移動端非顯式用戶身份信息的隱私問題研究①
2018-08-17 12:06:54代遵志滕彩峰張路橋
計算機系統應用 2018年8期
張 穎,代遵志,滕彩峰,張路橋
(成都信息工程大學 網絡空間安全學院,成都 610000)
隨著社會的發展,人們對隱私保護的重視程度越來越高,大家對隱私問題越來越敏感,移動互聯網隱私安全研究逐漸成為一個熱點.傳統的隱私保護技術主要分為3類:數據擾動技術、數據加密技術和數據匿名化技術[1].通過這些技術,我們能有效保護個人隱私,但是在日常生活中不經意間隱私信息可能會就被泄漏,從用戶的角度看,微量隱私[2]的泄露也許并無嚴重后果,但難以證實的是,通過獲取大量用戶的數據,利用機器學習分析用戶行為習慣可能會得到用戶其他隱私信息,用戶的身份信息,以及社會關系,現階段這方面的研究是很少的.
為了更好的保護我們的隱私,我們得知道隱私泄露的途徑有哪些,一個應用可以通過哪些信息得到我們的隱私數據.顯而易見,隱私數據包括通信錄,通話記錄,聊天記錄,短信[3]等等這些有明顯身份信息的顯式信息,而另一方面一個應用不僅可以收集上傳信息,也可以在不需要額外的權限下收集一些非顯式的用戶身份信息,這方面是經常被忽略的,而本文的研究目的就是去分析這些非顯式的用戶身份信息是否對用戶的隱私產生威脅,如果產生威脅的程度有多大,這個衡量的標準取決于通過這些信息挖掘出用戶身份的準確率[4].準確率越高那么產生的威脅越大,也叫告訴我們在使用手機的過程中,為了保護我們的隱私[5]也要額外警惕不良應用收集這些非顯式的身份信息,有需要的話可以利用Android系統權限限制,禁止應用使用某些權限.
本文通過志愿者來采集智能手機使用過程中產生的不包含任何顯式用戶身份信息的用戶行為數據,通過分析數據對用戶身份進行識別,推測他們的社會關系,并研究哪些數據會對用戶隱私產生威脅,而這些數據造成的隱私泄露不容小覷,應該對非顯式用戶身份信息加以保護,使用過程中加以限制,幫助普通用戶更好的保護隱私.
1 國內外研究現狀
對于移動互聯網隱私安全的研究很早就開始了,并且對于移動用戶信息隱私的泄露和保護的研究也逐漸成為一個熱點.文獻[6]是利用手機傳感器數據加上蜂窩網及Wi-Fi網絡信息強度等參數實現對用戶連接AP時長的預測.文獻[7]利用用戶與AP關聯數據實現對用戶身份預測,并證明了僅僅通過對設備編號的哈希等匿名化處理是不能夠有效保護用戶隱私的.文獻[8]利用手機使用過程中所產生的網絡流量對用戶網絡使用行為進行統計學分析.文獻[9]利用了用戶在不同類型地點連接網絡時體現出來的網絡使用方式的差異,實現了用戶所在地點類別的識別.現階段大多是利用Wi-Fi網絡信息、AP關聯數據、用戶手機使用行為等直接對個體或群體層面進行用戶行為分析預測,而關于非顯式的用戶身份信息對用戶的隱私保護的研究還不完善,本文就此進行研究.
2 用戶行為數據處理流程
人們在智能手機使用的過程中會產生各種各樣的數據,絕大部分的數據本身是不包括和攜帶任何用戶身份信息的[10,11],這些原始信息如果沒有經過特殊處理是不會對用戶隱私產生威脅的.但是通過采集大量用戶數據建立用戶行為特征庫,可以實現對用戶身份信息進行識別,甚至推測用戶的社會關系.
2.1 移動端非顯示身份信息數據采集階段
數據采集階段主要根據需求采集相應的非顯式身份信息,即這些信息是不直接標識用戶身份的.因為這些數據均與用戶使用習慣和行為存在著直接或者間接的聯系,可以通過分析對用戶身份進行識別,并且一個正常的應用收集這些信息也不需要申請其他敏感權限.這些信息詳情見基礎數據表1.

