基于PCA-Clustering的壓縮機回液故障診斷
2018-08-08 09:57:34
制冷學報 2018年4期
(1 華中科技大學能源與動力工程學院 武漢 430074; 2 珠海格力電器股份有限公司 珠海 5179070)
據有關部門統計,我國建筑能耗約占社會總能耗33%[1],在發達國家如美國其建筑能耗約占社會總能耗的41%[2]。在建筑能耗中,空調能耗約占50%~60%[3],而其中壓縮機又是制冷空調的耗能大件之一。此外,J. E. Braun等[4]研究表明,壓縮機失效約占空調系統維修費用的24%。因此壓縮機故障不僅會對空調系統產生不良影響,造成能耗損失,還會產生高昂的維修費用。因此研究壓縮機回液的故障診斷,具有經濟意義與研究價值。目前對于制冷空調故障檢測與診斷的研究對象多為冷水機組[5-6],故障種類多為制冷劑充注量[7-9]、傳感器故障[ 10-12 ]等,而對于多聯機壓縮機的研究略有不足。L. R. Silva等[13-14]對制冷系統的壓縮機故障檢測進行了研究,主要針對壓縮機閥片泄漏問題。周瑋[15]針對船用氟利昂制冷系統,總結了壓縮機回液產生的原因及控制回液的幾種方法,但其適用范圍局限于船用氟利昂空調系統,沒有給出壓縮機回液故障檢測與診斷的具體方法。王江宇等[16-17]首次提出采用決策樹算法對多聯機壓縮機回液故障進行檢測與診斷,但是出于魯棒性的考慮以及工程應用的需要,其決策樹樹深為兩層,只能利用有限的數據信息。
大數據在空調系統優化、新產品研發、故障診斷、能耗與維護預測等方面提供了新的思路[18],而故障檢測與診斷的傳統建模方法不及時、復雜、準確率低,難以滿足要求,因此利用數據挖掘技術與傳統故障排查相結合是未來的主流方向之一。但目前運用在制冷空調行業的故障檢測與診斷的算法如決策樹、PCA-DT、BT神經網路、SVDD等都是有監督的學習方法,這需要前期進行大量實驗獲得有真實標簽的先驗數據來進行訓練,但有時在實際工程過程中難以滿足條件。無監督的學習方法具有天然的優勢,無需事先獲得數據標簽,可以通過自身算法將數據進行分類從而進行故障檢測與診斷。