應用連續投影算法及最小二乘支持向量機的單組分紡織品識別
2018-08-23 09:48:30李佳平沈國康歐耀明辛斌杰
紡織學報 2018年8期
李佳平, 沈國康, 歐耀明, 孟 想, 辛斌杰
(1. 上海工程技術大學 服裝學院, 上海 201620; 2. 浙江中天紡檢測有限公司, 浙江 海寧 314400;3. 浙江萬方安道拓紡織科技有限公司, 浙江 海寧 314400)
隨著科技水平的快速進步和紡織新材料的不斷涌現,紡織品檢測顯得極其重要,特別是人們對紡織品的要求越來越高,將更多的注意力聚集在紡織品對人體的危害性[1]上,但以往的紡織品檢測方法大都有局限性,例如測量周期長,對檢驗人員的身體造成傷害,污染環境等。近年來,利用圖像處理技術進行紡織品檢測逐漸興起,這種技術不僅可降低人為因素的弊端,有效地檢測紡織品的外觀以及質量,還可提高勞動生產率[2]。在圖像處理技術中,高光譜成像技術比較高效,盡管在紡織領域的應用并不多,但其優越高效的檢測方式,不損傷纖維的優點,勢必將在紡織行業有廣闊的應用空間。
高光譜成像技術結合傳統二維成像和光譜技術[3],融合電磁學、光學、信號處理、計算機通信等多學科在光譜維度上進行細致地分割,采集到的圖像不但信息豐富、量大,并且識別度高,數據描述模型也比較多[4]。由于該技術具有很高的空間分辨率和譜間分辨率,在軍事偵察、地質填圖、海洋監測、農業監測、大氣和環境監測、航天研究等領域得到越來越廣泛的應用[5-6],但是其在紡織行業的應用卻剛剛起步[7-9],如應用于棉花雜質的檢測和皮棉表面多類異性纖維的檢測等[10-12]。楊文柱等[13]提出 780~1 800 nm的近紅外波段為異性纖維檢測的最優波段;郭俊先等[14]證明高光譜圖像可檢測多類共存的異性纖維;王戈等[15]利用近紅外光譜對竹原纖維、竹粘膠纖維和苧麻纖維進行快速鑒別。本文在利用高光譜成像技術對纖維等進行識別的基礎上,嘗試利用連續投影算法以及最小二乘支持向量機對織物層面進行識別,在不損傷纖維的情況下,通過相關織物標準樣品庫的建立、高光譜數據的采集、高光譜數據預處理、高光譜特征提取、纖維成分檢測系統的搭建與其校正,試驗檢測所搭建的系統快速鑒別織物的有效性。
1 材料與方法
1.1 儀器設備與數據處理軟件