表1 基礎數據表
① 網絡流量信息、Wi-Fi網絡信息以及移動蜂窩網信息:這些信息反映了用戶網絡使用習慣,網絡連接的偏好,智能手機安裝應用產生的網絡流量,推測用戶選擇的通信運營商等等.另外,Wi-Fi網絡的SSID信息和蜂窩網基站信息都間接隱藏著用戶的地理位置信息,這種對應關系可以經過推測能得到用戶訪問的歷史位置信息,可以通過構建每位用戶連接過的Wi-Fi網絡集合,對用戶社會關系進行推測.
② 屏幕狀態信息:通過每一次屏幕的點亮熄滅的時間間隔、一段時間的點亮次數,知道用戶各個時段手機使用時長等習慣,推測用戶使用手機強度和頻率.
③ 電池電量信息:用戶使用手機的充電方式,充電時間規律等行為習慣的體現.
④ 手機陀螺儀、光敏傳感器:是對用戶使用手機時的環境、拿握手機的姿勢(睡姿或者坐姿),手機攜帶方式(隨身攜帶或者放置在桌面上等)行為的體現.
除此之外,還會采集設備的國際移動設備標識(International Mobile Equipment Identity,IMEI)[12]為用戶身份標定,以便進行實驗結果的準確率的驗證.
本次采集的數據未包含任何顯式的用戶身份信息,與數據相對應的時間戳也同步記錄.為此我們開發了一個數據采集系統安裝在志愿者的手機上去采集這些數據,此系統包括Android手機客戶端,Python自動化腳本,用戶行為特征數據庫.
2.2 移動端非顯示身份信息數據預處理和特征選取階段
數據預處理階段主要是從采集到的數據中提取與用戶行為有關的數據,通過腳本導入數據庫,剔除無效數據,再根據采集數據類型進行分類,以便于后期進一步處理[13].
對于數據包大小、數據量等數值數據,將根據其采集時間進行分箱,數據分箱后可以進一步得到其最大值,最小值、均值等統計學特征.網絡連接狀態,充電狀態等布爾型的數據可以通過計算轉化為網絡連接時長,充電時長等數據,再計算其統計學特征.最后,去除部分相關性較高的數據,例如:電池電量消耗速度與屏幕點亮熄滅的頻率等,以降低后續數據處理的復雜度.
2.3 移動端非顯示身份信息數據分析階段
數據分析階段結合預處理后的數據和數據分析模型實現用戶行為的分析和身份的識別,推測出其存在的社會關系.為降低難度和提高識別率,前期可通過數據可視化技術得到一些統計學特征和趨勢圖,使用Weka分類算法中的J48(決策樹C4.5)將數據預處理后充電時長,充電間隔,屏幕點亮時長,屏幕點亮間隔,網絡流量大小,并以天為單位進行分箱,得到輸入的樣本數據,構建決策樹從而對用戶分類識別[14],再根據這些信息選取適當的數據使用皮爾森相關系數等方式描述用戶行為,推測其社會關系.
3 數據分析
3.1 用戶識別
目前小規模收集的有效數據有八萬多條,包括5名用戶對象,采集的數據的用戶社會關系包括了情侶關系,同年級不同寢室同實驗室的同學關系,不同年級不同寢室同實驗室的同學關系以不同年級不同寢室不同實驗室的同學關系.
以手機的IMEI號為唯一標識確定他們的對應關系如表2所示,為保護采集數據的用戶隱私,本文用戶名字使用字母代替.

表2 用戶關系圖
我們對目前收集的數據進行分析,發現用戶的行為不論是網絡行為,還是手機的使用習慣都存在著明顯的差異.如表3所示,用戶每天屏幕點亮的次數就存在這明顯的差異

表3 用戶每天屏幕點亮數據統計表
分析表中的數據可以發現,用戶BD相對而言每天使用手機的頻率要遠高于其他三人,與事實相吻合,用戶BD經常使用手機刷微博微信等社交軟件.用戶AC使用手機的頻率相對較少,原因是A為研究生一年級的同學,課時任務比較多,C同學在上班,使用手機的頻率自然要少一些.這說明屏幕點亮信息與個人使用手機的習慣是正相關的.同時也對手機充電次數也做了類似的分析,其充電次數統計信息如表4所示

表4 每天充電次數
從表中可以看出用戶BDE每天充電的次數要高于其他兩者,與表3每天屏幕狀態統計信息的數據基本相符,一般而言,手機使用頻繁度與充電次數是正相關的.其中不同的地方在于用戶E,因為E從事Android開發,常常會在真機上測試程序,但平時使用手機并不頻繁,這也是用戶E充電次數會偏高的原因.
