基于殘差回歸網絡的復雜背景下海界線檢測?
2018-08-28 02:50:36邱藝銘杜華軍郭硯輝
艦船電子工程 2018年8期
邱藝銘 杜華軍 馬 杰 郭硯輝 呂 武
(華中科技大學自動化學院 武漢 430074)
1 引言
無人水面艇(Unmanned Surface Vessel),是一種無人操作的水面艦艇,需要在復雜海情下(海、天、地背景)自動檢測和識別海面目標,海界線的檢測具有非常重要的價值。主要體現在:1)排除陸地和天空的虛假目標或者噪聲所帶來的干擾;2)在遠距離平視觀測狀態下,艦船目標大概率會出現在海界線位置,檢測出海界線的位置有利于縮小海面目標搜索范圍;3)根據多幀海界線的歷史運動軌跡,可以估計無人艇當前的運動姿態,消除慣導累積誤差,提高航行過程中的穩定性和安全性。
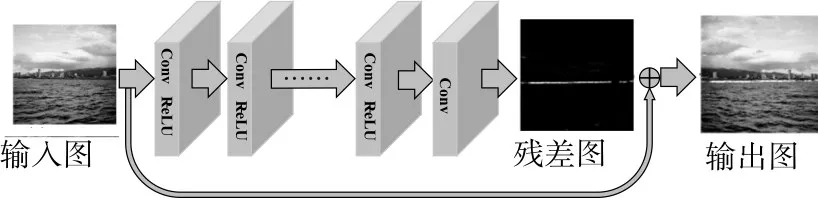
圖1 殘差回歸網絡結構圖
海界線是由海面向天空或者海面向陸地的一條明顯分界線,但是由于海面天氣復雜(如雨、霧、霾等),會降低圖像清晰度,導致海界線的邊緣信息不明顯;海界線附近干擾物(如礁石、輪船)會破壞其直線特征;海面的波浪及天空的云層還有陸地的建筑等可能呈現出與海界線相似的直線特征,造成誤判。因此進行海界線的精準檢測至今未取得較好的解決方法。針對該難題,近年來國內外學者進行了大量的研究工作,王博[1]等首先采用梯度顯著性計算有效增強海界線的直線特征,再采用梯度生長方法實現了最終海界線的檢測。Wang[2]和 Kim[3]等利用隨機一樣性(RANSAC)算法實現對海界線的擬合;Zou[4]等提出了一種基于剪切波變換算法,通過辨識邊緣的梯度方向信息來進行海界線檢測;曾文靜[5]等采用周圍紋理抑制的Canny邊緣檢測和Hough變換的方法實現了海界線檢測;孫雄偉[6]等利用雙邊濾波原理實現海界圖像的保邊抑噪,圖像邊緣方向信息相位編碼的增強和抑噪,然后以相位組分內掃描線的響應強度累積值和海界區域內像素強度分布模式的差異值辨識出最優海界線的位置。Evgeny[7]等對幾種常用的海界線檢測算法進行了對比總結。上述方法基本都是基于邊緣梯度特征來進行海界線的提取,但是由于海面狀況復雜,各種干擾信息(如云層、水花、水波浪紋、海面船只、礁石及建筑信息等)都會造成與海界線相似的梯度特征,影響最終海界線的精確檢測。
基于淺層的圖像梯度信息是很難將圖像中非海界交界處的邊緣特征濾除掉。為了解決這個問題,我們設計了一個基于卷積神經網絡的殘差回歸模型來進行海界線檢測,其能有效地濾除除了海界線之外的梯度信息,精準地檢測出當前圖像中海界線的位置。
2 基于殘差回歸的海界線檢測
近年來隨著公用數據集的增長,GPU并行速度的倍增及深度學習的迅猛發展,計算機視覺領域中的卷積神經網絡研究得到了質的飛躍,各種網絡結構 模 型 層 出 不 窮 ,比 如 AlexNet[8]、VGG16[9]、GoogLeNet[10]及 ResNet[11],基本都朝著網絡深度加深并且訓練速度加快的方向發展。CNN模型中擁有著多層的卷積、激活及池化層,通過反向傳播的訓練方式,能夠自動提取非線性表達能力強、可區分能力佳的高級特征。采用CNN模型后,不僅在高級任務(如檢測、跟蹤、識別)等取得了重大的突破,在一些低級任務中,如圖像去噪、超分辨率及去霧等領域也有了顯著的提升。本文方法有效地利用了CNN自動提取高級特征的優點,設計了殘差回歸網絡進行海界點的概率估計(網絡結構如圖1所示),再通過OTSU及meanshift聚類算法,去除無效的干擾點,最終通過最小二乘有效進行海界線的檢測。本文主要突出點如下所示:
1)采用在海界線處用白線描繪的方式進行標簽集的制作,突顯網絡的學習目標是海界線,有效濾除復雜海界背景下其他梯度信息的干擾,且網絡的輸出結果易于理解,方便后續進一步處理。
2)基于 ResNet[11~12]的思想,采用殘差回歸的方式進行網絡訓練,將標簽圖與原圖相減后的殘差圖作為我們需要學習的目標,簡化學習的任務,有效縮減模型深度,提高模型的收斂速度。
3)采用深度學習與傳統機器學習相結合的方式進行海界線的提取,在測試集上的檢測準確率相比傳統的海界線提取算法有顯著提升。
4)既可以檢測直線形式的海界線,也可以檢測曲線形式的海界線。
3 模型構建
由于學習目標是檢測海界線的位置,所以采用回歸模型來進行網絡搭建。在學習任務的描述上,先后采用了多種方式進行試驗。

