語音識別領域的特征提取技術專利分析
2018-07-31 07:55:20么旭君
專利代理 2018年2期
么旭君 安 飛
一、全球專利狀況分析
(一)申請趨勢
語音識別中的特征提取技術相關申請始于20世紀80年代,并從19 86年開始,該領域有了持續的專利申請。圖1顯示了從19 86年至2016年的申請量按最早申請日/優先權日的年度分布的情況。
從圖中可以看出,語音識別領域的特征提取技術自19 86年開始萌芽。最先提出相關申請的有美國和日本的申請人,使用的特征提取技術包括L P C線性預測編碼、基于字典的方法等,且申請量在此后一直呈逐漸上升趨勢;從19 9 7年開始,隨著語音識別技術的大規模興起,特征提取技術的專利年申請量開始持續增長,并于2000年突破120件;2004~2007年申請量有所回落,保持在100件左右,這可能和技術發展的遇到瓶頸有關;2008年之后,隨著語音識別技術飛速發展,全球申請量有了持續的大規模漲幅,從2008年的132件達到2016年的年申請量235件。
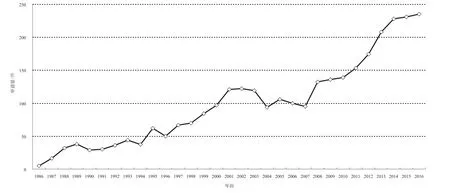
圖1 全球專利申請量年度變化圖
(二)區域分布
1.產出地專利布局
圖2為全球專利申請產出地分布圖。可以看出,我國在語音識別領域的特征提取技術上非常活躍,申請量近千件,接近居于第二位的美國和第三位的日本的申請量之和,居世界首位。美國和日本在特征提取技術上的申請量也較多,申請量都超過了500件。而產自韓國、德國以及英國的申請量偏低,韓國不足兩百件,德國、英國不足100件。
2.產出地申請趨勢
可以看出,美國在語音識別領域的特征提取技術上起步較早,在19 9 8~2004期間處于領先地位,申請量保持在25件左右,于2004年~2006年期間申請量略有下滑,于2007年開始有所回升,并于2007~2009年再次保持在年申請量25件左右,2009~2014年申請量有所增加,至2014年達到申請量的頂峰,為52件。日本在該領域研發也較早,發展規律與美國類似,在19 9 8~2015年期間年申請量一直保持在25件左右,只于2004年和2007年略有波動。我國在該領域起步較晚,2004年之前的年申請量處于10件以下,在2004~2007年有所增長,2007年達到18件,并于2007年之后呈現出快速增長趨勢,年申請量遠超其他國家,于2016年達到年申請量212件。總體上,美國、韓國、日本的申請量在2012年之前都保持基本穩定,在2012年至今申請量取得了一個小幅度上升,而我國的專利申請量從2008年開始呈增長趨勢并遠超其他國家,此外,近三年的申請量則受到公開滯后因素的影響。
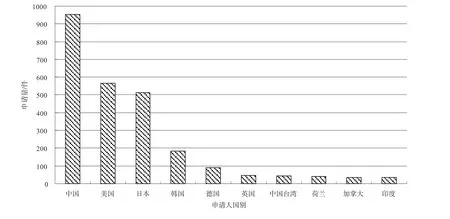
圖2 全球專利申請產出地分布圖
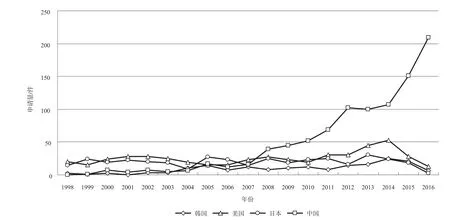
圖3 全球主要產出地近20年申請量年度變化圖
3.產出地專利布局
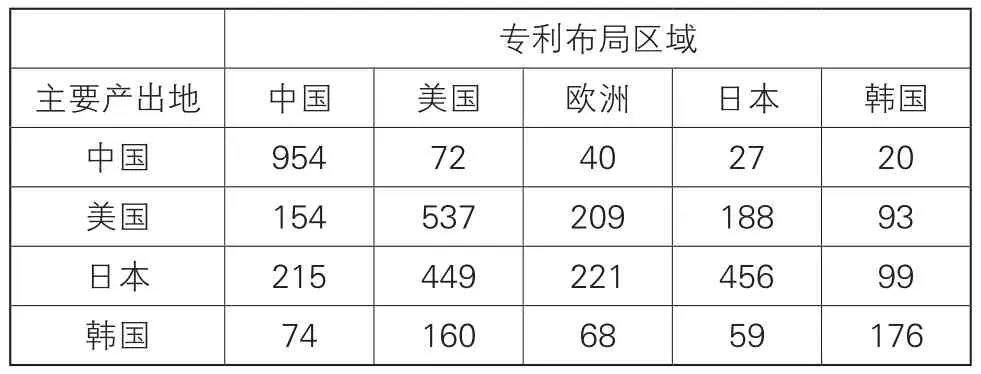
表1 主要產出地的專利布局區域分布
表1是主要產出地的專利布局區域分布情況。語音識別領域的特征提取技術主要產出地為日本、美國、韓國和中國,各產出地普遍重視在本國和美國進行專利布局,可見美國是語音識別領域最重要的市場之一。此外,我國的大多數申請都集中在本國,向國外申請的專利數量較少,需要更加重視在國外進行專利布局。
