面向高層次綜合的自定義指令自動識別方法
2018-08-27 10:42:40肖成龍王珊珊
計算機應用 2018年7期
肖成龍,林 軍,王珊珊,王 寧
(遼寧工程技術大學 軟件學院,遼寧 葫蘆島 125105)(*通信作者電子郵箱2437017377@qq.com)
0 引言
隨著半導體技術的飛速發展以及集成電路的復雜度不斷增加,在低層次的寄存器傳輸級(Register-Transfer Level, RTL)下手寫代碼、維護和仿真較困難并且極易出錯。高層次綜合(High Level Synthesis, HLS)是一個將高抽象層次的行為描述轉換為低層次的寄存器傳輸級描述的自動化或半自動化編譯過程,它接收基于C或C++語言的行為描述、含硬件組件詳細信息的資源庫以及特殊的約束條件作為輸入,經過前端編譯、資源分配、調度、綁定以及代碼轉換等過程,自動生成寄存器傳輸級的代碼。高層次綜合(HLS)可以有效解決寄存器傳輸級所遇到的問題,且具有設計周期短、產品質量高等優點[1-2]。
近年來,研究者致力于高層次綜合的性能和能耗方面的研究。自定義功能單元(自定義指令的硬件實現)是權衡可擴展處理器靈活性和效率的重要組件[3-4],在可擴展處理器中使用自定義指令能夠有效提高運算速度、減少面積和代碼量[5-6]。將自定義指令應用到高層次綜合中,可以有效解決高層次綜合能耗問題[7-8]。然而,現有研究多數是在高層次綜合的過程中進行[7-13],需要修改高層次綜合的核心算法,實現起來相對困難。
針對以上問題,本文提出了一種面向高層次綜合的自定義指令自動識別方法,主要貢獻包括:
1)方法在高層次綜合過程之前識別自定義指令,可適用于大部分的高層次綜合工具,克服了現有研究在高層次綜合過程中識別自定義指令的缺點。
2)針對子圖枚舉,結合搜索樹設計了一種基于節點刪除技術的深度優先(Depth-First based on Node Deletion technique, DFND)搜索算法,可靈活修改圖大小、連通性等約束條件。
3)針對子圖選擇,提出了基于最少子圖數目的選擇(Minimum number of matches based subgraph Selection, MS)算法、基于關鍵路徑的子圖選擇(Critical paths based subgraph Selection, CS)算法以及基于出現頻率的模式選擇(frequency of occurrence based Pattern Selection, PS)算法。在測試基準程序上進行實驗并對3種算法進行比較,驗證了3種算法的有效性。
1 相關研究
面向高層次綜合的自定義指令自動識別方法涉及兩個關鍵問題:子圖枚舉問題和子圖選擇問題。本章分別對這兩個問題進行分析。
1.1 子圖枚舉問題
由于寄存器的讀寫端口數目有限,近期的研究專注于在I/O端口約束的條件下枚舉子圖。Chen等[14]證明子圖枚舉是具有多項式時間復雜度的問題;Bonzini等[15]提出一種多項式時間的子圖枚舉算法;Arnold等[16]用動態規劃的方法枚舉出所有子圖,然而當圖的規模變大,這些枚舉方法效率較低。自定義指令執行過程中需要保持原子性,因而在硬件功能單元中實現的自定義指令應該滿足凸性[17],Giaquinta等[18]提出枚舉出最大凸子圖的算法;Wang等[19]提出枚舉出所有凸子圖的方法;Atasu等[20]提出一種在凸性和I/O端口約束下的二元決策樹的精確算法。在此基礎上,Pozzi等[21]通過添加一項基于永久輸入數目的修剪標準,使算法得到進一步改進。Yu等[22-23]通過合并向上和向下的錐體型子圖構建連通子圖,然而,該算法可能使得同一個子圖被多次枚舉。Xiao等[24-25]所提出的子圖枚舉算法利用數據流圖的拓撲特性來減少部分搜索空間,從而減少了算法的執行時間。Xiao等[26]提出了一種靈活的算法,該算法可以枚舉出連通子圖或所有子圖。Xiao等[27]將自定義指令識別應用到高層次綜合之中,提出多約束條件組合的枚舉算法。
