基于映射分組的改進型碰撞跟蹤樹算法
2018-07-25 12:09:54劉本超楊恒新
計算機技術與發展 2018年7期
關鍵詞:信息
劉本超,楊恒新,張 昀
(南京郵電大學 電子科學與工程學院,江蘇 南京 210003)
0 引 言
射頻識別(RFID)是一種以無線電技術為基礎,以對目標物體的自動識別為目的非接觸式識別技術,主要由閱讀器、標簽和中央信息處理系統組成[1]。識別距離較遠的超高頻射頻識別是利用空間電磁反向散射耦合實現無線雙向數據傳輸,從而實現對目標的自動識別[2]。標簽與閱讀器進行通信時主要有兩種形式的碰撞,分別是標簽碰撞和閱讀器碰撞。閱讀器碰撞可通過閱讀器間建立的工作協調機制解決沖突問題[3]。由于受成本制約,標簽的功能單一、功率低,標簽碰撞問題成為制約RFID系統的關鍵因素。
為解決標簽碰撞問題,研究人員提出了許多有效的防碰撞算法。目前,標簽防碰撞算法大體可分為兩類:確定性防碰撞算法和隨機性防碰撞算法。
隨機性算法主要是基于ALOHA的算法,這種算法設備簡單,花費低,識別速度快。基于ALOHA的算法,包括純ALOHA算法、時隙ALOHA算法、幀時隙ALOHA算法、動態幀時隙ALOHA算法以及基于ALOHA的各種改進算法[4-5]。但由于ALOHA類算法標簽隨機選擇時隙,因而造成識別的不確定性,即可能出現大量標簽“扎堆”碰撞或者出現大量空閑時隙的情況,即“標簽饑餓”問題[6]。
確定性算法主要是基于樹的算法,它采用了分離的思想,將碰撞的標簽連續分為不同的子集,直至成功識別所有標簽,所以它避免了“標簽饑餓”問題,識別效率高[7]。最基本的基于樹的防碰撞算法是二進制防碰撞算法,但其吞吐率較低。查詢樹(QT)算法[8]是一種無記憶防碰撞算法,極大地促進了樹型防碰撞算法的發展。人們在查詢樹算法的基礎上又提出了許多改進算法,例如基于前綴檢測的算法[9],提高了RFID系統工作效率。碰撞跟蹤樹(collision tracking tree,CTT)[10]算法的核心思想是在查詢樹算法的基礎上通過曼徹斯特編碼(Manchester encoding)方式來檢測具體的碰撞位,通過只查詢非碰撞位來提高查詢速度。其改進算法[11]在檢測碰撞位的基礎上引入多位查詢前綴,降低了查詢深度。
