基于深度表示的中醫(yī)病歷癥狀表型命名實(shí)體抽取研究*
2018-06-21 06:25:22盧克治袁玉虎舒梓心張潤(rùn)順李曉東周雪忠
原 旎,盧克治,袁玉虎,舒梓心,楊 擴(kuò),張潤(rùn)順,李曉東,周雪忠**
(1.北京交通大學(xué)計(jì)算機(jī)與信息技術(shù)學(xué)院 北京 100044;2.湖北省中醫(yī)院 武漢 430061;3.中國(guó)中醫(yī)科學(xué)院廣安門(mén)醫(yī)院 北京 100053)
中醫(yī)臨床記錄通常由醫(yī)生在日常臨床診療工作中記載,其中包含大量的表型信息、檢查記錄病人的治療信息[1]。隨著現(xiàn)代化生物醫(yī)學(xué)電子病歷的快速發(fā)展,應(yīng)用現(xiàn)代技術(shù)實(shí)現(xiàn)對(duì)臨床病歷文本中數(shù)據(jù)的深度挖掘[2],對(duì)其進(jìn)行數(shù)據(jù)分析,以發(fā)現(xiàn)中醫(yī)診療規(guī)律是一項(xiàng)非常有價(jià)值的工作。但由于中文語(yǔ)言的靈活性和中醫(yī)臨床的個(gè)體化表達(dá)[3],使得自動(dòng)從中醫(yī)電子病歷數(shù)據(jù)中提取有意義的信息和知識(shí)具有挑戰(zhàn)性。
目前為止,命名實(shí)體識(shí)別技術(shù)在許多領(lǐng)域取得了顯著的成果,其F-評(píng)測(cè)值(F)已經(jīng)高達(dá)90%以上[4],但是在生物醫(yī)學(xué)領(lǐng)域,命名實(shí)體識(shí)別的研究尚處于初級(jí)階段。因此,對(duì)生物醫(yī)學(xué)領(lǐng)域的命名實(shí)體識(shí)別的相關(guān)研究正在引起人們的重視。Wang等[5]比較了條件隨機(jī)場(chǎng)(Conditional Random Field,CRF),支持向量機(jī)(Support Vector Machines,SVM)和最大熵(Maximum Entropy,ME)三種機(jī)器學(xué)習(xí)算法的性能,并應(yīng)用這三種算法識(shí)別中國(guó)古代醫(yī)案中的癥狀和發(fā)病機(jī)制,發(fā)現(xiàn)CRF更具有優(yōu)勢(shì)。Wang等[6]對(duì)中醫(yī)臨床文本中的癥狀名稱(chēng)的識(shí)別進(jìn)行了初步研究。Xu等[7]研究提出一種將分割和命名實(shí)體識(shí)別相結(jié)合的聯(lián)合模型,以提高對(duì)出院數(shù)據(jù)的命名實(shí)體識(shí)別的性能。Zhou等[8]在中醫(yī)方面使用Bootstrapping方法自動(dòng)識(shí)別中醫(yī)題錄文獻(xiàn)中的疾病名稱(chēng)和復(fù)方名稱(chēng),取得了很好的效果。Xu等[9]應(yīng)用CD-REST提取系統(tǒng)從化學(xué)誘導(dǎo)疾病的生物醫(yī)學(xué)文獻(xiàn)中提取化學(xué)關(guān)系,該系統(tǒng)使用的是CRFs方法進(jìn)行的化學(xué)和疾病名稱(chēng)的命名實(shí)體識(shí)別。Zhang等[10]參加2015年BioCreativeV中的化學(xué)專(zhuān)利與藥物命名實(shí)體抽取任務(wù),使用基于詞向量(Word embedding)的方法測(cè)試了CRF[11]和SSVM[12-13]的性能,其中CRF模型的精確度、召回率、F-測(cè)度值達(dá)到了(0.860 2、0.884 5、0.872 2),SSVM模型達(dá)到了(0.858 8、0.899 9、0.878 9)。