在可擴展處理器的設計中,由于處理器和自定義功能單元之間存在數據通信成本,I/O端口數目是重要的約束。然而,在高層次綜合的技術背景下,I/O端口的數目不再被限制[7]。Cong等[8]提出一種子圖枚舉算法,該算法能夠枚舉出所有滿足用戶定義的編輯距離和頻率限制的子圖,但是在枚舉階段應用用戶定義的編輯距離和頻率限制約束使一些具有較好提升性能的子圖在早期被丟棄,該算法還必須使用額外的重復檢查來排除冗余子圖。Balister等[28]以自頂向下的方式枚舉所有連通凸子圖(connected convex subgraphs, cc-subgraphs),算法至少產生了2·cc(G)-n個遞歸調用來枚舉所有的連通凸子圖。其中:cc(G)表示枚舉cc-subgraphs的數目,n是圖G的節點數。在這些遞歸調用中,只有葉節點負責生成連通凸子圖。
此前國內外的研究主要是在特定約束條件下枚舉子圖。然而當用戶增加或刪除約束條件時,算法將不再適用。本文提出一種更為有效的枚舉算法(DFND算法),DFND算法只需cc(G)次調用就可以枚舉所有的連通凸子圖。當約束條件發生變化時,此算法以自底而上的方式靈活地枚舉出滿足圖大小約束的連通凸子圖。
1.2 子圖選擇問題
枚舉出的候選子圖被選擇的原因多數是由于其在應用代碼中被頻繁利用,或者與其他組件相比具有較高的性能,又或者可以顯著減少面積,因此,提出良好的子圖選擇方法對于應用程序性能提升或面積減少至關重要。針對子圖選擇問題,許多研究者提出了不同的方法。
Clark等[29]提出一種精確算法,旨在用最少數目的自定義指令覆蓋每個節點,該算法將子圖選擇問題轉換為單邊覆蓋問題。Martin等[30]嘗試通過使用約束編程來解決子圖選擇問題,該文獻對自定義指令的選擇通過兩種相應的調度策略實現:時間約束調度或資源約束調度。Yu等[22-23]提出一種基于整數線性規劃(Integer Linear Programming, ILP)的自定義指令選擇的最優方法。
由于子圖選擇問題的計算復雜度較高,當應用程序對應的數據流圖較大時,精確算法可能無法給出最優解。而探索式方法能夠高效地解決該問題。Kastner等[31]通過沿著最頻繁出現的邊生成子圖來選擇具有高出現頻率的子圖;Guo等[32]提出基于沖突圖的模式選擇算法,此算法用最少數目的模式來覆蓋圖,該算法在子圖之間不能有重疊的前提下,使用一個目標函數貪婪地選擇子圖;Bozorgzadeh等[33]提出子圖選擇由調度決定,使重要的子圖獲得更高的優先級。近年來,一些元啟發式算法也用來解決子圖選擇問題[34-36]。Cong等[7-8]將實現的子圖選擇算法應用在基于自定義指令的高層次綜合之中。然而,該算法所選擇的自定義指令會引起延遲增加的問題。為解決時延問題,Xiao等[26-27]提出基于關鍵路徑的數學模型,提升了高層次綜合效率。本文在無重疊和無循環約束條件下提出了3種不同子圖選擇方法,重點研究了高層次綜合在性能、面積和代碼量方面的內容。
2 相關定義
數據流圖(Data Flow Graph, DFG)是一種有向無環圖(Directed Acyclic Graph, DAG)。圖G=(V,E),頂點集V={v1,v2,…,vn}表示基本指令,邊集E={e1,e2,…,en}?V×V表示指令之間數據依賴關系。圖G的子圖S=(Vs,Es),其中Vs?V,Es?E。
定義1 凸子圖。對于G的子圖S,?u,v∈Vs,若在G中u與v之間的任何路徑都只經過S中的節點,則稱S是G的凸子圖。
