基于深度學習的運動目標實時識別與定位①
2018-08-17 12:06:16童基均常曉龍趙英杰蔣路茸
計算機系統應用 2018年8期
童基均,常曉龍,趙英杰,蔣路茸
(浙江理工大學 信息學院,杭州 310018)
1 引言
目標檢測與定位是計算機視覺領域中一個重要的研究課題[1].檢測出感興趣目標及其位置是計算機視覺科研工作者關注的重點[2].傳統的檢測方法通過特征提取、多特征融合進行目標檢測.例如通過提取HOG[3]、LBP[4,5]和SIFT[6]特征,將提取到的特征通過SVM[7]或者AdaBoost[8]等分類器進行分類識別.但隨著場景的變換、光照的影響以及實時性要求等使得傳統方法無法滿足人們的需求.
近幾年深度學習由于其快速的處理能力和較高的準確率在計算機視覺中得到廣泛應用,使得在一些復雜條件下利用視覺對場景進行分析成為可能.2012年Krizhevsky等[9]采用AlexNet網絡的卷積神經網絡(Convolutional Neural Networks,CNN)在ImageNet圖像分類中取得了最好的成績.最初將深度學習應用到目標檢測的是Girshick[10]等提出的R-CNN(Regionbased Convolutional Neural Networks)方法.R-CNN將區域建議(region proposal)[11,12]和卷積神經網絡相結合,但是在速度與精度上還無法滿足人們的需求.而后,He[9]等人提出SPP-Net、Girshick[13]等人提出Fast RCNN以及Ren[14]等人提出的Faster R-CNN都是在最開始的R-CNN的基礎上進一步的改進,且都是基于區域建議框,因此其速度都受到一定限制.針對此問題,有研究者提出了一系列的基于無區域建議的方法:如Redmond[15]等提出的YOLO(You Only Look Once)已經達到了實時檢測的效果,但是檢測精度確不夠理想,隨后Liu[16]等人提出SSD(Single Shot multibox Detector)模型,在提高檢測精度的同時也兼顧到了實時性的要求,可以說是一個相對而言比較理想的一個算法.本文就是基于此算法構建了人體運動檢測模型.
2 系統架構
本系統首先用不同的視覺標記物對運動目標進行一定的標記,并通學習訓練相應的模型;接著通過深度學習技術對穿戴標記物的運動人體進行檢測和識別,文中標記物為自己設計的不同顏色和紋理的帽子,通過檢測人體所佩戴的標記物來唯一識別每一個個體,便于后面做定位,因此只需對標記物進行訓練,當人員更換時只需佩戴相應的視覺標記物而不需要重新訓練;最后利用立體視覺定位算法對其進行定位,從而實現人體運動目標實時檢測與定位.
本視覺定位系統通過2路高清網絡攝像機獲取視頻碼流,直接輸出數字信號,省去了圖像采集卡將模擬信號轉化為數字信號的操作.視頻實時流首先通過解碼服務器將碼流轉換為能夠處理的圖像格式,然后在分析管理服務器上進行多路視頻同步、檢測以及定位等操作,將結果反饋給客戶端,分析管理服務器同時也負責接受客戶端的控制指令.視頻檢測流程圖如圖1所示.
2.1 多線程并行視頻流采集
視頻采集端采用2個網絡攝像頭進行采集,利用ffmpeg中的解碼庫,將相機輸出的rtsp實時流通過解協議、解封裝最終將視頻解碼成在RGB顏色空間上的圖像格式,同時利用pthread多線程處理庫,通過互斥鎖和信號量實現多相機并行采集以及同步問題.
2.2 人體運動目標檢測
目標檢測部分采用深度學習框架Caffe[17],利用SSD物體檢測模型進行運動人體的檢測.該方法既保證了目標檢測的精度,又保證了目標檢測的速度.SSD方法的核心是使用小的卷積濾波器來預測特征圖上固定的一組默認邊界框的類別分數與位置偏移量.從不同尺度的特征圖上產生不同尺度的預測,并通過不同的寬高比來正確的進行預測.一個單次檢測器SSD用于多類別目標檢測,比YOLO速度更塊,和使用區域建議、pooling技術的檢測方法(faster R-CNN)一樣準確.SSD目標檢測的原理如圖2所示.
