基于隨機森林的北票市水質(zhì)評價模型及應用
2018-07-05 09:09:42董艷玲
水科學與工程技術(shù) 2018年3期
董艷玲
(遼寧省北票市地質(zhì)打井隊,遼寧 北票 122100)
傳統(tǒng)的水質(zhì)評價將水質(zhì)指標視作水質(zhì)的單一影響因子,并據(jù)此建立多元綜合評價線性方程,雖然該方案操作簡易、可移植性強,然而未能確定水質(zhì)指標與水體質(zhì)量之間非線性關(guān)系,受共線性或數(shù)據(jù)噪聲影響敏感。隨著機器學習算法的廣泛應用,其在水質(zhì)評價研究中取得良好效果,有學者采用BP、RBF、SVM等算法建立了水體質(zhì)量自動評價模型。隨機森林算法集合了多個弱的分類器,其隨機自助抽取數(shù)據(jù)集實現(xiàn)自上而下遍歷樹形生長從而分割至純樣本,有效避免維數(shù)災難和過擬合,在各類數(shù)據(jù)挖掘問題中表現(xiàn)良好。鑒于此,本文以北票市為研究區(qū),闡釋了基于隨機森林算法的水質(zhì)評價模型建模過程與應用,以期為區(qū)域水質(zhì)綜合評價提供參考依據(jù)。
1 北票市概況
北票市位于我國東北渤海外流區(qū)、大凌河中游,區(qū)域面積4469km2。區(qū)域自東北向西南傾斜,高程介于0~1074m,以丘陵為主,平原盆地狹小而破碎。由于位居歐亞大陸東岸中高緯度,形成溫帶季風性氣候,氣候溫涼、雨熱同期,多年平均氣溫8.6℃,年平均降水量509mm,無霜期153d。生產(chǎn)生活用水以河水為主,地表水資源總量為17343萬m3,地下水資源量達16090萬m3。
2 研究方法
以北票市水源地為研究區(qū),結(jié)合區(qū)域水文情勢、水源地分布特征,布設(shè)了36個水樣,于2017年10月天氣穩(wěn)定時采集水體標本,并將樣品封裝后送至實驗室化驗分析。
測定的指標分別有pH值,總硬度,NO-3,NH+4,SO24-,Na+,Cl-等,依次來反映區(qū)域水體質(zhì)量。測定方法安裝SL219—2003《水環(huán)境檢測規(guī)范》執(zhí)行。
2.1 隨機森林原理
