基于多特征組合的細粒度圖像分類方法
2018-08-27 10:42:36鄒承明徐曉龍
計算機應用 2018年7期
鄒承明,羅 瑩,徐曉龍
(1.交通物聯(lián)網技術湖北省重點實驗室(武漢理工大學),武漢 430070; 2.武漢理工大學 計算機科學與技術學院,武漢 430070)(*通信作者電子郵箱luoyingwork@foxmail.com)
0 引言
一直以來,細粒度圖像分類都是計算機視覺和模式識別等領域的許多研究人員感興趣的課題,但由于細粒度圖像往往擁有較大的類內差異和細微的類間差異,其分類難度遠遠高于普通的圖像分類[1]。
細粒度圖像的樣本通常屬于同一大類,不同子類間擁有較高的相似性,相互的區(qū)別往往體現(xiàn)在難以察覺的局部細節(jié)之上,而同一子類下的樣本又會由于拍攝距離、目標姿勢、復雜背景和遮擋物等因素的干擾產生極大的差異,彼此的共性可能存在旋轉、縮放、變形和缺失的情況,因此細粒度圖像分類問題成為了機器視覺領域一個極大的挑戰(zhàn)[2]。
早期的細粒度分類方法使用簡單的特征提取和編碼方式生成特征表示,這些表示方法相當粗糙,采集到的有效信息十分有限。比如Wah等[3]在細粒度數(shù)據集CUB- 200- 2011上作基準測試時,通過對圖像提取RGB顏色直方圖特征和尺度不變特征轉換(Scale Invariant Feature Transform, SIFT)[4]特征,運用詞袋模型(Bag of Words, BoW)生成特征編碼,最終分類精度最高僅為17.3%。這項工作表明,簡單的特征表示方法描述性較弱,不足以支撐更高的細粒度圖像分類準確度。但這并不意味著早期提取的特征是完全無用的,隨著更為強大的編碼方式的出現(xiàn),如Fisher Vector編碼[5]、局部特征聚合描述符(Vector of Locally Aggregated Descriptors, VLAD)[6]等,與之結合的SIFT特征的分類準確度也有所提高。
近年來卷積神經網絡(Convolutional Neural Network,CNN)[7-10]在一般的圖像分類任務中取得了令人矚目的成績,證明了卷積特征對圖像的描述能力,這一結論也為細粒度圖像分類帶來了新的發(fā)展方向,研究人員開始選擇CNN特征作為圖像表示用于細粒度圖像分類[11]。Zhang等[12]依次對目標整體、頭部和身體區(qū)域訓練CNN模型分別用來提取三種卷積特征,最后將三種特征級聯(lián)成一個向量用于分類;Branson等[13]對目標整體和不同部位分別提取不同層的CNN特征,綜合多項卷積特征進行分類。上述算法在CUB- 200- 2011數(shù)據集上都達到了75%以上的分類準確度。這些工作證明了卷積特征在細粒度圖像分類中可以發(fā)揮較好的作用,但是分類準確度仍然存在上升空間。
從現(xiàn)有研究成果來看,目前細粒度圖像分類的主流框架大多是基于單一特征,這往往導致一定的片面性。以SIFT和CNN特征為例,前者注重圖像底層信息,針對關鍵點提取的特征太過細化且極易被噪聲干擾,自身無法支撐較高的全局分類準確度;后者擁有強大的抽象能力,能夠捕捉圖像的高層語義,可針對目標整體區(qū)域提取的全局特征卻過于泛化,忽視了底層和局部的細節(jié),不利于區(qū)分細粒度圖像庫中十分相似的異類樣本。針對這些問題,本文提出的多特征組合方法綜合考慮高層和底層、全局和局部的信息,采用針對目標整體、關鍵部位和關鍵點層層遞進的特征提取方法,將各個層次的特征組合起來,得到更豐富的特征表示。本文算法在CUB- 200- 2011鳥類數(shù)據集上進行實驗,結果表明,本文提出的特征表示方法對于細粒度圖像分類準確度的提升有積極作用。