采用北京卓立漢光儀器有限公司的Gaia Sorter蓋亞高光譜分選儀[16-17]采集圖像。該儀器其核心部件包括均勻光源、光譜相機、電控移動平臺(或傳送帶)、計算機及控制軟件等。儀器的光譜范圍為 1 000~2 500 nm,光譜分辨率為10 nm,像元數為 320像素×256 像素。
采用ENVI Classic 5.3(64-bit)和MatLab R2016b軟件對高光譜圖像數據進行后續處理。前者主要用于感興趣區域的設定、點和簇像素的平均光譜以及偏差光譜的提取、圖像的一般處理;后者主要用于圖像的一般處理、特征降維、特征提取和模式識別等運算。
1.2 實驗樣本與高光譜圖像的獲取
利用現有的織物樣品庫,篩選出8種常見的純紡織物:棉(C)、滌綸(PET)、羊毛(W)、聚乙烯(PE)、聚氯乙烯(PVC)、錦綸(PA)、亞麻(L)、蠶絲(S),其中每種紡織材料織物80塊,共計640塊樣品。從每塊織物上裁剪出5 cm×5 cm的布樣作為代表該織物樣品的小樣,最終獲得參與拍照及后續處理的8種純紡織物的640個織物小樣。
將織物小樣按照種類排列整齊送入高光譜分選儀中進行高光譜圖像采集。圖像采集前調整曝光時間為15 ms,以確保采集得到的圖像清晰、明亮。電動移動平臺設置推進線速度為10 mm/s,避免圖像失真。每次圖像采集前都進行標準白板校正,采集過程中光譜掃描10次,再取其平均值待用。最終獲得大小為640 像素×320 像素×256 像素的三維數據塊。
1.3 高光譜圖像標定
高光譜圖像除包含光譜反射與輻射信息之外,還包含各種對圖像有干擾的噪聲,如傳感器儀器的誤差、大氣散射吸收導致的傳輸效應、地形造成的誤差等,這些會讓光譜曲線失真[18],因此,必須對織物高光譜圖像進行校準。對高光譜圖像進行輻射校正、圖像掩膜、圖像濾波之后,才能進行后續的提取感興趣區域(ROI)[19]:通過輻射校正可消除干擾,得到真實反射率數據[20],由于此次試驗所用織物均為純紡織物,純度較高,且整體平整,選擇平場域法處理圖像;通過掩膜處理,使得處理后的高光譜圖像只保留有效的織物圖像區域以及反射率為0的黑色背景區域[21];通過圖像均值濾波[22],對圖像進行去噪處理[23]。
2 高光譜數據處理