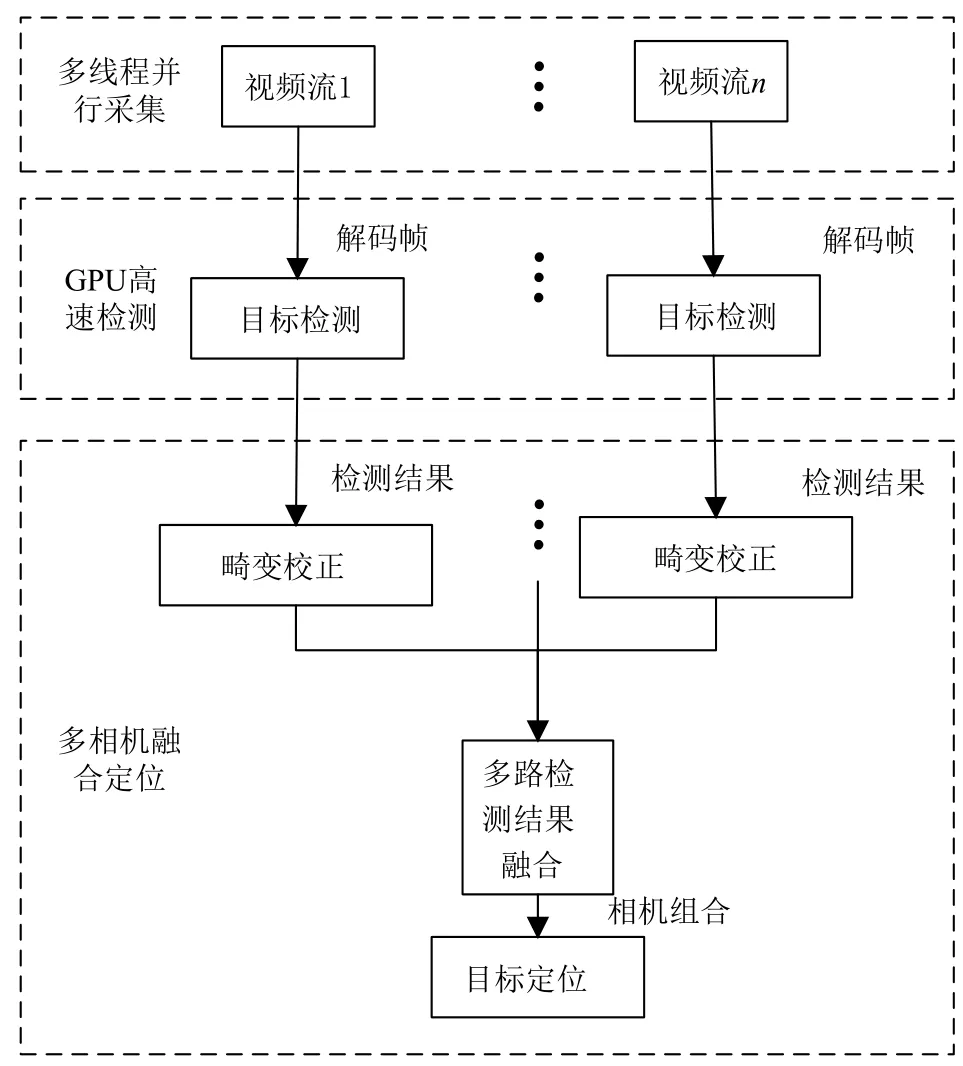
圖1 人體運動目標實時檢測定位流程圖
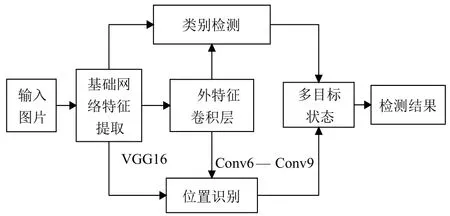
圖2 SSD檢測原理圖
2.2.1 SSD網絡模型
SSD是基于前饋卷積神經網絡,產生固定大小的邊界框集合和邊界框中對象類別的分數,然后通過非最大抑制來產生最終檢測結果.本文采用VGG16[18]網絡作為基礎網絡,用于特征提取,然后再向基礎網絡中添加輔助結構,產生特定的特征用于檢測[15].如圖3所示,這些特征層的尺度逐漸變小,可以得到多個尺度檢測的預測值.