并且無監督的學習方法已在其他行業驗證了可行性,H. Fernando等[19]采用無監督的人工神經網絡進行自動組裝機器中的故障檢測和識別,孫才新等[20]通過多層次聚類進行了變壓器油中溶解氣體分析故障診斷,陳鐵華等[21]通過模糊聚類進行了水電機組振動故障診斷。本文采用無監督的聚類算法來進行壓縮機回液故障診斷。聚類分析(Clustering analysis)是一種原理簡單、應用廣泛的數據挖掘技術[22]。它通過某種相似性或差異性指標定量確定樣本之間的親疏關系,盡可能的將相似的數據歸為一類,將不相近的數據歸為其他類別,從而到達分類或模式識別等目的。聚類算法能夠有效利用全部的數據信息,不會因為樹深而影響診斷結果的準確率。系譜聚類層次可以任意控制,能夠有效處理不規則的類圓形數據。
本文針對壓縮機回液故障問題,提出了一種基于PCA-Clustering的壓縮機回液故障檢測與診斷的方法,來彌補目前缺乏先驗數據標簽條件下,無法有效的進行壓縮機回液故障檢測與診斷的不足。
1 PCA-Clustering方法原理
PCA-Clustering方法原理為:將前期整理與篩選后的不含真實標簽的數據,通過主成分分析(principle component analysis,PCA)進行數據處理,提取得到新的主元變量解決變量信息冗余問題,依據主元累計方差貢獻率對主元進行篩選,以簡化變量維度。再利用篩選后的主元變量進行聚類建模,得出壓縮機回液故障診斷模型。
1.1 主成分分析(PCA)
假設有n維樣本集Q=(x(1),x(2),…,x(m)),首先按照式(1)對所有樣本進行中心化,得到中心化樣本集Q1。
依據式(2)求出數據集的協方差矩陣,按照式(3)對矩陣XXT進行特征值分解。式(3)中W為XXT的n′個特征向量組成的矩陣,λ為XXT的特征值。
XXTW=λW
(3)
取出最大的n′個特征值對應的特征向量(w1,w2,…,wn′),將所有特征向量標準化后,組成特征向量矩陣W。并按照式(4)對每一個數據集中每一個樣本x(i),都轉化為新的樣本z(I)。
z(i)=WTx(i)