隨機森林(RandomForest,RF)是由N棵分類回歸樹{p(x,Θn),k=1,2,…,N}集成而形成的組合器算法。其基于隨機子空間(random subspace) 理 論 和 自 助 聚 集(Bootstrap aggregating) 法對隨機向量(X,Y){Θn,k=1,2,…,N}進行隨機選取并進行樹形生長成為決策樹,設(shè)X,Y分別為獨立隨機向量(X,Y)中的隨機子集中的輸入、輸出向量,對于預測樣本的輸出p(h)存在泛化誤差:
隨機森林輸出結(jié)果是基于對N棵回歸樹{p(Θ,Xn),k=1,2,…,N}取均值得到,當k→∞時,則有:
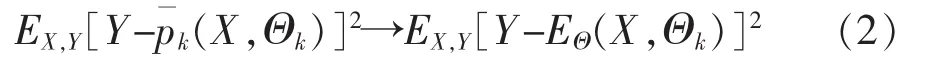
其泛化誤差(RE)為:
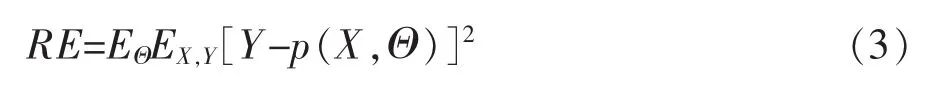
對于所有單棵樹平均泛化誤差為:

式中為殘差,且單棵樹Θ之間相對獨立。
待其構(gòu)成決策樹后節(jié)點的屬性變量值由隨機選中幾個屬性子集中產(chǎn)生。對于待測試的樣本,隨機森林通過自助聚集(Bootstrap aggregating)讓每棵樹進行投票,票數(shù)最高類別即為輸出結(jié)果,即:
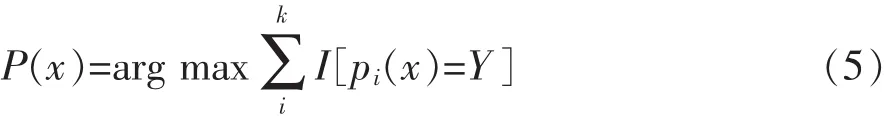
式中 P(x)為隨機森林組合模型結(jié)果;pi為單棵樹分類模型;I為指示函數(shù)。該算法核心是構(gòu)建回歸決策樹組合模型,單樹由根節(jié)點遍歷向下分裂,使其自由生長而不剪枝處理,N棵樹集成即為隨機森林[1-2]。
2.2 基于隨機森林的水質(zhì)評價方法
2.2.1 水質(zhì)評價標準
水質(zhì)評價分級標準是進行水質(zhì)評價的依據(jù),該標準需要具有公開性、統(tǒng)一性,以及反映水體質(zhì)量漸進變化。參照相關(guān)學者的研究經(jīng)驗,以《水環(huán)境質(zhì)量標準》為依據(jù),選取相應指標水質(zhì)上下限值,如表1。采用隨機內(nèi)插法于每一水質(zhì)等級區(qū)間內(nèi)生成200組樣本數(shù)據(jù),5個水質(zhì)等級共計有1000組樣本數(shù)據(jù)。隨機選取其中的750組作為訓練樣本,另外250組為測試樣本, 分布以數(shù)字1,2,3,4,5表示水質(zhì)等級I,II,III,IV,V。以水質(zhì)指標數(shù)據(jù)為輸入變量,以水質(zhì)等級為輸出變量,對于預測輸出值,將其按照四舍五入法進行歸類。
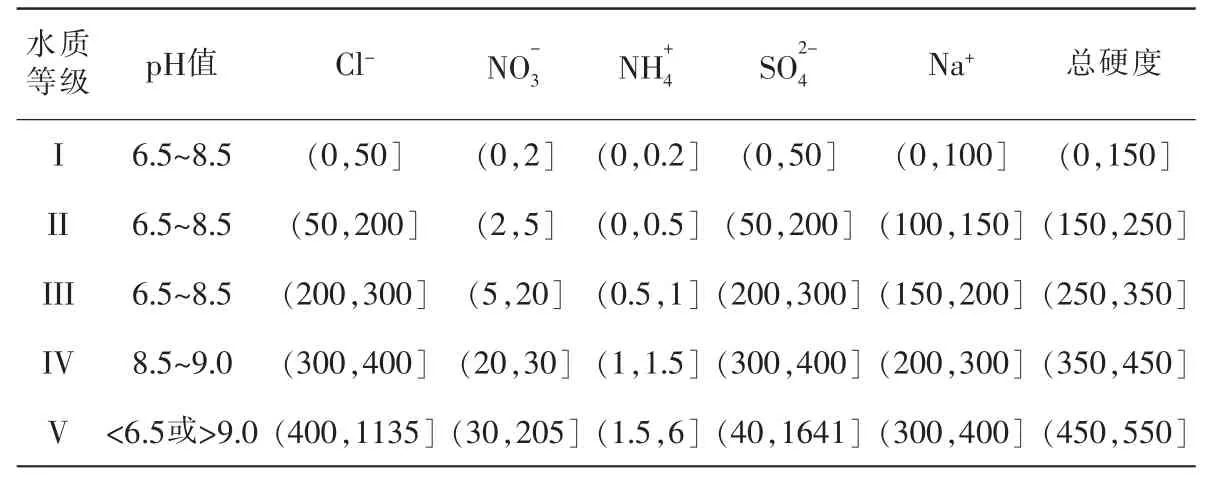