經過高光譜圖像標定后,將采集到的每種純紡織物的80張高光譜圖像中所有織物圖像區域設置為感興趣區域(ROI),均值濾波后得到每種織物在920~2 528 nm內的代表光譜曲線。觀察原始光譜數據發現,曲線在920~1 000 nm和2 400~ 2 528 nm區間內變化趨勢相同,且存在較多噪點,所攜帶的光譜信息較少,所以在利用連續投影算法對原始光譜數據處理前,先篩選掉這2個區域內的波段,將 288個波長的數據初步壓縮至250個,如圖1所示。將采集到的每種純紡織物(80個)隨機分為訓練集(60個)和測試集(20個),以方便后續特征波長的提取和分類模型的建立。
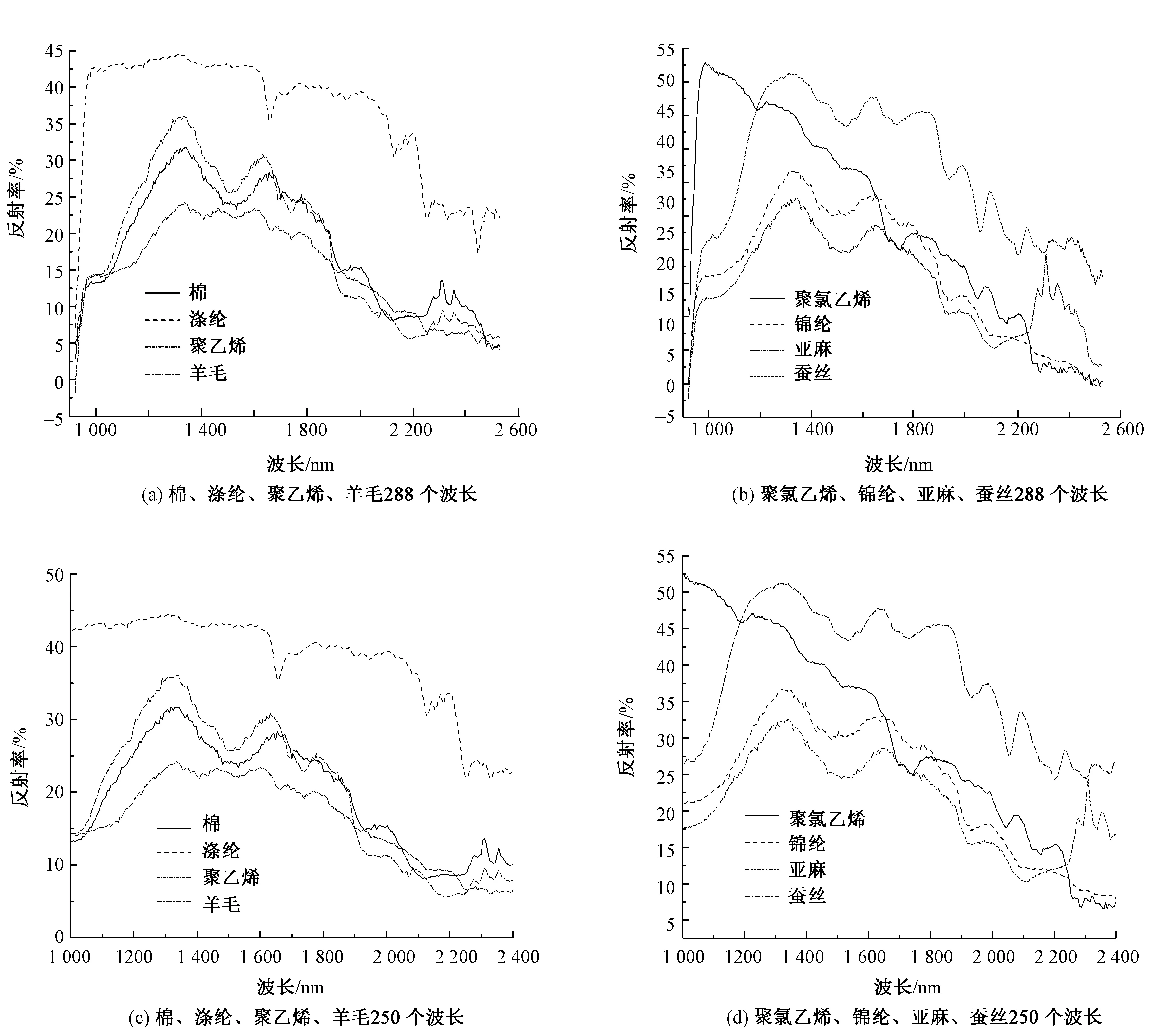
圖1 波長與反射率的關系Fig.1 Relationship between wavelength and reflectance.(a)288 wavelengths of C,PET,PE,W; (b)288 wavelengths of PVC,PA,L,S; (c)250 wavelengths of C,PET,PE,W; (d)250 wavelengths of PVC,PA,L,S
2.1 基于連續投影算法的特征波長提取
采用全部250個波長進行訓練、篩選時運行數據量大,某些范圍內的光譜信息量少,與待測織物的構成及因素缺乏相關關系,因此,進一步對數據進行壓縮、降維必不可少。連續投影算法在1965年被提出用來解決凸可行性問題,目前已廣泛應用于海洋檢測、生物醫學成像、森林植被研究、農業生長信息傳遞、大氣輻射監控等領域。連續投影算法可從光譜數據中找到包含最低限度的冗余信息的變量組,使波長變量間的共線性去除,提高光譜信噪比,進而提高模型預測能力[24]。設樣本光譜反射率矩陣為Xn×p,性質參數矢量為y,總體樣本數為n,全譜波長數為p。波長的確定分為2個步驟。
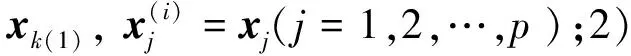
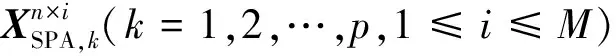
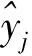