2.2.2 訓練
SSD的訓練與傳統方法的區別在于真實標簽需要與固定的檢測器輸出集合中的某一個特定的輸出相對應(端到端訓練).訓練時,需要建立默認框與真實框之間的一一對應關系[15].可以從不同位置、尺度、寬高比的默認框中選擇真實的目標標簽框.
2.3 雙目定位
雙目定位首先需要考慮攝像機的標定與圖像的畸變矯正問題.本文采用張正友的基于平面模版的標定方法[19],然后進行去畸變處理,得到合理的相機標定結果.
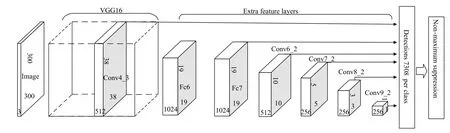
圖3 SSD網絡結構圖
圖4 中oc為攝像機的光心,zc為光軸,(u,v)為像素坐標,o(u0,v0)為圖像坐標系原點,oco為攝像機的焦距f,圖像坐標與像素值的對應關系為:
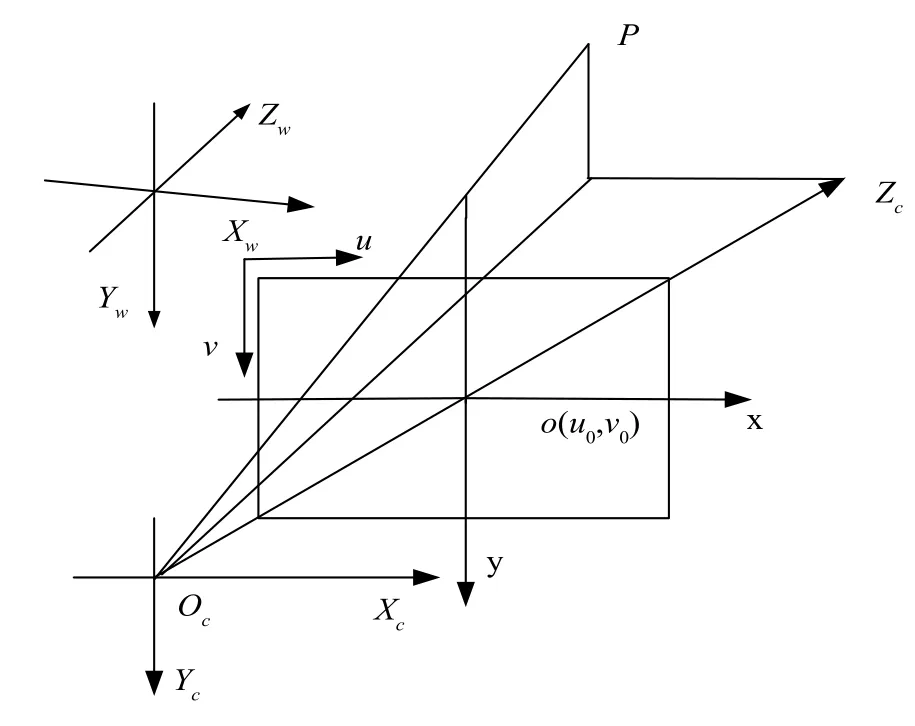
圖4 相機成像模型
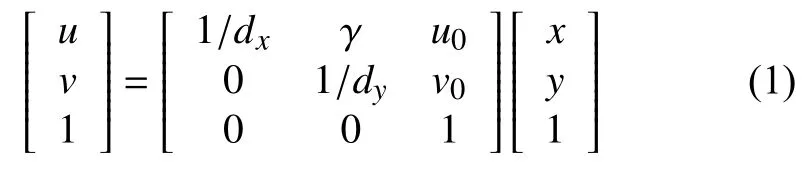
其中,dx,dy為單位像素的物理長度.相機坐標與圖像坐標的對應關系為:
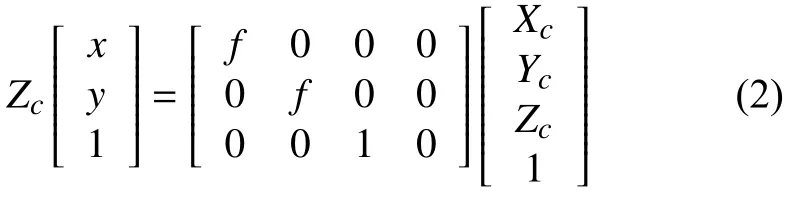