表1 水環(huán)境質(zhì)量評價標準
2.2.2 模型參數(shù)優(yōu)化
隨機森林算法中存在ntree和mtry兩個敏感參數(shù),前者為決策樹數(shù)量,影響著算法運行速度與分類效果;后者為分裂屬性集中屬性個數(shù),影響著結(jié)點分裂屬性賦值;為確立最優(yōu)模型,通常采用網(wǎng)格搜索法進行參數(shù)設(shè)置[2-3]。隨著參數(shù)變化,模型精度略有不同如圖1。模型精度隨著mtry變化,精度呈U型趨勢,其在mtry=3時,OOB達到最小,為0.0298,表明mtry最優(yōu)參數(shù)為3。隨著ntree增加,error總體呈減小趨勢,當ntree大于500時,error較小而穩(wěn)定,綜合考慮誤差變化趨勢,將其設(shè)置為600。
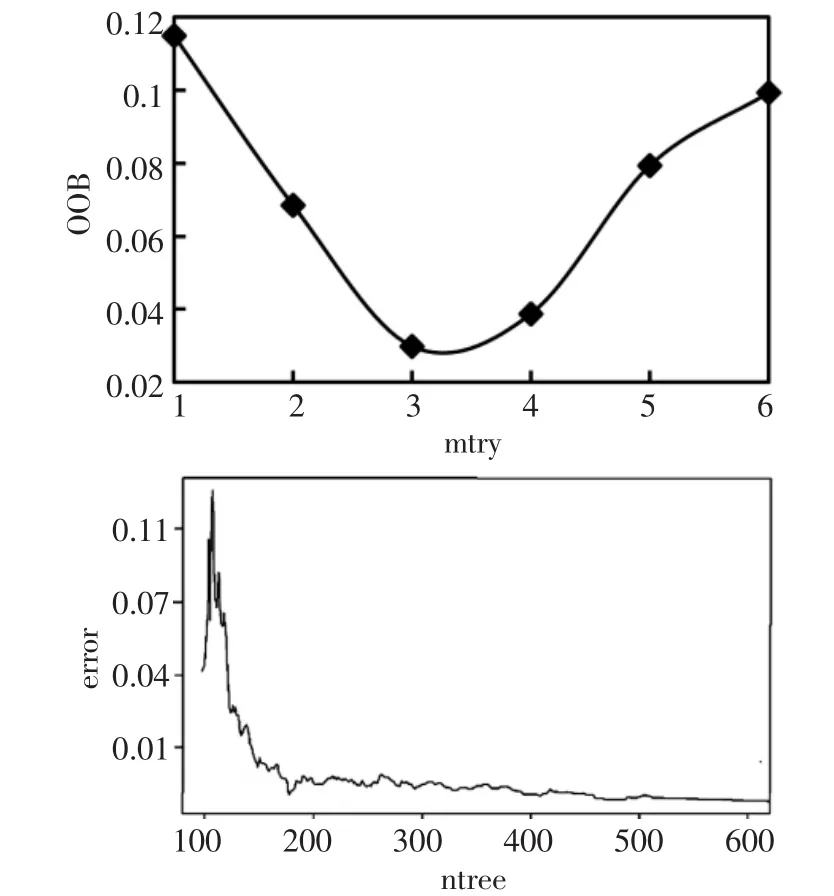
圖1 水質(zhì)評價模型參數(shù)設(shè)置
2.2.3 OOB重要性
隨機森林建模過程中能夠排除變量間共線性、數(shù)據(jù)噪聲影響,從而識別變量的重要性,依據(jù)其重要性分值大小,可以判定水質(zhì)評價模型中的各指標因子的影響。隨機森林算法中OOB是變量重要性度量方法之一,在單棵樹中Gini系數(shù)為節(jié)點分裂過程中各節(jié)點的樣本純度,其公式[4-5]:
OOB=2p(1-p)
式中 p為分配到樹節(jié)點k的正樣本的比例,節(jié)點負樣本比例為(1-p),OOB為系數(shù)值。在隨機森林中模型中,一個變量的重要性為用該特征變量進行分裂時,所有節(jié)點上從父節(jié)點到子節(jié)點的OOB值減少量的和(Mean Decrease Gini,MDG),其分值越高,表明該變量重要性越大。
2.3 數(shù)據(jù)處理
將測定的水體樣本數(shù)據(jù)按照3+δ方法進行篩選,移除特異值。在Excel2016中進行基本統(tǒng)計處理,統(tǒng)計36個樣本水質(zhì)的極值、平均值和標準差。隨機森林建模和水質(zhì)評價在Rstudio中完成,水質(zhì)評價空間分布結(jié)果在GIS平臺Arcgis10.3中進行。
3 結(jié)果與分析
3.1 北票市水源地水質(zhì)統(tǒng)計特征
表2為北票市36個水體樣點水質(zhì)指標統(tǒng)計特征。