袁玉虎等[14]用CRFs模型對(duì)中醫(yī)臨床病歷中的現(xiàn)病史部分進(jìn)行癥狀術(shù)語(yǔ)抽取實(shí)驗(yàn),發(fā)現(xiàn)CRFs模型可以很好的實(shí)現(xiàn)文本中癥狀術(shù)語(yǔ)的序列標(biāo)注任務(wù)。本文將運(yùn)用深度表示的方法對(duì)中醫(yī)病歷文本進(jìn)行命名實(shí)體抽取的實(shí)驗(yàn),并對(duì)抽取結(jié)果進(jìn)行比較與評(píng)價(jià),實(shí)現(xiàn)對(duì)臨床上現(xiàn)病史數(shù)據(jù)的自動(dòng)標(biāo)識(shí)。
1 研究方法
1.1 方法介紹
我們使用CRF和SSVM兩種機(jī)器學(xué)習(xí)算法來(lái)進(jìn)行癥狀詞的實(shí)體標(biāo)識(shí)。CRF是一個(gè)經(jīng)典的基于概率圖模型的序列標(biāo)識(shí)算法。SSVM結(jié)合了CRF和SVM的優(yōu)點(diǎn)[15-18],適用于命名實(shí)體抽取的任務(wù)[13]。條件隨機(jī)場(chǎng)和結(jié)構(gòu)支持向量機(jī)是目前為止最好的命名實(shí)體抽取(NER)機(jī)器學(xué)習(xí)方法。我們首先使用基于規(guī)則的方法對(duì)現(xiàn)病史句子進(jìn)行規(guī)則化處理,然后基于條件隨機(jī)場(chǎng)和結(jié)構(gòu)化支持向量機(jī)構(gòu)建機(jī)器學(xué)習(xí)分類(lèi)器。本文中,使用CRF和SSVM的Web引用作為CRF和SSVM的實(shí)現(xiàn)[15]。
條件隨機(jī)場(chǎng)是自然語(yǔ)言處理領(lǐng)域常用的算法之一,常用于句法分析、命名實(shí)體識(shí)別、詞性標(biāo)注等。CRF本質(zhì)上是隱含變量的馬爾科夫鏈和可觀測(cè)狀態(tài)的隱含變量的條件概率。以詞性變量為例,在詞性標(biāo)注中詞性標(biāo)簽就是隱含變量,具體的詞語(yǔ)就是可觀測(cè)狀態(tài),詞性標(biāo)注的目的是通過(guò)可觀測(cè)到的各個(gè)單詞推斷出每個(gè)單詞應(yīng)該被賦予的詞性標(biāo)簽。
SVMHMM是用于序列標(biāo)簽的SSVM的實(shí)現(xiàn),它可以應(yīng)用于詞性標(biāo)簽、命名實(shí)體識(shí)別、主題查找等[12,19]問(wèn)題。跟過(guò)去的SVM算法相比,SVMHMM算法可以輕松的處理數(shù)百萬(wàn)字或數(shù)百萬(wàn)標(biāo)簽的標(biāo)注問(wèn)題,可以轉(zhuǎn)換和輸出任意長(zhǎng)度依賴(lài)性的更高階模型,其中包括用于快速近似訓(xùn)練和預(yù)測(cè)可選的搜索算法。
本文使用詞嵌入(Word embedding)方法生成詞向量,該詞向量作為CRFs和SSVM模型的輸入。在自然語(yǔ)言處理中,詞嵌入是語(yǔ)言模型集合和特征學(xué)習(xí)的集合名稱(chēng),它把字典中的詞或者短語(yǔ)映射為實(shí)數(shù)向量。詞嵌入把每個(gè)字轉(zhuǎn)化為更低維的數(shù)字型連續(xù)向量空間,它生成的這種映射方法包括:概率模型[20-22]、詞共現(xiàn)矩陣降維[23]、神經(jīng)網(wǎng)絡(luò)[24-25]和利用詞的上下文信息。利用詞嵌入技術(shù)作為底層輸入表示,可以提高自然語(yǔ)言處理任務(wù)的性能。
