改進二叉樹支持向量機及其TE過程故障診斷
2018-07-03 11:33:52陳柏志石宇強詹鈞凱鄔江波
西南科技大學學報 2018年2期
陳柏志 石宇強 詹鈞凱 鄔江波
(西南科技大學制造科學與工程學院 四川綿陽 621010)
支持向量機(Support Vector Machines,SVM),是一種建立在統計學習理論基礎上的機器學習新方法[1],它在解決小樣本、非線性以及高維模式識別等問題中表現出特有的優勢,并在很大程度上克服了“維數災難”和“過學習”等問題。最初SVM是針對二分類問題設計的,而實際問題往往屬于多類別分類,如故障診斷、文本分類、人臉識別等。目前,SVM解決多類分類的方法主要有一對多SVM、一對一SVM、決策有向無環圖SVM和二叉樹SVM等[1-4]。其中,與一對一、一對多以及決策有向無環圖等SVM方法相比較,二叉樹SVM具有需要訓練的分類器數目最少、樣本重復訓練率低、分類速度快且不存在不可分區域等優點,是一種非常適合故障診斷的支持向量機多類分類算法。
二叉樹SVM由于其特有的優勢,近年來受到了學者的廣泛關注,主要聚焦在三個方面:(1)二叉樹SVM的推廣能力依賴于二叉樹的樹形結構,類間差異性估計是設計二叉樹結構的基礎。樣本之間歐式距離是廣泛采用的度量手段。文獻[5]以類間樣本最短距離來度量類間的距離,讓距離最遠的類最先分離出來。文獻[6]以類內樣本間最大距離來度量類內樣本分布的范圍,讓分布廣的類最先分離出來。文獻[7-8]綜合考慮類間和類內樣本分布的情況,將兩個角度的描述合理結合起來,更全面地反映類別之間的差異性。(2)將其他方法與二叉樹SVM結合起來進一步優化二叉樹SVM的樣本不平衡、訓練時間以及精度等,文獻[9-10]將二叉樹與雙支持向量機相結合,利用雙支持向量機克服了二叉樹SVM可能存在的樣本不平衡問題和減少二叉樹SVM的訓練時間。(3)將二叉樹SVM應用到實際問題中,如機械故障診斷、焊縫缺陷檢測、網絡入侵檢測等[8,10-11]。
TE(Tennessee Eastman)過程作為一個典型的化工生產模型,具有復雜多變、非線性等特點[12],其過程存在以下特點:(1)復雜的非線性;(2)故障發生表現出強烈的滯后性;(3)工藝參數眾多且相互干擾,彼此耦合,存在部分重合。鑒于SVM在解決非線性、高維數據以及局部極小等問題的優勢,是TE過程故障診斷的理想方法。
本文基于帕累托原則結合類間樣本距離和類內樣本分布設計了一種新的類間差異性估計策略,并提出了完全二叉樹SVM的構建方法。較之前的研究,本文還探討了完全二叉樹、偏二叉樹以及從上到下構造二叉樹、從下到上構造二叉樹的推廣性能。利用標準數據集,與一對一、一對多、決策有向無環圖以及其他二叉樹方法作比較,評定改進算法的性能。以TE過程為故障診斷對象,基于核主成分分析提取故障特征,利用改進算法收到了令人滿意的故障診斷效果。
