基于遷移學習的多標簽圖像標注
2018-07-23 05:30:34秦瑩華李菲菲
電子科技
2018年8期
秦瑩華,李菲菲,陳 虬
(上海理工大學 光電信息與計算機工程學院,上海 200093)
近年來,隨著互聯網的快速發展和移動設備的不斷普及,海量的圖像數據每天由各類數碼產品制作,并快速在網絡上傳播。如何有效管理和檢索這些數據成為一項亟需解決的問題。
自動圖像標注是圖像檢索領域一項基本和富有挑戰性的任務。它利用已標注圖像集或其他可獲得的信息自動學習語義概念空間與視覺特征空間的關系模型,并用此模型標注未知語義的圖像,即它試圖在圖像的高層語義信息和底層特征之間建立一種映射關系,因此在一定程度上可以解決“語義鴻溝”問題。自動圖像標注本質上是一個多標簽學習問題,不同于單標簽圖像分類。圖像分類中每張圖像只含有一個標簽,這與現實世界中事物不符。
過去很多方法致力于人工提取圖像視覺特征來改善圖像標注性能[1-2]。卷積神經網絡在2012年大規模視覺識別挑戰中取得了突破性成果[3],然而該方法僅考慮單標簽分類。為了更自然地描述圖像,采用卷積神經網絡處理多標簽圖像就尤為重要。考慮到卷積神經網絡需要大量的訓練圖像和收集大規模有標簽數據集的困難,采用遷移學習的方法從ImageNet[4]分類任務中遷移已經訓練好的中層參數到其他視覺識別任務中,例如Caltech256圖像分類[5],場景識別[6]和Pascal VOC對象和場景分類任務[7]。
1 模型結構與算法
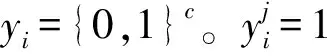
1.1 模型結構
文獻[3]的CNNs結構包含超過六千萬個參數,直接從幾千張圖像中學習這些參數是很困難的。……
登錄APP查看全文
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
數學物理學報(2020年2期)2020-06-02 11:29:24
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