世界坐標系與相機坐標系的對應關系為:

綜合公式(1)(2)(3)可得圖像坐標系(像素表示法)與世界坐標系的關系公式如下:
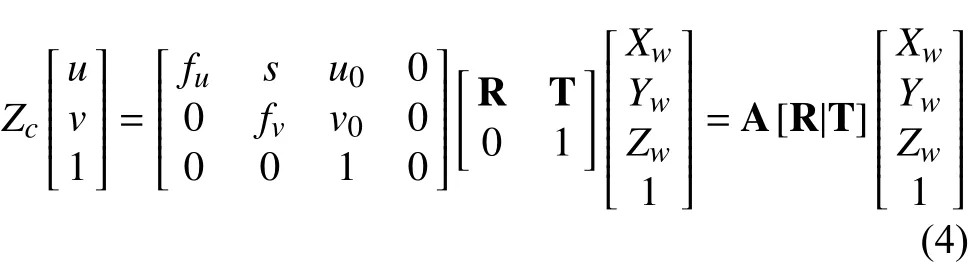
在公式(4)中(Xw,Yw,Zw)為自定義的世界坐標系,(u,v)為圖像坐標系.A為相機的內參矩陣,R,T為旋轉和平移矩陣,即外參矩陣.
本文自定義世界坐標,用Matlab工具箱中棋盤格標定法來求得兩個相機的內參數矩陣A1,A2、以及兩個相機的畸變系數k1;k2,由相機的內參矩陣和畸變系數可以得到無畸變的圖片,根據求得的無畸變圖以及對應自定義的世界坐標中的10組對應點,根據公式(5)可求出世界坐標與相機坐標的單映矩陣H.

再由地平面與圖像平面之間的單應關系可以求得相機坐標系和世界坐標系之間的旋轉矩陣R和平移矩陣T.設H=[h1,h2,h3],在已知內參數矩陣的情況下容易通過下面的公式(6)解得兩個相機的外參數RT1和RT2.
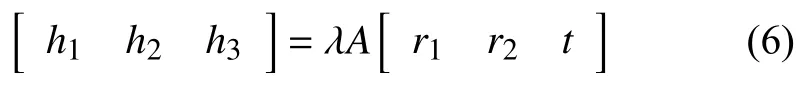
為獲取目標在世界坐標中的位置信息,需由兩個攝像機對目標進行定位.攝像機參數見表1.