1 特征提取模型
圖像特征提取是解決圖像分類問題的重要步驟,特征提取方法的優(yōu)劣決定了所提取特征的描述能力,從而影響圖像分類性能。細粒度分類由于其分類目標更加細致,對圖像特征的要求也更加苛刻,往往需要在描述全局特征的同時不忽視局部特征,因此,一個綜合考慮全局特征和局部特征的特征提取模型對細粒度分類尤為重要。
CNN是LeCun等[7,14]提出的一種經典的神經網絡特征提取模型,它可以直接處理原始圖像,還能夠根據不同的分類問題從圖像中提取出相應有效的特征,目前在計算機視覺領域中應用廣泛,其基本的網絡結構如圖1所示。

圖1 CNN基本結構
網絡整體可分為三個部分:輸入層、中間層和輸出層[15]。輸入層為原始圖像,輸出層為特征向量,中間層由若干個卷積層和池化層交替組成,其作用是對輸入層的數(shù)據進行逐層抽象,最終通過全連接得到含有高層語義的輸出向量。對于CNN而言,不同的卷積參數(shù)和池化策略將導致網絡最終所提取特征的不同意義,而多樣化的特征又伴隨著強大的描述能力和遷移能力,因此,卷積層和池化層是CNN提取更具區(qū)分度的特征的關鍵所在。
其中,卷積層由大小固定的卷積核對上層的輸出進行卷積操作,其核心原理如圖2所示:圖2(a)展示了多種卷積核的卷積操作,每個卷積核都擁有相同尺寸的局部感受野,感受野內部是各自的權值參數(shù),參數(shù)值的差異決定了卷積核的不同種類,卷積核依次沿著x軸和y軸方向在圖層上進行滑動和卷積,得到的值組成該卷積核的特征響應圖;圖2(b)是卷積的計算過程,一個卷積核的內部權值參數(shù)對于它要卷積的對象是共享的,也就是它在滑動和卷積過程中不會發(fā)生權值的變化,而卷積就是將感受野所覆蓋的圖層數(shù)據與自身相應位置的權值進行加權求和,所得結果作為輸出數(shù)值。
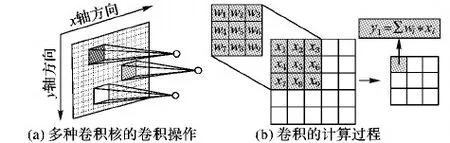
圖2 卷積層核心原理
池化層操作原理與卷積層類似,區(qū)別在于池化層的感受野會根據不同池化策略來取對應位置的最大值或者平均值。
從CNN的基本結構來看,它所提取的特征屬于全局屬性,而通過CNN中卷積和池化的操作過程也不難看出,隨著中間層層數(shù)的增加,CNN將原始圖像的底層信息逐步合并和歸納,進而向高層過渡,但一些局部細節(jié)也隨之逐層丟失,因此CNN雖然在一般的分類任務中出類拔萃,卻在細粒度分類中表現(xiàn)欠佳。受這一現(xiàn)象的啟發(fā),本文提出了利用SIFT關鍵點來增強局部點特征的方法,獲得更強大的特征描述力。
SIFT是一種局部特征描述子,它可以定位和篩選圖像尺度空間中的極值點,并用128維的向量描述每個關鍵點,這種特征具有旋轉不變性和尺度不變性,是極為可靠的局部描述符。然而,不同圖像的SIFT關鍵點數(shù)目往往差異較大,因此SIFT特征不便于直接用于圖像分類,此時就需要特定的編碼方式在考慮到每張圖像SIFT特征的同時,生成統(tǒng)一維度的特征向量。VLAD就是極為優(yōu)秀的一種特征編碼方式,它相對于BoW編碼而言損失較少的信息,相對于Fisher Vector編碼而言計算更為簡單,而且在一些分類任務中它的效果還優(yōu)于前兩者。它保存了每個SIFT特征點到離它最近的聚類中心的距離,且考慮了特征點每一維的值的影響,對圖像局部內容有更細致的刻畫,因此本文選擇用VLAD模型編碼SIFT特征,獲取的信息用來強化其他全局特征的局部描述性。