(4)
最后得到輸出的新的數據集Q′=(z(1),z( 2 ),…,z(m))。需要說明的是,新的得到的主元變量z都是原始變量x的線性組合,且各主元變量之間互不相關。
1.2 聚類分析
系譜聚類算法是聚類分析中常用算法之一,先計算通過PCA后獲取的新的主元變量數據之間的距離,每次將距離最近的點合并到同一類,再計算類與類之間的距離,將距離最近的類合并為一個大類。不停的合并,直到合成一個類。具體原理步驟如下:
1) 建立數據樣本兩兩之間的距離相似性矩陣F∈Rn×n,矩陣元素:
2) 采用式(6)計算規范化拉普拉斯矩陣,其中對角度矩陣D滿足式(7):
LN=D-1/2WD-1/2
(6)
3) 確定劃分分子集數目k,建立矩陣V=[v1,v2,…,vk]∈Rn×k,v1,v2,…,vk為拉普拉斯矩陣LN的前k個最大特征值對應的特征向量。
4) 對V的行向量規范化處理,得到單位長度向量矩陣Y∈Rn×k,其中Yij滿足式(8):
5) 將Y的每一行數據當做Rk空間中的一個數據點,運用Kmeans聚類算法將Y中各點劃分為3類。
6) 當且僅當矩陣Y的第i行歸入第j(j∈[1,K])類時,劃分原數據點si至第j類。
2 實驗設置
對于多數空氣調節系統而言,冬季工況與夏季工況相比蒸發溫度低,制冷劑蒸發速率小。因此在制冷劑充注量相同的情況下,壓縮機回液故障更傾向于發生在制熱工況下。所以本文進行的實驗操作均是在制熱工況下完成的。
圖1所示為多聯機系統結構。該多聯機(VRF)系統由右邊5臺室內機,左邊1臺室外機組成。VRF系統采用R410A制冷劑,標準充注量為9.9 kg。在制熱工況下圖中過冷器不工作。虛線表示高壓管路,實線表示低壓管路,帶箭頭的虛線表示故障1(Method#1)引入方式,即在氣液分離器前引入高壓制冷劑;帶箭頭的粗實線表示故障2(Method#2)引入方式,即充注140%的過量制冷劑。圖1中表示出了部分傳感器,數據采集軟件將系統傳感器采集到的數據每3 s記錄一次,并保存到電腦客戶端。正常(normal)、故障1(fault#1)和故障2(fault#2)工況的實驗參數:室內環境溫度設定為22 ℃,室外環境溫度為7 ℃,室內機開機3臺,實驗共獲得數據21 522條,各工況數據量如表1所示。
