融合深度學(xué)習(xí)特征的漢維短語(yǔ)表過(guò)濾研究
2018-07-25 12:09:38朱順樂(lè)
計(jì)算機(jī)技術(shù)與發(fā)展 2018年7期
朱順樂(lè)
(浙江海洋大學(xué),浙江 舟山 316000)
1 概 述
隨著經(jīng)濟(jì)全球化的不斷深入,國(guó)家與國(guó)家之間、民族與民族之間交流時(shí)的語(yǔ)言障礙突顯,已成為經(jīng)濟(jì)發(fā)展、文化交流的不利因素。機(jī)器翻譯技術(shù)的發(fā)展為緩解這一障礙提供了契機(jī)。統(tǒng)計(jì)機(jī)器翻譯(statistical machine translation,SMT)是目前學(xué)術(shù)界研究的主流方法。它是非限定領(lǐng)域機(jī)器翻譯中性能較佳的一種方法。其基本思想,是通過(guò)對(duì)大量的平行語(yǔ)料進(jìn)行統(tǒng)計(jì)分析,構(gòu)建翻譯模型(translation model,TM),對(duì)目標(biāo)語(yǔ)言單語(yǔ)語(yǔ)料進(jìn)行統(tǒng)計(jì)建模,構(gòu)建語(yǔ)言模型(language model,LM),進(jìn)而使用上述模型對(duì)輸入源語(yǔ)言句子進(jìn)行翻譯。
統(tǒng)計(jì)機(jī)器翻譯模型又分為基于詞的翻譯模型、基于短語(yǔ)的翻譯模型以及基于句法的翻譯模型三類。其中,基于短語(yǔ)的翻譯模型既在翻譯過(guò)程中考慮到了局部上下文信息,又不需要句法標(biāo)注語(yǔ)料,并且能取得較好的翻譯效果,因而廣受學(xué)術(shù)界與工業(yè)界的青睞。
(1)
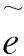
漢維翻譯模型訓(xùn)練架構(gòu)如圖1所示。
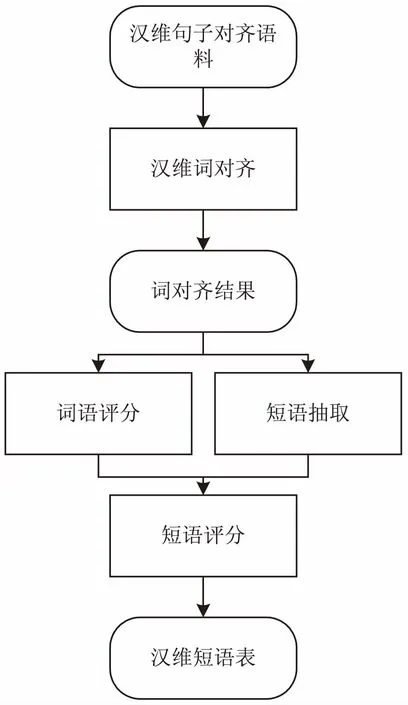
圖1 漢維翻譯模型訓(xùn)練架構(gòu)
作為基于短語(yǔ)機(jī)器翻譯模型框架的核心部分,翻譯模型提供短語(yǔ)表、調(diào)序規(guī)則表等重要知識(shí)。短語(yǔ)表中包含雙語(yǔ)短語(yǔ)的互譯信息,其質(zhì)量直接影響機(jī)器翻譯模型的性能。然而,以下兩個(gè)因素會(huì)對(duì)短語(yǔ)表的質(zhì)量以及后期解碼效率產(chǎn)生影響。(1)短語(yǔ)表抽取位于統(tǒng)計(jì)機(jī)器翻譯框架的中間環(huán)節(jié),前期的詞對(duì)齊階段產(chǎn)生的錯(cuò)誤會(huì)延續(xù)到短語(yǔ)表生成階段;(2)統(tǒng)計(jì)機(jī)器翻譯模型性能很大程度上依賴于雙語(yǔ)句子平行語(yǔ)料。