1 改進二叉樹支持向量機
1.1 SVM多類分類算法介紹
目前,SVM多類分類方法根據其指導思想大致有兩類:一種是通過構造多個二類分類器并將它們組合起來完成多類分類;另一種是只使用一個SVM分類器,該分類器對SVM的原始最優化問題作適當修改從而“一次性”地計算出多類分類決策函數。第二種方法的指導思想看似簡單,但它的最優化問題求解過于復雜,計算量大,而且在分類精度上也不占優勢。因此,第一種方法更為常用。
第一種方法主要包括一對多(One-against-Rest,1-a-r),一對一(One-against-one,1-a-1),決策有向無環圖(Decision Directed Acyclic Graph,DDAG)、二叉樹(Binary Tree,BT)等方法。一對多方法簡單,需要訓練的子分類器個數少,但其缺點是當類別數較多時,訓練樣本的不平衡將對精度產生影響,且存在拒分區域。一對一方法訓練樣本是平衡的,訓練精度高于一對多方法,但類別較多時,需要訓練較多的子分類器,其時間復雜度大大增加,不適用類別較多的情況,并且也存在拒分區域。DDAG方法的優點是分類速度較前面兩種方法有明顯提高,不存在拒分區域,缺點是需要同一對一方法一樣多的子分類器,并且其根節點選取的二值分類器不同其精度會有明顯差異[2]。
二叉樹SVM是一種采用二叉樹結構來構造SVM多類分類的算法,其構造過程如下:將所有類別依據某種策略劃分成兩個子類,再將這兩個子類分別劃分成兩個次子類,如此循環下去,直到所有的類別都作為一個單獨節點為止,此節點也就是二叉樹中的葉子節點。二叉樹SVM方法可以避免傳統的一對多、一對一方法存在的不可分區域,并且只需構造k-1個子分類器,其分類時平均需要經過log2k個子分類器,分類速度大大提高,缺點是二叉樹的結構對整個模型的分類精度有較大的影響,可能存在“誤差累積”現象,上層節點發生的分類錯誤,會把這種錯誤延續下去,使后續節點的分類失去意義,并且分類錯誤越靠近根結點,模型推廣性能越差。因此,二叉樹SVM的關鍵是如何設計有效的二叉樹結構。上述4種SVM多類分類方法對比如表1所示。
1.2 類間差異性估計
為了避免“誤差累積”現象,應該讓最容易分割的類率先分離出來,也就是要盡可能的去估計類別之間的差異性,類別之間差異性越大越容易分割。然而由于各個類別數據的真實分布情況無法得知,只能利用有限的樣本集的分布情況去近似估計真實數據的類別差異性。在先前的研究中,學者分別使用了多種策略對類別差異性進行描述,其策略大致有兩個方面:一是采用不同類別樣本之間的歐氏距離來度量類別之間的距離,二是利用類內樣本分布半徑作為類別分布區域大小的度量,或者是綜合考慮類間距離和類內樣本分布的影響,從實際的分類效果來看[7-8],綜合考慮兩個方面的策略能更好地估計類間差異性。但是這些方法也存在一些問題,當訓練樣本數據存在測量誤差或者方法誤差即所謂的“野值”,導致數據的散布較大,由此生成比實際所占區域更大的超球體半徑,同時這些“野值”由于距離超球體中心較遠,因此在計算方差或者超球體中心時容易造成偏差,這樣就會帶來層次誤差,誤差逐層累積,導致分類精度降低。