圖2 原圖與標簽圖
3.1 模型設計
我們開始嘗試著進行圖與圖之間像素點的直接回歸,簡化學習的抽象程度。在標簽集的制作上,采用了巧妙的方法,為了強調海界線是需要學習的對象,人工對處于海界線處的像素用白線進行描繪,提高其與周圍背景的對比度。采用白線的原因主要兩個:1)該顏色與整個海界背景具有較為明顯的差異性2)通過將網絡訓練出來的輸出圖與原圖進行相減,得到的差值圖中每個像素點的值可以大致理解為該像素點屬于海界點的概率大小,利于后續算法處理。原圖與標簽圖對比如圖2所示。
模型代價函數為最小平方和損失函數如下:
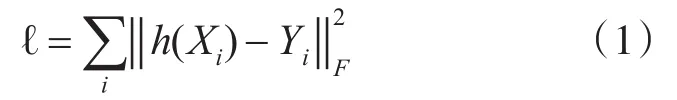
其中X表示輸入圖片,Y表示輸出圖片,h表示卷積網絡中間處理過程。由于是進行全圖直接回歸任務,所以為了不破壞空間位置信息,中間沒有采用任何池化操作,基本單元由卷積和修正線性單元(Relu)組成。訓練過程的損失值變化如圖3所示,可明顯觀察到損失值只在剛開始有過一次顯著下降,之后就呈小幅震蕩狀態,并未收斂。對輸入圖和標簽圖的顏色直方圖(如圖5(d)和5(e)所示)進行分析,其中所有像素值都已經歸一化到了[ ]0,1 ,可以發現回歸模型要學習的任務需要將輸入圖中所有范圍為的像素值映射到輸出圖中所有范圍值為的像素值,這是一個較為復雜的任務,對于我們當前的模型容量來說明顯處于嚴重欠擬合的狀態。

圖3 不同網絡收斂性對比,縱軸對數處理
3.2 殘差回歸
在當前的模型容量中,如果要使得網絡得以收斂,需要簡化學習的任務,從殘差網絡[13~14]中得到了啟發。由于網絡學習的目的是得到海界點的位置,那么將標簽圖Y與原圖X相減得到的殘差圖(Y-X)即為海界點概率圖,其顏色直方圖如圖5(f)所示,與圖5(d)和圖5(e)相比,可以發現其顏色變化范圍已經顯著縮減,大部分區域屬于0附近,如果將殘差圖作為回歸任務要學習的目標,學習任務即可以得到大大的簡化。新的網絡模型結構如圖1所示,其中將輸入圖像與最后一層卷積層的輸出直接逐像素疊加,作為目標函數的輸入,新的模型代價函數如下