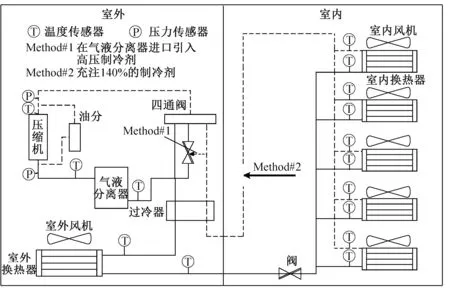
圖1 多聯機系統結構Fig.1 VRF structure

工況數據量/條正常9 348故障16 336故障25 838
3 基于PCA-Clustering回液故障診斷
3.1 回液診斷流程
圖2所示為基于PCA-Clustering的壓縮機回液故障檢測與診斷的流程,由數據獲取、數據處理、數據建模和故障診斷4個步驟組成。
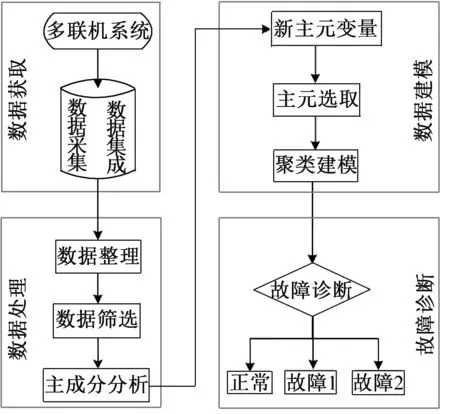
圖2 回液故障診斷流程圖Fig.2 Liquid floodback diagnosis flow chart
1)數據獲取
如圖2所示,首先通過多聯機實驗平臺中的各類傳感器,實時采集實驗的各類變量的參數,同時數據實時傳輸到PC端,然后數據采集軟件對獲得的數據進行集成操作。
2)數據處理
直接獲取的數據,數據質量較差,需要進行處理以免影響診斷結果的準確性。首先由于傳感器故障或其他原因會存在數據缺失,需要對數據進行整理。此外初步采集的數據直接用來建模會降低模型精度,所以在建模之前需要篩選數據變量。最后為解決數據變量信息冗余和減少變量維度,采用主元分析法(PCA)進行數據降維,得到新的主元變量。
3)數據建模
獲取新的主元變量的累計方差貢獻率,選取前面累計方差貢獻率大于95%的主元變量,采用系譜聚類算法,建立聚類診斷模型。
4)故障診斷
將不含數據標簽的數據,在聚類模型中通過聚類分析,進行故障判定,得出分類結果。然后將其分類標簽和實際標簽進行對比,采用可視化圖表進行結果可視化。
3.2 變量篩選
通過傳感器測得的原始數據通常是不完整(某些數據由于傳感器故障而缺失,或缺少屬性值)、含噪聲(包含錯誤或存在離群值)且不一致的(如變量的命名標簽),這樣的數據必須經過預處理,恢復數據完整性和一致性后才能使用數據挖掘技術進行分析。傳感器測得變量多達數百個,首先通過缺失值處理和數據集成將數據進行前期處理。運用已有的專家知識對剩余變量進行篩選。具體操作如下:
1)對于邏輯變量,如熱力膨脹閥控制模塊,其本身就是一個控制參數,它會根據系統的變化而實施自我調控。故這一類變量予以剔除。
2)考慮到回液是一種室外機故障,因此相較于室內機數據,室外機運行數據更能表征回液故障,故將與室內相關參數予以剔除。
3)為了使得數據測量簡便,在數據篩選時偏向選取單一相關變量參數作為回液故障診斷的變量。
4)基于已有的專家知識,初步對變量進行判斷是否對故障有影響。
綜合考慮以上4條篩選原則,將邏輯變量和室外參數予以剔除,通過已有的專家知識,認為壓縮機回液與溫度的相關性較大,考慮到數據測量簡便,盡可能選擇單一變量作為輸入參數,預處理篩選得到6個溫度變量。分別為冷凝飽和溫度(Tcond)、壓縮機排氣溫度(Tcom,dis)、氣液分離器進管溫度(Taccu,in)、氣液分離器出管溫度(Taccu,out)、蒸發飽和溫度(Tevap)、壓縮機殼頂溫度(Tcond,shell)。
為使數據更直觀、可視化,并展示變量在不同工況下的差異性和總體情況,本文采用數據變量箱體圖來進行數據概覽,如圖3所示。為了便于對比和可視化,將數據先進行標準化,再用boxplot函數繪制出箱體圖。圖3中中間粗實線表示數據中位數,上下細實線表示上四分位數和下四分位數。由圖3可知,無論在何種工況下均存在一定數量的異常值,即數值偏離在主箱體圖之外的數據。每一類變量的不同工況之間的差異性并不大,因此采用PCA獲取原始變量的綜合變量,可能會提高診斷結果的準確率。
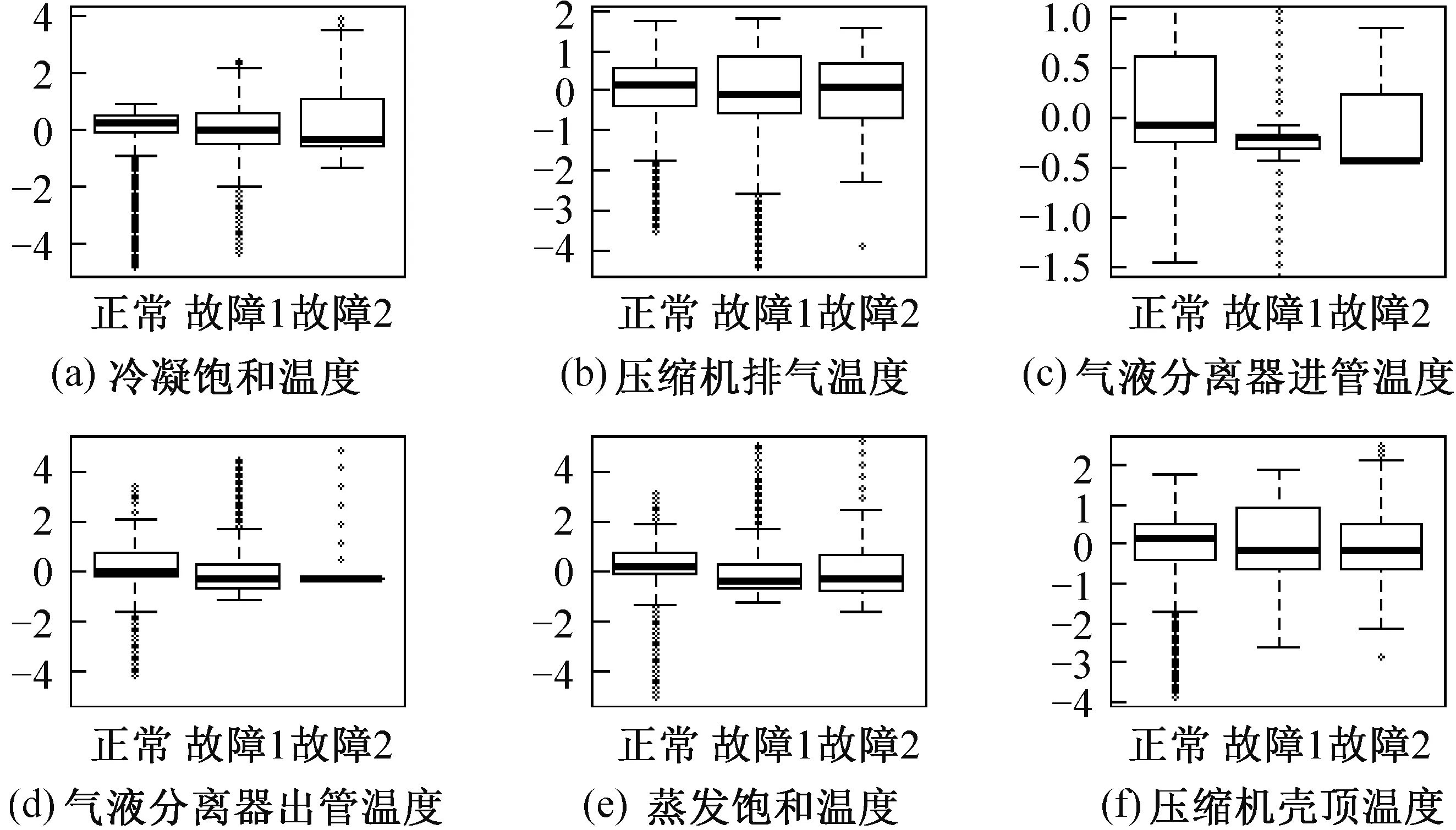
圖3 數據變量概覽箱體圖Fig.3 Data variables overview box diagram
3.3 主成分分析處理數據
由1.1節可知,主成分分析法能夠在保證原始變量主要信息的前提下,通過原來變量的少數幾個線性組合來解釋隨機向量的方差-協方差結構,以此來降低變量的維度,使得問題簡化。故將變量篩選處理后的數據進行主成分分析,得到新的主元變量。原始變量與新主元變量的關系如表2所示。表中數據表示構成新主元變量中原始變量的線性系數。