表1 SVM多類分類方法對比Table 1 Comparison of SVM multi-class classification methods
如圖1所示,各個類別的樣本在高維空間是各自聚集在一起的,形成了超球體中心點,按照距離中心點的遠近將數據的分布范圍由內到外可分為核心圈、計算半徑圈以及邊界圈。核心圈內的數據是類別最具代表性的數據,具有明顯的類別特征;計算半徑圈是將類別所有樣本都納入半徑計算過程得到的;邊界圈是依據距離中心點最遠的樣本劃分的,包含了類別所有的樣本。
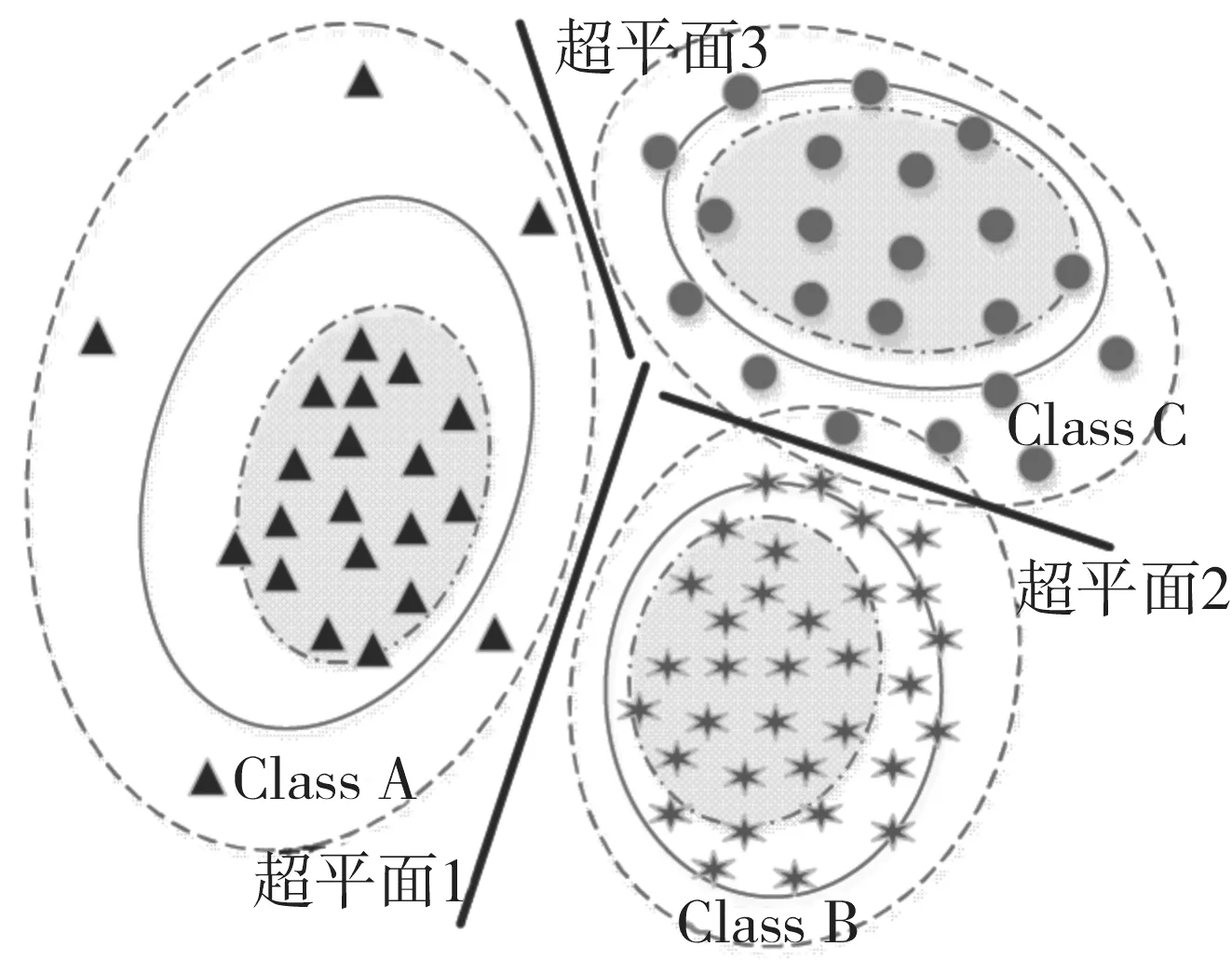
圖1 類分布示意圖Fig.1 Schematic diagram of class distribution
19世紀末期的意大利經濟學家兼社會學家維弗利度·帕累托提出“重要的少數與瑣碎的多數”原理,該原理指出在特定領域20%的少數達到總體貢獻度的80%,掌握該20%的因子就能控制全局,這就是著名的帕累托法則,也稱80/20效應。
根據帕累托法則,結合前面的分析,可以得出,分類樣本中20%的數據能夠代表核心圈的分布情況,80%的樣本能夠代表計算半徑圈的分布情況。
核心圈內的樣本距離其類別中心點最近,是具有明顯類別特征的樣本,與其他類別樣本的距離較遠,不會存在樣本重疊現象。在此,采用核心圈樣本最近類間距離來衡量類間距離。核心圈樣本最近類間距離越大,類間距離越遠,類別之間的差異性越大,反之亦然。核心圈樣本最近類間距離定義如下:
計算i,j類核心圈樣本的最近距離
min(di,jker)=min{‖xiker-xjker‖}
(1)
計算半徑圈內的樣本反映了同類樣本的整體有效分布情況。在此,采用計算半徑圈內樣本平均密度來衡量類內樣本的分布情況。平均密度小,表明樣本分布得越緊密,反之亦然。類內計算半徑圈內樣本平均密度定義如下:
(2)
其中ximax表示計算半徑圈內的樣本,nimax表示計算半徑圈內的樣本數目。類內計算半徑圈內樣本的均值
(3)
根據類間距離大且類內樣本分布得越緊密集中的類間差異性越大的原則,設計的類間差性估計策略要能夠體現兩方面的因素,具體形式為:
(4)
類間差異性估計策略具體計算步驟如下:
步驟1 建立訓練樣本集{xi,yi},yi={1,2,…,k},k為類別數,然后將訓練樣本的各特征值歸一化,線性調整到[-1,+1]。