文中在碰撞跟蹤樹算法的基礎上,通過曼徹斯特編碼鎖定碰撞位,將碰撞位每3比特為一組進行分組,并進行重新編碼,引入映射碼。標簽端發送第i組映射碼,閱讀器根據收到的映射碼有效地識別標簽ID,設置合理的查詢前綴。
1 碰撞跟蹤樹算法
設閱讀器端有一堆棧Q,閱讀器發送查詢指令,查詢范圍內所有標簽;標簽返回自身唯一ID信息,閱讀器根據曼徹斯特編碼的特點得到碰撞信息即具體碰撞位。設標簽ID長度為k,首位碰撞位為第i位,閱讀器首先將第i位之前的信息r1…ri-1添加0和1組成r1…ri-10和r1…ri-11前綴壓入堆棧,閱讀器再次發送查詢命令,所有匹配查詢序列的標簽將返回長度為k-r的標簽剩余ID。閱讀器收到信息后再次檢測碰撞位,將碰撞位之前的ID添加0和1再次作為查詢前綴壓入堆棧,直到沒有標簽未被識別。當堆棧為空時,閱讀器可判定所有標簽已被成功識別,結束查詢。因為CTT算法是在碰撞位基礎上進行的查詢,所以避免了空時隙,極大地提高了識別速率。
2 基于映射分組的改進型碰撞跟蹤樹算法
CTT算法雖然能去除空閑時隙,但由于每次查詢仍然采用二叉樹的形式,因此查詢次數仍然很多。文獻[12]提出了一種基于分組碼的改進型防碰撞算法(IABC算法),該算法令標簽ID每3比特為一組,以0和1的分布情況進行分類,得到四種類型的分組碼。由于分組碼01和001分別對應三種標簽識別碼,因此需要二次發送確定準確的標簽識別碼。因此,提出一種基于映射分組的改進型碰撞跟蹤樹算法(improved collision tracking tree algorithm based on mapping grouping,ICTTMG)。該算法可以建立標簽識別碼與映射碼的一一對應關系,因此可以準確地判定所需要的查詢前綴,避免了二次發送,提高了識別速率,又降低了系統通信量。
2.1 算法描述
ICTTMG算法主要分為兩個階段:鎖定碰撞位和映射識別。
(1)鎖定碰撞位。
算法首先利用曼徹斯特編碼鎖定碰撞位。曼徹斯特編碼采用電平的跳變表示信息,從高電平跳變到低電平表示“1”,從低電平跳變到高電平表示“0”,采用該編碼方案的優點是當有碰撞發生時,閱讀器接收到的信號全為高電平,可確定此時發生碰撞。
(2)映射識別。
首先將標簽碰撞ID按每3比特為一組分為k組,因為CTT算法可得到具體碰撞位數,所以我們可確定最后一組的具體位數,不足3比特的按照最高位添加0處理。閱讀器發送查詢指令,標簽返回第i組ID的映射碼,映射規則如表1所示。