我們引入了新的基于圖的算法學(xué)習(xí)框架node2vec,使用它來(lái)發(fā)現(xiàn)節(jié)點(diǎn)的連續(xù)特征并構(gòu)建節(jié)點(diǎn)向量,以供下游的機(jī)器學(xué)習(xí)方法使用。node2vec最早是在自然語(yǔ)言處理任務(wù)中提出的。由于node2vec尋找節(jié)點(diǎn)的連續(xù)特征的特點(diǎn),在文本中通過(guò)設(shè)置上下文窗口的大小,最終形成節(jié)點(diǎn)向量。我們將生成的詞向量運(yùn)用于SSVM模型和CRFs模型,將其結(jié)果和基于Word embedding生成的詞向量的兩種模型進(jìn)行對(duì)比分析。在Word embedding方法和node2vec方法的基礎(chǔ)上,融合命名實(shí)體抽取的模型即CRF模型和SSVM模型形成WENER方法和GENER方法。
1.2 方法框架
本次實(shí)驗(yàn)的流程圖如圖1所示,在本文中引入詞嵌入方法:(1)基于規(guī)則的數(shù)據(jù)預(yù)處理:由于臨床文本本身具有半結(jié)構(gòu)化,口語(yǔ)化的特點(diǎn),為了使其在進(jìn)行命名實(shí)體抽取時(shí)能夠直接使用,我們使用Java正則表達(dá)式對(duì)現(xiàn)病史文本中的數(shù)字、時(shí)間、單位、標(biāo)點(diǎn)符號(hào)和特殊符號(hào)用S、TU、DU或者其組合字母代替,這種方法可以簡(jiǎn)化句子結(jié)構(gòu)。由于在一些癥狀詞后面常常跟著不同的標(biāo)點(diǎn)符號(hào)或者單位信息,這些信息對(duì)于文本的提取是沒(méi)有用的,因此,在進(jìn)行統(tǒng)一處理后,由字母S、TU或DU來(lái)取代這些無(wú)用的信息。(2)分詞:實(shí)驗(yàn)中使用中科院提供的分詞工具(NLPIR)進(jìn)行分詞,在分詞中使用的術(shù)語(yǔ)列表為湖北中醫(yī)藥大學(xué)課題研究組整理出的疾病癥狀詞列表;(3)特征抽取:本實(shí)驗(yàn)使用基于skipgram模型的word2vec方法生成的詞向量和node2vec生成的詞向量,并將這兩種詞向量特征應(yīng)用到CRFs模型和SSVM模型上,進(jìn)行癥狀詞的實(shí)體抽取;(4)評(píng)價(jià)指標(biāo):針對(duì)不同特征,分析對(duì)比CRFs模型和SSVM模型的標(biāo)注性能。
1.3 評(píng)價(jià)指標(biāo)
為了評(píng)估文本序列標(biāo)記策略的可行性和引入的序列分類(lèi)器在現(xiàn)病史文本中的性能,我們使用了癥狀名稱(chēng)識(shí)別精確度(P)、召回率(R)和F-測(cè)評(píng)值(F)進(jìn)行評(píng)估。這些評(píng)價(jià)指標(biāo)可以評(píng)估CRF算法模型和SSVM算法模型序列標(biāo)記的可行性。
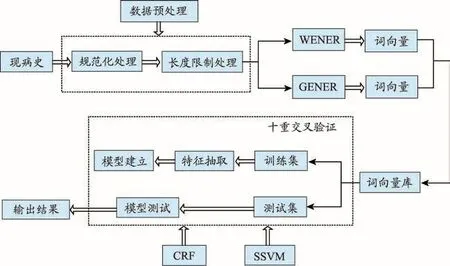
圖1 深度表示的命名實(shí)體抽取框架流程圖
如圖2所示,A表示正確識(shí)別的癥狀名稱(chēng)的數(shù)量,B表示未正確識(shí)別的癥狀名稱(chēng),A+B表示從現(xiàn)病史文本中抽取的實(shí)體個(gè)數(shù),A+C表示標(biāo)準(zhǔn)病歷文本中癥狀實(shí)體個(gè)數(shù)的總數(shù)。癥狀名稱(chēng)正確識(shí)別是指該癥狀詞的開(kāi)始、中間、結(jié)尾部分全部被正確標(biāo)識(shí)[26]。
2 實(shí)驗(yàn)數(shù)據(jù)集及相關(guān)處理
2.1 數(shù)據(jù)集