步驟2 依據公式(3),計算每個類別的超球體中心ci。
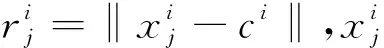
步驟4 對各個類別的樣本取重新排序后前20%的樣本依據公式(1)計算min(di,jker),取前80%的樣本依據公式(2)和(3)計算σimax,σjmax,最后依據公式(4)求出i,j類的類別差異度Ii,j。
步驟5 按照上述步驟計算得出各類間的差異性SI=Iij,i,j=1,2,…,k,i≠j。構造表示類間差異性的對稱矩陣
1.3 改進的二叉樹支持向量機算法設計
如圖2所示,二叉樹支持向量機有兩種結構,一種是偏二叉樹,在判斷節點處由一個類作為正類與余下的類別作為負類構造分類超平面;一種是完全二叉樹,在判斷節點處由多個類與多個類構造分類超平面。盡管偏二叉樹構造過程簡單,但是對于類別數較多的樣本集來說,樹的深度大,測試平均時間比完全二叉樹長,同時容易造成樣本不均衡。

圖2 完全二叉樹與偏二叉樹示意圖Fig.2 Schematic diagram of complete binary trees and partial binary trees
與常見的從上到下構造策略不同的是,哈夫曼樹(Huffman Tree,HT)是從下往上構造的二叉樹結構,其思想是將當前認為最不好分的兩類率先生成決策節點。從構造思想上看,基于這種構造思路得到的上層決策節點是全局最優解,其整體分類效果可能優于從上往下構造的二叉樹結構,但其實際生成的樹形結構往往傾向于偏二叉樹,其原因在于往上的構造過程中形成的由多個類別構成的決策節點在與單個類別的葉子節點估計類間差異性時占有很大的優勢,已生成的決策節點容易與葉子節點生成上一層的決策節點,其總體形態偏向于偏態樹。
完全二叉樹克服了偏態樹的缺點,特別是類別數較多時,其性能優勢更加明顯。為了生成完全二叉樹或者近似完全二叉樹,具體算法步驟如下:
步驟1 對于k類問題,求出差異性估計矩陣SI,并將各類的類別標號由小到大存入集合C中;
步驟2 從SI中找出差異性最大(maxIi,j)的兩個類i和j,將i類樣本存入集合C1中,將j類樣本存入集合C2中,并從C中刪除i,j類標號;
步驟3 若C=φ,則轉到步驟5;
步驟4 在SI中查找類m(m∈C)分別與i,j類的差異性,若Ii,m 步驟5 將C1作為二叉樹的左子樹,C2作為二叉樹的右子樹。將C1中對應的樣本標記為正類,C2中對應的樣本標記為負類,至此,得到一個子分類器; 步驟6 令C=C1,直到C1只包含一個類別不可再分為止,此時左子樹構造結束。否則,返回步驟2,將C1進一步分割成左右子樹; 步驟7 令C=C2,直到C2只包含一個類別不可再分為止,此時右子樹構造結束。否則,返回步驟2,將C2進一步分割成左右子樹。 