在硬件功能單元中實現的自定義指令應該滿足凸性,否則不能滿足自定義指令執行過程中的原子性。在圖1中,子圖{1,2,3}是凸子圖,而子圖{2,3,5}不是凸子圖。

圖1 數據流圖示例
定義2 同構圖。從圖G到圖S的同構是一個雙射f:V(G)→V(S),使得uv∈E(G),記為G?S。如果圖G中的頂點u和v的連線uv屬于圖G邊的集合E(G),則u和v映射到圖S邊的集合E(S);反之亦然,則稱圖G和圖S同構。有向圖的同構是圖中的節點以及邊的一一對應關系。
定義3 模式。給定兩個子圖a和b,如果a與b同構,則創建模式P,并且子圖a和b被記錄在模式P中。模式是所有同構子圖的圖形化表示。
給定DFGG=(V,E)和子集X,子集X?G,X的后繼或前驅如下表示。
X的直接前驅節點集:
IPred(X)={v|u∈V,v∈X,(u,v)∈E}
X的直接后繼節點集:
ISucc(X)={v|v∈X,u∈V,(v,u)∈E}
X的所有前驅節點集:
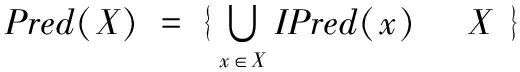
X的所有后繼節點集:
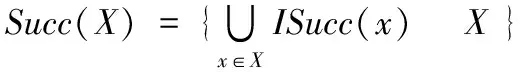
問題1 子圖枚舉。給定一個DFG,G=(V,E),枚舉滿足以下約束的所有子圖:
1)凸性。S是凸子圖。
2)連通性。S是連通的。
3)最大規模(可根據用戶需求設置)。
子圖滿足凸性可使程序執行過程中保持原子性。由于連通子圖內部數據流可減少多路選擇器的使用,因而枚舉連通子圖。在圖1中,自定義指令{1,3}是一個連通的子圖,而自定義指令{1,2}是分離子圖。當枚舉所有連通凸子圖過于復雜時,限制子圖大小很有必要。多數情況下,考慮到資源重用(面積成本),具有高出現頻率的小子圖更有可能被選擇。
問題2 子圖/模式選擇。給定一個DFG,G=(V,E)和一組枚舉的子圖/模式,根據不同的選擇方法選擇一組最佳子圖集,使G中的每個節點被覆蓋,滿足以下約束:
1)無重疊約束。兩個子圖可能具有共同的節點。允許重疊有時可能會改善程序運行時間,但同時增加不必要的功耗并難以生成新代碼[37],因此,本文中不允許選擇的子圖之間有重疊。
2)無循環約束。如果兩個子圖相互提供數據,則生成一個循環。在這種情況下,兩個自定義指令之間會發生死鎖[6],因此,本文不允許選擇的子圖之間存在循環。
3 面向高層次綜合的自定義指令自動識別方法
本文所提出的面向高層次綜合的自定義指令自動識別方法在不修改高層次綜合的核心算法前提下,高效地識別滿足用戶指定的不同約束條件和設計目標的自定義指令。該方法相對靈活,改進自定義指令自動識別階段的算法就可以提升高層次綜合效率方面的問題,降低了研究問題的難度。本文的方法主要由中間表示生成、子圖枚舉、子圖選擇以及代碼轉換組成。方法如圖2所示。圖2中:RTL(Register-Transfer Level)為寄存器傳輸級;VHDL(Very-High-speed integrated circuit hardware Description Language)為超高速集成電路硬件描述語言。

圖2 面向高層次綜合的自定義指令自動識別方法
3.1 中間表示生成
本文方法的第一步是自動生成源代碼的中間表示,該階段的輸入是C或C++源代碼。使用開源編譯器GECOS(Generic Compiler Suite)將源代碼轉換為控制數據流圖(Control Data Flow Graph, CDFG),控制數據流圖是多個基本塊之間的數據依賴關系圖。程序代碼對應的數據流圖如圖3所示。

圖3 源代碼的中間表示
在生成源代碼的中間表示后,基于控制數據流圖內的數據流圖進行自定義的枚舉和選擇。其中,子圖是自定義指令的圖形化表示。