以棉織物為例,利用連續投影算法對棉織物的250個波段進行篩選,樣本為驗證集的60個待測織物。均方根誤差值最小時對應的波長數就是光譜變量的最優解,由測試集的均方根誤差預測值確定光譜變量的最優解。模型中包含變量數改變會引起均方根誤差改變,其變化如圖2所示。若取均方根誤差最小值,則為0.426 93,此時變量個數為7。確定的特征波長共7個,按照重要性排序分別為 1 531.4、1 929.2、2 203.7、1 329.8、1 789.1、762.0、1 654.7 nm,此時數據量較最初數據減少97.22%。

圖2 均方根誤差和與其對應的波長Fig.2 Root mean square error (a) and its corresponding wavelength (b)
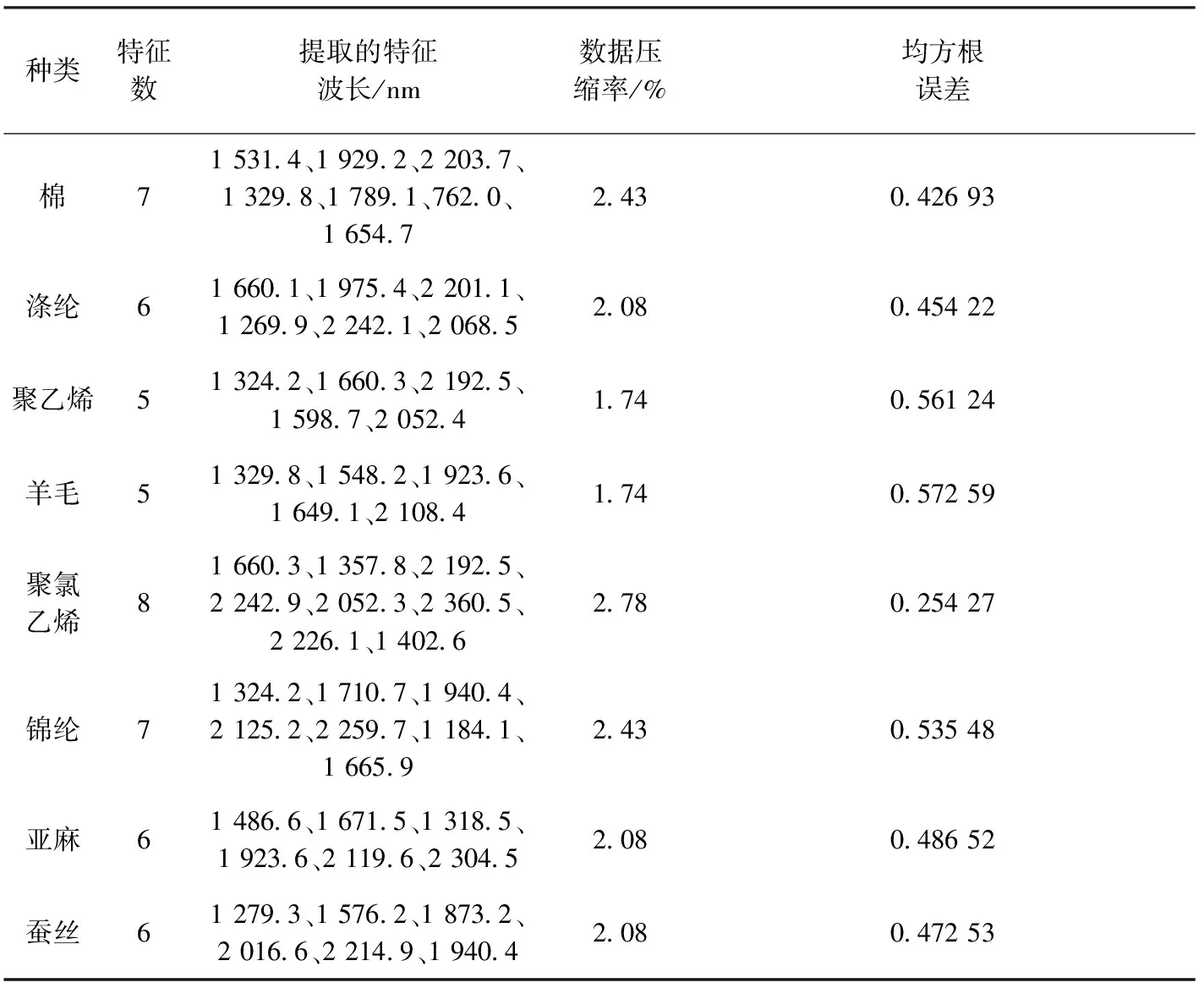
表1 連續投影算法提取的特征波長Tab.1 Characteristic wavelengths extracted by continuous projection algorithm
分別利用連續投影算法提取8種純紡織物的特征波長,得到的具體數據如表1所示。可知,經過連續投影算法(SPA)處理之后,原始的288個波段被壓縮至5~8個特征波長,僅占原始數據的1.74%~2.43%,刪減了大量冗余信息,節省了大量的建模時間,且所提取的特征波長所對應的預測均方根誤差均小于0.6,有很強的代表性,誤差小,符合后續建模要求。
2.2 建立最小二乘法支持向量機分類器
最小二乘支持向量機(LS-SVM)是對標準支持向量機(SVM)的改進,其用等式約束代替了SVM中的不等式約束,通過非線性映射函數φ(x)建立回歸模型,利用拉格朗日算子求解最優化問題,對各變量求偏微分。
本文試驗采用徑向基函數RBF函數作為核函數,其原因為:1)RBF能把樣本映射到更高維的空間;2)RBF確定的參數較少,核函數參數的數量直接影響函數的復雜程度。
由此可見,LS-SVM將凸二次規劃問題轉化為求解線性方程,極大地簡化了計算復雜程度,對存儲空間要求大大降低,也降低了計算成本。
本文基于核函數為RBF的LS-SVM的相關算法在MatLab 2016b上設計出分類模型,如圖3所示。其中模型中的正則化參數gam=10,核參數 sig2=0.2。
圖3 以RBF為核函數的LS-SVMFig.3 LS-SVM with RBF kernel function