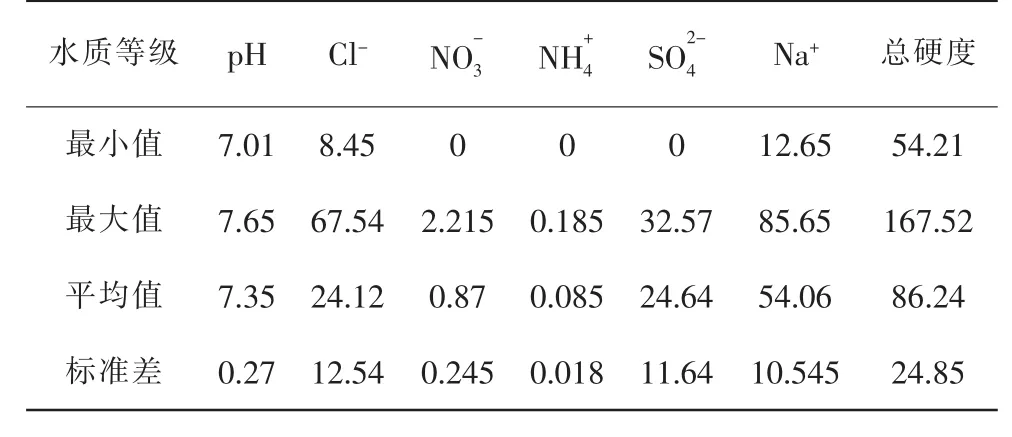
表2 北票市水源地水質(zhì)特征 單位:mg/L
由表2可知,本區(qū)水體pH值屬于中性,介于7.01~7.65之間,達到I類水質(zhì)要求。Cl-含量大部分屬于I類,部分為II類, 超標率為4.21%;,,Na+屬于I,II類,超標率為6.75%,2.38%,3.17%,但總體達到I類水質(zhì)要求。NO-3含量在0~2.215mg/L之間,滿足I類水質(zhì)標準。研究區(qū)水體總硬度較小,為54.21~167.52mg/L,平均值為86.24mg/L。水體中Cl-含量為24.12mg/L,NO-3為0.87mg/L,僅為0.085mg/L,和Na+依次為24.64,54.06mg/L,分別低于區(qū)域水環(huán)境背景值。
3.2 北票市水源地水質(zhì)綜合評價
應用前述隨機森林模型對研究區(qū)36個水質(zhì)樣點進行綜合評價,得到評價結(jié)果如圖2。
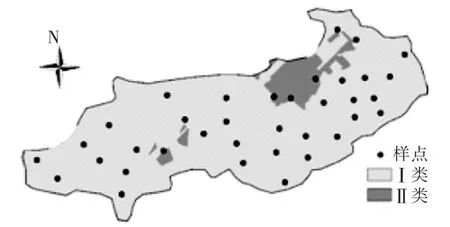
圖2 北票市水源地水質(zhì)空間分布
由圖2可知,36個樣點中5個樣點屬于II類水質(zhì),占樣點總數(shù)的13.89%,有31個樣點屬于I類水質(zhì),占樣點總數(shù)的86.11%。I類水質(zhì)呈片狀分布,分布范圍較廣,表明北票市水源地整體水質(zhì)較好。這是由于這些水源地位于區(qū)域河流中上游,源地原生態(tài)環(huán)境良好、人為活動較弱,除了受自然環(huán)境過程影響外,幾乎為遭受破壞。II類水質(zhì)呈斑點狀離散分布,主要由于部分樣點水質(zhì)指標略有超標,雖然II類水質(zhì)樣點較少,但是作為重要水源地,仍然應當加強水源防護。
3.3 水質(zhì)影響因素
隨機森林算法通過自助隨機抽樣規(guī)避了多維變量間線性干擾,其對各因子重要性的識別是無偏的。應用隨機森林OOB對水質(zhì)評價模型中各項指標因子重要性分值進行估計,水資源承載力對各指標的MDG重要性分值如圖3。
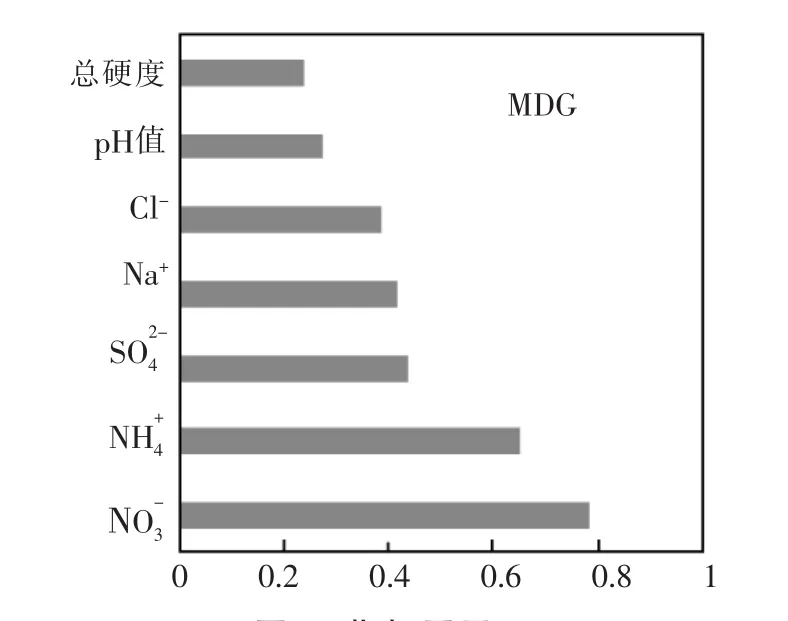
圖3 指標因子