3.2 子圖枚舉
在枚舉階段中,如果生成冗余子圖,將極大地影響子圖枚舉效率。目前識別子圖的方法存在冗余問題,需進行重復檢查過濾掉重復的子圖,進而額外地增加了程序的運行時間。本文提出了一種可避免產生冗余子圖的子圖枚舉算法——DFND算法,DFND算法通過節點刪除技術使所有子圖只能被識別一次,提升了枚舉效率。
一般情況下,可以通過添加鄰居節點到預先識別的較小子圖來迭代地生成較大的子圖。例如,通過將相鄰節點添加到k-subgraph來形成(k+1)-subgraph(如果子圖中節點的數目為k,則稱為k-subgraph)。然而,大的子圖在枚舉過程中可能被枚舉多次。如圖1所示,子圖{1,2,3}可以通過添加節點2到{1,3}或者添加節點1到{2,3}生成,因而子圖{1,2,3}可以被枚舉兩次。
為了避免多次枚舉,DFND算法是以深度優先的方式枚舉出所有子圖,并在每次迭代過程中刪除已經識別過的節點。從圖1的DFG構建搜索樹并枚舉所有連通子圖的DFND算法過程如圖4所示,其中,枚舉子圖的最大節點數設為3,R={}代表記錄刪除的節點,如R={1}代表記錄刪除節點1。算法首先枚舉出包含節點1的子圖(子圖{1});然后,枚舉包含節點1和3的子圖(子圖{1,3});緊接著枚舉出包含子圖{1,3}和節點2的子圖(子圖{1,3,2})。在枚舉包含子圖{1,3}和節點5的子圖之前,應先刪除節點2。在枚舉出所有的包含節點1的子圖之后,當枚舉包含節點2,節點3,節點4或節點5的子圖時,應先刪除節點1。以這種方式可以枚舉出所有滿足條件的子圖,并且避免了任何一個子圖被枚舉多次。DFND算法的偽代碼如算法1所示。
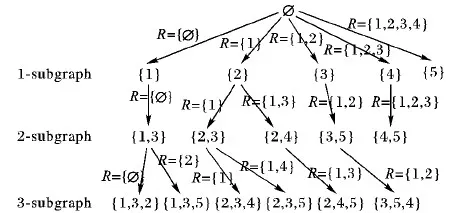
圖4 DFND算法過程圖
算法1 子圖枚舉算法。
Require:G//圖G
Ensure:CS//CS代表所有枚舉出的子圖集合
1) Procedure SubgraphEnumeration()
2)R=?; //R是記錄的被刪除的節點
3) for each noden∈Gdo
4)M={n};
5)CS=CS∪M;
6) call DepthFirstEnumeration(M,R);
7)R=R∪n;
8) end for
9) Procedure DepthFirstEumeration(M,R)
10) for each neighbour nodenofMandn?Rdo
11) if SizeCheck(M) && ConversityCheck(M,n) //進行圖大小約束和凸性約束檢查 then
12)M′=M∪{n};
13)CS=CS∪M′;
14) call DepthFirstEumeration(M′,R);
15)R=R∪n;
16) end if
17) end for
如算法1所示,對于枚舉過程中的每個子圖,都需進行圖大小約束檢查和凸性約束檢查(第11)行)。此外,該枚舉算法還可以用來枚舉分離子圖(將算法1中的第10)行替換為M的鄰居節點和非鄰居節點)。
3.3 子圖選擇
子圖選擇是在枚舉所有滿足約束條件的子圖之后進行的。由于精確算法非常耗時且通常不能在合理的時間內得出結果,因此需要更高效的啟發式方法。本文提出了3種不同的啟發式選擇方法。3種方法考慮的約束條件如下。
1)無重疊。子圖(M)或模式(P)作為候選子圖時,按照式(1)檢查已經選擇的子圖(C)與候選子圖是否有重疊部分:
M∩C=?
(1)
2)無循環。為了確保所選的子圖與當前候選子圖沒有形成循環,應該進行無循環檢查。如果當前候選子圖滿足式(2),則候選子圖與其他所選子圖之間不存在循環:
Succ(M)∩Pred(M)=?