為了評價改進算法的性能,本文使用UCI數據庫[13]的Win,Segment,Optdigits,Satimage 4個標準數據集(表2),將本文所提改進算法與一對一、一對多、DDAG 3種常規SVM分類算法進行實驗測試對比的同時,還與從上到下構造的偏二叉樹(偏BT)、哈夫曼樹(HT)、偏哈夫曼樹(偏HT)3種二叉樹算法進行實驗測試對比。本文所有算法均采用VC++編程,在LIBSVM工具包基礎上修改實現。實驗平臺為AMD A10-7400P,4GB RAM,操作系統為Windows 7 SP1。 為了避免取值范圍更大的屬性占更多優勢,本文對樣本數據全部進行標準分歸一化預處理,將屬性范圍調整到[-1,+1]。SVM的核函數采用徑向基核函數,具體形式為:K(x,xi)=exp{-γ‖x-xi‖2}。同時由于模型的推廣能力與核參數γ、懲罰參數C有關,為了保證參數搜索空間的完備性以及對訓練數據集獲得更好的誤差估計,將網格尋優和交叉驗證共同作用,參數C的尋優空間為[21,22,…,28],參數γ的尋優空間為[2-4,2-3,…,20],共8×5=40種組合,采用十折交叉驗證,從而獲得推廣能力最佳的(C,γ)組合。實驗結果如表3所示(表中所有精度值保留兩位有效小數)。 不同算法運行的時間結果見表4,Win數據集由于其樣本數較少,運行時間過短難以比較,故省略。為了避免不同的參數對運行時間產生影響,將各個數據集的參數固定為:Segment(28,20),Satimage(23,20),Optdigits(23,2-4)。運行時間采用CPU時間,運行10次求平均值作為最終結果(單位為s,結果保留3位有效小數)。 表2 數據集信息統計表Table 1 Statistic information of data sets 表3 各算法最優參數及識別準確率Table 3 Optimal parameters and recognition accuracy of each algorithm 表4 各算法運行時間Table 4 Operation time of each algorithm 為了對比二叉樹方法與一對一、一對多、DDAG方法在精度和時間方面的優劣以及驗證本文算法,將4種二叉樹方法作為整體與其他3種方法進行比較的同時比較各個數據集上精度和時間的最優算法,如前面表1所描述,在精度方面,一對一、DDAG和二叉樹方法相當,明顯優于一對多方法,除Segment數據集上一對一方法精度最高外,其他數據集上本文算法精度最高;在訓練速度方面,一對一和DDAG方法由于訓練的分類器完全一樣,其訓練速度是一致的,一對多方法在各個數據集上的訓練速度都最慢,HT、偏HT以及偏BT訓練速度要明顯慢于一對一和DDAG方法,但本文所提算法在Satimage數據集上訓練速度最快,在Segment和Opdigits數據集上略微慢于一對一和DDAG方法;在測試速度方面,本文所提算法用時最短,二叉樹方法要明顯優于其他3種方法,DDAG方法要略優于一對一和一對多方法,一對一和一對多方法測試速度相當。 