由圖3可知,NO-3的MDG值最大,為0.784,表明其是北票市水源地水質(zhì)的關(guān)鍵影響因子;NH+4的MDG值次之,為0.651,其對水質(zhì)具有重要影響;SO24-,Na+,Cl-的MDG介于0.438~0.321之間,對水資源承載力有較大影響;而pH值和總硬度的MDG值較小,僅為0.274,0.241,其對水質(zhì)的影響較低。
3.4 算法對比
對于算法模型精度的衡量,可采用決定系數(shù)(R2)、平均絕對誤差(MSE)表示,一般認為R2接近于1,MSE接近于0時,表明算法擬合度高,模型效果較好,鑒于此計算了訓練樣本和測試樣本的決定系數(shù)與MSE,并以BP和SVM算法為對比,結(jié)果如表3。
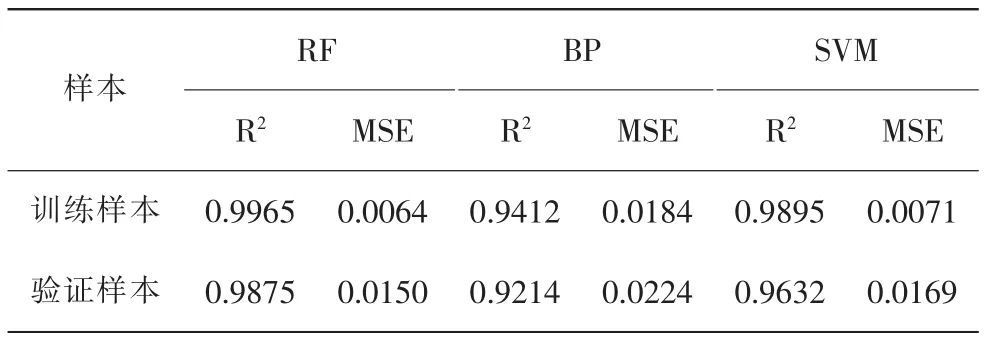
表3 隨機森林算法擬合結(jié)果
就RF算法來看,訓練樣本的R2,為0.9965,MSE值均較小,檢測樣本R2為0.9875,MSE為0.0150,表明該算法精度可靠,可用于對目標樣本的預測。就BP算法來看,訓練樣本的R2,為0.9412,MSE值為0.0184,檢測樣本R2為0.9214,MSE為0.0224;SVM算法顯示訓練樣本的R2為0.9895,MSE為0.0071, 檢測樣本R2為0.9632,MSE為0.0169。訓練模型存在一定誤差,將其代入檢測樣本進行測試時,由于誤差傳遞而精度降低,故而檢測樣本的精度略小于訓練樣本。綜合分析,基于隨機森林算法的水質(zhì)評價模型精度由于BP和SVM算法,表明隨機森林算法在水質(zhì)評價中具有一定應用性。
4 結(jié)語
(1)運用隨機森林原理和水質(zhì)評價標準,采用隨機數(shù)的方法生成樣本數(shù)據(jù),據(jù)此建立基于森林的水質(zhì)評價模型。訓練好的模型可移植于其他目標對象的評價,并具有智能化特性。
(2)隨機森林對于水質(zhì)因子的識別是無偏的,結(jié)果顯示,北票市水質(zhì)的關(guān)鍵影響因素是NO-3,今后應予以防治。
(3)研究區(qū)水質(zhì)屬于I類,NH+4,SO24-,Na+略有超標,但超標率較低。
(4)該方案的應用性在于模型簡潔、學習速率快,對維度較高和數(shù)據(jù)噪聲容忍度好,能夠排除內(nèi)部維度間相互影響,通過袋外誤差對象模型效果進行評估,相較于BP和SVM等傳統(tǒng)機器學習方法,具有一定優(yōu)勢。