目前,日益豐富的網(wǎng)絡(luò)資源使得大規(guī)模語(yǔ)言資源的獲取成為可能,然而大規(guī)模語(yǔ)料使得雙語(yǔ)短語(yǔ)表規(guī)模呈指數(shù)級(jí)增長(zhǎng),從而減緩了解碼速度。因此,對(duì)短語(yǔ)表中的噪音短語(yǔ)進(jìn)行過(guò)濾,增大了解碼階段解碼器檢索到更為準(zhǔn)確的翻譯片段的概率;非法短語(yǔ)對(duì)的過(guò)濾可以減小短語(yǔ)表的規(guī)模,一定程度上提升了解碼效率。
針對(duì)短語(yǔ)表過(guò)濾這一任務(wù),國(guó)內(nèi)外學(xué)者進(jìn)行了一些研究。Nishino等提出一種基于子模函數(shù)最大化的短語(yǔ)表過(guò)濾方法,采用貪心的啟發(fā)式算法策略實(shí)現(xiàn)[1];Wang等提出一種面向短語(yǔ)表過(guò)濾的相對(duì)熵模型,并用其衡量用小概率的翻譯事件推導(dǎo)出短語(yǔ)對(duì)表示翻譯事件的概率[2];Azadi等使用主題模型進(jìn)行短語(yǔ)表的剪枝[3];Zens等首先比較了多種短語(yǔ)表過(guò)濾方法,并提出了基于語(yǔ)音理論的短語(yǔ)表過(guò)濾框架[4];Torr提出了一種基于句法的短語(yǔ)表過(guò)濾模型,該模型依賴于句法分析的結(jié)果[5]。
針對(duì)漢維機(jī)器翻譯的相關(guān)研究開(kāi)展較晚,前期的研究主要集中在語(yǔ)言的分析[6-8]、語(yǔ)料庫(kù)建設(shè)[9]、命名實(shí)體識(shí)別[10-12]以及翻譯系統(tǒng)構(gòu)建[13-16]等方面。對(duì)于短語(yǔ)表的過(guò)濾及其相關(guān)工作的研究較少。
前期的研究工作并沒(méi)有考慮短語(yǔ)的上下文信息以及雙語(yǔ)的語(yǔ)義關(guān)系,即使有基于句法的模型,也要依賴于大規(guī)模的句法標(biāo)注語(yǔ)料。文中提出一種新穎的漢維短語(yǔ)表過(guò)濾方法,將短語(yǔ)表的過(guò)濾看作分類問(wèn)題:基于樸素貝葉斯(Na?ve Bayes,NB)模型,融合了短語(yǔ)對(duì)循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN)特征、上下文特征等深度學(xué)習(xí)特征,以及平均詞共現(xiàn)特征等淺層特征,獲得漢維短語(yǔ)對(duì)是否保留的概率值,并通過(guò)實(shí)驗(yàn)對(duì)其進(jìn)行驗(yàn)證。
2 短語(yǔ)表生成
基于短語(yǔ)翻譯模型中的短語(yǔ)表依賴于詞對(duì)齊階段產(chǎn)生的對(duì)齊文件以及漢維平行語(yǔ)料構(gòu)建。因此短語(yǔ)表的創(chuàng)建可分為兩個(gè)階段:詞對(duì)齊矩陣生成和短語(yǔ)表抽取。