(2)
其中Succ(M)和Pred(M)代表子圖M的后繼節點集和前驅節點集。如果候選子圖經過無重疊檢查和無循環檢查,則該候選子圖就能被加入到子圖集中。
3.3.1 基于最少子圖數目的選擇
所選子圖的數目與代碼量相關,在子圖選擇過程中,所選子圖數目越少,經代碼轉換后生成新代碼量越少。從能耗的角度出發,在給定的數據流圖中選擇最少子圖數目(MS算法)可以作為子圖選擇的一個策略。
對于選擇最少子圖數目的方法,所選子圖包含的節點越多,子圖數目越少。同時,由于自定義指令的內部數據流不包含多路選擇器,因此利用所選子圖內部邊數目可以粗略地估計節省多路選擇器的數目。然而,貪婪地選擇包含節點數多的子圖,其結果使一些包含少量節點卻能夠較好提升性能的子圖被排除。根據節點數目多的子圖與枚舉的所有子圖重疊概率大的特點,引入重疊參數。選擇較少重疊的子圖限制圖的大小。在最少子圖數目方法下,該算法根據式(3)計算每個子圖的優先級:
fi=N+E+α*1/O(Mi)
(3)
其中:N表示子圖Mi的節點數,E表示子圖Mi的內部邊數目,O(Mi)表示Mi與其他子圖重疊的次數,α表示重疊權重的參數。α小于1時,重疊對最少子圖數目的選擇方法影響過小,導致所選子圖節點數過多。為了控制所選子圖節點的數目,α的取值為2較為合適。1/O(Mi)表示選擇較少重疊的子圖。
如圖5所示,當候選子圖的最大規模為3,α的值為2時,且僅考慮連通子圖的情況下,計算子圖M1和M2的優先級。子圖M1為{1,3,4},子圖M2為{2,4,5},圖5枚舉的所有子圖為{{1},{2},{3},{4},{5},{1,3},{1,4},{2,4},{4,5},{1,3,4},{1,4,2},{1,4,5},{2,4,5}},共13個子圖,有5個1-subgraph,4個2-subgraph和4個3-subgraph。子圖M1與所有候選子圖重疊的子圖有{{1},{3},{4},{1,3},{1,4},{2,4},{4,5},{1,3,4},{1,4,2},{1,4,5},{2,4,5}},O(M1)的值為11。而子圖M2與所有候選子圖重疊的子圖有{{2},{4},{5},{1,4},{2,4},{4,5},{1,3,4},{1,4,2},{1,4,5},{2,4,5}},O(M2)的值為10。根據式(3),fM2=3+2+2*1/10,fM1=3+2+2*1/11,得到fM2>fM1,由于子圖M2與所有候選子圖有較少的重疊,最終選擇子圖M2。
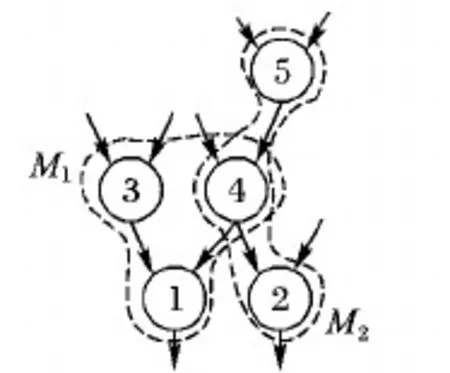
圖5 基于較少重疊的子圖選擇
3.3.2 基于出現頻率的模式選擇
基于出現頻率的模式選擇(PS)算法從提供的一系列模式當中選擇一組子集作為自定義指令。模式是一些同構子圖的圖形化表示。考慮到硬件資源重用,選擇較少數量的模式可使得高層次綜合中使用較少的面積,這樣,出現頻率較高的模式更可能被選擇。通常,較小的模式具有較高的出現頻率;然而,較小的模式可能不會帶來更好的性能提升或明顯的面積減少。根據式(4),本文提出了一個可在模式大小和頻率之間平衡的優先級函數:
fi=N*|M|+α*N
(4)
其中:N表示模式的大小,|M|表示模式對應的子圖數目。參數α用來控制模式大小所占的權重。α>1時,模式較大,而模式出現的頻率較低,不能有效地節省面積;而α<0.1時,所選模式較小,影響性能提升的效果。為了控制模式的大小,參數α取值0.3較為合適。如圖6所示,當參數α的值為0.3時,模式A(PA)的大小為3,模式B(PB)的大小為1。圖6按照模式A劃分3個子圖,按模式B劃分9個子圖。根據式(4)分別求PA和PB的值,fPA=3×3+0.3×3,fPB=1×9+0.3×1,fPA>fPB。模式A是更好的選擇。