4.目的地申請趨勢
圖4為全球專利申請目的地分布圖。其中將我國作為目的地的專利申請占比最高,達到26.5%,可見各國申請人對我國市場的重視程度。此外,美國申請量也較多,與中國相差并不大,可見美國市場也是語音識別領域的重要市場。這樣的分布除反映市場的受重視程度外,另一方面,申請量受到該國本國申請人以及技術水平的影響,上文已經分析過,我國產出量在近10年顯著增長,并且以本國為目的地的申請占據了大部分比重,這也是我國作為全球專利申請目的地占比最高的一個因素。因此,上述國家和地區中,市場競爭主要集中在本國和處于市場主導地位的美國,我國作為新興市場,也已經成為各國申請人進行專利布局的主要地區。
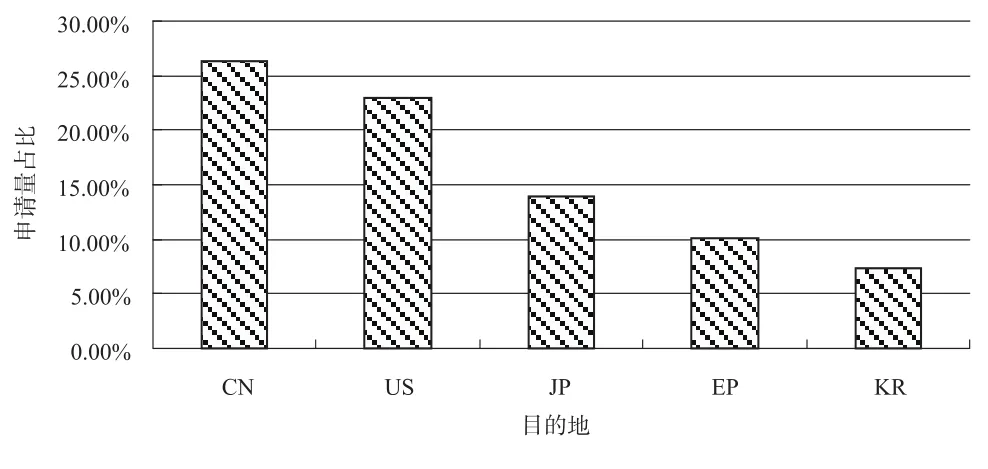
圖4 全球專利申請目的地分布圖
(三)主要申請人
1.主要申請人分布
圖5為全球主要申請人分布。在排名前20的申請人中,有6位中國申請人,6位日本申請人,4為美國申請人,3位韓國申請人和1位荷蘭申請人。日本申請人數量最多,并且申請人的申請量排名靠前,東芝公司的申請量居于首位,為65件,索尼公司申請量為53件,都遠超其他申請人,可見日本在語音識別領域的研究較為深入。中國的6位申請人中,包括聯想、華為、中興三家公司和中科院等三家科研院所,這體現了我國企業和高校對技術研發方面的發展程度和對專利申請的重視。此外,中國申請量排名第1位的聯想公司在全球申請人中排名第8位,可見我國申請人數雖然較多,但是在數量上距離世界先進水平仍有差距,存在一定的提升空間。
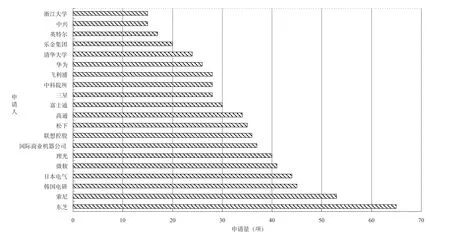
圖5 全球主要申請人分布
2.主要申請人申請趨勢
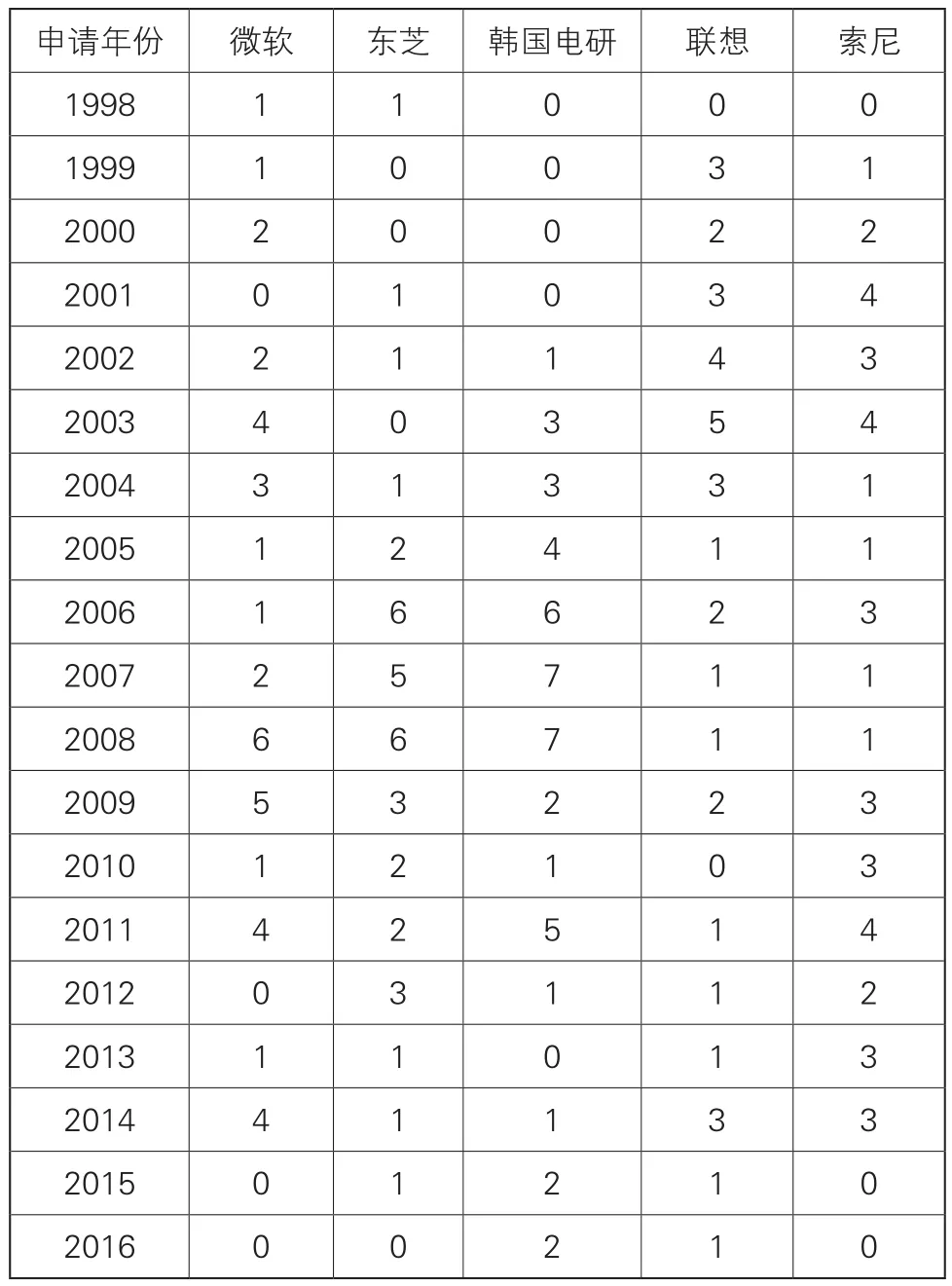
表2 主要申請人申請趨勢單位/件
表2示出了全球重要申請人微軟、東芝、韓國電研、聯想、索尼這五位申請人的申請趨勢情況。可以看出,在2004年之前,我國的聯想公司的申請量一直處于領先地位,19 9 9~2000的申請量為2~3件,2003年增長至5件,2005年之后聯想公司的申請量有所下降,2006至2016年的申請量0~2件波動,申請量不大,這可能與該公司的主要研究方向有關。韓國電研起步較晚,從2001年開始申請量從0逐步增加至2007~2008年的7件,于2010年降至1件,2011年回升至5件,此后的2012~2016年申請量在0~2件波動,可能不再側重特征提取領域的研究。微軟公司的申請量波動較大,19 9 8~2000年起步期間的申請量為1~2件,2001年申請量為0,2002~2003年逐漸增加至4件,2005~2006年申請量下降為1件,并于2007~2008年逐漸增長至6件,2008~2010年逐漸下降為1件,并于2011年申請量再次增加至4件,2012年申請量為0,2013~2014年再次增加至4件,這樣的波動可能是由于其技術研發周期長或有多項技術同時研發造成的。東芝公司起步也較晚,2005年之前為其起步期,申請量在2件以內,2005~2009年逐步增加至5~6件,2009~2013年降至2~3件,并于2013~2015年維持在1件。各公司2016年申請量較少與其研究重點和技術布局有關,也可能與專利尚未公開有關。