通過圖3分析,可以發現殘差回歸網絡的收斂性能相比直接回歸大大提高。
為了進一步加快網絡收斂速度,通過分析殘差圖,可以得知最后一個卷積層的輸出除了海界線位置外應該基本都為0,再進一步分析圖1中的網絡中間層結構(簡化為如下公式所示)。
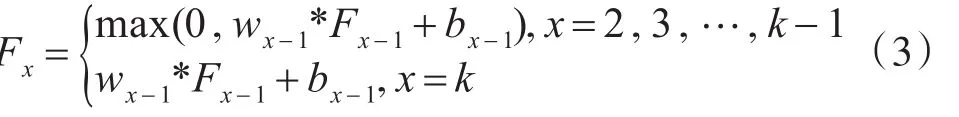
其中*表示卷積操作,w為卷積核,b為偏置,若將卷積單元和修正線性單元(Relu)作為網絡中一個基本單元,則F1為原始輸入圖像,Fx表示經過x個基本單元處理后的輸出特征圖,k表示網絡中間層數。為了使得Fk中的元素基本為0,就必須使得每一層的w和b基本為0,又為了打破網絡對稱性,所以我們采用高斯核初始化w,對b則采用固定值進行初始化,經過實驗,發現w在均值為0、方差為0.001,而b在值固定為0的時候收斂最快,其網絡收斂性如圖4所示,通過與經典MSRA的參數初始化方式相對比,可以發現在訓練初始階段,網絡的損失值就已經很小,顯著加快了收斂速度。
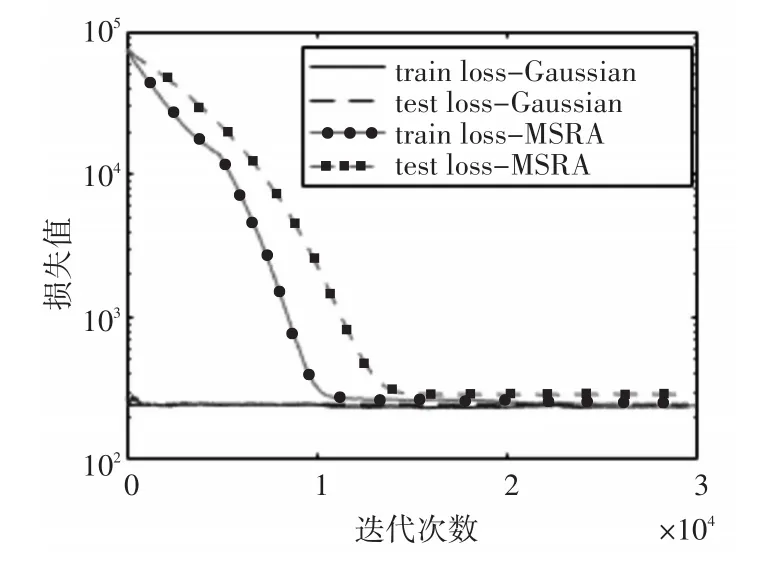
圖4 不同參數初始化對網絡收斂性影響,縱軸對數處理
3.3 數據集的生成
由于網上沒有公開的關于海界線檢測的數據集,所以我們人工制作了一個,數據集中圖片分別來源于 VOC[13]、IMAGENET[14]、COCO[15]這些公開數據集及搜索引擎獲取的與海界面相關的圖片。為了獲得較為真實的實驗結果,對數據集中的圖片進行了嚴格的篩選,對于人工合成、卡通、高壓縮、嚴重運動模糊、低曝光或者高曝光等嚴重失真的圖片都一律舍棄。經過篩選之后,最終確定的數據集共有2817張圖片。然后經過隨機抽取,總共選取其中2317張作為訓練集,500張圖片作為測試集。而在標簽集的制作上,我們采用的方法是對于處于海界線的像素點全部采用半徑為1的白色圓點進行標記。對于橫跨海界線的,比如輪船、礁石、魚等,一概不予標記。