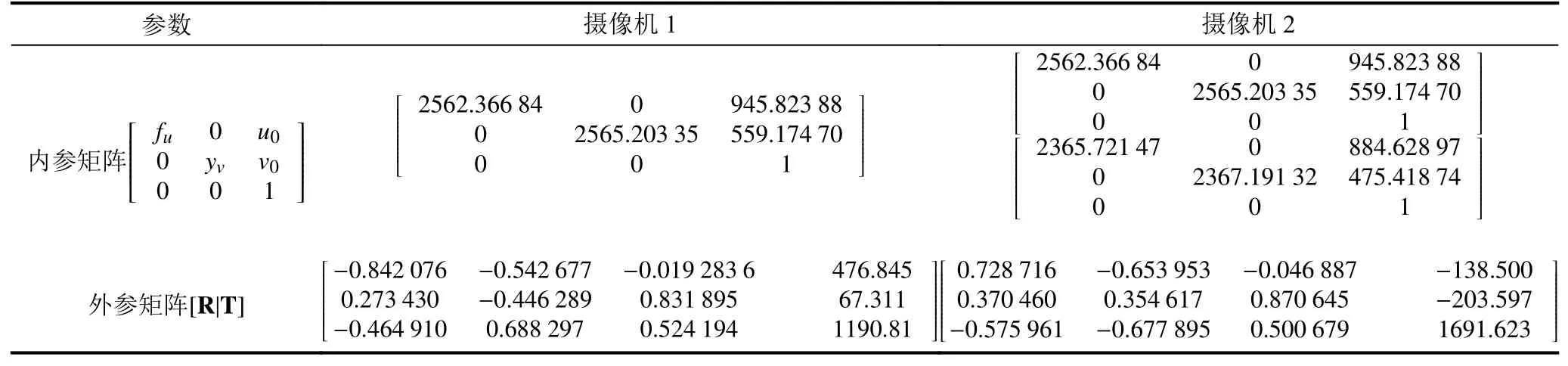
表1 相機參數表
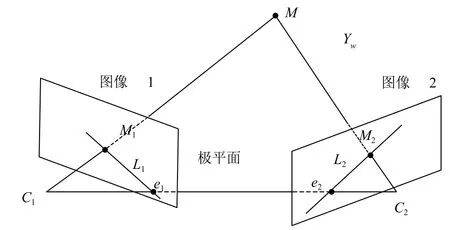
圖5 雙目相機極線幾何約束模型圖
根據如圖5所示的約束模型,設兩個攝像機的投影矩陣為P1,P2:
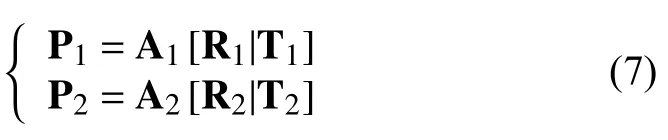
點m為 自定義坐標下的點,點m1和點m2為點m在兩個相機中的投{影點,兩個投影線和基線C1C2形成了一個三角形,則s1m1=p1m,因此利用三角形定位原理s2m2=p2m計算空間坐標點m.
3 實驗
本文采集相機為Dahua DH-IPC-HF8431E,圖像分辨率為1920×1080,訓練和檢測的電腦硬件配置為:CPU:Intel Core i7-6850K CPU @ 3.60 GHz;GPU:NVIDIA GeForce GTX 1080 Ti,11 G×2.
3.1 數據集制作
本文是針對特定場景設計的一套運動目標檢測與定位系統.以一個10 m×10 m的室內場景中運動的人體為檢測目標,每一個運動目標佩戴一頂不同的帽子作為視覺標定物,通過4路相機采集不同視角的圖片數據作為樣本集,然后通過人工對采集的數據進行標注.本文對于10個目標的場景的數據集包括:Images:752 張/JPG,Labels:752 個/XML,BoundingBoxes:7520個/Rectangles.訓練集有632張圖片,測試集有120張圖片,比例大概為5:1.驗證集分為兩個場景,每個場景中都有10個運動目標,共956張圖片.