本實(shí)驗(yàn)使用的數(shù)據(jù)是來(lái)自于湖北省中醫(yī)院肝病研究所的2012年到2016年肝病臨床電子病歷數(shù)據(jù),其中包括人口學(xué)領(lǐng)域(如年齡、性別)和主要癥狀診斷數(shù)據(jù)(如現(xiàn)代疾病診斷,中醫(yī)癥候診斷),我們一共收集整理了10 426條現(xiàn)病史文本數(shù)據(jù),并對(duì)數(shù)據(jù)進(jìn)行規(guī)范化處理和長(zhǎng)度限制分割,再使用分詞工具對(duì)現(xiàn)病史句子進(jìn)行分詞。分詞以后的現(xiàn)病史句子,在基于word2vec和node2vec兩種方法上分別生成詞向量。為了避免選取的語(yǔ)料出現(xiàn)最佳與最差偶然性的事件,對(duì)生成的詞向量用不同的機(jī)器學(xué)習(xí)方法進(jìn)行十重交叉驗(yàn)證取平均值,選取其中90%的數(shù)據(jù)量作為訓(xùn)練集,10%的數(shù)據(jù)量作為測(cè)試集。
2.2 數(shù)據(jù)預(yù)處理
2.2.1 數(shù)據(jù)規(guī)范化處理
由于臨床病歷文本自身具有口語(yǔ)化、專(zhuān)業(yè)化、半結(jié)構(gòu)化的特點(diǎn),因此不能直接對(duì)文本進(jìn)行命名實(shí)體抽取。為了讓我們能更方便的提取到準(zhǔn)確的信息,需要用字符代替一些對(duì)文本抽取無(wú)用的信息,例如跟時(shí)間相關(guān)的詞語(yǔ)、用藥的劑量、標(biāo)點(diǎn)符號(hào)等,這些詞會(huì)對(duì)信息提取造成干擾,因此,我們可以用TU取代時(shí)間,S取代標(biāo)點(diǎn)符號(hào),DU取代劑量單位。通過(guò)對(duì)現(xiàn)病史的規(guī)范化處理,可以大大地提高標(biāo)注算法的性能。表1所示為進(jìn)行規(guī)范化處理前后的一個(gè)現(xiàn)病史文本句子。
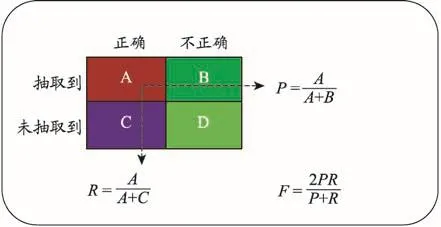
圖2 評(píng)價(jià)指標(biāo)公式
2.2.2 數(shù)據(jù)長(zhǎng)度限制處理
現(xiàn)病史是記述患者病后的全過(guò)程,即發(fā)生、發(fā)展、演變和診治經(jīng)過(guò),包含的內(nèi)容豐富,相對(duì)來(lái)說(shuō),現(xiàn)病史的句子較長(zhǎng)。句子過(guò)長(zhǎng)會(huì)導(dǎo)致一個(gè)句子中涵蓋的信息過(guò)多,通過(guò)前人的研究了解到,句子過(guò)長(zhǎng)會(huì)對(duì)命名實(shí)體抽取造成一定的影響。因此本文在進(jìn)行命名實(shí)體抽取時(shí),將現(xiàn)病史句子長(zhǎng)度控制在一定的范圍之內(nèi)。本文在對(duì)現(xiàn)病史進(jìn)行規(guī)范化處理時(shí)采用了以下處理規(guī)則:由于前期對(duì)文本進(jìn)行了規(guī)范化處理,標(biāo)點(diǎn)符號(hào)用大寫(xiě)英文字母S表示,因此可以用S來(lái)分割句子,將長(zhǎng)的文本分割成若干個(gè)短的字符串。因?yàn)樽址拈L(zhǎng)度大部分都在50字以上,我們就以50為單位來(lái)進(jìn)行分割。如果一個(gè)進(jìn)行過(guò)規(guī)范化處理的文本句子長(zhǎng)度本身就在50個(gè)字以?xún)?nèi),則不做任何處理。如果文本長(zhǎng)度超過(guò)了50個(gè)字,那么我們就用50來(lái)分割。若最后剩下的字符串小于20,則將其和上一個(gè)字符串合并為一個(gè)字符串。表2是分割現(xiàn)病史長(zhǎng)度的具體例子。