表1 映射碼
為了減少通信量同時能方便地識別映射碼,閱讀器端設有5個堆棧S1、S2、S3、S4、S5。閱讀器根據第i組映射碼位數的不同壓入不同的查詢堆棧:映射碼位數為1、2、3、4位的響應信息分別壓入堆棧S1、S2、S3、S4。例如:ID為001和101對應的映射碼分別為01和10,將其存入堆棧S2,則根據曼徹斯特編碼,得到信息xx,x表示無法確定0和1,那么可以很容易地確定出標簽返回的信息是10和01,即存在ID為001和101的標簽,并將10和01前綴壓入堆棧S5,同時記錄分組編號i。每個標簽都附帶一個計數器和存儲器RC,用來記錄映射碼信息。
首先將標簽狀態分為激活態、等待態和睡眠態。激活態:標簽處于激活態時,能夠接收閱讀器發送查詢指令并與之通信。等待態:標簽處于等待態時,暫時無法與閱讀器通信,直到被激活。睡眠態:標簽處于睡眠態,表示標簽已經被成功識別,并且不再響應閱讀器。
為了更好地描述該算法,引入下列三條指令:
(1)Query_all:閱讀器發送該命令,查詢范圍內所有標簽,標簽被激活并發送自身ID;
(2)Lock(TID):標簽收到該命令后鎖定碰撞位,轉換成映射碼并存儲到寄存器RC中;
(3)Query(prefix,i):閱讀器發送該命令,prefix為查詢前綴序列,i表示分組編號。處于激活態的標簽需將自己臨時ID號中第i組映射碼與prefix進行比較,若匹配,響應閱讀器;反之,標簽轉為等待態。
2.2 算法具體步驟
以下為ICTTMG算法的具體執行過程:
(1)初始化堆棧,閱讀器發送Query_all指令,所有標簽響應并返回ID信息。
(2)閱讀器記錄能正確識別的比特位,同時記錄發生碰撞的位置。假設有四個標簽,其ID分別為:11010,10101,10001,11000,那么閱讀器收到的信息為:1xxxx,x表示發生碰撞。
(3)閱讀器發送Lock(TID)命令,其中碰撞位用1表示,非碰撞位用0表示,標簽將收到的信息與自己的ID進行匹配,得到碰撞位信息,根據映射關系表,每3比特為一組,進行映射操作,將映射碼存入寄存器RC中,初始化標簽計數器i為1。
(4)閱讀器發送Query(prefix,i)指令,標簽被激活并響應閱讀器,標簽發送第i組映射碼加上剩余ID信息給閱讀器,同時標簽計數器i值加1。