所建模型中,將棉、滌綸、聚乙烯、羊毛、聚氯乙烯、錦綸、亞麻、蠶絲8種織物的訓練集分別導入向量機中進行訓練,最終得到8個二類分類器SVM1、SVM2、SVM3、SVM4、SVM5、SVM6、SVM7、SVM8。在識別過程中,將8種織物的驗證集和測試集(共640條代表光譜曲線數據)導入SVM1中,分類器分類結果n為1或0,結果為1時即為成功分類,結果為0時就會自動將特征波長輸入到下一分類器SVM2,依此類推。若所有分類器輸出結果n均為0時,即為無法分類。二類分類器原理及分類器對640個樣本分類效果如圖4所示。
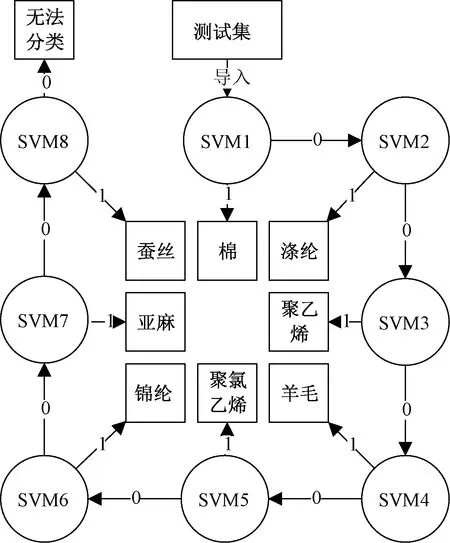
圖4 分類器示意圖Fig.4 Schematic diagram of classifier
2.3 分類結果
利用連續投影算法(SPA)提取8類共640個紡織樣品的特征波長,并將每類80個樣品分為訓練集(60個)和測試集(20個),最后利用訓練集導入基于最小二乘法支持向量機(LS-SVM)建立的二類分類器中,得到了8個二類分類器。8個二類分類器對640個樣本分類效果如表2所示。
結果顯示,棉、滌綸、聚乙烯、羊毛、聚氯乙烯、錦綸、亞麻、蠶絲8種純紡織物的60個驗證集和20個測試集均得到正確的識別,640個試驗樣品沒有無法識別分類、錯誤識別分類的情況,所建立模型的識別率和穩定性都符合要求。
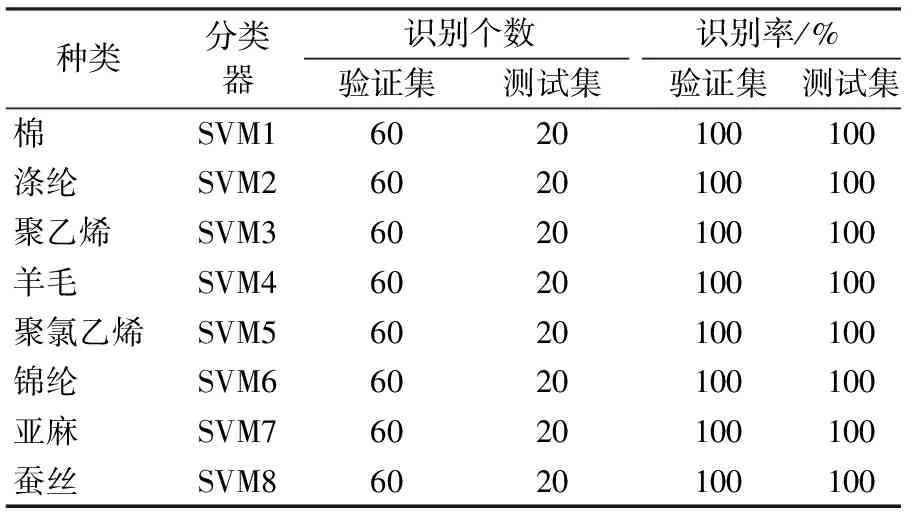
表2 SPA-LS-SVM模型的識別效果
3 結 論
利用高光譜成像技術對由8種常見的天然纖維和合成纖維制成的純紡織物進行識別,將采集到的 8種織物按照種類分為驗證集(60個)和測試集(20個),采用連續投影算法(SPA)結合每種織物的驗證集數據,提取出該織物所對應的特征波長數,將原始數據壓縮至1.74%~2.43%,大大減少了模型的復雜程度,提高了準確率和運算速度。繼而基于最小二乘法支持的向量機對每種織物進行建模得到了 8個二類分類器,并將8種織物的訓練集分別導入模型進行訓練。最后利用完成訓練的分類器對全部640個樣本進行識別分類。結果顯示對于此8種純紡織物的640個實驗樣本,所建模型均可正確識別,高光譜成像技術可用于棉、滌綸、聚乙烯、羊毛、聚氯乙烯、錦綸、亞麻、蠶絲的材料識別。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
