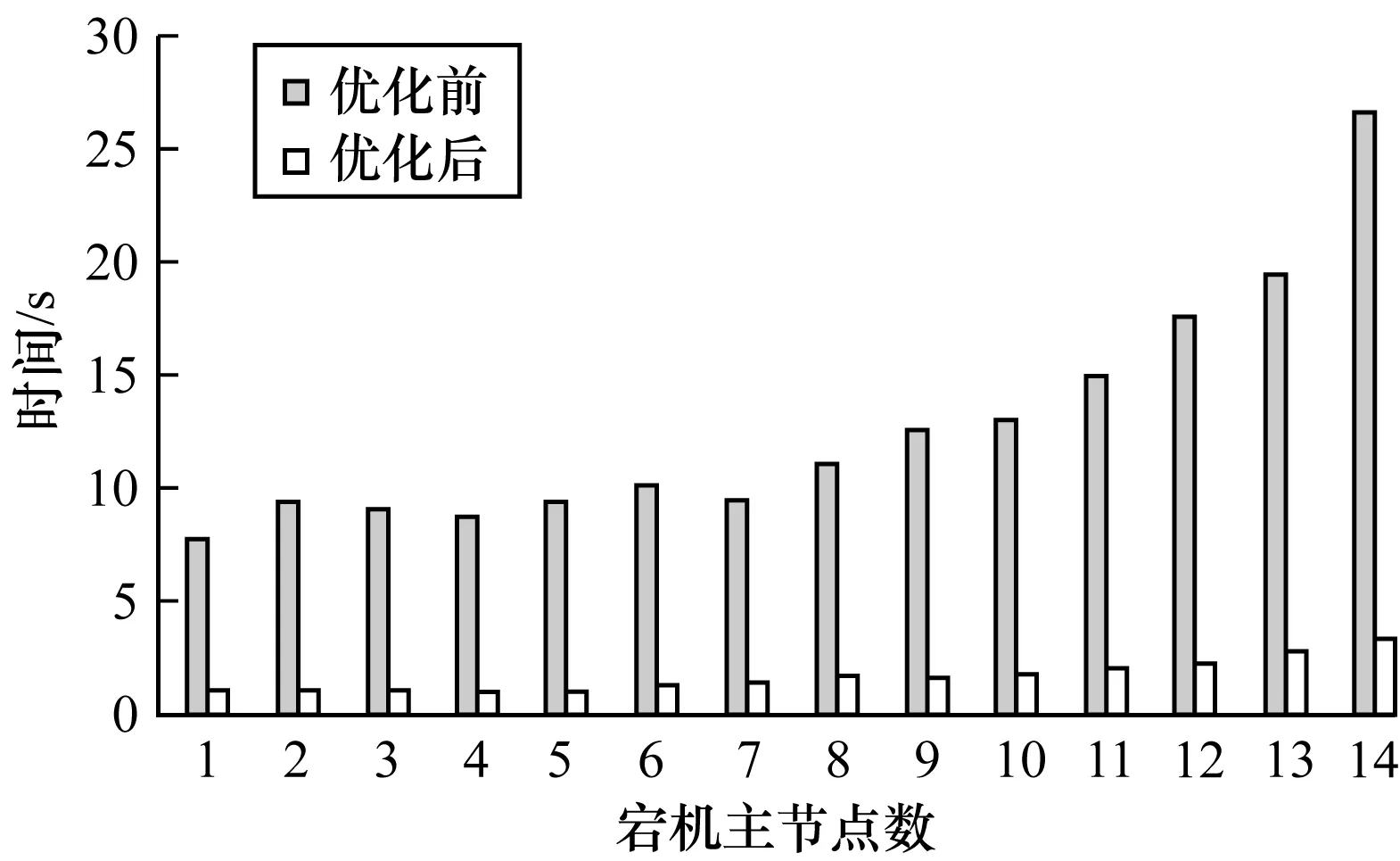
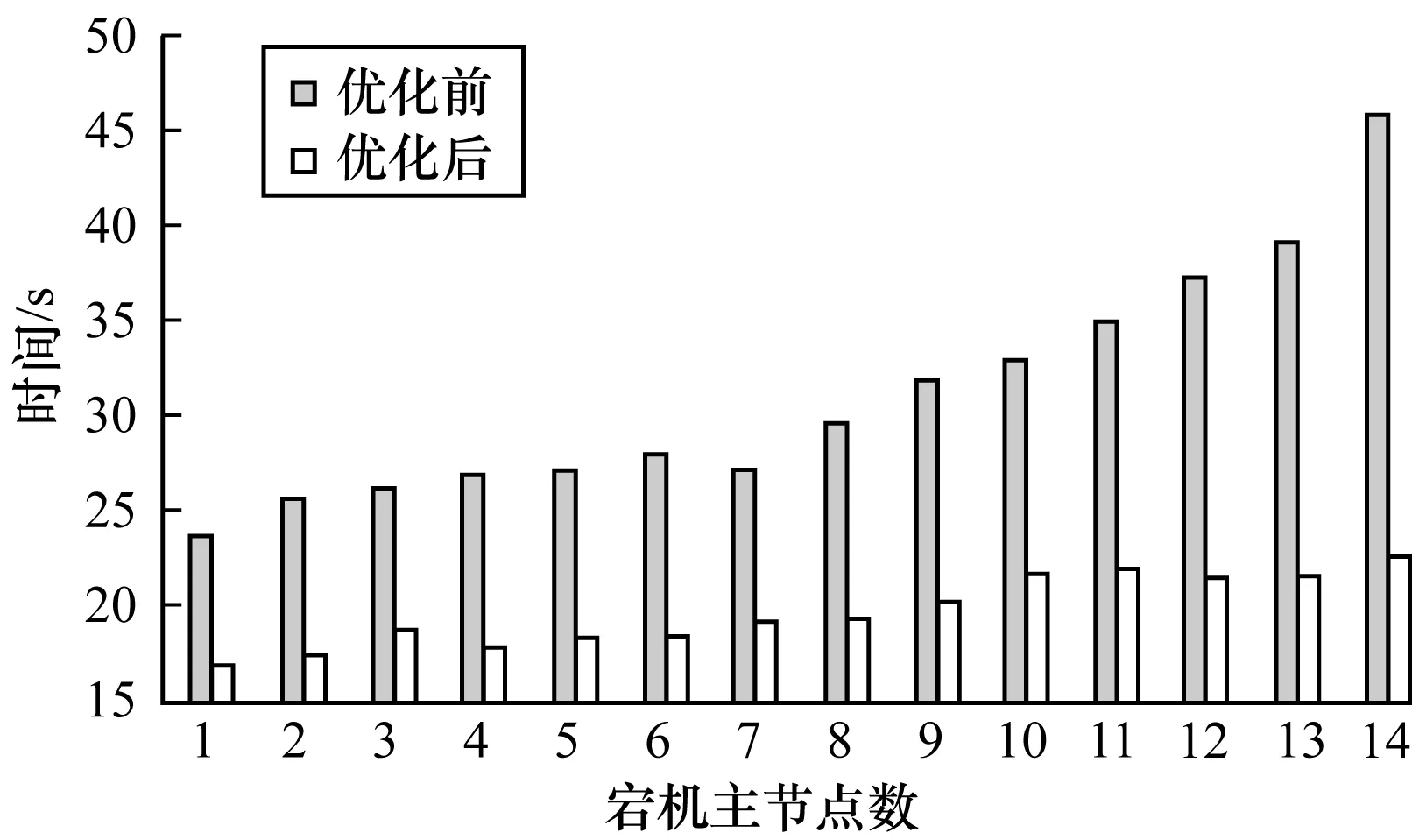
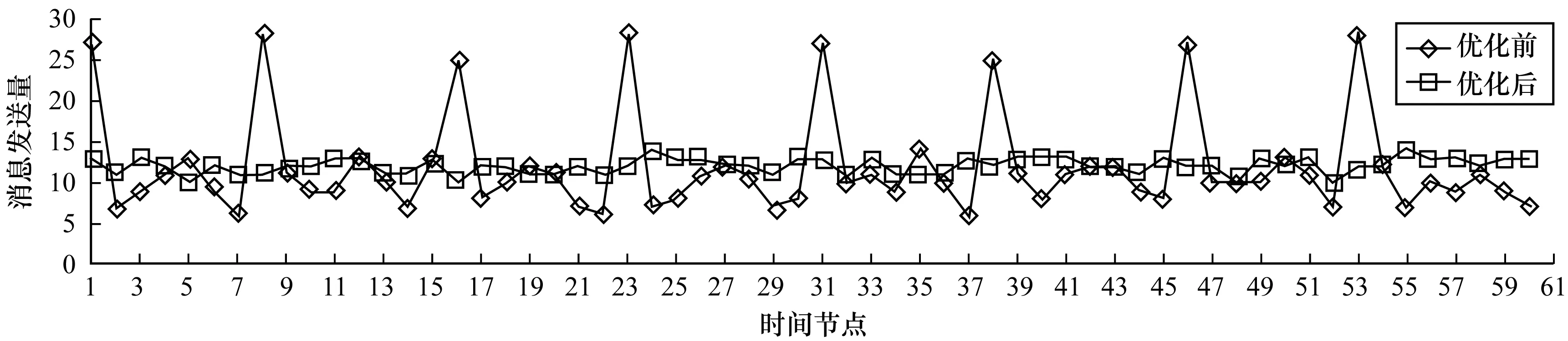
3.2 消息通信分布均衡性
3.3 對集群性能的影響


4 結束語
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
汽車維修與保養(2019年7期)2020-01-06 03:30:42
汽車維護與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維修與保養(2015年2期)2015-04-17 01:30:34