2.1 詞對(duì)齊矩陣生成
統(tǒng)計(jì)機(jī)器翻譯中的詞對(duì)齊,是基于統(tǒng)計(jì)學(xué)習(xí)的相關(guān)算法,從大規(guī)模的雙語(yǔ)句子平行語(yǔ)料中自動(dòng)獲取詞語(yǔ)共現(xiàn)等信息的過(guò)程。使用較多的詞對(duì)齊算法包括IBM Model 1-5[16-17]以及基于(hidden Markov model,HMM)的詞對(duì)齊模型[18]。Och基于上述模型,設(shè)計(jì)開(kāi)發(fā)了廣泛使用的詞對(duì)齊開(kāi)源工具GIZA++[19]。詞對(duì)齊矩陣[20-21]即是根據(jù)詞對(duì)齊結(jié)果生成的,見(jiàn)圖2。
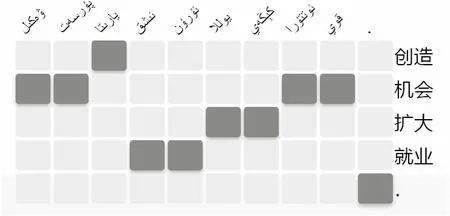
圖2 漢維機(jī)器翻譯詞對(duì)齊矩陣
2.2 短語(yǔ)抽取
漢維短語(yǔ)抽取是短語(yǔ)表創(chuàng)建的基礎(chǔ)。基于詞對(duì)齊矩陣獲取漢維雙語(yǔ)短語(yǔ)對(duì)的方法如下:若與矩形所在行范圍內(nèi)的漢語(yǔ)詞對(duì)齊的維吾爾語(yǔ)詞也在當(dāng)前子矩形內(nèi),提取對(duì)齊矩陣中所有以對(duì)齊點(diǎn)為頂點(diǎn)矩形區(qū)域所表示的漢維短語(yǔ)對(duì)。其核心思想,即是首先窮舉漢語(yǔ)句子中所有可能的短語(yǔ),根據(jù)詞對(duì)齊矩陣,檢索對(duì)應(yīng)維吾爾語(yǔ)句子中的短語(yǔ)。抽取的部分漢維短語(yǔ)表如圖3所示。
上述過(guò)程抽取到的只是候選短語(yǔ)。在添加至短語(yǔ)表之前,還應(yīng)對(duì)其進(jìn)行校驗(yàn)。校驗(yàn)遵循的原則有兩個(gè):
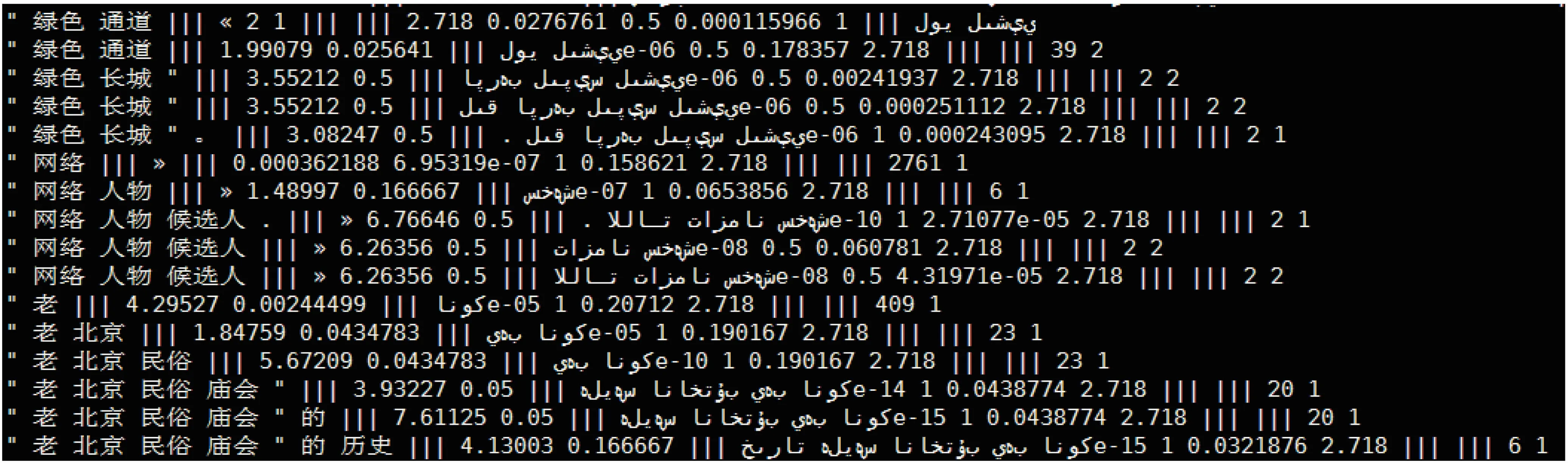
圖3 漢維短語(yǔ)表(局部)
(1)候選漢語(yǔ)端的單詞在漢語(yǔ)句子中的位置必須連續(xù);
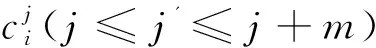
統(tǒng)計(jì)詞對(duì)齊模型基于大規(guī)模的平行語(yǔ)料。然而,由于平行語(yǔ)料規(guī)模的局限性以及漢語(yǔ)、維吾爾語(yǔ)的差異性,漢維詞對(duì)齊過(guò)程中會(huì)出現(xiàn)數(shù)據(jù)稀疏問(wèn)題,影響了詞對(duì)齊的準(zhǔn)確性,進(jìn)而導(dǎo)致漢維短語(yǔ)抽取過(guò)程中出現(xiàn)偏差,影響后續(xù)的翻譯模型訓(xùn)練以及機(jī)器翻譯系統(tǒng)的解碼效率。
3 特征描述
