一種基于可編程邏輯器件的卷積神經(jīng)網(wǎng)絡(luò)協(xié)處理器設(shè)計(jì)
2018-07-25 02:28:10楊一晨張國和梁峰何平吳斌高震霆
西安交通大學(xué)學(xué)報(bào) 2018年7期
關(guān)鍵詞:指令設(shè)計(jì)
楊一晨, 張國和, 梁峰, 何平, 吳斌, 高震霆
(西安交通大學(xué)電子與信息工程學(xué)院, 710049, 西安)
人工智能作為一門模擬人類能力和智慧行為的跨領(lǐng)域?qū)W科,機(jī)器學(xué)習(xí)是人工領(lǐng)域以及學(xué)術(shù)界的研究熱點(diǎn)[1]。伴隨著大數(shù)據(jù)時(shí)代的到來,深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)愈加復(fù)雜與參數(shù)集規(guī)模愈加巨大對計(jì)算力與存儲系統(tǒng)帶來了前所未有的壓力。目前,關(guān)于提供深度學(xué)習(xí)專用加速芯片成為半導(dǎo)體業(yè)界的熱門研究方向之一,特別是在2012年以后涌現(xiàn)出大量優(yōu)秀科研成果。值得注意的是,僅在2016年集成電路界的頂級會議ISSCC(IEEE international solid-state circuits conference)的“下一代處理器”主題中,就有6篇有關(guān)深度學(xué)習(xí)專用芯片的優(yōu)秀論文[2]。而2017年的 ISSCC直接將主題定為了“智能世界、智能芯片[3]”。ISSCC 2018中的5個(gè)全天活動圍繞機(jī)器學(xué)習(xí)與推理硬件方法[4],國內(nèi)各高校與研究機(jī)構(gòu)也積極從事本方向的研究。中科院計(jì)算所研制的通用架構(gòu)神經(jīng)網(wǎng)絡(luò)處理器“寒武紀(jì)”不但取得了從2014年到2016年間多個(gè)計(jì)算機(jī)體系結(jié)構(gòu)國際會議的最佳論文[5],并順利投入商業(yè)化。清華大學(xué)的團(tuán)隊(duì)開展了基于神經(jīng)網(wǎng)絡(luò)壓縮技術(shù)的神經(jīng)網(wǎng)絡(luò)處理器DPU的設(shè)計(jì)并提供了完整的開發(fā)系統(tǒng),其團(tuán)隊(duì)目前創(chuàng)立了專門進(jìn)行FPGA加速研究的科技公司。百度公司提出了“百度大腦”計(jì)劃[6],早在2012年就開始使用圖形處理器GPU、FPGA進(jìn)行異構(gòu)加速,在數(shù)以萬計(jì)的GPU集群中進(jìn)行高性能計(jì)算,百度無人車計(jì)劃也在研究相關(guān)嵌入式計(jì)算平臺,華為“2012實(shí)驗(yàn)室”、阿里云[7]、騰訊云也在進(jìn)行關(guān)于使用FPGA進(jìn)行加速的大規(guī)模研究,并開始提供基礎(chǔ)服務(wù)。