這些數據表明不同的用戶的手機行為或者習慣是不一樣的,正是因為每個人都有自己的行為特點,所以我們可以利用屏幕狀態信息和充電次數信息對用戶進行識別.本文使用Weka分類算法中的J48(決策樹C4.5)對用戶進行識別,J48是對ID3算法的擴展,其主要區別在于可以容忍缺失數據,這一點也是本文選擇這個算法的主要原因.由于手機上收集數據的特殊性,數據會存在一部分的缺失,通過J48這一特性可以很好的彌補數據上的缺陷.J48的主要思想是以信息熵的增益為依據,從原始樣本中提取最有利于區分類別的屬性,逐漸的由根節點到葉子節點構建決策樹,其流程如圖1所示.

圖1 決策樹算法流程圖
我們通過對數據預處理后,得到充電時長,充電間隔,屏幕點亮時長,屏幕點亮間隔,網絡流量大小,并以天為單位進行分箱,這樣得到輸入的樣本數據,而構建決策樹的過程中以上文計算得到的各種統計值作為分支條件,算法性能數據詳見表5.

表5 使用Fast decision tree進行用戶識別的準確率
從上表中ROC Area的值均在0.9左右,其準確率已遠高于隨機猜測,說明我們的分類算法能有效的對用戶身份進行識別.
3.2 社會關系推測
社會關系推測采用的方法如下:
首先,因Wi-Fi網絡的SSID不一樣,而每個SSID代表一個地理位置,若兩人連接的SSID相同說明兩人在同一區域出現過,越經常在同一區域出現,兩人認識的機率越大,故可通過用戶訪問過的Wi-Fi網絡重合度、相似度進行社會關系緊密程度推測.其SSID統計數據如表6所示,橫軸代表用戶,縱軸代表連接Wi-Fi的SSID,數字代表本文收集數據期間用戶與該SSID的Wi-Fi連接次數.由于每個用戶連接過的SSID數據較大,但常連接的一般只有三四個,因此只保留了用戶連接次數最多的前四個SSID,具體統計數據如下.
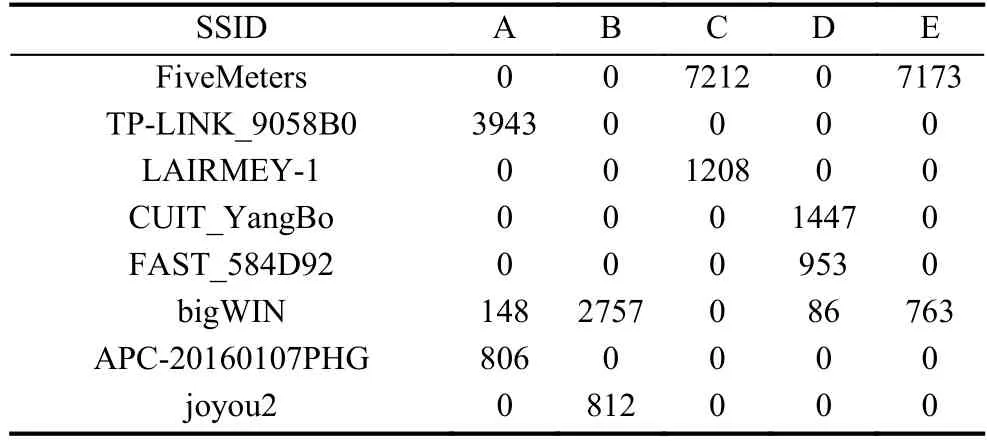
表6 SSID連接次數
其中連接bigWIN(SSID名稱)的人最多,說明用戶ABDE經常出現在同一個地點.還可以明顯看出用戶C E社會關系緊密程度很高,其共同連接FiveMeters的次數均在7200左右,而其他人均為了0,用戶CE除去FiveMeters外,并沒有相同連接的SSID,可以明確推測出CE用戶的關系十分緊密,實際上,CE為情侶關系,一人上班,一人在學校,所以其相同的FiveMeters只有一個.其中連接bigWIN的次數也可以明顯分析出他們的社會關系.用戶ABDE在經常出現在同一地點,而用戶C除了與E關系親近,與其他人并不熟悉,與實際相符合.