表1 現(xiàn)病史數(shù)據(jù)的規(guī)范化處理

表2 現(xiàn)病史文本的長(zhǎng)度限制處理

表3 現(xiàn)病史分詞結(jié)果
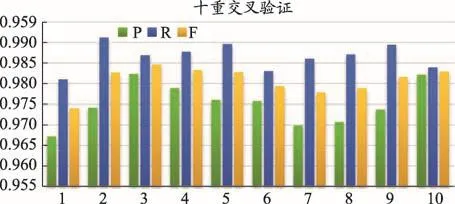
圖3 WENER方法的CRF模型標(biāo)注性能
2.2.3 數(shù)據(jù)分詞處理
基于深度學(xué)習(xí)的方法是用word2vec和node2vec的方法生成詞向量,用生成的詞向量表示現(xiàn)病史文本內(nèi)容,因此我們首先需要對(duì)現(xiàn)病史句子進(jìn)行分詞處理,其分詞結(jié)果如表3所示。
3 基于WENER方法的癥狀表型命名實(shí)體抽取方法研究
對(duì)于現(xiàn)病史數(shù)據(jù)的算法流程描述如下:首先要對(duì)現(xiàn)病史數(shù)據(jù)進(jìn)行數(shù)據(jù)預(yù)處理,將現(xiàn)病史句子進(jìn)行句子長(zhǎng)度限制處理,將每個(gè)現(xiàn)病史句子分割成若干個(gè)長(zhǎng)度在50個(gè)字左右的字符串,并對(duì)長(zhǎng)度處理以后的句子進(jìn)行分詞,將分詞后的結(jié)果作為WENER方法中詞嵌入方法的輸入文件,使用word2vec詞嵌入方法生成200維的詞向量,將生成的詞向量作為CRF模型和SSVM模型的輸入文件,測(cè)試比較兩種模型的算法性能。
如圖3所示為WENER方法的CRF模型在十重交叉驗(yàn)證的評(píng)價(jià)結(jié)果,其性能的平均值分別為:精確度(0.975 0)、召回率(0.984 9)、F值(0.979 8),比傳統(tǒng)的CRF模型的命名實(shí)體抽取的性能提高8.61%,召回率提高19.8%,其F值提高了14.5%。
如圖4所示,是基于word2vec的方法生成詞向量后,使用SSVM模型在現(xiàn)病史數(shù)據(jù)文本上十重交叉驗(yàn)證方法的評(píng)價(jià)結(jié)果。其十重交叉驗(yàn)證的平均值分別為:精確率(0.992 8)、召回率(0.988 9)、F值(0.990 8)。這比傳統(tǒng)的基于CRF算法的命名實(shí)體抽取方法的精確度高出10.39%,召回率高出20.2%,F(xiàn)值高出15.6%。
從以上的結(jié)論可以看出,深度表示的命名實(shí)體抽取方法比傳統(tǒng)的命名實(shí)體抽取的算法性能好,其原因分析如下:由于生物醫(yī)學(xué)上命名的主觀性,癥狀名稱(chēng)的命名規(guī)則不統(tǒng)一[4,27],并且臨床病歷的文本數(shù)據(jù)是由醫(yī)生手工書(shū)寫(xiě)的中文字符,具有靈活多樣性,導(dǎo)致其利用較為困難[28],使得傳統(tǒng)的CRF模型的標(biāo)注性能要略差于WENER下的命名實(shí)體抽取算法。另外,詞嵌入方法能夠隨意選擇特征的維數(shù),并且不需要人為干預(yù),與傳統(tǒng)的方法相比,能更好的利用詞的上下文特征。但是WENER方法依賴(lài)于分詞后的結(jié)果,而領(lǐng)域知識(shí)會(huì)影響到分詞系統(tǒng)的分詞效果,從而影響到命名實(shí)體識(shí)別系統(tǒng)的性能。
從表4中可以看到,雖然WENER方法中的SSVM模型和CRF模型的均值和標(biāo)準(zhǔn)差相差不大,但是SSVM模型的F值比CRF模型的F值有所提高。SSVM模型的性能比CRF的性能好是因?yàn)镃RF模型是一種有代表性的序列標(biāo)注算法,它是一種有辨識(shí)度的無(wú)向概率圖判別模型[28],而SSVM模型是基于結(jié)構(gòu)數(shù)據(jù)的最大化決策邊界模型[12],如序列、二分圖和樹(shù)。SSVM模型結(jié)合了CRF算法和SVM算法的優(yōu)點(diǎn),適用于序列標(biāo)注問(wèn)題[15]。因此,SSVM模型的F值通常要比CRF模型的F值高[15-18,29]。