(5)閱讀器將不同位數的響應信息分別壓入堆棧S1、S2、S3、S4,進行譯碼后得到查詢前綴,并將前綴壓入堆棧S5中,同時記錄分組編號i。
(6)標簽接收到前綴prefix和分組編號i,計數器值等于i的標簽將前綴與自身映射碼做比對,具有相同前綴的標簽激活并響應閱讀器。若閱讀器未檢測到碰撞,則直接識別該標簽,讀取數據并進行滅活操作,堆棧S5彈出下一組前綴,返回步驟4;若檢測到碰撞,則令i=i+1,跳轉至步驟4。
(7)判斷堆棧S5是否為空或者全部標簽被識別,結束識別過程。
2.3 算法實例
假設有8個待識別標簽分別為:A(10110100)、B(10010110)、C(11010001)、D(11000100)、E(11000000)、F(10000110)、G(10000101)、H(11010110)。閱讀器根據標簽返回的信息,確定碰撞位,可得1xxx0xxx,即有6個碰撞位,標簽根據閱讀器發送的碰撞跟蹤信息,將自己的碰撞位取出,根據上面的編碼規則進行編碼,如表2所示。
算法具體查詢過程如表3所示。

表2 標簽ID映射
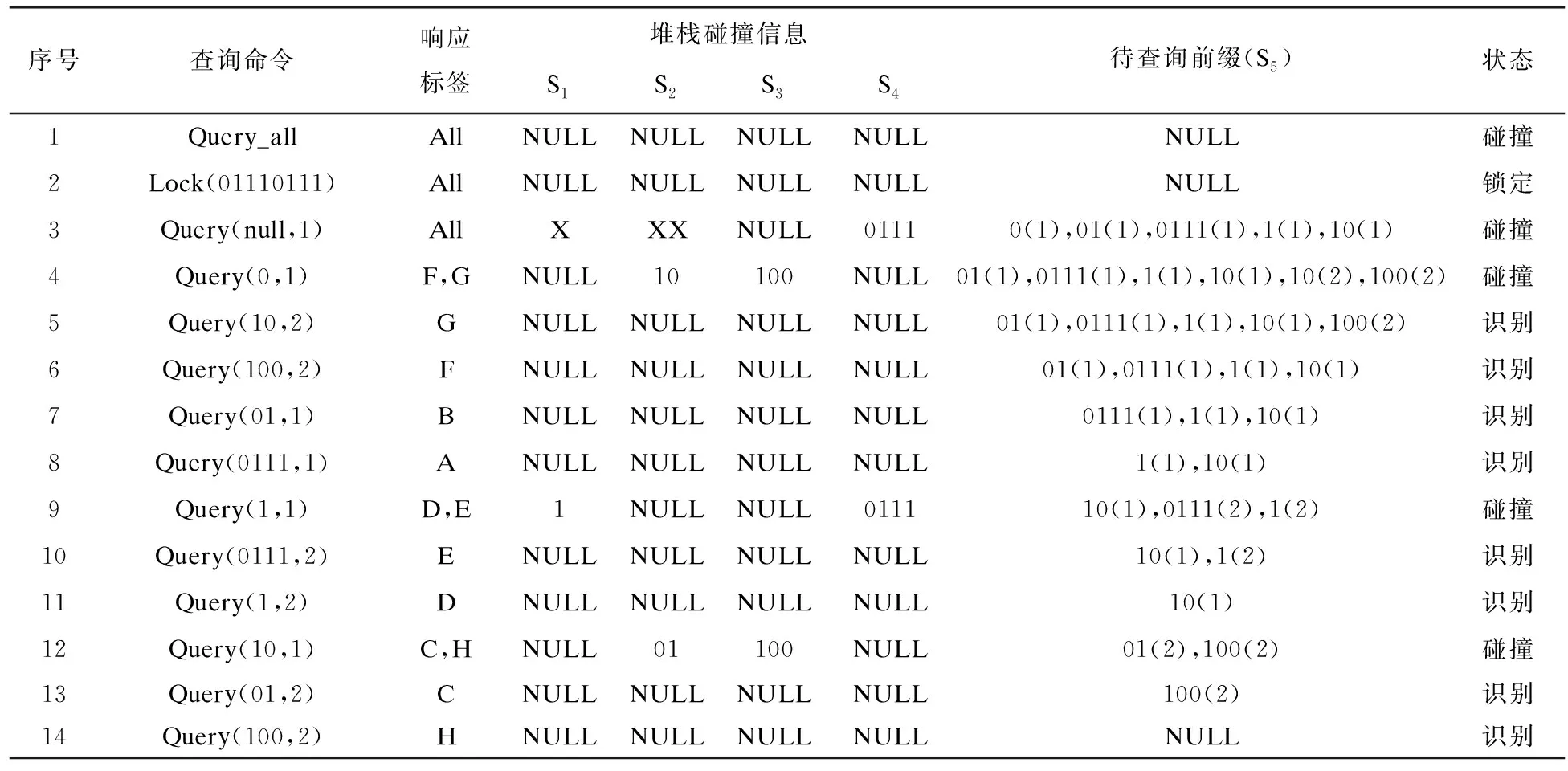
表3 ICTTMG算法查詢過程
3 算法仿真驗證
3.1 時間復雜度
由文獻[13]可知,對于八叉樹算法識別n個標簽所需要的總時隙數為:
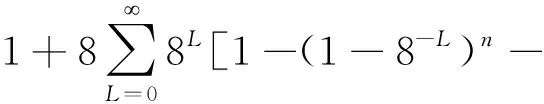
n8-L(1-8-L)n-1]
(1)
其中,碰撞時隙數、空閑時隙數和識別效率分別如下:
(2)
(3)
(4)
對于提出的算法,時間復雜度主要由標簽數量和非碰撞位數決定。設標簽數量為n,非碰撞位數為m(取50),則總時隙數TICTTMG和吞吐率E經MATLAB[14]仿真驗證的結果如圖1和圖2所示。
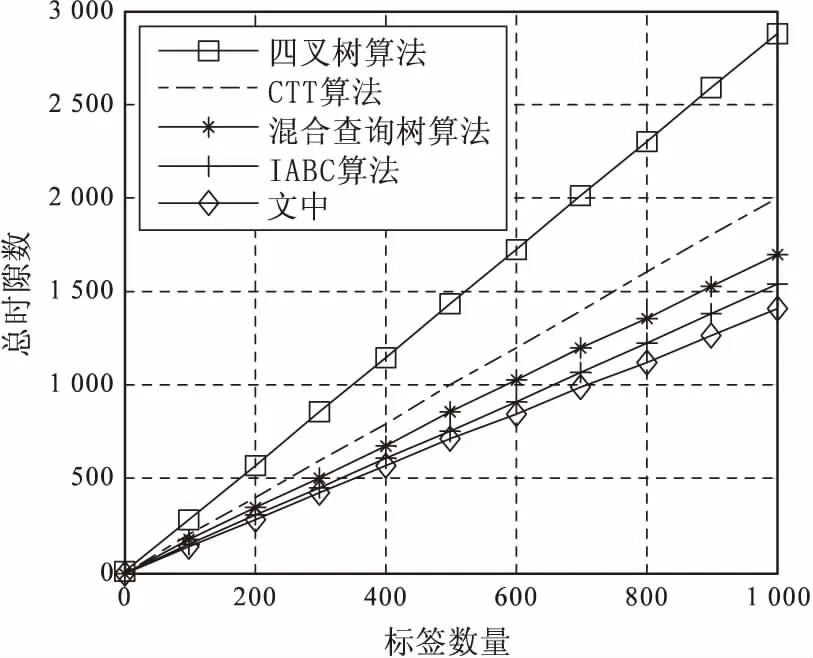
圖1 五種算法總時隙數比較
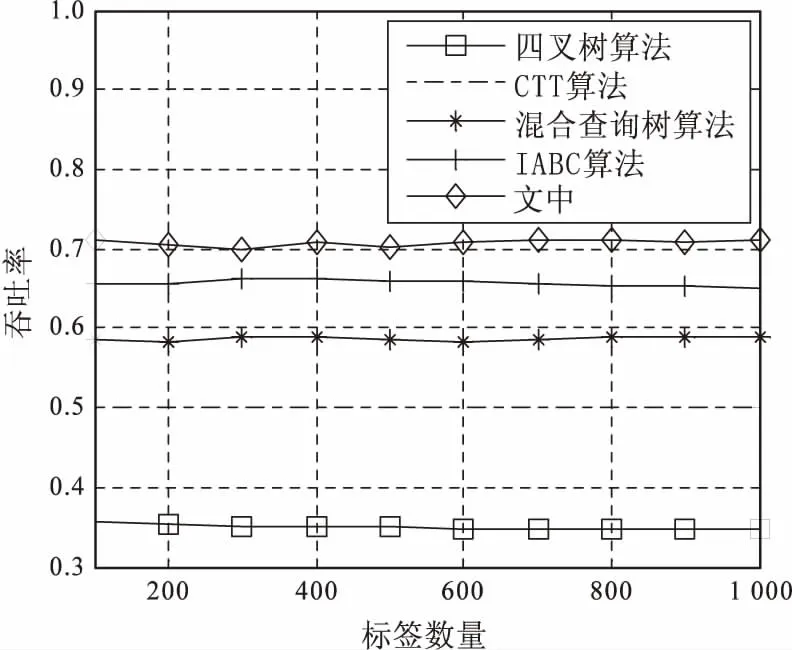
圖2 五種算法吞吐率比較
由圖1可以看出,提出的算法需要的時隙數最少,識別1 000個標簽只需要1 416個時隙,比基本CTT算法少用了30%的時隙,比IABC算法也少用了約5%的時隙。由圖2可以看出,提出的算法具有最高的吞吐率,比基本CTT算法提高了約22%,明顯高于其他算法[15-16]。