為了更深入更直觀地比較4種二叉樹算法的性能,將針對4種二叉樹算法生成的樹形結構進行討論。Win數據集由于只有3個類別,4種算法生成一樣的二叉樹結構,其精度和時間都是一致的;在Segment數據集上,HT與本文算法生成完全一樣的樹形結構,其精度和時間呈現出一致的效果,偏BT精度略微高于其他3種算法,但HT和本文算法由于生成的是近似完全二叉樹,其時間明顯快于偏HT、偏BT;在Satimage和Optidigits數據集上,本文算法在精度上略占優勢,其速度明顯快于其他3種算法,特別是在類別數較多的Optidigits數據集上其速度優勢更明顯,本文算法生成完全二叉樹結構,其樹的深度比其他3種算法小很多,HT與偏HT都生成完全一致的偏二叉樹結構,偏BT生成與HT、偏HT不一樣的二叉樹結構,HT、偏HT以及偏BT由于都是偏二叉樹結構,其速度都是一致的。 TE過程是由Downs和Vogel[14]提出的一個仿真化工過程,根據伊斯曼化學公司的實際工藝流程模擬實現而來,具有復雜多變、非性線的特點。TEP(Tennessee Eastman Process, TEP)包括:化學反應器、冷凝器、壓縮機、氣液分離器、汽提塔這5個運行單元和A,B,C,D,E,F,G,H這8種成分,A,C,D,E 4種生產原料和不參與反應的惰性成分B投入裝置生成產品G和H,F是反應過程中的副產品。TE過程含有41個測量變量(22個連續變量、19個成分變量)和12個操作變量,由于第12個操作變量(攪拌速度)是恒定值,所以TE過程共有52個可控的過程變量。除正常運行狀態外,TE過程包括20個典型故障,其中有5個未知故障,本文利用15個已知故障進行實驗,仿真產生7 700條訓練數據,其中500條是無故障數據,各個故障類別均是480條數據;12 960條測試數據,960條無故障數據,各個故障類別均是800條數據。 TE過程含有大量的監控工藝參數,這些工藝參數之間存在較強的相關性,并且反應器溫度、壓力、原料進料量等容易發生階躍變化,呈現出強非線性。而核主成分分析通過將原始數據映射到高維空間進行主成分分析,達到線性可分和特征降維的效果,在過程監測領域得到廣泛應用。通過核主成分分析,選取少數的核主成分就可以表征過程主要的變化信息,實現過程特征提取,縮短了支持向量機的訓練時間和訓練精度。本文核主成分分析采用徑向基核函數,特征值貢獻率確定為95%,核參數通過達到貢獻率時所需核主成分數最少與支持向量機訓練結果最優共同經驗確定γ=2-12,選取23個核主成分。核主成分分析結果如表5所示。 