為了對(duì)漢維短語(yǔ)表進(jìn)行過(guò)濾,從雙語(yǔ)短語(yǔ)對(duì)循環(huán)神經(jīng)網(wǎng)絡(luò)特征(RNN)、上下文特征(BIT)以及短語(yǔ)對(duì)中平均詞共現(xiàn)次數(shù)(ACC)等特征出發(fā),分別構(gòu)建相應(yīng)的特征函數(shù)。
3.1 短語(yǔ)對(duì)循環(huán)神經(jīng)網(wǎng)絡(luò)特征
為了最大限度獲取漢維短語(yǔ)表中候選雙語(yǔ)短語(yǔ)的對(duì)應(yīng)關(guān)系,以便更好地對(duì)短語(yǔ)表進(jìn)行過(guò)濾,基于RNN[21-22]獲取維吾爾語(yǔ)和漢語(yǔ)短語(yǔ)之間的互譯概率。RNN的主要優(yōu)勢(shì)在于處理序列數(shù)據(jù)。與以往的模型不同,基于RNN處理序列預(yù)測(cè)問(wèn)題時(shí),該序列當(dāng)前的輸出與之前的輸出也有關(guān)系,即網(wǎng)絡(luò)會(huì)對(duì)前面的信息進(jìn)行記憶并應(yīng)用于當(dāng)前序列輸出的計(jì)算中;RNN網(wǎng)絡(luò)中,隱藏層之間的節(jié)點(diǎn)是有連接的,當(dāng)前隱藏層的輸入不僅包括輸入層的內(nèi)容,還包括上一時(shí)刻隱藏層的輸出。
根據(jù)短語(yǔ)表過(guò)濾這一應(yīng)用,文中使用RNN的編碼器-解碼器架構(gòu)。基于該網(wǎng)絡(luò)結(jié)構(gòu)可以同步獲得短語(yǔ)表中漢維短語(yǔ)對(duì)的對(duì)齊及翻譯概率值,將其作為該短語(yǔ)是否保留的重要特征之一。
將雙語(yǔ)短語(yǔ)之間的對(duì)應(yīng)概率進(jìn)行轉(zhuǎn)換,用以預(yù)測(cè)漢維短語(yǔ)詞之間的對(duì)應(yīng)關(guān)系。使用RNN方法預(yù)測(cè)i時(shí)刻的詞對(duì)應(yīng)概率可形式化地表示如下:
(2)
其中,si表示RNN模型時(shí)刻t的隱藏狀態(tài);上下文向量ci依賴于輸入短語(yǔ)映射的標(biāo)記序列,ci可被定義為對(duì)標(biāo)記hi的加權(quán)求和,標(biāo)記的權(quán)值計(jì)算如下:
(3)
3.2 短語(yǔ)上下文特征
統(tǒng)計(jì)機(jī)器翻譯模型訓(xùn)練過(guò)程中存在較為嚴(yán)重的數(shù)據(jù)稀疏問(wèn)題。造成數(shù)據(jù)稀疏的原因是復(fù)雜的,即使使用超大規(guī)模的語(yǔ)料庫(kù)也不能獲取每個(gè)詞組成的所有字符串。訓(xùn)練過(guò)程中的數(shù)據(jù)稀疏問(wèn)題也會(huì)對(duì)短語(yǔ)表的過(guò)濾產(chǎn)生影響。針對(duì)該問(wèn)題,提出一種緩解數(shù)據(jù)稀疏的策略,即基于Skip-gram[23-24]獲取雙語(yǔ)短語(yǔ)中的上下文特征,計(jì)算相應(yīng)的概率值,并將其作為短語(yǔ)表過(guò)濾模型的特征之一。