4 基于GENER方法的癥狀表型命名實(shí)體抽取方法研究
GENER方法是基于網(wǎng)絡(luò)嵌入方法node2vec生成的詞向量,其算法流程如下:首先構(gòu)建node2vec的網(wǎng)絡(luò)結(jié)構(gòu)圖,通過(guò)隨機(jī)游走的方式生成200維的詞向量,然后將生成的詞向量作為CRF和SSVM模型的輸入文件,最后計(jì)算CRF和SSVM兩種模型的評(píng)價(jià)指標(biāo)。其訓(xùn)練集和測(cè)試集同樣使用肝病現(xiàn)病史文本數(shù)據(jù),并對(duì)肝病現(xiàn)病史數(shù)據(jù)進(jìn)行長(zhǎng)度限制處理和分詞處理。在分詞過(guò)程中,我們根據(jù)中文粒度的不同,將分別構(gòu)建基于字和基于詞特征的網(wǎng)絡(luò),并測(cè)試不同網(wǎng)絡(luò)之間GENER方法的標(biāo)注性能。
(1)基于詞特征的GENER方法的實(shí)驗(yàn)結(jié)果分析
從圖5所示可知,GENER方法的CRF模型的性能評(píng)價(jià)結(jié)果的平均值分別為精確度(0.950 1)、召回率(0.950 8)、F值(0.950 4)。相比傳統(tǒng)的CRF模型的性能精確度、召回率、F值分別提高了6.12%、16.39%、11.56%。

圖4 WENER方法的SSVM模型標(biāo)注性能
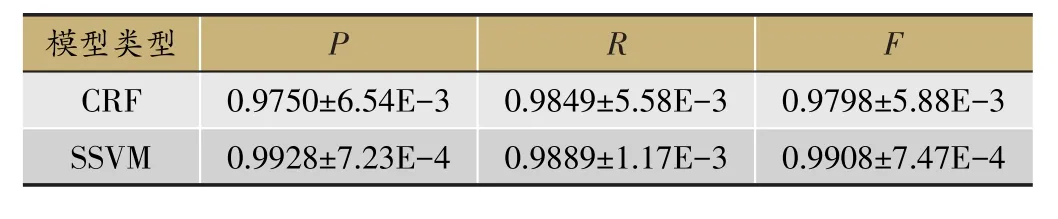
表4 WENER方法下的CRF方法和SSVM方法的性能對(duì)比
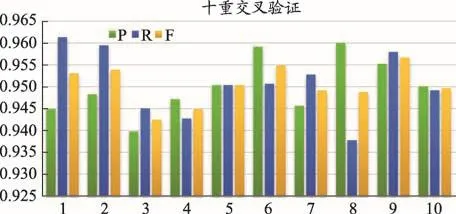
圖5 GENER方法CRF模型基于詞特征的標(biāo)注性能
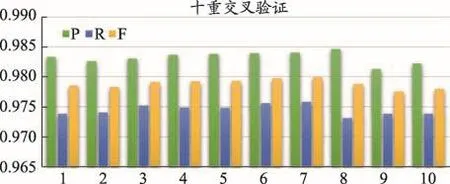
圖6 GENER方法的SSVM模型基于詞特征的標(biāo)注性能

表5 GENER方法下基于詞特征的CRF模型和SSVM模型的性能對(duì)比
從圖6中可以看出,GENER方法在SSVM模型上的標(biāo)注性能結(jié)果的平均值為:精確度(0.983 3)、召回率(0.974 5)、F值(0.978 8)。結(jié)果比傳統(tǒng)的基于CRF的命名實(shí)體抽取算法的精確度高出9.44%,召回率高出18.76%,F(xiàn)值高出14.4%。
GENER方法在基于詞特征下的CRF模型和SSVM模型的性能的對(duì)比結(jié)果分析如表5所示。
從表5可以看出,在GENER方法下的基于詞特征的CRF模型和SSVM模型的評(píng)價(jià)指標(biāo)的對(duì)比,發(fā)現(xiàn)SSVM模型的F值比CRF模型的F值高0.36%,說(shuō)明在基于網(wǎng)絡(luò)嵌入方法提取的特征上,雖然CRF和SSVM的F值相差不大,但是SSVM模型的性能還是要優(yōu)于CRF模型的性能。

圖7 GENER方法的CRF模型基于字特征的標(biāo)注性能

圖8 GENER方法的SSVM模型基于字特征的標(biāo)注性能

表6 GENER方法下基于字特征的CRF模型和SSVM模型的性能對(duì)比
(2)基于字特征的GENER方法的實(shí)驗(yàn)結(jié)果及分析
在基于字特征的GENER方法下的CRF模型和SSVM模型的評(píng)價(jià)結(jié)果如圖7和圖8所示。