表5 TEP訓練樣本核主成分分析結果Table 5 Analysis results of kernel principal component in TEP training samples 將原始訓練集和測試集通過核主成分變換成新的訓練集和測試集,對于每個算法選擇其十折交叉驗證的平均分類精度最好情況下對應的懲罰參數C和核函數參數γ。對于本文算法的每個兩類問題,如果正類和負類樣本數目差別太大,則令C1=n1×C/n,C2=n2×C/n,其中n1和n2分別表示兩類問題中的正、負類樣本數目,n=n1+n2。各算法的實驗結果如表6所示。 表6 各算法故障診斷識別準確率Table 6 Recognition accuracy of fault diagnosis of each algorithm (1)在分析類間差異性估計策略的基礎之上,基于帕累托原則以核心圈樣本最近類間距離和類內計算半徑圈樣本平均密度建立了類間差異性估計策略,提出了改進二叉樹SVM的算法步驟。 (2)利用標準數據集,通過與其他SVM多類分類方法比較,所提算法識別準確率高,訓練和測試時間短,驗證了該算法的優越性。 (3)基于核主成分分析提取TE過程故障特征,應用改進的完全二叉樹SVM進行故障診斷,收到了較傳統SVM多類分類算法更好的故障識別率。 [1] VAPNIK V N. The nature of statistical learningtheory[M]. NewYork:Springer,1995. [2] HSU C W, LIN C J. A comparison of methods for multiclass support vector machines[J]. IEEE Transactions on Neural Networks, 2002,13(2):415- 425. [3] PLATT J C, CRISTIANINI N, SHAWE TAYLOR J. Large margin DAGs for multiclass classification[J]. In:Advances in Neural Information Processing Systems,MIT press,2000,12:547-553. [4] CHEONG S, OH S H, LEE S Y. Support vector machines with binary tree architecture for multiclass classification[J]. Neural Information Processing Letters and Reviews,2004,2(3):47-51. [5] XIA S Y, LI J X, XIA L Z, et al.Tree structured support vector machines for multiclass classification[A]// Lecture Notes in Computer Science[C].Berlin,Heidelberg:Springer-Verlag,2007:392-398. [6] 唐發明,王仲東,陳綿云.