二、中國專利狀況分析
(一)趨勢分析
1.專利申請趨勢
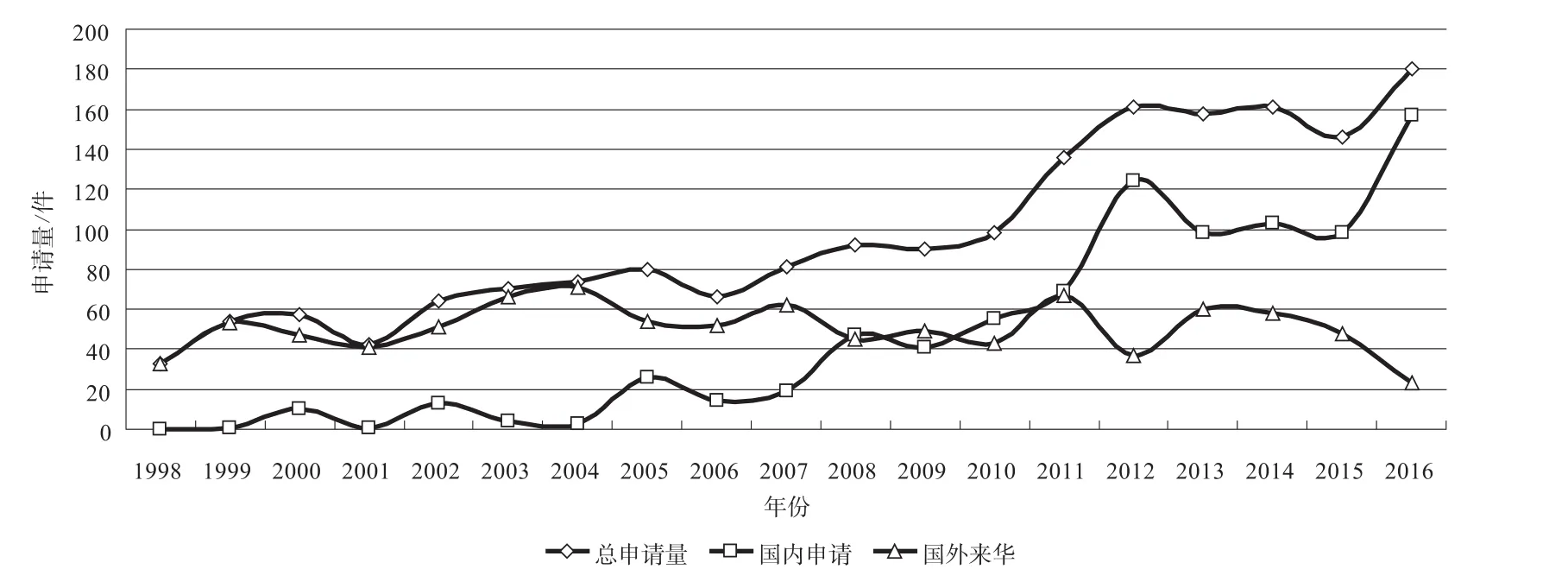
圖6 中國專利申請量年度變化圖
圖6顯示了我國語音識別領域的特征提取技術專利申請量的年度變化情況。從圖中可以看出,從圖中可以看出,在2000年之前,我國的語音識別領域的特征提取專利年申請量很小,都在60件以下,從2002年開始,年申請量開始有所增加,其中以國外來華申請為主。從2010年開始,年申請量開始迅速增加,2012年至2014年申請量穩定在160件左右,2016年增長至180件。從國內申請量和國外在華申請量對比來看,2008年以前,我國的語音識別領域的特征提取專利主要以國外來華申請為主,國內申請比重較小。2008年國內申請量首次超過國外在華申請量,并從2012年開始搖搖領先于國外來華申請。可以說,2010年之后我國語音識別領域的特征提取專利數量的迅速增長主要來自于國內申請的迅速增長。
2.專利授權趨勢
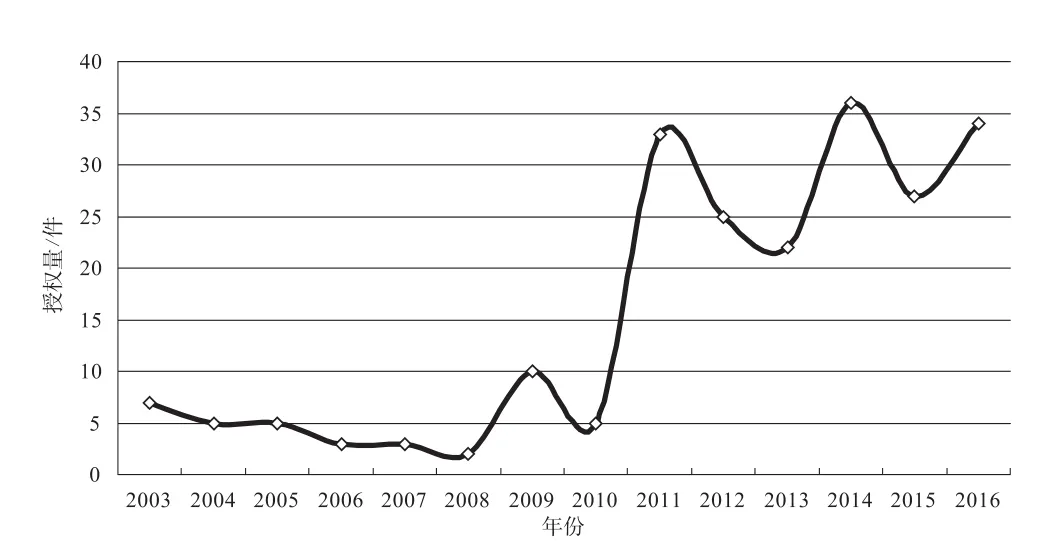
圖7 中國專利授權趨勢圖
圖7展示了語音識別領域特征提取技術相關專利的授權趨勢圖。由圖可知,2010年之前我國授權量較低,雖略有波動但一直不足10件,2010年之后有了顯著增長,2011年增長至33件,2012~2013授權量略有下降,分別為25件和23件,2014年再次增長至36件,2015年下降至27件,并于2016~2017年逐漸上升至36件。授權量在2010年的大幅度增長與該領域的申請量在2008年之后迅速增長有關,其后的授權量波動也與申請量的波動有關。總體上,授權量在2010年之后大幅度提高,這與該領域技術的發展和申請量的趨勢一致。
(二)申請人區域/省市分析
1.國外來華申請國家分析
圖8顯示了國外來華申請人區域分布情況。可以看出,日本申請人所占比例最大,達到38%,美國僅次于日本,占27%,韓國占9%,說明日本、美國和韓國比較重視中國市場,這也與這三個國家在語音識別領域的研發實力相統一。
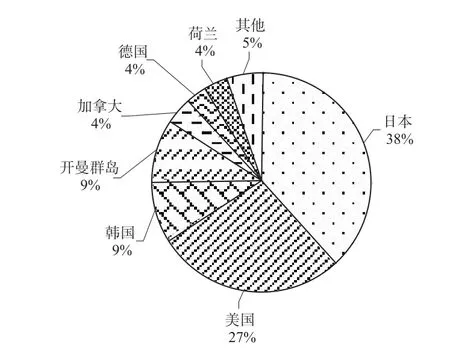
圖8 國外來華申請人區域分布圖
2.國內申請省市分析
圖9顯示了國內申請人的省市分布情況。可以看出,北京所占比例最高,達25%,反映出北京在語音識別領域特征提取技術方面研發實力最強,這也與大量相關企業、高校和科研院所位于北京有關。接下來分別是廣東、江蘇和上海,分別位于我國長三角和珠三角,這兩個地區科技發展速度快,研發實力也比較強,集中了國內有優勢的高校如浙江大學、華南理工大學等,代表了國內語音識別領域特征提取技術的整體實力。
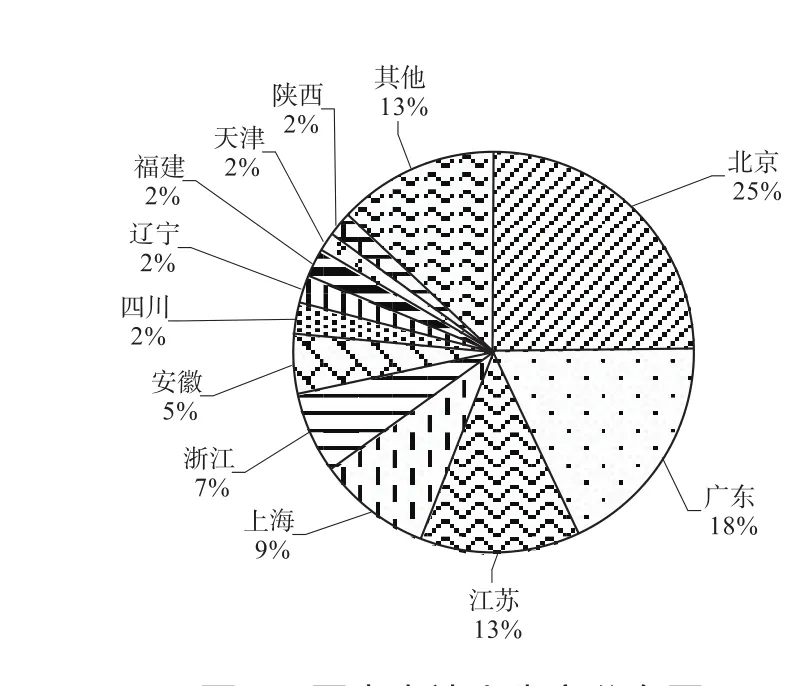
圖9 國內申請人省市分布圖
(三)申請類型和法律狀態
1.法律狀態(授權、駁回、視撤、在審、終止)
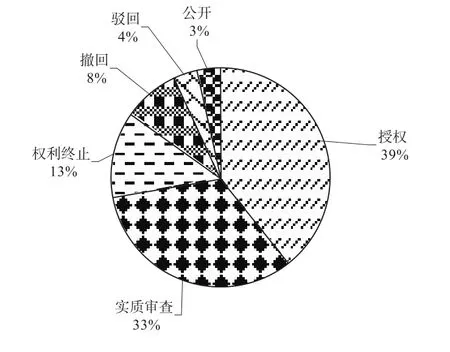
圖10 中國專利申請的法律狀態
圖10展示了申請人在華專利申請中發明專利申請的法律狀態。從圖中可以看出,授權專利在處理中的專利申請占比最高,占比39%;其次是處理中的專利申請,占比33%;權利終止的專利申請在13%左右,其余各種失效狀態的占比較少。