[1]Boulesteix A L, Bender A, Lorenzo Bermejo J, et al.Random forest Gini importance favours SNPs with large minor allele frequency: impact, sources and recommendations[J].Briefings in Bioinformatics, 2012, 13(3):292.
[2]Wolfslehner B, Vacik H.Evaluating sustainable forest management strategies with the Analytic Network Process in a Pressure-State-Response framework [J].Journal of Environmental Management, 2008, 88(1):1-10.
[3]徐元鳳.ISO發(fā)布關(guān)于水安全的國際專題組協(xié)議[J].中國標準化, 2008(6):78-78.
[4]Sabatia C O, Burkhart H E.Predicting site index of plantation loblolly pine from biophysical variables[J].Forest Ecology&Management, 2014, 326:142-156.
[5]吳敏,溫小虎,馮起,等.基于隨機森林模型干旱綠洲張掖盆地地下水水質(zhì)評價[J].中國沙漠,2018,38(3):1-7.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
環(huán)境(2023年5期)2023-06-30 01:20:01
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
當代水產(chǎn)(2019年1期)2019-05-16 02:42:04
當代水產(chǎn)(2019年3期)2019-05-14 05:42:48
電子制作(2018年14期)2018-08-21 01:38:16
光學精密工程(2016年6期)2016-11-07 09:07:19
水利規(guī)劃與設(shè)計(2016年7期)2016-02-28 15:06:27
核科學與工程(2015年4期)2015-09-26 11:59:03