本文的研究工作在課題組中屬于探索性工作,目的是為課題組未來涉及機(jī)器學(xué)習(xí)與硬件相結(jié)合的研究領(lǐng)域建立理論與流程體系,并提供一個(gè)穩(wěn)定可用的卷積神經(jīng)網(wǎng)絡(luò)協(xié)處理器IP,成為一個(gè)更大規(guī)模基于深度學(xué)習(xí)的嵌入式計(jì)算機(jī)視覺片上系統(tǒng)SoC中的關(guān)鍵組件。通過對深度學(xué)習(xí)中的卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行算法的分析,并結(jié)合FPGA系統(tǒng)的特點(diǎn)進(jìn)行硬件實(shí)現(xiàn)與優(yōu)化,設(shè)計(jì)出一款基于FPGA的高性能、可配置的卷積神經(jīng)網(wǎng)絡(luò)協(xié)處理器。本文著重探討了在硬件架構(gòu)層級的算法實(shí)現(xiàn)與優(yōu)化機(jī)制,并闡述了一個(gè)詳細(xì)的設(shè)計(jì)方案,并全面進(jìn)行了設(shè)計(jì)驗(yàn)證、FPGA硬件實(shí)現(xiàn)與性能評估。
1 卷積神經(jīng)網(wǎng)絡(luò)分析
卷積神經(jīng)網(wǎng)絡(luò)起源于標(biāo)準(zhǔn)神經(jīng)網(wǎng)絡(luò)并提供了一種端到端的學(xué)習(xí)模型,與此同時(shí)作為神經(jīng)網(wǎng)絡(luò)領(lǐng)域一個(gè)重要的研究分支,卷積神經(jīng)網(wǎng)絡(luò)的特點(diǎn)在于其每一層的特征都是由上一層的局部區(qū)域通過共享權(quán)值的卷積核激勵而得到。因此,卷積神經(jīng)網(wǎng)絡(luò)是計(jì)算機(jī)視覺領(lǐng)域的研究焦點(diǎn),特別適用于二維數(shù)據(jù)處理的應(yīng)用場景。
1.1 基本概念
卷積神經(jīng)網(wǎng)絡(luò)中,各層對應(yīng)的神經(jīng)元組織形式是一個(gè)三維矩陣,分別定義為長、寬、深度(也可稱為通道數(shù))。以尺寸為32×32的RGB圖像作為輸入層,三個(gè)維度的尺寸分別為32、32與3,權(quán)值同樣以三維矩陣的形式存在。因此,卷積神經(jīng)網(wǎng)絡(luò)中的每一層都完成了把輸入的三維矩陣轉(zhuǎn)換為輸入的另一個(gè)三維矩陣的過程,卷積神經(jīng)網(wǎng)絡(luò)由一系列具有功能不同的層按序單向連接組織。當(dāng)前使用的卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)多種多樣,但均會包含以下最基本的層:卷積層;池化層;全連接層,每一層的輸出還需要經(jīng)過在Alex Net[8-9]以及各種CNN模型中常見的ReLU激活函數(shù)。
1.2 卷積層與其運(yùn)算模式
卷積層是整個(gè)卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的核心,對于卷積層的算法及硬件結(jié)構(gòu)的優(yōu)化至關(guān)重要。卷積層的輸入數(shù)據(jù)是若干組分辨率相同的圖像,按照卷積核的尺寸進(jìn)行卷積運(yùn)算,輸出若干組分辨率相同的圖像。圖像的卷積運(yùn)算通過利用一個(gè)卷積核,把對應(yīng)行列的權(quán)值與輸入圖像的像素值進(jìn)行對應(yīng)的累乘及累加運(yùn)算,卷積核計(jì)算的數(shù)學(xué)表達(dá)式為