圖5 顏色直方圖對比
4 Meanshift聚類與曲線擬合
4.1 Meanshift聚類
原始圖片經過殘差回歸網絡處理后,其輸出的殘差圖即為海界線概率圖(如圖6(b)),我們首先采用OTSU算法對概率圖進行閾值分割,初步獲得所有前景點,但是由于噪聲點的存在,并非所有的前景點都是海界點。根據觀察分析可知,海界點在圖像處中所處的行位置信息及其四周的顏色特征一般都比較相近。于是對于每個前景點,共提取了7 維特征 (Row,Ru,Gu,Bu,Rd,Gd,Bd)來對其進行表征,其中Row表示前景點所處的行數,Ru,Gu,Bu表示前景點上方中心(W*H)范圍內所有像素的RGB 平均值,Rd,Gd,Bd表示前景點下方中心(W*H)范圍內所有像素的RGB平均值。根據對比實驗,W取值為9,H取為8。然后采用聚類算法對所有的前景點特征向量進行有效歸納,在聚類算法的選擇上,采用了meanshift算法,又稱為均值漂移算法,其無需預先設定聚類的個數,并且對離群點很魯棒。其主要聚類過程如下:
1)在未被標記的前景點中隨機選擇一個點作為中心點。
2)采用歐式距離計算所有前景點到中心點的距離,然后找出距離中心點在δc內的所有前景點,記為集合M,設定這些前景點屬于類C并進行標記。把這些內點屬于類C的頻率加1,如果內點個數小于指定的閾值δn,則重新回到步驟1)。
3)通過式(4),計算出偏移向量 Δx,其中 n表示所有的內點,x表示當前的中心點,w表示各個特征。
4)權重值,⊙表示點乘。然后重新計算新的中心點 x=x+Δx。重復步驟2)、3)直到 Δx的值收斂小于指定閾值δΔx或者超過指定的迭代次數δt,然后保存當前的中心點。
5)重復1)、2)、3)、4)直到所有的前景點都遍歷過。
6)對于每個前景點,獲取對其訪問頻率最大的那個類作為其所屬類。

根據大量對比實驗,最終 h、δc、δn、δΔx、δt的取值分別0.35、0.35、0.1n、0.00035、20,其中 n 表示前景點的個數。而在w中Row的權重為6,其余顏色特征權重都為1,最終處理結果如圖6(d)所示。
4.2 曲線擬合
由于海界線不僅有直線也有曲線的形式,在此我們采用最小二乘法對經過噪聲處理后的海界點進行曲線擬合。

圖6 算法處理過程示意圖
設定擬合多項式為

其中y表示海界點的縱坐標,x表示海界點的橫坐標,k表示維度,本文取為2。其偏差平方和則為
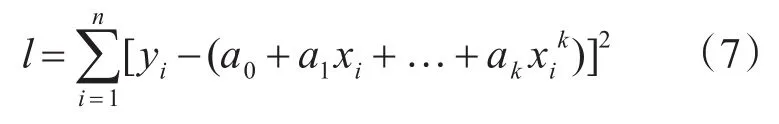
對等式右邊的ai{i=0,1,...k}求偏導,可以得到:

經過化簡并寫成矩陣形式,可以得到:

然后采用LU分解,即可得到最終的系數解,其最終的擬合結果如圖6(d)所示。
5 實驗
為了體現本文算法的高性能,我們與另外兩種常用的海界線提取算法 RANSAC[2]和 HOUGH[5]方法進行對比。采用Caffe深度學習框架來進行殘差網絡的訓練,訓練時間需要10.5h,訓練參數如下所示。
5.1 參數設置
經過實驗分析,我們最終使用的網絡深度為5,采用隨機梯度下降法(SGD)來進行訓練,權值衰減系數為10-4,動量(momentum)為0.9,批大小為16,總訓練批次為80000。學習率剛開始為10-4,經過迭代60000后改為10-5。網絡中所有的卷積核大小都為3×3,除了最后一層卷積核通道數為3之外,其余的通道數都為64,較大的通道數有利于獲得跟多的特征信息,提高結果的準備性。輸入圖片大小統一縮放到224×224,這個尺度能夠在縮小處理時間的同時保證檢測率基本不變。數據集只采用了翻轉擴增方法,所以最終總共有4634張訓練圖片,1000張測試圖片。
5.2 測試集處理效果
圖7展示了采用本文基于殘差回歸網絡的海界線檢測效果圖,使用的都是屬于測試集中的圖片且每張都十分具有代表性,分別是在存在大量云層干擾、海浪干擾、大面積遮擋、海界線分界不明顯、陸地信息復雜及海界線為曲面的情況下采集得到的。圖7(b)中算法采用的核心思想是計算圖像中每列梯度的最大值點然后用RANSAC進行直線擬合,但是在復雜背景中,云層、海浪及船只等所形成的邊緣梯度很可能會大于海界線的梯度,所以導致較高的錯誤率。圖7(c)則是利用HOUGH方法[5]得到的結果,但是同樣在復雜背景下,云層、海浪及船只等邊緣形成的干擾直線特征對最終的檢測結果造成了嚴重的影響。而圖7(d)則是采用本文的海界線檢測方法,從效果圖中可以看出在各種復雜海界背景下,其依然能精準地檢測出海界線的位置。
5.3 性能測試
測試平臺采用的PC操作系統是Windows 10,擁有32GB內存,4.2GHz的CPU及NVIDIDA的1080GPU,擁有8GB顯存。對于海界線檢測準確率的計算,我們采用平均偏離誤差大小來判斷海界線是否檢測準確,其計算方式如下:

其中n表示測試集的大小,m表示圖像的列數,tj和pj分別表示標簽圖和實際預測圖中海界線在第j列中的位置,由于在標簽圖中海界點被遮擋的位置由-1表示,所以需要排除這些點。k則表示標簽圖中有效的海界點個數,而e則為允許容忍的誤差。各種海界線檢測方法在測試集上的檢測準確率和平均計算速度如表1所示,所采用的測試圖片大小都為224×224,其中本文方法和RANSAC方法[2]都采用GPU進行優化。通過對比可以發現,RANSAC方法[2]雖然具有較快的計算速度,但檢測準確率太差。而HOUGH方法[5]相比RANSAC方法[2]在檢測準確率上雖然有一定的提高,但依然達不到可用的標準。而本文方法在檢測準確率遠遠高于其他兩種方法的同時還能保持較好的實時性,且當容忍平均偏離誤差減小的情況下,檢測準確率基本沒有太大的變化,充分說明了本文方法的抗干擾能力極強,在復雜背景下,依然能精準地檢測出海界線的位置。

圖7 海界線檢測效果對比圖
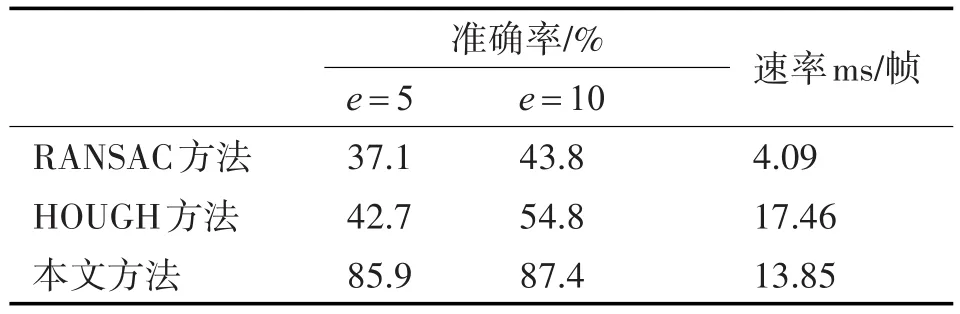
表1 海界線檢測效果對比
6 結語
在復雜海天或者海陸背景下,由于云層、海浪及嘈雜海面等各種干擾因素存在,對于海界線的檢測產生了嚴重的干擾。本文提出了一種基于卷積神經網絡的海界線檢測算法,利用殘差回歸網絡獲得海界點的概率圖,然后使用傳統機器學習聚類算法meanshift進行干擾點排除,最終通過最小二乘法獲得最終海界線的位置。經過測試集的驗證和分析,結果表明了本文方法在檢測準確率大幅度高于RANSAC[2]及 HOUGH[5]等方法的同時,依然能保持著很好的實時性,非常具有實際使用價值。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