從表6可以看出,SSVM模型的精確度要比CRF模型的精確度高1.59%,召回率高8.4%,F(xiàn)值高5.34%。
無(wú)論是基于字還是基于詞的GENER方法,SSVM模型的精確率、召回率和F值與CRF模型相差不大,但是SSVM的性能指標(biāo)要略高于CRF模型的性能。再次驗(yàn)證了對(duì)于SSVM模型和CRF模型在不同領(lǐng)域的比較,SSVM模型的性能通常優(yōu)于CRF模型的性能。
5 討論
在本文的研究中,我們提出了基于深度表示的中醫(yī)病歷中癥狀表示的命名實(shí)體抽取方法,CRF和SSVM兩種算法模型,實(shí)驗(yàn)結(jié)果表示,深度表示的命名實(shí)體抽取性能要明顯高于傳統(tǒng)的命名實(shí)體抽取算法CRF模型的性能。傳統(tǒng)的非深度表示的命名實(shí)體抽取算法(CRF算法)的F值為0.834 8,而深度表示的算法的F值分別為(0.979 8,0.990 8,0.975 2,0.887 9,0.978 8,0.941 3),因此,其性能比傳統(tǒng)的非深度表示的命名實(shí)體抽取的算法性能好;而對(duì)于同一種詞向量特征下,SSVM模型的F值要比CRF模型的F值高。例如,在WENER方法下,SSVM的F值是0.990 8,而CRF的F值為0.979 8,SSVM的性能要高于CRF模型一個(gè)百分點(diǎn)。通過(guò)對(duì)不同的詞向量特征的比較發(fā)現(xiàn),基于word2vec生成的詞向量下的CRF和SSVM模型的性能要高于基于node2vec生成的詞向量下的CRF和SSVM模型的性能。另外,SSVM模型與CRF模型在基于詞的網(wǎng)絡(luò)嵌入方法特征上的性能比基于字的網(wǎng)絡(luò)嵌入方法特征上的性能好,基于詞的網(wǎng)絡(luò)嵌入只有兩種判別類(lèi)型,即是否為癥狀表型術(shù)語(yǔ)。而基于字的網(wǎng)絡(luò)判別類(lèi)型三種:“B-S”、“E-S”、“O”。基于字的判別類(lèi)型增加需要做出更多的判斷,可能造成性能的下降。而且,基于字的特征使得特征粒度減小,特征信息降低,而基于詞的特征粒度比基于字的粒度大,特征信息較強(qiáng)。
1 Jensen P B,Jensen L J,Brunak S.Mining electronic health records:towards better research applications and clinical care.Nat Rev Gen,2012,13(6):395.
2 劉凱,周雪忠,于劍,等.基于條件隨機(jī)場(chǎng)的中醫(yī)臨床病歷命名實(shí)體抽取.計(jì)算機(jī)工程,2014(9):312-316.
3 Feng L,Zhou X,Qi H,et al.Development of large-scale TCM corpus using hybrid named entity recognition methods for clinical phenotype detection:An initial studyComputational Intelligence in Big Data,2015.
4 王世昆,李紹滋,陳彤生.基于條件隨機(jī)場(chǎng)的中醫(yī)命名實(shí)體識(shí)別.廈門(mén)大學(xué)學(xué)報(bào)(自然版),2009,48(3):359-364.
5 Wang S K,Shao-Zi L I,Chen T S.Recognition of Chinese Medicine Named Entity Based on Condition Random Field.J Xiam Univ,2009,48(3):359-364.