1.3 其他模塊其運(yùn)算模式
卷積層的輸出往往需要經(jīng)過池化或子采樣。池化操作用于減小輸入特征對應(yīng)的每一個(gè)通道二維尺寸,進(jìn)而減小了下一層計(jì)算的參數(shù)量,同時(shí)在訓(xùn)練效果上也可以控制過擬合[10]。以步長為2、尺寸為2×2的非交疊池化為例, 二維尺寸上從每2×2的非交疊子區(qū)域中輸出一個(gè)值,即在長寬方向上的尺寸均縮減為原特征的1/2,數(shù)據(jù)量縮減為1/4。全連接層的輸入特征與神經(jīng)元是一一連接的[11],與標(biāo)準(zhǔn)的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)相同。全連接層的計(jì)算過程可視為普通的矩陣乘法:將輸入特征延展為一維行向量,通過乘以規(guī)模比較大的二維矩陣,其輸出為一個(gè)一維行向量。假設(shè)前一層的輸出特征為4×4×64,延展為1×1×1 024的行向量,其權(quán)值矩陣為1 024×64的二維矩陣,輸出特征為1×1×64。由于全連接層也可視為一個(gè)與輸入特征尺寸相同的卷積核作用下的特殊卷積運(yùn)算,因此現(xiàn)有研究中也出現(xiàn)了全卷積的概念,將現(xiàn)有網(wǎng)絡(luò)中的全連接層全部轉(zhuǎn)化為卷積進(jìn)行計(jì)算。
2 協(xié)處理器概述
協(xié)處理器是輔助主處理器進(jìn)行計(jì)算的模塊,主要承擔(dān)加速任務(wù)處理的功能。一般情況下,協(xié)處理器使用硬件設(shè)計(jì)實(shí)現(xiàn)幾種運(yùn)算復(fù)雜、耗時(shí)長的軟件指令。通過簡化多條指令代碼為單一指令,以及直接在硬件中實(shí)現(xiàn)指令的方式,加速代碼的計(jì)算,提升系統(tǒng)整體的運(yùn)行效率。
2.1 卷積神經(jīng)網(wǎng)絡(luò)協(xié)處理器的意義
協(xié)處理器作為高速度和高精度的關(guān)鍵運(yùn)算部件,其性能直接影響系統(tǒng)的運(yùn)算能力。大數(shù)據(jù)時(shí)代的來臨,卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)日趨復(fù)雜,大規(guī)模、深層次的網(wǎng)絡(luò)利用了海量數(shù)據(jù)樣本,其學(xué)習(xí)能力與表現(xiàn)能力不斷提升,然而隨之而來的是訓(xùn)練參數(shù)與計(jì)算量的成倍增加。復(fù)雜的深度學(xué)習(xí)網(wǎng)絡(luò)的訓(xùn)練與預(yù)測過程需要消耗巨額浮點(diǎn)計(jì)算資源以及極高訪存帶寬,由于硬件體系結(jié)構(gòu)的限制,僅利用通用架構(gòu)CPU進(jìn)行深度學(xué)習(xí)計(jì)算效率低、速度慢,難以部署大規(guī)模的計(jì)算任務(wù)。使用協(xié)處理器進(jìn)行加速計(jì)算成為業(yè)內(nèi)主流選擇。
2.2 協(xié)處理器的通用實(shí)現(xiàn)