綜上,本文所使用的特征提取模型兼顧了CNN和SIFT兩種特征的提取,以CNN提取的高層語義特征把控全局方向,以VLAD算法編碼的SIFT關鍵點特征補充局部細節(jié),得到對細粒度圖像目標更具判別力的特征表示。
2 多特征組合
由第1章CNN的原理介紹可知,CNN特征提取模型針對的是圖像塊,它所輸出的特征是將圖像塊中所有像素以某種方式進行融合后的產物。這樣的特征充分反映了該圖像塊的全局屬性,然而圖像塊的尺度是可變的,也就是說同樣大小的圖像塊,它的內容可能是整個目標,也可能只是目標的一部分,例如鳥類的整體和頭部區(qū)域本質都是圖像塊,都可以通過CNN模型進行特征提取,因此CNN模型本身也可以提取出多種特征,這些特征與VLAD模型提取的SIFT點特征組合在一起可以構建出豐富的特征表示,不同成分的組合特征在細粒度圖像分類中也有著不同的結果,因此即使已經確定了多特征提取的模型,各種特征的選取也至關重要。
本文結合人眼分辨細粒度圖像的經驗,對CNN模型和VLAD模型提取的多種特征的選擇和組合策略進行了分析。在面對需要辨別的細粒度圖像時,人們通常會先根據目標整體區(qū)域的信息判斷大致類別,這一過程說明了目標整體區(qū)域的特征的必要性,這類特征可通過CNN模型提取;接下來就是根據目標關鍵部位和關鍵點的細節(jié)差異來區(qū)分細粒度類別,這一過程說明了目標關鍵部位區(qū)域和關鍵點的特征對細粒度圖像最終辨識結果的重要性,這兩類特征可分別通過CNN和VLAD模型提取,因此,本文提出的多特征組合方法同時選取目標整體、關鍵部位和關鍵點三重特征層層遞進組合成對細粒度圖像具有更高描述性和區(qū)分性的最終特征。
圖3為相應的多特征組合結構示意圖:分別用各自的模型提取目標整體、關鍵部位和關鍵點特征,三者級聯(lián)之后用SVM分類器進行分類。其中關鍵部位取用的是目標的頭部區(qū)域,原因有二:其一是頭部區(qū)域往往蘊含大量細粒度圖像分類所需信息;其二是圖像樣本中頭部區(qū)域的完整性最能得到保障。
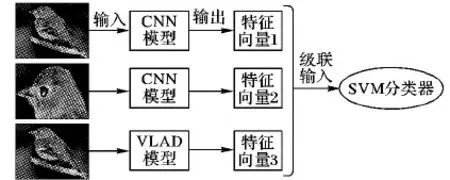
圖3 多特征組合結構
在實現(xiàn)本文提出的多特征組合方法時,需要提前對三種特征提取模型進行訓練,圖4為本文細粒度圖像分類模型的訓練過程示意圖。首先,分別以細粒度圖像庫訓練集中的目標整體和頭部區(qū)域訓練CNN得到兩個網絡模型M1和M2,提取訓練集中所有目標的整體和頭部CNN特征F1和F2;然后,對訓練集中所有目標區(qū)域提取SIFT特征,通過K均值聚類生成聚類中心集合作為碼本C,再將每個目標區(qū)域的SIFT特征點通過VLAD參照碼本C編碼為特征F3;最后,組合F1、F2和F3作為最終的特征表示,訓練SVM分類器S。
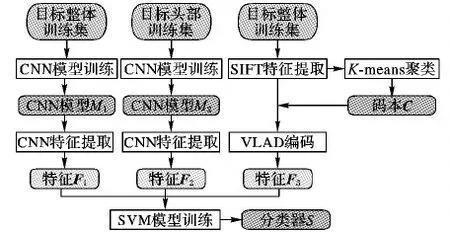
圖4 模型訓練過程