為了可視化新主元變量數據在不同工況下的情況,采用箱體圖獲得的新主元變量概況如圖4所示。由圖4可知,前面主元1與主元2,在不同工況下差異性較大,區分較為明顯,且所包含的異常值也較少。
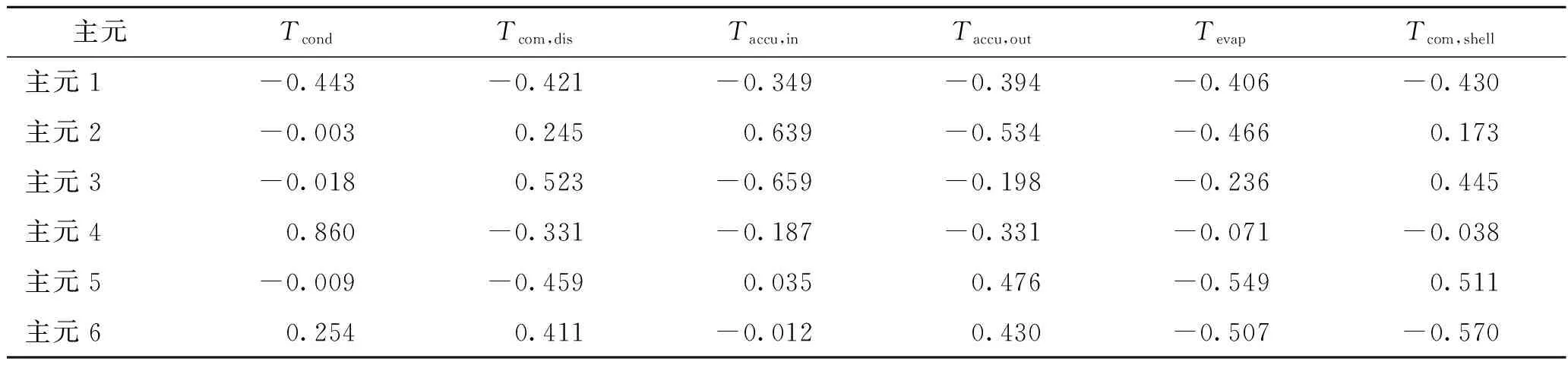
表2 主元變量與原始變量線性關系表Tab.2 The linear relationship between the principal variable and the original variable
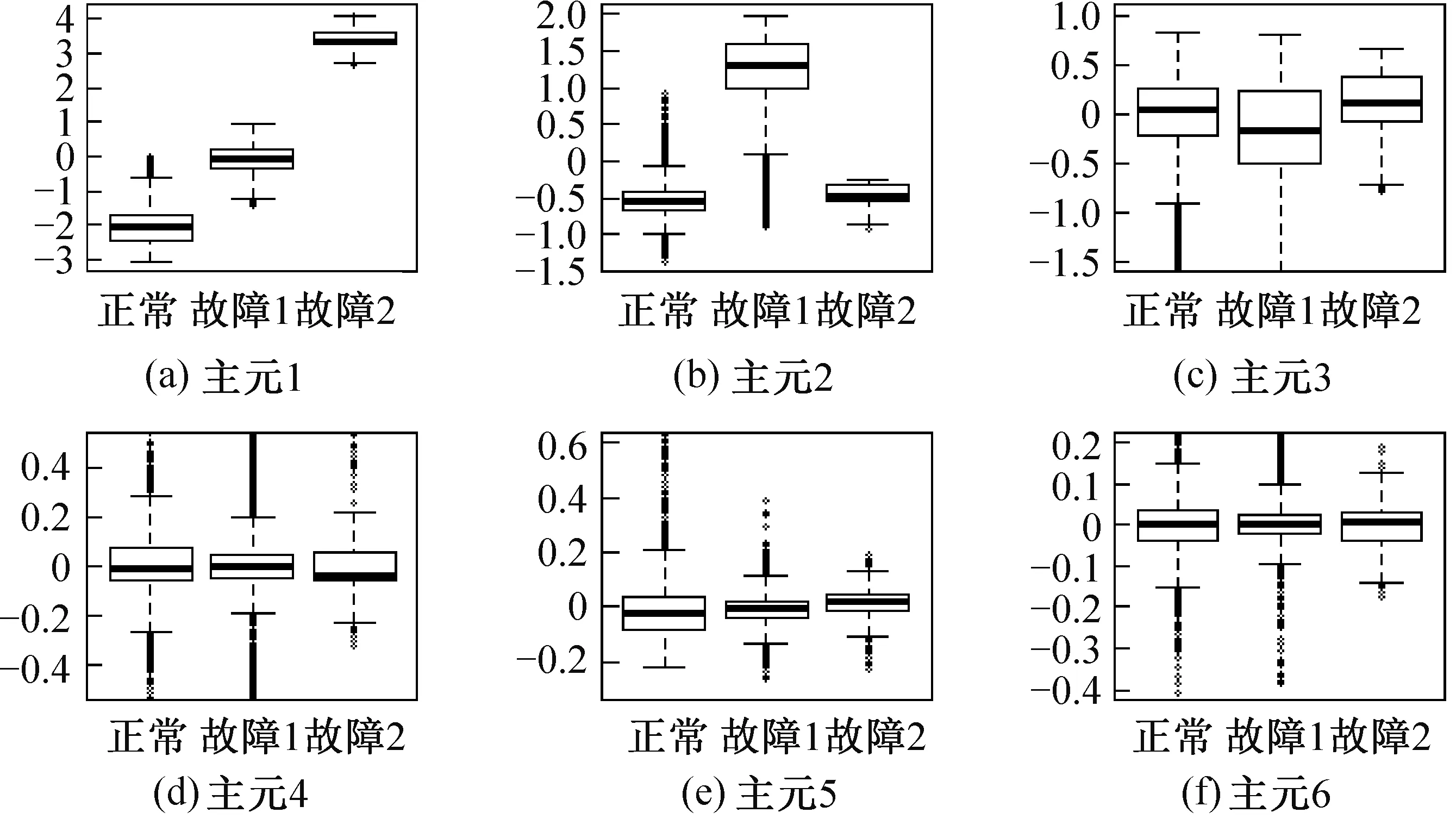
圖4 主元變量箱體圖Fig.4 The principal variable box figure
圖5所示為主元分析后主成分方差貢獻率和累計方差貢獻率。由圖5可知,前兩個主成分的累計貢獻率為96.0%,與圖4分析結果一致,因此可以認為主元1和主元2包含了數據的絕大多數信息,故可以舍去剩余的主成分,僅保留主元1和主元2進行聚類,可以達到降維,簡化計算的效果。

圖5 主成分方差貢獻率Fig.5 Principal Component variance contribution rate
4 故障診斷與結果分析
選取主元1和主元2兩個主成分進行聚類分析。事先無需知曉數據類別標簽,聚類算法自動按照選定的分類數目(正常、故障1和故障2)進行分類。為了使聚類結果可視化,繪制了聚類散點圖,得到聚類結果圖,如圖6所示。為便于分析對比故障診斷聚類結果,采用真實數據標簽繪制數據散點圖,如圖7所示。
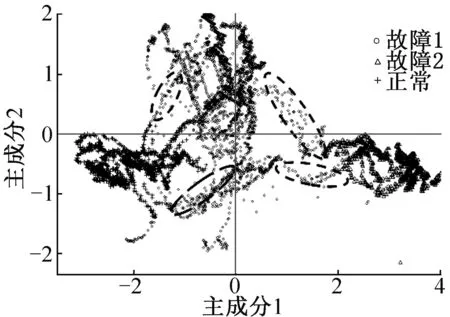
圖6 故障診斷聚類結果圖Fig.6 Fault diagnosis clustering result graph
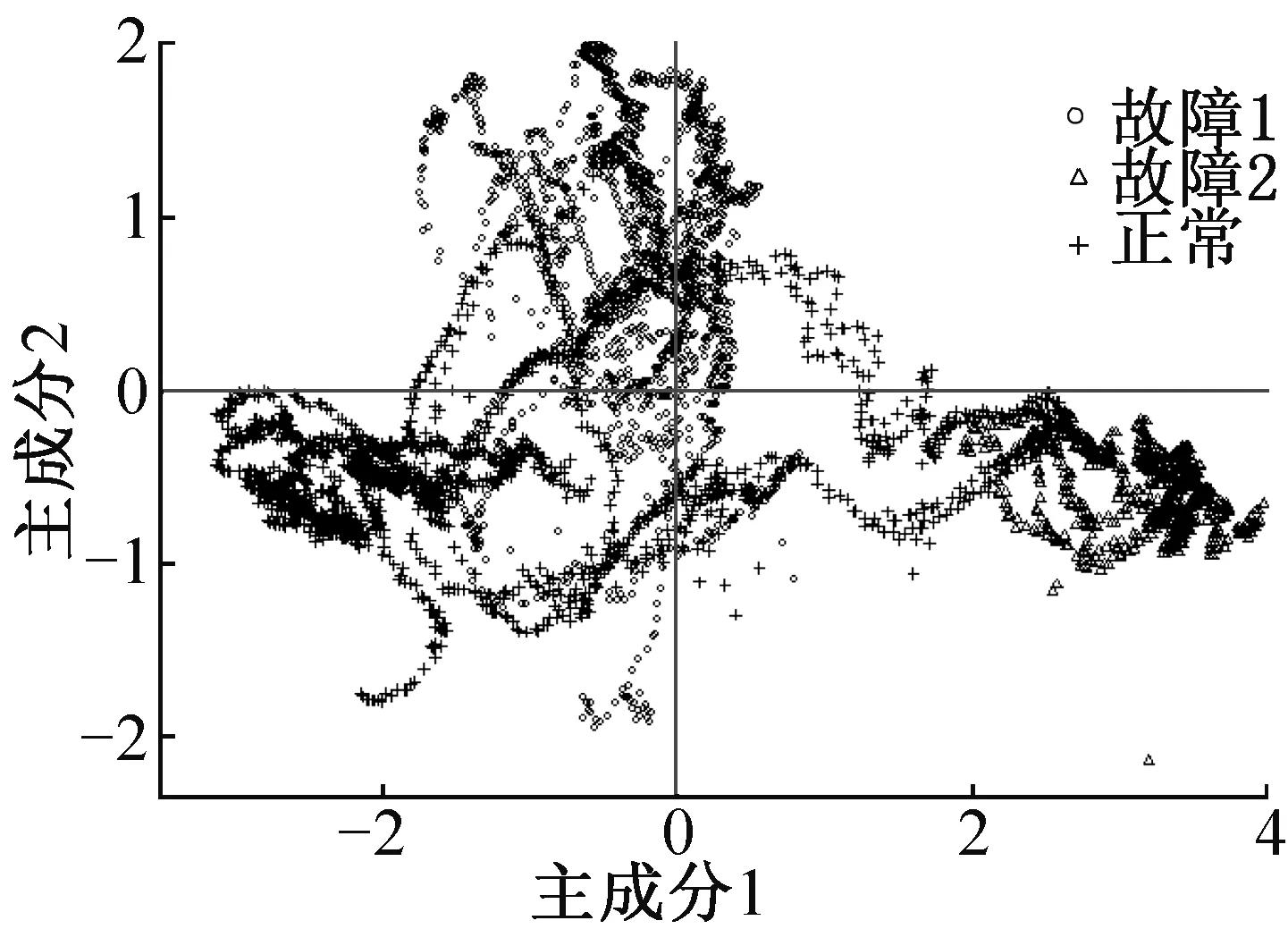
圖7 數據真實標簽散點圖Fig.7 Data true tag scatter plot