通用實(shí)現(xiàn)方面,CPU可以訪問加速器及存儲器而加速器通過訪問存儲器對數(shù)據(jù)進(jìn)行處理,即協(xié)處理器作為主從復(fù)合機(jī)實(shí)現(xiàn)整個(gè)系統(tǒng)的加速。通過任務(wù)內(nèi)部的并行機(jī)制和自定義大小的存儲器,能夠?yàn)槊恳粋€(gè)計(jì)算任務(wù)優(yōu)化數(shù)據(jù)路徑,從而很好地處理數(shù)據(jù)。
2.3 基于FPGA協(xié)處理器
傳統(tǒng)使用通用CPU以及CPU+GPU的解決方案,結(jié)構(gòu)復(fù)雜硬件開銷大,并且對資源的利用率不高,而導(dǎo)致其工作能耗高。高端的CPU、GPU價(jià)格昂貴,基于FPGA的協(xié)處理器加速方案越來越受到學(xué)術(shù)界的關(guān)注認(rèn)可。在處理模型結(jié)構(gòu)復(fù)雜、數(shù)據(jù)量大、深層次的計(jì)算時(shí),通用CPU僅需發(fā)送所需算法以及運(yùn)算規(guī)模的計(jì)算指令給FPGA協(xié)處理器,由FPGA協(xié)處理器完成相應(yīng)數(shù)據(jù)的讀取以及運(yùn)算實(shí)現(xiàn)硬件加速的功能[12]。
2.4 卷積神經(jīng)網(wǎng)絡(luò)協(xié)處理器設(shè)計(jì)思想
參考近年來新出的CNN模型,得到不同CNN模型都需要卷積層、池化層、填充單元、全連接層這些必要的基本組件,而各種模型的不同之處在于卷積層和池化層的數(shù)量以及它們的連接方式。本設(shè)計(jì)將每個(gè)組件都獨(dú)立實(shí)現(xiàn),并利用資源復(fù)用的思想,通過不同組件按一定順序配置,在硬件資源允許的情況下就能實(shí)現(xiàn)任意結(jié)構(gòu)的CNN模型,從而實(shí)現(xiàn)了卷積CNN的協(xié)處理器加速。
3 硬件實(shí)現(xiàn)細(xì)節(jié)
本協(xié)處理器設(shè)計(jì)包含了卷積處理器的完整的計(jì)算流程,具有高效能、低功耗的特點(diǎn)。考慮到未來應(yīng)用場景對可配置性、可編程性的要求,設(shè)計(jì)了可支持不同規(guī)模,具有標(biāo)準(zhǔn)的接口、可擴(kuò)展性與可定制性的卷積、池化、全連接、填充、非線性激活函數(shù)的計(jì)算模塊。卷積協(xié)處理器結(jié)構(gòu)圖如圖1所示。
卷積計(jì)算模塊是整個(gè)卷積神經(jīng)網(wǎng)絡(luò)中的核心,具有計(jì)算量大、占用資源多的特點(diǎn)。高效能的卷積計(jì)算模塊是卷積神經(jīng)網(wǎng)絡(luò)整體框架的性能分析的基礎(chǔ),需要著重優(yōu)化卷積計(jì)算模塊進(jìn)而提高卷積神經(jīng)網(wǎng)絡(luò)的性能。
3.1 卷積計(jì)算特點(diǎn)分析
卷積計(jì)算是將卷積核和對應(yīng)輸入特征圖的數(shù)據(jù)進(jìn)行累加,其基本計(jì)算是矩陣乘法計(jì)算,由一系列的乘加計(jì)算組成。在運(yùn)算中,數(shù)據(jù)會有高度的復(fù)用性以及不相關(guān)性:輸入特征圖數(shù)據(jù)對應(yīng)多組卷積核,并且運(yùn)算相互無依賴;輸入特征圖數(shù)據(jù)中的卷積子區(qū)域共享同一個(gè)卷積核;輸入特征圖像數(shù)據(jù)中的不同卷積子區(qū)域數(shù)據(jù)在空間上有大量重疊。