模型的測試過程如圖5所示:對測試目標整體和頭部分別用M1和M2提取特征F1′和F2′,對測試目標整體提取SIFT特征點,再參照碼本C進行VLAD編碼,得到特征F3′,將F1′、F2′和F3′級聯(lián),輸入到分類器S中得到結果。
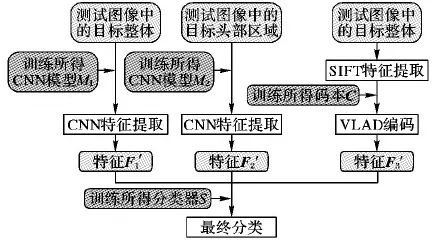
圖5 模型測試過程
3 實驗結果與分析
3.1 實驗設置
本文在細粒度圖像分類領域中最為經典和常用的數(shù)據集CUB- 200- 2011上進行實驗,該數(shù)據集包含200種不同鳥類的類別,共計11 788張圖像,實驗選取數(shù)據集中的5 994張作為訓練集,其他5 794張作為測試集。實驗主要硬件環(huán)境為Nvidia Tesla P100計算顯卡,軟件環(huán)境為Linux系統(tǒng)下Caffe和Matlab R2014a。
為了便于目標整體和關鍵部位區(qū)域CNN特征的統(tǒng)一提取,將所有圖像數(shù)據的尺寸預處理為227×227。實驗中CNN結構設置如下:1~5層為卷積層,每層卷積后都有ReLU激活函數(shù)處理和最大值池化操作;6~7層為全連接層,本文算法取用的CNN特征就是第7層的4 096維特征。
為了得出本文算法中VLAD特征編碼時最適合的k均值聚類中心數(shù),分別在8、16、32、64四種k值下進行實驗,表1為在細粒度數(shù)據集CUB- 200- 2011上使用本文算法時選用不同k值所對應的分類準確度。

表1 不同聚類數(shù)下的分類準確度
從表1可以看出,當聚類數(shù)等于16時,細粒度圖像識別準確度達到了最高值。分析其原因,當聚類數(shù)過小時,聚類中心之間相距較遠,每個中心輻射的聚類范圍較廣,各個聚類的關鍵點分布也較為分散,也就是聚類很可能并沒有達到較好的收斂狀態(tài),因此憑借這個聚類中心集合作為碼本提取的信息沒有足夠的可靠性;而聚類數(shù)過大時,聚類中心較為擁擠,每個中心輻射的聚類范圍重疊,關鍵點可能同時歸入多個聚類,造成某些特征的重復提取,從而導致過擬合,因此,本文算法提取VLAD特征時的關鍵點聚類數(shù)設置為16,相應的特征維度為16×128。
上述兩種特征確定后,將它們進行級聯(lián)組合后,選擇一對多方式下的多類SVM分類器對數(shù)據進行訓練和測試。
3.2 實驗結果
本文算法結合CNN特征和VLAD編碼的SIFT特征,使用“目標整體+關鍵區(qū)域+關鍵點”的特征提取和組合方法,最后通過一對多SVM進行分類。
為了方便對比分析,在進行本文提出的三重特征組合的細粒度分類實驗的同時,也分別在同樣的數(shù)據集上進行了多種單一CNN特征的分類和多種組合CNN特征的分類。
實驗結果如表2所示,表中字母的含義如下:Fentirety-cnn、Fhead-cnn和Fbody-cnn分別表示在目標整體、頭部和身體區(qū)域提取的CNN特征,F(xiàn)entirety-cnn+Fhead-cnn、Fentirety-cnn+Fbody-cnn和Fhead-cnn+Fbody-cnn分別表示三種CNN特征的兩兩組合,F(xiàn)entirety-cnn+Fhead-cnn+F(16×128)-vlad則表示目標整體CNN特征、頭部CNN特征和以16個聚類中心為碼本編碼的VLAD特征的組合表示。