2.申請類型
圖11顯示了國內申請的申請類型分析情況。從圖中可以看出,對于語音識別特征提取技術領域的專利申請中,發明專利申請所占比重極大,為9 9%,實用新型專利申請僅占1%。
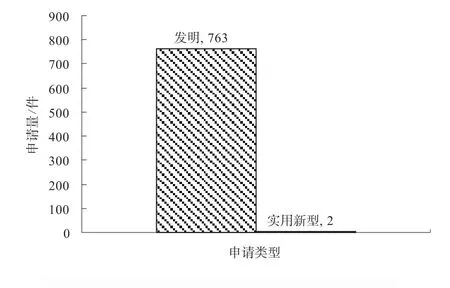
圖11 申請類型分布
(四)主要申請人
1.申請人類型
如圖12所示,大專院校和企業的申請占據了申請量的絕大部分,其中專利申請人中大專院校所占比例最大,為55%,代表了我國高校在語音識別領域特征提取技術上的科研實力。其次是企業申請,占比41%,證明了我國企業的科研實力和對專利權保護的重視。之后是科研單位和個人申請等,差距量不大,占比在6%~8%。
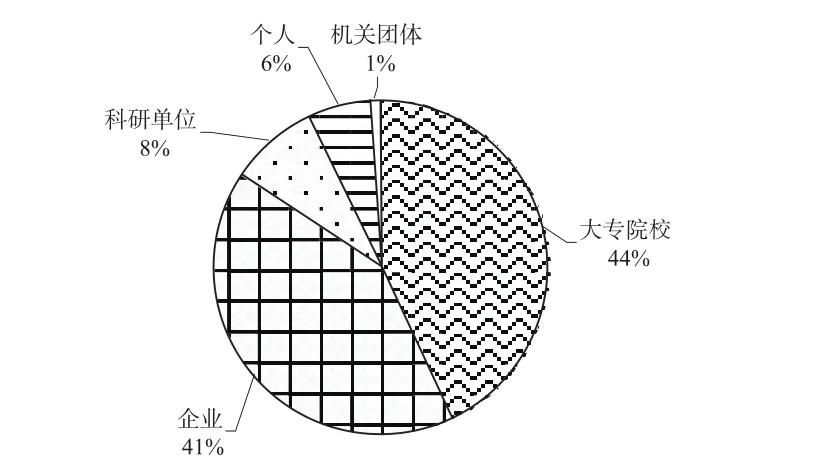
圖12 申請人的類型分布
2.申請人排名
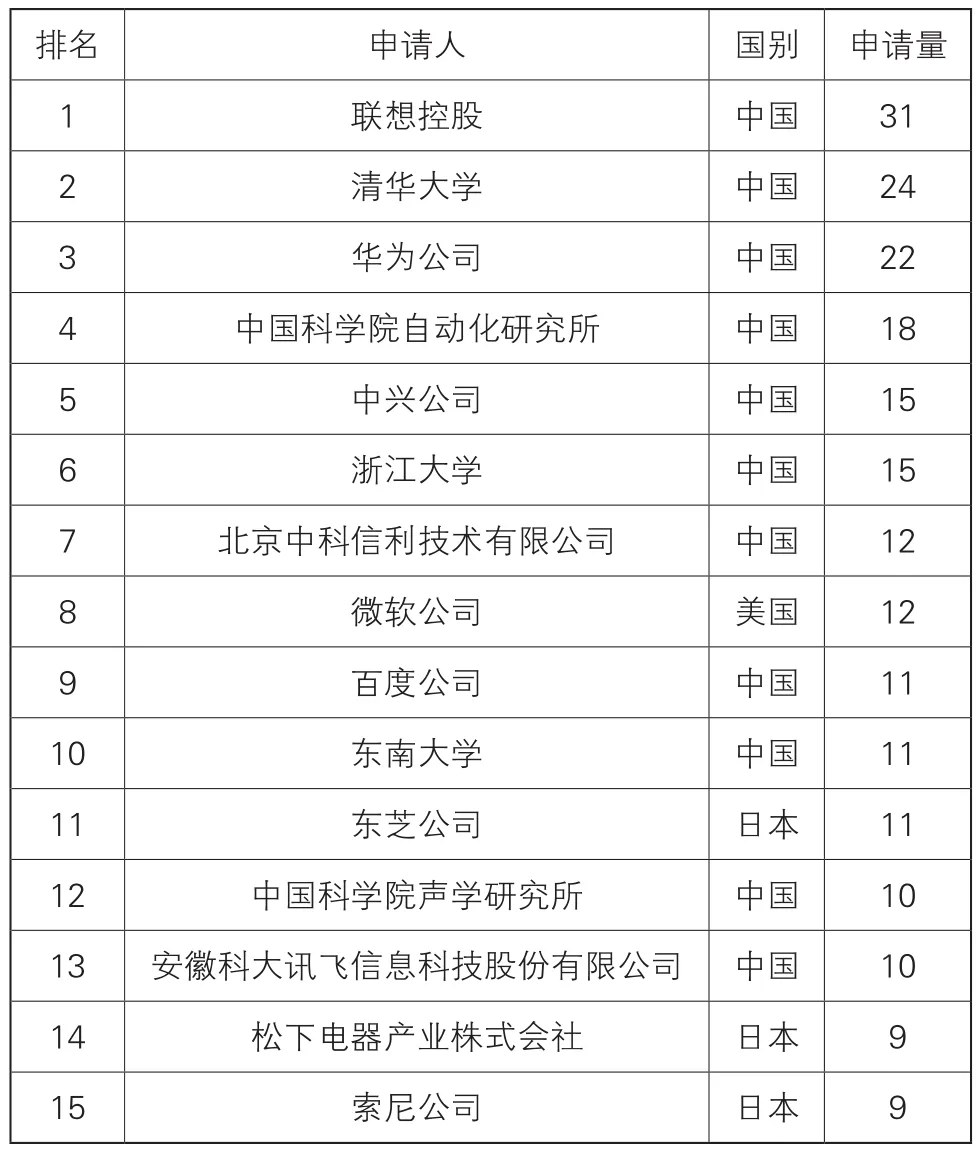
表3 中國專利申請的主要申請人排名
表3列出了中國專利申請的前15位申請人的分布情況。其中中國申請人11位、日本申請人3位,美國申請人1位。中國的11位申請人中有6位高校及科研院所申請人和5位企業申請人,體現了我國企業和高校對技術進步、專利保護的重視程度;國外申請人中微軟公司的申請量最多,為12件,其次是日本的松下電器產業株式會社和索尼公司,申請量都為9件,這在一定程度上反映了國外申請人對我國市場的重視。前15位申請人的申請總量占全部中國專利申請總量的28.8%,還有大量申請分布在中小企業和高校及科研院所,這反映了還有大量中小企業和科研院所處在研發的起步期,我國申請人在語音識別領域特征提取技術上還有進步空間。
3.申請人申請趨勢
納入標準:(1)患者肝、腎等功能正常。(2)患者有焦慮癥狀,SAS評分>50分。(3)有正常語言表達和理解能力。
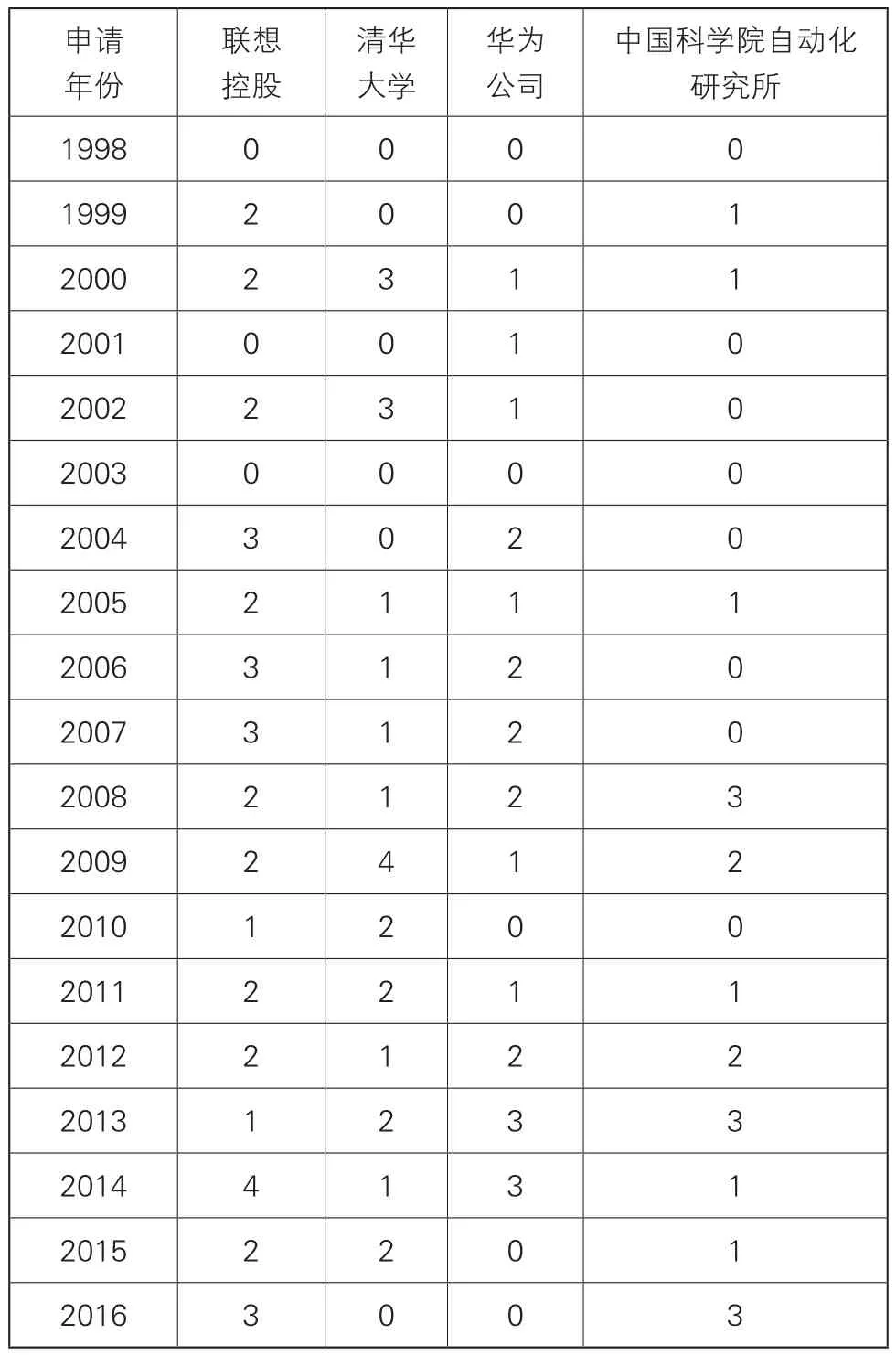
表4 主要申請人申請趨勢
中國申請的重要申請人以我國申請人為主,表4選取了重要申請人進行分析,示出了聯想控股、清華大學、華為公司、中國科學院自動化研究所四位申請人的申請趨勢情況。可以看出,在2005年之前,四位申請人的申請量都在0~3件,我國在語音識別領域特征提取技術上還處于萌芽階段。從2005年開始,我國在該領域有了初步發展,申請量有所增加,每位申請人的申請量維持在每年2~3件。從2011年開始,我國在該領域進入蓬勃發展階段,除表中所示的四位申請人之外,還有一批中小型企業和高校的申請量也值得一提,如安徽科大訊飛公司在2012年的申請量為8件,華南理工大學在2013年的申請量為6件,雖然這些申請人的總申請量還不高,但已經體現了其科研實力和知識產權保護意識,也為該領域的進步做出了一定的貢獻。而上表中的幾位申請人在近幾年的申請量總體呈下降趨勢,這可能也和該公司的研究方向有關。
五、重點技術分析