圖6 選擇具有更多節點的模式
3.3.3 基于關鍵路徑的子圖選擇
DFG的關鍵路徑長度與程序的運行時間有關。基于關鍵路徑的子圖選擇方法(CS算法)能夠在一定程度上節省時延開銷。
如圖7所示,假設乘法需要2個時鐘周期,加法需要1個時鐘周期,子圖/模式的最大規模為2。當前關鍵路徑為{4,2,1},關鍵路徑的長度為4個時鐘周期。如果選擇子圖M1和M2,進一步假定每個子圖需要2.7個時鐘周期。顯而易見,子圖選擇之后,關鍵路徑的長度增加到7.4個時鐘周期(乘法累加器的時間延遲要少于乘法器和加法器運算的時間延遲之和)。該選擇方案最終會造成更多的時延開銷。
基于關鍵路徑的子圖選擇方法首先評估每個候選子圖,將候選子圖合并成一個節點之后,計算關鍵路徑長度。如果關鍵路徑長度增加,則放棄選擇該子圖作為候選子圖。為了不增加關鍵路徑的長度,使所選子圖的節點盡量出現在關鍵路徑上,根據式(5)按照降序排列候選子圖:
fi=|M∩CP|
(5)
其中:M表示子圖中的節點集合,CP表示關鍵路徑上的節點集合。如圖7所示,子圖{1,2}具有比子圖{1,3}更高的優先級(f{1,2}=2,f{1,3}=1)。對候選子圖排序后,評估每個候選子圖,不選擇增加關鍵路徑長度的子圖。子圖{1,2}可減少關鍵路徑的長度,則子圖{1,2}將被選擇,而不選擇子圖{1,3}。

圖7 選擇子圖導致關鍵路徑長度增加的示例
由于所提出的3種方法都是啟發式算法,主要區別在于給定的優先級函數,可使用通用的偽代碼來描述它們(參見算法2)。
算法2 子圖/模式選擇算法。
Require:CS
//CS代表全部的枚舉子圖
fi
//功能函數
Ensure:SS
//被選擇的候選子圖集
SortCSin descending order according tofi;
//根據fi降序排列
whileCS≠? do
M=the highest prioritized candidate inCS;
if Overlapping(M,SS) and Cycle(M,SS)
//進行無重疊和無循環檢查
then
if IncreaseCriticalPath(M) then
SS=SS∪M;
end if
end if
CS=CS-M;
end while
3.4 代碼轉換
在選擇一組子圖集作為候選自定義指令之后,需要確定兩個選擇的子圖集是否可以使用相同的自定義功能單元實現。此任務可以看作是一個圖同構問題,本文采用約束編程實現子圖同構算法[38]。
在將功能等效的子圖映射成相同的自定義指令之后,需要在表示自定義指令的代碼之前增加一個特定的編譯指令。自定義指令用程序語言的方法來表示。這樣,高層次綜合工具就會像對其他基本指令一樣,對自定義指令進行調度和綁定。對于高層次綜合工具CtoS(C-to-Silicon) Cadence,所有非內聯函數都被默認為自定義指令,即不需要特殊編譯指令。此外,自定義指令運算特定技術的時間和面積數據通過使用RTL綜合工具獲得。自定義指令的代碼格式如圖8所示。

圖8 自定義指令集的代碼
4 結果和分析
4.1 實驗設置