硬件設(shè)計(jì)過程中需要在性能、控制靈活度、硬件資源使用方面進(jìn)行折中權(quán)衡,片上的運(yùn)算資源理論上可以全部并行使用,但其需要的數(shù)據(jù)會受到外部存儲器的限制。當(dāng)數(shù)據(jù)重復(fù)利用率較低的時(shí)候,運(yùn)算單元需要在完成計(jì)算時(shí)立即從外部存儲器中取數(shù)據(jù),并行開啟的計(jì)算單元數(shù)量會受限制于有限的外部存儲器帶寬單指令多數(shù)據(jù)的架構(gòu)(SIMD)更適合面對大量數(shù)據(jù)的處理任務(wù),可以大幅增強(qiáng)卷積神經(jīng)網(wǎng)絡(luò)的運(yùn)算能力。為滿足SIMD構(gòu)架以及提升等效帶寬,需要對外部存儲器進(jìn)行連續(xù)的讀寫操作,但卷積計(jì)算單元所請求的數(shù)據(jù)在存儲器中的地址并不連續(xù),會出現(xiàn)跨區(qū)域訪存數(shù)據(jù)的情況,此時(shí)靈活的控制邏輯則是整體框架運(yùn)行的保障。在硬件資源限制之內(nèi),充分利用卷積計(jì)算數(shù)據(jù)復(fù)用特性可以減小對外部存儲器帶寬的依賴,縮小硬件面積,提高計(jì)算能力并節(jié)約存儲空間。
在確定各層級指標(biāo)權(quán)重的基礎(chǔ)上,建立縣域鄉(xiāng)村旅游公路選線適宜性評價(jià)模型為:式中:B為鄉(xiāng)村旅游公路選線適宜性的綜合評價(jià)值,ai表示評價(jià)因子的權(quán)重,ri表示評價(jià)因子的評分值。
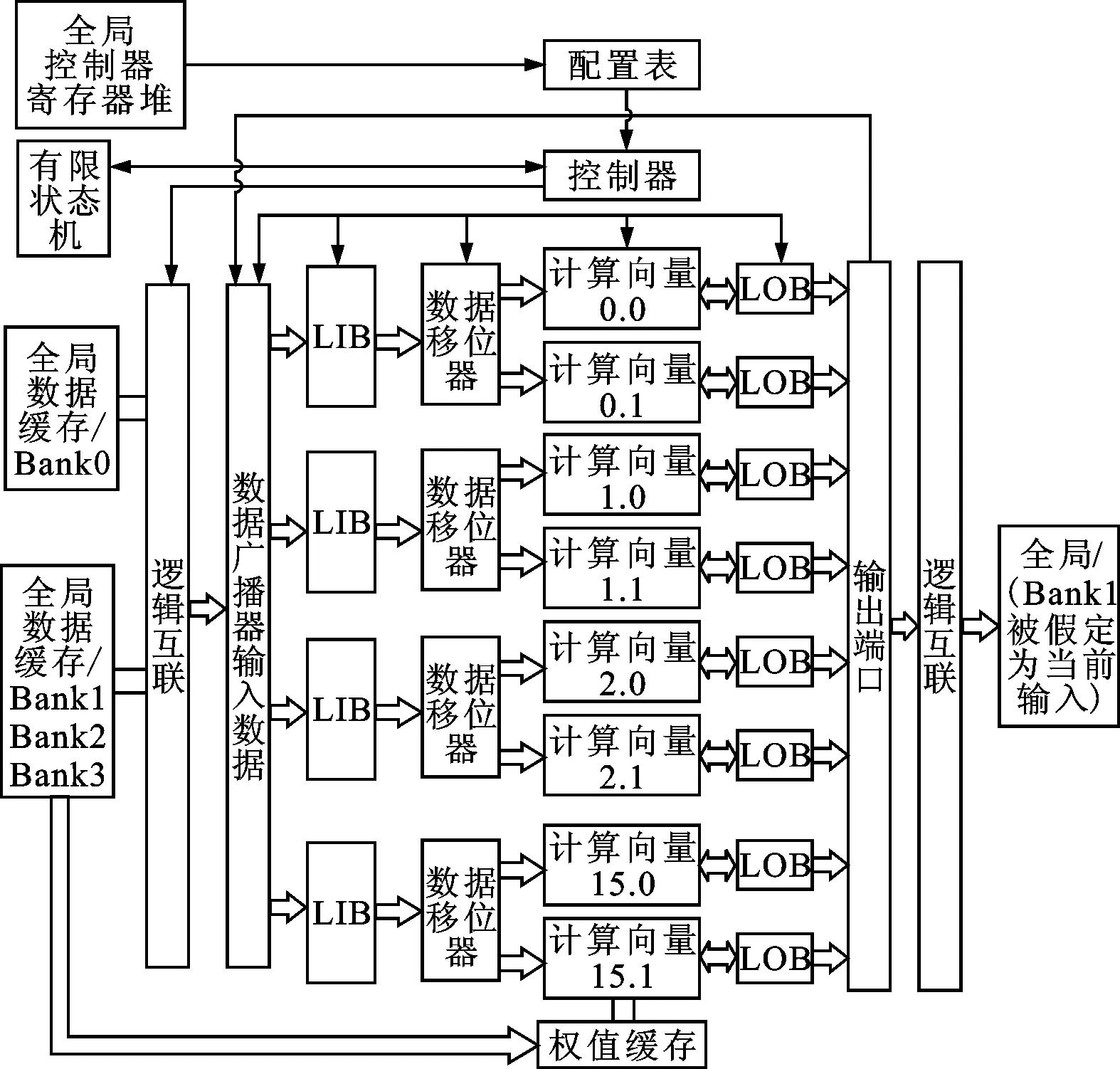
圖2 卷積協(xié)處理器結(jié)構(gòu)圖
3.2 卷積模塊硬件設(shè)計(jì)
依據(jù)上一小節(jié)所闡述的設(shè)計(jì)思路,本設(shè)計(jì)中的卷積模塊架構(gòu)如圖2所示,各基本組件主要分為以下4個(gè)子模塊:①控制模塊,包含配置表與卷積單元控制器;②數(shù)據(jù)輸入模塊,包含輸入緩存LIB和移位器;③計(jì)算模塊,包含多組向量計(jì)算單元;④數(shù)據(jù)輸出模塊,包含輸出緩存LOB。
計(jì)算模塊由多組向量計(jì)算單元組成,在本設(shè)計(jì)中,每組向量計(jì)算單元長度為8個(gè)單精度浮點(diǎn)型,即256 bit,其結(jié)構(gòu)如圖3所示。
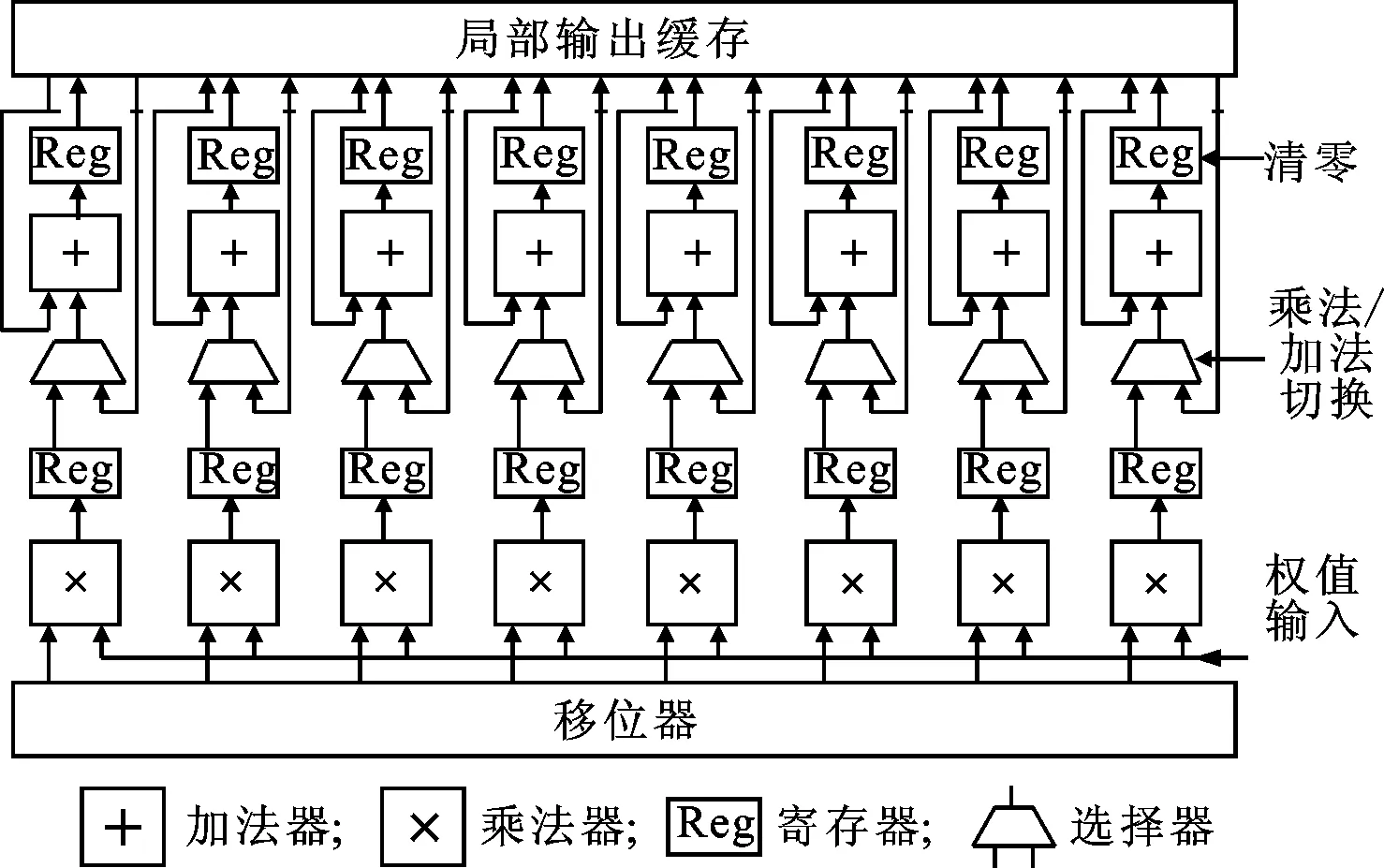
圖3 向量單元結(jié)構(gòu)圖示
向量計(jì)算結(jié)構(gòu)中浮點(diǎn)加法單元,運(yùn)算復(fù)雜,耗時(shí)較長。為了獲得更高整體性能,并滿足高頻率下的時(shí)序要求,本設(shè)計(jì)選用了3級流水浮點(diǎn)加法器。由于加法器輸出還要進(jìn)行累加操作還需要一級的時(shí)鐘節(jié)拍,所以運(yùn)算結(jié)果需要4個(gè)時(shí)鐘節(jié)拍傳給下一級。由于累加計(jì)算具有依賴性,即下一組的累加計(jì)算需要等待上一組累加計(jì)算結(jié)果得出,因此需要有合理的控制邏輯保障卷積計(jì)算在流水線的正確節(jié)拍上,浮點(diǎn)加法流水線填充示意圖如圖4所示,其中Ai、Bi、Ci、Di(i=0,1,2,3)為填入加法器流水線的數(shù)據(jù),Sai、Sbi、Sci、Sdi為有效的運(yùn)算結(jié)果。