Skip-gram是n-gram的泛化。與n-gram類似,也是使用n-gram的方式對(duì)語(yǔ)言建模,但允許n-gram語(yǔ)法中跳過(guò)若干詞。Skip-gram可定義如下:
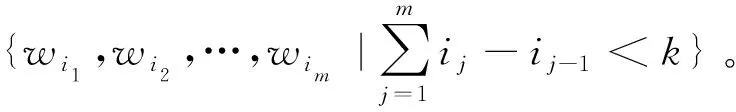
文中的當(dāng)前詞設(shè)定為詞對(duì)齊階段準(zhǔn)確率較高的詞,根據(jù)該漢維詞對(duì),預(yù)測(cè)其上下文信息,進(jìn)而獲得雙語(yǔ)上下文信息中存在的有對(duì)齊關(guān)系詞對(duì)的對(duì)齊概率。將此概率作為最終的雙語(yǔ)短語(yǔ)上下文特征。
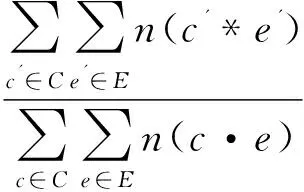
(4)
其中,C和E是根據(jù)Skip-gram算法得到的對(duì)應(yīng)位置元素有語(yǔ)義關(guān)系的子短語(yǔ)集合;c'*e'表明兩個(gè)單詞的對(duì)齊概率大于某個(gè)閾值t(經(jīng)驗(yàn)值)。
3.3 短語(yǔ)對(duì)平均詞共現(xiàn)特征
漢維雙語(yǔ)平行語(yǔ)料包含大量的詞對(duì)應(yīng)信息。文中提出的短語(yǔ)表過(guò)濾模型中第三個(gè)重要的特征即是充分利用漢維平行語(yǔ)料中的詞共現(xiàn)信息,提取漢維短語(yǔ)之間的對(duì)應(yīng)關(guān)系。具體做法如下:根據(jù)詞對(duì)齊階段統(tǒng)計(jì)的漢維詞共現(xiàn)信息,計(jì)算得到當(dāng)前漢語(yǔ)短語(yǔ)對(duì)中有互譯關(guān)系詞在短語(yǔ)對(duì)中所占比例。
(5)
其中,CoNUM(ci,ej)表示根據(jù)漢維詞共現(xiàn)信息,短語(yǔ)對(duì)中的漢語(yǔ)詞c和維吾爾語(yǔ)詞ej之間存在對(duì)應(yīng)關(guān)系;Lens表示漢語(yǔ)短語(yǔ)長(zhǎng)度;Lent表示維吾爾語(yǔ)短語(yǔ)長(zhǎng)度。
4 漢維短語(yǔ)表過(guò)濾模型
根據(jù)上述短語(yǔ)對(duì)循環(huán)神經(jīng)網(wǎng)絡(luò)特征、漢維雙語(yǔ)短語(yǔ)上下文特征以及漢維短語(yǔ)對(duì)平均詞共現(xiàn)特征以及樸素貝葉斯分類模型,構(gòu)建面向漢維機(jī)器翻譯的短語(yǔ)表過(guò)濾模型。
4.1 樸素貝葉斯分類器