本文實驗的環境為3.5 GHz的i7- 47704處理器。實驗使用具有豐富算數和邏輯運算的測試基準程序,測試基準程序來源于MediaBench[39]和MiBench[40],測試基準程序對應的DFG包含數十個到數百個節點。實驗測試基準程序的特征如表1所示。其中:DFG1用于評價子圖枚舉算法的數據流圖的大小(節點數);DFG2用于評價選擇方法的數據流圖的大小(節點數)。測試基準程序是由通用編譯平臺GECOS進行前端編譯和模擬,高層次綜合工具CtoS用于評價該方法對高層次綜合性能的提升和面積的減少。其中,使用tutorial.lbr作為技術庫,時鐘頻率設為50 MHz。本實驗涉及到的測試基準程序包括:MP3、點積(Dot Product, DOTPRODUCT)、逆離散余弦變換(Inverse Discrete Cosine Transform, IDCT)、快速傅里葉變換(Fast Fourier Transform, FFT)、速率自適應調整(Automatic Rate Fallback, ARF)算法、無限脈沖響應(Infinite Impulse Response, IIR)、MESA(Mesa 3D是開放源代碼的三維計算機圖形庫,本文采用求逆矩陣的測試基準程序)。

表1 基準程序特征
4.2 子圖枚舉效率比較
為了評價DFND算法的效率,將DFND算法與Balister等[28]提出的較新的TD(Transitive Digraph)算法以及Chen等[14]提出的經典CMS(Chen, Maskell, Sun)算法進行了比較,3種算法具有相同的約束條件。比較結果如表2所示,第一列代表測試基準程序;NV(Number node V)和NE(Number Edge)表示DFG中的節點數和邊數;NS(Number Subgraph)表示枚舉出的子圖數;CT(Calculating Time)表示算法的運行時間,單位為ms。
從表2的結果可以看出,枚舉所有的連通凸子圖是一個復雜的計算問題。當DFG的規模較大時,枚舉所有的連通凸子圖是非常耗時的。例如,對于包含43個節點的基準程序MP3,DFND算法需要227 s枚舉所有的連通凸子圖。實驗結果表明,DFND算法優于CMS算法和TD算法。與CMS算法相比,TD算法的枚舉效率平均提升了44.5%;對于基準程序ARF,TD算法的枚舉效率提升了49.5%。與CMS算法相比,DFND算法的枚舉效率平均提升了83.8%。與TD算法相比,DFND算法的枚舉效率平均提升了70.8%;對于基準程序MESA,DFND算法的枚舉效率提升了73.1%。

表2 子圖枚舉算法的比較
4.3 面積減少率和性能提升率比較
為了評價本文提出的選擇方法,應用程序的源代碼和本方法產生的新代碼分別作為高層次綜合工具CtoS的輸入。然后,使用高層次綜合工具對兩份代碼分別進行高層次綜合處理,表3中列Patterns和Matches分別表示候選模式和候選子圖的數目。本文提出的基于關鍵路徑的子圖選擇算法、基于出現頻率的模式選擇算法和基于最少子圖數的選擇算法分別表示為CS、PS、MS。符號X_P和X_M分別表示在不同選擇方法下的模式數和子圖數(如CS_P表示基于關鍵路徑選擇方法的模式數,PS_M表示基于出現頻率的模式選擇方法的子圖數。此外,實驗中子圖節點數不超過6)。
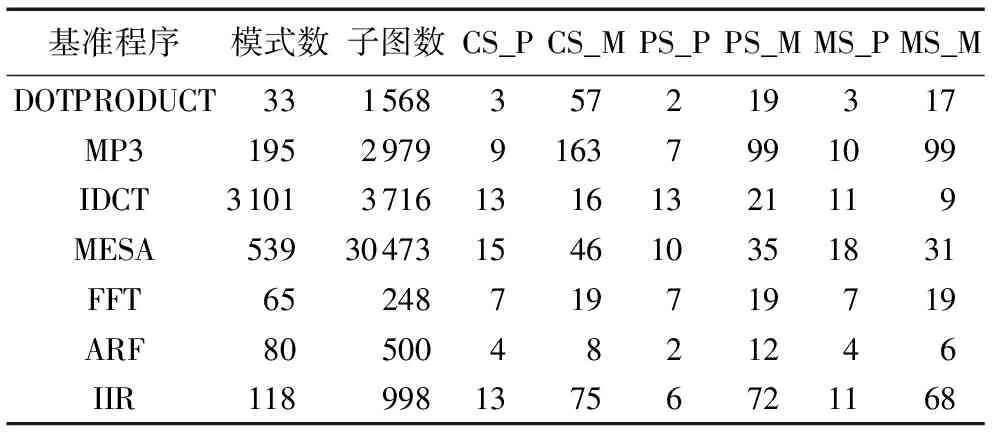
表3 選擇的模式和子圖的數目