圖4 浮點(diǎn)流水線填充示意圖
為了避免浪費(fèi)流水線出現(xiàn)空閑節(jié)拍而造成的效率降低,在流水線的3個(gè)節(jié)拍上控制器需要插入3個(gè)屬于不同輸出通道的卷積核進(jìn)行計(jì)算,從而保障流水線的使用效率以及整體框架的性能。輸入特征將會與多組不同的卷積核進(jìn)行卷積運(yùn)算操作,因此輸入端移位器輸出的數(shù)據(jù)可被多組向量計(jì)算單元共享使用。本設(shè)計(jì)中,設(shè)置有雙端口全局緩存與兩組向量計(jì)算單元相連接,實(shí)現(xiàn)兩組卷積的并行計(jì)算,同時(shí)輸出兩組不同通道的輸出特征。如果充分利用硬件資源,保證卷積計(jì)算單元流水線4個(gè)節(jié)拍不出現(xiàn)氣泡,那么一次卷積迭代可以輸出8組來自連續(xù)輸出通道的輸出特征。
3.3 其他函數(shù)單元
3.3.1 池化單元 池化層也稱為抽象層,計(jì)算過程較為簡單,分為最大池化和平均池化,計(jì)算本質(zhì)并不是神經(jīng)元計(jì)算,其主要作用是對特征圖的數(shù)據(jù)進(jìn)行采樣,縮小數(shù)據(jù)規(guī)模。
根據(jù)學(xué)術(shù)界的研究成果,池化區(qū)域的尺寸多為2×2與3×3,滑動步長為2,本設(shè)計(jì)為實(shí)現(xiàn)更好的兼容性,同時(shí)支持這兩種尺寸的池化計(jì)算。獨(dú)立設(shè)計(jì)的池化單元有著更高的靈活性,實(shí)現(xiàn)兼容不同規(guī)模與結(jié)構(gòu)的卷積神經(jīng)網(wǎng)絡(luò)。池化操作較為簡單,且輸入數(shù)據(jù)復(fù)用度低,在整個(gè)卷積神經(jīng)網(wǎng)絡(luò)框架中消耗時(shí)間和硬件資源較少,可以不必注重優(yōu)化,故設(shè)計(jì)較為簡潔。池化計(jì)算模塊包含了輸入數(shù)據(jù)緩沖區(qū)、控制器、最大池化計(jì)算模塊、平均池化計(jì)算單元。池化操作開始時(shí),池化控制器會從全局緩存中將特征數(shù)據(jù)讀入到池化輸入緩存中,池化計(jì)算模塊根據(jù)計(jì)算類型計(jì)算數(shù)據(jù),運(yùn)算完成后計(jì)算結(jié)果將寫回全部數(shù)據(jù)緩存。
3.3.2 全連接單元全連接單元在整個(gè)構(gòu)架中起到分類器的作用,全連接操作是向量的乘加操作,完成輸入特征行向量與權(quán)值矩陣相乘,輸出為另一個(gè)行向量的計(jì)算。根據(jù)全連接的計(jì)算特點(diǎn),全連接模塊支持的輸入向量長度應(yīng)與全局?jǐn)?shù)據(jù)緩存及相應(yīng)的權(quán)值緩存的帶寬匹配,其性能主要受限于外部存儲器的帶寬。本設(shè)計(jì)中的全局?jǐn)?shù)據(jù)緩存和權(quán)值的緩存位寬都是512 bit,因此設(shè)置了16組浮點(diǎn)乘法器,其運(yùn)算結(jié)果送入如圖5所示的16-8-4-2-1樹形結(jié)構(gòu)連接的乘加結(jié)構(gòu)。