樸素貝葉斯分類模型[25]是一種基于特征獨(dú)立假設(shè)貝葉斯定律的簡(jiǎn)單概率分類器。該分類器可以更加精確地描述特征之間潛在的概率關(guān)系。樸素貝葉斯模型基于概率推理過(guò)程,即各個(gè)條件均存在一定概率的不確定性,在僅僅知道其出現(xiàn)概率的情況下,如何完成分類過(guò)程。樸素貝葉斯分類模型基于獨(dú)立假設(shè),即分類假設(shè)樣本特征之間是相互獨(dú)立的。
樸素貝葉斯模型依賴精確的概率推理,因此,與其他分類算法相比,其在有監(jiān)督學(xué)習(xí)的樣例集合上能獲得較好的分類效果,廣泛應(yīng)用于文本分類、數(shù)據(jù)挖掘等領(lǐng)域。
通過(guò)對(duì)漢維短語(yǔ)表中抽取出的三個(gè)特征進(jìn)行分析,發(fā)現(xiàn)三個(gè)特征之間不存在直接的相關(guān)性,短語(yǔ)對(duì)循環(huán)神經(jīng)網(wǎng)絡(luò)特征依賴于當(dāng)前短語(yǔ)所在句子的全局信息;短語(yǔ)上下文特征考慮當(dāng)前短語(yǔ)對(duì)中詞在大規(guī)模單語(yǔ)語(yǔ)料中的語(yǔ)義關(guān)系;平均詞共現(xiàn)特征僅僅考慮當(dāng)前短語(yǔ)對(duì)中詞之間的對(duì)齊信息。因此,文中選擇樸素貝葉斯模型作為短語(yǔ)對(duì)過(guò)濾模型的基線算法。
4.2 短語(yǔ)表過(guò)濾模型
文中提出的漢維短語(yǔ)表過(guò)濾模型主要由以下三部分組成:原始漢維短語(yǔ)表獲取;漢維短語(yǔ)對(duì)特征抽取;漢維短語(yǔ)對(duì)平均詞共現(xiàn)特征。
漢維短語(yǔ)表過(guò)濾模型的輸入為特征向量f,輸出為類標(biāo)記c。其中,特征向量包括三類特征:漢維短語(yǔ)對(duì)循環(huán)神經(jīng)網(wǎng)絡(luò)特征、漢維短語(yǔ)對(duì)上下文特征以及漢維短語(yǔ)對(duì)平均詞共現(xiàn)特征。文中提出的短語(yǔ)表過(guò)濾模型構(gòu)成的特征向量可以形式化地表示為:T={(f1,c1),(f2,c2),…,(fn,cn)},其中的特征由三元組組成:
5 實(shí) 驗(yàn)
5.1 實(shí)驗(yàn)設(shè)置
5.1.1 實(shí)驗(yàn)數(shù)據(jù)
為了驗(yàn)證提出的短語(yǔ)表過(guò)濾模型的有效性,實(shí)驗(yàn)使用了三類語(yǔ)料:漢維雙語(yǔ)句子平行語(yǔ)料(訓(xùn)練集:300 000,開(kāi)發(fā)集:700,測(cè)試集:1 500)、漢維詞典(24萬(wàn)詞)以及人工篩選的漢維短語(yǔ)對(duì)正反例(正例1 000短語(yǔ)對(duì),反例1 000短語(yǔ)對(duì))。其中雙語(yǔ)句子平行語(yǔ)料主要用于統(tǒng)計(jì)機(jī)器翻譯模型訓(xùn)練及其雙語(yǔ)特征抽取;漢維詞典用于雙語(yǔ)短語(yǔ)特征獲取;漢維短語(yǔ)對(duì)正反例用于訓(xùn)練短語(yǔ)對(duì)過(guò)濾模型。