相比傳統的高層次綜合,本文提出的3種不同的子圖選擇方法對面積減少的結果如圖9所示。其中,圖9中的平均值表示對于7個基準程序的平均面積減少量。實驗結果表明,不同的基準程序面積減少不相同。對于基準程序MP3使用CS算法可以減少41.6%的面積,對于基準程序DOTPRODUCT只減少5.5%的面積。通過觀察發現,兩個基準程序對應的DFG形狀有很大差別,基準程序DOTPRODUCT對應的DFG是一個樹形圖,而基準程序MP3對應的DFG是一個網狀圖。通常,網狀圖具有較高密度的內部數據流。由于內部數據流可以粗略地表示多路選擇器的數目,從具有更多內部數據流的網狀圖當中提取自定義指令可以節省大量的多路選擇器。總體上,PS算法較其他兩種選擇算法能減少更多的面積。
相比傳統的高層次綜合,本文提出的3種不同的子圖選擇方法對性能提升的結果如圖10所示。使用不同的選擇方法在性能提升方面有很大的差異:CS算法能較好地提升性能,而其他兩種算法不能提升性能,甚至可能降低性能,這主要是因為CS算法評估了關鍵路徑長度。實驗結果表明,對于基準程序DOTPRODUCT使用CS算法的性能提升達59.4%,然而,對于基準程序IDCT的性能提升只有12.2%,因此對于不同的基準程序,性能提升的效果差異明顯。

圖9 3種選擇算法減少面積結果比較

圖10 3種選擇算法提升性能結果比較
綜上所述,相比傳統的高層次綜合:采用PS算法可平均減少19.1%的面積,最高可減少37.1%的面積;同時,采用CS算法平均可獲得22.3%的性能提升,最高可達到59.4%的性能提升。相比Cong等[7-8]把自定義指令應用到高層次綜合過程中的方法,本文方法能夠在減少面積和性能提升之間提供更好的權衡。
4.4 代碼減少率比較
為了評價代碼的減少量,使用式(6)計算代碼減少率:
RSize=((|G|-|G′|)/|G|)*100%
(6)
其中:|G|代表源代碼中的運算指令數目,|G′|代表新代碼運算指令的數目。
使用三種子圖選擇方法減少的代碼量如圖11所示,最少子圖數目選擇算法顯著地減少了代碼量。最少子圖數目選擇算法更傾向于選擇較大的子圖,而另外兩種算法考慮到出現頻率或關鍵路徑傾向于選擇較小的子圖。例如,對于基準程序DOTPRODUCT,MS算法可減少81%的代碼量。該算法可平均減少74%的代碼量。通過減少代碼量,高層次綜合工具需要更短的時間去處理新代碼,進而更快地產生電路設計方案。

圖11 3種選擇算法減少代碼量結果比較
5 結語
本文利用自定義指令在專用硬件中可以提升性能、減少面積和減少代碼量等優點,提出了面向高層次綜合的自定義指令的自動識別方法。該設計方法克服了現有研究必須在高層次綜合過程中識別自定義指令的限制。本文的DFND子圖枚舉算法可通過修改約束條件靈活地枚舉出滿足用戶需求的子圖。該算法以一種節點刪除技術使得一個子圖只被識別一次,顯著地降低了枚舉算法的運行時間。此外,不同的選擇方法使高層次綜合在解決性能和能耗問題上具有一定的應用價值,并且CS算法在面積減少、性能提升和代碼量減少之間提供了很好的折中。
針對PS算法和MS算法對部分基準程序會帶來負性能提升的問題。下一步的工作是結合PS、MS、CS三種算法的優點改進子圖算法的功能函數,使子圖選擇算法能夠更好地權衡性能、面積和代碼量。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
兒童故事畫報(2019年5期)2019-05-26 14:26:14
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
西安航空學院學報(2014年5期)2014-07-13 01:27:52