通過對我國語音識別中的特征提取技術專利分析可知,目前常見的特征參數包括基于線性預測編碼系數(Linear Predictive Coding,LPC)、線性預測倒譜系數(Liner Predictive Cepstrum Coefficient,LPCC)和基于人耳聽覺原理的梅爾頻率倒譜系數(Mel-Frequency Cepstrum Coefficient,MFCC),以上參數都能夠獲得很好的語音個性特征,根據特性不同,分別用于不同的系統中。同時,LPC、LPCC 和MFCC 還有著技術上的遞進順序,其中MFCC 是目前語音識別中廣泛使用的特征參數之一。MFCC 是在80 年代由Steven.B.Davis 提出的,它是將信號短時頻譜先在頻域將頻率軸變換為梅爾頻率刻度,再變換到倒譜域得到的。當前很多類型的聲音辨識是采用MFCC、MFCC的差量(一階變化量)以及MFCC 的次差量(二階變化量)的組合,或上述值的線性變換為特征參數,因此具有可觀的研究價值。
在探究MFCC的技術發展路線之前,需要進一步理解MFCC參數的計算過程。MFCC是基于人耳聽覺模型建立的倒譜系數,人的聽覺系統是一個特殊的非線性系統,它響應不同頻率信號的靈敏度是不同的,通常是一個對數關系。也就是說,人耳對不同頻率的語音具有不同的感知能力,聲音的物理頻率表示單位是梅爾(Mel )。Mel刻度表示了人耳對于頻率感知的非線性特性,根據人類聽力的臨界帶效應,設計若干個具有三角形或者正弦型的帶通濾波器,然后把語音處理成能量譜,再輸入到該濾波器組。通過取對數,作離散余弦變換,就能得到MFCC系數。具體如圖13所示:
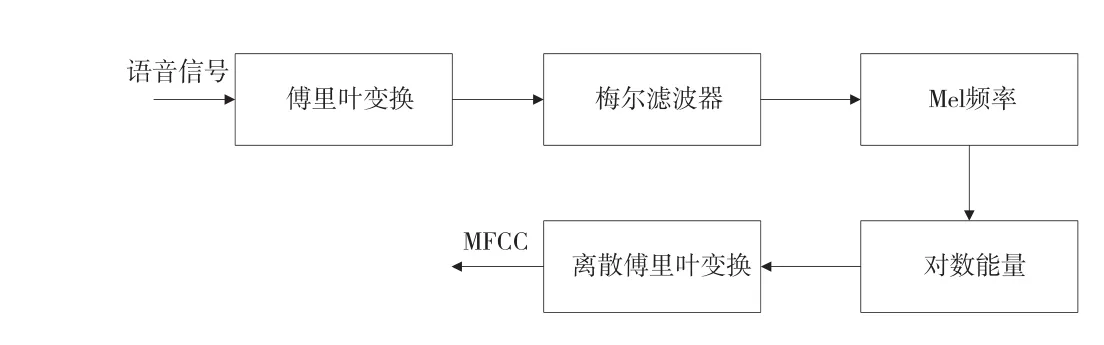
圖13 MF C C參數的計算過程
具體可以解釋為:
(1)將語音信號,即時域信號進行傅里葉變化(DFT),求出線性頻譜;
(2)將得到的線性頻譜經過梅爾濾波器組形成Mel頻譜;
(3)然后經過對數能量處理,得到對數頻譜;
(4)將對數頻譜經過離散余弦變換((DCT)得到倒譜頻域,即可得到Mel頻譜倒譜系數,即MFCC參數。
近些年,在特征提取領域MFCC是最常用的特征參數,因此下面將針對MFCC的技術發展路線分析其技術重點和研究方向。
2012年,國際商業機器公司提出了一種聲音特征量提取方法(CN 1024839 16A),該申請針對傅里葉變換后的頻譜信息,使用線性域的差分作為聲音的差量特征量及次差量特征量,以此計算MFCC參數,通過該方法可提取較先前技術更能抗回音及噪音的特征量,且其結果可改善聲音辨識的正確率。該方法具體為獲取輸入聲音信號的各頻率的頻譜,對于各幀,對上述各頻率算出前后的幀間的頻譜的差分,作為差量頻譜;通過將上述各頻率的差量頻譜除以該頻率的總發音即平均頻譜的函數而正規化,將輸出設為差量特征量,最終計算出MFCC參數。
對于輸入端進行改進的還有2016年聯想公開的一種MFCC提取方法及裝置(CN 105513587A)。該申請是針對現有技術里,在提取MFCC的過程中,無論語音數據幀的大小,均采用固定的量化位數對每一幀語音數據幀進行定點化處理(包括放大處理),而對于能量較小的語音數據幀,即使放大后,數據范圍還是很小,因此,在通過后續各處理步驟的累積后,形成的誤差依然不可忽視。因此,該發明依據語音數據幀的范圍,確定第一處理參數,并使用所述第一處理參數,放大經過預處理后的語音數據幀,隨后提取放大后的語音數據幀的MFCC,也就是說,在進行MFCC提取之前,先將數據幀進行放大,并且因為第一處理參數與所述預處理后的語音數據幀的數據范圍反相關,即語音數據幀的數據范圍越小,第一處理參數越大,所以,對于能量較小的語音數據幀,在進行定點化時,比能量大的數據幀放大的程度更大,因此大數據幀比小數據幀更能抵消定點化帶來的誤差,提高從小能量的語音數據幀中提取到的MFCC的精度。