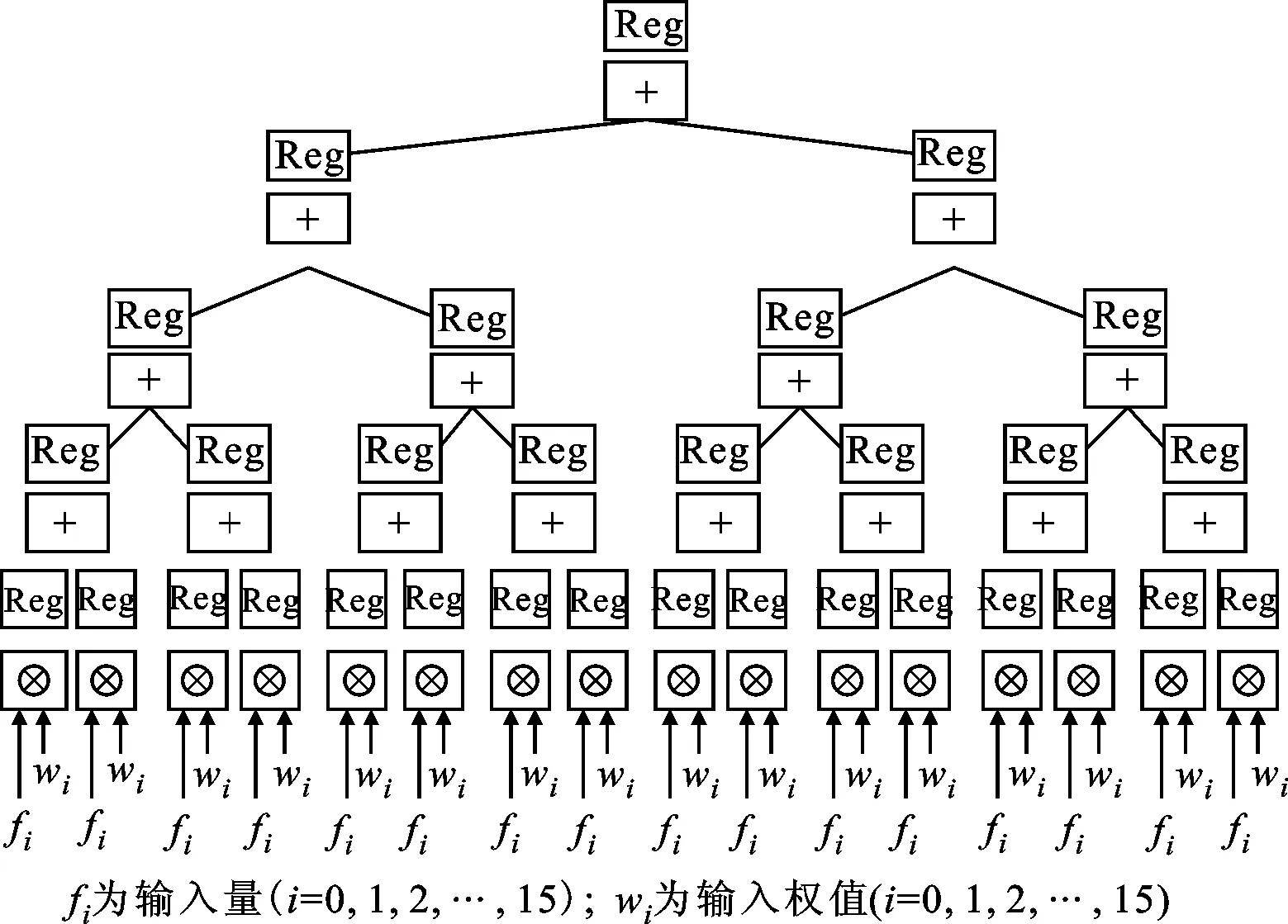
圖5 全連接單元樹形乘加結(jié)構(gòu)
浮點(diǎn)加法器的速度較慢,不能滿足高速主時(shí)鐘的時(shí)序要求,這里的處理方案同前文中卷積浮點(diǎn)加法計(jì)算,采用了3級流水浮點(diǎn)加法器以及相應(yīng)的控制器,來解決時(shí)序與數(shù)據(jù)依賴問題進(jìn)而提高浮點(diǎn)加速器的速度。
3.3.3 I/O與存儲體系 本設(shè)計(jì)設(shè)置了全局?jǐn)?shù)據(jù)DDR3 SDRAM緩存器和局部數(shù)據(jù)權(quán)值緩存的多級存儲結(jié)構(gòu)[13]。協(xié)處理器的工作模式是配合通用CPU進(jìn)行計(jì)算,其外部存儲器采用與GPU配置外部單獨(dú)顯存相似的解決方案,采用了DDR3 SDRAM。
3.4 全局控制器與指令系統(tǒng)
3.4.1 全局控制器 全局控制器實(shí)現(xiàn)對本設(shè)計(jì)各個(gè)模塊的控制,該模塊可解析指令使得各單元進(jìn)入不同的工作狀態(tài),完成相應(yīng)的工作。本模塊包含了8個(gè)32位寄存器組成的通用寄存器堆、指令譯碼單元、獨(dú)立指令緩存,容量為4 kB、對應(yīng)各個(gè)模塊的控制接口。當(dāng)外部主機(jī)或外部主控向協(xié)處理器發(fā)出啟動信號后,協(xié)處理器從等待狀態(tài)上線,自動進(jìn)入啟動狀態(tài),訪問DDR3控制器的指令存儲區(qū)域,指令指針自動從零地址開始讀取指令,讀取到的指令送入譯碼器之后執(zhí)行,在執(zhí)行上一條指令的同時(shí)讀取下一條指令。
3.4.2 指令系統(tǒng) 控制器完成了任務(wù)的調(diào)度工作,本設(shè)計(jì)為了實(shí)現(xiàn)更高的靈活性兼容性,設(shè)計(jì)了指令系統(tǒng)來直接控制計(jì)算單元。采用位寬為32 bit的指令,指令的具體格式如表1所示。
4 實(shí) 驗(yàn)
本設(shè)計(jì)的硬件測試平臺為XILINX公司的VC707評估套件,其搭載的FPGA芯片為Xilinx Virtex-7 VX485T,在VIVADO2016軟件上進(jìn)行綜合,使用100 MHz的系統(tǒng)主時(shí)鐘,由時(shí)序分析得知,本設(shè)計(jì)各條關(guān)鍵路徑滿足時(shí)需要求。本設(shè)計(jì)使用MNIST-LeNet、CIFAR-10測試集進(jìn)行測試,得到較高的準(zhǔn)確率,MNIST-LeNet的準(zhǔn)確率高達(dá)99%,CIFAR-10可實(shí)現(xiàn)80%,與標(biāo)準(zhǔn)實(shí)現(xiàn)準(zhǔn)確率一致。
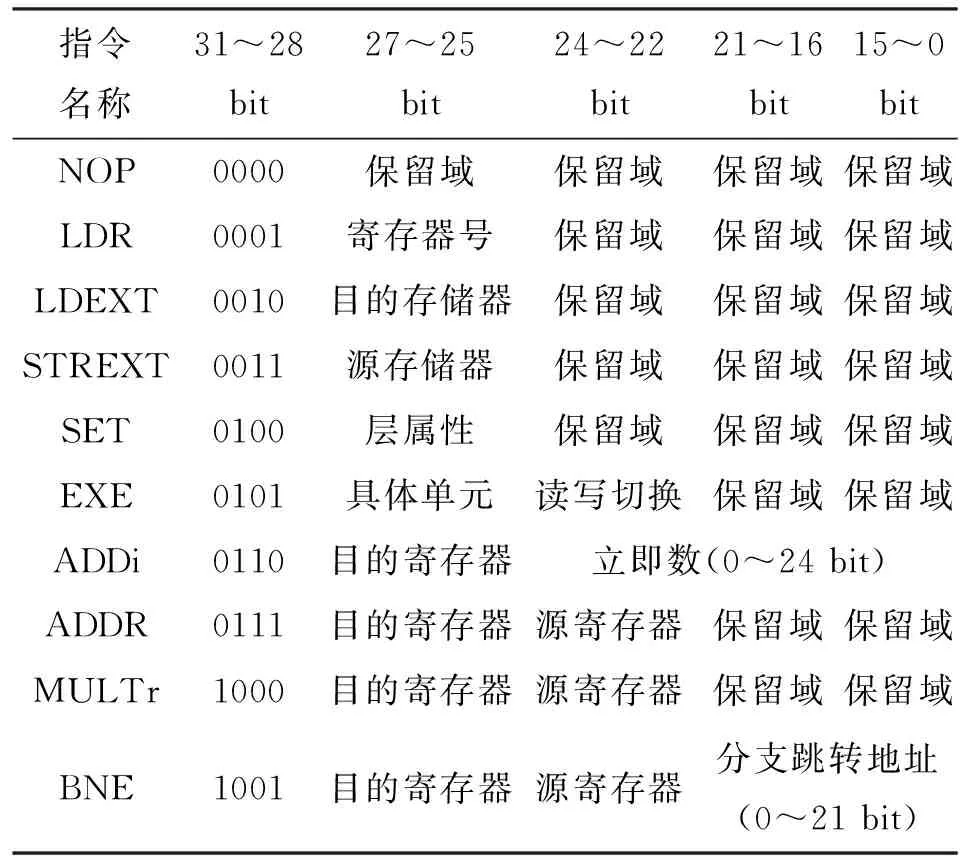
表1 指令格式說明
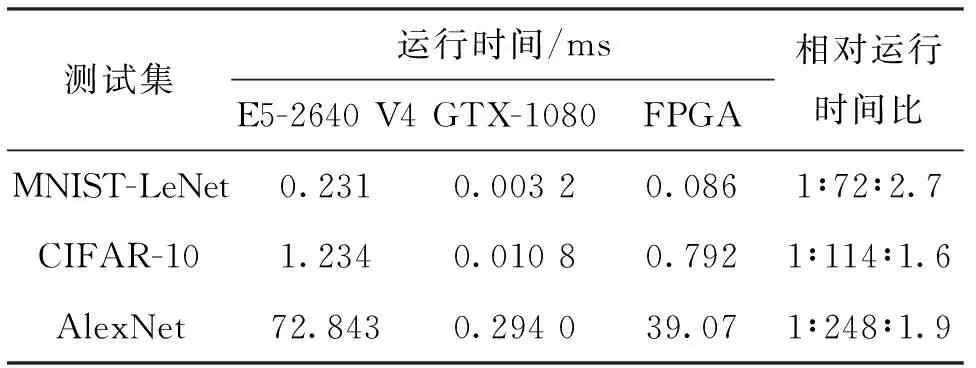
表2 不同平臺的耗時(shí)比