5.1.2 實(shí)驗(yàn)裝置
漢維機(jī)器翻譯實(shí)驗(yàn)使用開(kāi)源的機(jī)器翻譯工具集Moses,分別在基于短語(yǔ)模型以及基于層次短語(yǔ)模型上進(jìn)行實(shí)驗(yàn)。語(yǔ)言模型選用SRLM,使用五元語(yǔ)言模型。參數(shù)調(diào)整使用MERT算法[26]。機(jī)器翻譯性能打分使用BLEU[27]。漢語(yǔ)端分詞工具使用NLPIR。漢維短語(yǔ)對(duì)循環(huán)神經(jīng)網(wǎng)絡(luò)特征抽取基于開(kāi)源的工具集DeepLearning4j實(shí)現(xiàn)。短語(yǔ)對(duì)上下文特征抽取,使用word2vec工具實(shí)現(xiàn)。漢維短語(yǔ)表過(guò)濾模型采用自主實(shí)現(xiàn)的naivebayes4j訓(xùn)練。
5.2 實(shí)驗(yàn)過(guò)程
首先,對(duì)漢語(yǔ)和維吾爾語(yǔ)語(yǔ)料進(jìn)行全半角轉(zhuǎn)換、分詞、Tokenization操作;其次,采用雙語(yǔ)語(yǔ)料獲取原始短語(yǔ)表;再次,抽取漢維正反例語(yǔ)料中的漢維短語(yǔ)對(duì)循環(huán)神經(jīng)網(wǎng)絡(luò)特征、漢維短語(yǔ)對(duì)上下文特征以及漢維雙語(yǔ)短語(yǔ)平均詞共現(xiàn)特征,將其作為輸入進(jìn)行短語(yǔ)表過(guò)濾模型訓(xùn)練;最后,采用訓(xùn)練得到的模型在不同短語(yǔ)長(zhǎng)度限制下進(jìn)行短語(yǔ)表過(guò)濾實(shí)驗(yàn)。
5.3 實(shí)驗(yàn)結(jié)果與分析
分別從對(duì)短語(yǔ)表規(guī)模、翻譯解碼效率以及翻譯性能的影響進(jìn)行分析。
5.3.1 對(duì)漢維短語(yǔ)表的影響
根據(jù)提出的短語(yǔ)表過(guò)濾模型,基于短語(yǔ)漢維機(jī)器翻譯短語(yǔ)表的規(guī)模在最大短語(yǔ)長(zhǎng)度分別取7,9,11時(shí)均有較大幅度減小(見(jiàn)表1)。為了驗(yàn)證文中方法的泛化功能,也在漢維層次短語(yǔ)模型上進(jìn)行了實(shí)驗(yàn),在最大規(guī)則長(zhǎng)度分別取上述值時(shí),規(guī)則表規(guī)模也有所減小。分析原因,提出的方法過(guò)濾了大量的不合理短語(yǔ)(規(guī)則)對(duì)。

表1 對(duì)漢維短語(yǔ)表(規(guī)則表)規(guī)模的影響