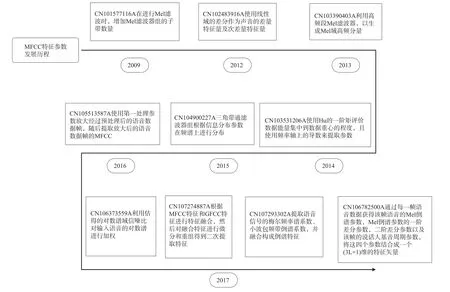
圖14 MF C C技術發展路線圖
針對梅爾濾波器的設置方式,2009年,北京中星微電子有限公司公開了一種語音信號的MFCC系數提取方法、裝置及一種Mel濾波方法(C N 101577116A),該發明為解決H T K的MFCC系數提取方法中子代數量不匹配的問題,特地在進行Mel濾波時,增加Mel濾波器組的子帶數量,在頻率范圍內進行Mel濾波,得到對應每條子帶的Mel濾波輸出;然后,將高頻范圍內的子帶數量進行聚合,得到聚合后相應子帶數量的Mel濾波輸出;隨之繼續對低頻范圍和聚合后高頻范圍的Mel濾波輸出進行非線性變換和離散余弦變換,最終提取出MFCC系數。該發明既保證了低頻信號有足夠的頻率分辨精度,同時,又將高頻范圍內的子帶數量進行聚合,提高了高頻的抗干擾能力,從而優化了提取的MFCC系數,能夠語音識別的準確率。
在隨后的2013年,百度提出了一種MFCC特征的提取方法及裝置(CN 10339 0403A),從其他角度優化了MFCC參數的計算方法。該方法為通過令Mel濾波器組中包括高頻段Mel濾波器,對經過預處理的音頻信號進行過濾處理,以生成Mel域高頻分量,進而對所述Mel域高頻分量進行離散余弦變換,以生成每個所述Mel域高頻分量的變換特征,使得能夠根據每個所述Mel域高頻分量的變換特征,獲得所述音頻信號的MFCC特征,由于利用Mel濾波器組中所包括的高頻段Mel濾波器,對經過預處理的音頻信號進行過濾處理,可以獲得Mel域高頻分量。該方法能夠去掉容易受環境影響的Mel域低頻分量,使得從測試數據中提取的MFCC特征與從訓練數據中提取的MFCC特征不會存在較大差異,從而提高了MFCC特征的魯棒性,是我國申請人在特征提取技術上作出的又一項改進。
接著,2015年聯想公開了一種語音特征信息的提取方法及電子設備(CN 1049 00227A)。該發明獲取與語音信息對應頻率寬度中的信息分布參數,基于所述信息分布參數,確定三角帶通濾波器組在頻譜上的分布系數,根據分布系數,將三角帶通濾波器組分布在頻譜上進行濾波,獲取Mel頻譜,基于所述Mel頻譜,獲取Mel頻率倒譜系數MFCC。由于三角帶通濾波器組是根據所述信息分布參數來所述頻譜上進行分布的,使得所述頻譜中攜帶信息量多的頻帶設置較多的三角帶通濾波器組,以及攜帶信息量少的頻帶設置較少的三角帶通濾波器組,從而解決了現有的電子設備在獲取語音特征信息時,存在不能根據實際情況自動調整三角帶通濾波器組的分布的技術問題。
針對得到對數頻譜后再進一步進行處理的申請包括:2014年,華南理工大學提出了一種結合局部與全局信息的語音情感特征提取方法(C N 103531206A)。該發明針對忽略Mel濾波器內部能量分布信息以及每一幀不同濾波器結果之間的局部分布信息造成的對噪音敏感的問題,提出了以下改進:(1)將語音信號分幀;(2)對每一幀進行傅立葉變換;(3)使用Mel濾波器對傅立葉變換結果濾波,對濾波結果求能量,并對能量取對數;(4)對取得的對數結果使用局部H u運算,獲得第1類特征;(5)對局部H u運算后的每一幀進行離散余弦變換,獲得第2類特征;(6)對第3步計算的對數結果進行差分運算,然后對差分結果的每一幀進行離散余弦變換獲得第3類特征。