6 Wang Y,Liu Y,Yu Z,et al.A preliminary work on symptom name recognition from free-text clinical records of traditional chinese medicine using conditional random fields and reasonable features.The Workshop on Biomedical Natural Language Processing,2012.
7 Xu Y,Wang Y,Liu T,et al.Joint segmentation and named entity recognition using dual decomposition in Chinese discharge summaries.J Am Med Inform Ass,2014,21:e84.
8 Zhou X,Wu L Z,Yi F.Integrative mining of traditional Chinese medicine literature and MEDLINE for functional gene networks.Artif Intell Med,2007,41(2):87-104.
9 Xu J,Wu Y,Zhang Y,et al.CD-REST:a system for extracting chemical-induced disease relation in literature.Database the Journal of Biological Databases&Curation,2016,baw036.
10 Zhang Y,Xu J,Hui C,et al.Chemical named entity recognition in patents by domain knowledge and unsupervised feature learning.Database the Journal of Biological Databases&Curation,2016:baw049.
11 Andrew G,Gao J.Scalable training of L1-regularized log-linear models,2007.
12 Tsochantaridis I,Joachims T,Hofmann T,et al.Large Margin Methods for Structured and Interdependent Output Variables.J Mach Learn Res,2005,6(2):1453-1484.
13 Bakir G,Hofmann T,Sch?lkopf B,et al.Support Vector Machine Learning for Interdependent and Structured Output SpacesInternational Conference on Machine Learning.ACM,2004.
14 袁玉虎,周雪忠,張潤(rùn)順,等.面向中醫(yī)臨床現(xiàn)病史文本的命名實(shí)體抽取方法研究.世界科學(xué)技術(shù):中醫(yī)藥現(xiàn)代化,2017,19(1):70-77.
15 Tang B,Feng Y,Wang X,et al.A comparison of conditional random fields and structured support vector machines for chemical entity recognition in biomedical literature.J Cheminformatics,2015,7(S1):1-6.
16 Zhang Y,Wang J,Tang B,et al.UTH_CCB:A report for SemEval 2014-Task 7 Analysis of Clinical Text.International Workshop on Semantic Evaluation,2014.
17 Tang B,Wu Y,Jiang M,et al.A hybrid system for temporal information extraction from clinical text.J Am Med Inform Ass Jamia,2013,20(5):828-835.
18 Balamurugan P,Shevade S,Sundararajan S,et al.An Empirical Evaluation of Sequence-Tagging Trainers.Computer Science,2013.
19 Mikolov T,Sutskever I,Chen K,et al.Distributed Representations of Words and Phrases and their Compositionality.Adv Neur Inform Process Sys,2013,26:3111-3119.
20 Lebret R,Collobert R.Word Emdeddings through Hellinger PCA.Computer Science,2014.
21 Levy O,Goldberg Y.Neural word embedding as implicit matrix factorization.Adv Neur Inform Process Sys,2014,3:2177-2185.
22 Li Y,Xu L,Tian F,et al.Word embedding revisited:a new representation learning and explicit matrix factorization perspectiveInternational Conference on Artificial Intelligence,2015.
23 Globerson A,Chechik G,Pereira F,et al.Euclidean Embedding of Cooccurrence Data.J Mach Learn Res,2007,8(4):2265-2295.
24 Levy O,Goldberg Y.Linguistic Regularities in Sparse and Explicit Word Representations.Eighteenth Conference on Computational Natural Language Learning,2014.
25 AlexRudnicky.Can Artificial Neural Networks Learn Language Models?.Proc Int Conf Spok Lang Proc.2000:202-205.
26 Wang Y,Yu Z,Chen L,et al.Supervised methods for symptom name recognition in free-text clinical records of traditional Chinese medicine:an empirical study.J Biomed Inform,2013,47(2):91-104.
27 胡俊鋒,陳蓉,陳源,等.一種松耦合的生物醫(yī)學(xué)命名實(shí)體識(shí)別算法.計(jì)算機(jī)應(yīng)用,2007,27(11):2866-2869.
28 Lafferty J,Mccallum A,Pereira F.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data.Eight Int Conf Mach Learn,2002,53(2):282-289.
29 Lei J,Tang B,Lu X,et al.A comprehensive study of named entity recognition in Chinese clinical text.J Am Med Inform Ass,2014,21(5):808-814.
猜你喜歡
童話(huà)王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