支持向量機多類分類算法研究[J].控制與決策,2005,20(7):746-749. [7] 趙海洋,徐敏強,王金東.改進二叉樹支持向量機及其故障診斷方法研究[J].振動工程學報,2013,26(5):764-770. [8] 羅愛民,沈才洪,易彬,等.基于改進二叉樹多分類SVM的焊縫缺陷分類方法[J].焊接學報,2010,31(7):51-54. [9] 謝娟英,張兵樹,汪萬紫.基于雙支持向量機的偏二叉樹多類分類算法[J].南京大學學報(自然科學版),2011,47(4):354-363. [10] 聶盼盼,臧洌,劉雷雷.基于對支持向量機的多類分類算法在入侵檢測中的應用[J].計算機應用,2013,33(2):426-429. [11] 朱新才,鄧星,周雄,等.二叉樹支持向量機的旋轉機械故障診斷[J].重慶大學學報,2013,36(7):21-26. [12] 李宏光,夏麗君.改進的FP-growth算法及其在TE過程故障診斷中的應用[J].北京工業大學學報,2016,42(5):697-706. [13] MURPHY P M, AHA D W. UCI repository of machine learning databases[EB/OL]. http://www.ics.uci.edu/mlearn/MLRepository.html. [14] DOWNS J J, VOGEL E F.A plantwide industrial process control problem[J]. Computers and chemical engineering,1993,17(3):245-255.2 標準數據集實驗
2.1 實驗數據與實現

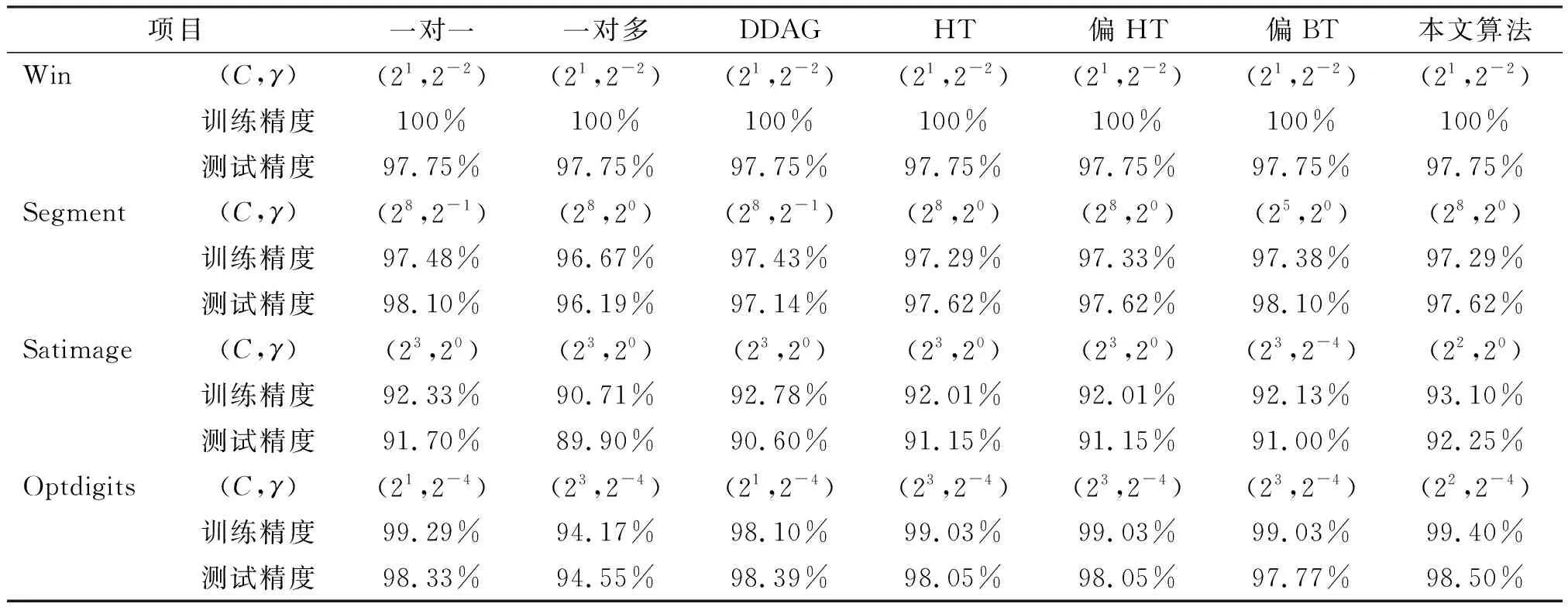
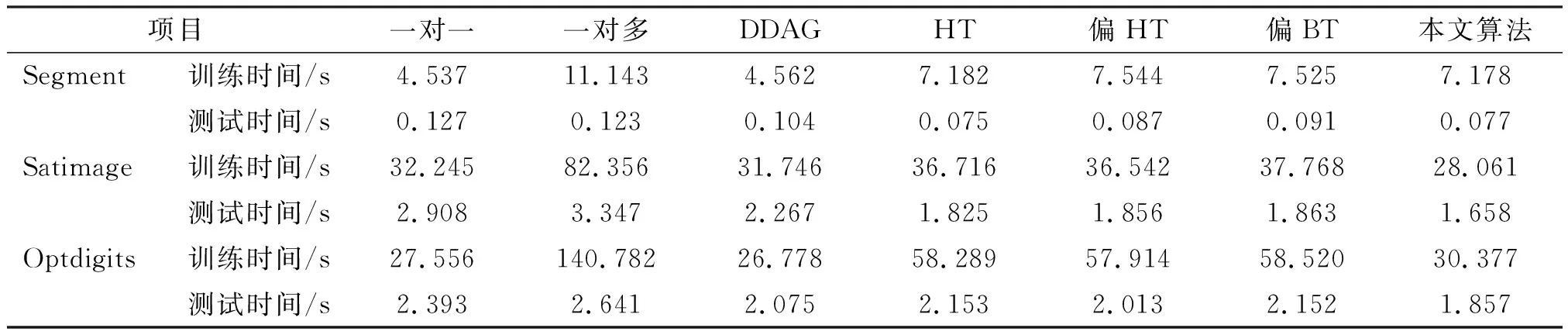
2.2 實驗結果分析
3 TE過程故障診斷
3.1 TEP簡介
3.2 故障特征提取
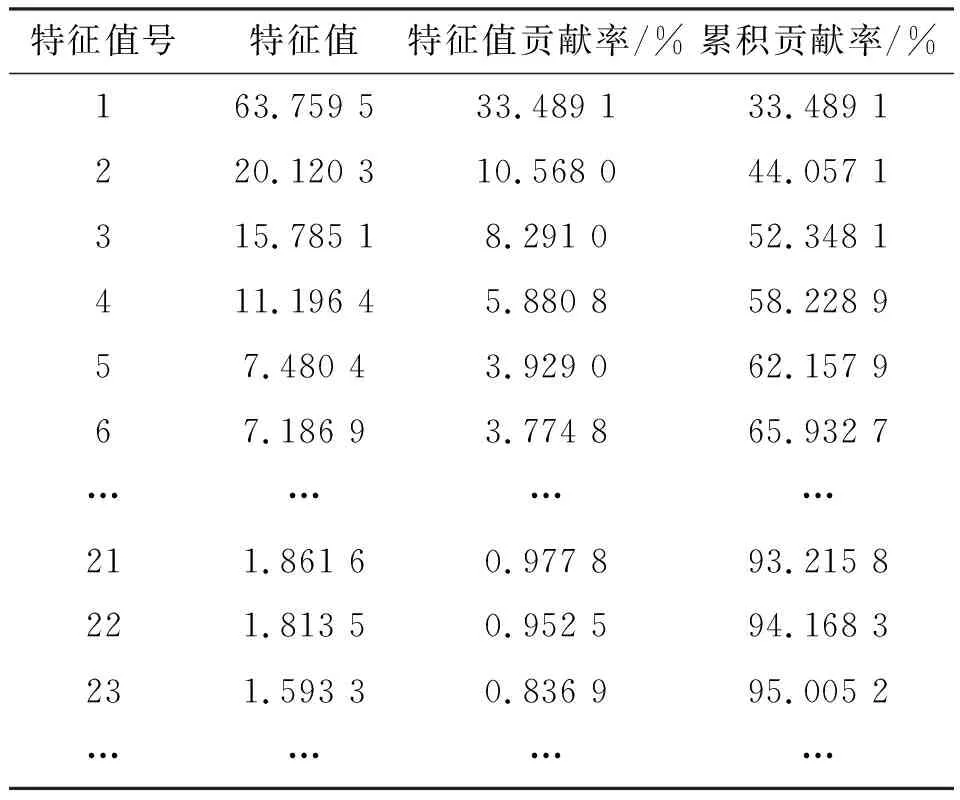
3.3 TEP故障診斷
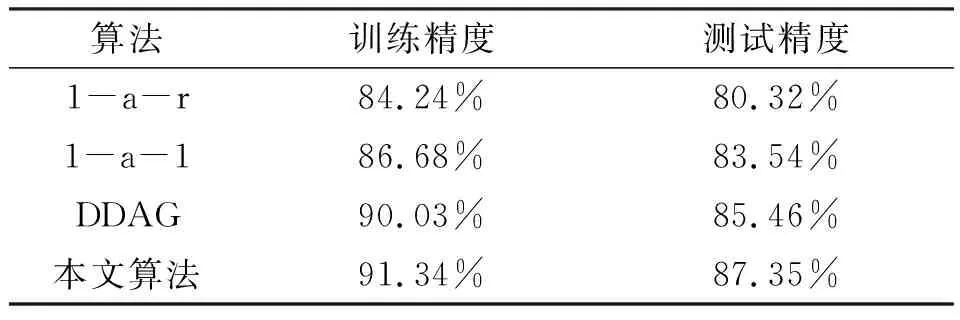
4 結論
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