3.2 模型訓練
訓練時采用VGG16作為本次實驗的基礎網絡,并將最后的fc8層和所有dropout[20]層去掉,將fc6和fc7轉化為卷積層[13],將pool5的2x2-s2改為3x3-s1,并使用atrous算法填洞.使用GSD對網絡進行微調,設置初始學習率為0.000 25,采用 multistep的方法對學習率進行改變,gamma設置為0.1,即當迭代到30 000,40 000,50 000次時,學習率改為原來的0.1倍.Momentum為0.9,weight_decay為0.0005,batch_size為32,總共訓練60 000次,總共訓練時間約為60個小時,最后兩次訓練得出的精度分別達到96.2%和92.4%.利用訓練好的模型(.caffemodel文件)就可以對圖片視頻進行檢測.使用網絡中的conv4_3,fc7,conv6_2,conv7_2,conv8_2 和 conv9_2總共 6 個不同尺度的特征圖上進行預測置信度和位置.
通過2.3節方法求得相機的內參A和參矩陣H,并利用兩路網絡攝像機的目標檢測結果進行定位.
4 結果與分析
從圖6中的網絡訓練精度與損失函數中可以看到當訓練迭代到3萬次的時候,損失函數基本保持不變,檢測精度也在3萬次以后趨于穩定,在95%左右.利用訓練好的模型對視頻的每一幀進行檢測.實驗統計檢測識別結果如表2.

圖6 網絡訓練精度與損失函數圖

表2 目標識別結果(σ=0.2)
表中的σ為置信度,表示每個目標在檢測網絡中默認框與真實目標框的IOU大于0.45時默認框數量的多少.當σ=0.6時,每個目標的漏檢率相對較高,當σ=0.2時,誤檢率都有明顯的下降.如表3,為兩個場景視頻中隨機抽取一幀的檢測情況,場景1中,σ=0.6時,檢測到3個目標,σ=0.2時,檢測到9個目標;在場景2中σ=0.6時,檢測到5個目標,當σ=0.2時,檢測到所有目標.

表3 不同σ檢測結果圖