該發明可快速有效地表達各類情感的語音,應用范圍包括語音檢索、語音識別、情感計算等領域。該申請的發明構思為:在語音情感不同時,發音清晰度、基音變化程度、發音強度、語速都會發生相應的變化,這些變化將改變語譜圖能量的集中程度,如發音比較清晰、發音強度高時語譜圖能量比較集中。而H u的一階矩恰好能夠評價數據能量集中到數據重心的程度,這樣能夠很好的提取語音情感變化時導致語譜圖上能量集中度發生的變化。另外情感發生變化時會改變語音信號的頻率分布,從而在語譜圖的頻率軸上發生變化,所以該發明使用頻率軸上的導數來提取這些變化。
隨后,河海大學2017年還公開了一種基于對數譜信噪比加權的魯棒特征提取方法(C N 106373559 A)。該發明首先對輸入語音進行聲學預處理、短時譜估計和Mel濾波,得到每一幀的短時Mel子帶譜;再利用改進的對數函數對Mel子帶譜進行非線性變換,得到對數譜,同時從Mel子帶譜中估計輸入語音的對數譜域信噪比;然后,利用估得的對數譜域信噪比對輸入語音的對數譜進行加權,得到加權對數譜;最后,對加權對數譜進行離散余弦變換并作時域差分,得到輸入語音的特征參數。該發明提高了噪聲環境中提取的特征參數的環境魯棒性,減小加性噪聲對語音識別系統的影響。
當前,對于MFCC參數計算過程中對于特征的二次提取也備受申請人關注。2017年,電子科技大學公開了一種基于基音周期和MFCC的融合特征參數提取方法(C N 106782500A)。該發明通過增加Mel倒譜參數的維度來提高聲紋識別效率,具體為通過每一幀語音數據獲得該幀語音的Mel倒譜參數,Mel倒譜參數的一階差分參數,二階差分參數以及該幀的說話人基音周期參數,將這四個參數結合成一個(3L+1)維的特征矢量,這樣更逼近語音的動態特征和人體的生理結構,可以提高聲紋識別的效率。
2017年,重慶郵電大學公開了一種基于融合特征M GFCC的說話人二次特征提取方法(C N 107274887A)。該發明首先利用Mel濾波器對說話人語音進行處理得到MFCC特征;其次,同時利用Gammatone濾波器對說話人語音進行處理得到GFCC特征;然后,對兩種特征在噪聲環境下的各維特征區分度進行計算;接著,統計兩種特征的每一維特征處于最大F R值的次數;隨之根據兩種特征在噪聲背景下的最大次數的不同進行特征融合;最后對融合特征進行微分和重組得到二次提取特征。該發明可以在復雜噪聲環境下依然有較好的識別,并且較強的魯棒性,能夠進一步提取出說話人的隱藏特征,在較大程度上提升了說話人識別系統的性能。
2017年,蘇州大學公開了一種用于語音測謊系統中的稀疏譜特征提取方法(C N 10729 3302A)。該發明首先提取語音信號的梅爾頻率譜系數、小波包頻帶倒譜系數,并融合所述梅爾頻率譜系數和小波包頻帶倒譜系數構成倒譜特征;其次,采用K-奇異值分解算法對倒譜特征進行訓練得到混合過完備表示字典;然后,在混合過完備表示字典上,采用正交匹配追蹤算法對倒譜特征進行稀疏編碼,獲取稀疏譜特征。該發明一方面可以彌補傳統梅爾頻率譜系數提供中高頻段信息存在的不足,另一方面可以解決非線性融合參數集的冗余問題,降低分類模型的計算復雜度。