3.2 通信復雜度
文中算法的通信復雜度涉及兩個階段。
(1)鎖定碰撞位。
閱讀器需要發送鎖定命令字Lock,標簽返回ID信息,ID長度為k,因此總通信量為:
Tra1=2k
(5)
(2)前綴查詢。
設標簽非碰撞位為m,則碰撞ID長度為k-m,根據表1的編碼方案,標簽每3比特信息經再編碼后平均長度為2.5比特,比原來減少0.5比特,因此降低了系統通信復雜度。閱讀器發送查詢前綴和分組編號,而標簽發送一組映射碼加臨時ID的剩余位比特信息,其數據位長度取決于標簽在八叉樹第幾層成功識別。假設標簽在L層被識別的概率為Ps(L),則
(6)
標簽發送的比特位信息平均期望值為:
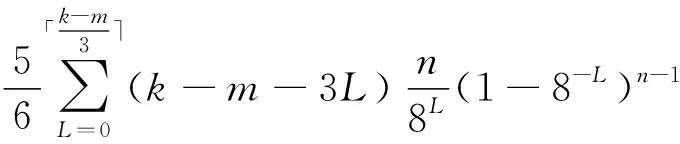
(7)
因此,第二階段標簽和閱讀器總通信量為:
Tra2=2.5*TICTTMG+CT*TICTTMG
(8)
總通信量為:
Tra=Tra1+Tra2
(9)
根據EPC C1G2協議[17]的規定,標簽ID長度k取96位,其中唯一標識序列號長度為36位,非碰撞位數m取值50,據此計算通信量。對各種算法的通信量進行仿真驗證,如圖3所示。
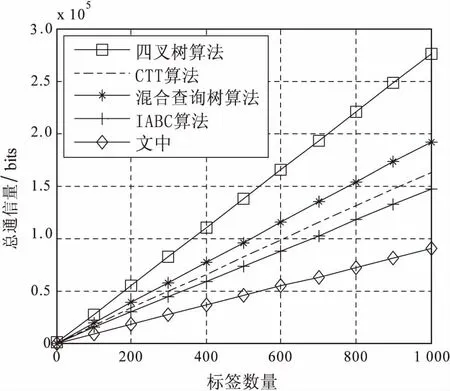
圖3 五種算法通信量比較
因為提出的改進算法使用了合理的映射編碼方案,每3比特ID經編碼后平均長度變為2.5比特,而且每次查詢平均只需查詢2.5比特前綴,極大降低了系統的通信量。MATLAB仿真表明,該算法具有最低的通信復雜度,比CTT算法減少了約68%的通信量,隨著非碰撞位數m的增大,算法通信復雜度性能進一步提升。
4 結束語
在傳統CTT算法的基礎上,提出的ICTTMG算法改變了傳統CTT算法每次只能識別一位比特的缺點,該算法結合映射識別碼,減少了整個識別過程中的查詢次數,利用一個查詢響應周期對識別碼中碰撞位進行鎖定,同時平均每次只需發送2.5比特查詢前綴,優化了閱讀器命令。仿真結果表明,算法在時間復雜度和通信復雜度方面都有明顯改善。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