通過上面的兩次測試結果可知當σ=0.2時,檢測效果最好,因此將σ設0.2,利用訓練好的模型對視頻中的目標場景進行檢測和定位,隨機選取12幀定位結果進行分析,定位結果如表4.
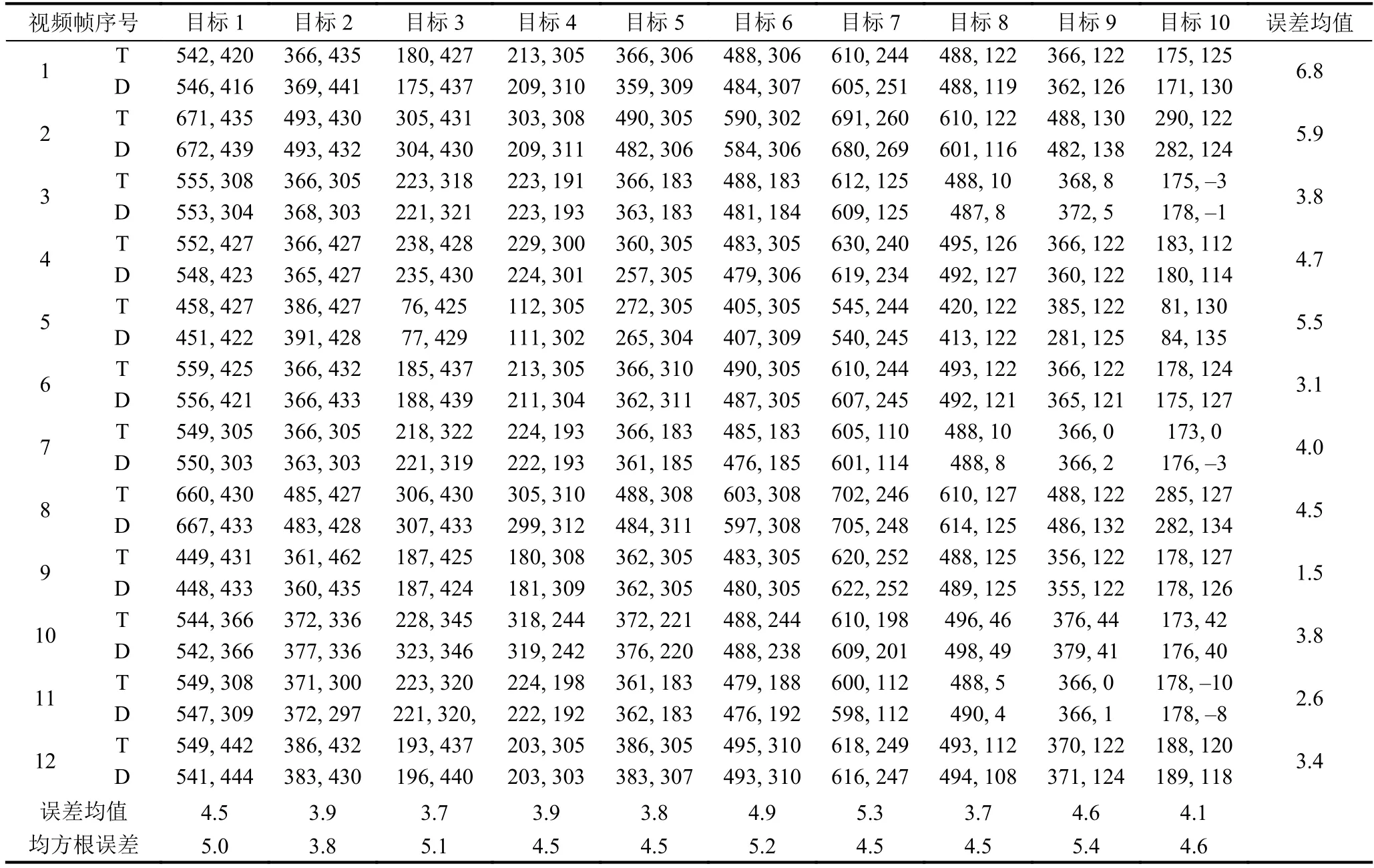
表4 目標定位誤差(單位:cm)
表4中T表示真實目標的坐標,D標表示檢測定位的坐標.從檢測定位結果表中可以觀察得出給個每個定位目標的平均定位誤差在6 cm以內,每幀檢測的所有目標的平均定位誤差也在6 cm以內,12幀圖片的所有檢測目標的平均定位誤差為4.17 cm,均方跟誤差在4.5左右,檢測速度可以達到40 fps以上,完全可以實現實時檢測的效果.需要說明一點,本文處理的圖片大小為1920×1080像素,處理圖片的分辨率一般較大,因此分辨率較大的圖片進行處理實現40 fps左右是一個相當有參考價值的方法.

圖7 目標檢測定位圖
5 總結
本文利用深度學習框架,采用SSD目標檢測方法和雙目視覺定位,實現人體運動目標實時檢測和定位.文中采用的SSD模型檢測方法與其他的利用神經網絡的檢測方法相比,省去了區域預測和特征重采樣的過程,因此檢測速度大大增加.本文提供的定位方法平均誤差在6 cm以內,具有較高的精度,且檢測速度可以達到40 fps以上.
本文的運動目標檢測與定位方法對于固定場景檢測定位效果較為理想,而針對小目標的場景,以及運動目標遮擋比較嚴重的情況下,會出現某個相機漏檢和誤檢的情況,可以通過以下兩種方法進一步研究:
1)通過增加多路攝像機,兩兩配對,增加融合機制,提高檢測結果;
2)目前使用的是VGG16作為基礎網絡,隨著計算機性能的提升,可以使用更深層次的網絡,例如ResNet、GoogleNet等作為基礎網絡或者從新設計網絡結構來提高檢測效果.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