綜上所述,在對特征參數選擇的問題上,目前主流的研究熱點是基于人耳聽覺特性的梅爾倒譜系數(MFCC),并且對于提取MFCC參數的改進基本集中在對于輸入端數據的過濾、對于濾波器的設置個數和位置、計算過程中對于特征的二次提取方式。分析表明,我國高校對于特征提取技術有著持續的關注,且近幾年能夠不斷提出價值較高的技術方案。同時,百度和聯想等涉及人工智能領域的國內大公司也對特征提取技術保持著研究。
六、企業建議
通過以上對于語音識別技術中特征提取技術的專利分析,可知我國在該領域高校的研究熱情較高,且其專利價值也較為客觀。同時,我國涉及人工智能的大公司也對其保持著持續的研究和關注,但鮮有在國外的專利布局。因此,結合我國的技術現狀給出如下企業建議:
(1)宏觀上講,國內公司應當加強校企合作,從技術和人員儲備、產品研發等環節,與涉及研究特征提取技術的高校合作;積極拓展全國知名高校的合作意向和研究領域,以高校技術為依托,企業加強資金投入和產品研制,在全國建立多個技術研究的研發中心。盡可能地把科研成果轉化為可以帶來經濟效益的生產力,同時提高教學質量和科研水平,在實踐中培養高科技人才,促進學校、企業和社會的共同進步為目標,在優勢互補、平等合作、互惠互利、共同發展的基礎上建立全面的校企合作關系。
從技術方面來說,通過上述分析,企業應該吸取高校對于特征提取研究中涉及多算法融合技術的相關技術方案。高校科研工作通常擅長算法研究和模擬仿真,對于提高特征提取精度、魯棒性,提高計算效率、降低復雜度,所提出的方法通常是十分有效,因此具有客觀的借鑒價值。
(2)企業應當培養專業的科研型人才,企業創新的快速發展離不開對專業人才的培養。首先,可以加強與國外人才的交流與合作,借鑒歐美發達國家的先進經驗,培養具有創新精神的研發人才,引進高水平的研發管理系統,在積累企業先進技術的同時解決技術研發過程中遇到的問題。
(3)鼓勵對外專利申請,加快走出去的步伐。近年來,我國在該領域的申請數量連年上升,但在國外專利申請上競爭力仍顯得較為薄弱。未來,我國申請人應當考慮目標市場、國際同行等多種因素進行布局,在布局時不拘泥于現有市場和格局,而是著眼于長遠,適當先于市場,注重海外專利布局能力,利用創新型企業強大的科研實力,搶占國外發達國家專利申請的領域。
七、結束語
語音識別的研究工作對于信息化社會的發展和人民生活水平的提高等方面有著深遠的意義。本文通過對語音識別領域特征提取技術的相關專利進行分析,對我國企業的研究方向和專利布局給出了建議。未來語音識別技術將會取得更多重大突破,特征提取技術的研究也會更加深入,是值得我國申請人關注和研究的重點。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
艦船科學技術(2022年15期)2022-09-14 09:21:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年19期)2018-11-14 02:37:08
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
自動化學報(2017年11期)2017-04-04 02:52:58
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