本設(shè)計(jì)的卷積計(jì)算模塊具有多核擴(kuò)展性,在硬件資源允許的情況下,可以實(shí)現(xiàn)更高的運(yùn)算性能。計(jì)算單元擴(kuò)展,在XiLinx VC709評估板其核心FPGA芯片為Xilinx Virtex-7 VX690T上實(shí)現(xiàn),卷積計(jì)算單元中,從每組兩個(gè)計(jì)算向量擴(kuò)展為每組4個(gè)計(jì)算向量,本設(shè)計(jì)方案與同期學(xué)術(shù)界對神經(jīng)網(wǎng)絡(luò)FPGA加速器的性能對比如表3所示。由表3可知,在單精度的設(shè)計(jì)方案中,本設(shè)計(jì)方案的性能達(dá)到同時(shí)期主流FPGA加速方案的水平。
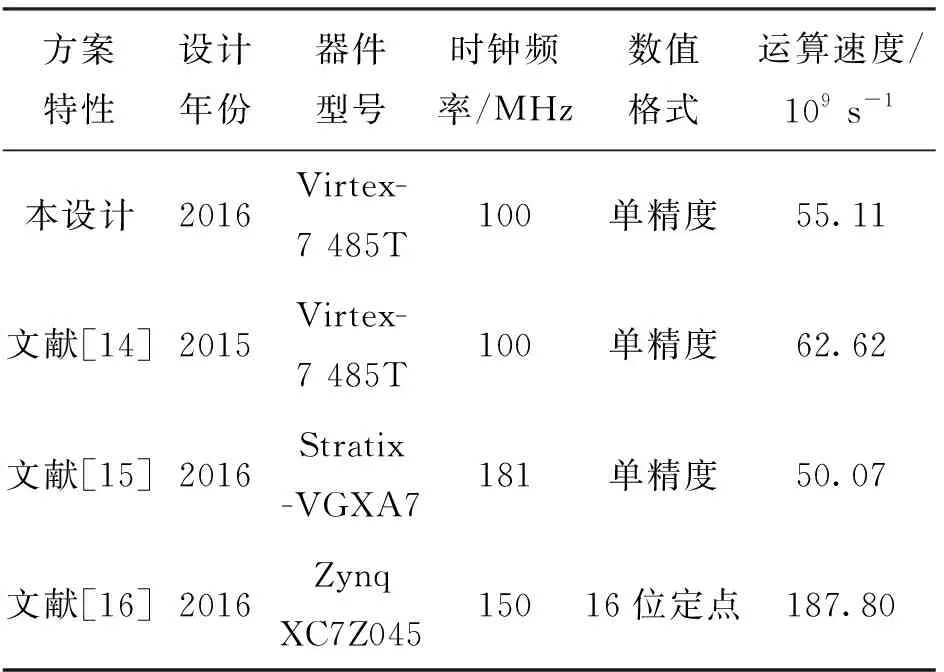
表3 與其他文獻(xiàn)的性能對比
5 結(jié)束語
本文提出一種針對卷積神經(jīng)網(wǎng)絡(luò)完整的協(xié)處理器加速方案,可實(shí)現(xiàn)卷積、池化、全連接等的計(jì)算操作,并采用硬件資源復(fù)用的思想,可以支持不同層數(shù)的計(jì)算。本設(shè)計(jì)的卷積計(jì)算單元,在硬件資源充裕的情況下,可以進(jìn)行多核擴(kuò)展,實(shí)現(xiàn)性能翻倍。通過指令系統(tǒng)通過不同的指令配置實(shí)現(xiàn)不同規(guī)模的網(wǎng)絡(luò)運(yùn)算,相較傳統(tǒng)固定規(guī)模的硬件設(shè)計(jì),有著更高的靈活性和通用性。
本設(shè)計(jì)充分利用了硬件并行計(jì)算帶來的優(yōu)勢,通過與通用處理器方案對比,體現(xiàn)了本設(shè)計(jì)的能效比優(yōu)勢;著重利用了卷積的數(shù)據(jù)復(fù)用特點(diǎn),設(shè)計(jì)了卷積計(jì)算單元;通過合理的多級緩存體系的設(shè)計(jì),使用一定的片上資源,降低了協(xié)處理器對外部存儲器讀寫頻率和帶寬的占用率,使得協(xié)處理器內(nèi)部各模塊通信更加高效,同時(shí)降低了功耗。
本文全面驗(yàn)證、測試與評估了本設(shè)計(jì),完成了行為級仿真、RTL級仿真、FPGA上板驗(yàn)證,功能符合設(shè)計(jì)預(yù)期,關(guān)鍵路徑滿足時(shí)序要求。使用經(jīng)典訓(xùn)練集MNIST-LeNet、CIFAR-10測試,與標(biāo)準(zhǔn)實(shí)現(xiàn)準(zhǔn)確率一致,通過對CPU、GPU的性能對比,顯示出本設(shè)計(jì)更高的運(yùn)算效率。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
現(xiàn)代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
測控技術(shù)(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
藝術(shù)啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
電信科學(xué)(2016年10期)2016-11-23 05:11:56
西安航空學(xué)院學(xué)報(bào)(2014年5期)2014-07-13 01:27:52