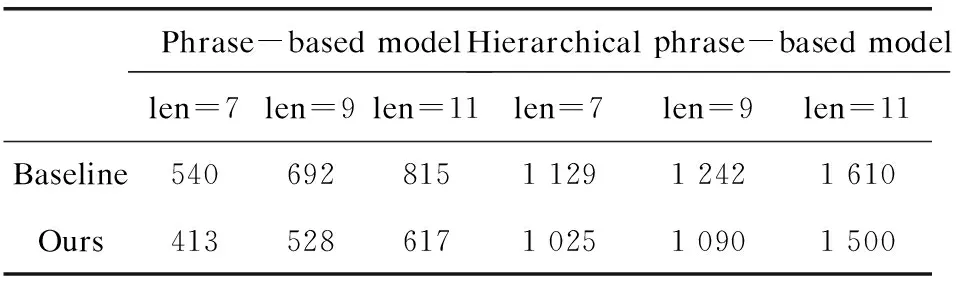
5.3.2 對(duì)機(jī)器翻譯效率的影響
從表1可以看出,由于大量不合理短語(yǔ)(規(guī)則)對(duì)被文中提出的模型過(guò)濾,短語(yǔ)(規(guī)則)表規(guī)模有了明顯減小。因此,解碼的效率也有所提高(見(jiàn)表2)。
表2 對(duì)漢維翻譯解碼效率的影響
s
5.3.3 對(duì)模型性能的影響
由于提出的短語(yǔ)表過(guò)濾模型一定程度上減少了不合理短語(yǔ)對(duì)的數(shù)量,過(guò)濾后的漢維機(jī)器翻譯質(zhì)量總體高于過(guò)濾前。對(duì)比短語(yǔ)模型和層次短語(yǔ)模型,在規(guī)則長(zhǎng)度不少于9時(shí),層次短語(yǔ)模型翻譯質(zhì)量高于短語(yǔ)翻譯模型。其中,最大規(guī)則長(zhǎng)度為9時(shí),基于層次短語(yǔ)的漢維機(jī)器翻譯模型在過(guò)濾后翻譯性能達(dá)到最優(yōu)(見(jiàn)表3)。分析原因,與基于短語(yǔ)的模型相比,層次短語(yǔ)模型中的非終結(jié)符有一定的泛化能力及局部調(diào)序能力。

表3 對(duì)漢維機(jī)器翻譯模型性能的影響
6 結(jié)束語(yǔ)
由于漢語(yǔ)和維吾爾語(yǔ)在構(gòu)詞及形態(tài)上存在較大差異性,模型訓(xùn)練過(guò)程中存在較嚴(yán)重的數(shù)據(jù)稀疏問(wèn)題,致使?jié)h維詞對(duì)齊出現(xiàn)偏差;這一偏差又會(huì)傳遞至短語(yǔ)表生成階段,產(chǎn)生不合理的短語(yǔ)對(duì),最終影響翻譯質(zhì)量機(jī)器解碼效率。綜合考慮漢、維吾爾語(yǔ)言特征及漢維短語(yǔ)表中存在的問(wèn)題,提出了一種融合深度學(xué)習(xí)特征的漢維短語(yǔ)表過(guò)濾模型,該模型基于短語(yǔ)對(duì)循環(huán)神經(jīng)網(wǎng)絡(luò)特征、上下文特征以及平均詞共現(xiàn)特征,并將各個(gè)特征概率及訓(xùn)練實(shí)例輸入到基于樸素貝葉斯分類器的短語(yǔ)表過(guò)濾模型進(jìn)行訓(xùn)練。該模型結(jié)合了漢維候選短語(yǔ)之間更為豐富的語(yǔ)義及上下文信息。實(shí)驗(yàn)結(jié)果表明,該方法有效提升了漢維機(jī)器翻譯性能,解碼效率也有了顯著提高。
在下一步的工作中,將在該模型的基礎(chǔ)上融入更多的語(yǔ)言學(xué)信息,如詞性標(biāo)注、句法標(biāo)注等,以更大幅度地改善漢維機(jī)器翻譯質(zhì)量及其翻譯效率。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