在判斷數據的相關性,將采用皮爾森相關系數去計算兩兩用戶間訪問過S S I D集合的相似度.Pearson相關系數也稱為皮爾森積矩相關系數,其計算公式如下:
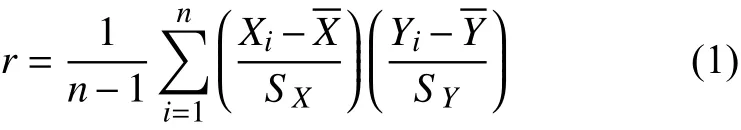
Pearson相關系數的取值在–1到1,值越接近于正負1,相關度越大,值為0代表兩個數據完全不相關.雙尾顯著性檢測就是雙側檢驗,舉例說明若雙尾顯著性為0.05,則說明有95%的把握確認相關性的存在.
我們使用表6的樣本計算Pearson相關系數,其結果如表7所示:
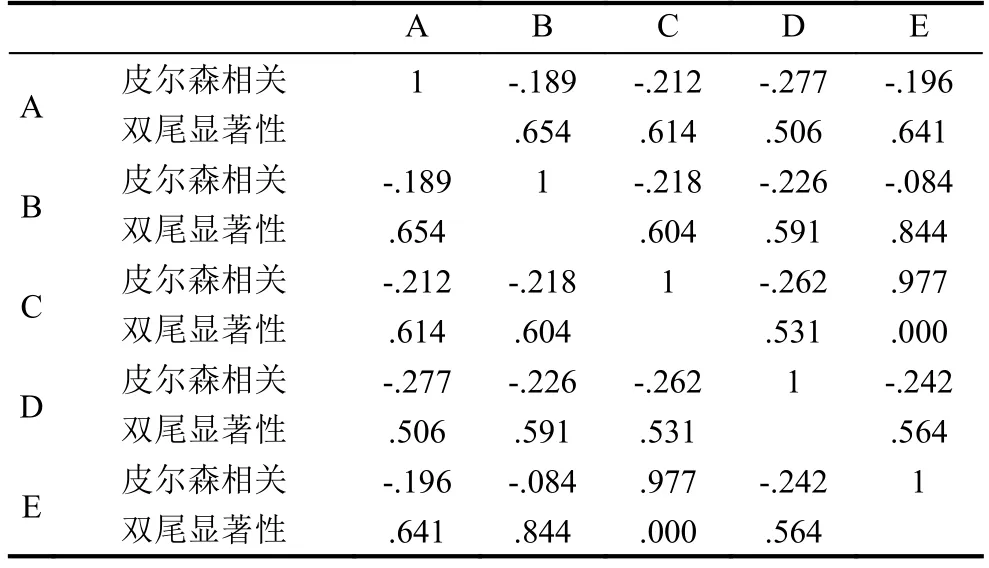
表7 SSID的Pearson相關系數表
綜上所述,我們的小規模實驗結果表明,用戶CE的關系十分緊密,與實際情況相一致,其中CE的皮爾森相關系數為0.977,雙尾顯著性為0.000029.
4 結語
通過我們的研究發現即便是非顯式用戶身份信息,通過大規模數據分析,對用戶身份進行識別,并推測出部分用戶間的社會關系等結論也會對用戶隱私造成威脅,為了保護我們的隱私要額外警惕不良應用收集這些非顯式的身份信息,有需要的話可以利用Android系統權限限制,禁止應用使用某些權限來加以保護.隨著個人的隱私越來越受到人們的重視,隱私保護逐漸成了當前迫在眉睫的研究課題.
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