由圖6可知,整個聚類結果較為理想,同類工況數據聚合緊密,異類工況相互交雜的部位較少,各類別工況大體區分明顯。對比圖6與圖7可得,主要診斷異常區域在于,圖6虛線框所標記的不同工況交合處。一方面可能是數據本身存在異常值,即數據標簽
有誤;另一方面因為依據距離作為標準的聚類算法對距離相近的異類工況判斷存在缺陷。但圖6中該區域數據點較為疏散,證明數據量較少,整體診斷結果仍較為良好。
采用混淆矩陣展示故障診斷具體分類情況。基于PCA-Clustering模型診斷結果的混淆矩陣如表3所示。由表3可得總數據結果準確率為94.29%,其中故障1工況的檢測結果準確率較其它兩類工況低,結合圖7分析可知故障1工況數據標簽散點圖分布散亂,有較多的數據與正常工況和故障2工況交合,說明該數據原本標簽具有較多異常值。此外對于正常工況和故障2工況的診斷準確率分別為97.39%、95.69%,診斷結果均較為理想。

表3 模型診斷結果混淆矩陣Tab.3 Model diagnostic results confusion matrix
為進一步佐證采用無監督的回液故障診斷結果準確率的可信度,本文將診斷結果與采用有監督的決策樹算法[17]進行的壓縮機回液故障診斷進行了對比。圖8所示為兩種模型診斷結果對比。從圖8可以看出,無監督基于PCA-Clustering的總數據故障診斷結果與Wang Jiangyu等[17]提出的有監督決策樹模型相差2.21%,并且在正常工況和故障2工況下的診斷效果還有所提升。因此無監督的基于PCA-Clustering的壓縮機回液故障診斷模型能夠在無有效的訓練數據的情況下,較好地診斷壓縮機回液故障。
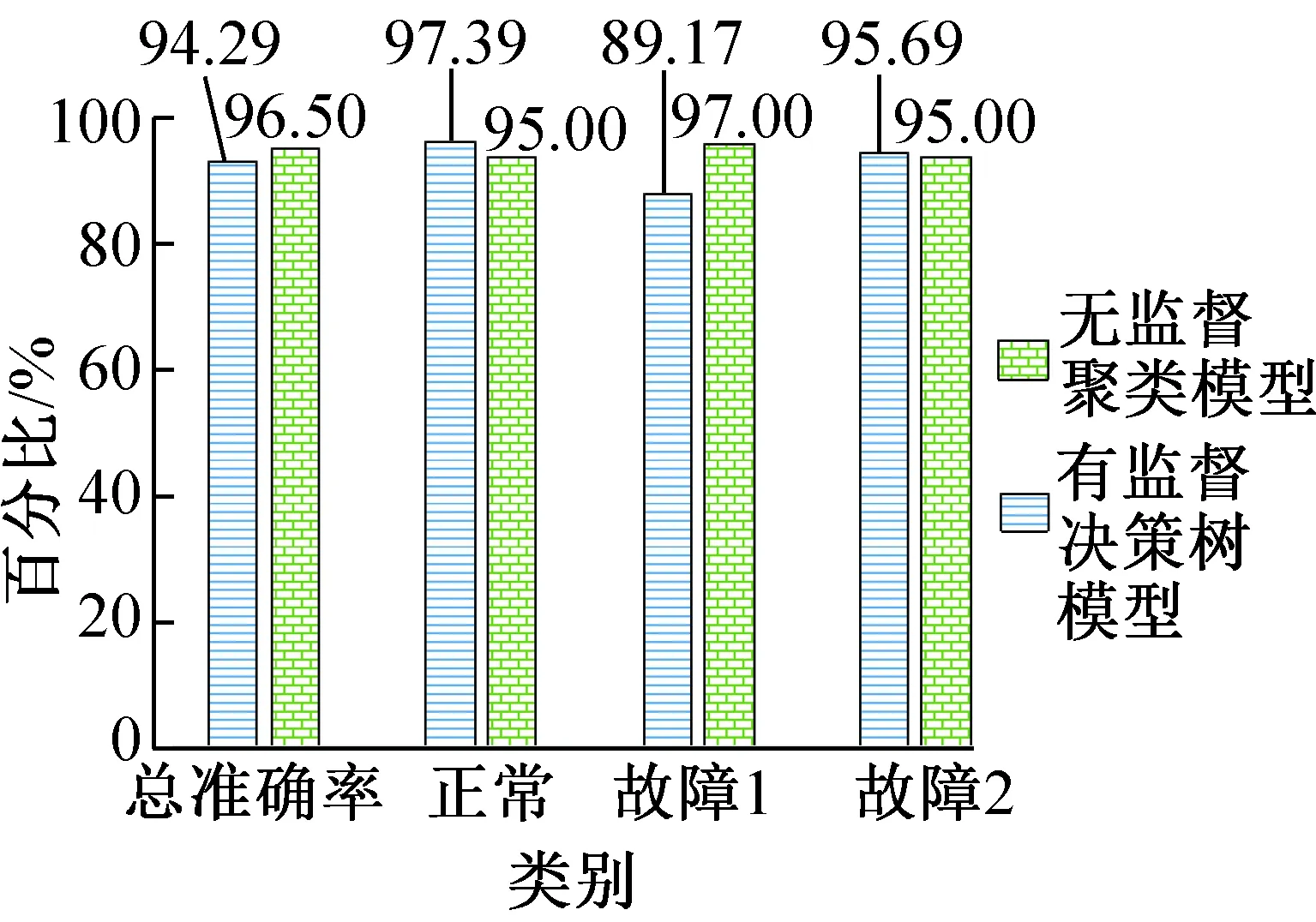
圖8 聚類模型與決策樹模型診斷結果對比Fig.8 Comparison of clustering model and decision tree model
5 結論