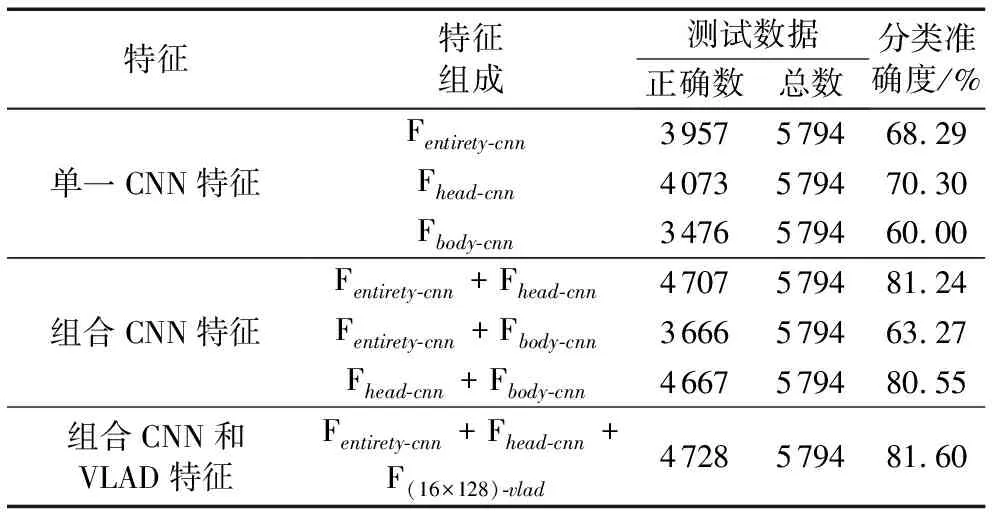
表2 不同特征的實驗結果對比
表2中分別記錄了上述特征表示方法所對應的細粒度圖像分類準確度,分析其中數(shù)據可以得出以下幾個結論:
1)單一的CNN特征本身有較強的描述性,但在細粒度分類問題中還缺乏足夠的區(qū)分度,因此其分類準確度只能停留在60%~70%。
2)三種單一CNN特征中,頭部區(qū)域的特征區(qū)分度明顯高于其他兩種,凡是有這一特征參與的特征組合都可以獲得80%以上的分類準確度,這種結果可以證明頭部是該數(shù)據集的關鍵部位,也可以證明關鍵部位的特征對細粒度分類至關重要。
3)多特征組合表示的分類準確度大多高于單特征表示,且優(yōu)勢明顯,除了Fentirety-cnn+Fbody-cnn組合這一特例,其他組合方法相比單特征表示都有10%~20%的準確度提升。而Fentirety-cnn+Fbody-cnn組合的準確度較低的原因除了目標整體區(qū)域和身體區(qū)域的單一CNN特征都不夠強大之外,還存在一些外部因素。結合實驗所用的圖像數(shù)據進行分析可以發(fā)現(xiàn),CUB數(shù)據集中存在一定量的樣本完全缺失身體區(qū)域,這種現(xiàn)象更加降低了這類特征組合的有效性,從而導致分類的失敗。
4)結合目標整體、頭部CNN特征和關鍵點VLAD特征的表示方法取得了最高的細粒度分類準確度81.6%,相較于直接將CNN結構套用到細粒度圖像分類問題上,憑借單一的目標整體區(qū)域CNN特征進行分類,提高了13.31%的準確度,證明了本文所提出多特征組合的有效性。
綜上所述,本文提出的綜合考慮目標整體、關鍵部位和關鍵點的多特征組合方法對細粒度圖像分類準確度有著明顯的提升。
此外,本文將所提出的方法和其他已有的細粒度圖像分類算法在同一個數(shù)據集CUB- 200- 2011下進行了實驗對比,結果如表3所示,從分類準確度對比結果可以看出本文提出的方法對細粒度圖像分類的確有較好的效果。
4 結語
為了解決單一特征表示的局限性會導致細粒度圖像分類準確度不高的問題,本文提出了一種基于CNN和SIFT的多特征組合表示方法。基于單一CNN特征和多特征組合的細粒度圖像分類對比實驗表明,綜合考慮對目標整體、關鍵部位和關鍵點的特征提取的多特征組合方法擁有最高的分類準確度。由于關鍵點定位和篩選算法的誤差,導致關鍵點特征對組合特征的提升不是很明顯,在下一步的研究過程中,可以針對這一問題進行改進。

表3 CUB- 200- 2011下的各方法分類準確度對比 %
猜你喜歡
中學生數(shù)理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(yè)(2021年8期)2021-11-28 05:07:50
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
電子制作(2019年15期)2019-08-27 01:12:00
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中國生物醫(yī)學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
中國衛(wèi)生(2014年2期)2014-11-12 13:00:16