本文利用制冷劑為R410A,標準充注量為9.9 kg的多聯機系統,在室內環境溫度設定為22 ℃,室外環境溫度為7 ℃,室內機開機3臺的實驗參數條件下運行,獲取了21 522條運行數據,提出了一種基于PCA-Clustering的壓縮機回液故障診斷的方法,首先運用主成分分析法對變量數據進行前期處理,提取出主元變量,然后采用聚類分析對無類別標簽的數據劃分。該方法采用無監督的學習方法,事先無需獲取有真實標簽的先驗數據,在一定程度上滿足了工程實際的應用。此外,通過結果分析和對比,認為該方法能夠較好的在無法獲得數據標簽的前提下,也能像有監督的決策樹模型一樣,達到較高的故障診斷準確率,有效的進行壓縮機回液故障診斷。相關結論如下:
1)利用主成分分析法來形成新的主元變量,有效解決了變量信息冗余問題和簡化了變量維度。
2)無監督的基于PCA-Clustering模型的診斷準確率為94.29%,有監督的決策樹模型準確率為96.50%,這表明無監督的基于PCA-Clustering的壓縮機回液故障診斷的方法,在無法獲得數據標簽的前提下,也能像有監督的決策樹模型一樣,達到較高的故障診斷準確率,有效的進行壓縮機回液故障診斷。
本文受空調設備及系統運行節能國家重點實驗室開放基金項目(SKLACKF201606)資助。 (The project was supported by the State Key Laboratory of Air-conditioning Equipment and System Operation (No. SKLACKF201606).)
猜你喜歡
裝備制造技術(2020年3期)2020-12-25 05:22:30
汽車維修與保養(2019年7期)2020-01-06 03:30:42
北京航空航天大學學報(2016年6期)2016-11-16 01:50:43
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維修與保養(2015年2期)2015-04-17 01:30:34
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
